产品介绍
产品背景
国家十四五规划及2035年愿景目标纲要中提到,要加快数字经济、数字社会、数字政府,以数字化转型整体驱动生产方式、生活方式和治理方式变革。新一代信息技术与行业加速融合,企业数字转型需求日益显现。为企业数字化提出了更高的目标“业务模式数字化+客户体验数字化+运营管理数字化”,企业数字化转型的要义:技术与业务的快速融合。 变革为企业带来机遇的同时也迎来了新的挑战,转型过程中的业务连续性成为了企业快速发展过程中的生命线,而业务连续性管理将成为运维的核心。 此外,在国产化浪潮下,主流软硬件更迭加快,在政策和技术的双轮驱动下,国产软硬件的市场份额逐年增加,基础软硬件国产化是IT市场发展必然趋势
IT运维困境
IT资产管理混乱,无法定义资产价值
- IT资产数量多,关联关系复杂多变,手工管理起来乱如麻,造成维护成本高,数据质量差。资产维保到期无感知,资产盘点无从下手,常规的运维工作极难开展;一旦出现故障,不知道找谁处理,不清楚影响范围有多大
IT监控缺乏全局视角,业务故障无法快速解决
- 每天接收海量告警事件,“狼来了”的故事持续上演,真实故障无法被响应;业务故障无感知,用户报障方察觉,信息部门变“救火队”,被动支持问题;无法清晰直观的展示业务系统的运行状态;
IT运维成本高,方式方法落后,产能低
- 高达80%时间手工处理重复、繁琐、低价值的日常运维工作,运维效率低;主机分散,运维入口不统一,权限无法统一控制,发生事故难以定位定责;经验难传承,“师傅带徒弟,口口相传”,不能形成知识库;
运维服务投入大,业务对服务的价值无感
- 服务请求量大,运维同事长期处于找人或者各种事件确认过程,造成大量的时间浪费;事件请求多以电话、企业微信等方式接收,常常出现事件处理遗漏或者遗忘等情况,经常导致用户投诉;运维人员疲于响应各类事件处理,但没有形成完整的工作记录,工作无法量化,价值难以体现;
产品定位
WeOps是为企业的IT运维部门提供覆盖资源管理、监控告警、健康扫描、运维工具、知识库等多项功能为一体的运维工具,通过打通各业务单元、贯穿各技术栈,以故障定位和全生命周期管理为核心,持续保障业务连续性。
产品架构
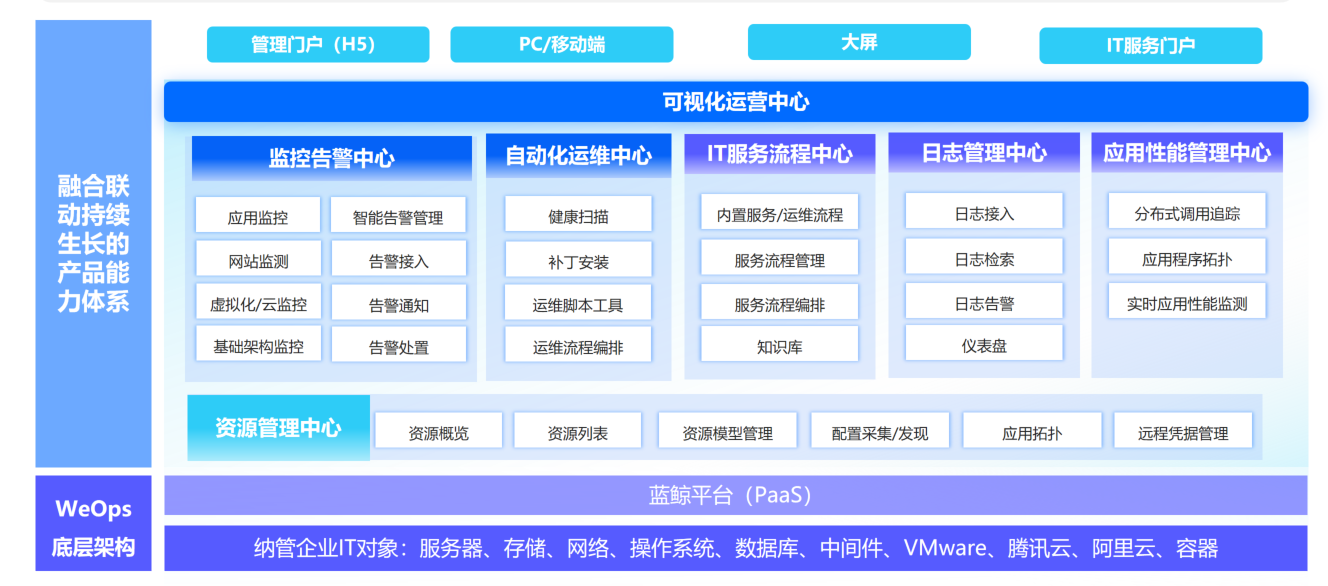
产品模块
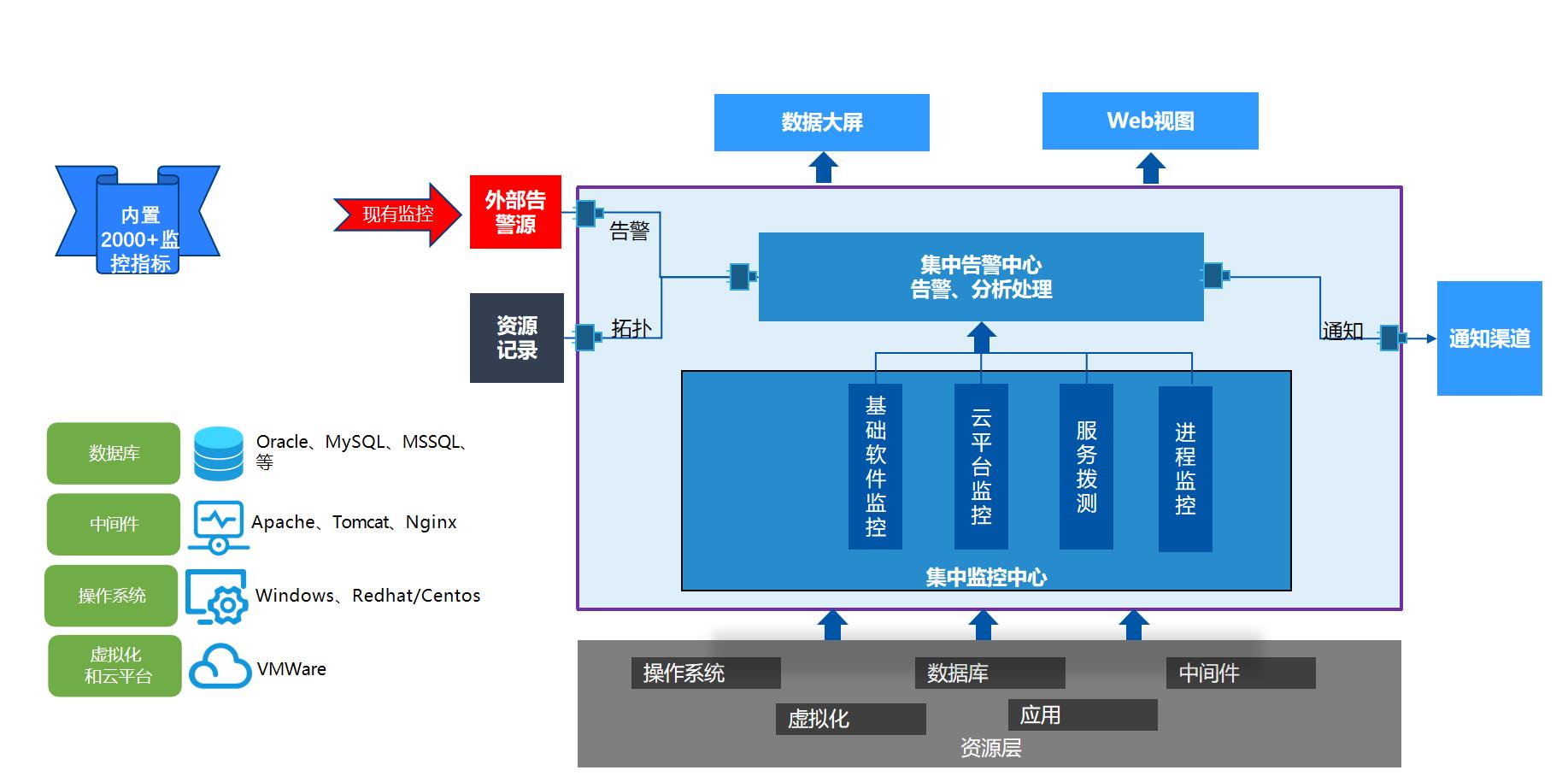
智能监控:业务及组件全方位监测,及时全面感知问题
WeOps性能监控提供统一的视图,支持看到应用整体的运行情况,覆盖:主机、数据库、中间件、K8S、网站、虚拟化、邮件系统、AD等对象
与其他监控工具不同,WeOps各模块之间融合联动,性能监控和智能告警、知识库以及自动化工具共同组成“发现问题-分析问题-解决问题-沉淀经验”的场景闭环,有效提升IT运维质量。
- 便捷易用,提供统一的应用视图
- 强大的监控能力,覆盖常用IT对象的2000+指标
- 具备自动化能力快速分析和解决问题
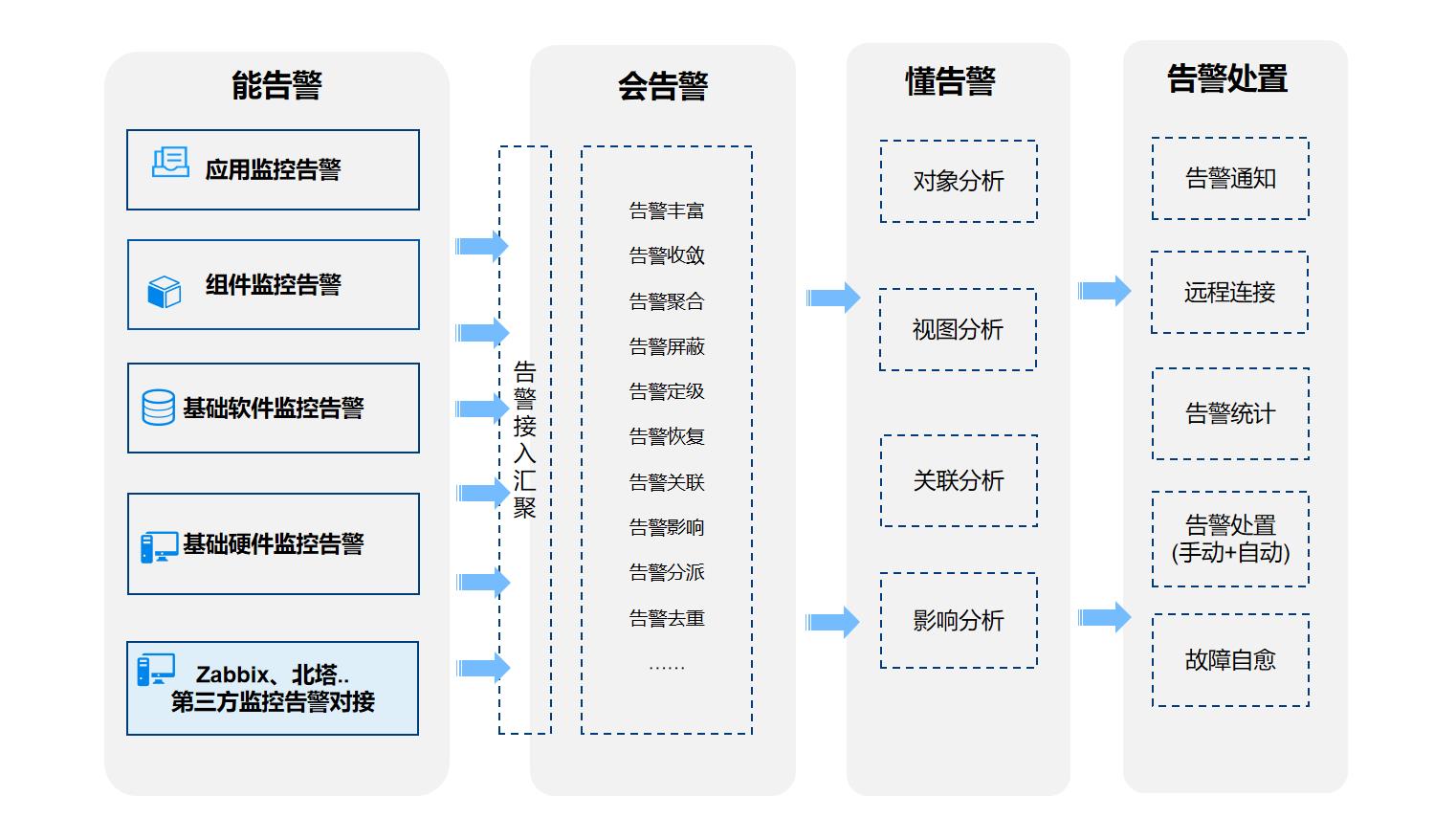
智能告警:故障及时感知,降低故障排查时间,提升运维效率,降低运维成本
WeOps智能告警提供智能处理告警的能力,集中海量的告警事件进行降噪和关联分析,辅助根因定位,并可联动自动化工具实现故障自愈,从而提升企业的运维效率,降低运维成本。
- 支持接入其他系统的告警事件进行集中管理
- 自动屏蔽无效告警,过滤重复告警
- 展示告警对象的关联拓扑,辅助根因定位和影响分析
- 故障自愈
日志管理:日志统一采集和管理,满足合规性要求
满足日志管理合规性要求,快速提高日志价值获取效率,扩充监控能力,完善监控体系。
- 使用无代理日志收集、基于代理的日志收集和日志导入,包括Syslog、JSON、Kafka、AMQP、SNMP等多种输入源
- 提供了多种日志字段提取的方式,将日志进行结构化,提取出相应的字段信息,有助于日志后继的分析
- 使用全文搜索引擎打造秒级关键字搜索功能,输入搜索条件一键抵达事件发生现场,无需手动登陆服务器查看日志。
- 提供监控告警规则,灵活配置支持各种日志监控应用场景,通过企业微信、电话等方式多种途径及时通知。
- 根据业务情况和系统状况,可以任意灵活插拔各种分析报表。报表自动刷新,异步交互,实时查看系统总览。

IT服务台:统一门户,凸显IT运维价值
WeOps IT服务台促进IT团队对业务部门提供更加及时有效的运维持续性服务,支持快速构建服务流程,并可联动自动化工具提供自助服务的能力,提升IT服务满意度。
- 快速构建服务流程
- 为业务人员提供IT自助服务
资产记录:资产管理自动化,构建自动化运维基石
WeOps资产清单全面管理IT资产数据,自动采集资产的配置信息和关联关系,生成应用架构拓扑,提升企业IT资产管理的规范性和数据准确性。
- 自动发现资产数据和配置信息
- 自动生成架构拓扑
- 配置文件管理
- 变更记录
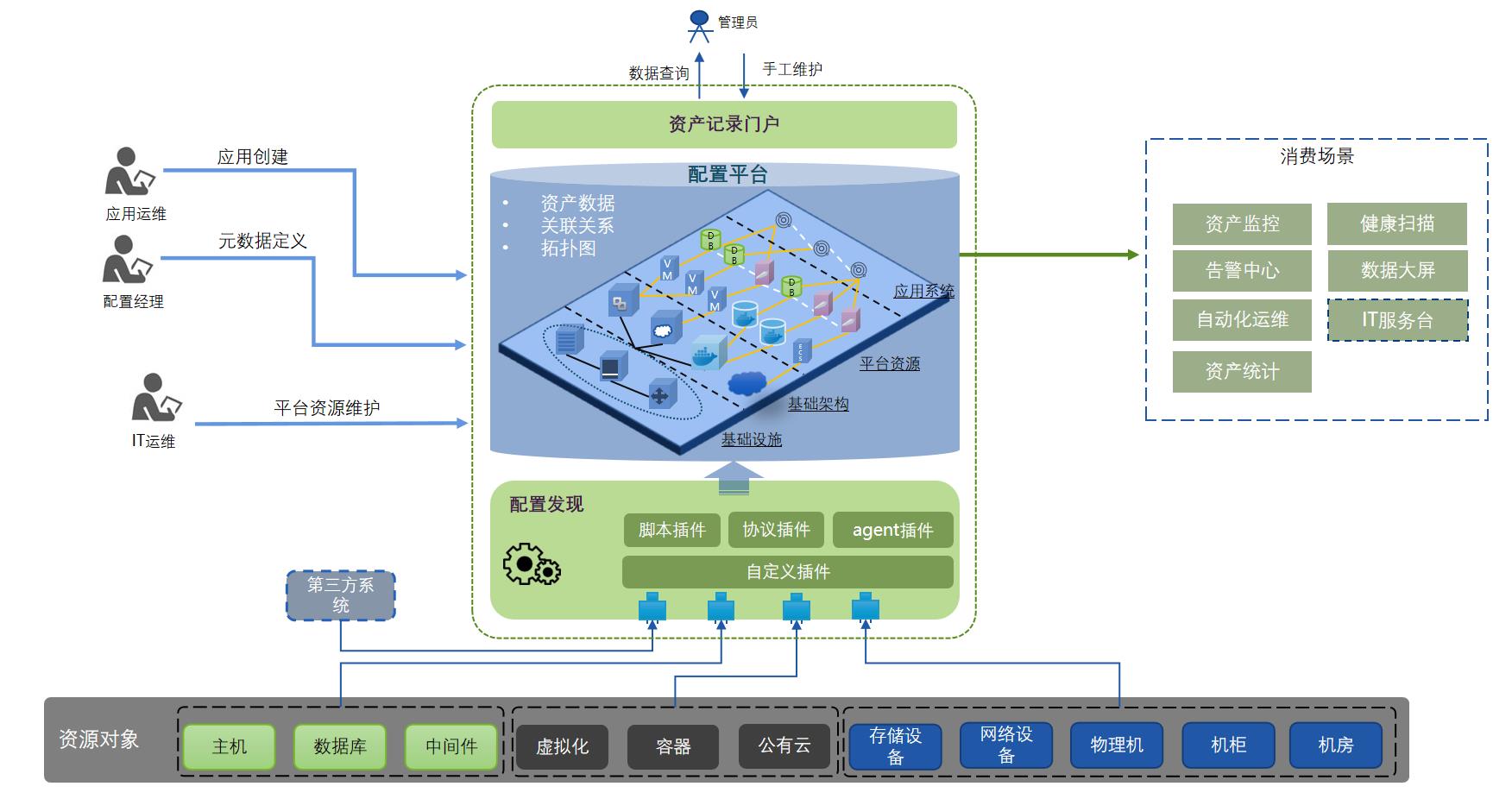
远程管理:一键远程,提供安全高效的连接通道
WeOps远程管理提供统一、安全、高效的运维连接通道,简化服务器故障分析和处理过程。
- 一键远程,高效运维
- 加密传输,安全运维
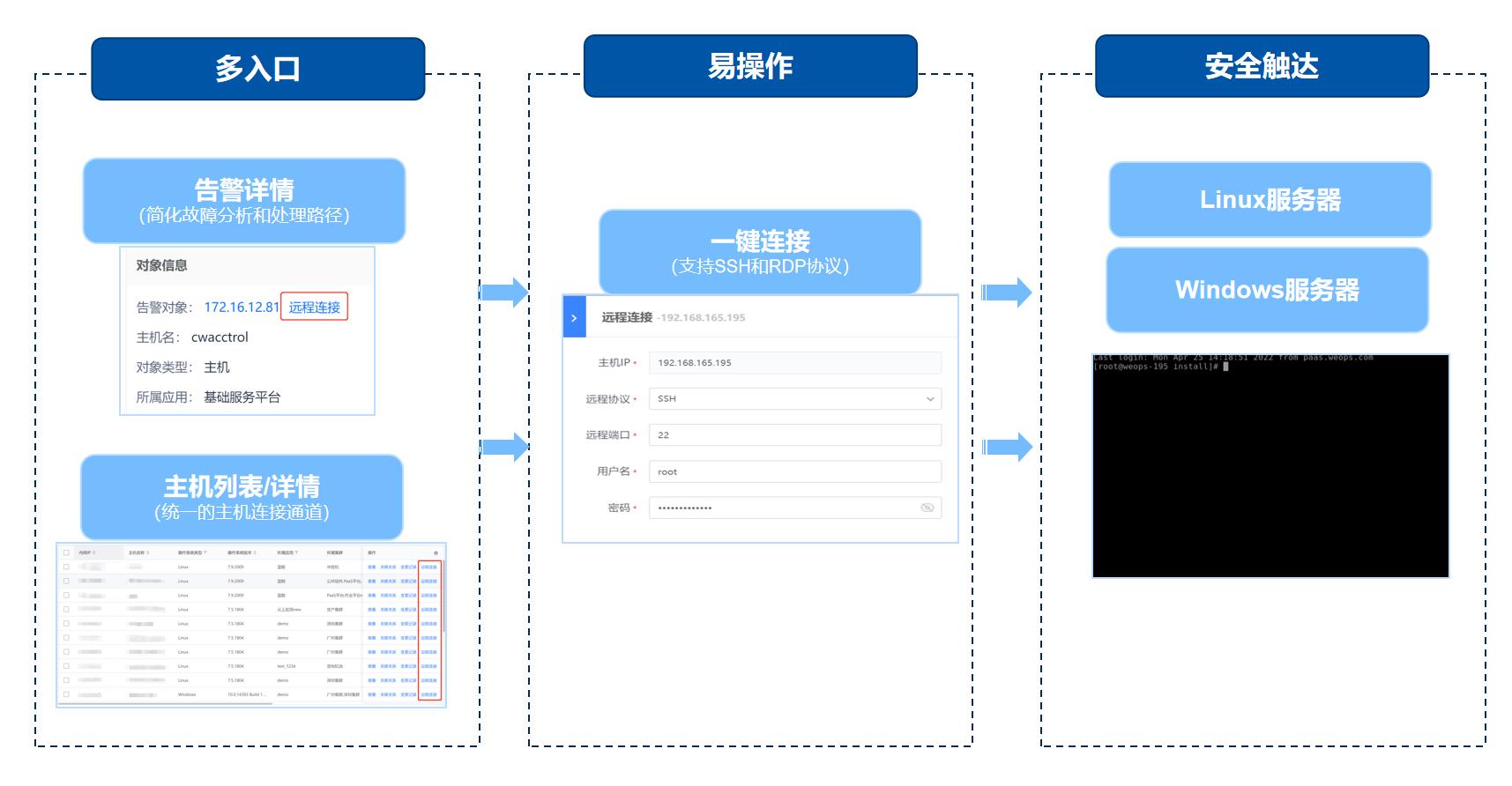
运维工具:持续积累的自动化工具,灵活丰富的故障处理手段
IT团队可以通过WeOps自动化工具将常用的脚本打包成简单易用的运维工具,支持批量快速下发脚本。 并且运维工具可被其他模块调用,如智能告警、IT服务台,形成故障自愈、自助服务等自动化能力。
- 简单易用,批量快速下发脚本
- 自定义制作运维工具
- 支持被其他模块调用
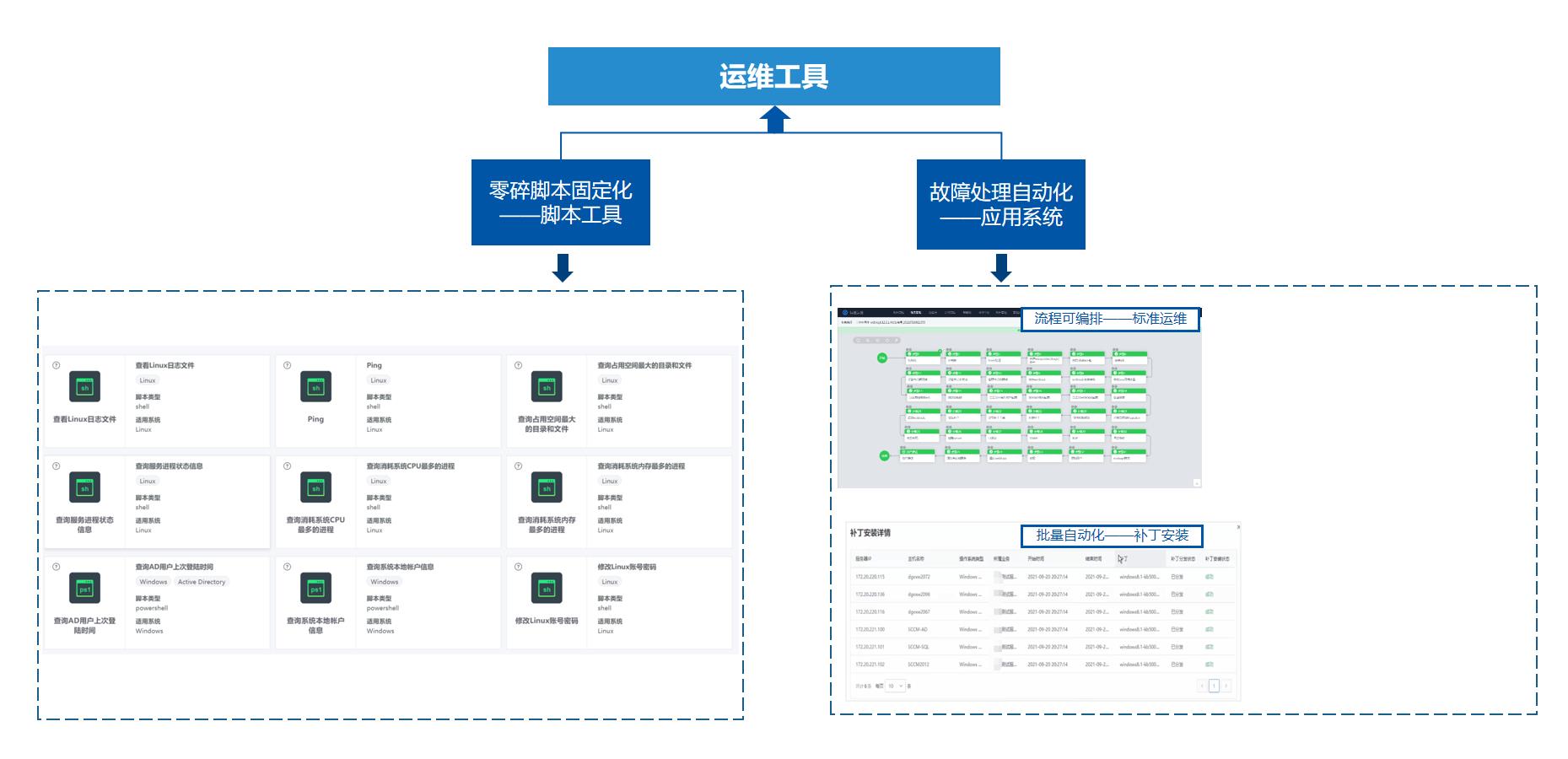
健康扫描:故障预防,消除潜在威胁
WeOps健康扫描针对各类IT资产提供了专业的巡检指标,全面检查主机、数据库、中间件、云平台等资产健康,并提供相应的改善建议。
- 定时批量扫描,高效巡检
- 专家定制巡检指标,自动生成专业的扫描报告
补丁安装:批量安装,省时省力,执行结果一目了然
WeOps补丁安装是省时省力的补丁批量安装工具,工程师不再需要彻夜紧盯,定时自动安装补丁,等待结果通知即可。
- 定时批量自动安装补丁
- 补丁安装成功率高
- 执行结果一目了然
知识库:经验复用让运维工作有迹可循
WeOps知识库和其他模块全方位打通:告警自动匹配解决方案、辅助完成服务工单、快速生成各类运维报告,让工作中沉淀的经验,灵活运用到工作中。
数据大屏:通过可视化展示全局视图
WeOps数据大屏动态汇总全局状态,运维全局一目了然,帮助管理人员直观审视业务运营与IT运维中的有效信息,提升企业IT管理的效能。
- 动态展现业务运行状况
- 持续增加场景化的精美大屏

产品优势
一站式运维体验
- 基于蓝鲸一体化平台构建,数据无缝对接,消除信息孤岛,统一访问入口,一站式使用各项运维模块,无需频繁切换。
构建故障全生命周期管理能力
- 围绕业务系统故障全生命周期管理,通过资源纳管、健康扫描、监控告警、数据大屏、运维工具之间的场景联动,贯穿“预防故障”、“发现故障”、“解决故障”的全过程,帮助IT构建故障全生命周期能力,实现主动运维。
内置海量知识
- 基于嘉为20年超过200位运维专家知识沉淀打造,助力运维最佳实践的落地。
- 内置丰富的“指标库”、“脚本库”和“知识库”,提供通用资源模型及关联关系拓扑、通用基线指标以及告警最佳实践方案。
术语解释
- 应用:指WeOps中纳管的业务系统,在传统企业中称为“应用系统”。
- 集群:用于区分一个业务的不同环境,或者同一个环境的多个部署区域。常见定义有,按照环境类型区分:正式集群、测试集群。按照区域区分:华东区、华北区。
- 模块:模块是业务拓扑管理的最小单位,通常用于标识一组固化的进程集合,例如 DB、DR、Login、Web 等。
- 空闲机:通过资源池分配到业务,默认放到空闲机模块中,在空闲机模块下即被定义为没有被设计资源。
- 实例:也称为配置实例,WeOps每条有意义的记录主体都是一个配置实例,例如一个交换机、一个主机等
- 模型:模型是对同类配置实例进行标准格式的定义,例如主机和机房有不同的配置记录需要:主机需要包含固资编号,机房需要包含运营商信息,可以定义主机、机房两个模型,以保证相关配置录入 的时候必须包含所需信息。除了属性列表以外,模型还能够定义唯一性校验、可关联性等。
- 关联关系:模型关联关系的分类,如主机与交换机、路由之间的关系可以分类为“上联”类型,软件与主机之间的关系是 “运行” 等。
- 监控指标:一般称为 Metric(s)、Item 或度量,即监控的内容,一般是坐标系中的纵坐标,比如 CPU 使用率、在线人数等
- 维度:一般称为 Dimension,区分指标的条件,比如 IP、主机名或平台(IOS、Andriod)
- 拨测节点:拨测发起的节点,就是要设置探测的源头,多个不同的位置节点检测同一个目标更能体现服务在地域上面的可用性。
- 活动告警:监控产品检测到的所有未恢复且未关闭的告警。
- 历史告警:已经恢复的告警事件。
- 告警级别:告警分为三个级别:“致命” Emergency 最严重,核心指标出现严重问题,将影响业务的稳定性,需要重点关注,红色;“预警” Critical 一般严重,需要关注,可能会导致更加严重的问题,橙色;“提醒”Warning 提示作用,需要了解,出现了问题的苗头,黄色
- 服务:服务场景的最小单元,具体提供服务的实体对象
- 服务目录:以目录列表形式,向外提供服务
- 流程:由处理人与处理节点,以及处理规则共同组成,以实现特定服务需求的功能
- 节点:流程中涉及到的每个具体步骤,或环节,或活动
- 知识库:面向用户或管理员的知识库,按类别及全文检索管理知识库
功能介绍
IT服务台门户
Weops 内置三类IT服务台门户可供选择适用,每个门户主要包括首页(提单+工单管理)、知识库(文章搜索和查看)等功能
门户的切换和主题背景图片的替换,可以在WeOps后台进行
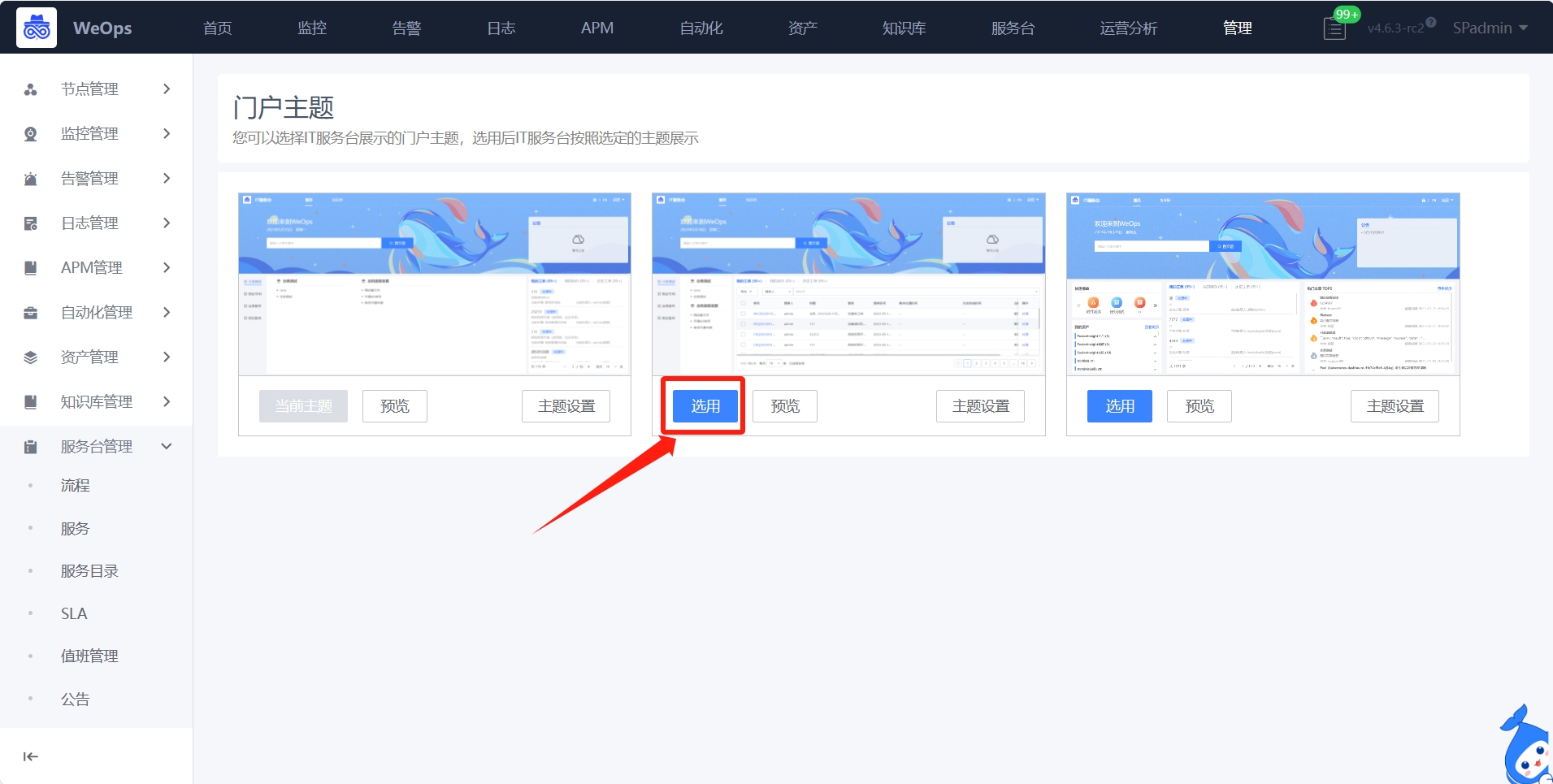
这里以其中一个门户介绍IT服务台具体的功能,服务台包括首页和知识库两大模块
首页
- 目前IT服务台已支持页面级别的中英自动翻译,包括PC端和移动端
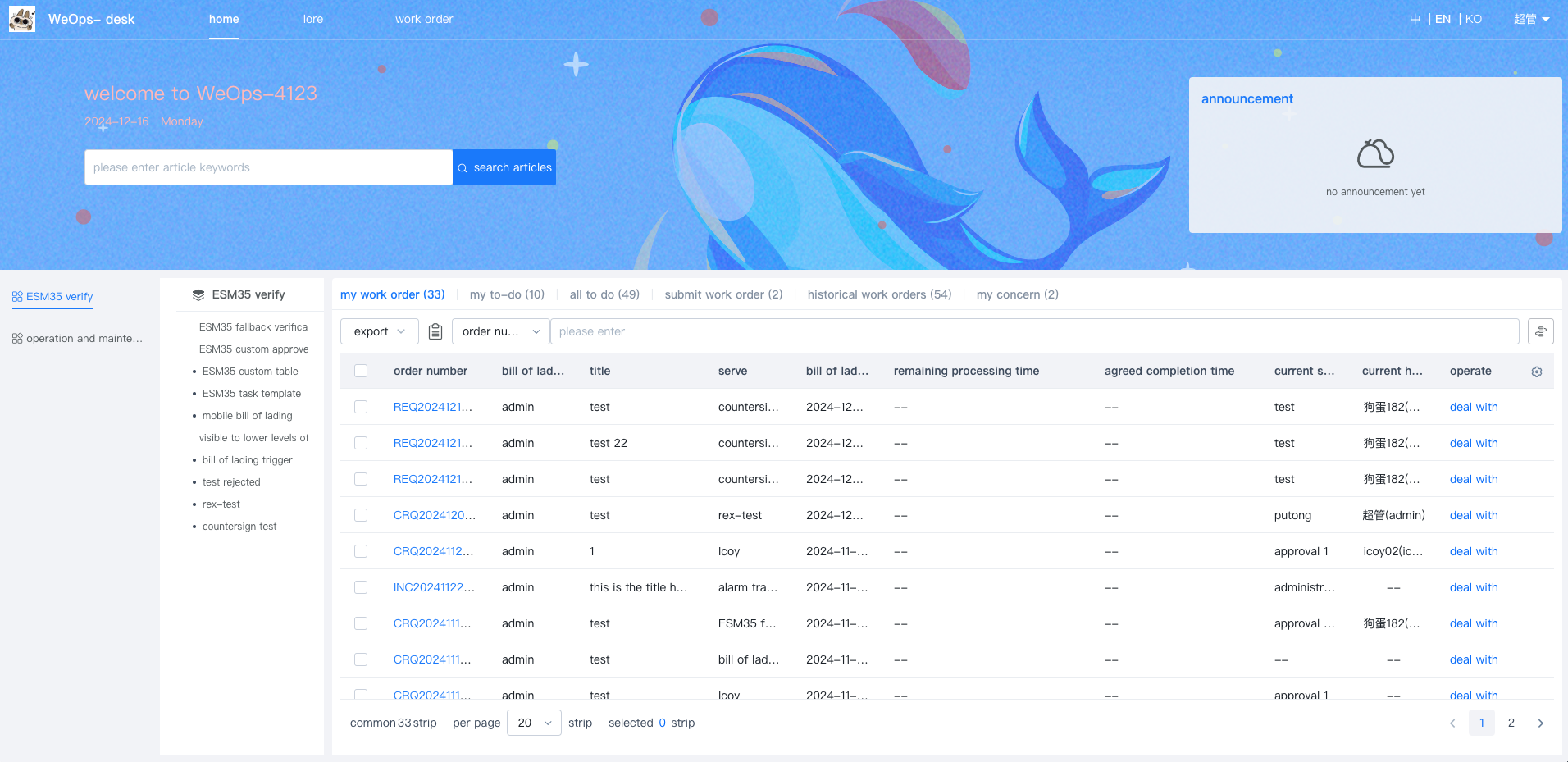
- IT服务台支持中文和英文两种语言模式,首页主要包括以下三大部分:文章快速搜索、快速提单、工单明细
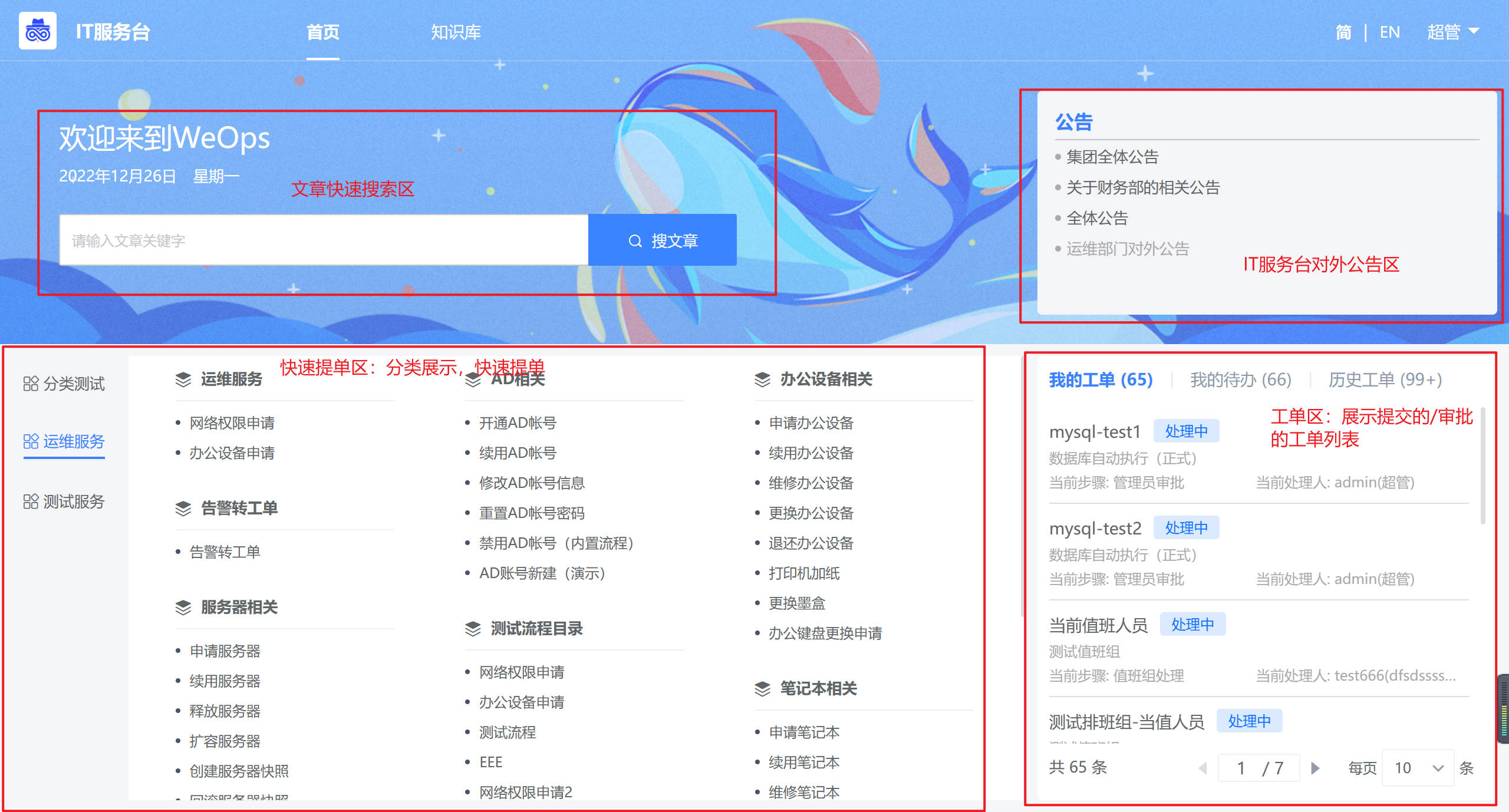
- 文章快速搜索:可在搜索框输入文章关键词,服务台知识文章进行搜索
- 快速提单:根据WeOps后台设置的服务目录展示服务流程的不同分类,可以根据分类进行选择流程,点击流程即可进行提单(这里以“申请笔记本”为例,展示提单界面。)
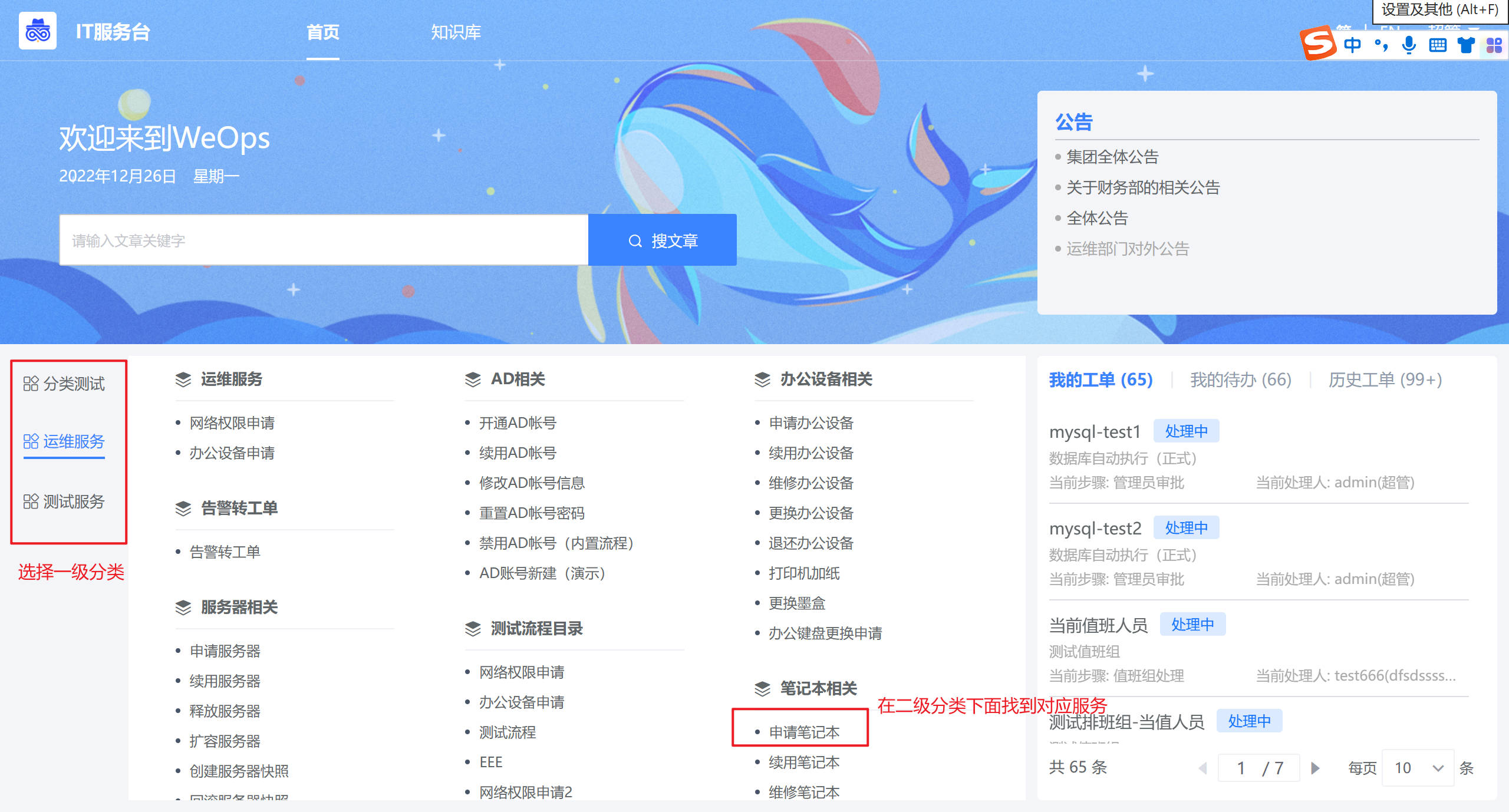

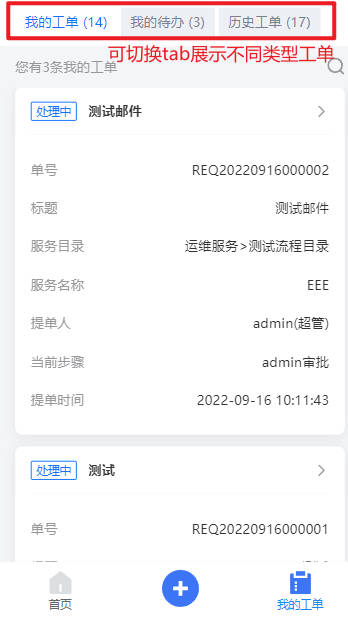
- 工单明细:展示不同状态下的工单,工单列表具体包括:我的工单、我的待办和历史工单
- “我的工单”:展示所有“我”提交的工单,展示流程名称、当前步骤和当前处理人信息以及各个工单的状态
- “我的待办”:展示所有需要“我”审批的工单,展示流程名称、当前步骤和工单创建人信息
- “历史工单”:展示与我有关的所有工单,展示流程名称、工单创建人、工单创建时间信息以及各个工单的状态
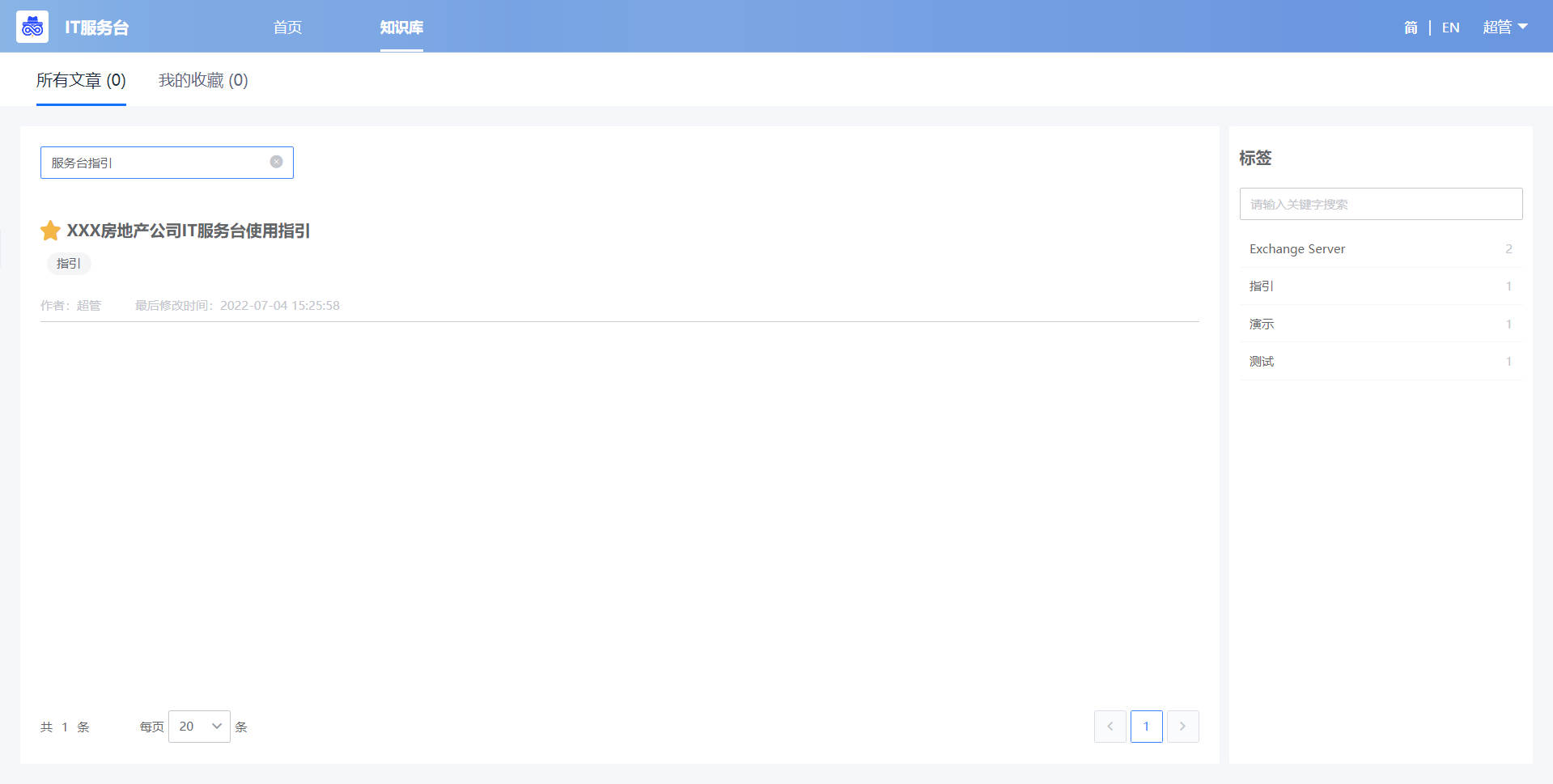
知识库
“IT服务台-知识库”展示了所有设置为“服务台文章”的文章(可在“WeOps-知识库”进行设置), 分为“所有文章”和“我的收藏”
- 所有文章:展示了在“WeOps-知识库”知识库标记的所有服务台文章,可以点击查看详情。
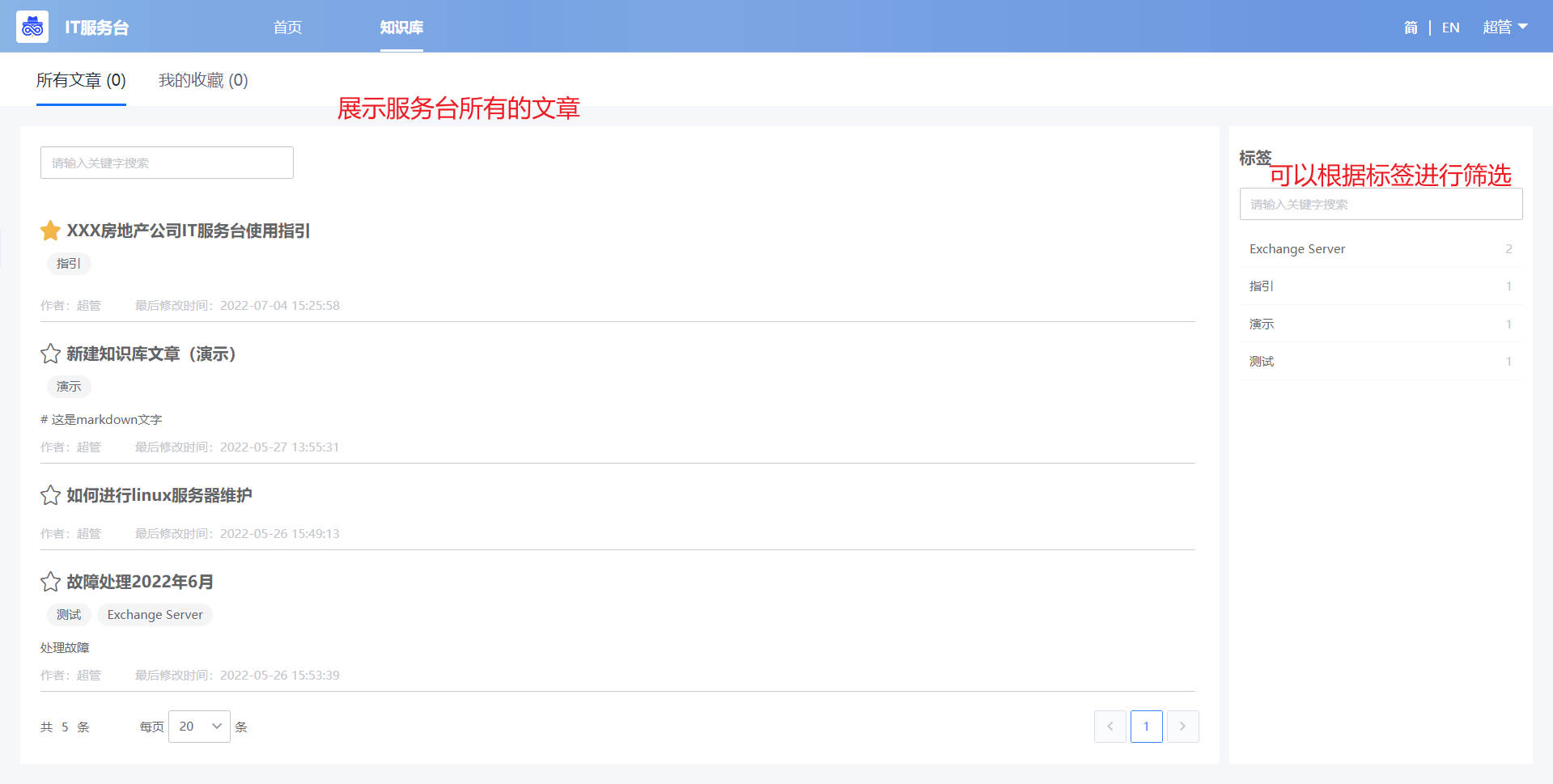
- 我的收藏:展示了我收藏的文章。
IT服务台移动端
WeOps运维平台/IT服务台支持与IM对接提供移动端操作和管理能力,默认支持企业微信、钉钉、飞书,支持通过插件拓展对接其他IM。(不支持调整移动端访问域名URL)
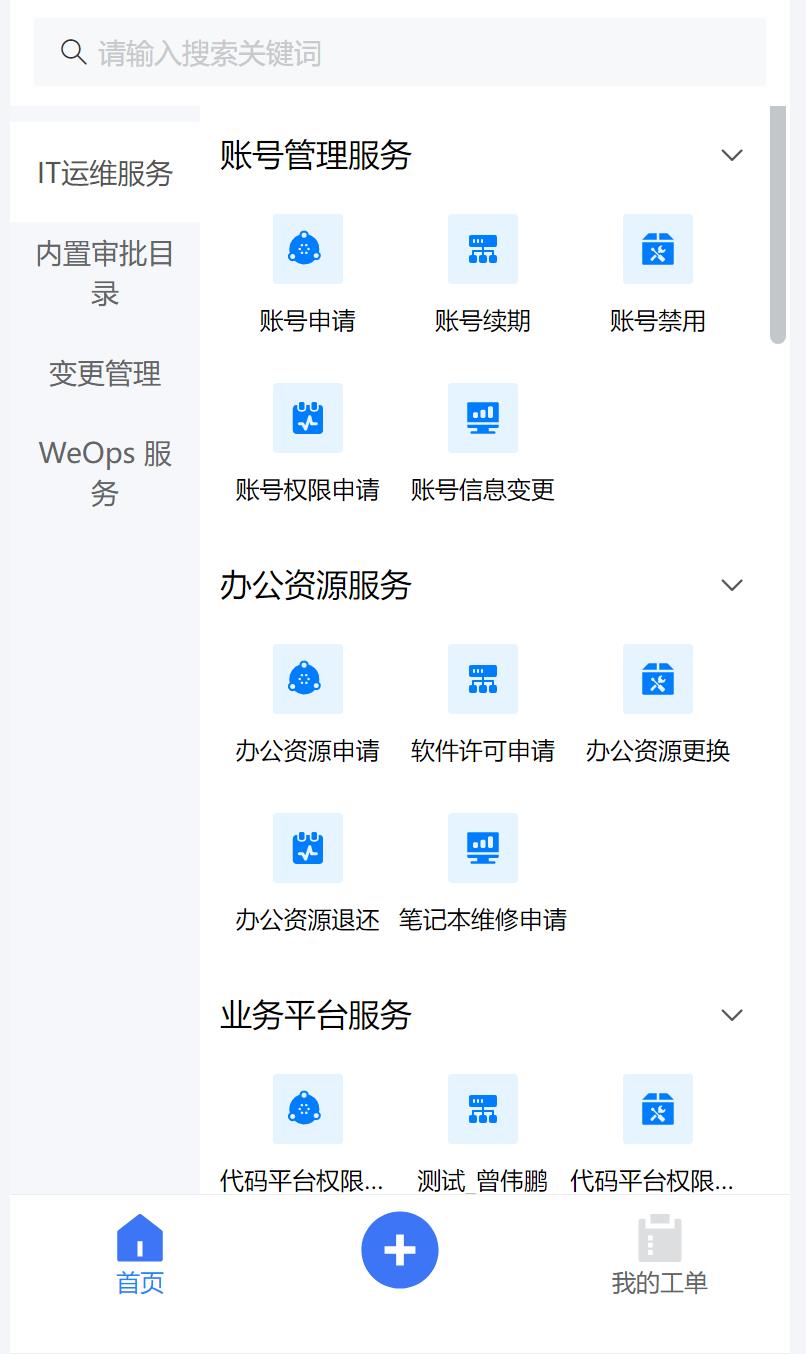
IT服务台移动端主要功能如下
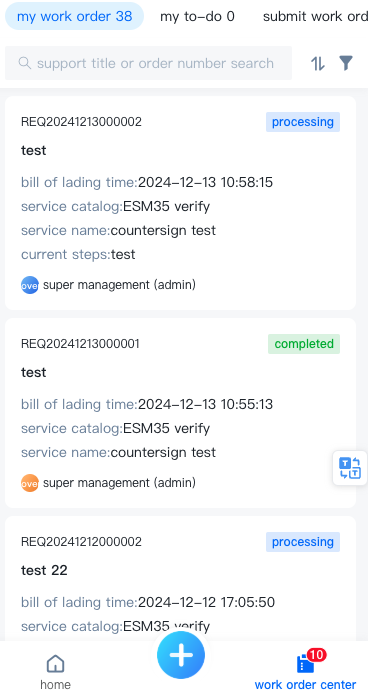
- 首页:移动端首页主要支持快速提单。
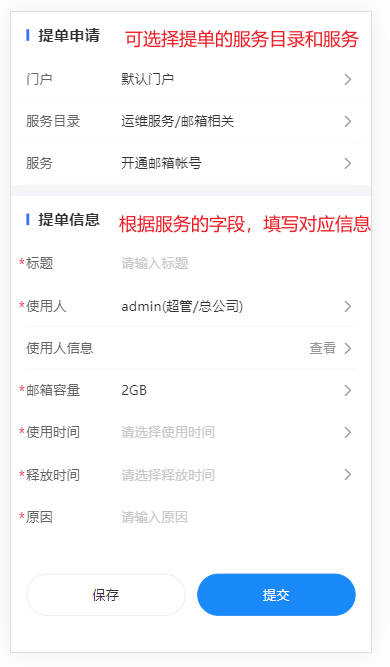
- 提单:点击首页“快速提单”的各个类型的工单管理/菜单的“+”进行快速提单,在提单页面中,在“提单申请”中,选择对应的服务目录和服务,在“提单信息”中,填写该工单的对应信息。
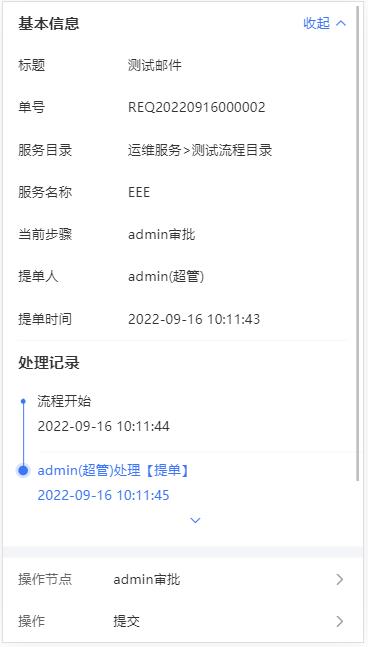
- 我的工单:我的工单包括“我的工单”、“我的待办”、“历史工单”分别展示我提交的工单、需要我审批的工单、所有与我有关的工单。
- 点击可查看工单详情
监控告警移动端
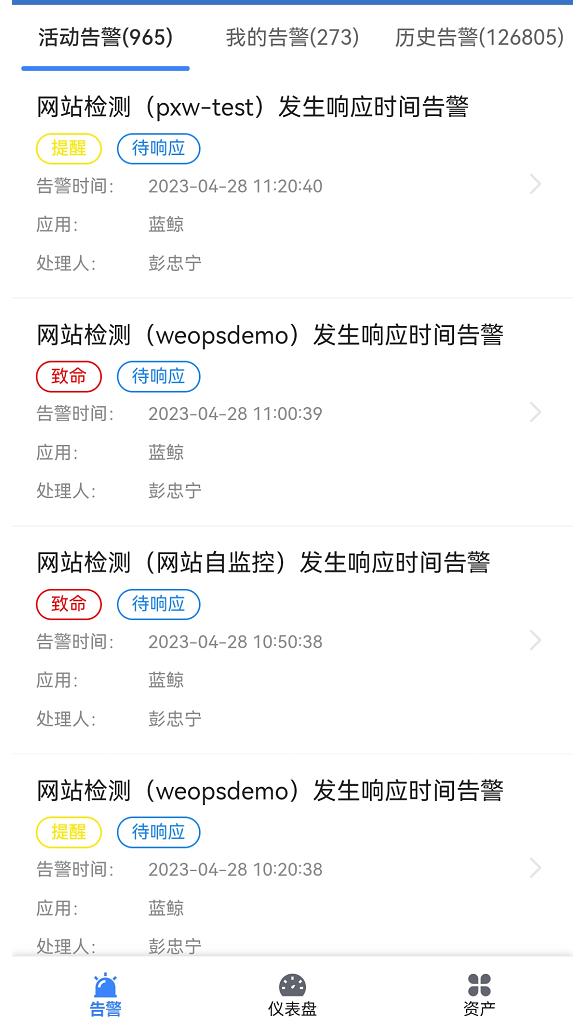
WeOps提供监控告警的移动端,满足多种场景的告警信息查看处理、监控信息查看的需求,包括告警、仪表盘、监控三个大模块
- 告警:展示了活动告警、我的告警、历史告警的列表,可以进行告警详情/视图的查看,支持告警认领/分派/关闭等处理
- 仪表盘:展示了所有视图、我的视图、我的收藏的基本情况,点击可查看仪表盘具体视图情况。
- 资产:展示了应用/基础监控/虚拟机/K8S/网站监控的基本情况,包括资产基本信息/监控视图/告警列表等,支持二维码/条形码扫描(需要使用WeOps-资产记录里面生成的资产编码),并展示扫描出来资产的监控情况、基本信息、告警情况等信息
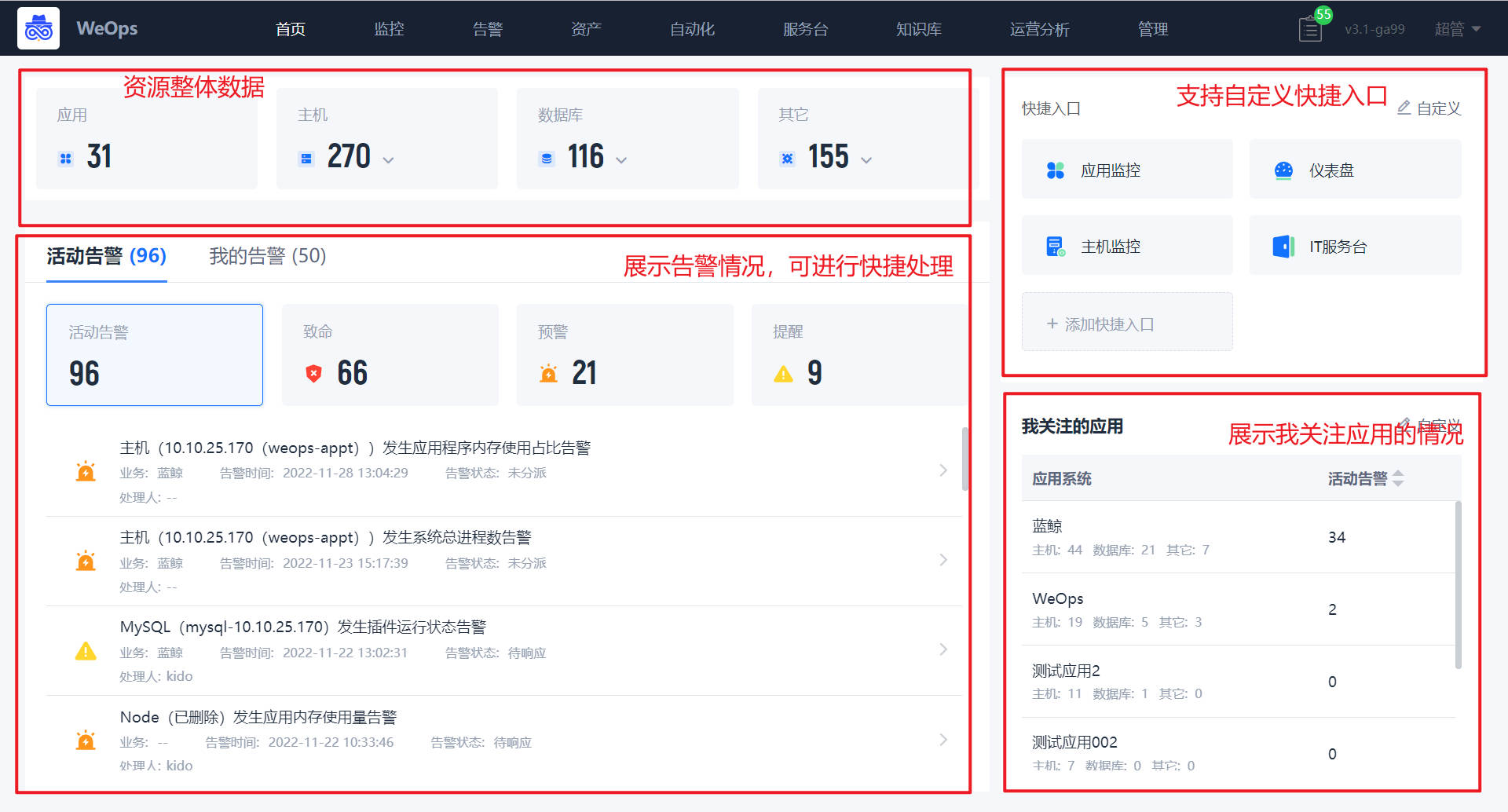
首页
首页主要展示WeOps关键的信息,可对于告警进行便捷的处理。
- ①资源情况:展示用户自己有权限的所有应用、主机(Windows、Linux、AIX、Unix、other…)、数据库(Oracle、MySQL、MSSQL、数据库集群、MongoDB、Redis…)、中间件(Apache、Tomcat、Nginx…),可以点击跳转至资产记录的对应页面。
- ②告警情况:活动告警和我的告警总数展示其中的致命、预警、提醒告警,点击告警信息,可查看该告警的具体信息,也可进行便捷的处理。
- ③快捷入口:可以自定义快捷入口
- ④我关注的应用:(我关注的)应用的资源数量、活动告警数
监控
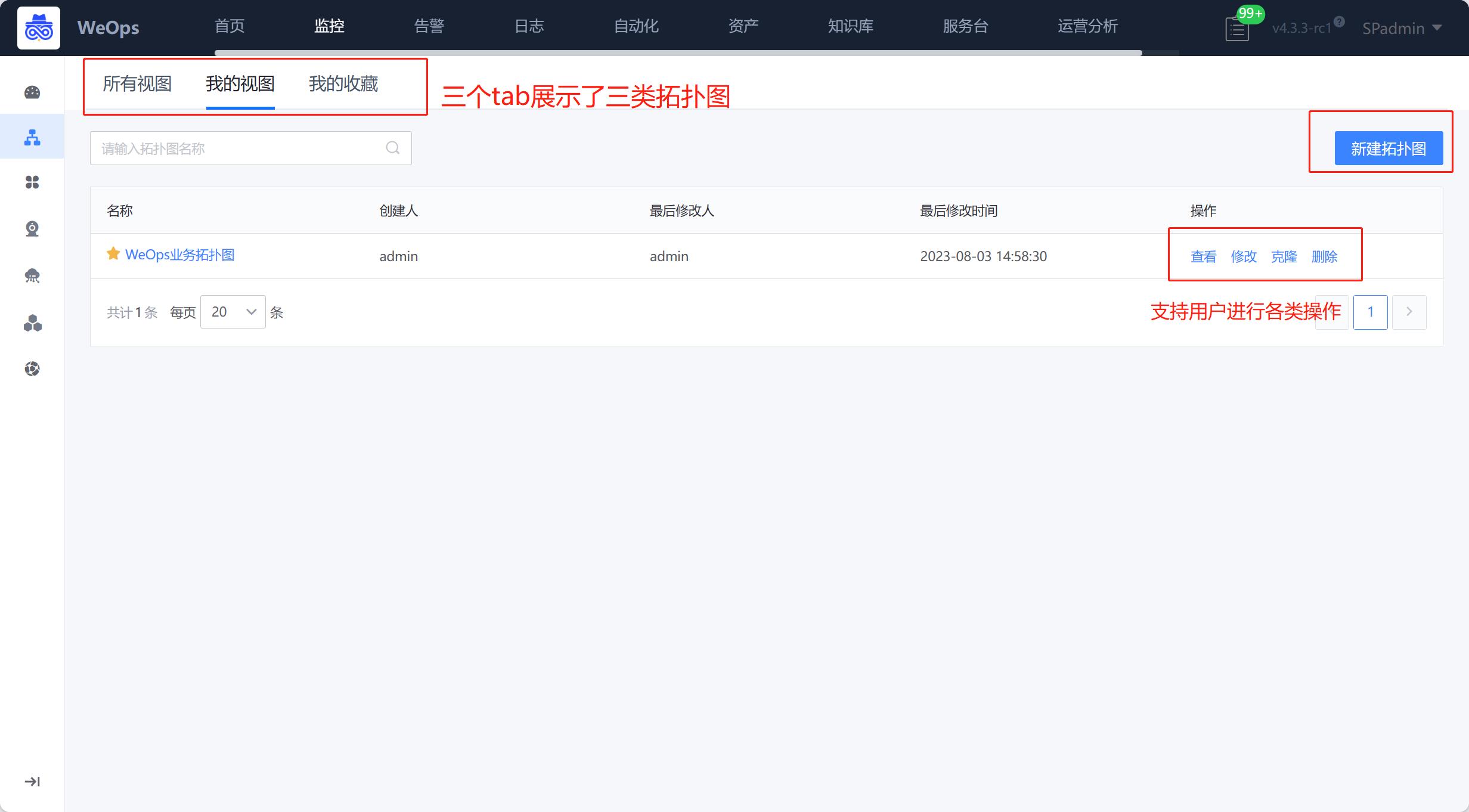
拓扑图
拓扑图支持对需要展示的资产对象进行自定义拓扑,绘制应用、资产等对象的关联关系,并展示告警信息,呈现告警关联链路。
(1)拓扑列表:拓扑列表分为三个tab:所有视图、我的视图、我的收藏。所有视图:展示我所有有权限查看的视图列表,点击进去可以查看具体的拓扑图;我的视图:我创建的视图;我的收藏:展示我比较关注的并且收藏的视图。
(2)拓扑图新建/编辑:如下图,支持进行拓扑图的绘制
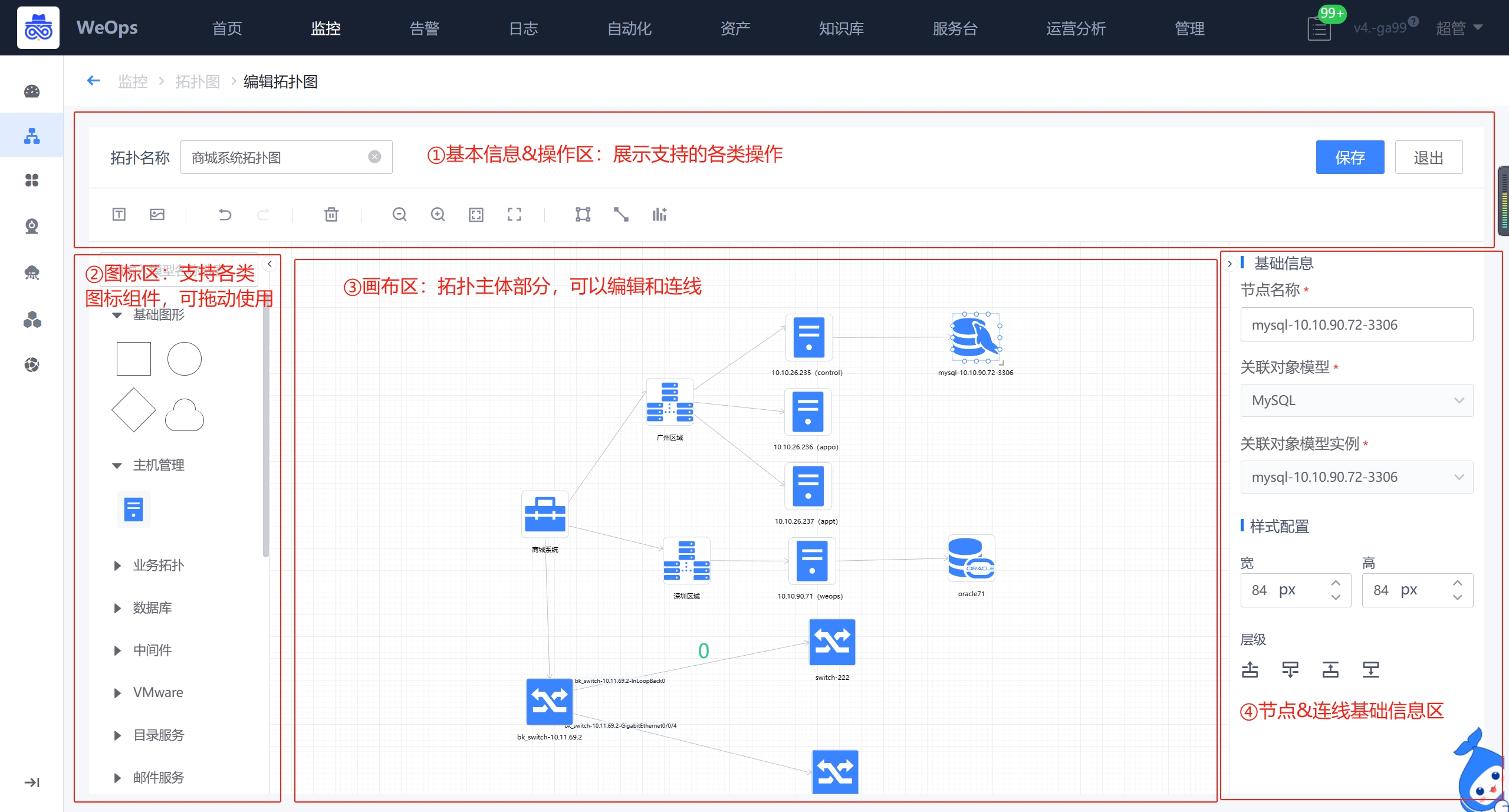
拓扑图详细操作介绍如下:
- ①基本信息&操作区:各个要素的使用和说明如下

拓扑名称:填写拓扑图的名称,并保存
文本按钮:点击按钮,再点击画布,即可插入文本,并支持编辑文本
图片按钮:点击可插入2M内的图片
撤销按钮:支持返回到上一步
删除按钮:选择画布中的节点组件/连线,点击按钮,可以删除
放大/缩小:放大/缩小画布
适配页面:将画布的要素放置为最合适的位置
全屏展示:将整个拓扑图绘制放大至全屏展示
框选按钮:选中一个要素,按住shift,可以多选其他要素
自动连线:针对网络设备类的资产,根据资产记录的关联情况,支持自动绘制连线
添加视图:支持添加“单值”类的监控组件,作为资产关联的监控关键指标展示- ②图标区:分为基础图形、业务拓扑、资产组件三类
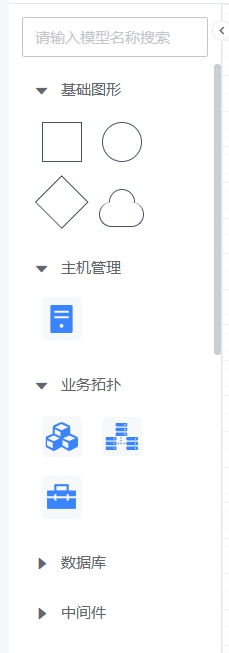
分类说明如下
基础图形:作为节点组件的装饰使用,分为正方形、圆形、菱形和云形
业务拓扑:分为应用(业务)、集群、模块三类,用于展示应用的层级
资产组件:展示各类资产,包括主机、数据库、中间件、云平台、网络设备、硬件设备等等
使用:拖动选中的组件节点至画布,可以选择需要的具体的资产(支持多选),选中后,根据选择的资产数量和类型,在画布中即可呈现出来,可以调整位置和大小。- ③画布区:各个组件支持连线,鼠标拖动调节大小等操作

- ④节点&连线基础信息区:节点基础信息支持修改节点显示名称,样式和层级;并支持设置交互跳转交互(已经内置查看详情的交互),交互设置完成后,查看拓扑图时右键可以点击操作

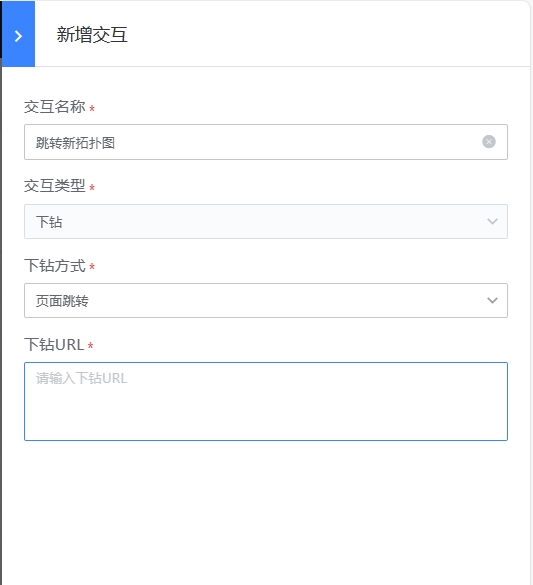
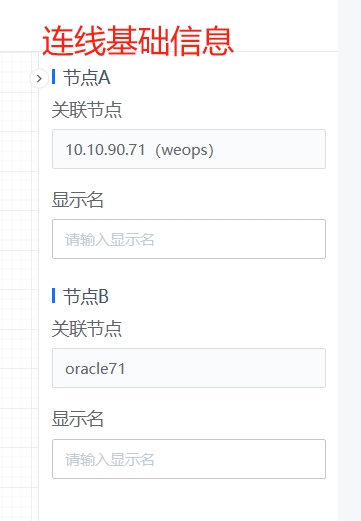
- 连线基础信息支持修改连线的显示名
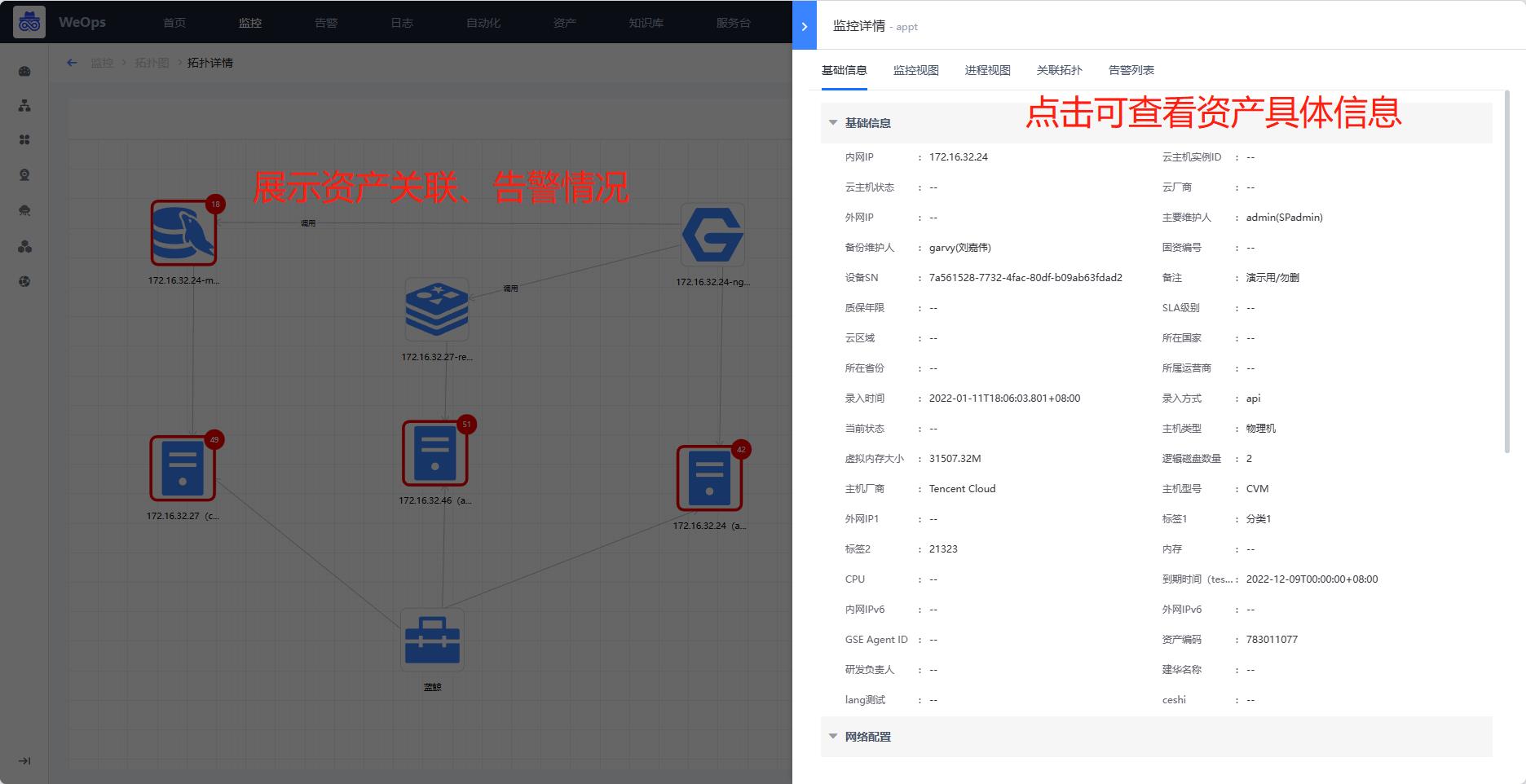
(3)拓扑图展示:点击查看拓扑图,可展示拓扑图已经绘制好的关联关系。交互:右键可以唤起交互列表(内置+自定义),内置了查看各个资产的详细信息,可以查看该资产的基本信息、监控视图、告警列表、关联拓扑等信息,其他交互可以按照规则点击使用。
仪表盘
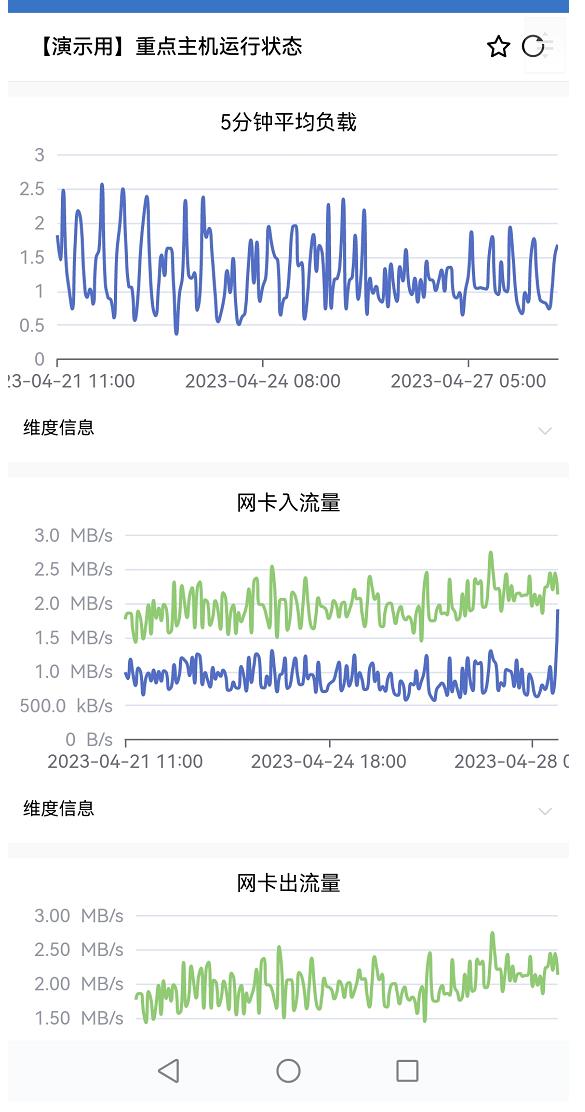
监控仪表盘可以进行快捷简单的监控视图配置,支持“仪表盘”、“折线图”、“柱状图”、“饼形图”、“单值”、“资产表格”、“运维工具”、“日志消息”、“日志表格”、“高级组件”等图表,可展示多项资产信息。
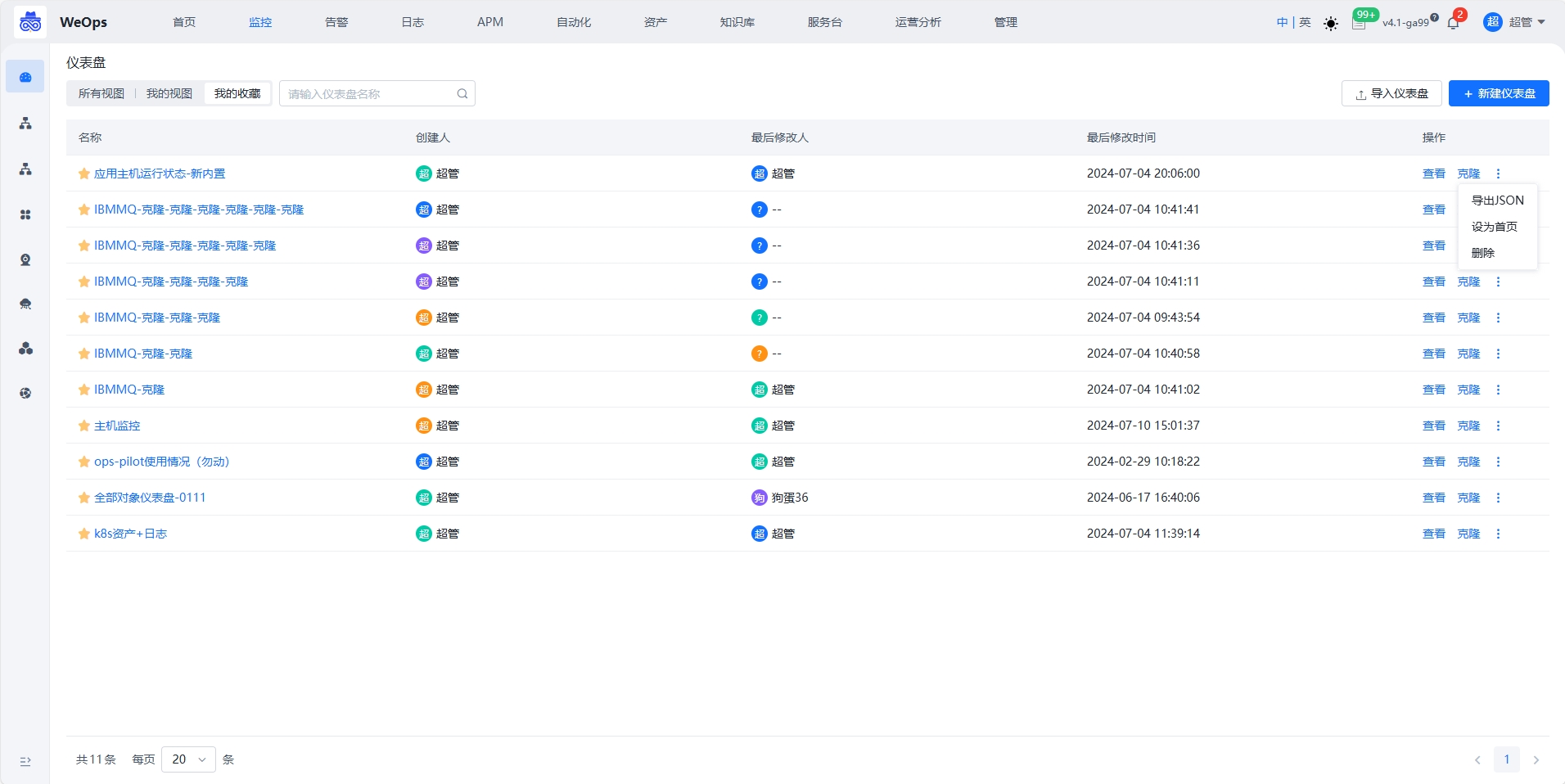
仪表盘列表
如下图,“仪表盘”列表页,分为所有视图、我的视图和我的收藏,支持仪表盘的创建、查看、克隆、修改、收藏、仪表盘的导出和导入、设置为首页。
仪表盘支持设置为首页,或者对已经设置为首页的仪表盘进行还原,如下图,设置首页后,该仪表的数据在首页展示,但是不能切换资产或者编辑。
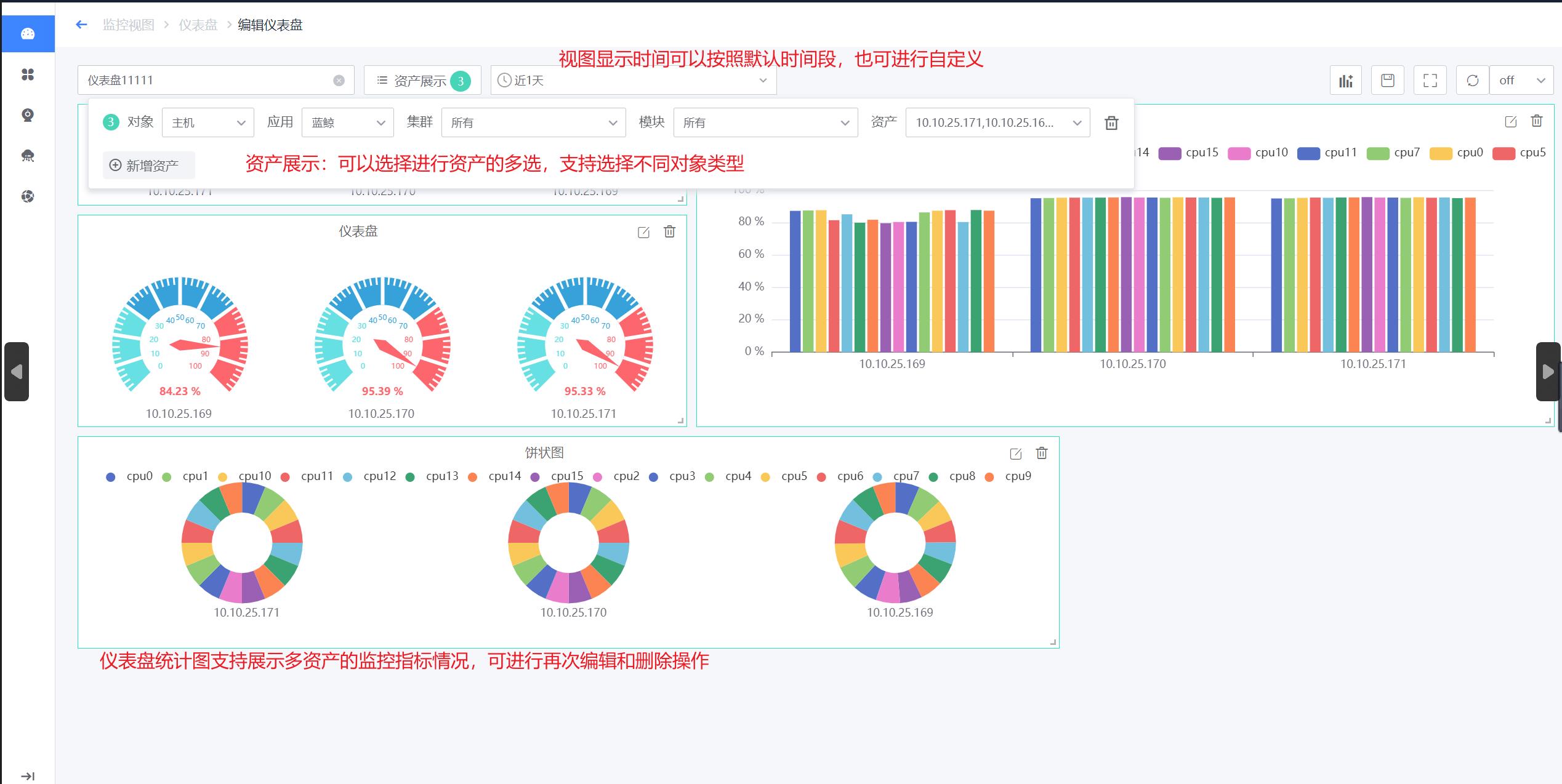
仪表盘编辑
如下图为“仪表盘-查看/编辑”页面,该页面支持以下功能
- 资产显示:支持对象的多选,可以同时选择主机、数据库等多类对象;支持应用的多选(新增一条资产展示);支持同一应用下资产多选,选择多项资产后,统计图会对应显示所有资产的监控指标数据。
- 时间范围选择:内置“近15分钟”、“近30分钟”“近1天”“近7天”等时间范围,支持自定义时间范围。
- 仪表盘操作:仪表盘可进行全屏放大、设置自动刷新时间。
- 统计图区域:各类统计图根据所选的资产及对应指标显示相关数据,各统计图支持再次编辑和删除。
仪表盘中的统计图新建如下
- 点击页面右上方“新建统计图”的图标
- 点击选择统计图类型
- 根据所选的统计图填写视图名称、选择展示的对象类型和监控指标、若为仪表盘/单值需选择多维度下数值的汇聚方式
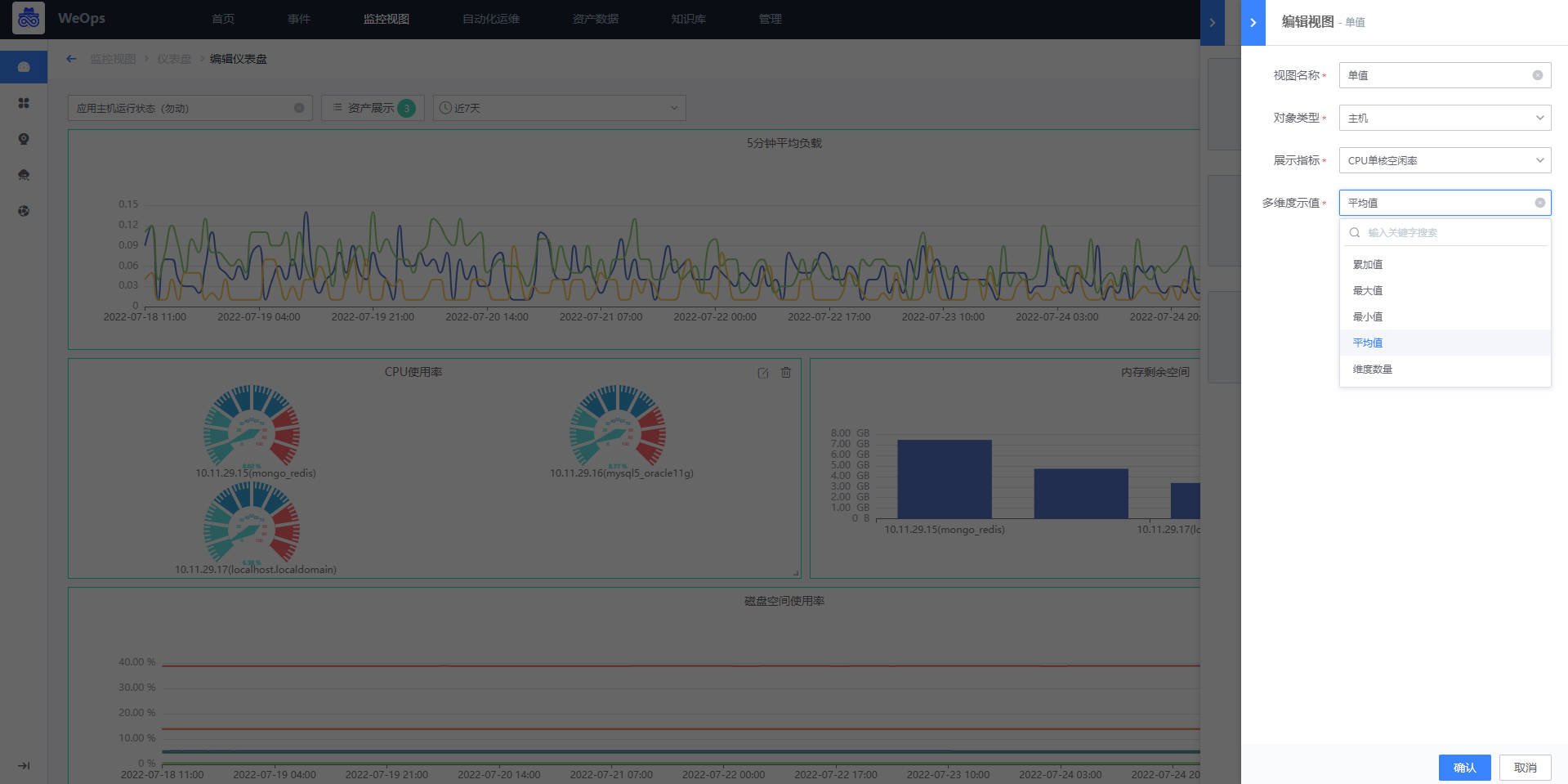
仪表盘-监控组件说明
- 监控——仪表盘:展示指定时间范围内,该监控指标的最近数值;若该监控指标有维度,可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量”(选择维度数量,单值则展示对应对象该指标下的维度数量),支持配置仪表盘展示的最大值/最小值,支持选择各个阈值的配色
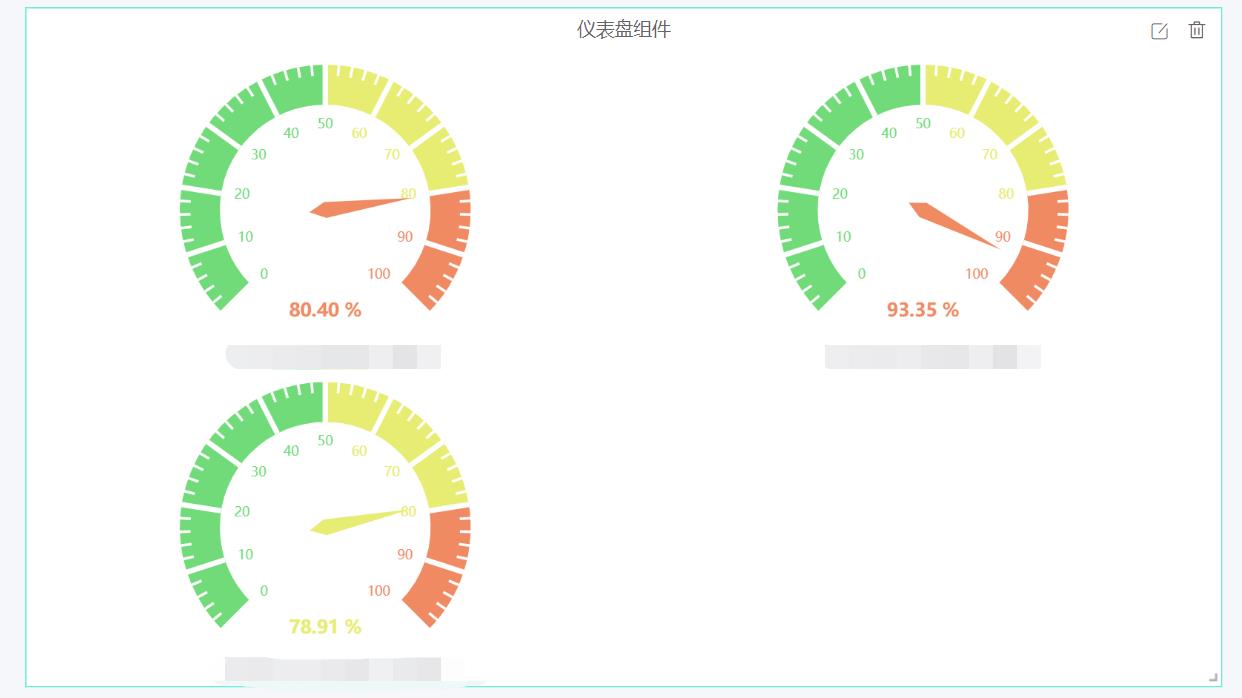

- 监控——单值:展示指定时间范围内,该监控指标的最近数值;若该监控指标有维度,可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量”(选择维度数量,单值则展示对应对象该指标下的维度数量),支持设置维度过滤(比如磁盘这种监控指标,可以通过挂载点的维度进行过滤),支持选择各个阈值的配色。
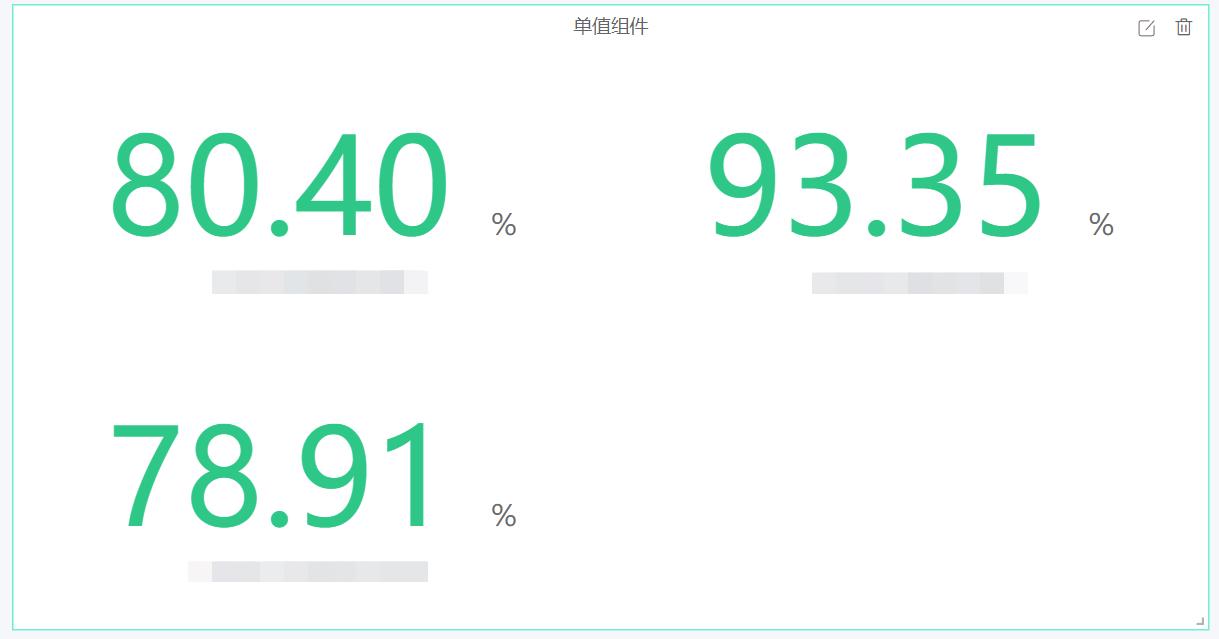

- 监控——饼形图:展示指定时间范围内,该监控指标的最近数值;每个饼状图代表一项资产,若有多维度,则在同一个饼状图中展示各个维度的数值。

- 监控——柱状图:展示指定时间范围内,该监控指标的最近数值;柱状图的每一簇代表一项资产,若资产有多维度,则在同一簇中进行展示各个维度的数值


- 监控——折线图:以时间为横坐标展示指定时间内该监控指标的数值变化,多资产和多维度都在用一个折线图中展示,折线图支持配置阈值线,支持配置面积填充。
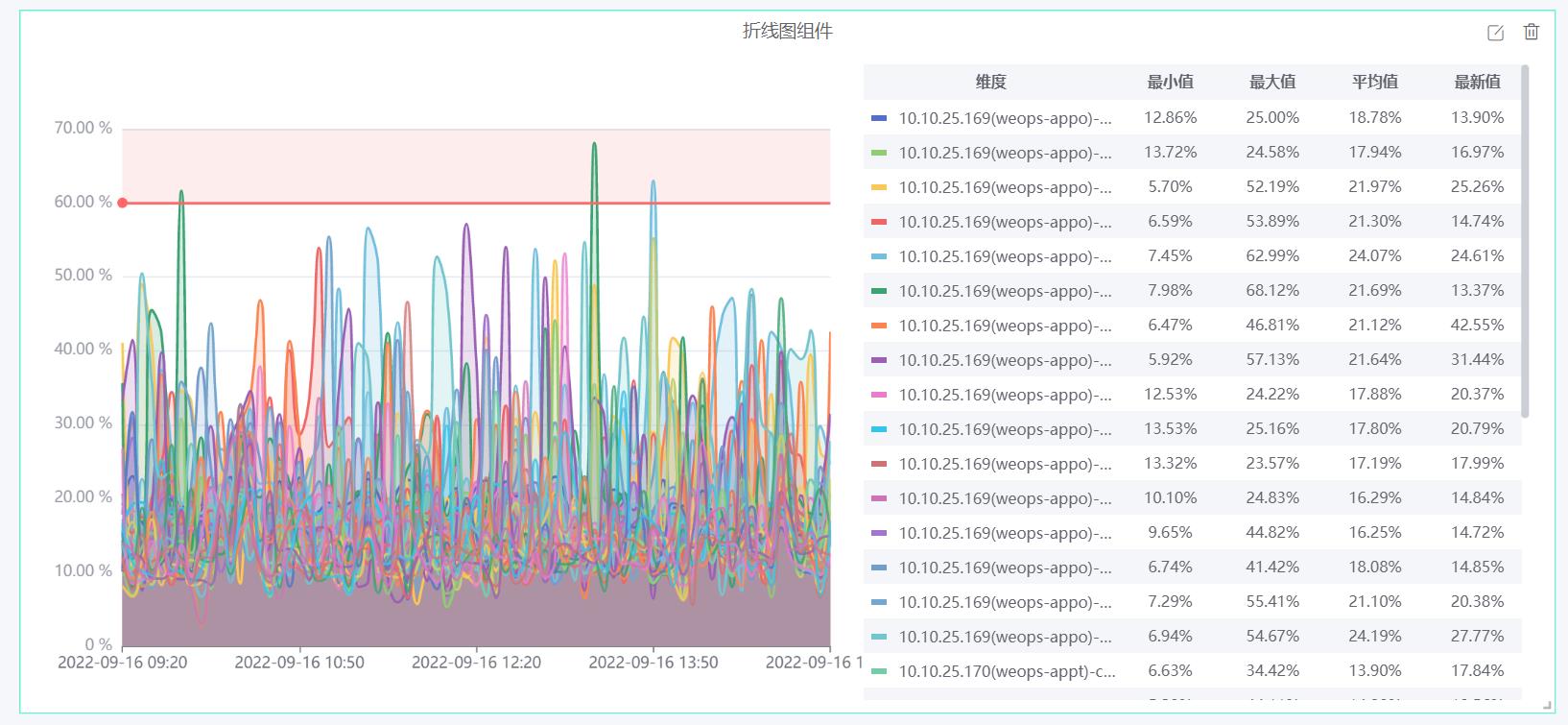

- 监控——水位图:展示指定时间范围内,该监控指标的最近数值;每个水位代表一项资产,若有多维度,则可以选择展示多维度的展示方式


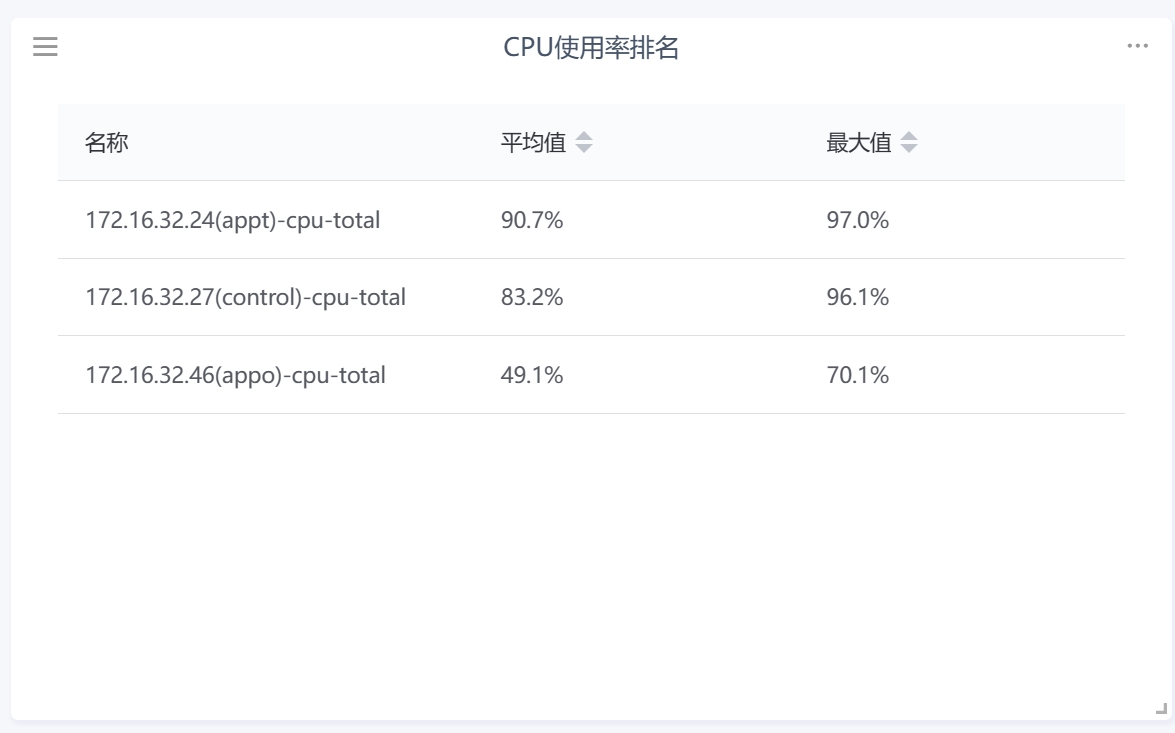
- 监控——排行图:展示指定时间范围内,该监控指标数值的排名情况,支持选择最新值、最大值、最小值等
仪表盘-资产组件说明
- 资产——资产表格:展示选中的资产基本信息,在配置过程中,可以选择展示的资产字段,对于枚举型字段等特殊字段,支持筛选/排序等操作
仪表盘-自动化组件说明
- 自动化——运维工具:支持配置展示不同的运维工具,支持在仪表盘直接使用该工具对选中的资产进行操作,并展示执行结果。


仪表盘-日志组件说明
- 日志——日志消息:支持配置展示日志的原始消息情况,可配置搜索条件、展示字段等信息

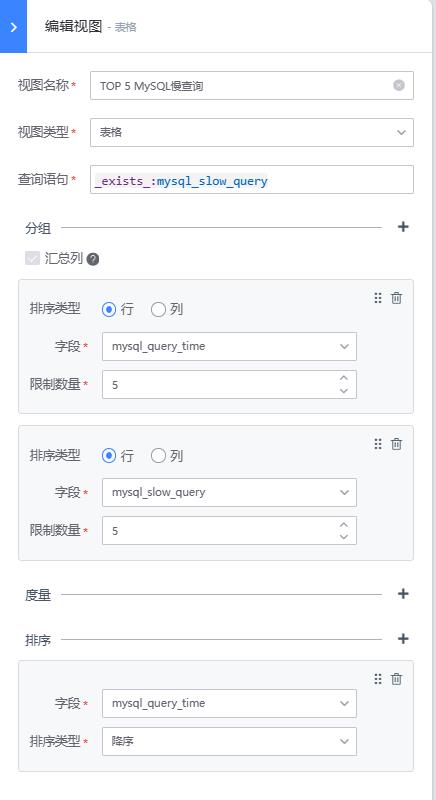
- 日志——表格:支持配置对日志的原始消息进行统计,并呈现在表格中,可配置搜索条件、分组条件、度量(分组的统计度量值)、排序等操作

- 日志——单值:展示单个数值或统计结果,最近数据的第一个值


- 日志-饼形图/柱状图/折线图:以不同的形式展示各个分组的度量值的情况,比如百分比、趋势等。
- 日志-饼形图/柱状图/折线图:以不同的形式展示各个分组的度量值的情况,比如百分比、趋势等。
- 日志—地图组件:支持中国地图和世界地图,选择ip地区分布字段,呈现IP地址地区分布情况,可设置不同数量的阈值。

仪表盘-高级组件说明
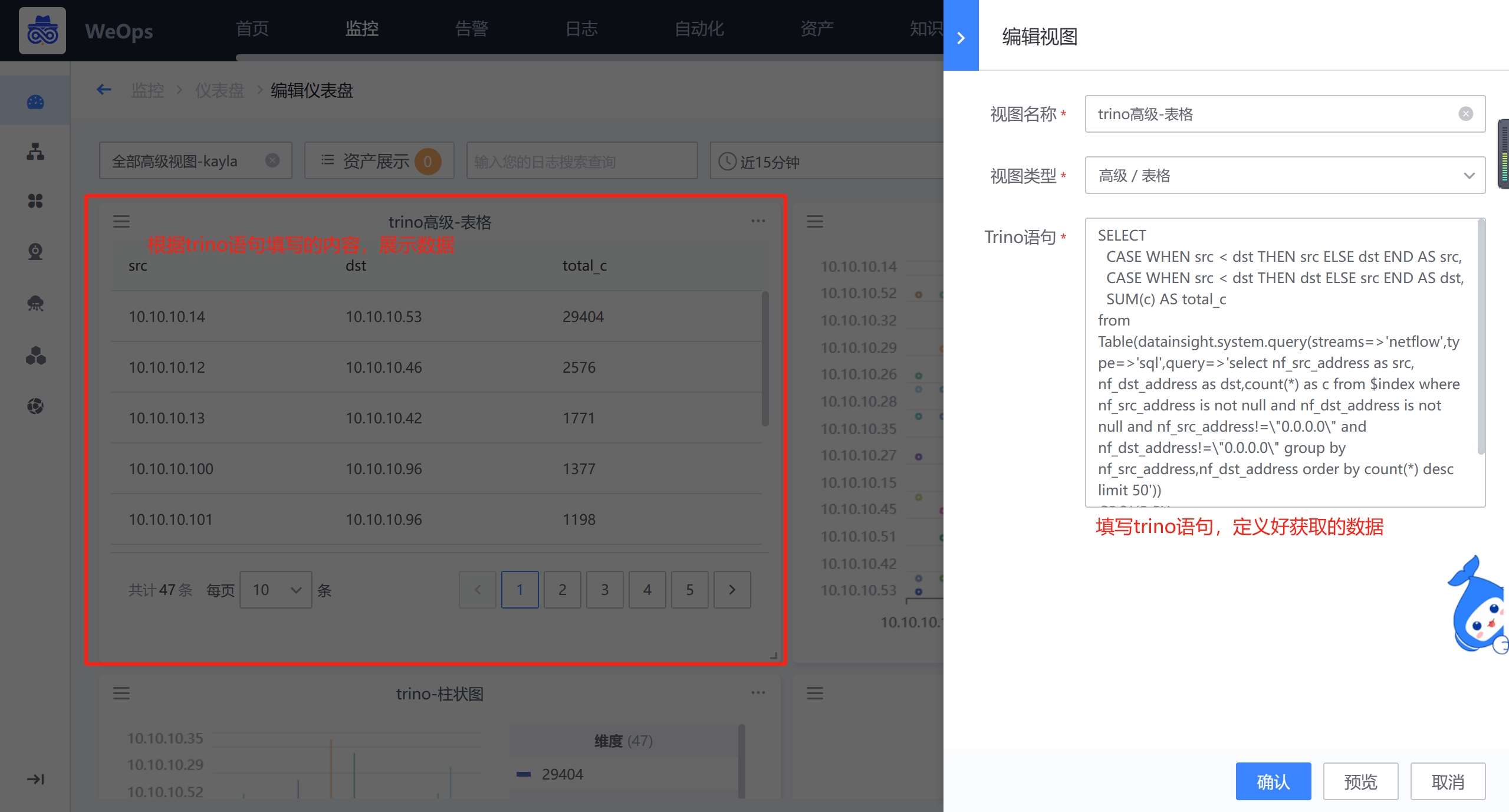
表格/单值
高级组件的表格和单值只需要填写Trino语句,在Trino中定义好需要获取的数据,就会以表格/单值的形式呈现
折线图/柱状图
高级组件的折线图和柱状图主要展示各个分组的变化情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,选择成为分组/X轴,度量/Y轴和维度信息,以便使用
分组/X轴:就是类别,为折线图和柱状图的X轴,呈现各个分组情况。比如告警的所属应用,每个应用就是一个分组。
度量/Y轴:就是数值,为折线图和柱状图的Y轴,展示各个分组的具体的值的情况。比如告警的处理时长,展示每个应用的告警处理时长。
维度:当分组的数值有多种情况时,需要选择展示维度,比如告警区分优先级,需要分开展示每个应用致命/预警/提醒三个等级的处理时长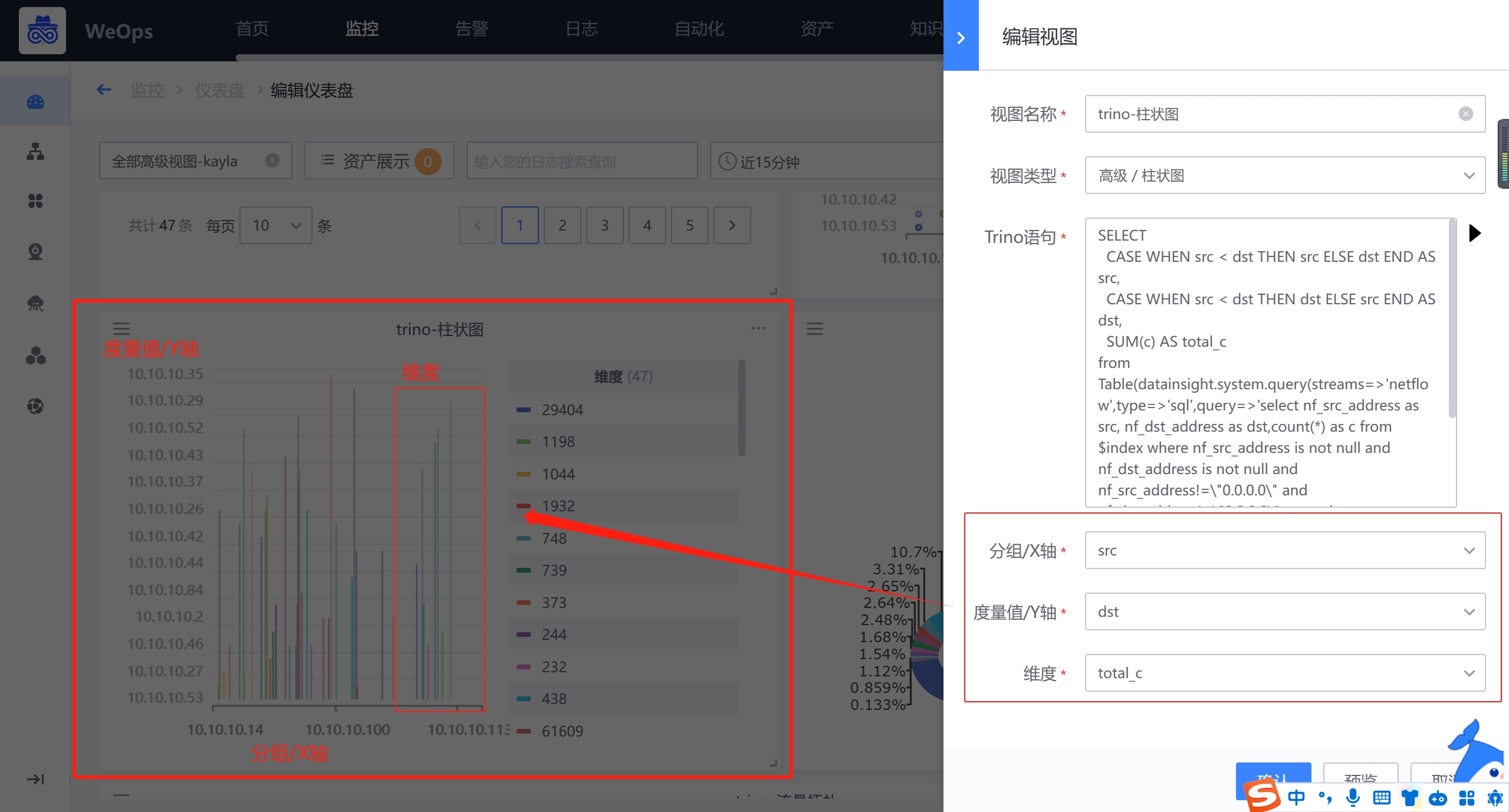
饼形图
高级组件的饼形图主要展示各个类别的百分比,需要填写Trino语句,点击执行从Trino语句获取返回字段,并且选择成为分组、度量值。
分组:就是类别,呈现各个分组情况,饼形图的每一块就是一个分组。比如分组是IP地址
度量值:就是数值,展示各个分组的具体的值的百分比情况,比如数值是IP地址的数量,则饼形图则表示所有IP地址数量的百分比。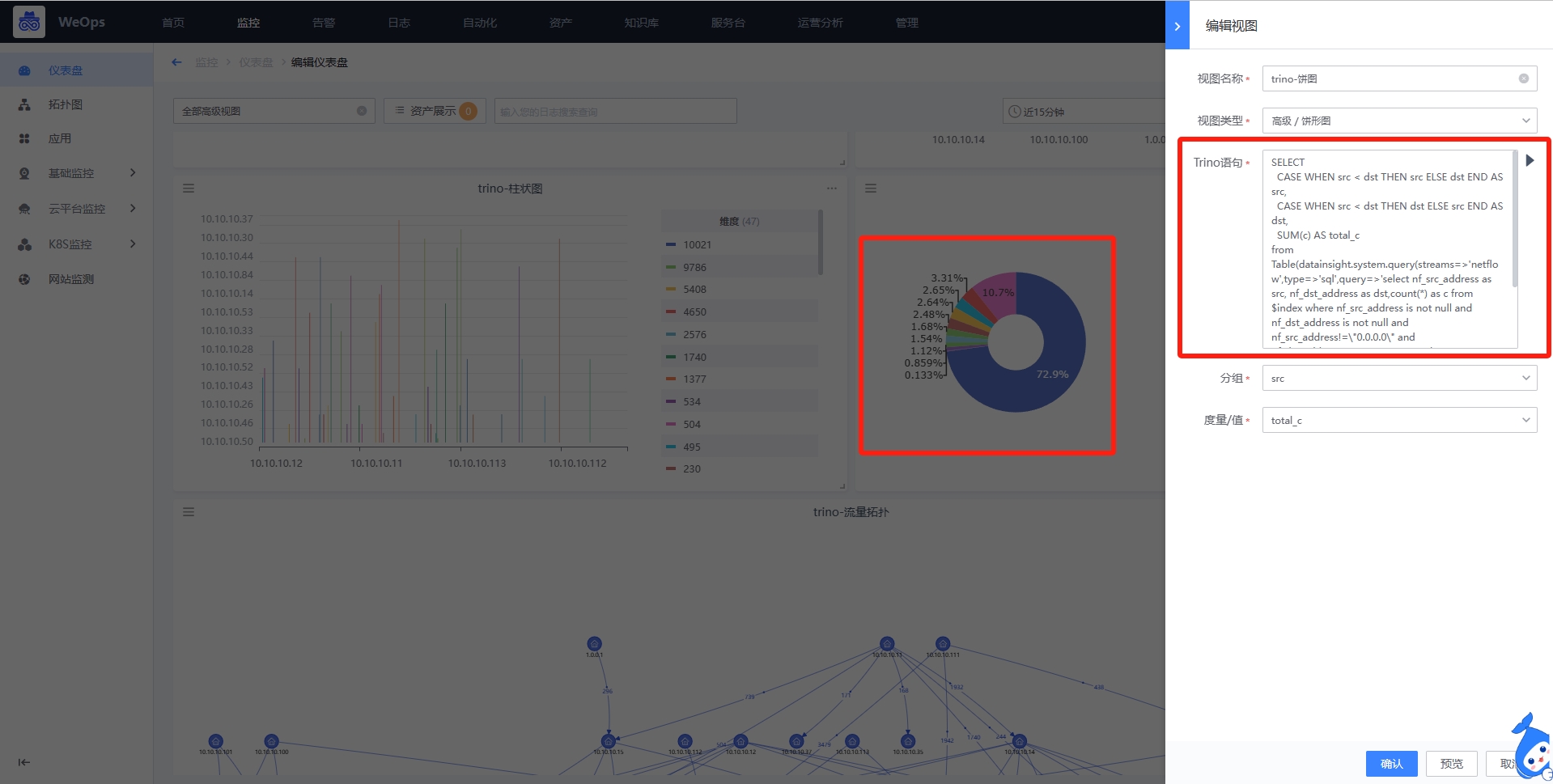
流量拓扑图
高级组件的流量拓扑图主要展示源和目标直接的流向关系,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及连线上的数值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
连线数值:连线上面的数值(从源到目标的数值),比如从源IP到目标IP直接响应时长的数值等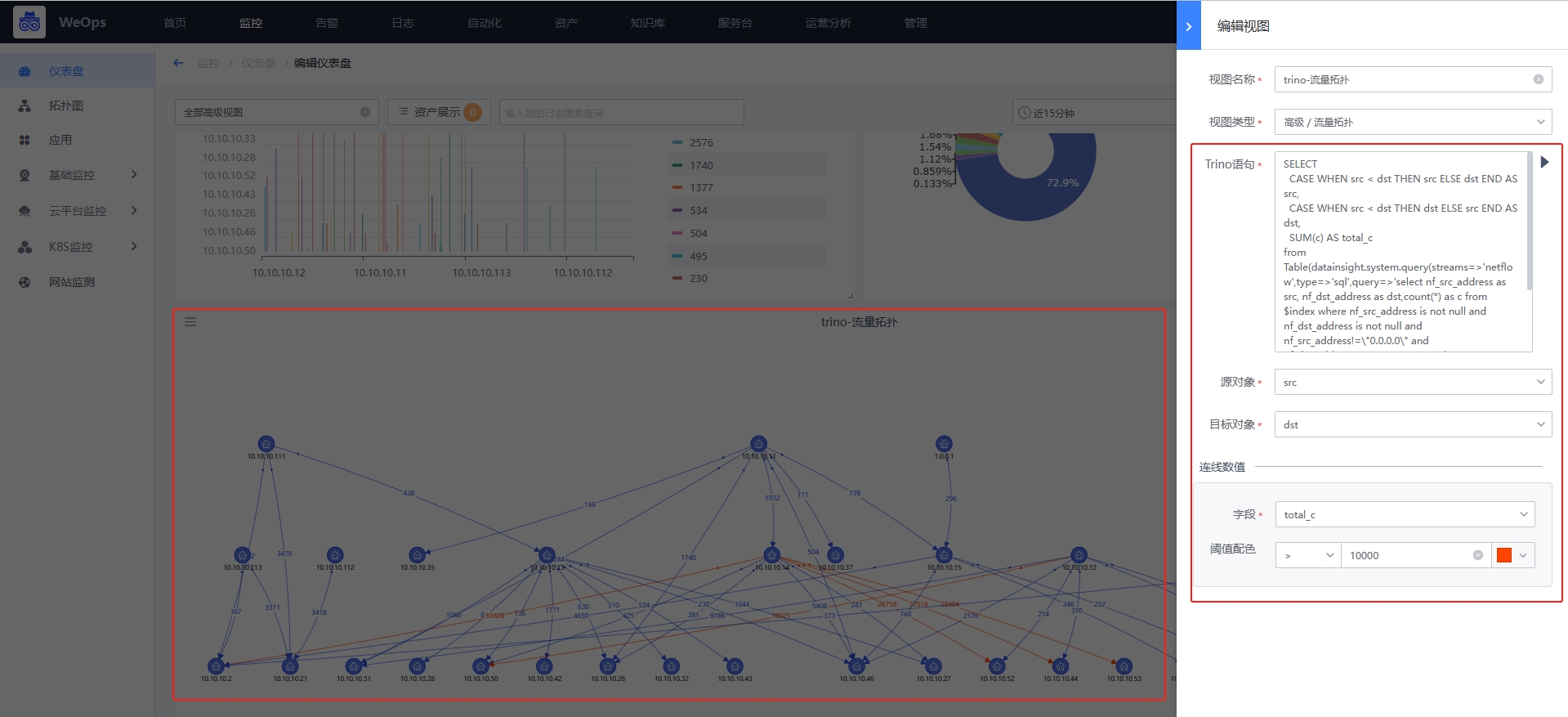
桑基图
高级组件的桑基图主要展示源和目标直接的流量大小情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及度量值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
度量值:度量值决定了连线的宽窄,越宽说明流量/数值越大
仪表盘高级组件的详细介绍步骤详见《操作手册-6、其他设置-仪表盘高级组件配置》
- 目前,所有仪表盘内置的组件说明如下
| 所属模块 | 组件名称 | 作用 | 支持的配置 |
|---|---|---|---|
| 监控 | 仪表盘 | 展示指定时间范围内,该监控指标的最近数值 | 1、配置需要展示的监控指标 2、可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量” 3、支持配置仪表盘展示的最大值/最小值,支持选择各个阈值的配色 |
| 监控 | 单值 | 展示指定时间范围内,该监控指标的最近数值 | 1、配置需要展示的监控指标 2、可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量” |
| 监控 | 饼形图 | 指定时间范围内,该监控指标的最近数值,每个饼状图代表一项资产,若有多维度则展示百分比 | 1、配置需要展示的监控指标 |
| 监控 | 柱状图 | 展示指定时间范围内,该监控指标的最近数值;柱状图的每一簇代表一项资产,若资产有多维度,则展示多条 | 1、配置需要展示的监控指标 |
| 监控 | 折线图 | 以时间为横坐标展示指定时间内该监控指标的数值变化,多资产和多维度都在用一个折线图中展示 | 1、配置需要展示的监控指标 2、支持配置阈值线 3、支持配置是否面积填充 |
| 监控 | 水位图 | 展示指定时间范围内,该监控指标的最近数值 | 1、配置需要展示的监控指标 2、可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量” 3、支持选择各个阈值的配色 |
| 监控 | 排行图 | 展示指定时间范围内,多个资产监控指标的数值的排行情况 | 1、配置需要展示的监控指标 2、可以选择展示“最大值”“最小值”“平均值”“累加值” |
| 资产 | 资产表格 | 展示选中的资产基本配置信息 | 1、支持配置所有资产管理的资产 2、支持选择展示的字段 3、对于枚举型字段等特殊字段,支持筛选/排序等操作 |
| 自动化 | 运维工具 | 展示/执行各个运维工具 | 1、配置展示不同的运维工具 2、在仪表盘直接使用该工具对选中的资产进行操作,并展示执行结果 |
| 日志 | 日志消息 | 展示日志的原始消息 | 1、配置搜索条件 2、配置展示字段 3、支持配置某个字段的升序/降序 |
| 日志 | 单值 | 展示单个数值或统计结果,最近数据的第一个值 | 1、配置分组和度量,确定统计的角度和值 2、设置趋势:越大越好、越小越好,普通 |
| 日志 | 表格 | 以表格的形式展示各个分组的度量统计数值 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 饼形图 | 按照特定度量字段,统计各个分组该度量值所占的百分比 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 折线图 | 用于展示统计数据的变化趋势,比如随时间的变化趋势 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 柱状图 | 以柱形图展示日志数据,展示各个分组的度量值 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 4、支持设置堆叠/分组模式 |
| 日志 | 地图 | 以地图的形式展示IP地址的地域分布情况 | 1、配置搜索语句 2、选择中国地图/世界地图 3、配置地域字段 4、支持阈值配色 |
| 高级 | 单值 | 填写Trino语句,获取对应数据后,以单值形式呈现 | 1、填写Trino语句 |
| 高级 | 折线图 | 填写Trino语句,获取对应数据后,以折线图形式呈现 | 1、填写Trino语句 2、配置X轴、Y轴展示的数值和维度数值 |
| 高级 | 饼形图 | 填写Trino语句,获取对应数据后,以饼形图形式呈现 | 1、填写Trino语句 2、配置分组(组别)和度量值 |
| 高级 | 柱状图 | 填写Trino语句,获取对应数据后,以柱状图形式呈现 | 1、填写Trino语句 2、配置X轴、Y轴展示的数值和维度数值 |
| 高级 | 表格 | 填写Trino语句,获取对应数据后,以表格形式呈现 | 1、填写Trino语句 |
| 高级 | 流量拓扑 | 填写Trino语句,获取对应数据后,以流量拓扑形式呈现 | 1、填写Trino语句 2、配置源对象和目标对象 3、配置连线数值和阈值配色 |
| 高级 | 桑基图 | 填写Trino语句,获取对应数据后,以桑基图形式呈现 | 1、填写Trino语句 2、配置源对象、目标对象和度量值 |
应用
“监控视图-应用”模块分为“总览页和详情页,总览页以应用卡片的形式展示了所有有权限应用的整体情况,包括该应用下资源情况、告警情况和异常网站情况。
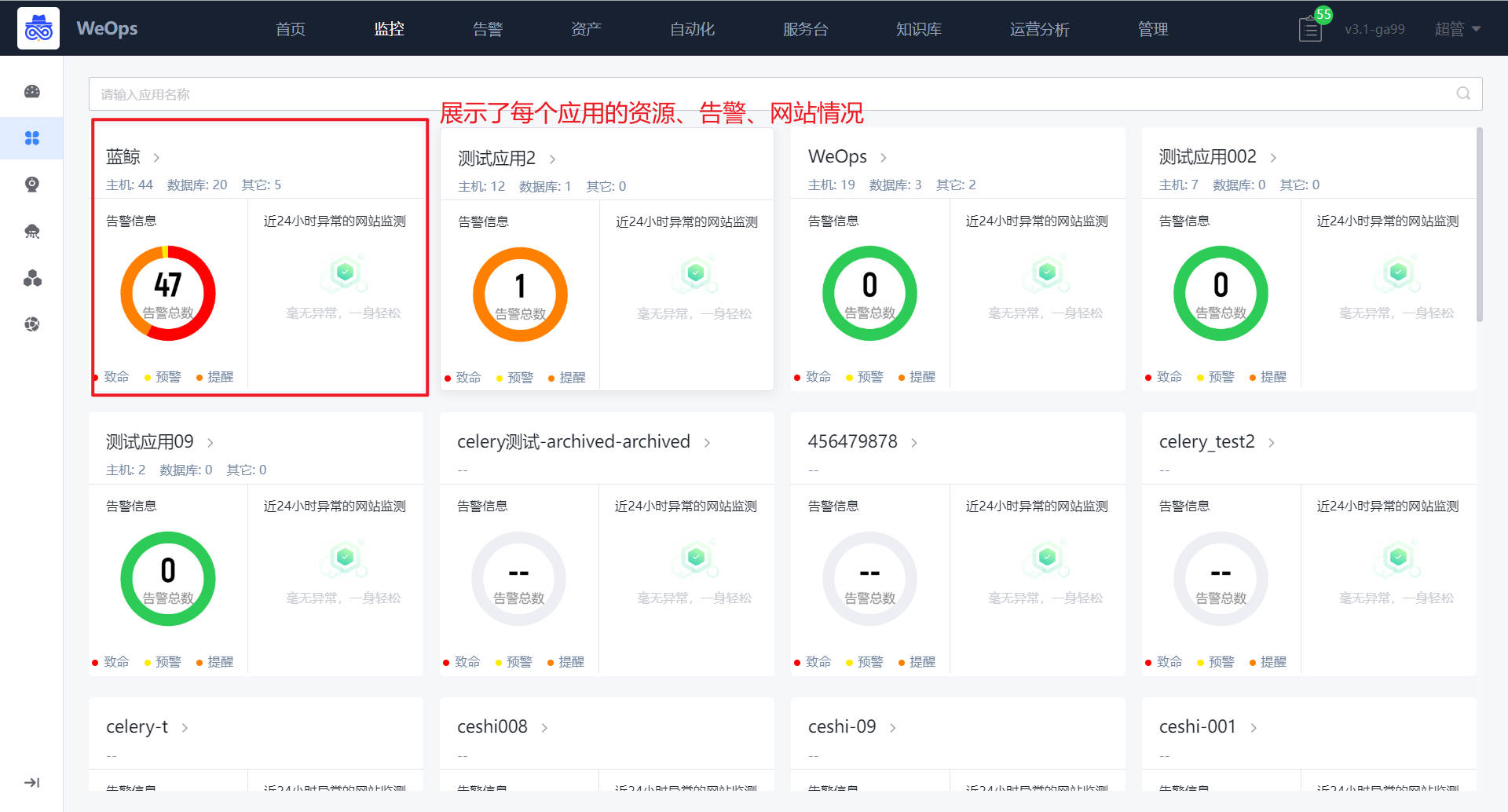
如下图,“监控视图-应用”的详情页,主要用于展示某应用下的网站监控情况、该应用下各个实例列表以及监控告警情况,在页面的左上角可以进行应用的切换。
- 网站监测: 展示该应用下的网站最近24个小时内的告警情况,以绿色表示该时间段无告警,黄色、橙色和红色表示该时间段存在的告警最大等级。
- 告警汇总概况:展示与该应用相关的实例/网站的活动告警数量汇总概览,可以点击查看不同等级的告警列表和详情。
- 实例列表:列出了该应用下的主机、数据库和其他实例的列表,可以在列表看到该实例的监控状态、未恢复告警、关键指标信息(比如CPU使用率,磁盘空间使用率、物理内存使用率),点击该实例可查看详细信息。

点击实例列表中的实例项,可查看该实例的详细信息, 以主机为例包括基础信息、监控视图、进程视图、关联拓扑、告警列表。
- 基础信息:展示该主机的基本信息,包括内网IP、操作系统、内存容量、磁盘容量等信息
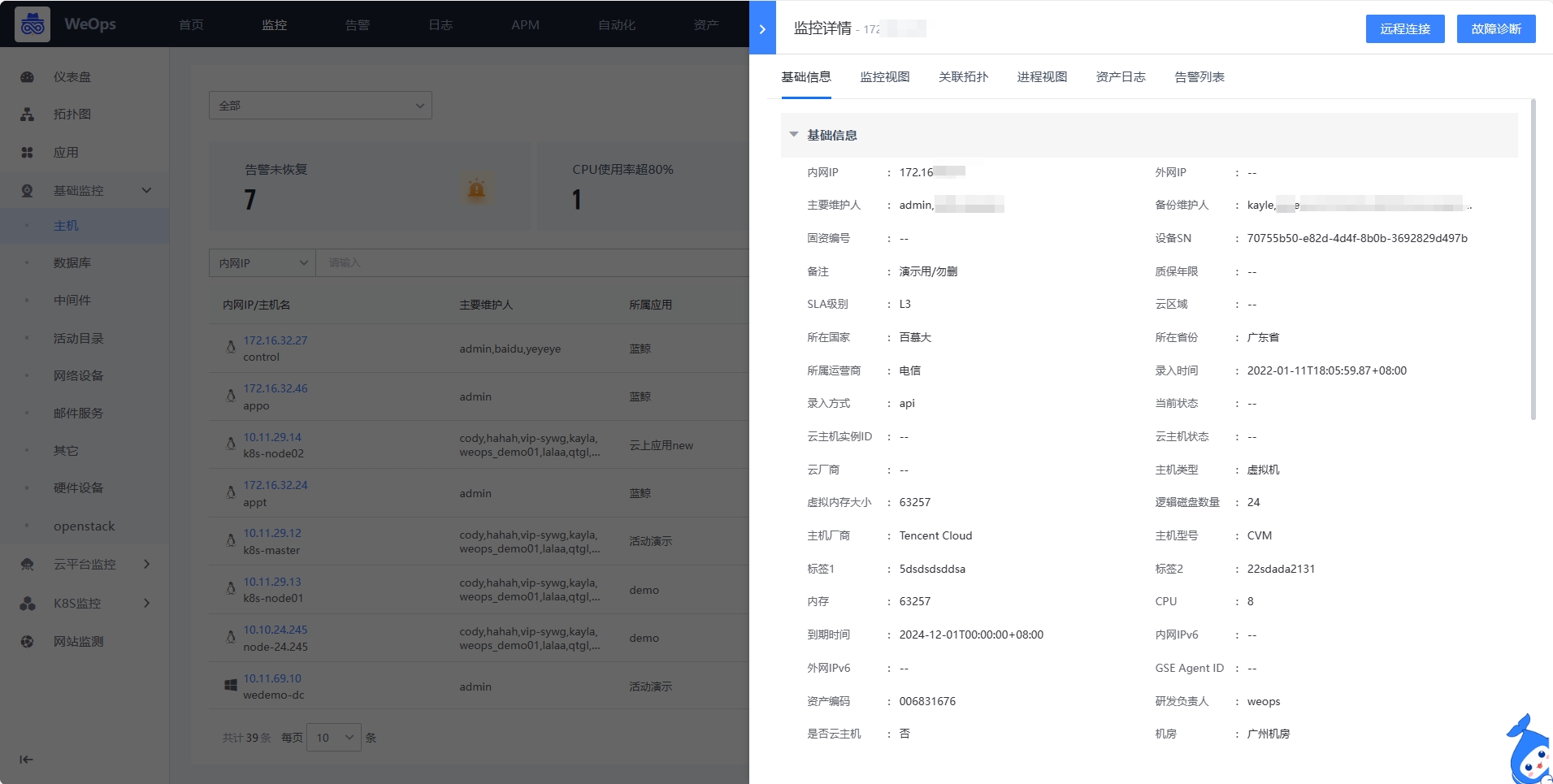
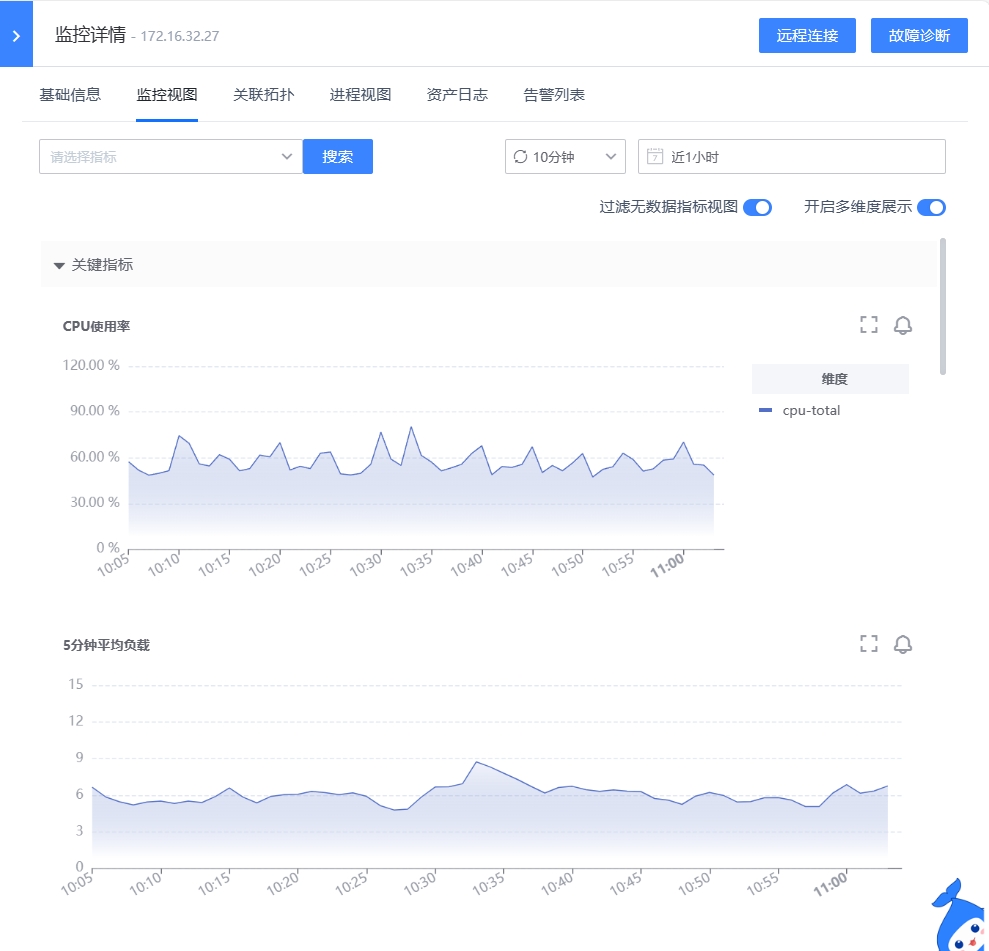
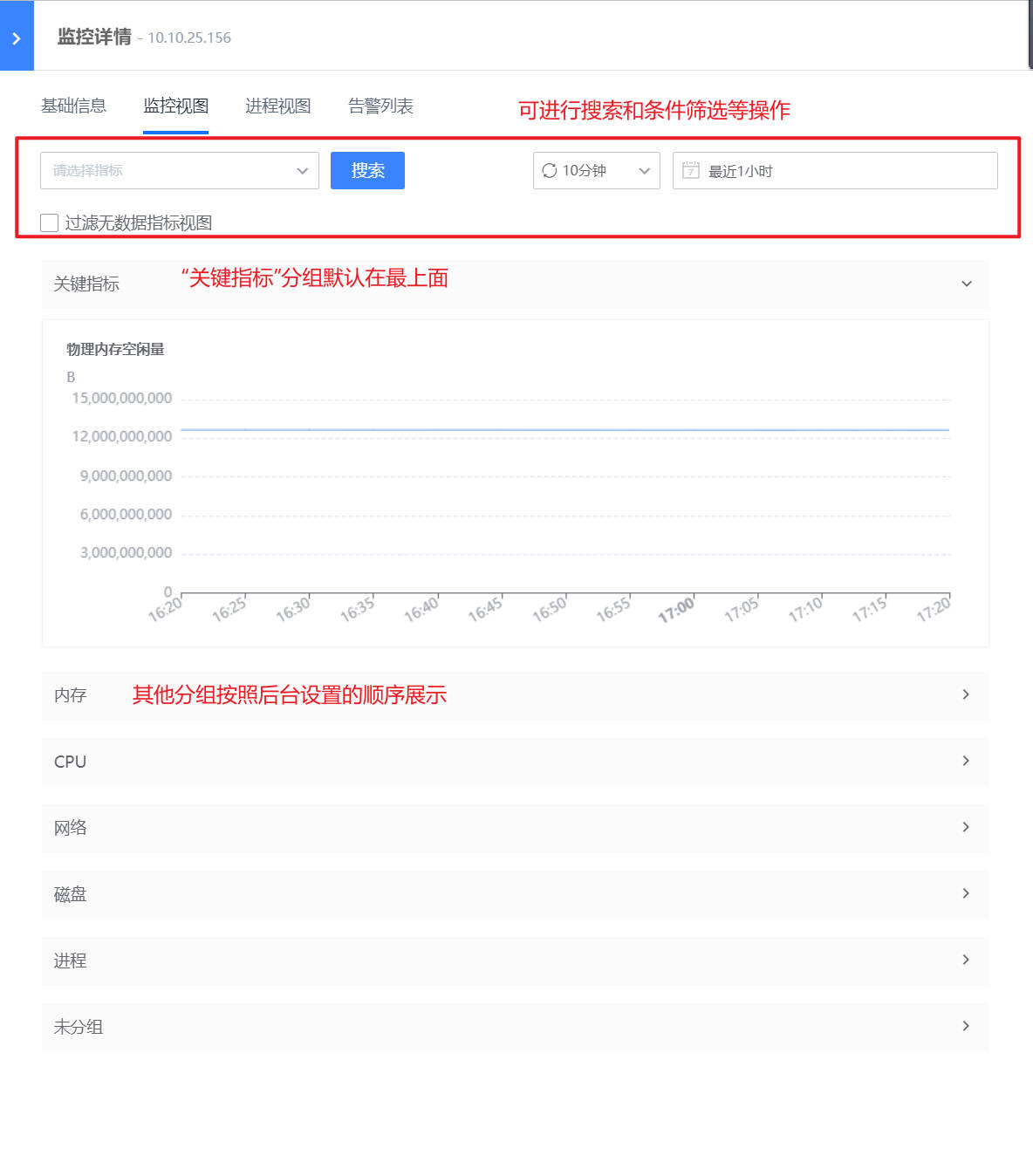
- 监控视图:以分组的形式进行主机监控视图的展示,可以进行搜索等操作,灵活的选择需要的视图,此外设置了“关键指标”组,当某个指标设置为关键指标后,可在监控视图的最上方展示。(可在“WeOps-管理中心-监控管理-指标管理”中设置指标分组和关键指标)
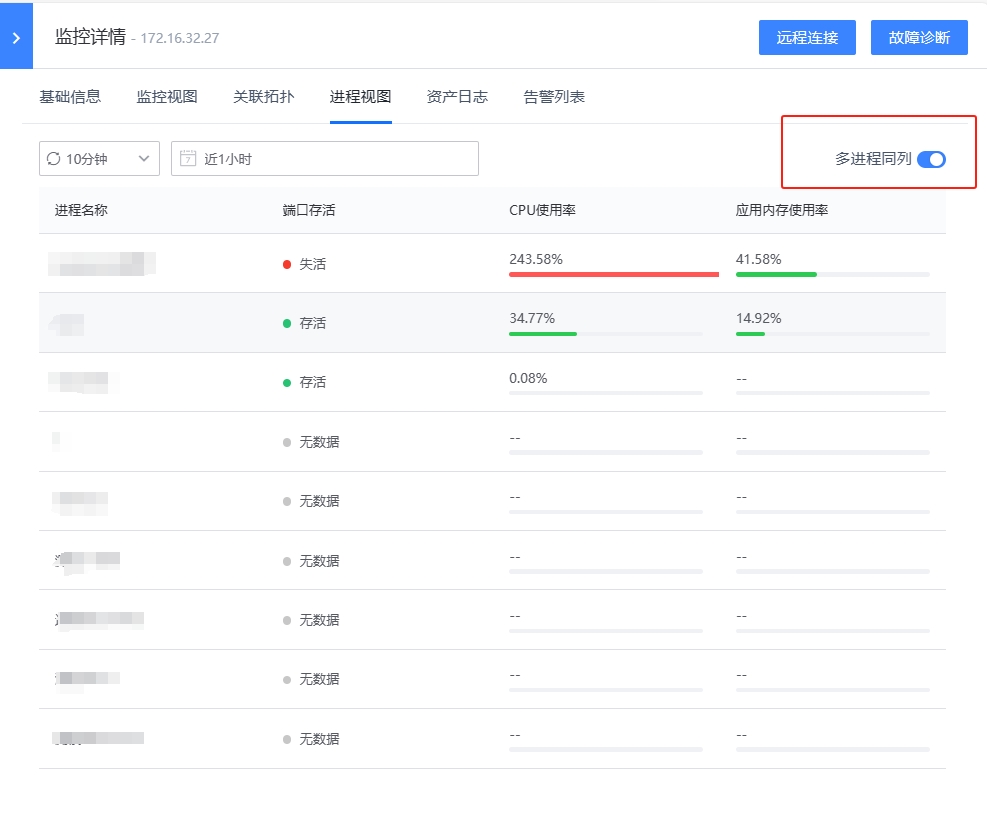
- 进程视图:展示该主机相关的进程情况,分成两种展示方式:一是多进程在同一个表格展示,二是单个进程关键指标以折线图展示
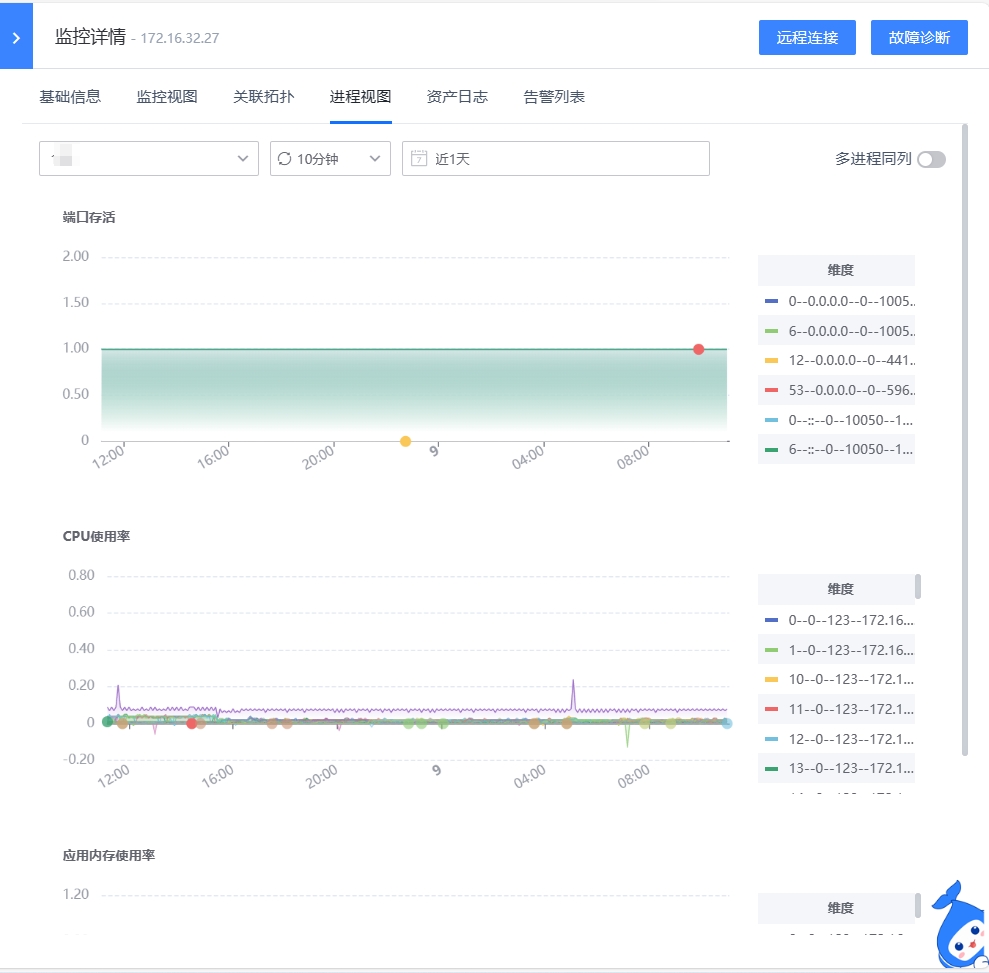
- 关联拓扑:展示与该实例相关联的所有实例,可以点击查看关联实例详情

- 资产日志:通过“资产管理-数据关联”设置资产和日志的匹配规则,这里展示与该个资产相关联的所有的日志数据

- 告警列表:展示与该主机相关的活动告警和历史告警列表,可以点击查看各个告警项的详情,并进行处理。
基础监控
主机
如下图,“监控视图-基础监控-主机”展示了所有的主机列表,包括监控告警状态、主机的关键指标信息等,点击各个主机可以跳转至该主机的详细信息抽屉,详情抽屉内容与“监控视图-应用”中的主机详情一致。
数据库
如下图,“监控视图-基础监控-数据库”展示了所有的数据库列表,包括数据库信息、监控告警状态、主机CPU使用率等,点击各个数据库可以跳转至该数据库的详细信息抽屉页。

网络设备
- 如下图,“监控视图-基础监控-网络设备”展示了所有的网络设备列表,包括交换机、路由器、防火墙、负载均衡等,展示了网络设备的信息、监控告警状态、主机CPU使用率等,点击各个设备可以跳转至该设备的详细信息抽屉页。
- 点击网络设备,可查看网络设备的基本信息、监控视图、端口视图、告警列表等信息。
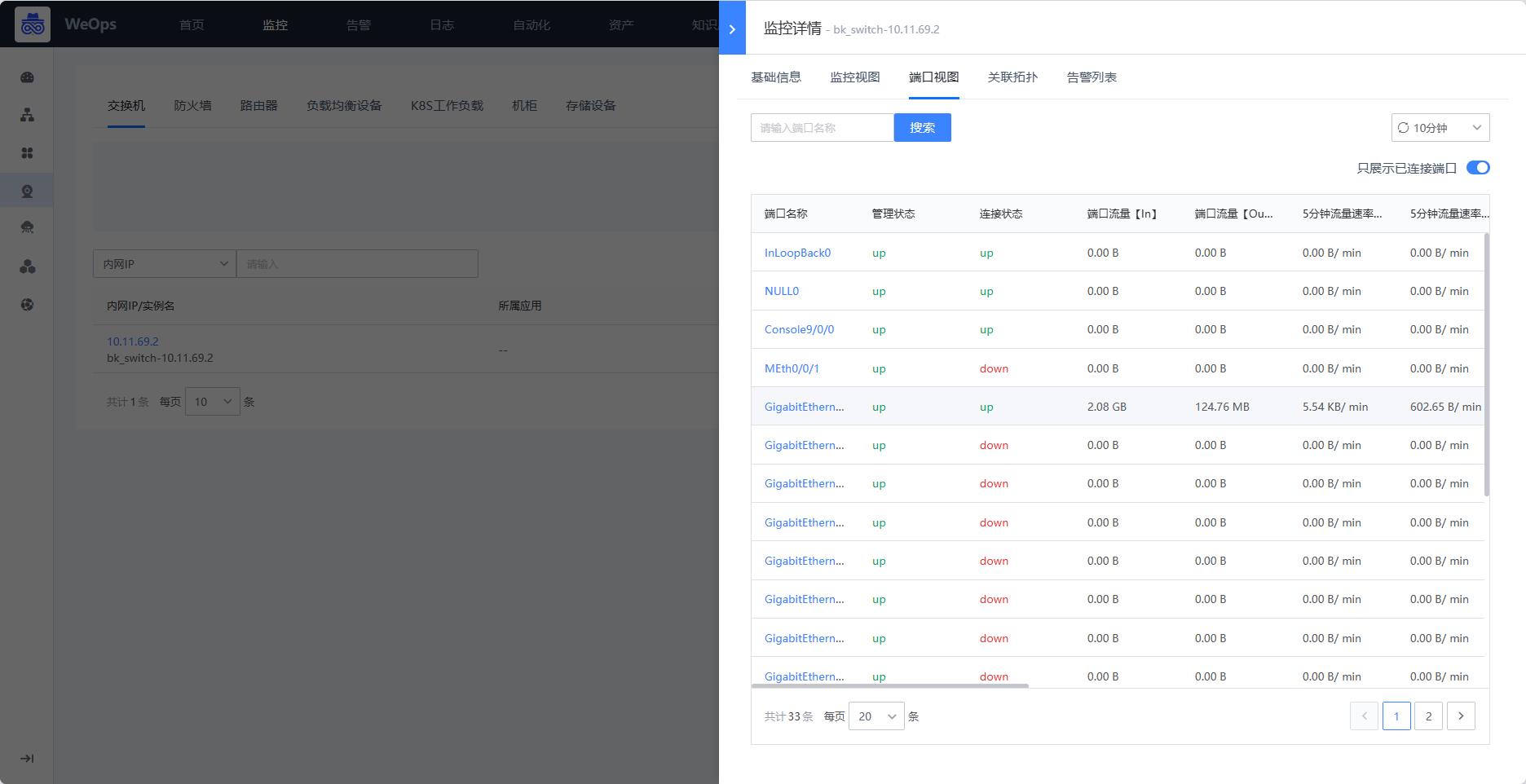
- 支持对接口监控视图进行配置,用户可以自由配置展示列表的表头字段。
硬件设备
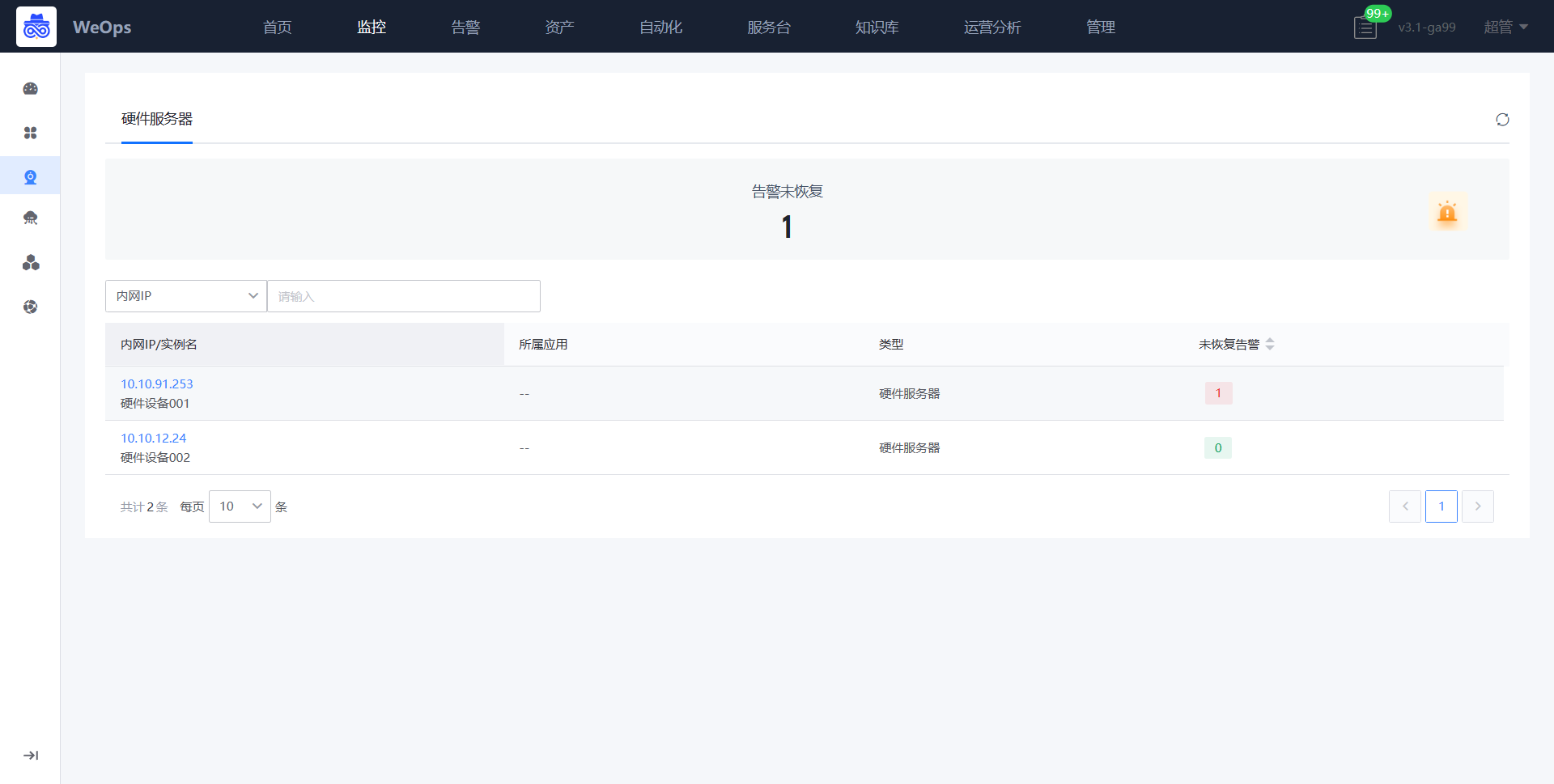
如下图,“监控视图-基础监控-硬件设备”展示了所有的硬件设备列表,展示了这些设备的信息、监控告警状态、主机CPU使用率等,点击各个设备可以跳转至该设备的详细信息抽屉页,展示了基本信息、监控视图、告警列表。
其他动态tab
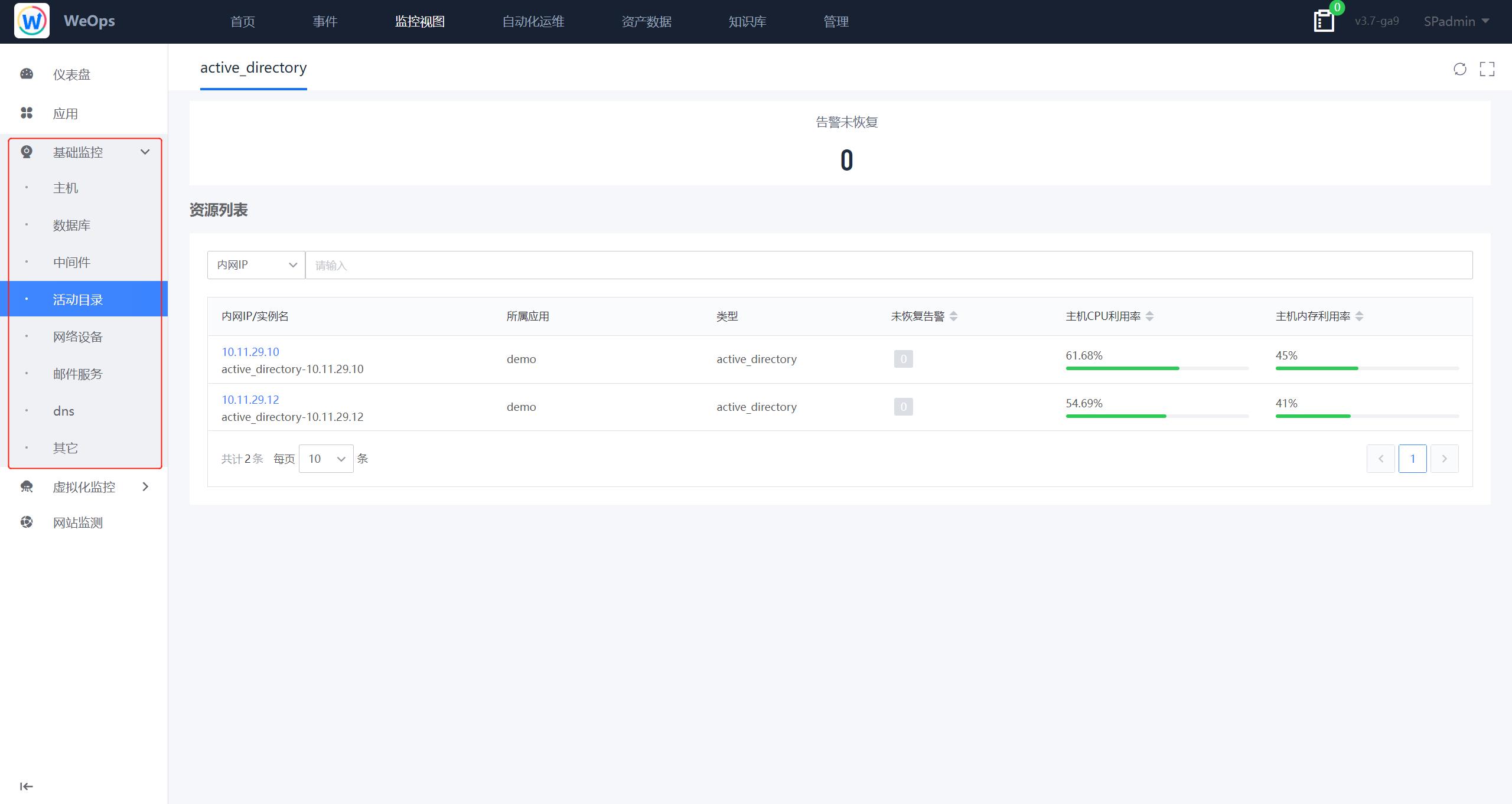
如下图,“监控视图-基础监控-其他动态tab”根据监控的对象动态展示tab,比如中间件等,展示了这些实例的的关键数据、监控告警状态等,点击各个实例可以跳转至该实例的详细信息抽屉页。
云平台监控
WeOps支持云平台监控/自动发现的拓展,拓展后可在“云平台监控”的tab中展示出对应对象以及监控情况。
VMware
VMware的监控视图展示了VMware下的虚拟机、ESXI和数据存储的监控情况,包括基本信息、监控视图、关联拓扑和告警情况。
- 虚拟机
如下图,“WeOps-云平台监控-VMware-虚拟机”展示了所有的虚拟机列表,包括监控告警状态、关键指标信息等
点击各个实例可以跳转至详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联拓扑、告警列表。
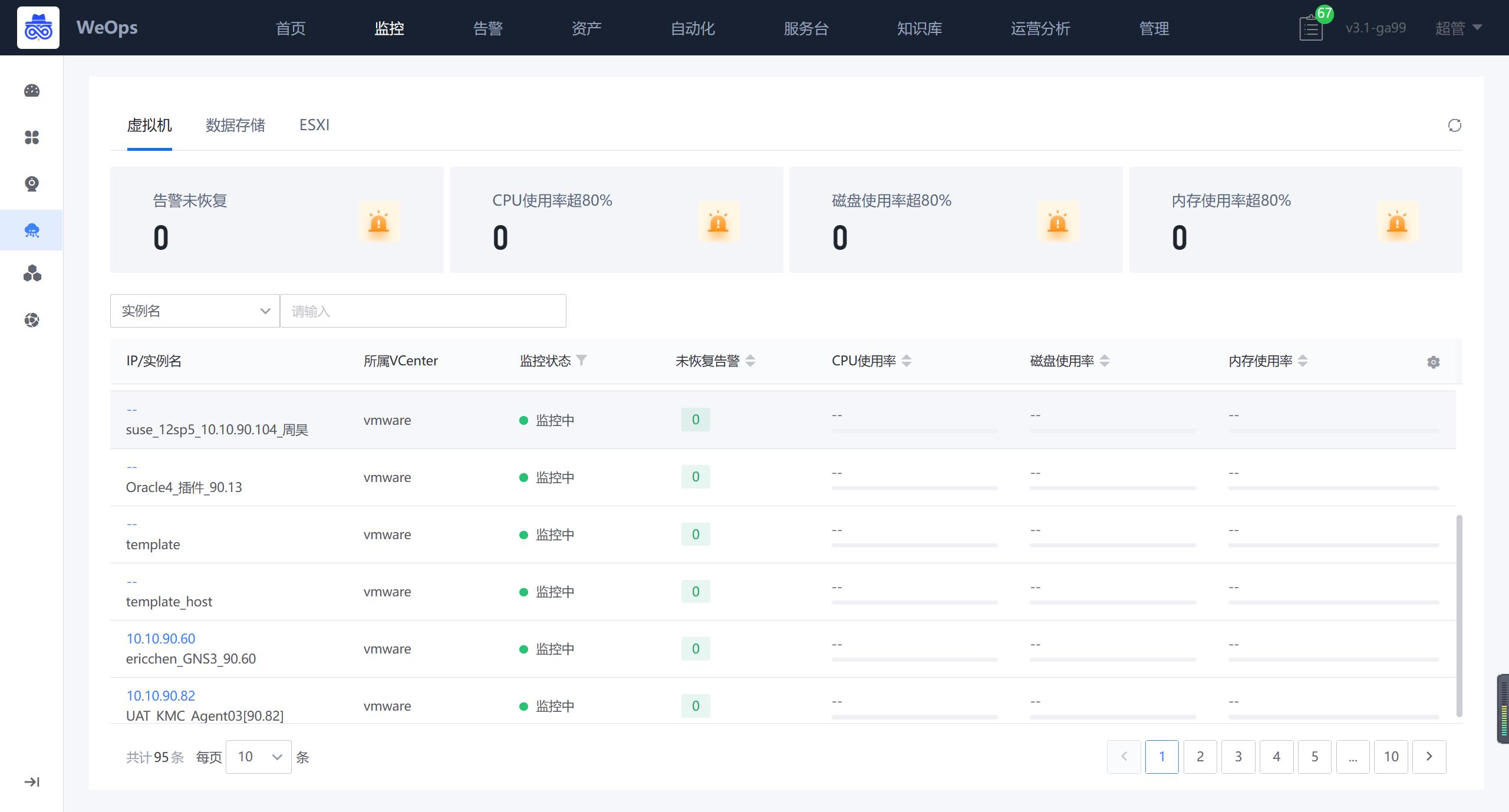
- 数据存储
如下图,“WeOps-云平台监控-VMware-数据存储”展示了所有的数据存储列表,包括监控告警状态、关键指标信息等
点击各个实例可以跳转至详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联的ESXI、关联拓扑、告警列表。
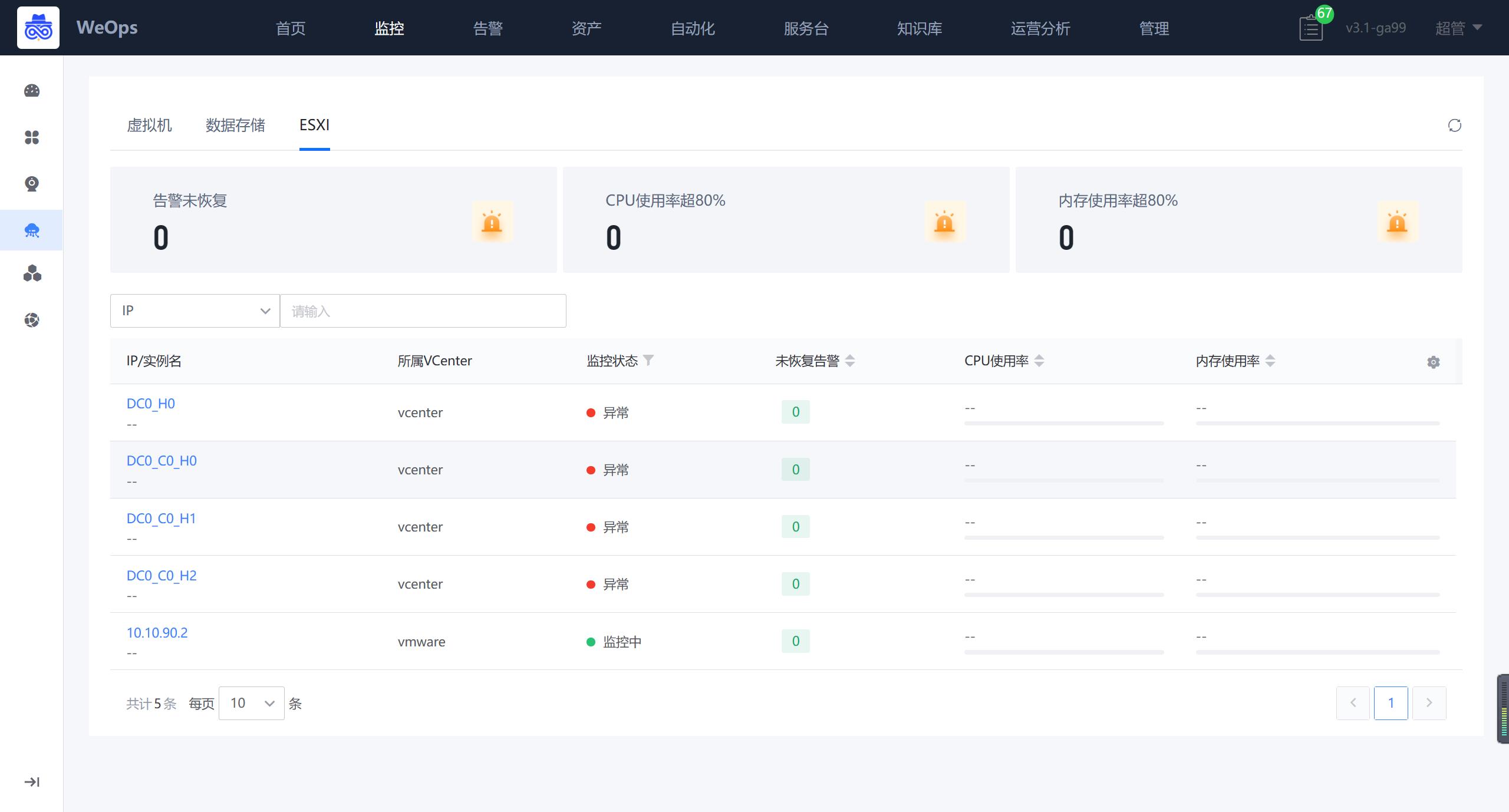
- ESXI
如下图,“WeOps-云平台监控-VMware-ESXI”展示了所有的ESXI列表,包括监控告警状态、关键指标信息等
点击各个实例可以跳转至详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联的数据存储、关联的虚拟机、关联拓扑、告警列表。
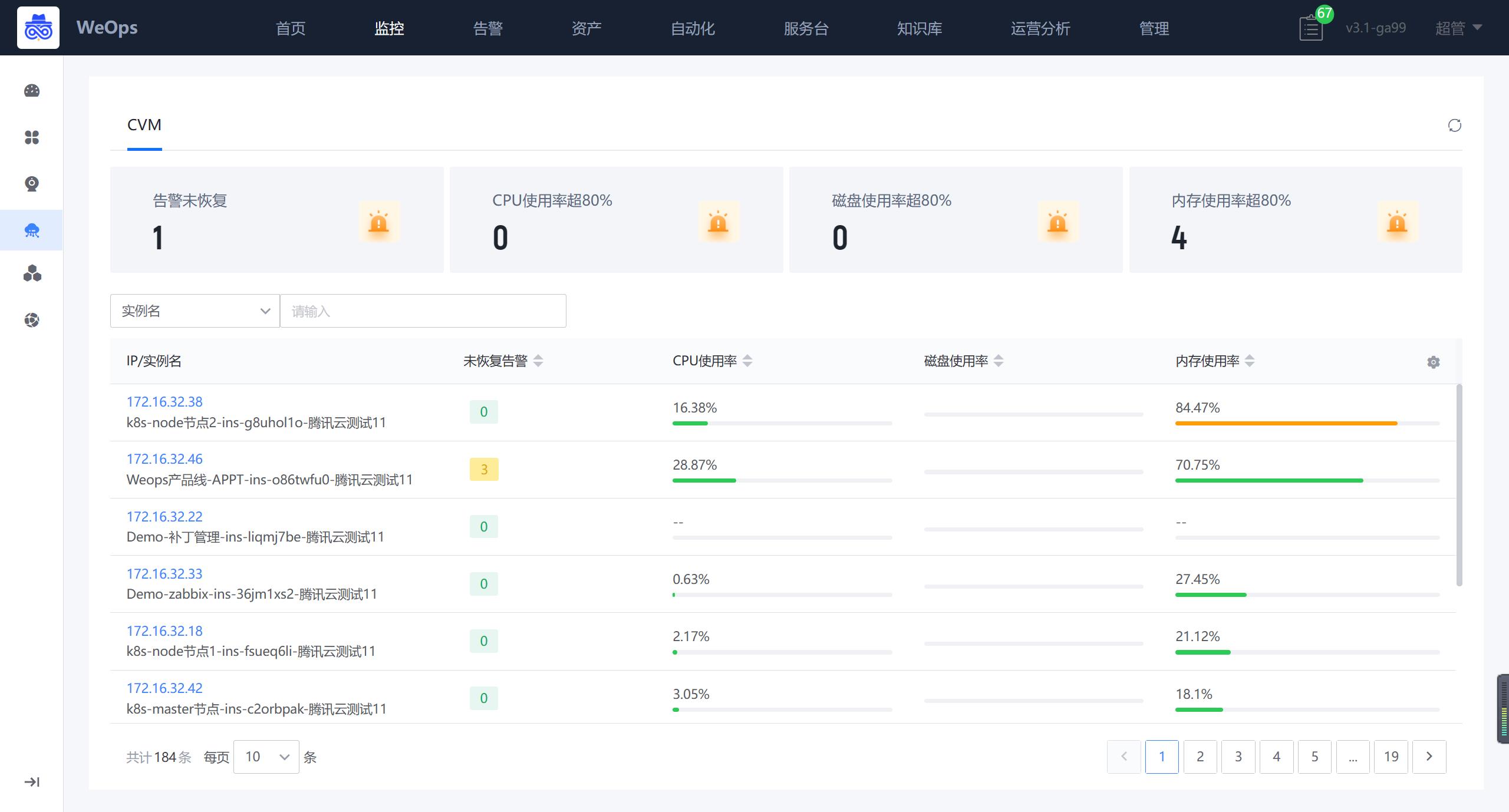
腾讯云
腾讯云的监控视图展示了所有CVM的监控情况,展示CVM列表,包括关键指标和告警状态等信息
点击各个实例可以跳转至CVM详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联拓扑、告警列表。
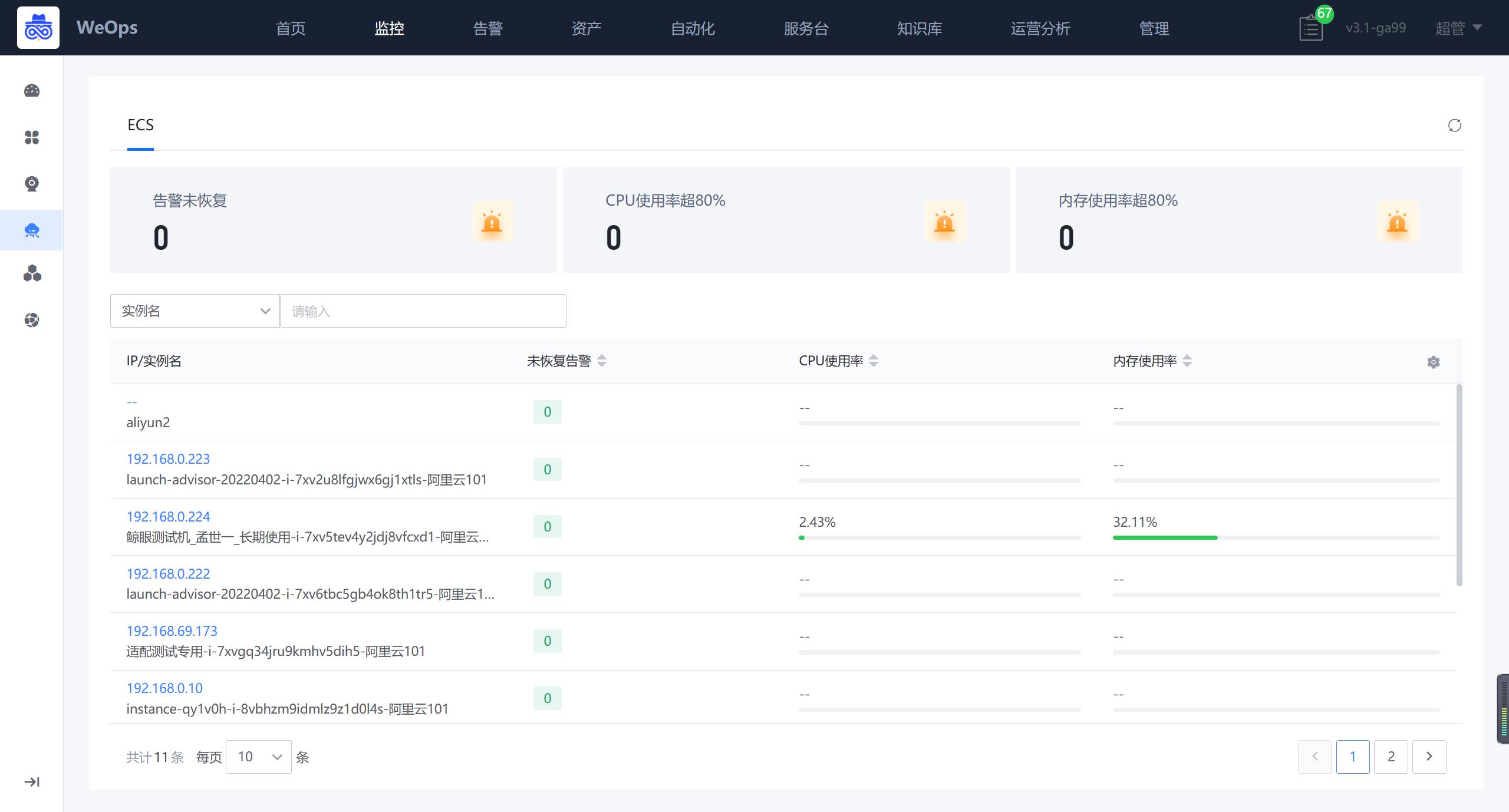
阿里云
阿里云的监控视图展示了所有ECS的监控情况,展示ECS列表,包括关键指标和告警状态等信息
点击各个实例可以跳转至ECS详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联拓扑、告警列表。
其他内置/自定义拓展的云平台的监控情况均在此展示
K8S监控
WeOps-K8S监控主要提供Pod、Node的监控,展现监控告警基本情况
Pod监控
如下图,“WeOps-K8S监控-Pod”展示了所有的pod列表,包括监控告警状态、关键指标信息等
Node监控
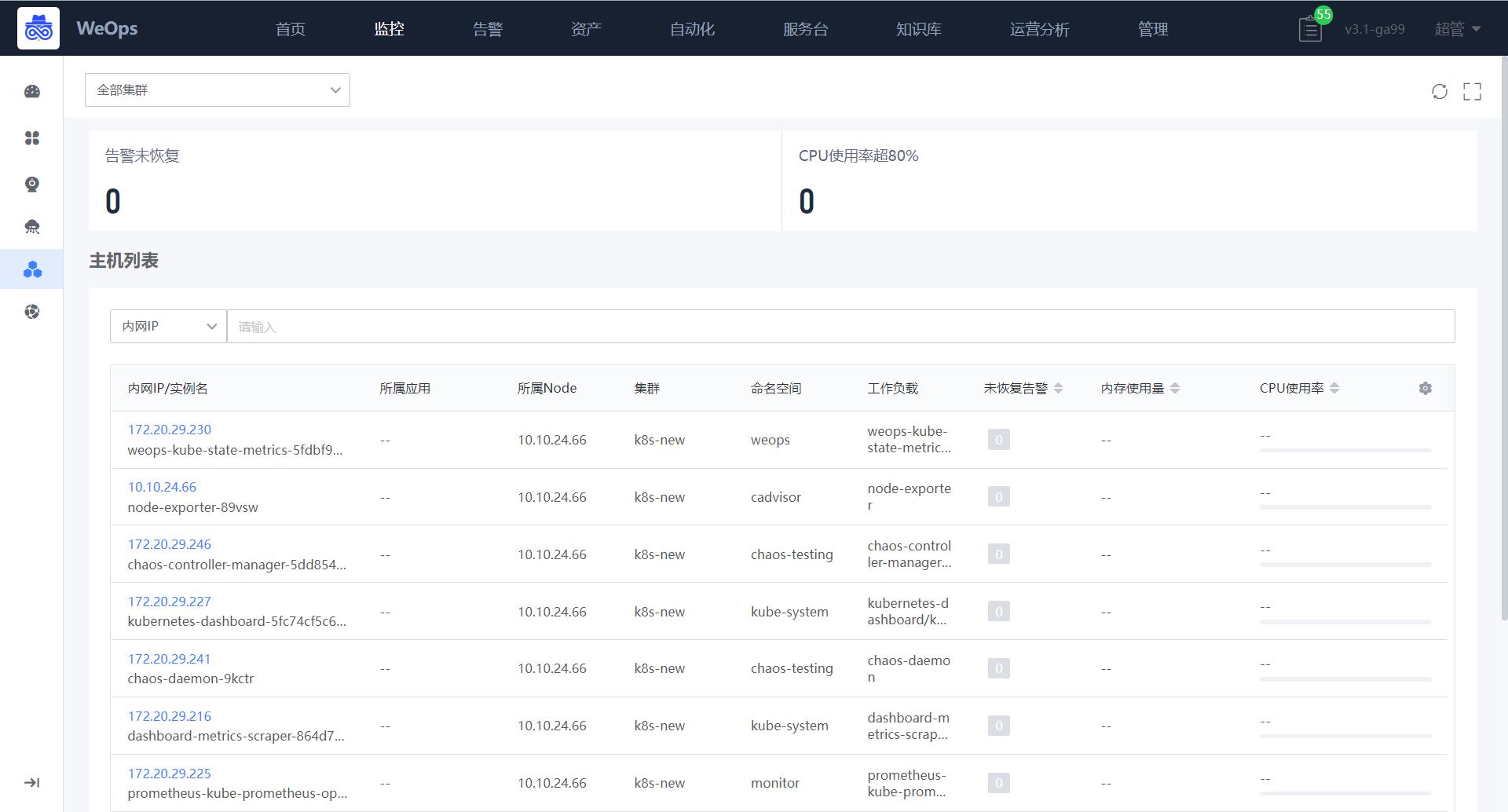
如下图,“WeOps-K8S监控-node”展示了所有的node列表,包括监控告警状态、关键指标信息等,可以点击切换不同的集群查看不同的node列表
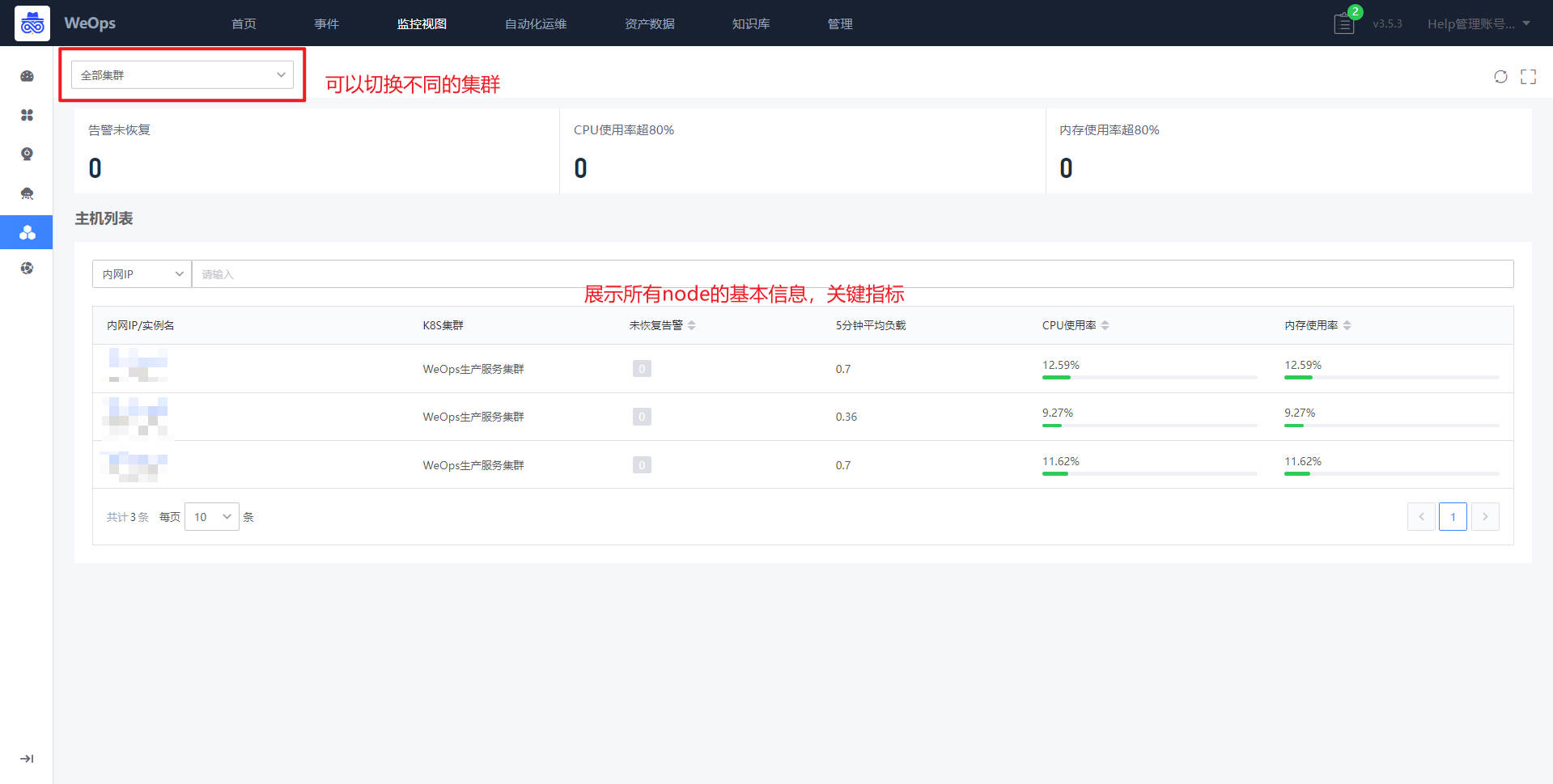
点击各个实例可以跳转至详细信息抽屉页面,详情抽屉包括基础信息、监控视图、关联拓扑、告警列表。
网站监测
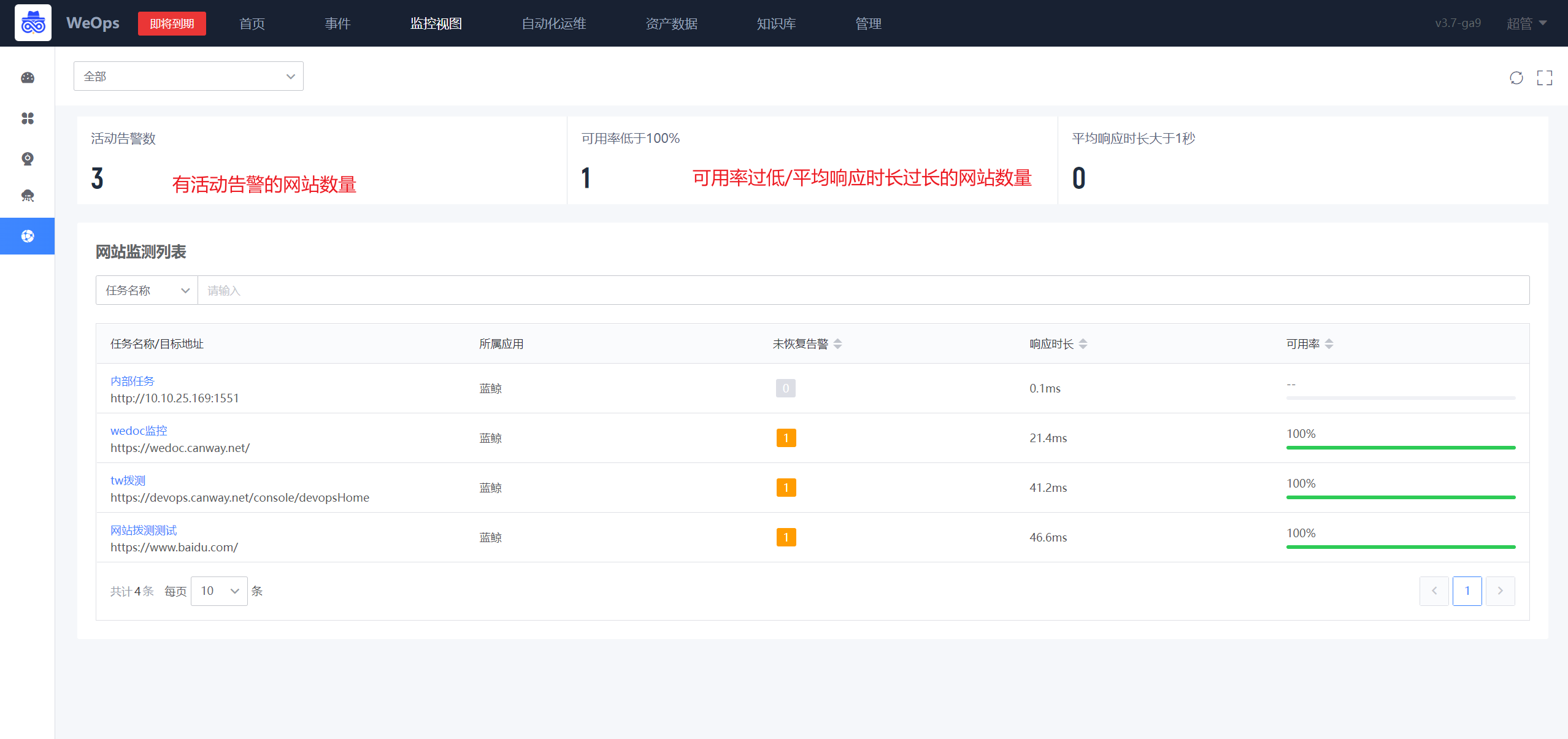
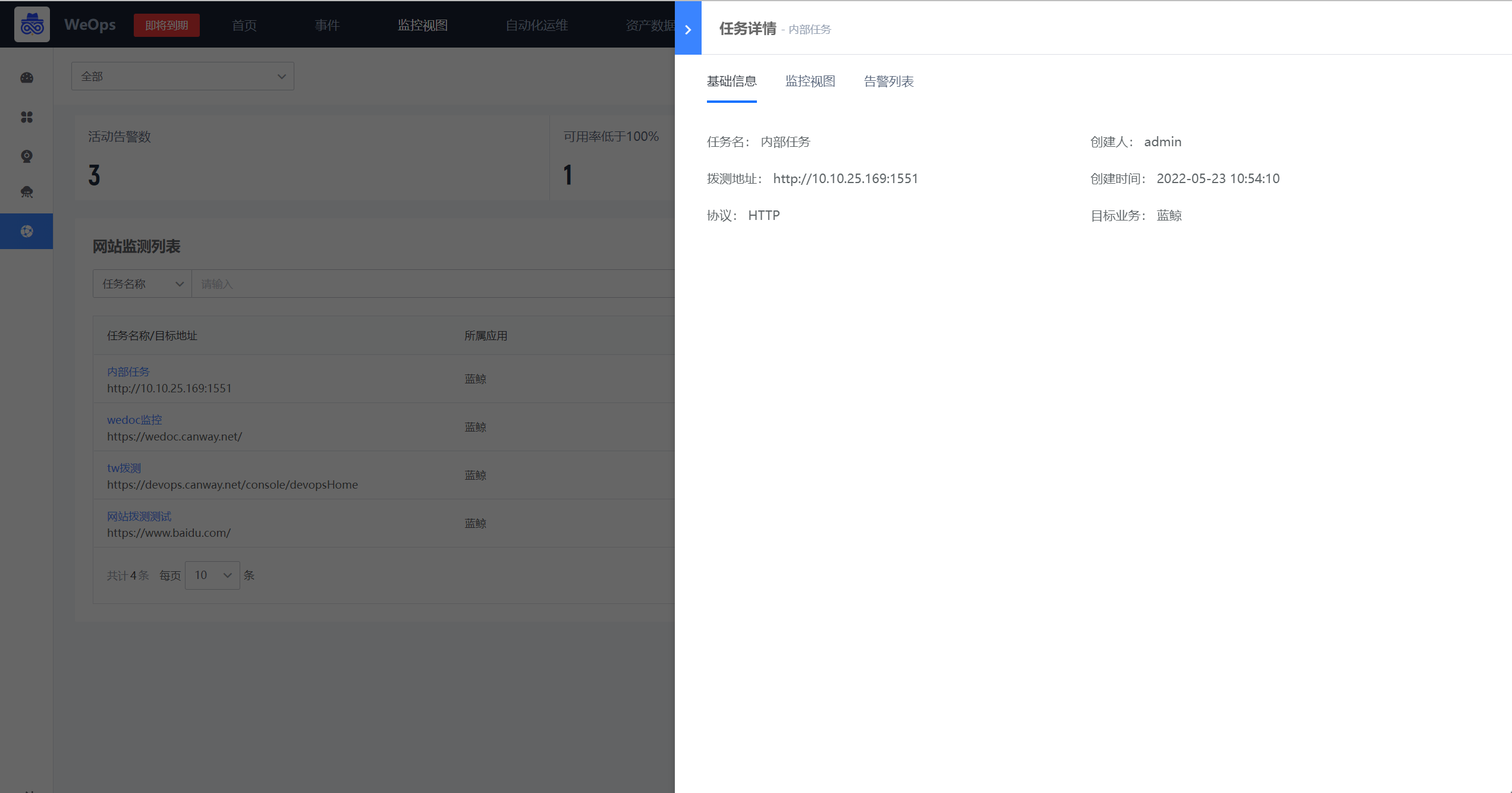
如下图,“监控视图-网站监测”展示了所有网站的监测情况。
- 监测情况概览:有活动告警的网站数量、可用率低于100%的网站的数量,平均响应时长大于1秒的网站总数。
- 网站监测列表:展示所有网站的监测状态、告警状态、响应和可用情况。
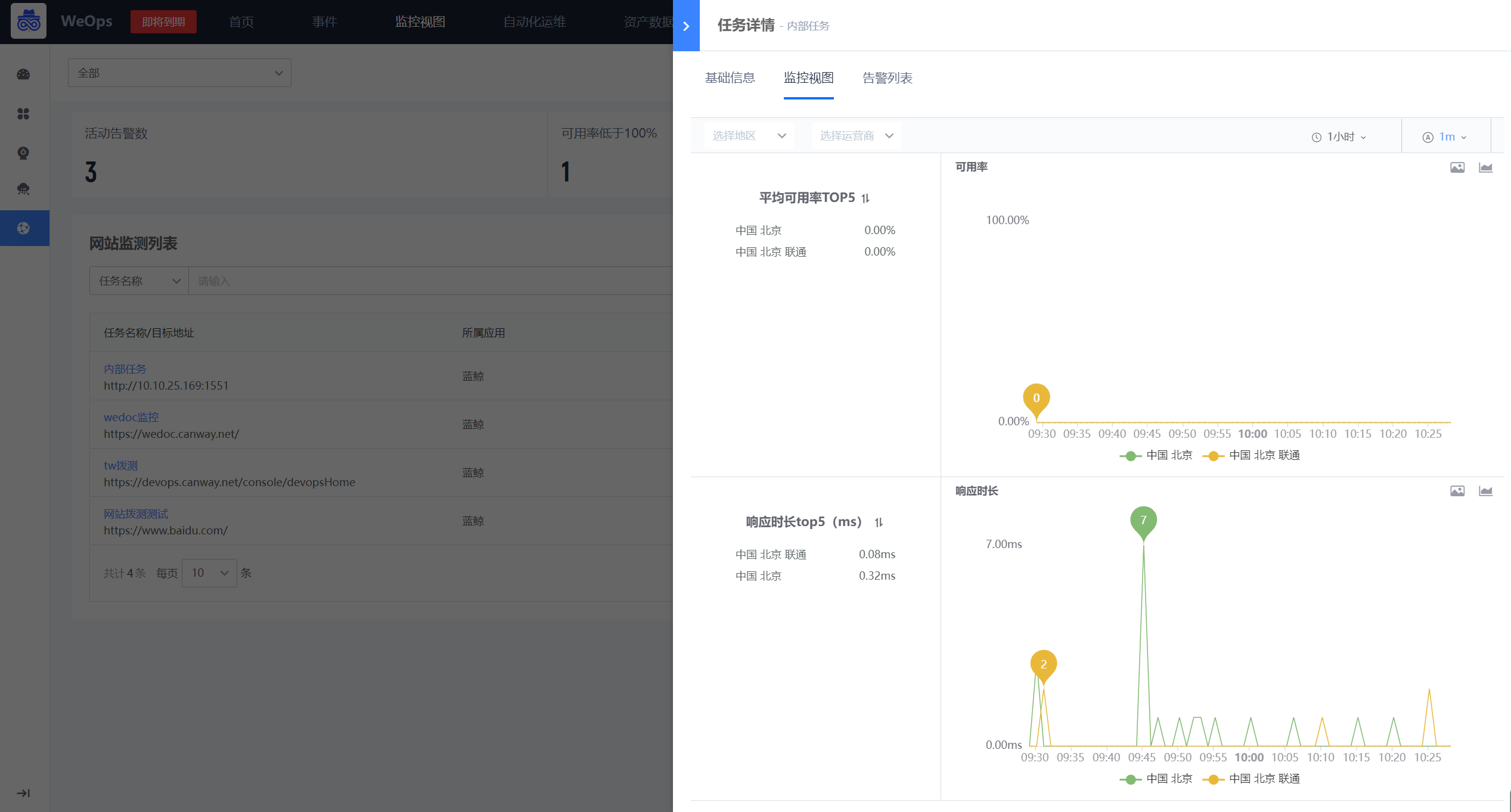
- 点击各个网站,可以进入该网站监测的详情页面,如下图,包括:基础信息、监控视图(可以查看可用率和响应时长的折线/面积图)、告警列表。
告警
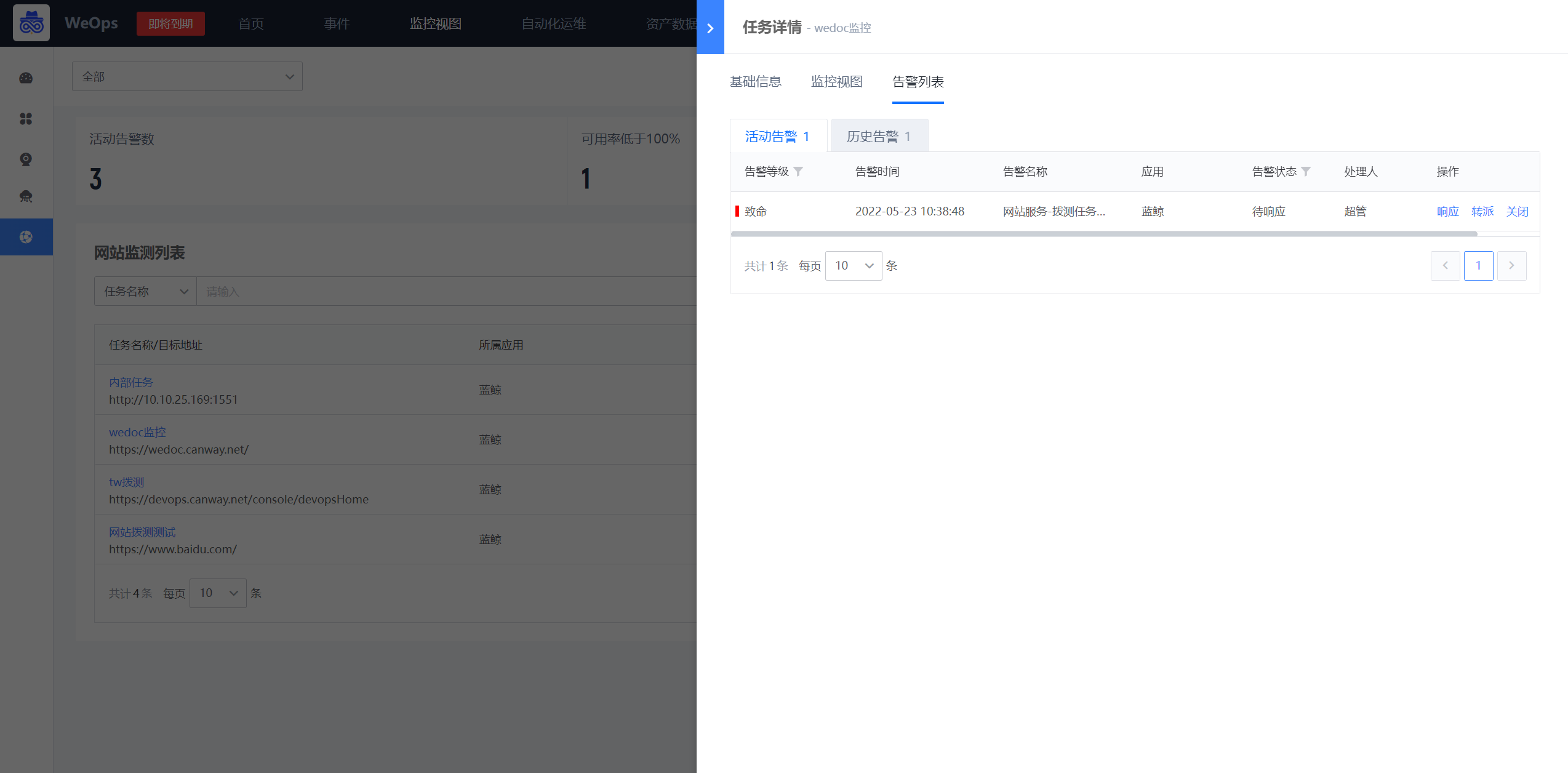
如下图,“WeOps-告警”用于展示“活动告警”“我的告警”和“历史告警”的列表信息,可以直接在列表界面进行各个告警项的操作,比如“认领”、“分派”、“关闭”等
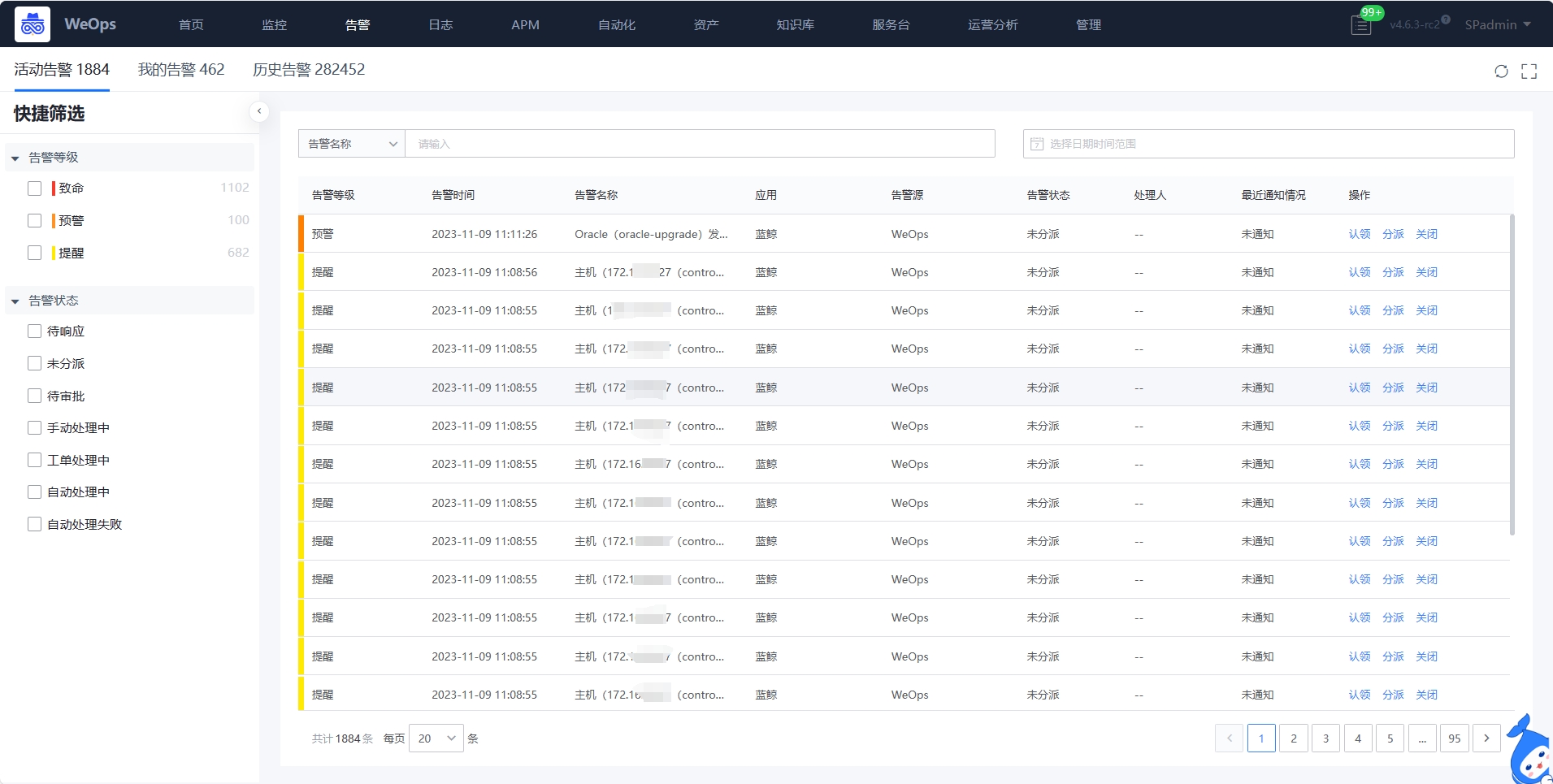
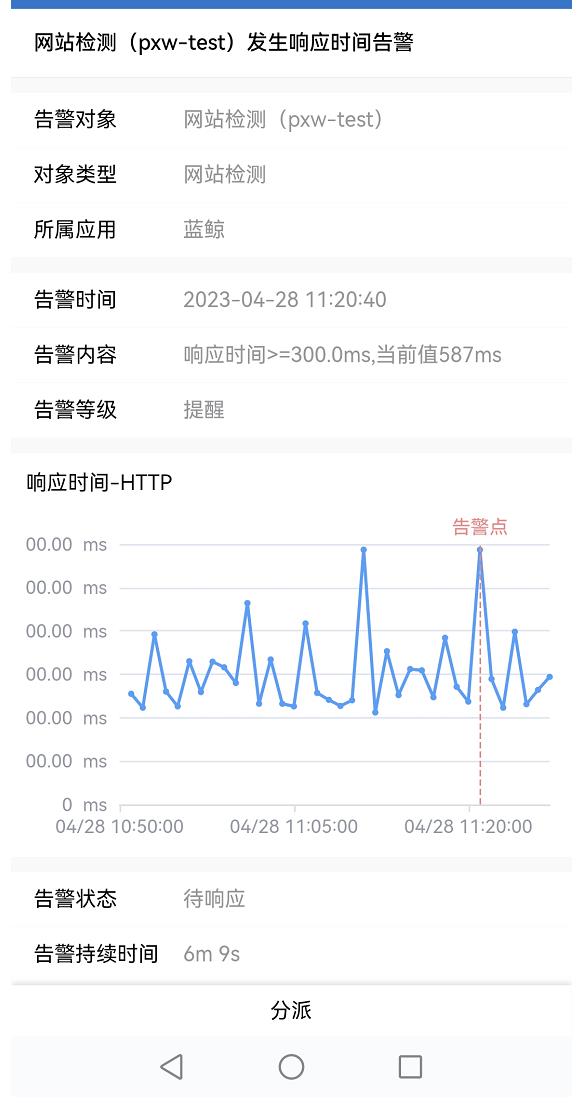
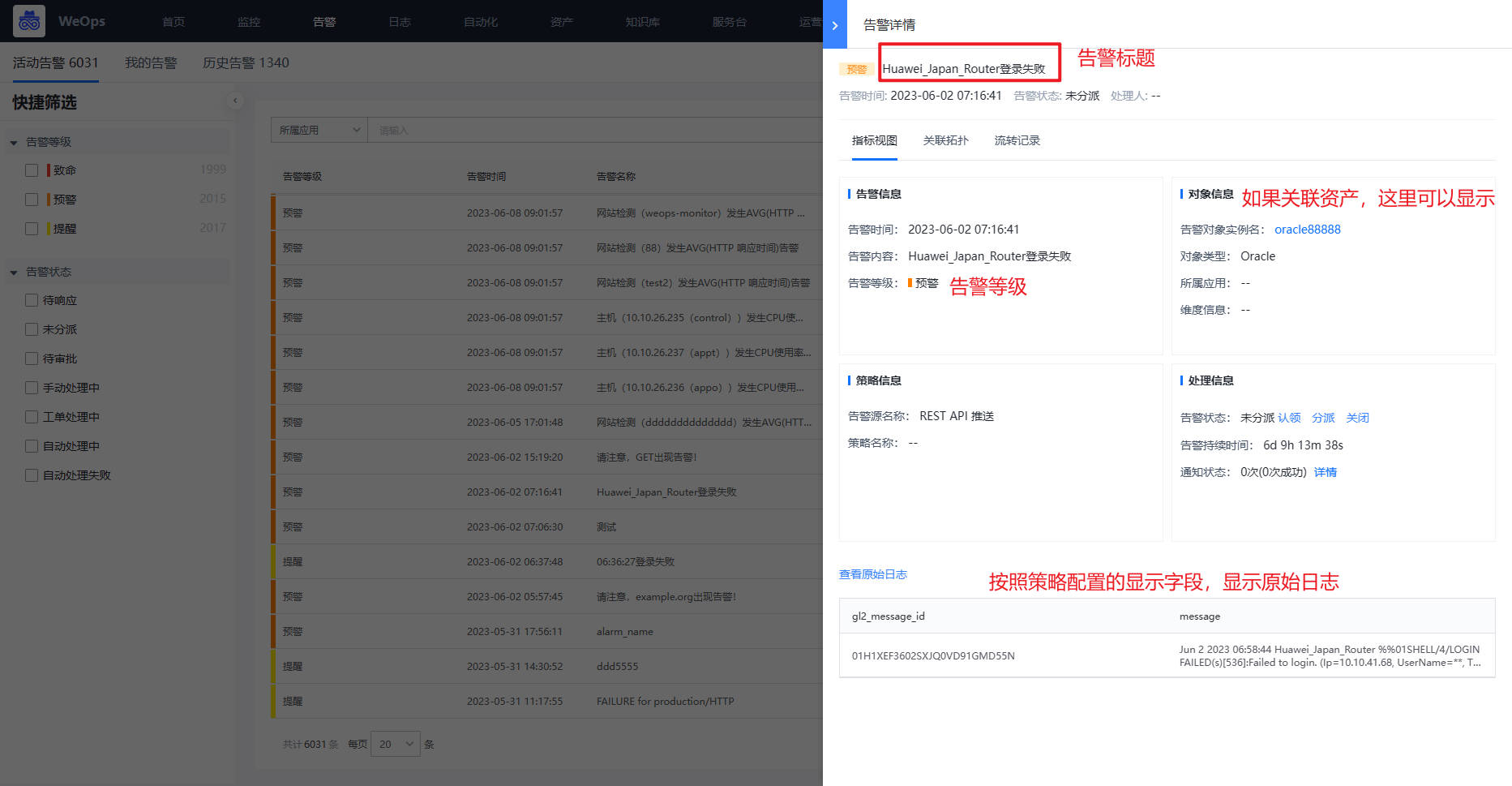
(1)告警基本信息:点击各个告警项,可弹出该告警项的详细信息,具体如下:
- 信息展示:告警信息(展示告警发生的时间、内容和等级)、告警对象信息(实例名称、对象类型、所属应用)、策略信息、处理信息(可进行告警的处理)
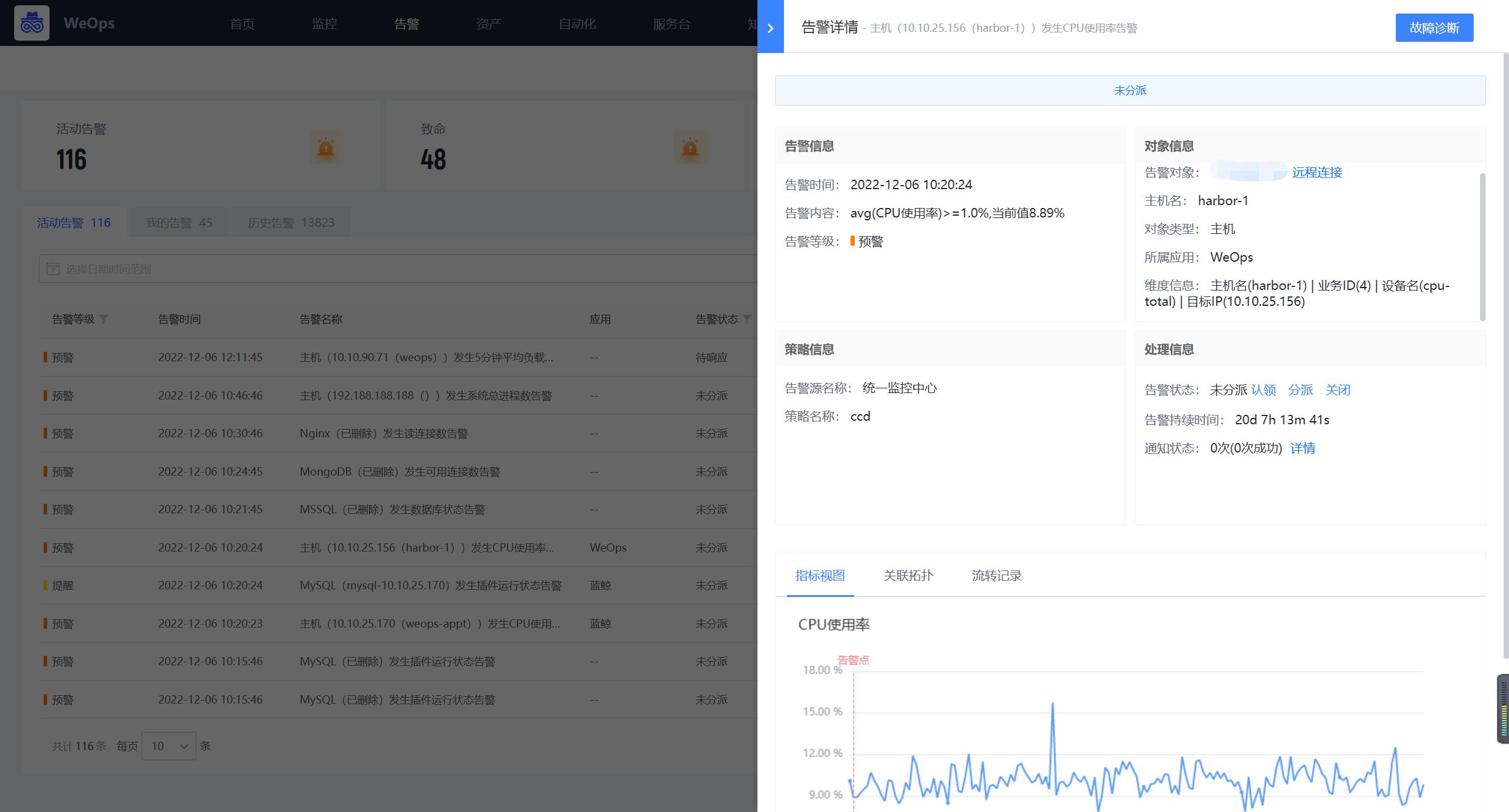
- 视图展示:包括指标视图可以清晰的查看告警发生点,设置的阈值线
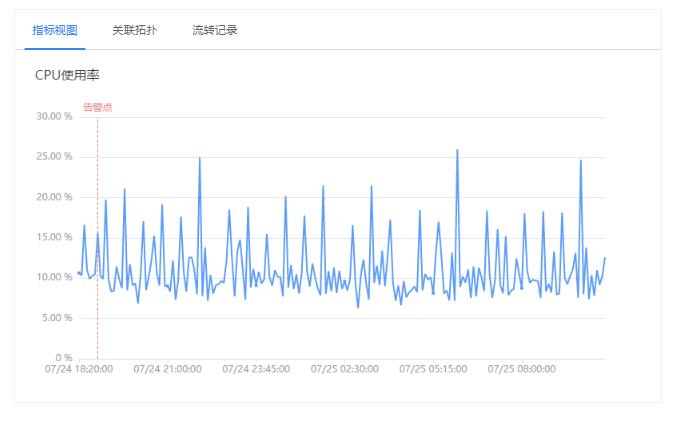
- 关联拓扑:可以清晰的看到产生告警的关联实例情况,可以点击查看关联实例的详细信息。
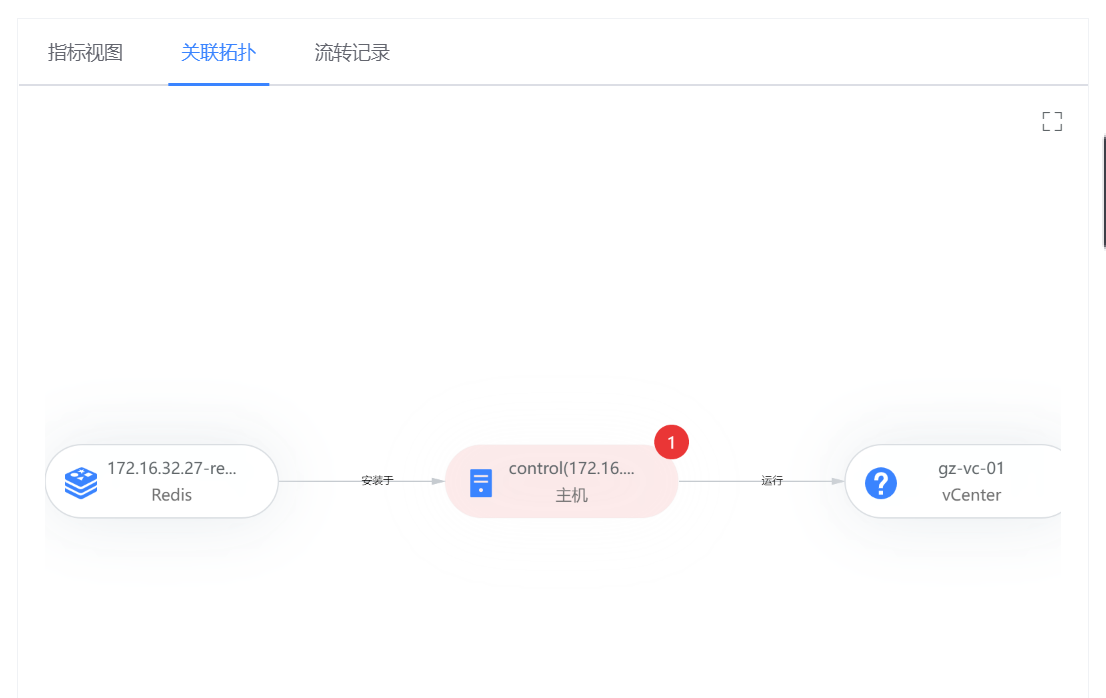
- 流转记录可以查看该告警的发生和处理的流转情况
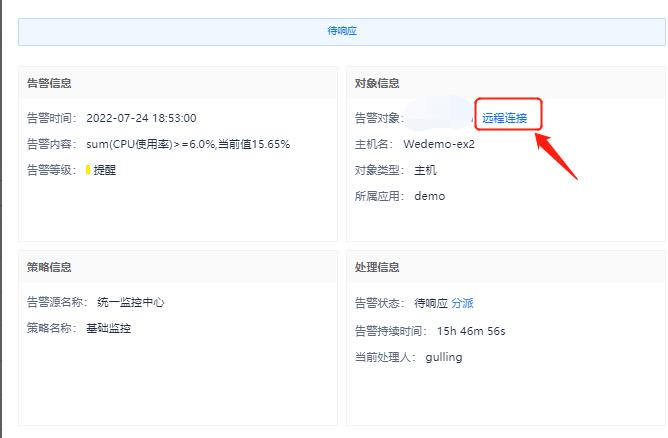
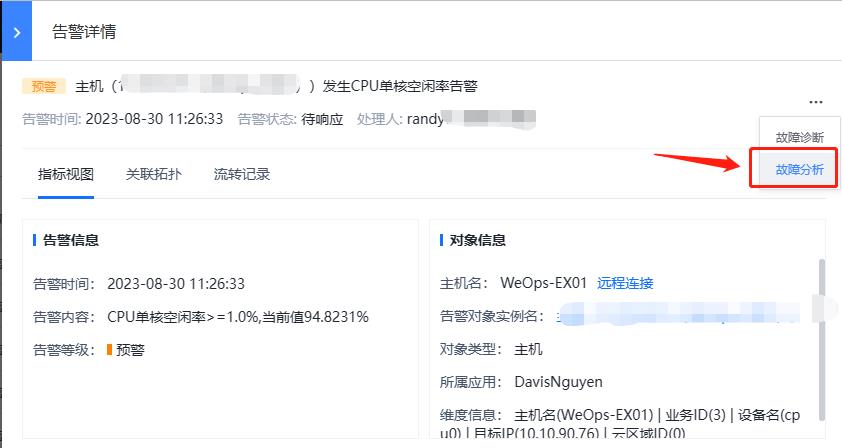
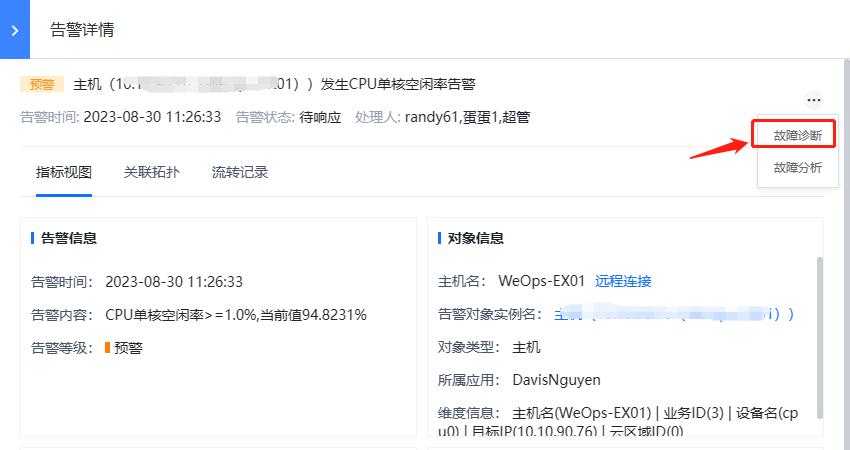
(2)告警联动: 告警与其他自动化/仪表盘等模块进行联动,实现主机远程连接、故障诊断、故障分析和寻求建议等操作,实现从“告警产生-告警信息查看—故障分析——故障诊断”等全过程,各个操作说明如下
- 远程连接:当告警对象为主机时,支持进行远程连接,直接填写远程的凭据,连接该主机。

- 故障分析:当出现告警的时候,点击“故障分析”按钮,可以把故障资产的相关信息、监控指标、日志等,形成专业的故障分析仪表盘,方便进行故障分析。

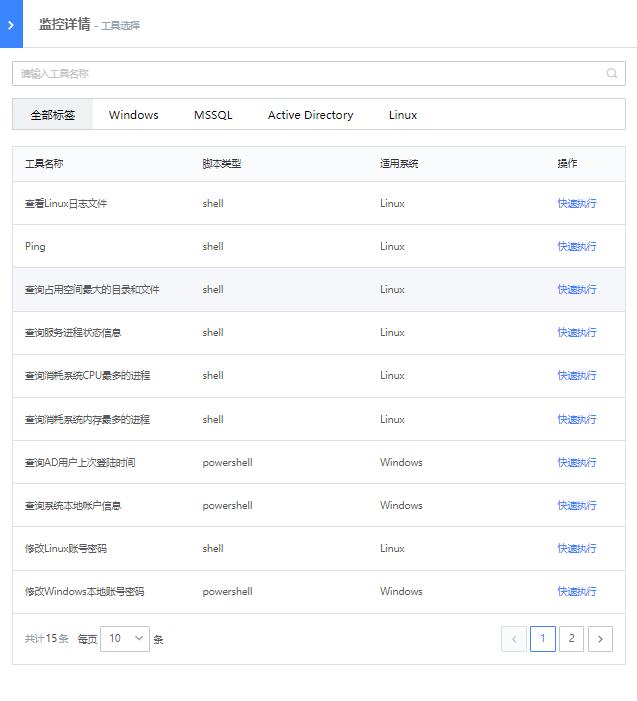
- 故障诊断:当告警对象支持执行运维工具进行故障诊断时,可以在告警的详细中点击“故障诊断”按钮,在展开的运维工具中选择需要执行的工具,进行执行,从而方便的获取更多故障信息。
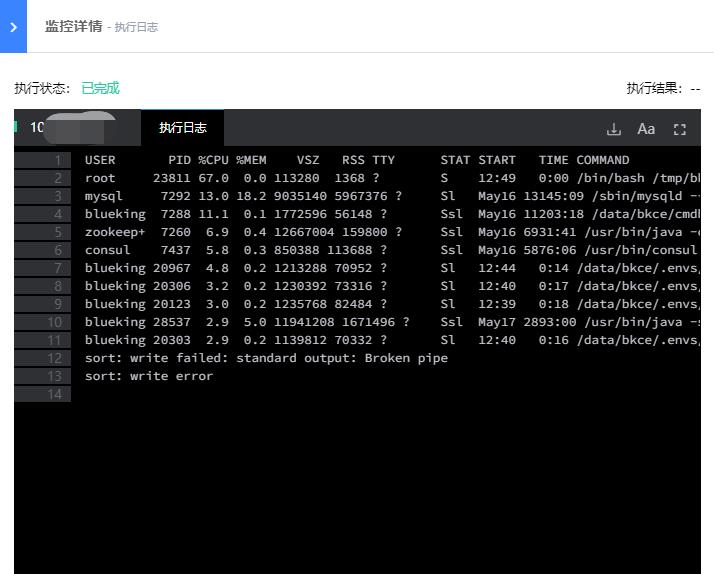
日志
WeOps日志页面支持日志数据的相关搜索,灵活的展示所需要的日志信息,具体如下图
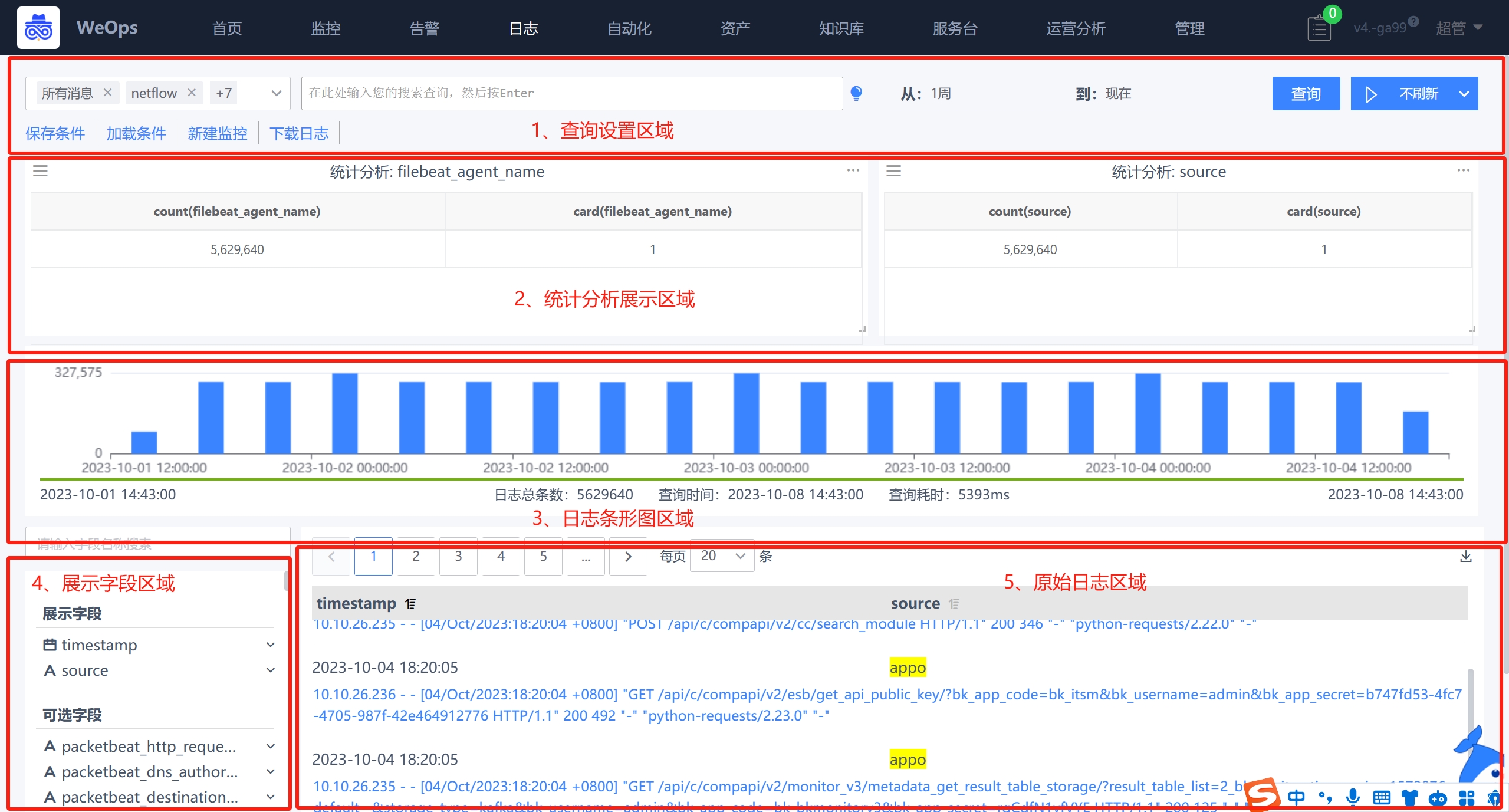
查询设置区域
WeOps提供灵活的搜索语法和搜索条件,支持按照各自需求进行设置,搜索条件是由“日志分组情况+搜索框关键字+搜索时间”生成,并按照设置的刷新时间进行自动更新,设置的搜索条件可以保存,以便下次直接使用,具体的设置说明如下
- 日志分组:根据用户拥有的日志分组权限进行选择,仅展示选中后的分组内的日志数据。
- 搜索框:支持对日志的关键词进行搜索,点击“灯泡”按钮,可以查看语法指引,输入日志字段会自动给出下列字段列表,便于使用。

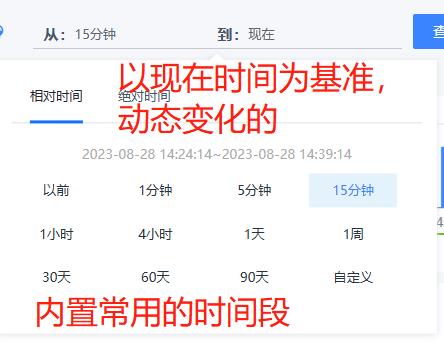
- 搜索时间:分成两类,相对时间和绝对时间,相对时间是指选择从过去的某个时间点到现在时间点的一段范围,是动态变化的,比如“1小时”是指1个小时前到现在的时间范围;绝对时间是一段确切的时间,不会随着时间流逝而动态变化,比如“2023-08-28 00:00:00 – 2023-08-29 23:59:59”就是指展示这段时间的日志。

- 刷新设置:支持设置自动刷新和不刷新,不刷新的是指在日志展示过程中不会更新最新的日志数据;自动刷新可以设置刷新时间,默认是5秒钟,开启自动刷新后,将会按照刷新时间自动更新日志数据。
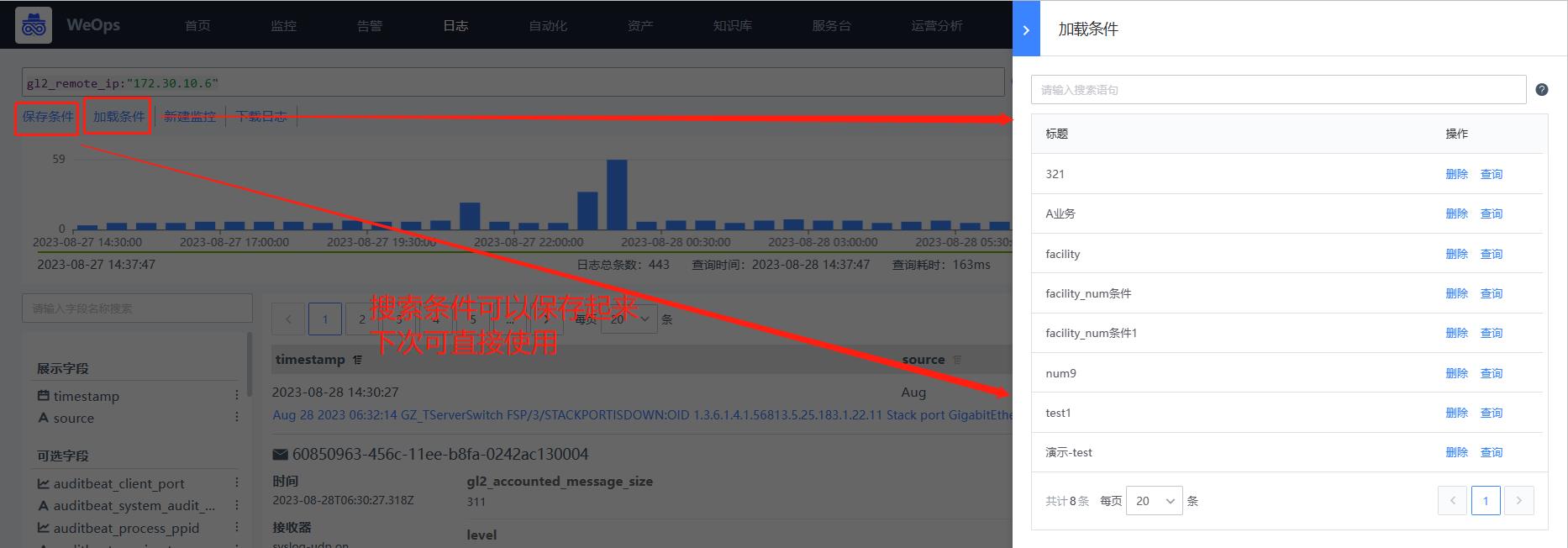
- 保存条件/加载条件:支持将常用的搜索条件进行保存为一个“保存条件”,可以保存的搜索条件为“日志分组+搜索关键词+搜索时间+展示字段”。当下次再使用该条件时,在“加载条件”中选择即可使用。
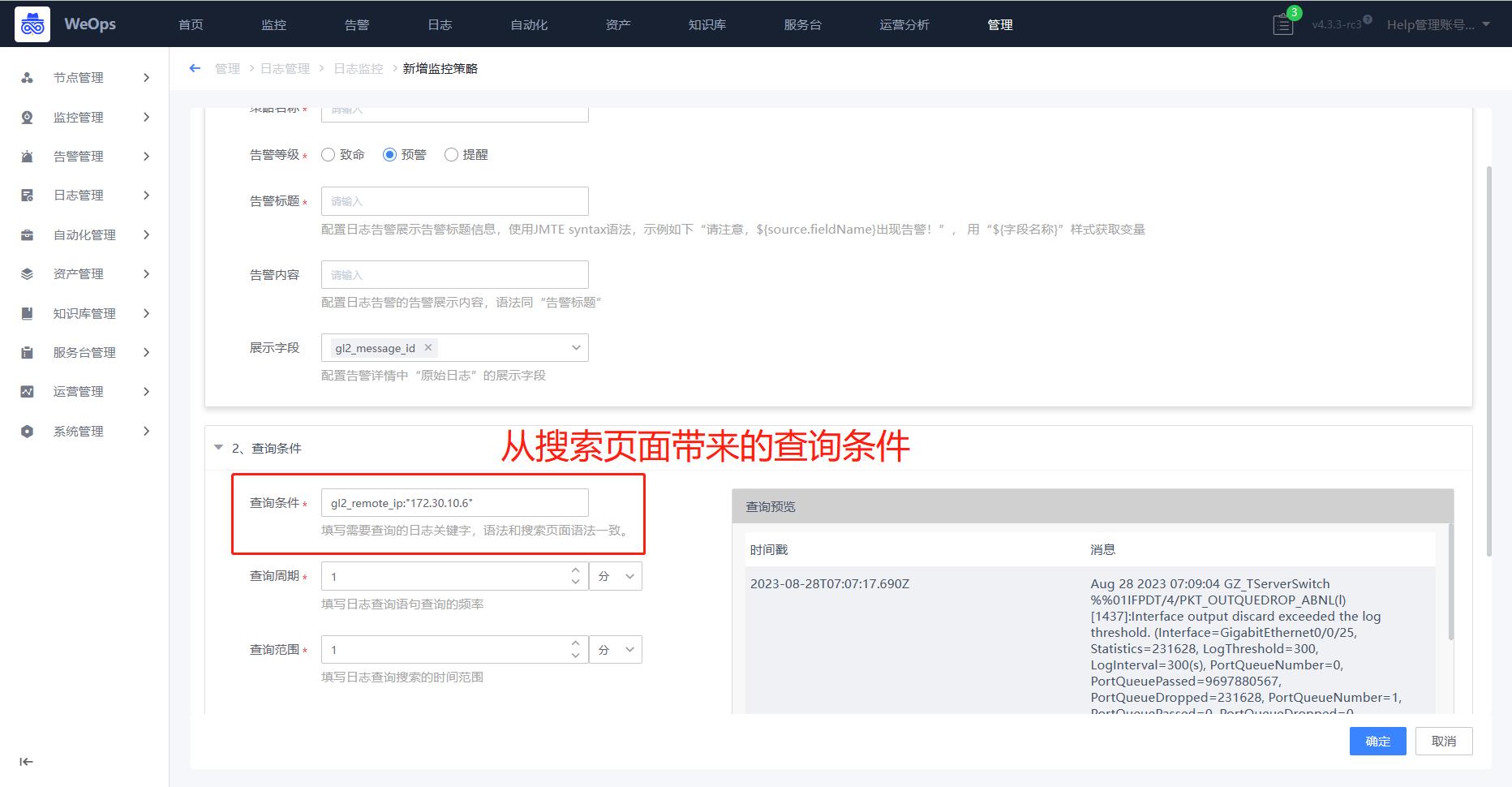
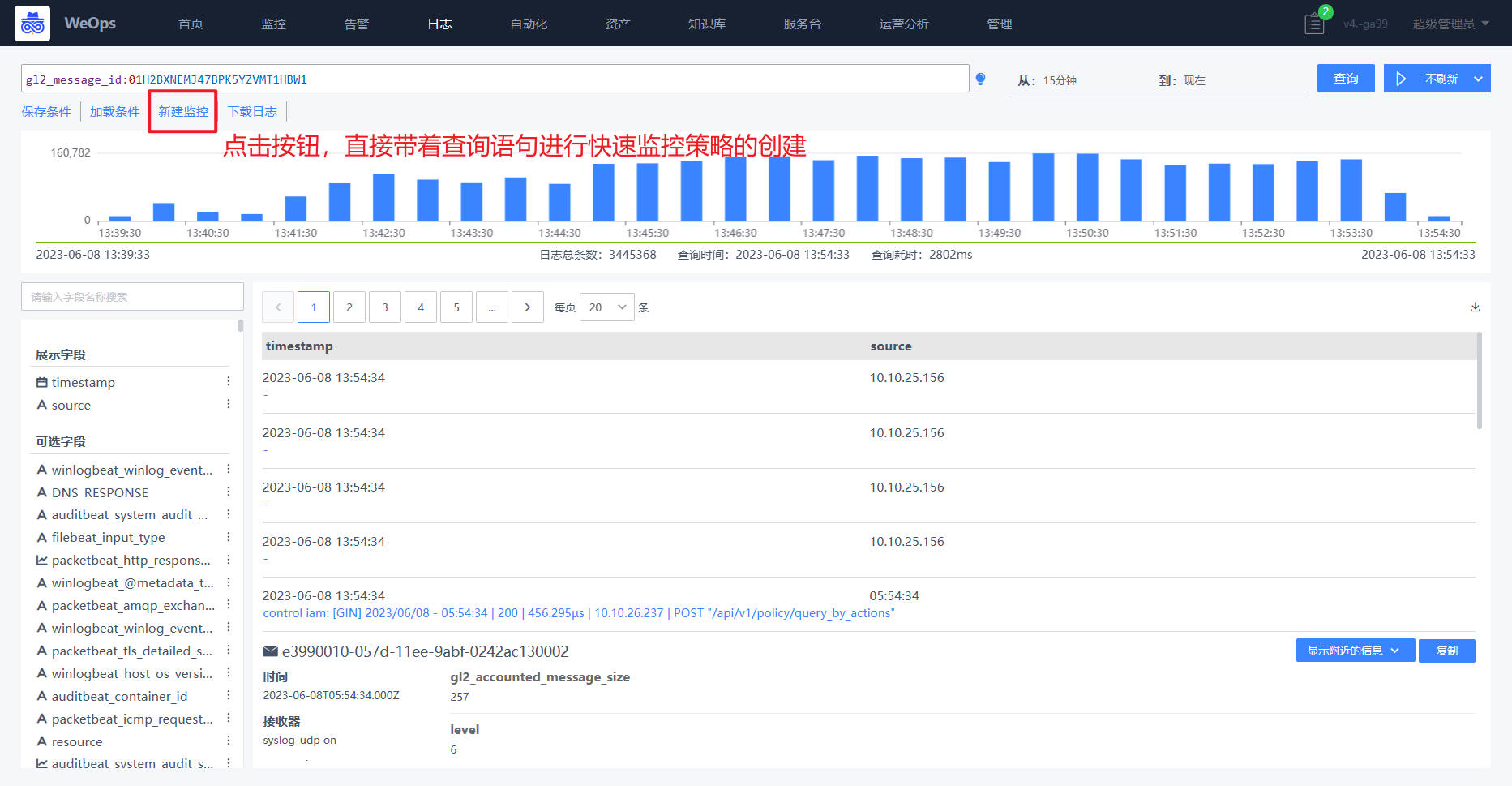
- 新建监控:点击“新建监控”按钮,可以快捷创建监控策略,在监控策略中,把本次查询的搜索关键词直接带入策略中
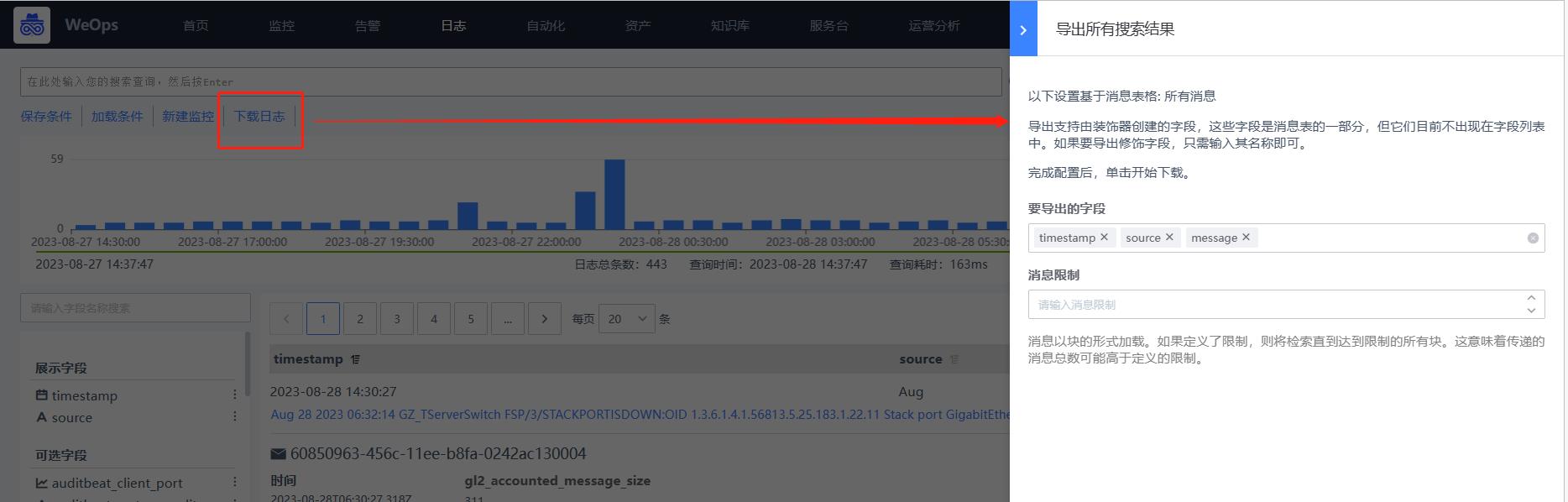
- 日志下载:点击“下载日志”按钮,可以下载该搜索条件下的所有原始日志,可以设置导出的字段和消息限制,导出格式为“.cvs”格式。
统计分析区域
- 当字段选择“统计分析”时,可以快速统计该查询时间范围内,字段所有的字段值的数量情况,并形成统计分析表格,统计分析表支持进行以下操作

- 复制:复制出一个一样的统计分析表格
- 复制到仪表盘:选择一个仪表盘,该组件会复制到该仪表盘内,成为仪表盘的一个组件
- 编辑:支持对该统计分析的组件进行编辑,编辑的选项与“仪表盘-日志-表格”组件一致
- 删除:将该组件进行删除
日志条形图区域
- 日志条形图:展示搜索时间段内,日志的随着时间的分布的情况;鼠标悬停可以展示该时间信息和日志的数量;鼠标左键按住拖动可以选择一段时间范围,放开后可以详细展示这段时间的情况和原始日志数据(相当于变化了搜索时间范围)


展示字段区域
WeOps-日志的字段区域展示了“展示字段”和“可选字段”两类
- 可选字段:展示所有的支持的字段,可以将该字段添加到表格中展示,或者添加到查询语句进行搜索
- 展示字段:展示了所有在表格表头的字段,从表格中移除,或者添加到查询语句进行搜索
- 可选字段和展示字段支持展示该字段的统计值top5,点击下拉该字段,即可进行统计展示。

原始日志区域
- 日志部分:日志部分展示了根据查询条件搜索到的所有的日志,可以点击查看详情每一条日志的详情,并进行特殊操作
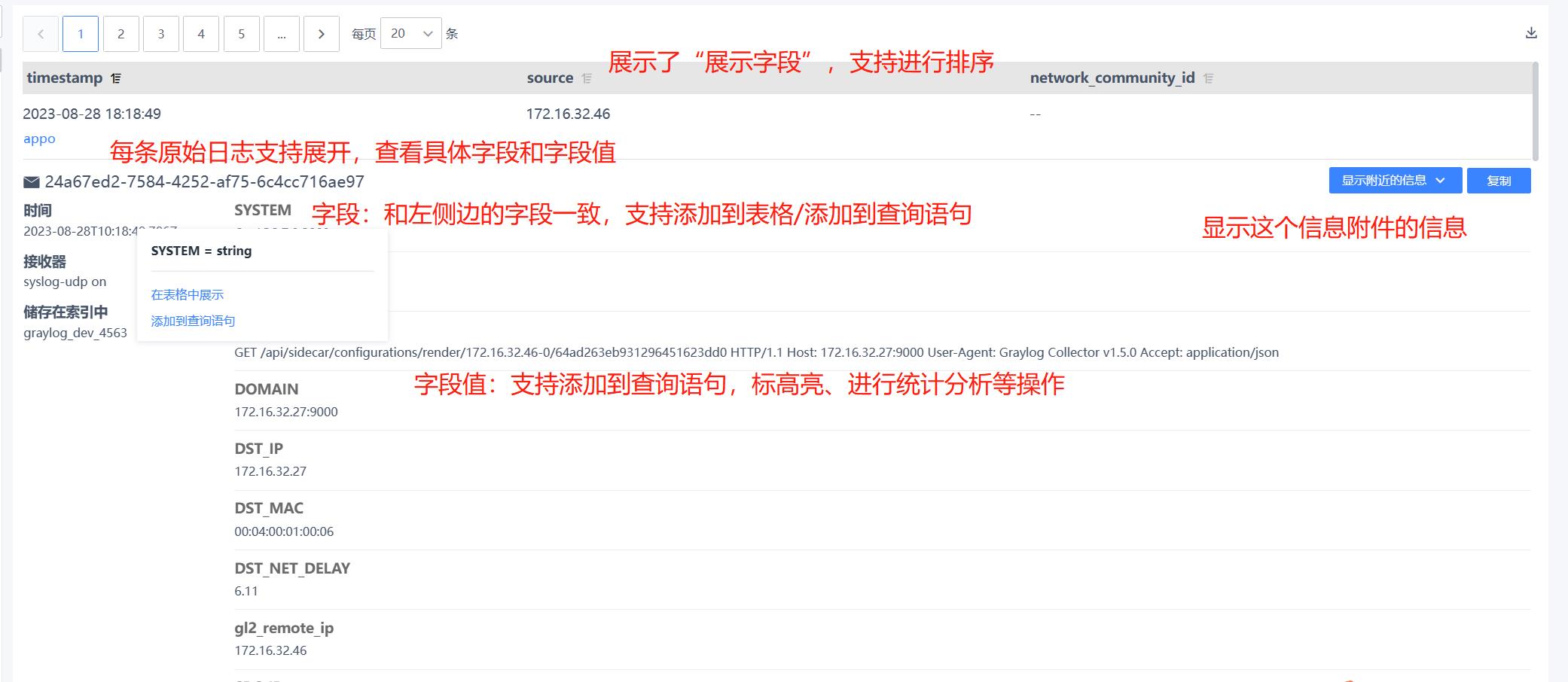
- 对于字段:支持设置在表格展示(展示在表头)、添加到查询语句(直接展示在查询语句里面)、统计分析(形成该字段的数量的统计分析表格,并呈现在统计分析区域)
- 对于字段值:支持设置添加到查询语句(直接展示在查询语句里面,用于查询所有带这个字段值的原始日志)、设置“从结果中排除”(在查询语句中展示,用于查询所有不带这个字段值的所有原始日志)、设置“高亮”(把所有带这个字段值都标为黄底)、设置提取器(支持把这个字段值设置提取器,提取出来需要展示的关键信息保存为另外一个字段)

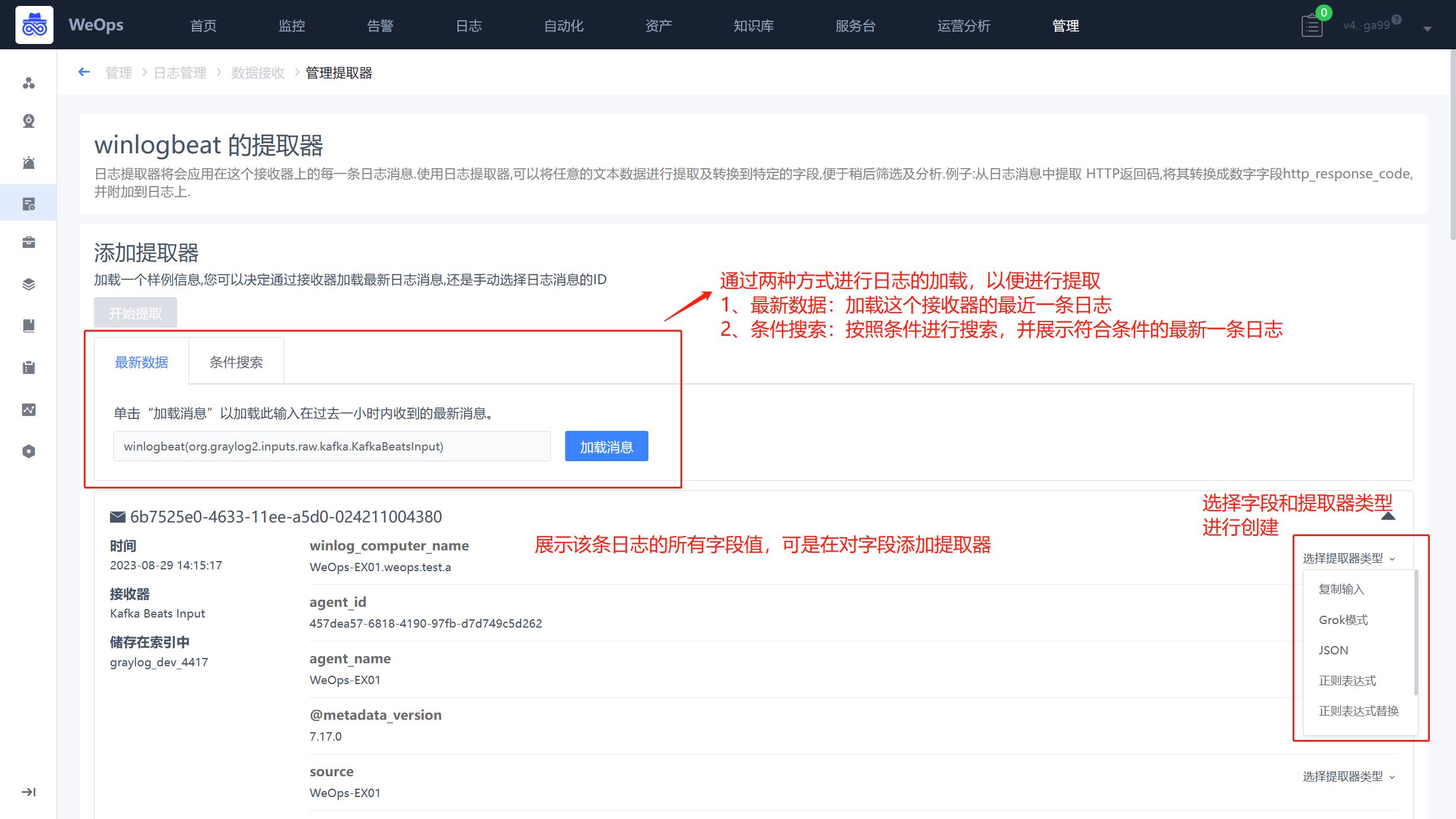
- 字段值提取器:支持复制输入、Grok模式等类型的提取器(各个提取器的对比如下表)。以正则表达式为例,设置提取器支持填写正则表达式、设置条件(什么情况下进行提取)、存储字段、提取策略(复制一个新的,剪切成为一个新的)、添加特殊格式的转换器
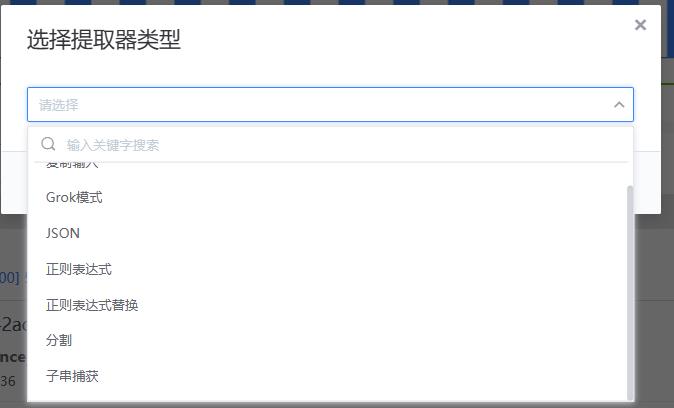

- WeOps支持的提取器如下表
| 提取器名称 | 适用 | 说明 |
|---|---|---|
| 复制输入 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 将原始消息中的一部分数据复制到提取器的规则中,并将其存储在结构化的数据字段中 |
| Grok模式 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 用于从非结构化的日志数据中提取结构化数据。它使用预定义的Grok模式或自定义Grok模式来匹配和提取数据,包括一些特殊的模式,用于匹配常见的数据格式,如IP地址、日期、时间戳等。(WeOps内置常用的Grok表达式)(Grok表达式是一种用于解析非结构化或半结构化数据的模式匹配工具。它是由Elasticsearch社区开发的一种基于正则表达式的模式匹配语言) |
| JSON | 适用于处理JSON格式的日志数据的场景。 | 可以从JSON格式的数据中提取特定的字段,并将它们存储在结构化的数据字段中。 |
| 正则表达式 | 适用于需要从未结构化的日志数据中提取特定字段或值的场景。 | 使用正则表达式从数据中提取特定的字段,并将它们存储在结构化的数据字段中 |
| 正则表达式替换 | 适用于需要替换日志数据中特定字符串的场景。 | 正则表达式替换器可以使用正则表达式从数据中匹配特定的模式,并将其替换为指定的字符串 |
| 分隔 | 适用于需要从日志数据中提取特定字段或值的场景。 | 使用指定的分隔符将数据分割成多个部分,并将它们存储在结构化的数据字段中 |
| 子窜捕获 | 适用于需要从日志数据中提取特定子字符串的场景。 | 使用指定的开始和结束字符串或位置来捕获数据中的子串,并将它们存储在结构化的数据字段中 |
APM
调用链检索
如下图,当应用的服务接入完成之后,可以在APM-调用链检索进行trace的搜索和查看。可分为如下四个区域,分别进行trace的条件/时间设置、trace列表查看和各个请求详情的查看。

- ①搜索条件区域:支持切换不同的应用和对应的服务,也支持通过trace ID或者链路入口接口/方法的关键词进行搜索,此外也可以设置耗时查询范围
- ②时间选择器:支持选择trace的产生时间范围,便于进一步锁定
- ③检索结果:展示符合搜索条件下所有的trace列表,可展开查看详情以及具体的请求步骤,各个请求也可点击查看详情。
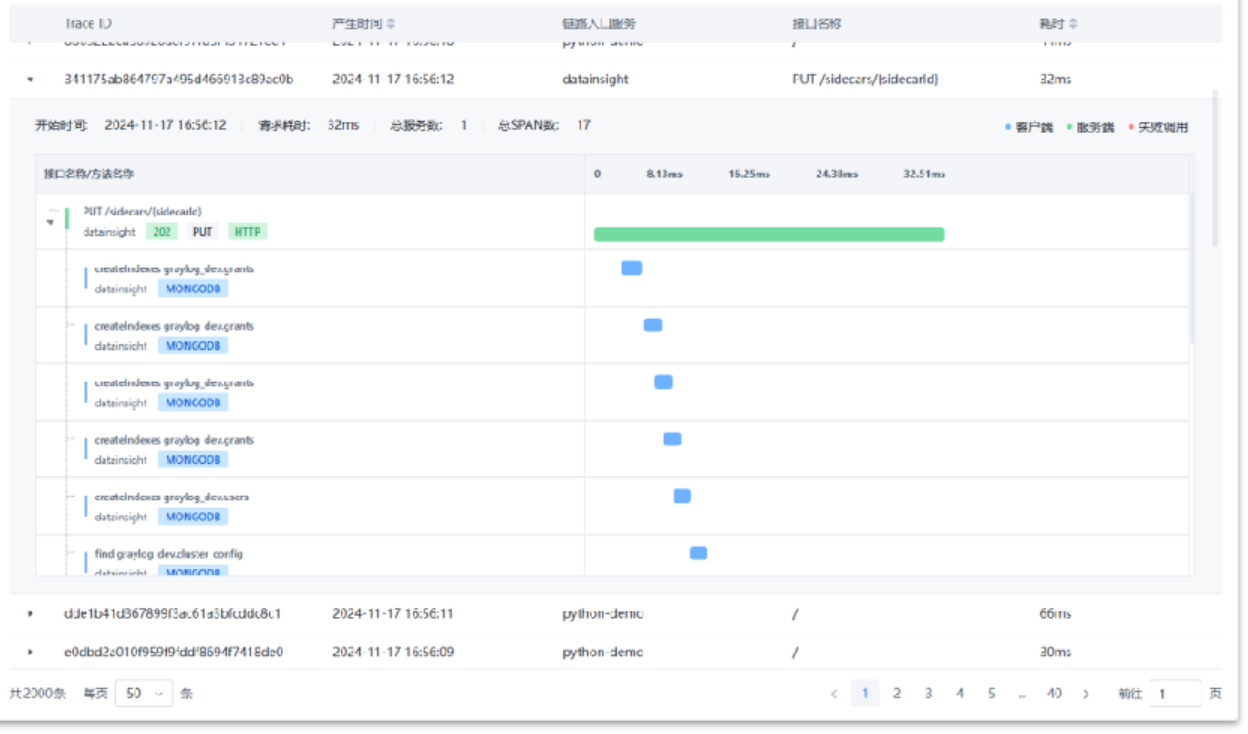
- ④请求详情:展示该次请求的相关信息,具体如下:
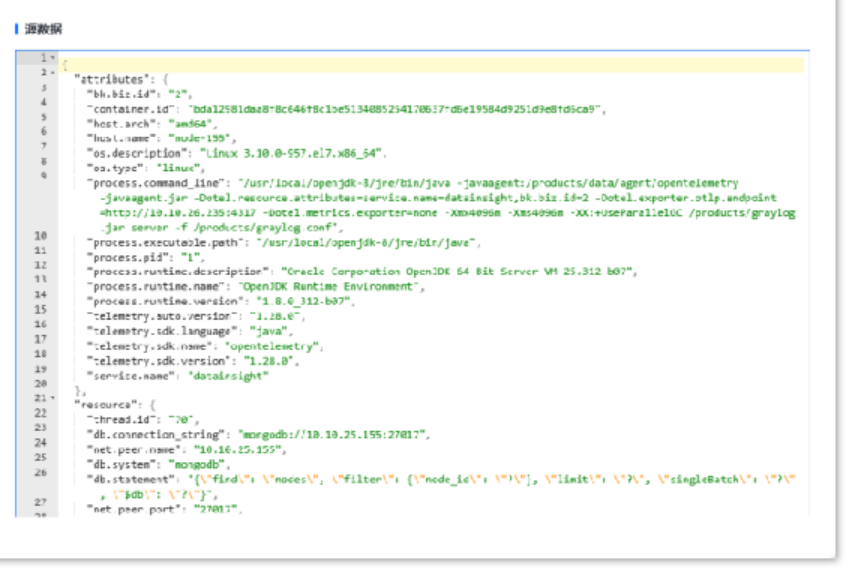
基本信息:该请求的基本调用信息,客户端和服务端调用的耗时情况
源数据:客户端和服务端原始的数据
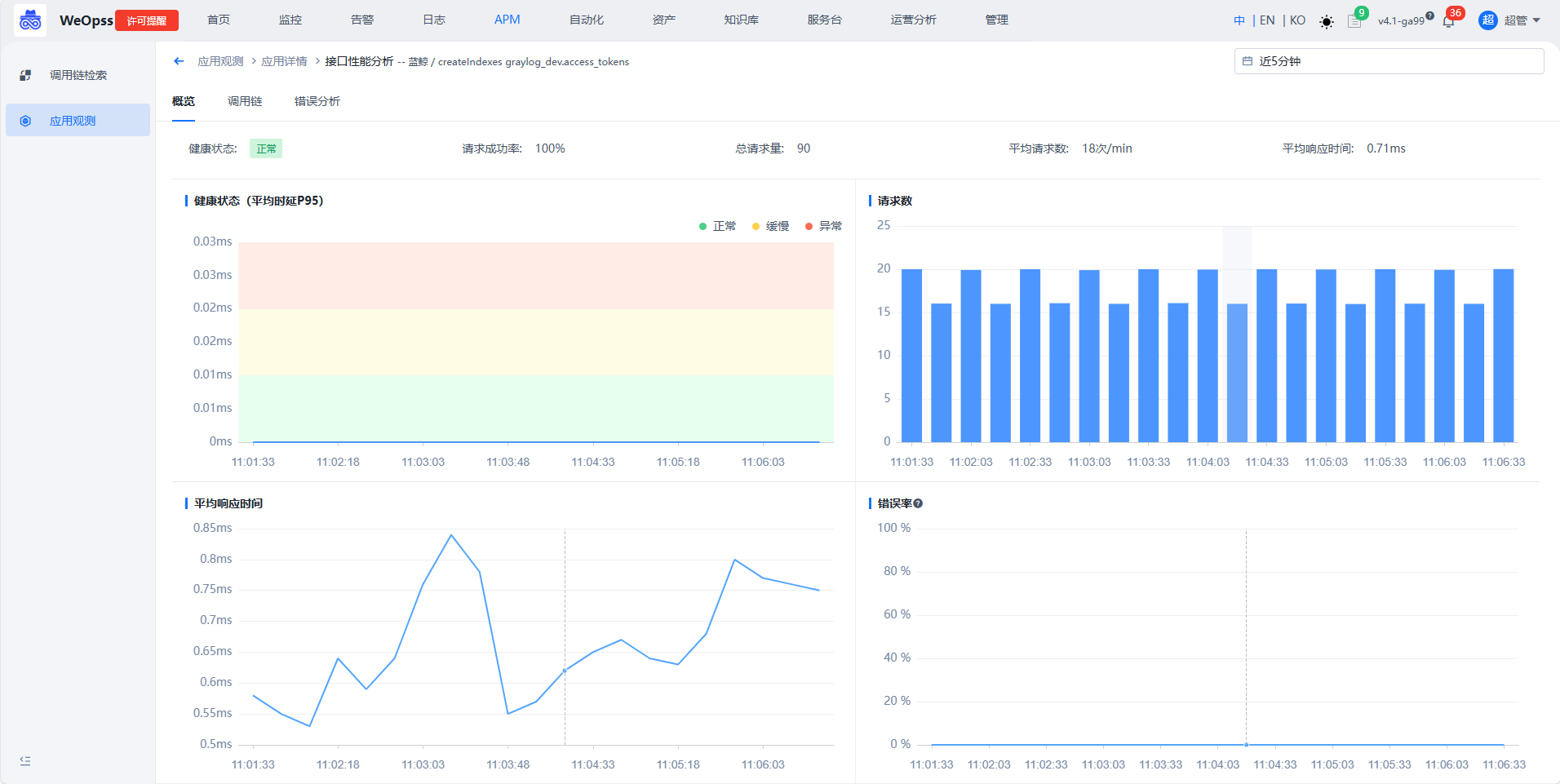
应用观测
应用观测提供应用下服务运行态全景调用关系和服务、接口请求量统计情况,帮基于全景视角观测系统运行时实际流量运行状态,清晰构建系统调用依赖关系包含服务、外部服务、数据库、中间件等系统组件。
应用列表
- 如下图,应用列表展示接入的所有应用,以及该应用的关键指标,点击进入该应用的详情页面。
- 应用的详情页分为三个模块:应用分析——展示整个应用的拓扑和关键指标情况,服务分析——该应用下所有服务的性能情况,接口分析——所有接口的性能情况。
应用分析
- 如下图,展示整个应用的全景拓扑图和该应用的关键指标信息,具体说明如下
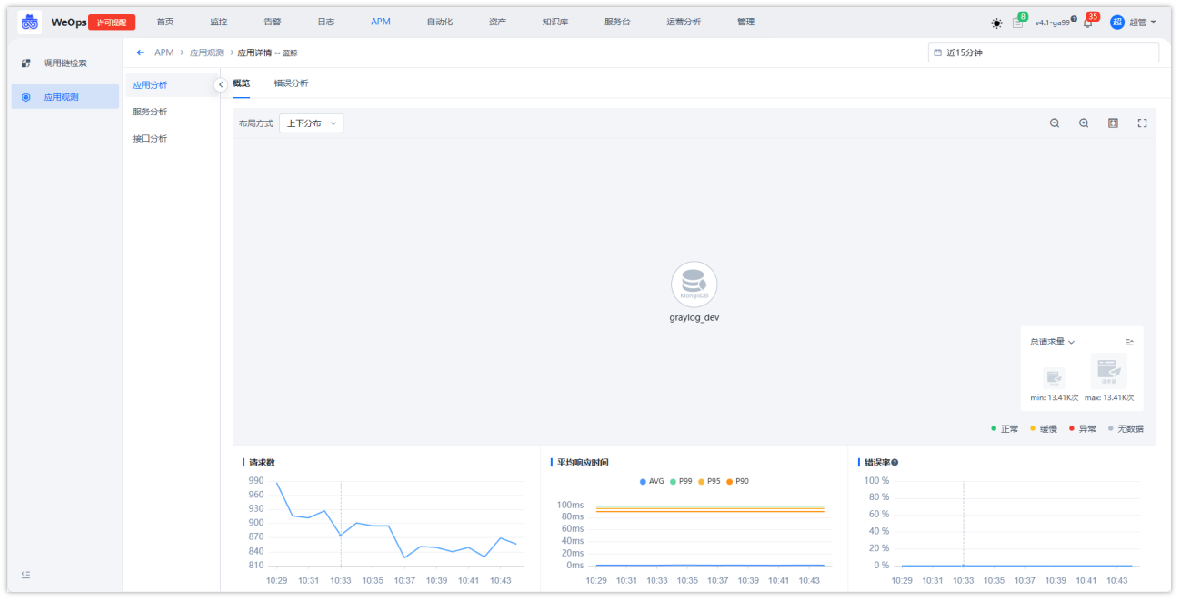
① 时间选择区域:支持切换时间范围,切换后下方的拓扑图和指标折线图会根据选择的时间范围更新展示。

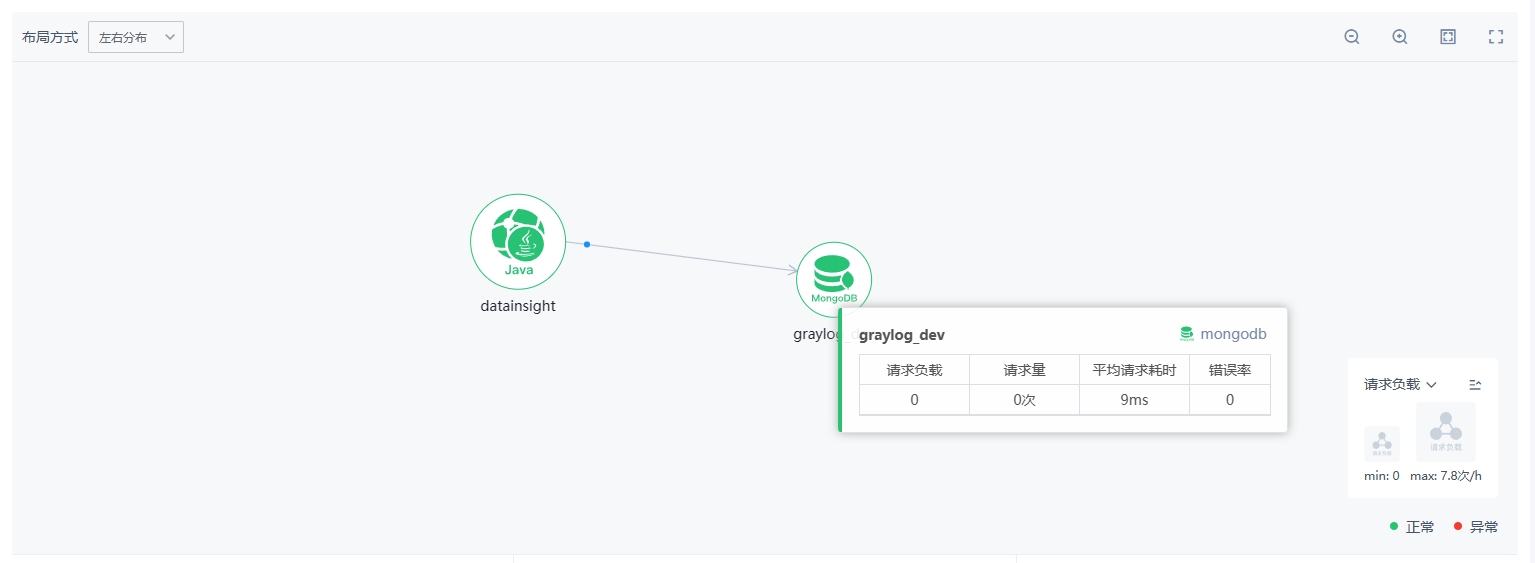
② 应用全景拓扑图:展示该应用所有服务的调用拓扑关系,具体说明如下
节点图标大小:根据服务请求量和请求负载判断节点拓扑大小,确定当前拓扑的最大值和最小值,其余节点按比例确定节点大小
图标悬停展示:将鼠标悬停在节点可以查看该节点详情,包括负载、请求量、耗时、错误等信息
③ 应用性能关键指标:提供当前时间范围的请求数量,错误数、服务请求,响应时间的关键指标折线图

④ 错误分析:如下图,切换可以查询所有错误的情况,支持按照时间/服务/接口/方法进行筛选。点击接口名称可以调整至这个接口的分析页面;点击调用链,可以跳转到该请求的trace详情页;点击错误堆栈,可以查看堆栈的详情。
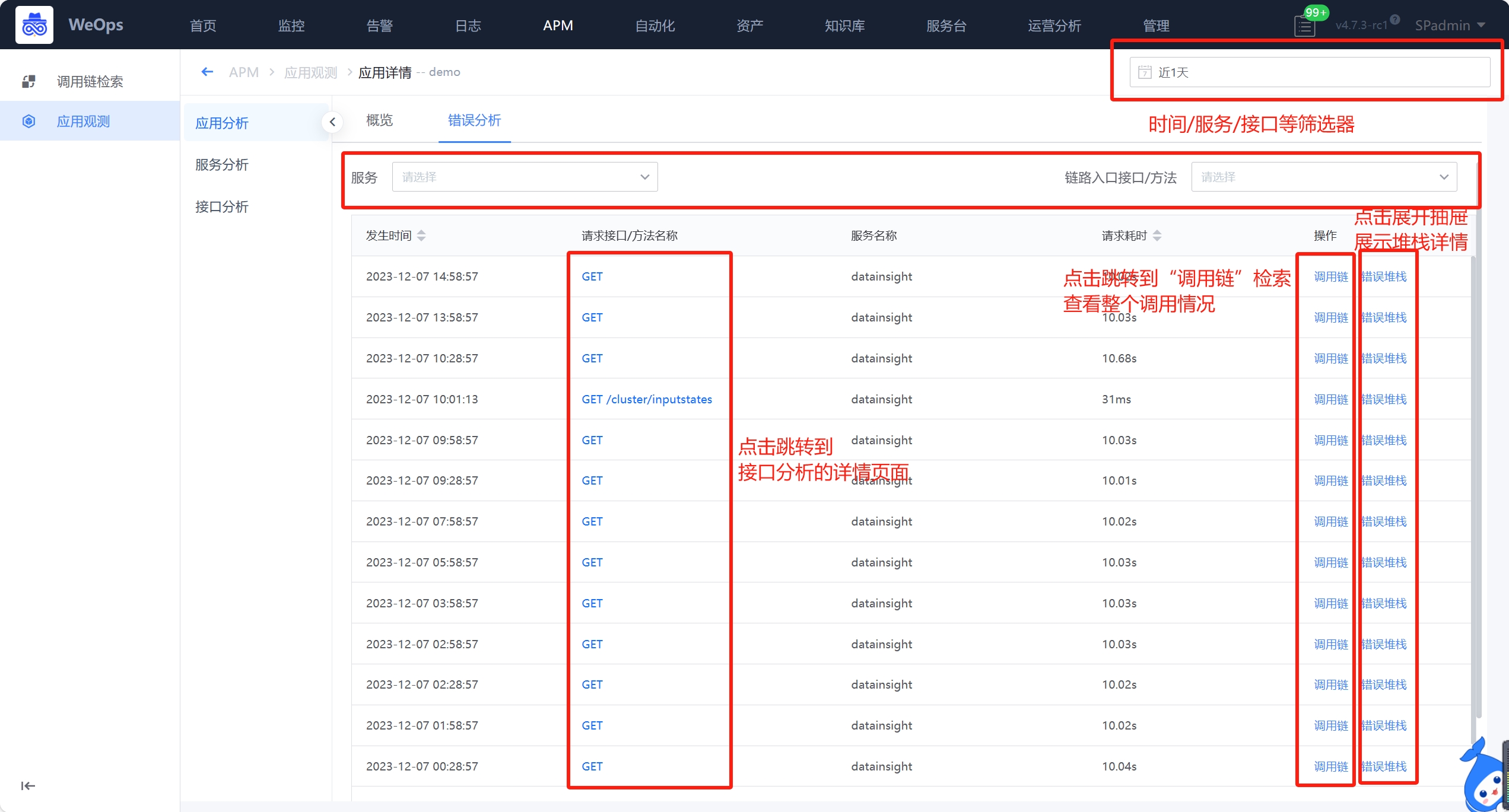
服务分析
- 如下图,展示该应用下所有服务的列表,展开后可以查看服务的详情
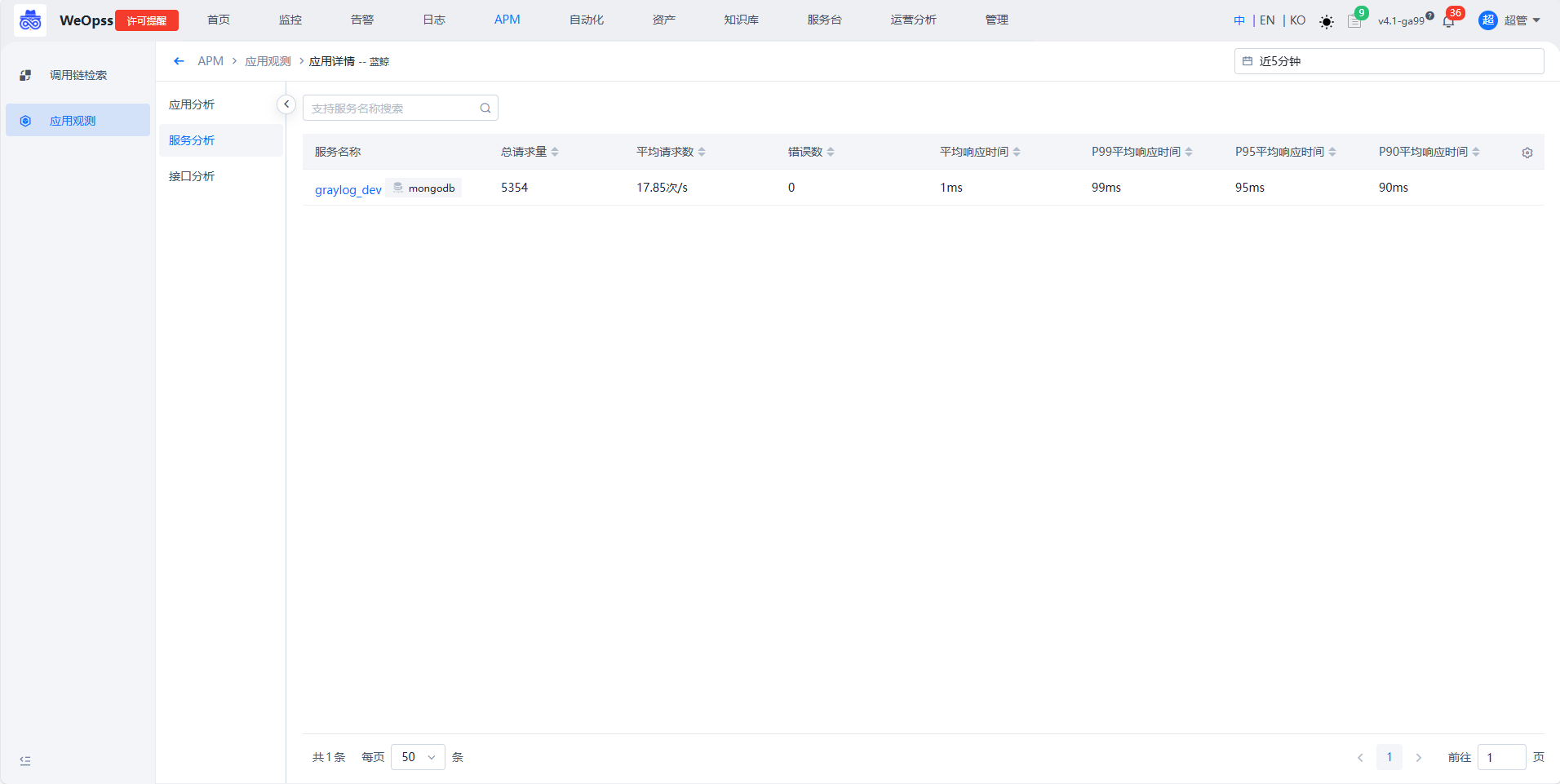
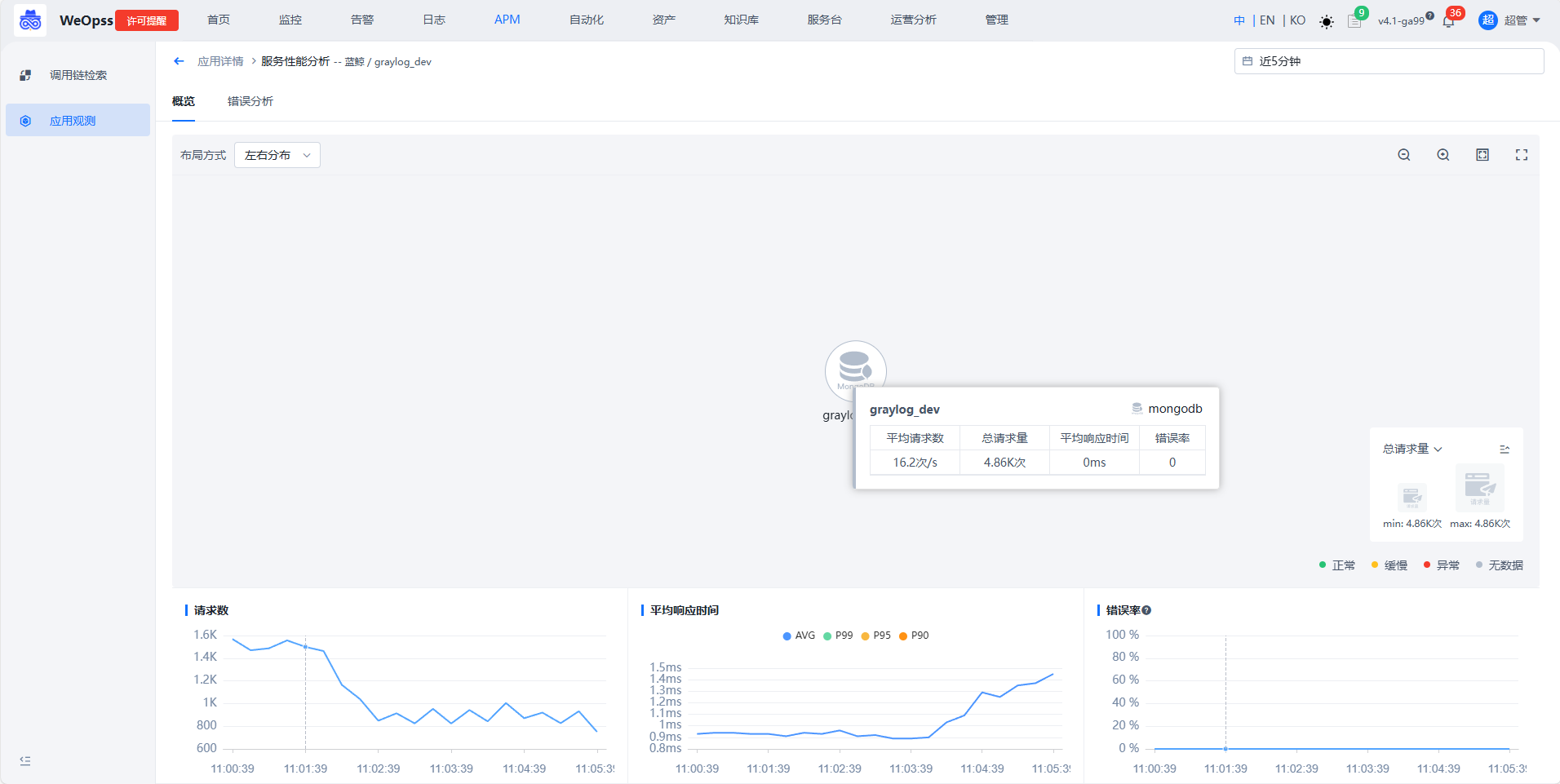
- 如下图,展示该服务相互调用的拓扑关系、关键指标(请求、响应时间、错误率)、错误分析
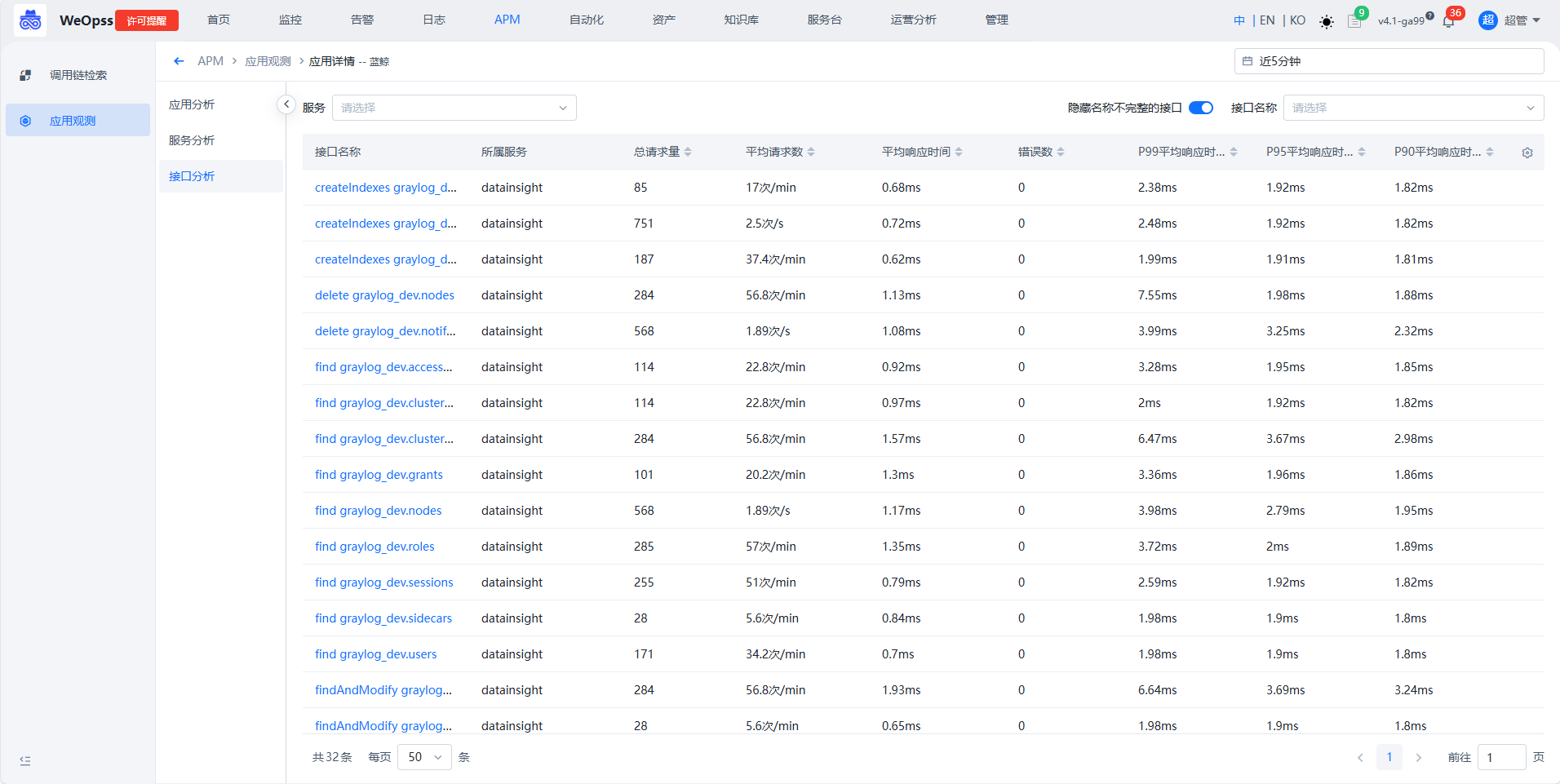
接口分析
- 如下图,展示该应用下所有接口的列表,展开后可以查看接口的详情
- 如下图,展示该接口关键指标(请求、响应时间、错误率)、错误分析
资产数据
应用
如下图,应用管理界面展示了应用以及子应用的相关信息。可点击查看该应用的详情和拓扑信息,进行应用新建和归档操作。

支持应用归档功能,已归档应用可以在“归档列表”中查看,也可以操作“恢复”应用
应用详情页主要展示了该应用的节点信息、变更记录、主机列表等信息,可以进行节点新建的查看和编辑、主机的新增和移动等操作、服务实例的新建和管理。
全文检索
为了让用户快速查找和查看资产的各种字段和属性信息,WeOps提供全文检索能力。全文检索的范围包括所有资产实例的所有字段属性,并且标识搜索到的关键词,可以点击查看资产的详情。
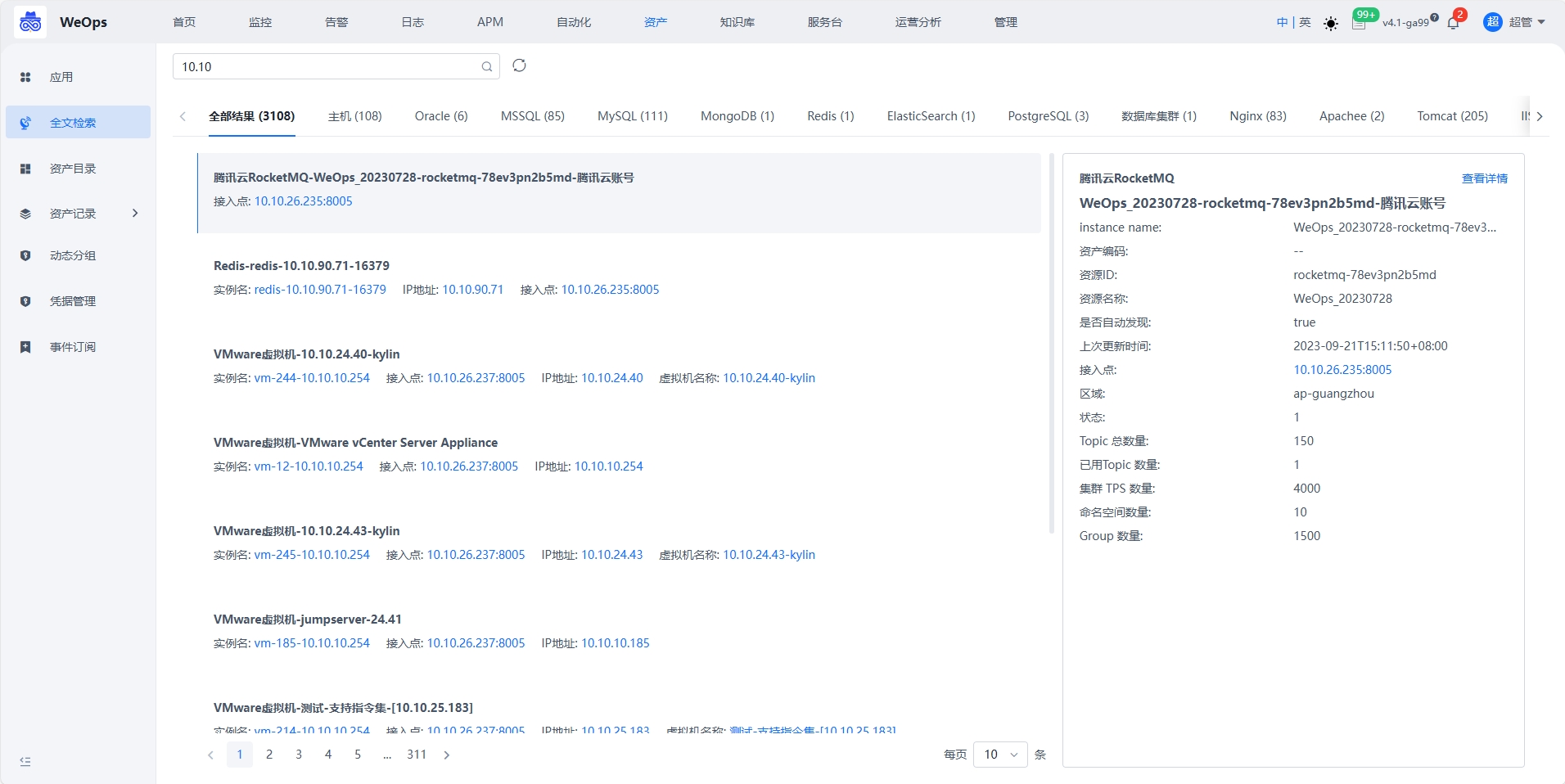
资产目录
运维团队需要全面了解公司所拥有的各种硬件、软件、网络设备等资产情况,并对其进行有效的管理和维护,需要一个总览页进行查看。 以一个简洁的页面呈现CMDB中所有的资产信息,如服务器、存储设备、网络设备等。用户可以通过该目录快速了解公司所拥有的各类资产情况和数量,并支持跳转到对应资产详细列表页面。
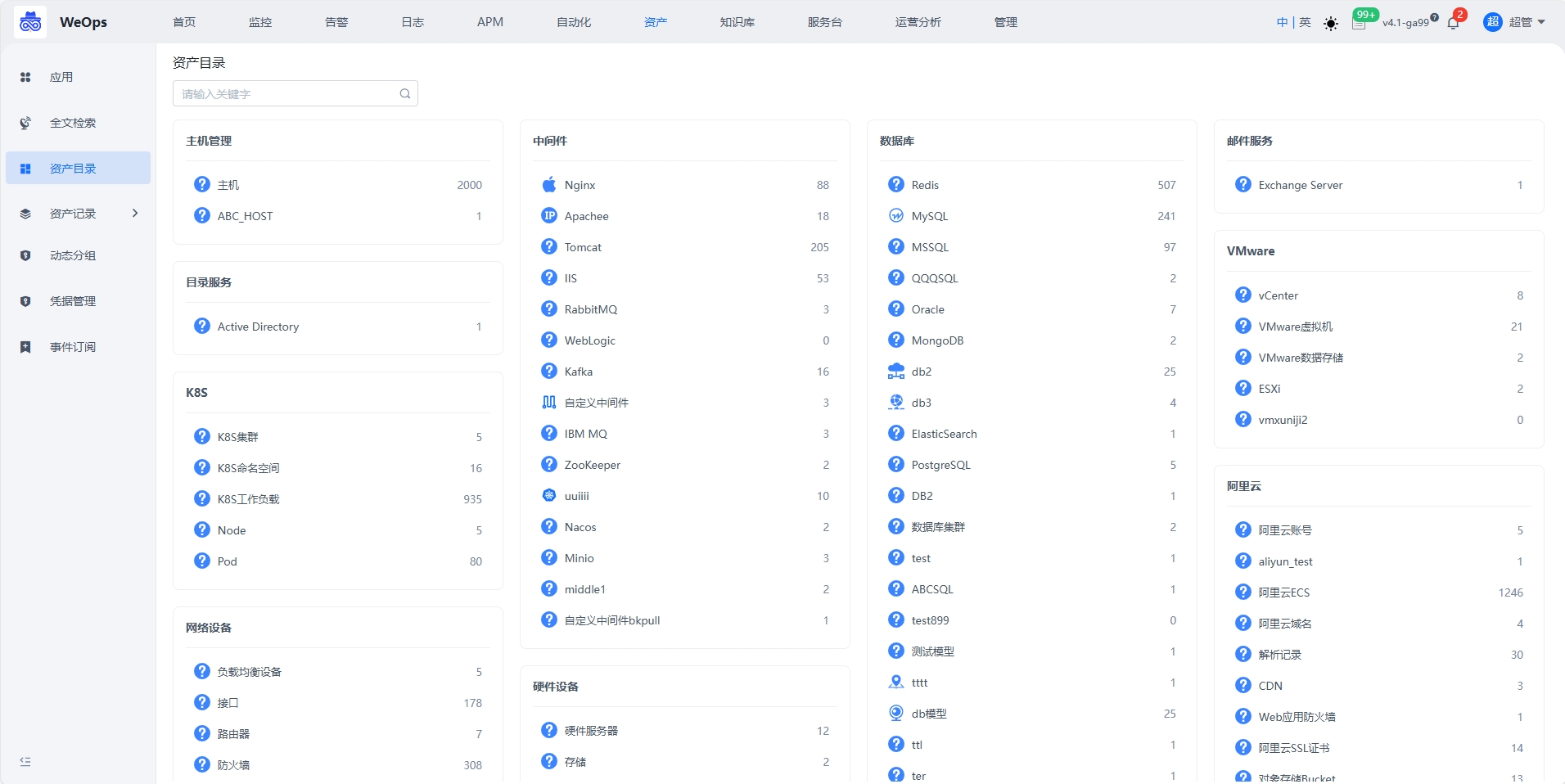
资产记录
主机
如下图,资产记录中的主机展示了所有的主机信息,可进行新建、批量修改和批量删除、导出,支持主机的远程连接。
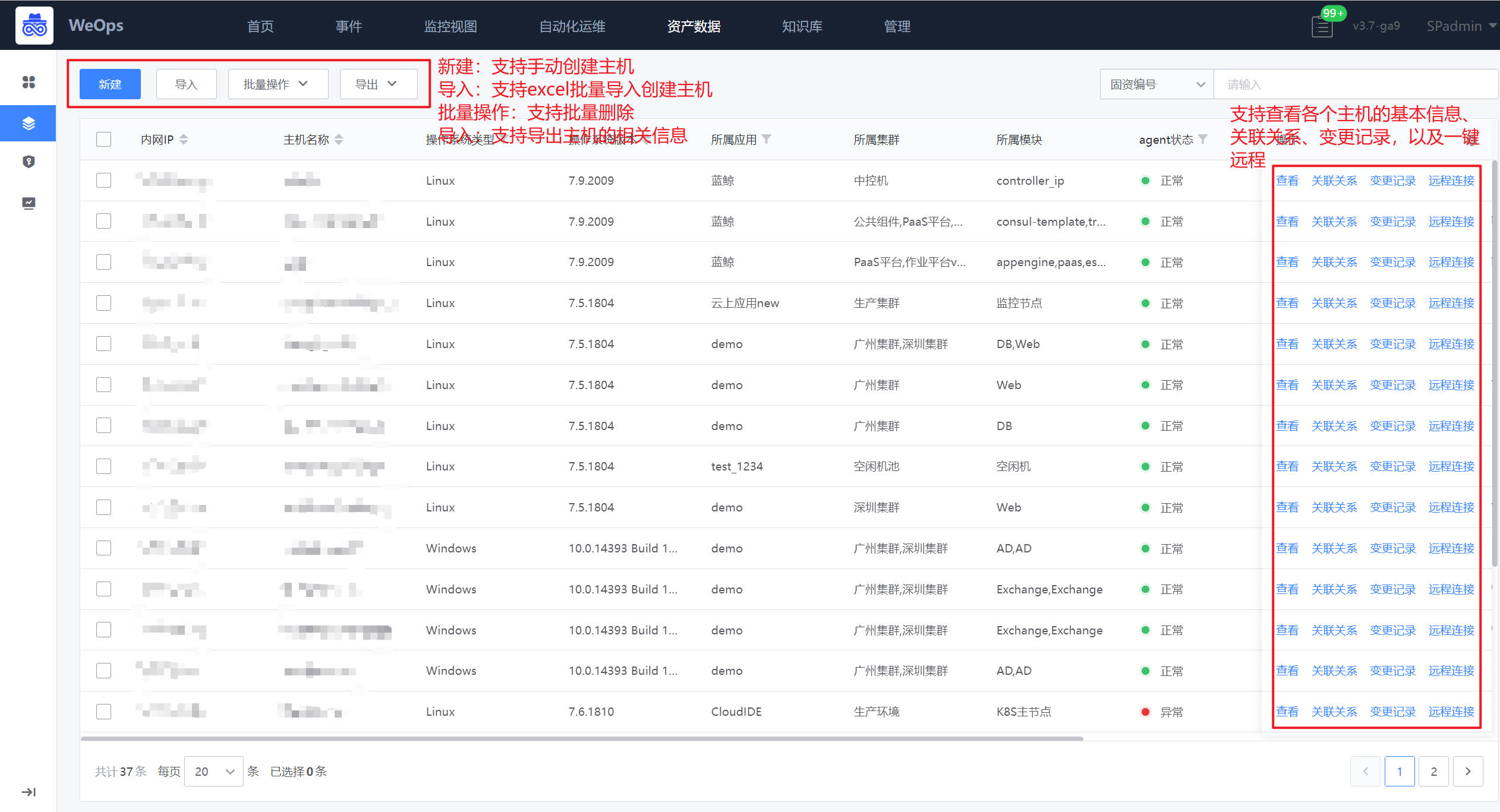
- 详细信息:点击可查看该主机的详细信息。

- 服务实例preview:展示了该主机下的服务实例和对应进程的信息。

- 关联信息:以列表和拓扑图两种形式呈现与该主机相关的实例信息,列表和拓扑图均可点击查看关联实例的详情信息。

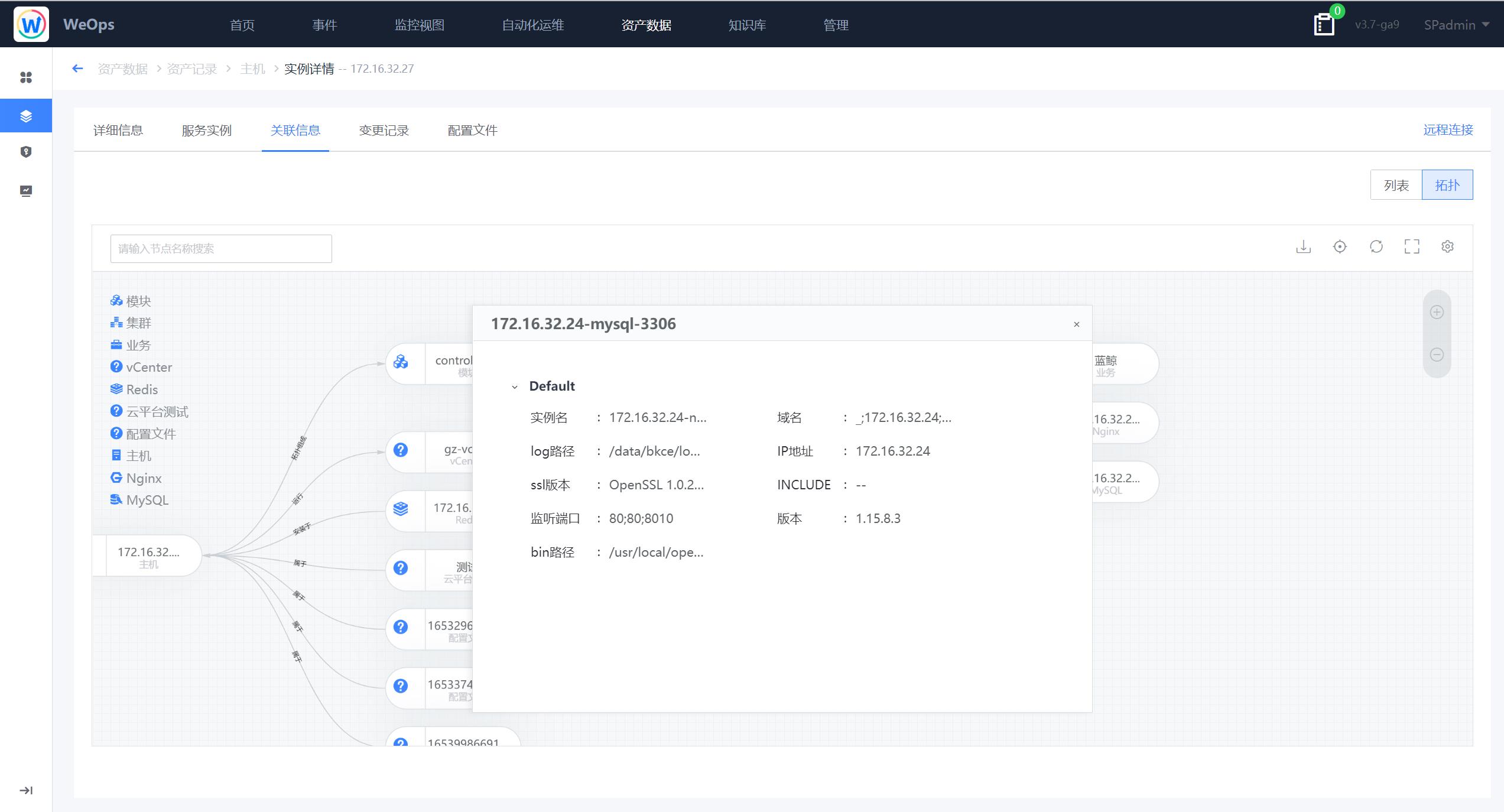
- 变更记录:可查看该主机的变更记录,可手动增加变更记录。
- 资产日志:当在“资产管理-数据关联”中配置好资产和日志的匹配关联后,可以在此处查看该资产的相关日志信息

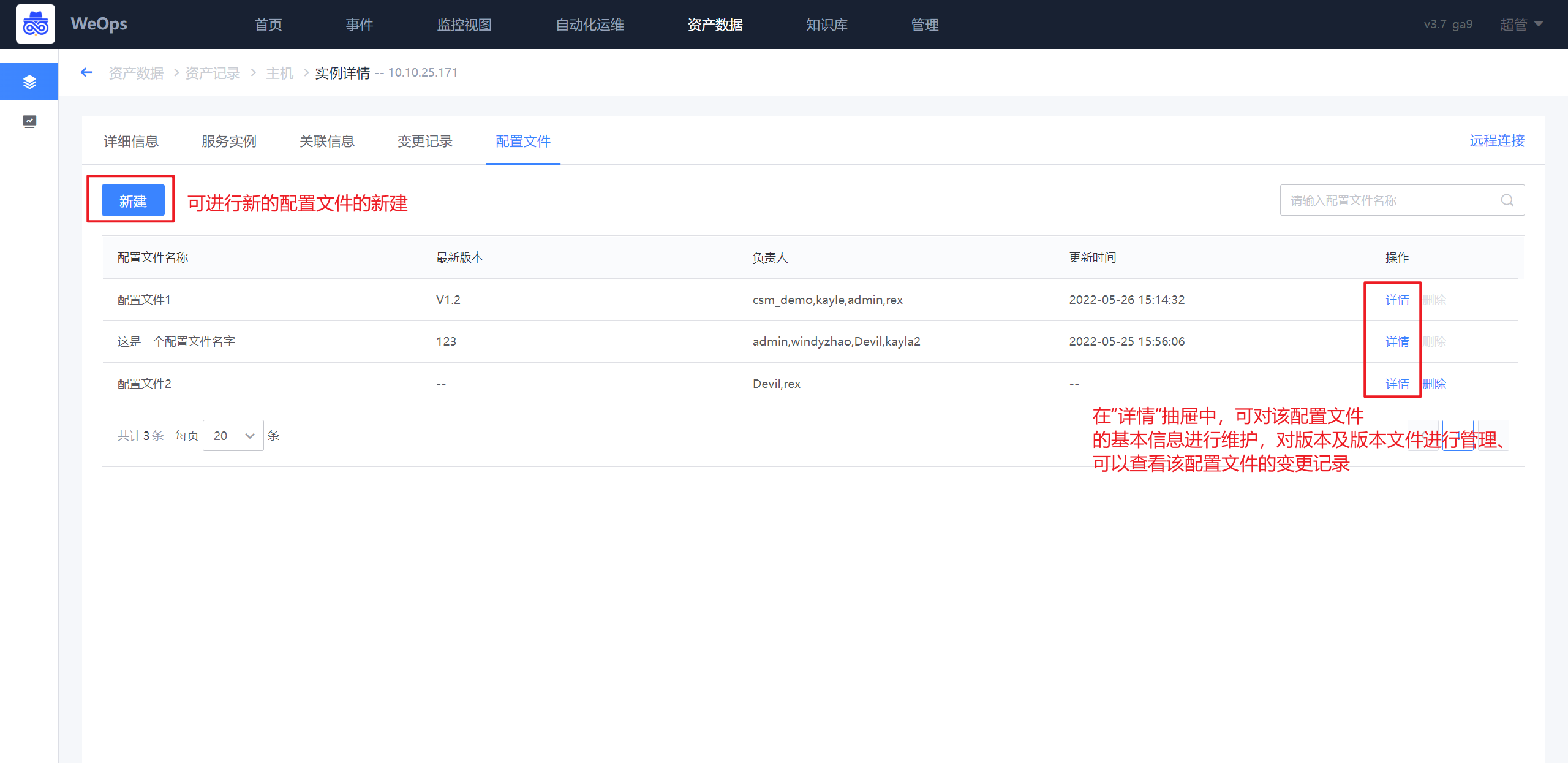
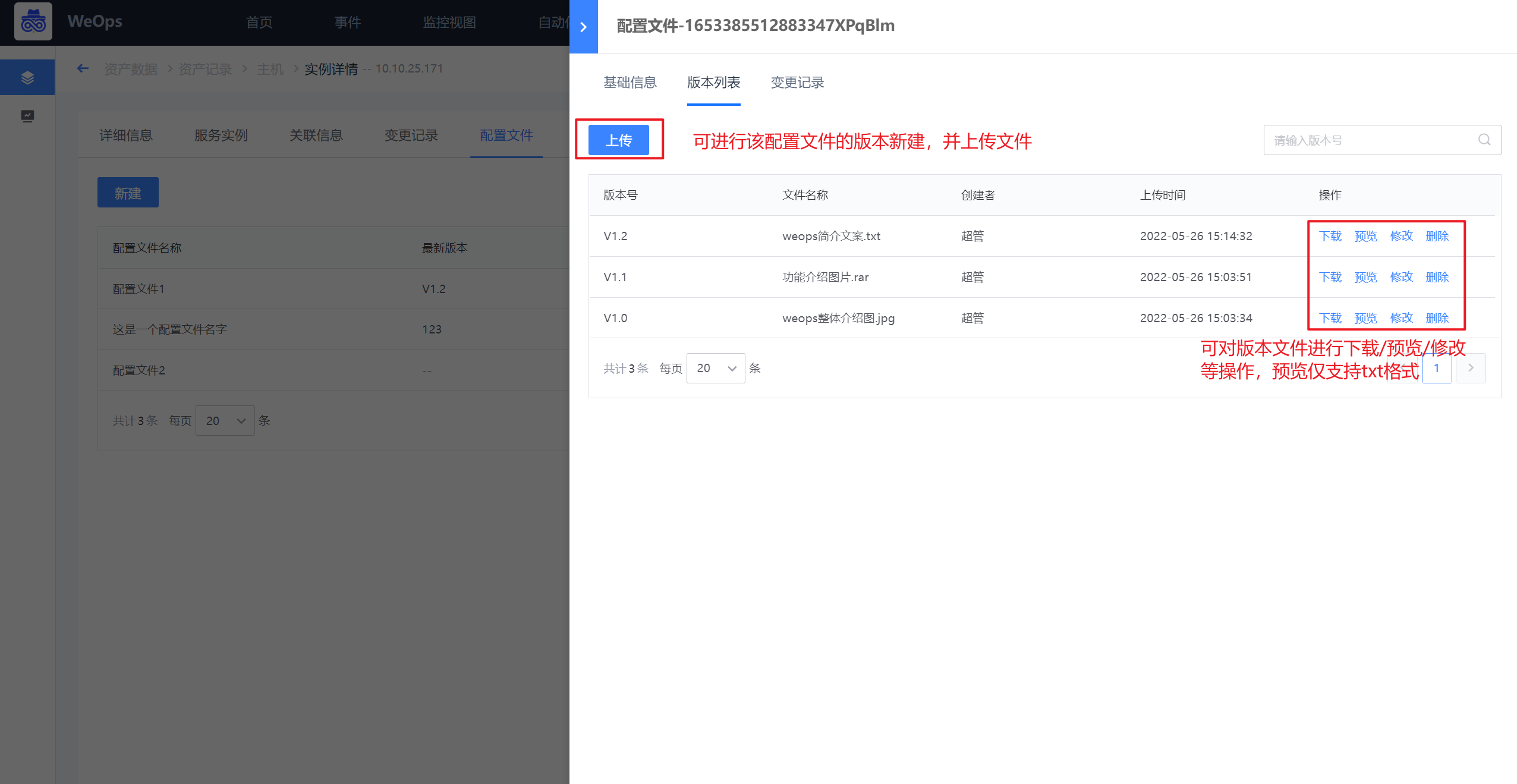
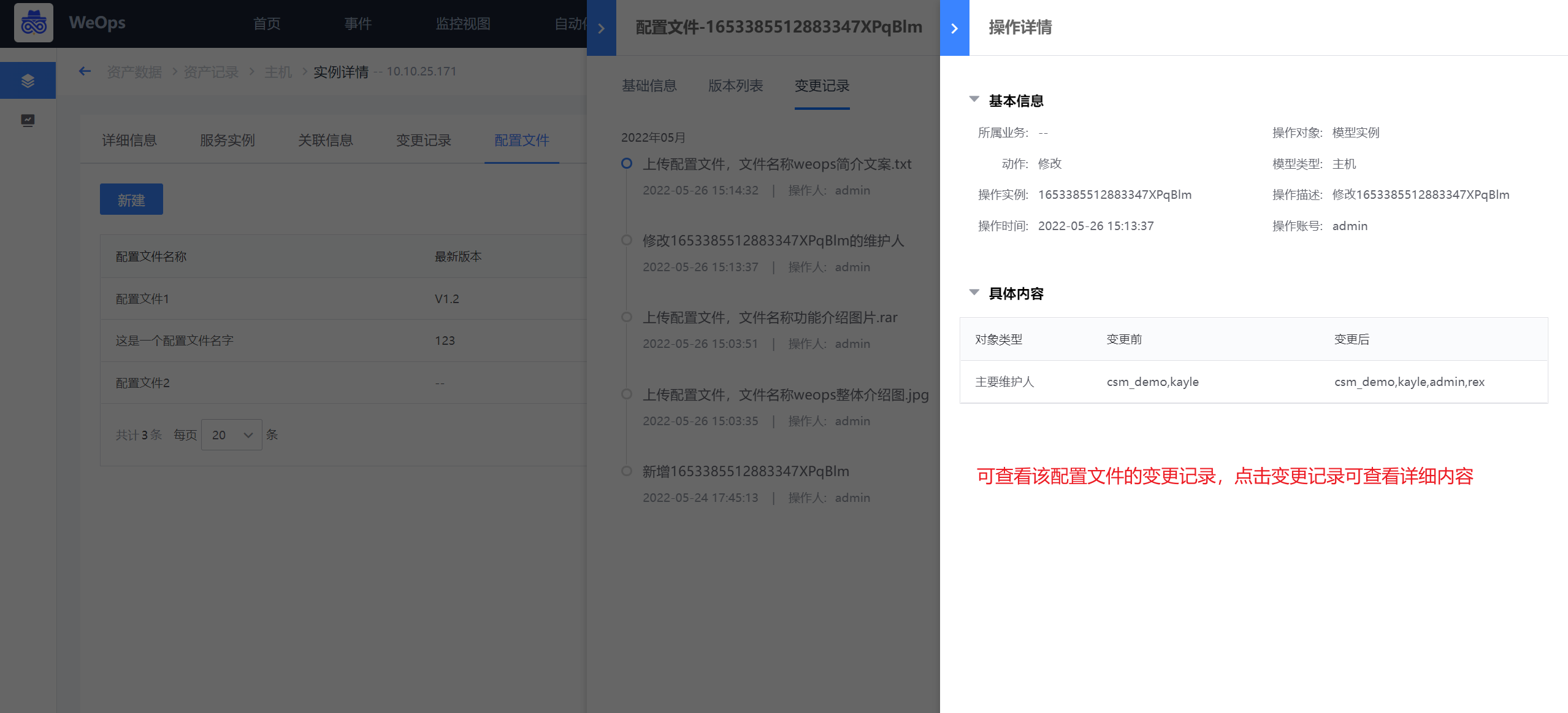
- 配置文件preview:如下图,可对配置文件进行管理,包括基本信息、版本管理(可进行各个版本文件的上传/下载/预览等操作)、变更记录。
- 远程连接:“WeOps-资产记录-主机”提供了Windows和linux主机的远程连接入口,可点击进行主机的远程连接
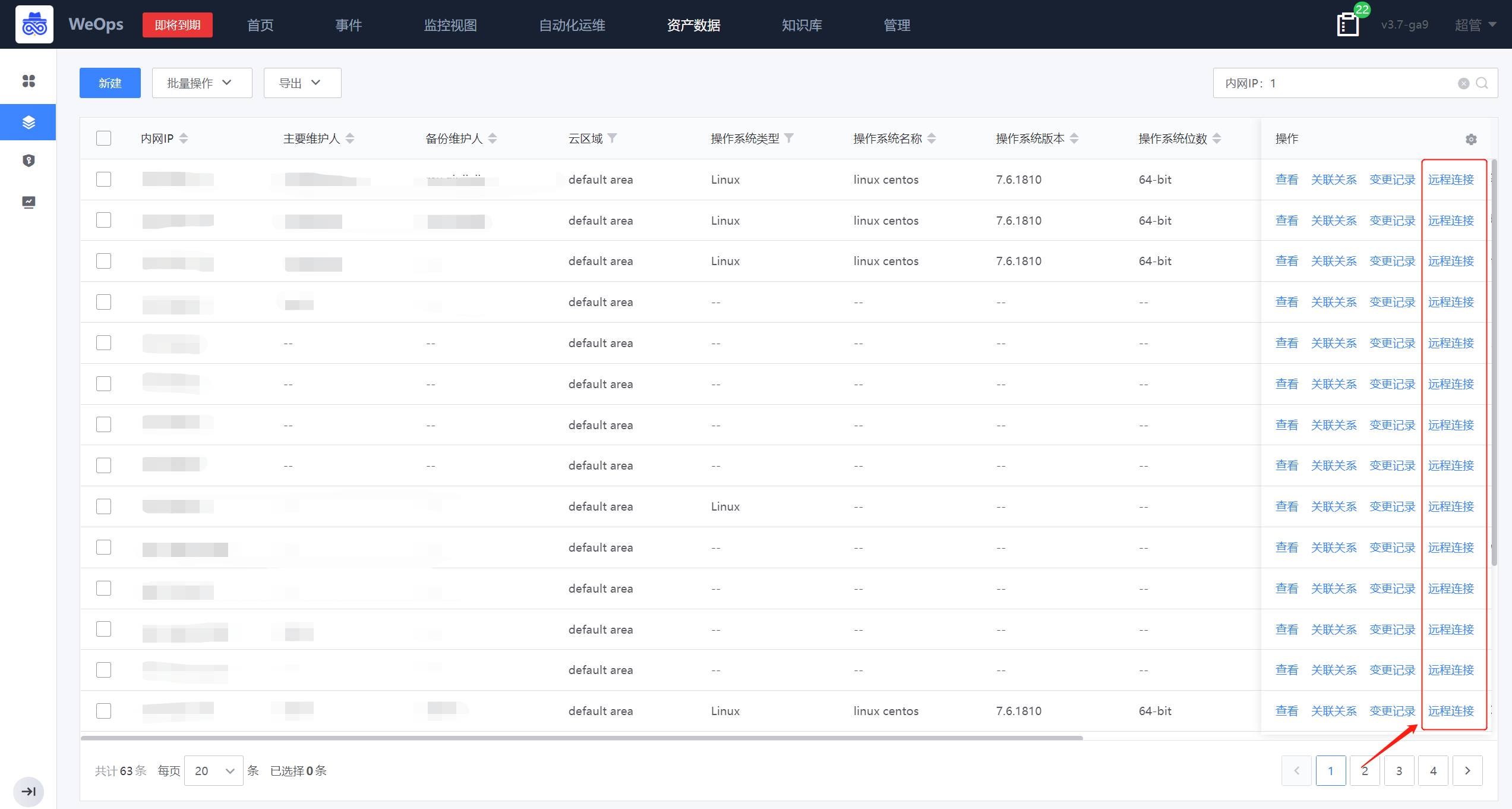
- 远程连接过程中可以选择“手动添加凭据”和“使用已有凭据”两类,Windows服务器可以选择分辨率,默认分辨率为1920*1080
- 手动添加凭据:支持RDP、SSH、VNC三类协议,Windows服务器默认RDP协议、默认远程端口为3389、默认用户名administrator;linux服务器默认使用SSH协议、默认远程端口为22、默认用户名root。
- 使用ssh协议时,要求对端的ssh服务器运行使用rsa密钥,如果ssh版本高于8,需将HostKeyAlgorithms +ssh-rsa添加到/etc/ssh/sshd_config中
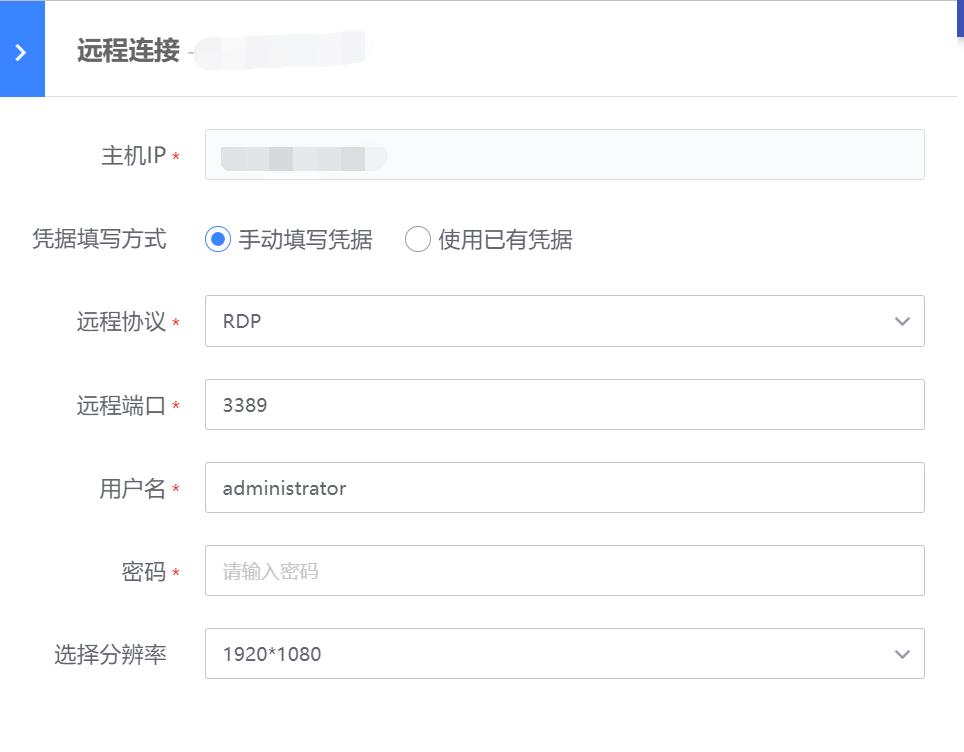
- 使用已有凭据:可以使用之前已经保存的凭据进行连接。
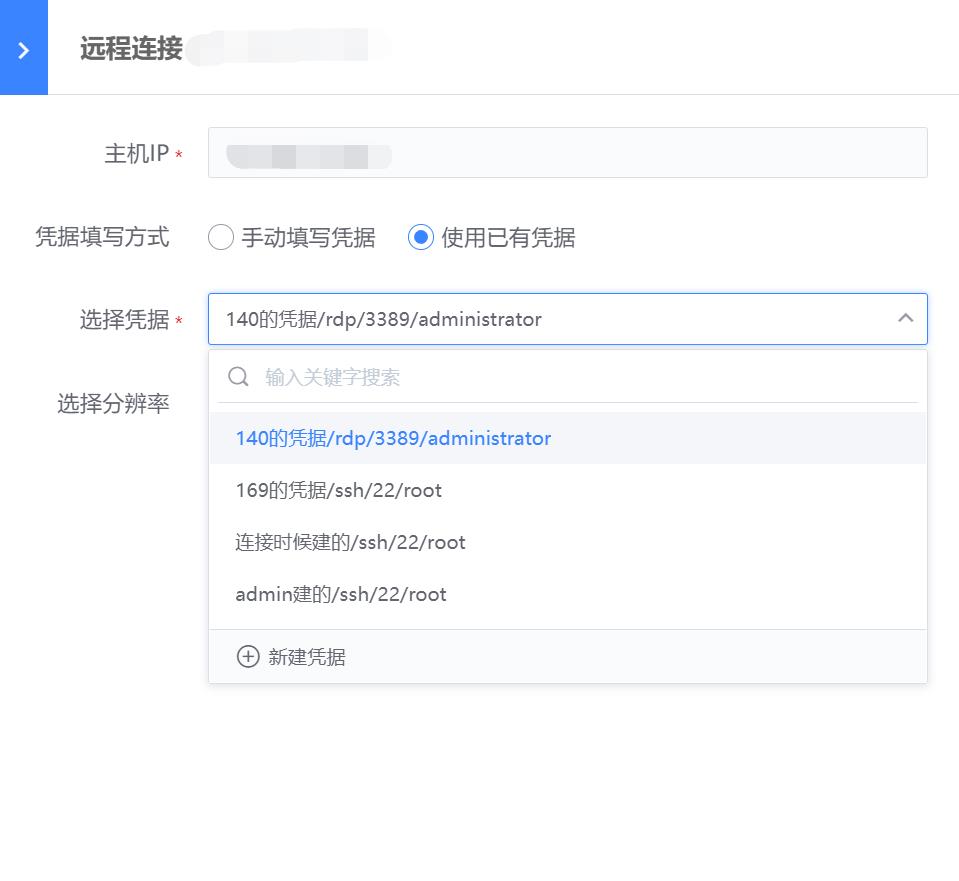
- 远程连接的服务器支持全屏放大和文件上传:Windows默认system帐号,Linux默认root帐号;Windows文件存放目录“c:\windows\temp”,Linux文件存放目录“/tmp”;

数据库
如下图,“资产记录-数据库”展示了所有类型的数据库列表的基础信息(包括所属应用)、关联关系、变更记录、配置文件。
K8S
如下图,“资产记录-K8S”展示了内置的K8S相关模型,包括“K8S集群”、“K8S命名空间”、“K8S工作负载”、“Node”、“Pod”。
创建K8S集群信息,设置“自动发现”,即可采集该K8S下的K8S命名空间、K8S工作负载、Node、Pod相关信息,并形成关联拓扑。

网络设备
如下图,“资产记录-网络设备”展示了内置的网络设备的相关模型,包括“路由器”、“防火墙”、“负载均衡”、“交换机”。展示了各类网络设备手动/自动发现采集的相关信息。

云平台
如下图,“资产记录-VMware/阿里云/腾讯云”展示了内置的云平台的相关模型,VMware包括了“vCenter”、“虚拟机”、“ESXI”、“数据存储”,阿里云包括了“阿里云账号”、“ECS”,腾讯云包括了“腾讯云账号”、“CVM”等。分别展示了云平台各个对象的手动/自动发现和采集的相关信息。
其他动态tab
如下图,“资产记录-其他动态tab”根据资产模型的分组情况进行动态展示,展示了中间件等其他实例类型的基础信息(包括所属应用)、关联关系、变更记录和配置文件。
机柜视图
为了直观的展示机柜内设备的布局和状态,新增机房视图,用于各类IT设备的集中管理和展示。
资产设置
在资产记录中已经内置常用资产模型“数据中心-机房-机柜-设备(网络设备/硬件设备等)”,需要在资产记录的对应位置创建资产实例、填写位置信息并创建关联,步骤如下:
1、创建数据中心实例并填写信息(如“深圳数据中心”);
2、创建机房实例,并且关联到数据中心。比如创建“2号机房”,并且创建它与“深圳数据中心”的关联;
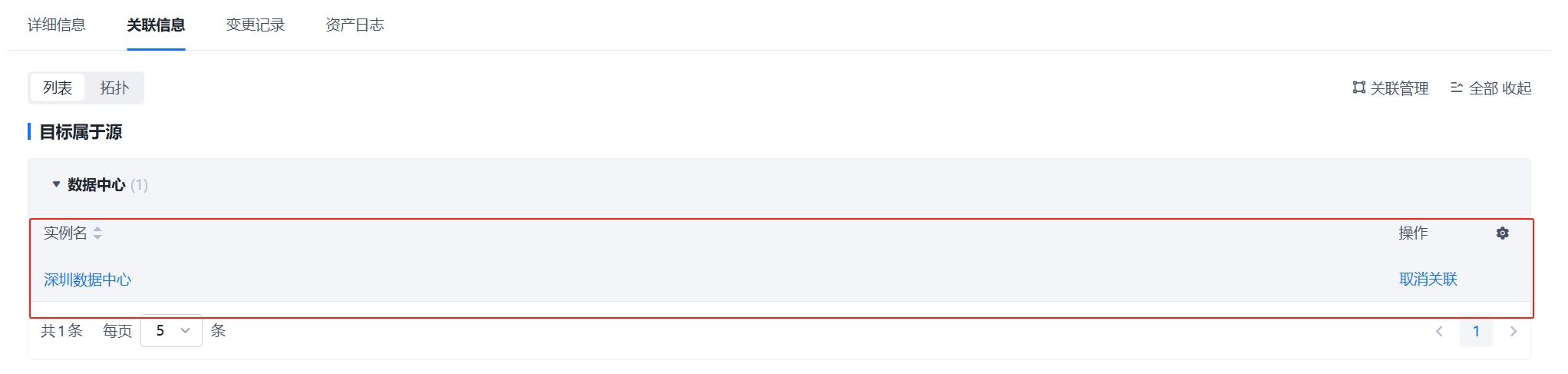
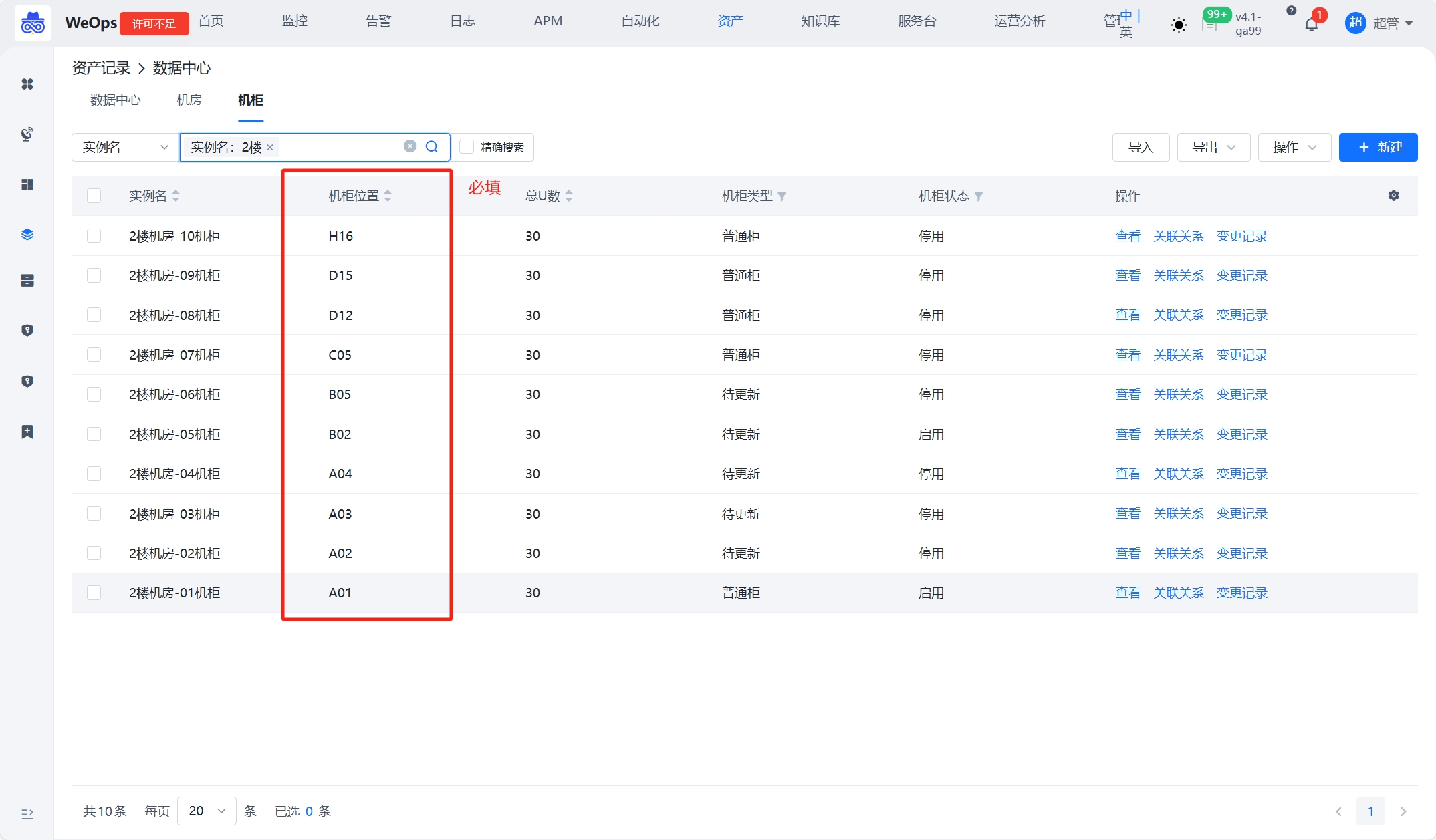
3、创建机柜实例,必须填写“机柜位置”字段,并且创建机柜与机房的关联关系。比如2楼机房放置了10个机柜,需要填写机柜的基本信息,必填“机柜位置”(机柜位置的填写标准格式为“A01”、“B11”等),创建机柜与机房的关联。通过机柜的位置和关联关系,可在机房视图中渲染出位置;
4、创建设备实例,支持“网络设备”和“硬件设备”分组下的实例,放置在对应机柜中,设备需要填写开始U位和结束U位,并创建与机柜的关联,可以渲染出机柜视图。
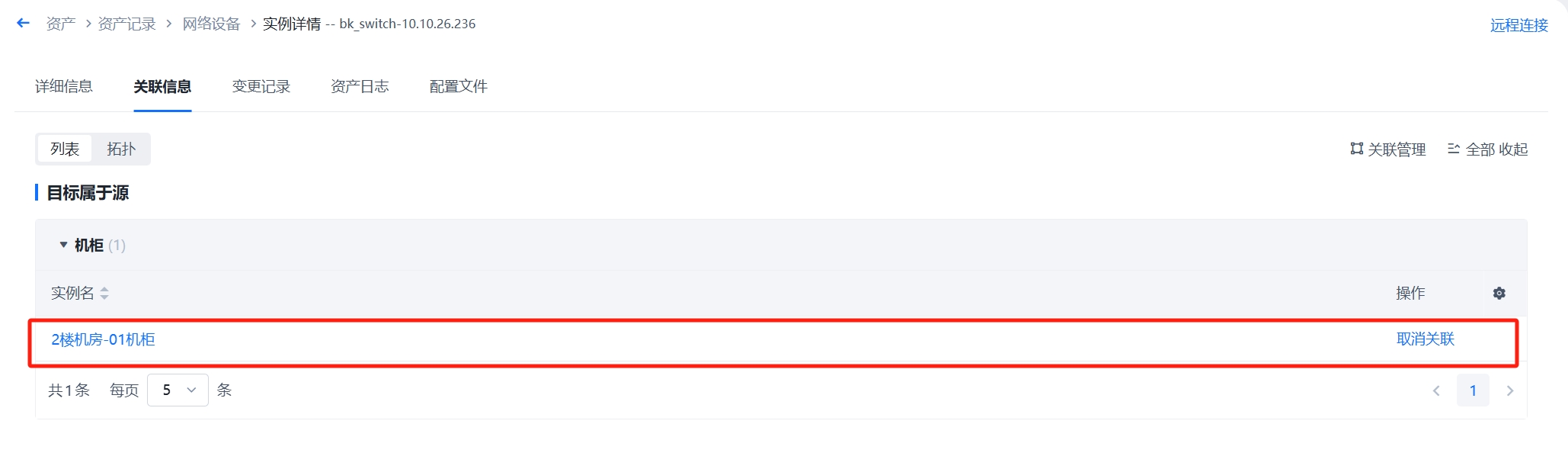
机房视图
根据“机房-机柜”关联和填写机柜的位置,在视图中按照机柜的位置和类型展示。
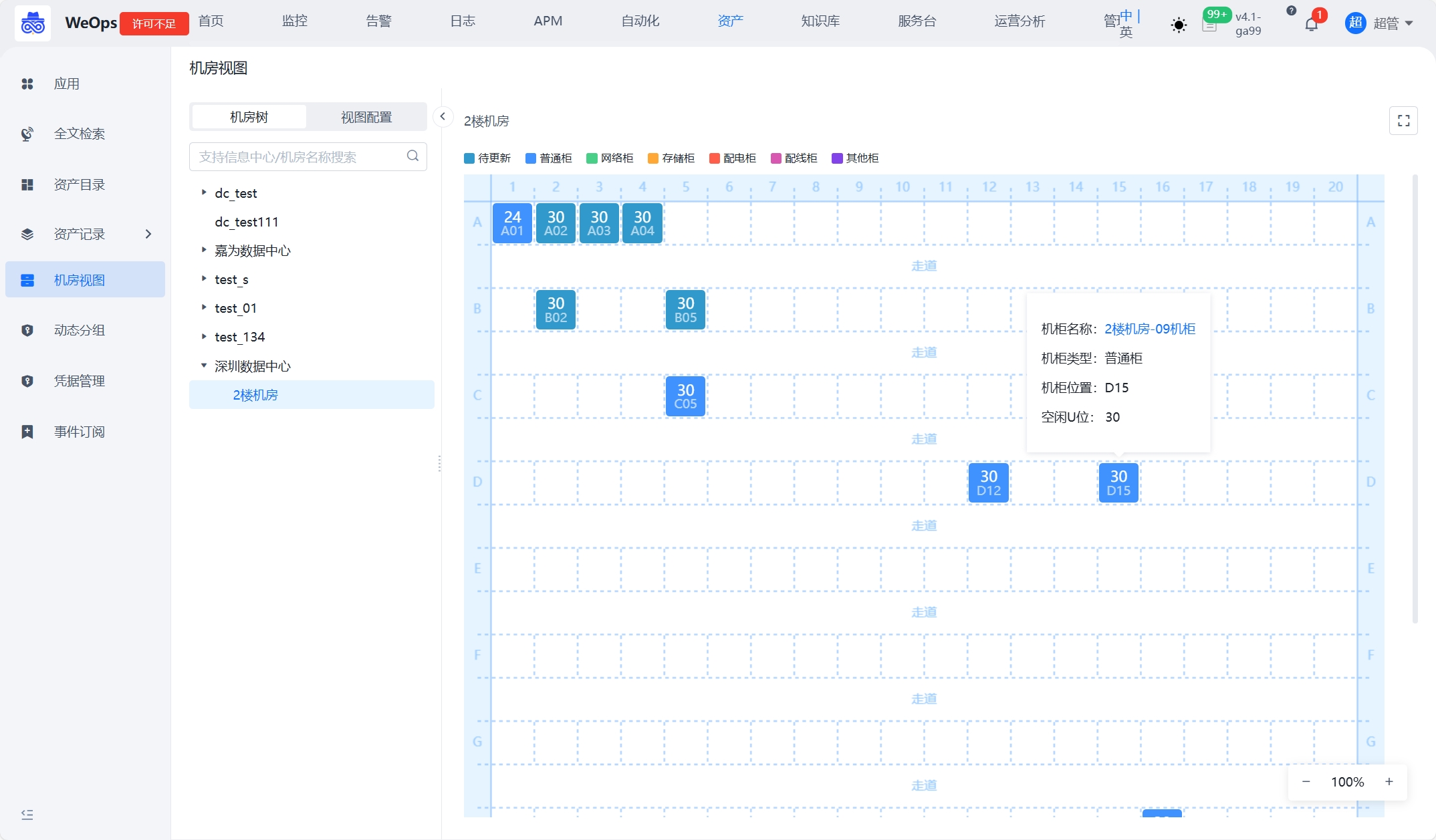
机柜视图
根据“机柜-设备”关联和设备的开始U位和结束U位,在机柜视图中展示设备的位置和信息。
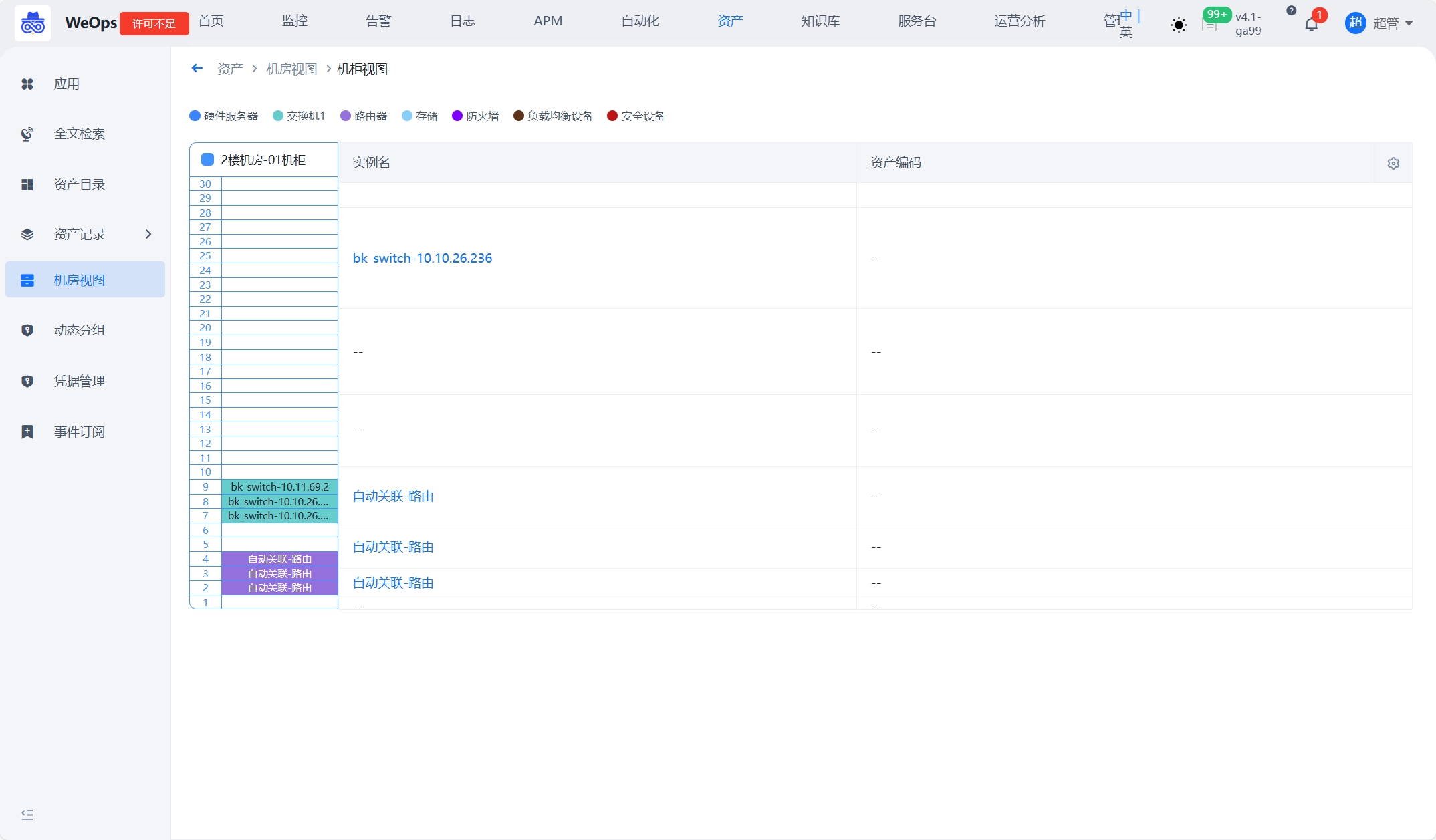
凭据管理
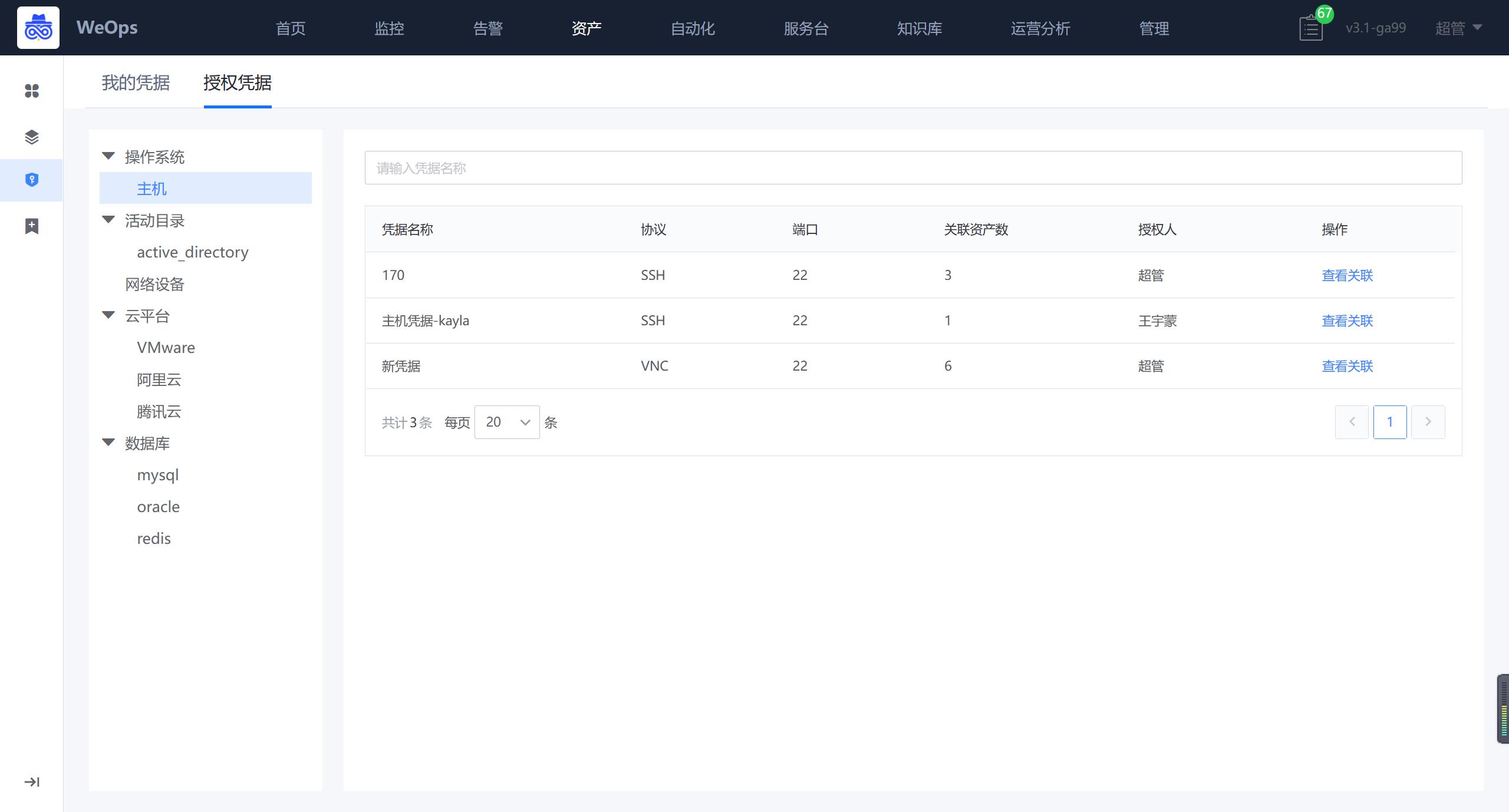
如下图,“资产数据-凭据管理”主要用于存放主机/AD/网络设备/数据库/云平台等资产的凭据,可进行凭据的增删改查和授权,包括如下两个模块:我的凭据、凭据授权
- 我的凭据:支持主机/AD/网络设备/数据库/云平台凭据的新建和操作,主机支持SSH/RDP/VNC协议,AD支持LDAP/LDAPS协议,凭据新建完成后需要关联资产,被关联的资产才可以使用该凭据。
- 授权凭据:别人授权给我的凭据,我可以在对应资产使用已经授权给我的凭据,也可以查看这个凭据关联的资产情况
凭据的使用场景
- 远程连接:“告警-主机”/“资产记录-主机”支持使用主机的凭据进行远程连接。
- 自动化工单流程:数据库/AD等凭据支持在内置的AD和数据库工单流程中选择使用
- 自动发现:网络设备和云平台的凭据支持在设置自动发现任务时选择使用
- 监控采集:网络设备和云平台的凭据支持在设置监控采集任务时选择使用
动态分组
- 当资产在变动的时候(增删改),对应的监控和订阅策略生效的对象支持动态变化,动态更新,适用于所有的资产类型

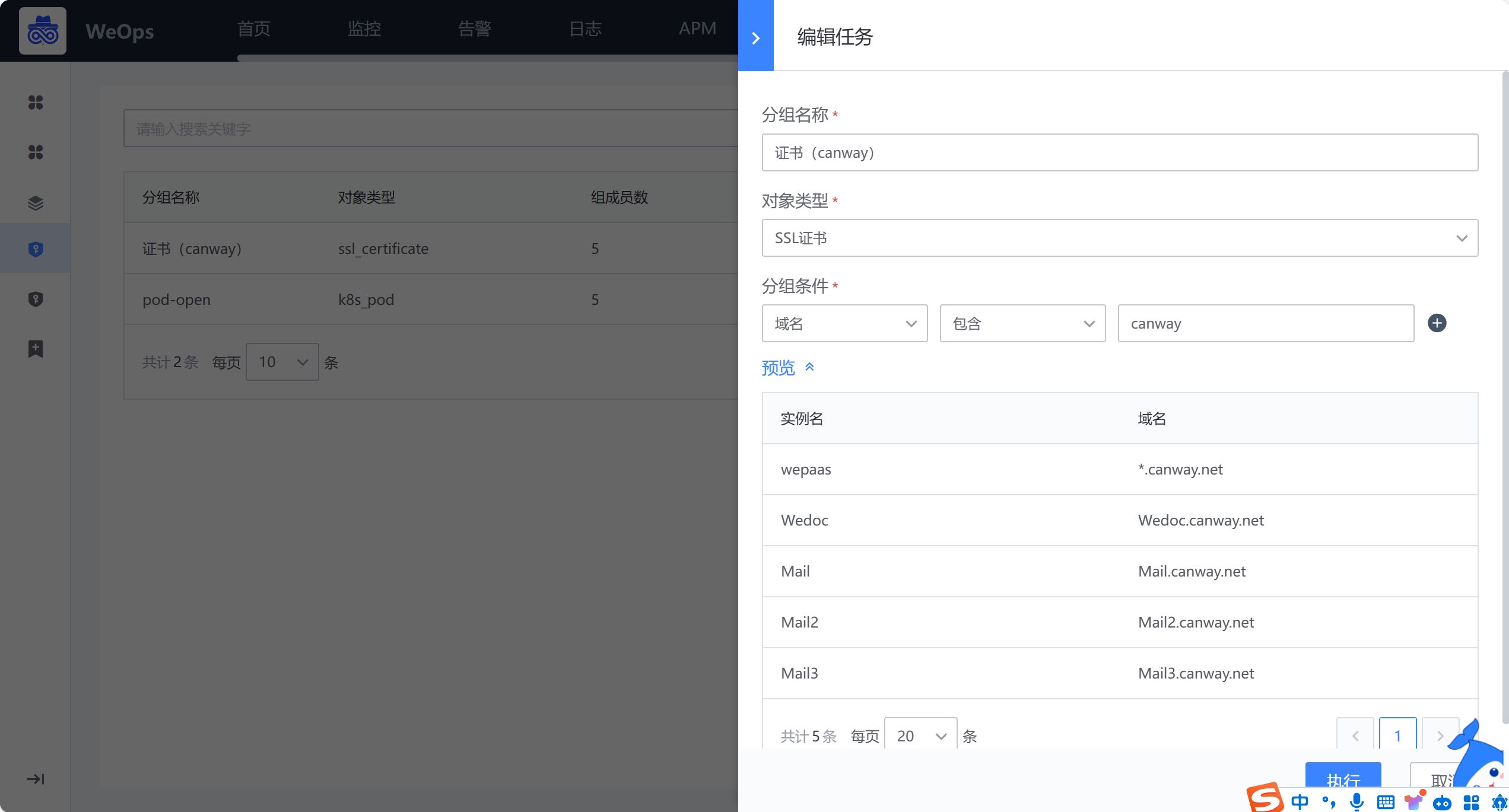
- 当动态分组设置完成后,可以用于事件订阅和监控策略的创建。
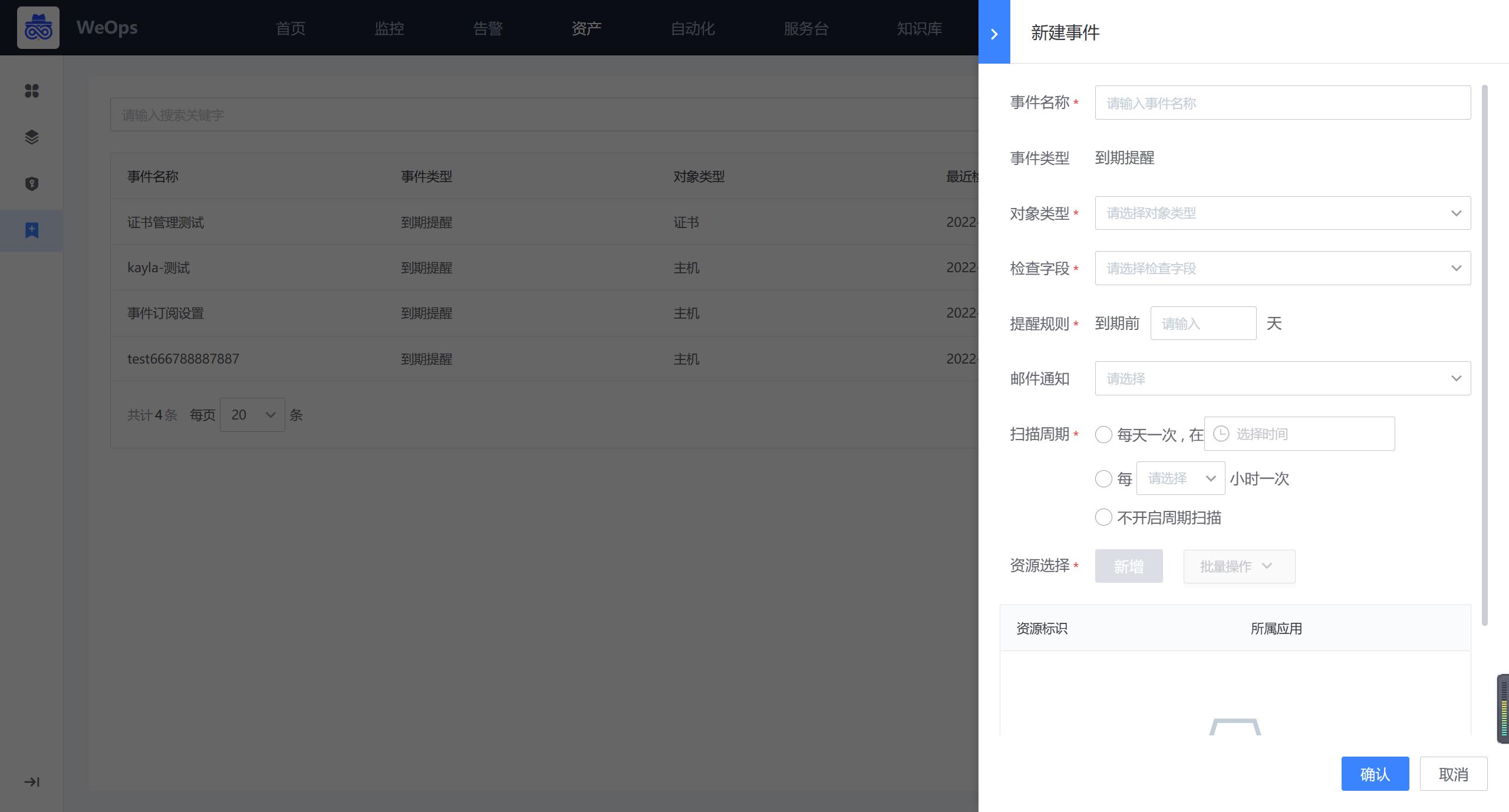
事件订阅
如下图,支持对资产记录中资产的到期情况进行订阅,可设置提醒的资产和字段,并设置到期提醒的规则。

自动化运维
运维工具
“自动化运维-运维工具”的类型分为操作系统工具和网络设备工具两类
操作系统工具
如下图,操作系统工具具展示了WeOps内置/自定义的常用的操作系统的脚本工具,支持脚本的快速执行。
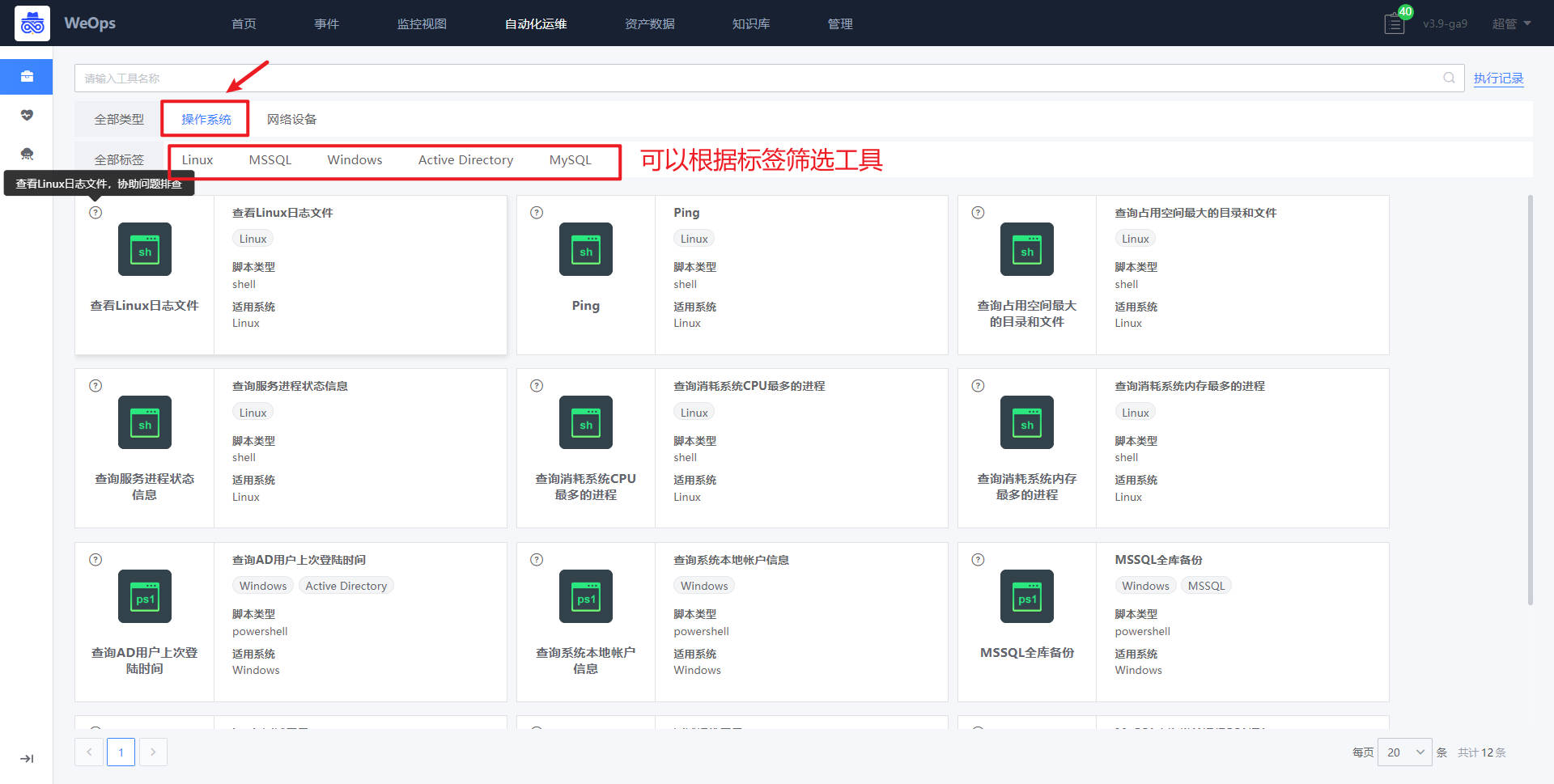
- 这里以“查询消耗系统CPU最多的进程”为例,点击脚本工具进入使用界面,选择对应的主机,输入参数,点击“执行”按钮,即可进行该脚本工具的使用。

- 如下图,执行完成后,可以再查看操作结果
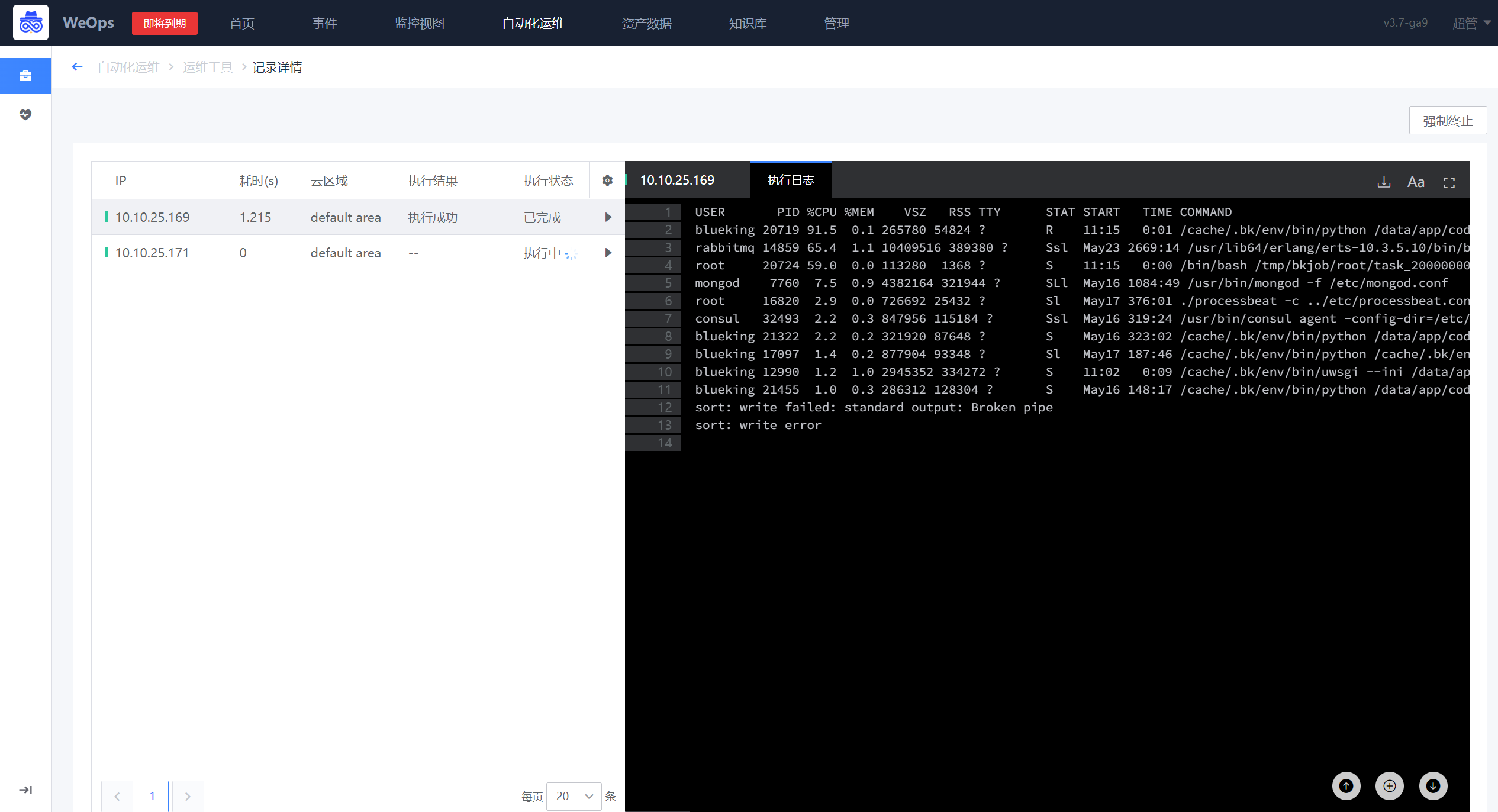
脚本工具支持自定义,自定义方式详见“操作手册-3、其他配置-工具管理”
网络设备工具
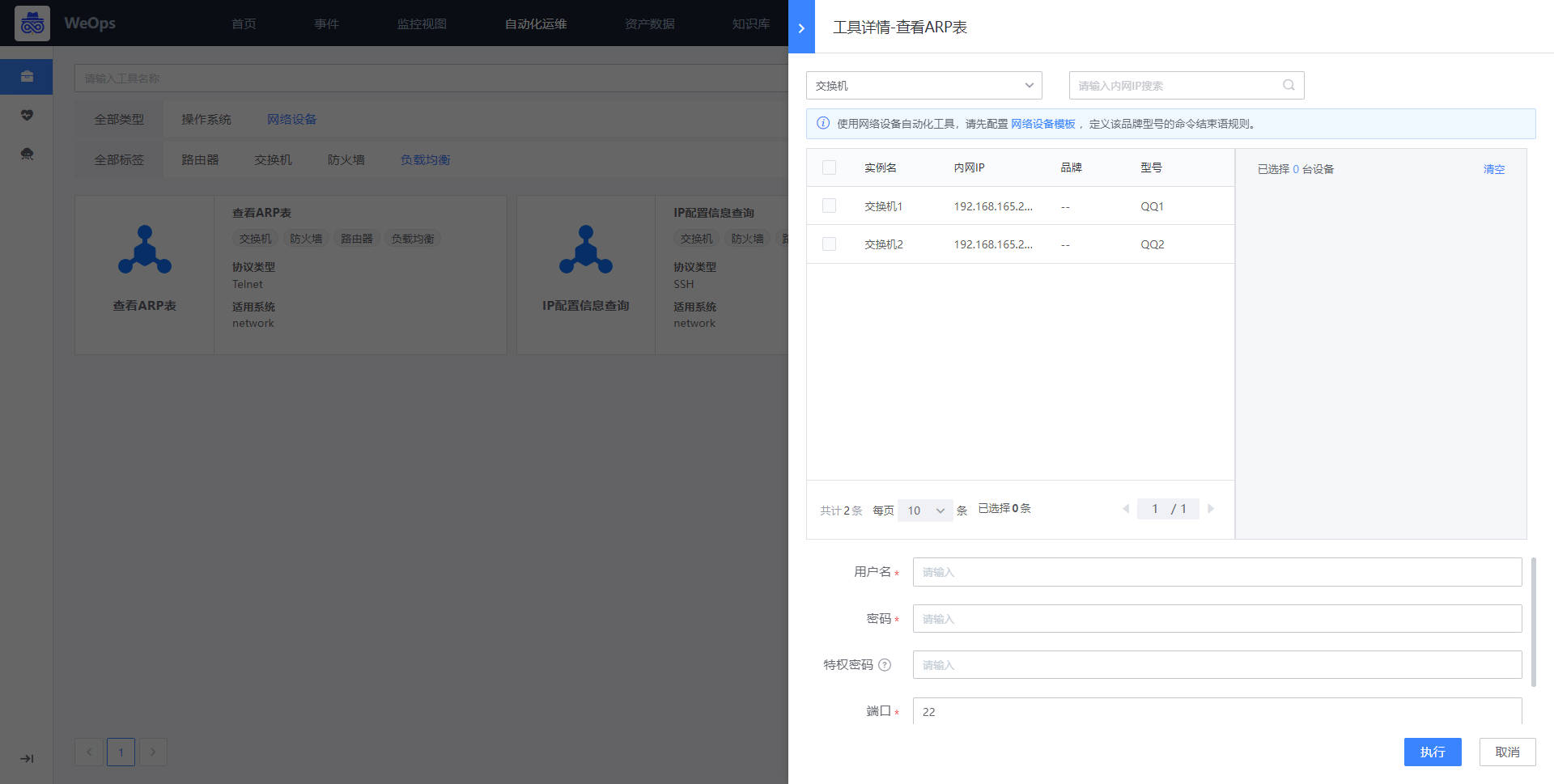
如下图,WeOps支持网络设备的脚本工具的执行,展示了内置/自定义的脚本工具,可以快速执行。

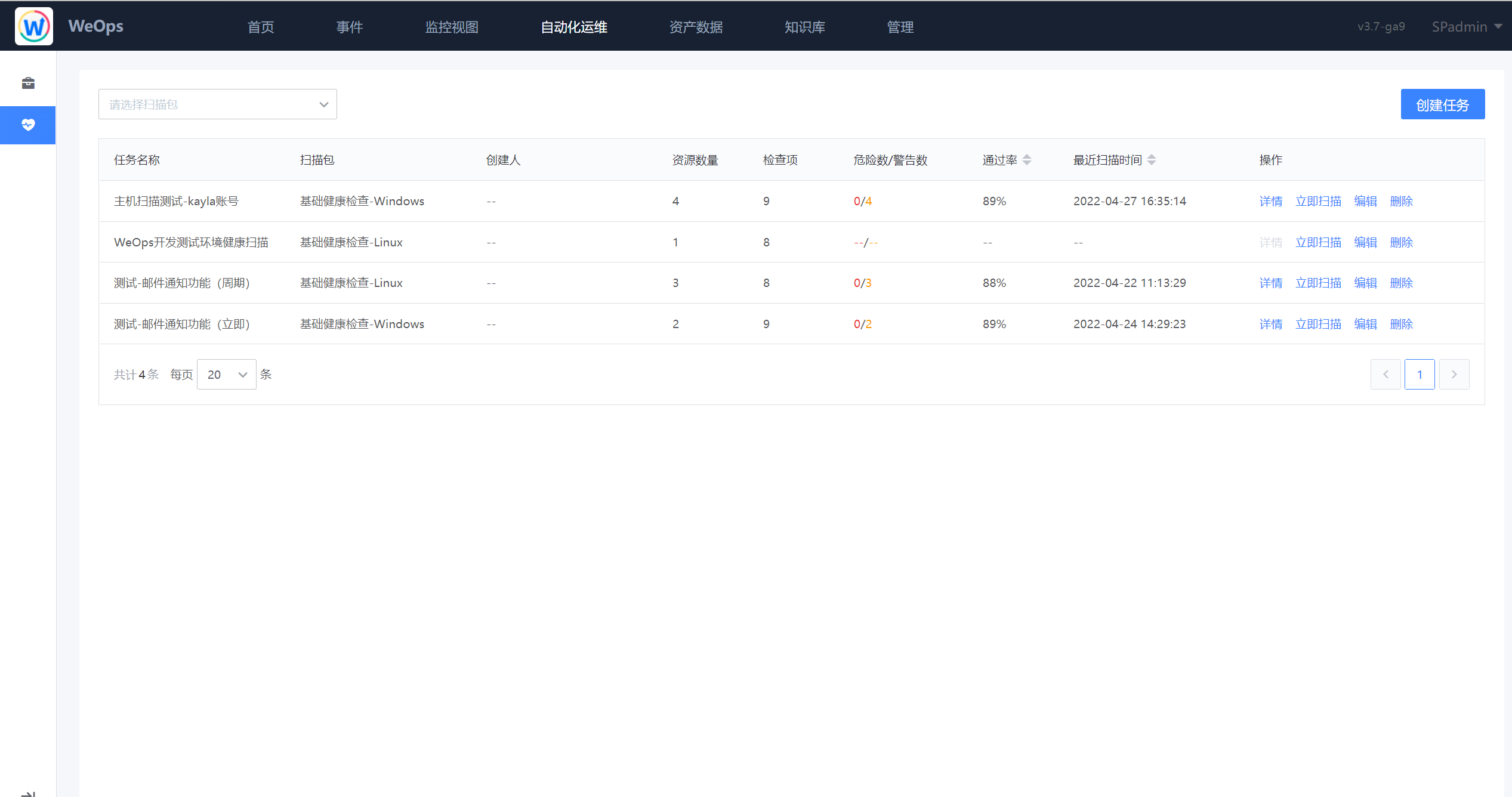
健康扫描
如下图,健康扫描以扫描包为主题,以任务的形式对指定的实例进行专题扫描,下图为健康扫描的任务页面,展示了创建的各个页面的基础信息以及扫描情况。
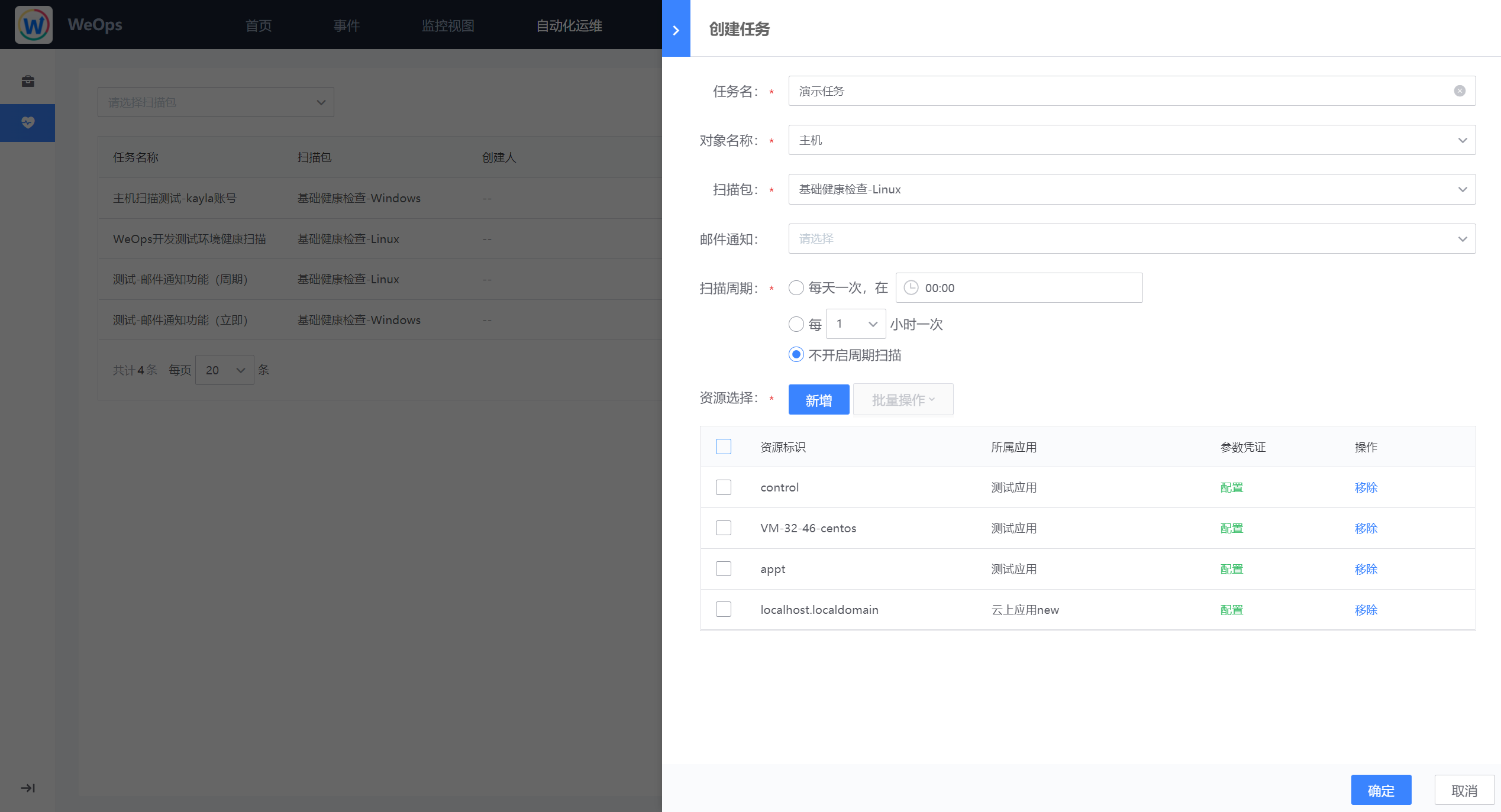
- 任务创建:如下图为任务创建界面,可选择主题的扫描包,以及对应资源,并可以选择扫描周期,也可以选择邮件通知人,选定邮件通知人后将在该任务扫描完成后接收到任务完成情况的邮件。
- 任务详情:如下图为任务详情界面,分为基本信息、任务概览、实例列表,基本信息展示该改任务的扫描时间、扫描包信息、扫描对象列表等信息;任务概览展示了该任务整体的健康状态、通过率、资源扫描情况以及警告/危险的指标情况,可以对任务概览进行PDF的导出;实例列表则将该任务下所有的扫描实例的情况进行展示。
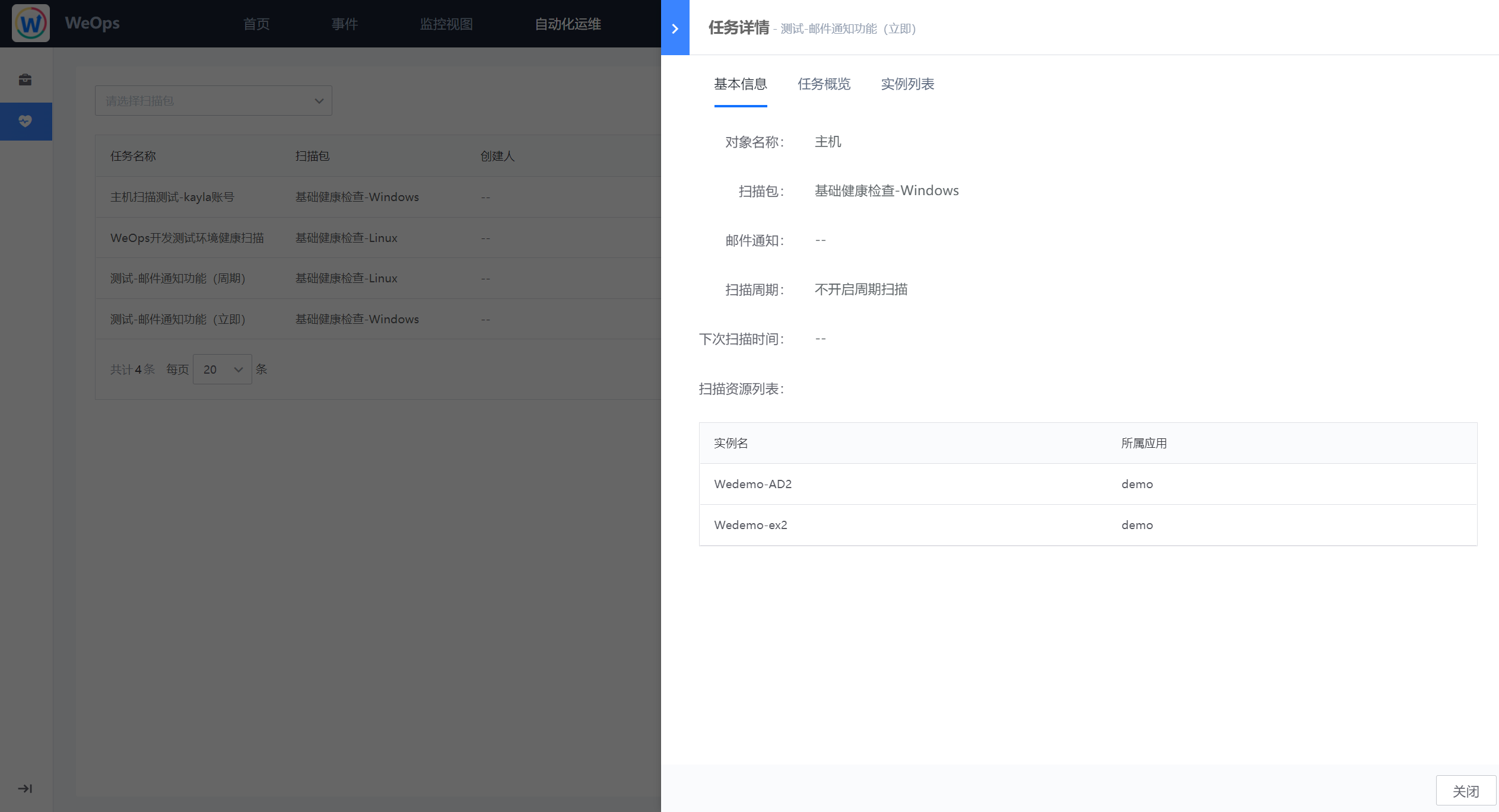
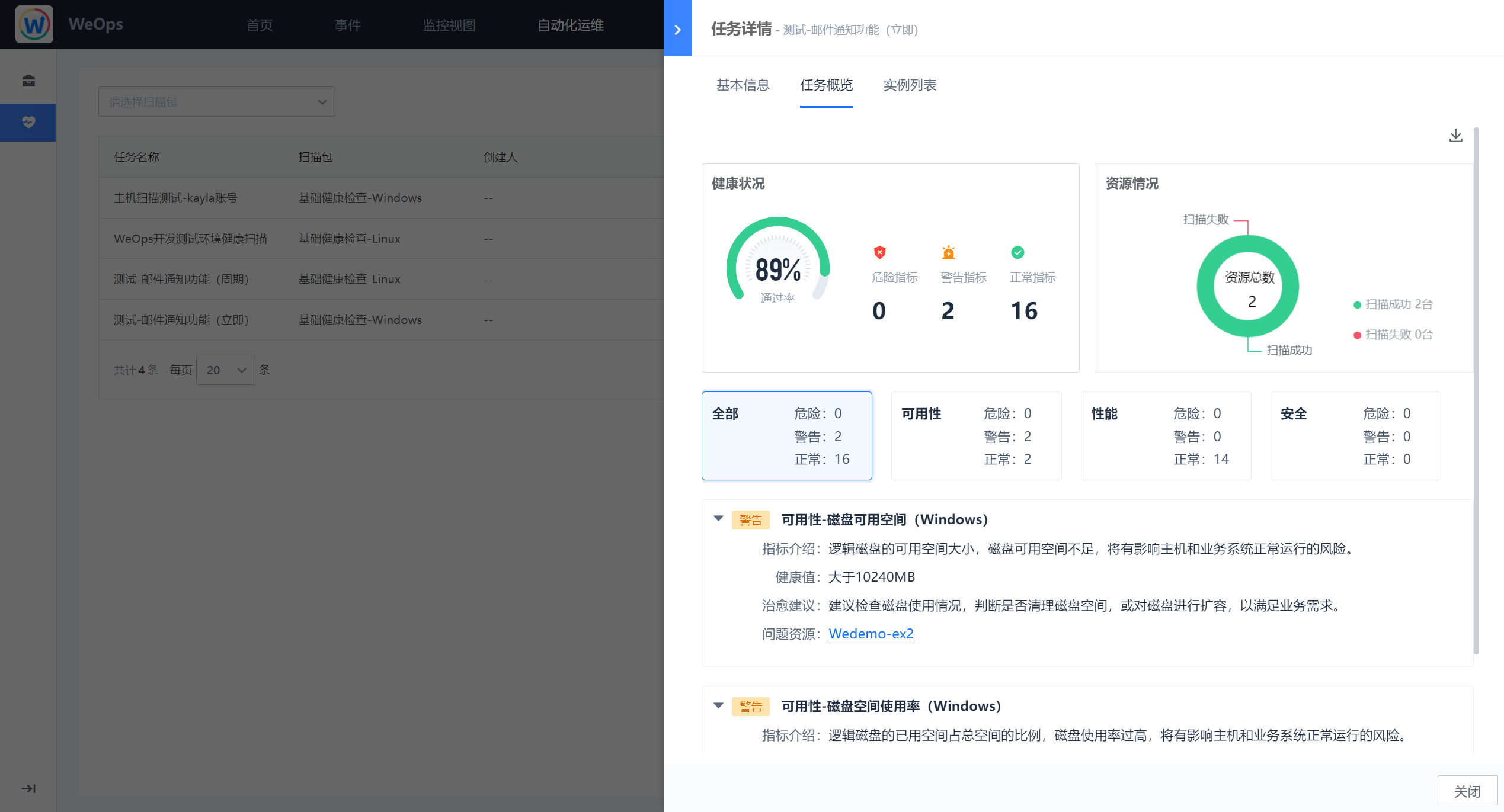
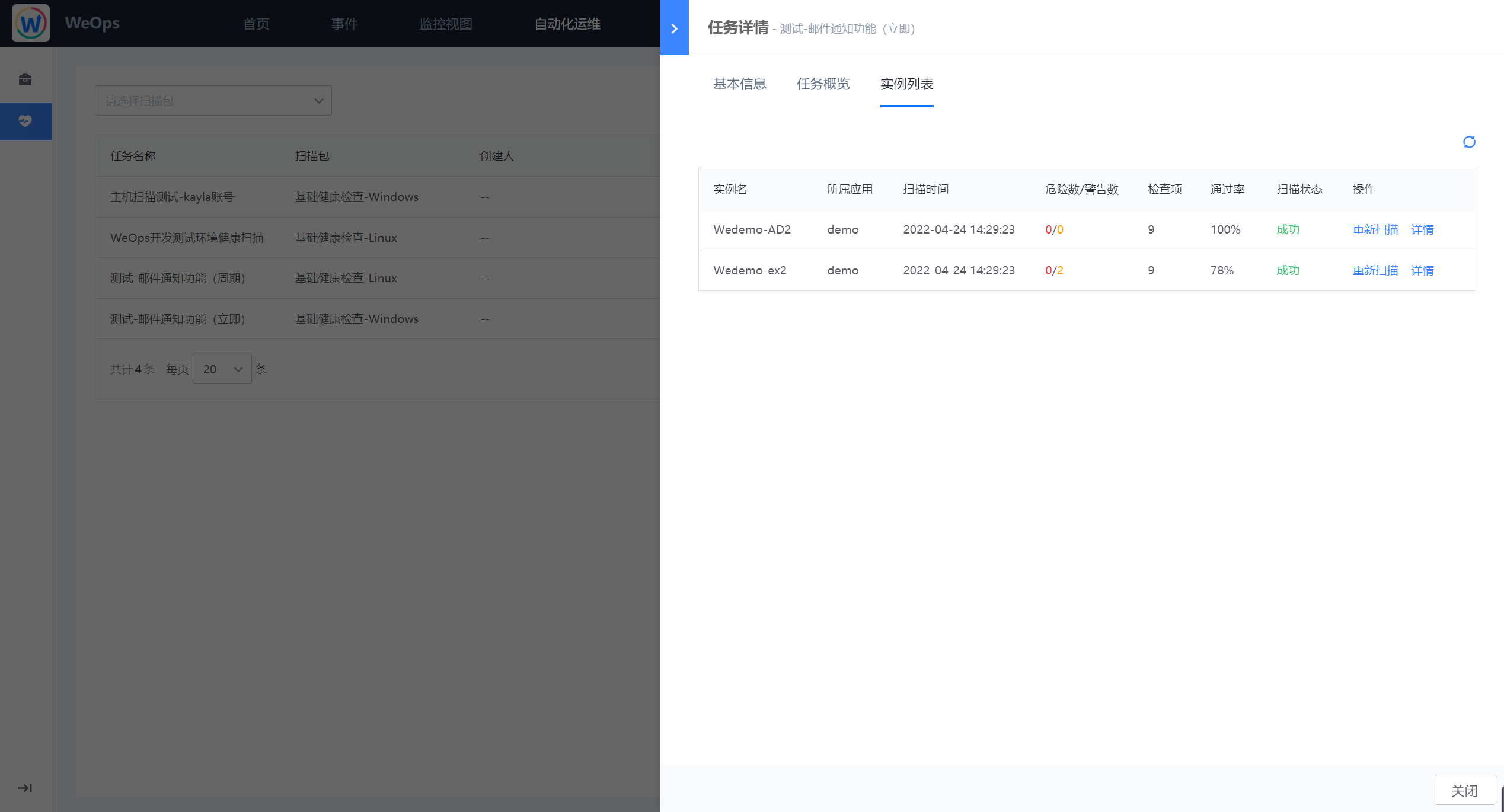
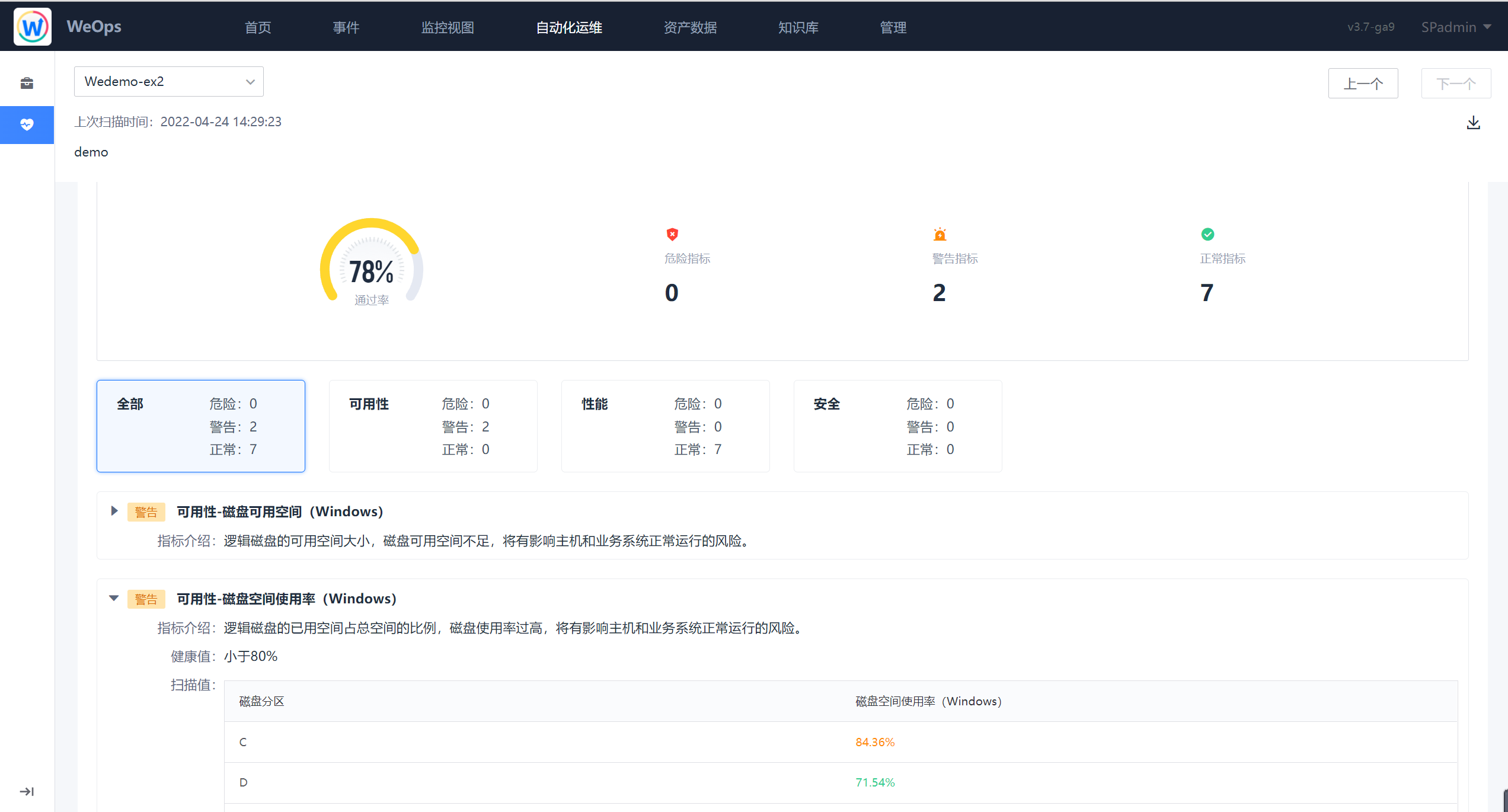
- 实例详情:通过任务详情中的概览页/实例列表页可以查看具体实例的扫描报告,针对实例详情可以导出为PDF格式文件。
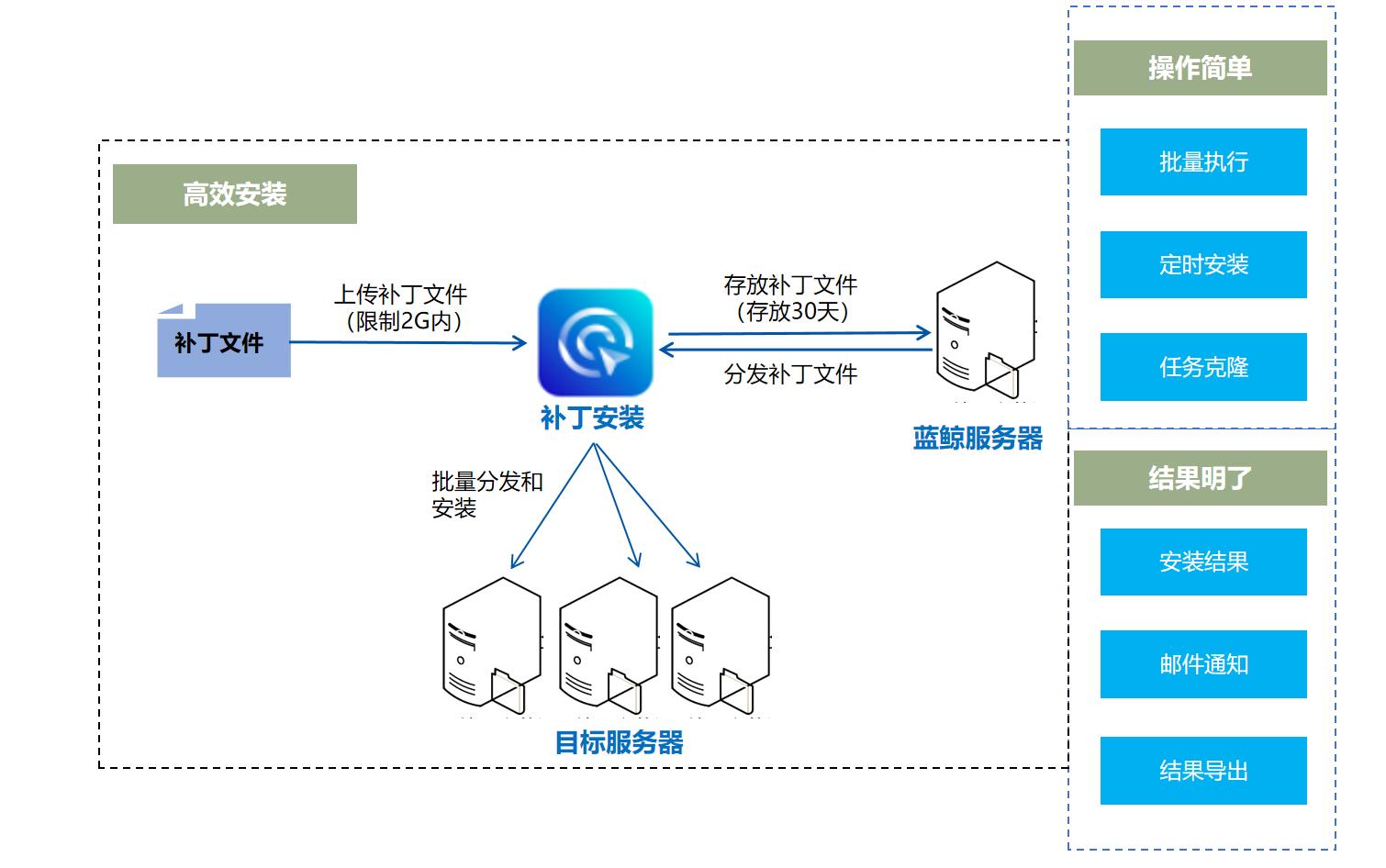
补丁安装
WeOps支持对Windows Server 2008及以上版本进行补丁扫描和安装。
补丁扫描
如下图,以任务的形式对服务器进行批量的补丁扫描,支持多补丁多服务器扫描
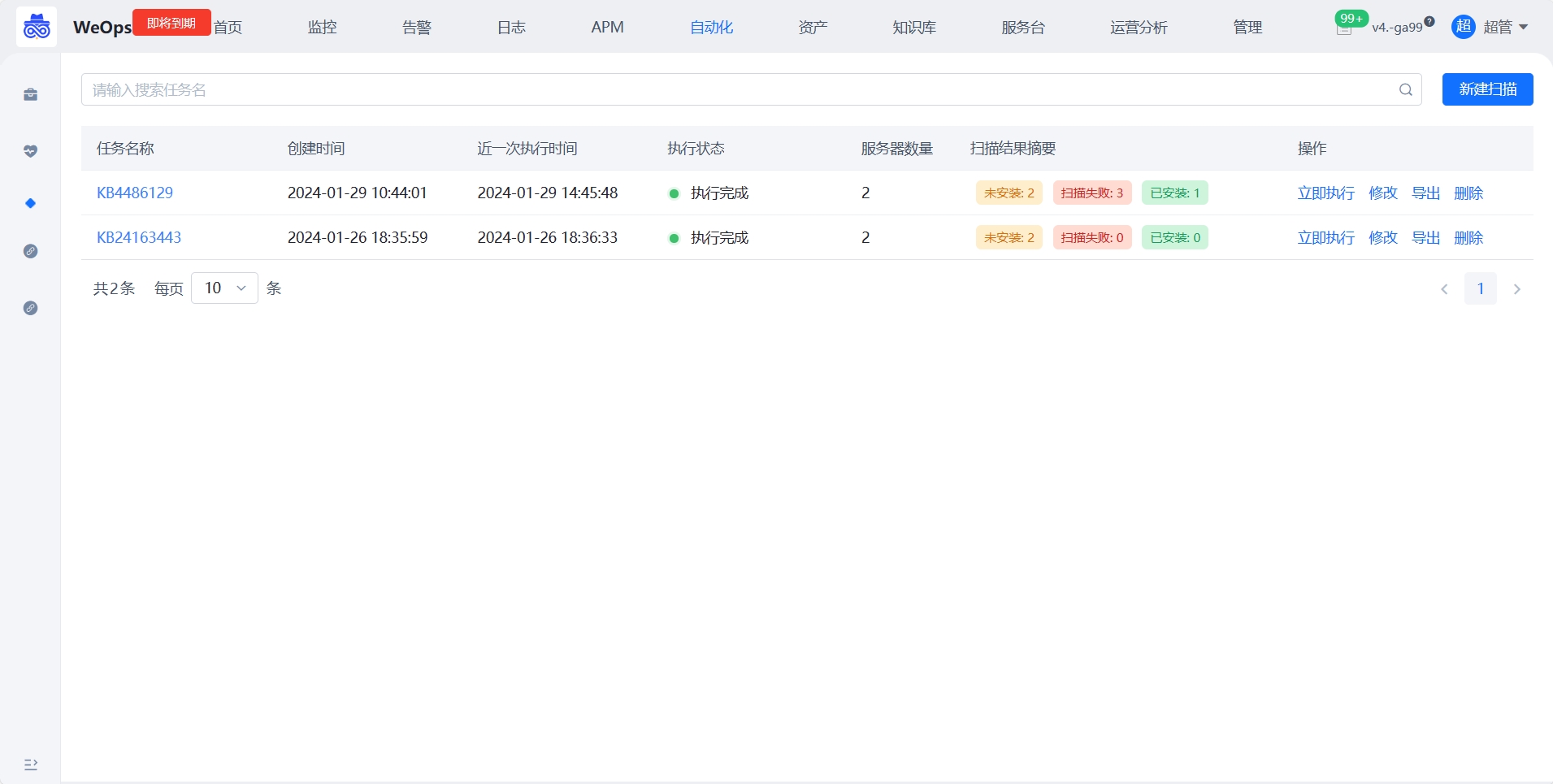
如下图,新建任务创建,目前支持Windows补丁扫描,需要添加补丁号(支持多个),选择服务器列表(支持多选),可以采用表格导入的方式进行补丁号的添加, 支持设置通知方式和通知人。
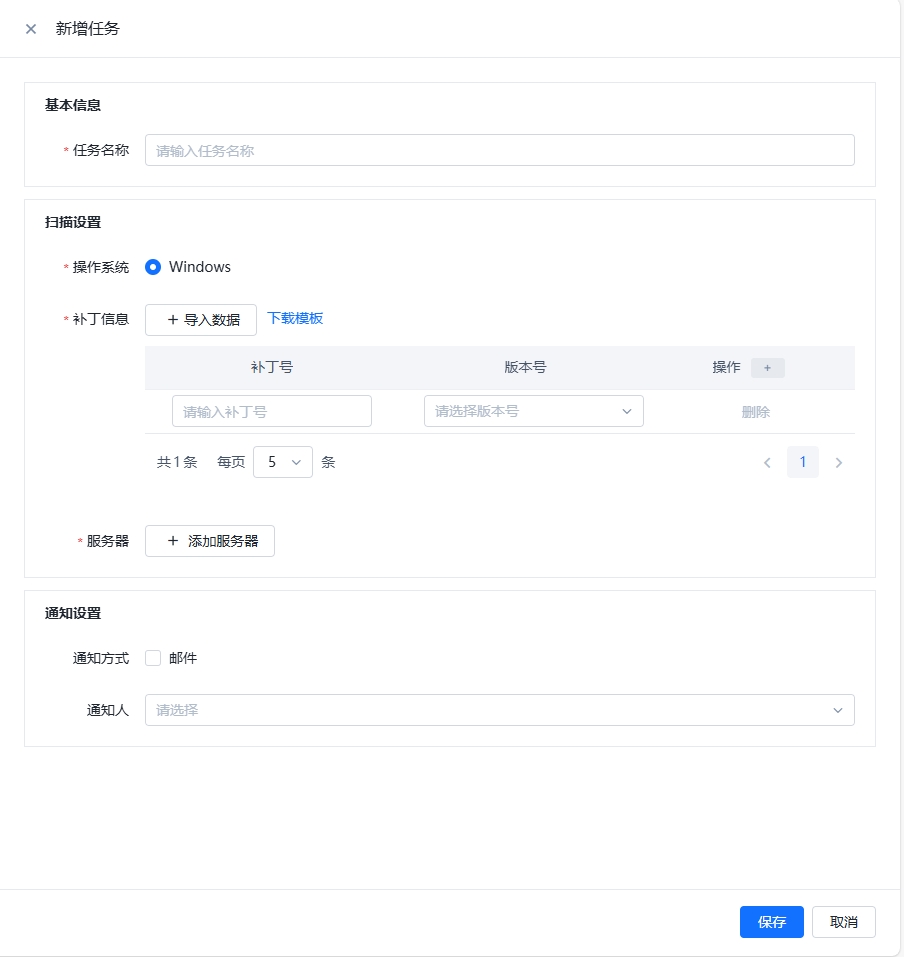
扫描结果如下:以补丁号为ta,分别展示所有服务器该补丁的安装情况(已安装/未安装/版本号不适用)
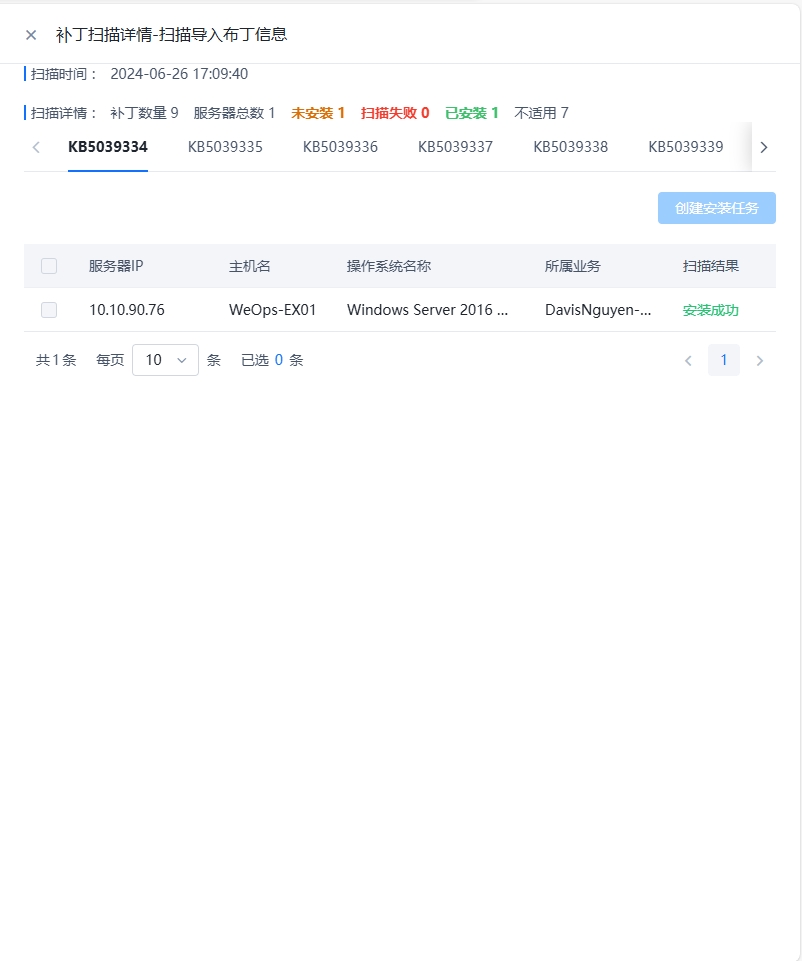
结果支持导出为表格
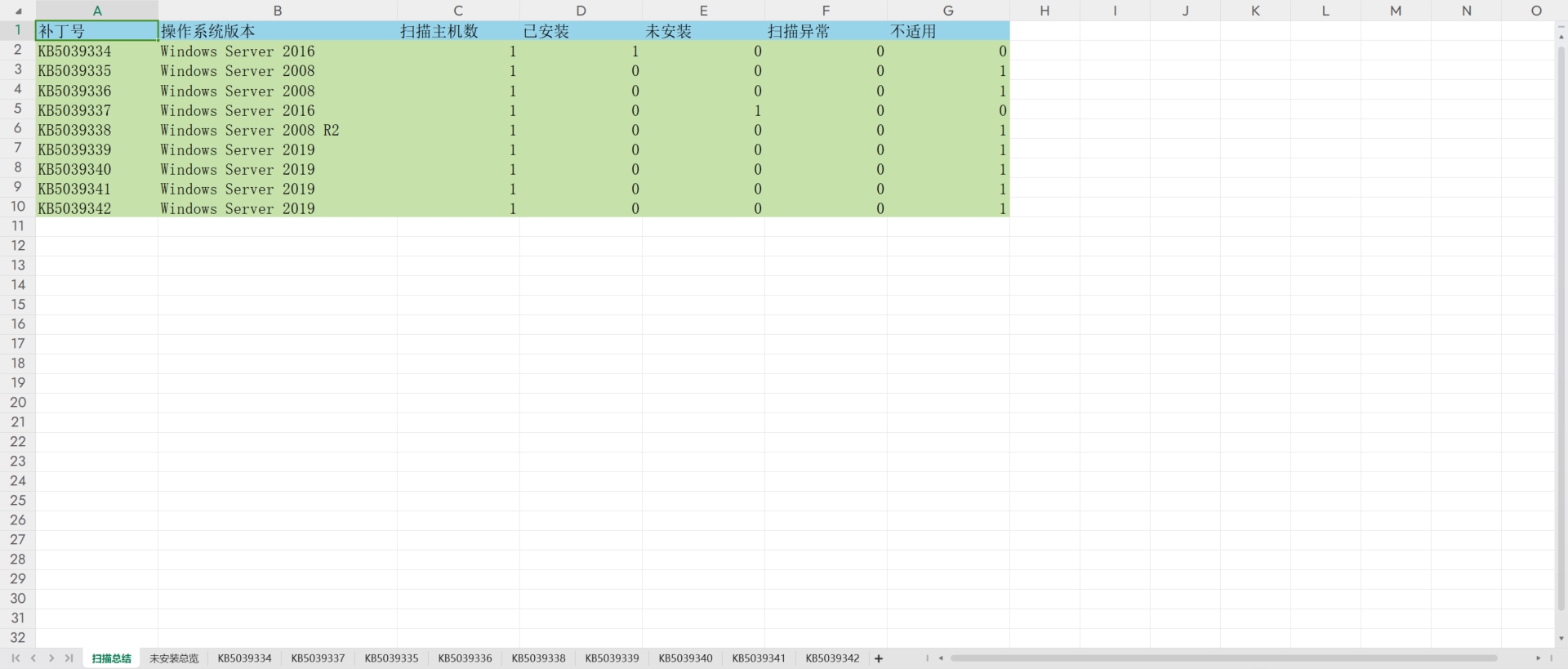
批量安装
如下图,以任务的形式进行服务器的批量安装,与传统方式相比,节省时间、安装成功率高,同时支持Windows和linux两类操作系统。
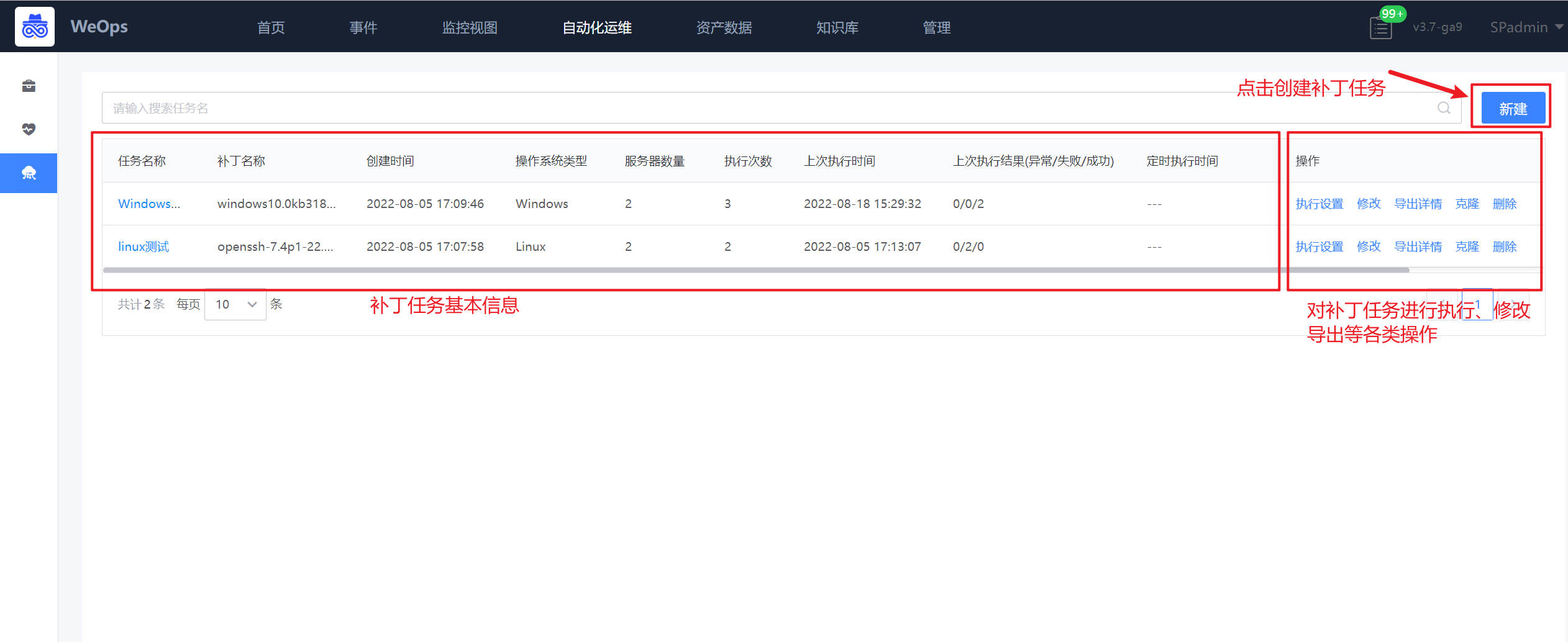
任务创建:如下图,点击“新建”按钮,即可进行补丁任务的创建,需要填写任务名称、选择服务器、上传/选择补丁文件、设置通知人。

任务执行:点击“执行设置”可以进行执行相关设置,支持立即执行/定时执行。

任务详情:任务执行中/执行结束,可以点击任务名称查看任务执行情况,可以点击“导出详情”按钮,进行任务执行结果的导出。
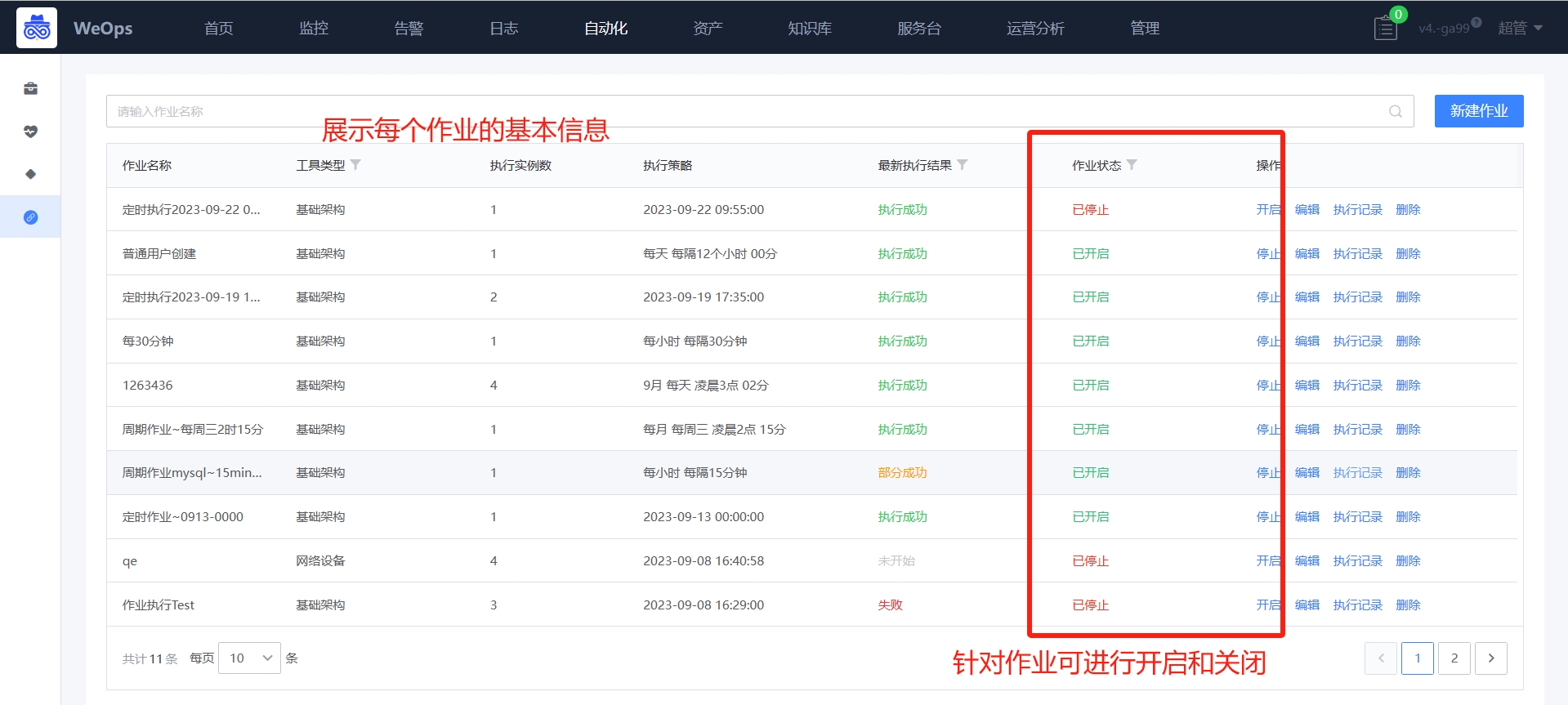
定时作业
- 如下图,以作业的形式进行脚本的定时执行,并展示每一次的执行结果。
- 新建作业:如下图,支持选择对应工具和资产,并且设置执行策略,其中定时作业支持无agent模式,即主机无需安装agent也可执行对应脚本,设置任务时需要填写对应凭据。

执行策略:定时执行-选择特定的时间只执行一次;周期执行-设置循环执行的周期,按照周期进行执行
工具类型:支持基础架构和网络设备两类设备的脚本执行
工具名称:与运维工具结合,可以选择现成的运维工具,进行定时作业
资源选择:支持跨业务选择多个资源,批量执行,支持无agent模式周期执行的时间语法采用crontab语法,具体说明如下
`数字`:固定的时间点,比如9点,周一
`*/数字`:"每隔",比如每隔2天,每隔15分钟
时间规范通常包含分钟、小时、天、月以及星期等信息,例如分钟可以是0-59的任意一个数字,小时可以是0-23,日可以是1-31,月(1-12),周(0-6)(星期天为0或者7)
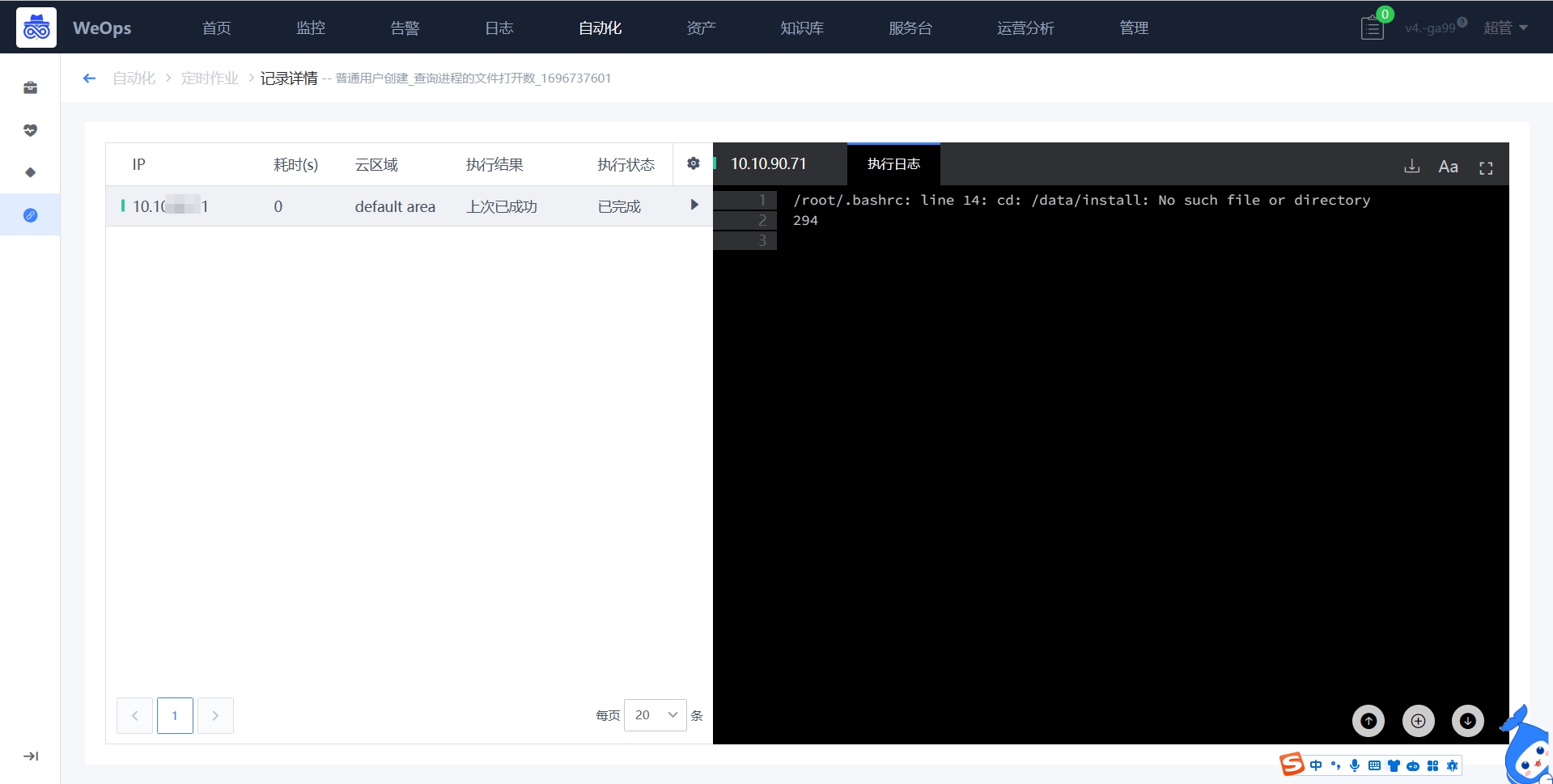
比如:每隔2小时执行一次(0 */2 * * * ),每日凌晨1点执行一次(0 1 * * *),每周日凌晨1点执行一次(0 1 * * 0)- 查看执行记录:作业每次执行结束后,会记录该次的执行情况,点击执行记录,可以查看具体的执行返回情况。
文件分发
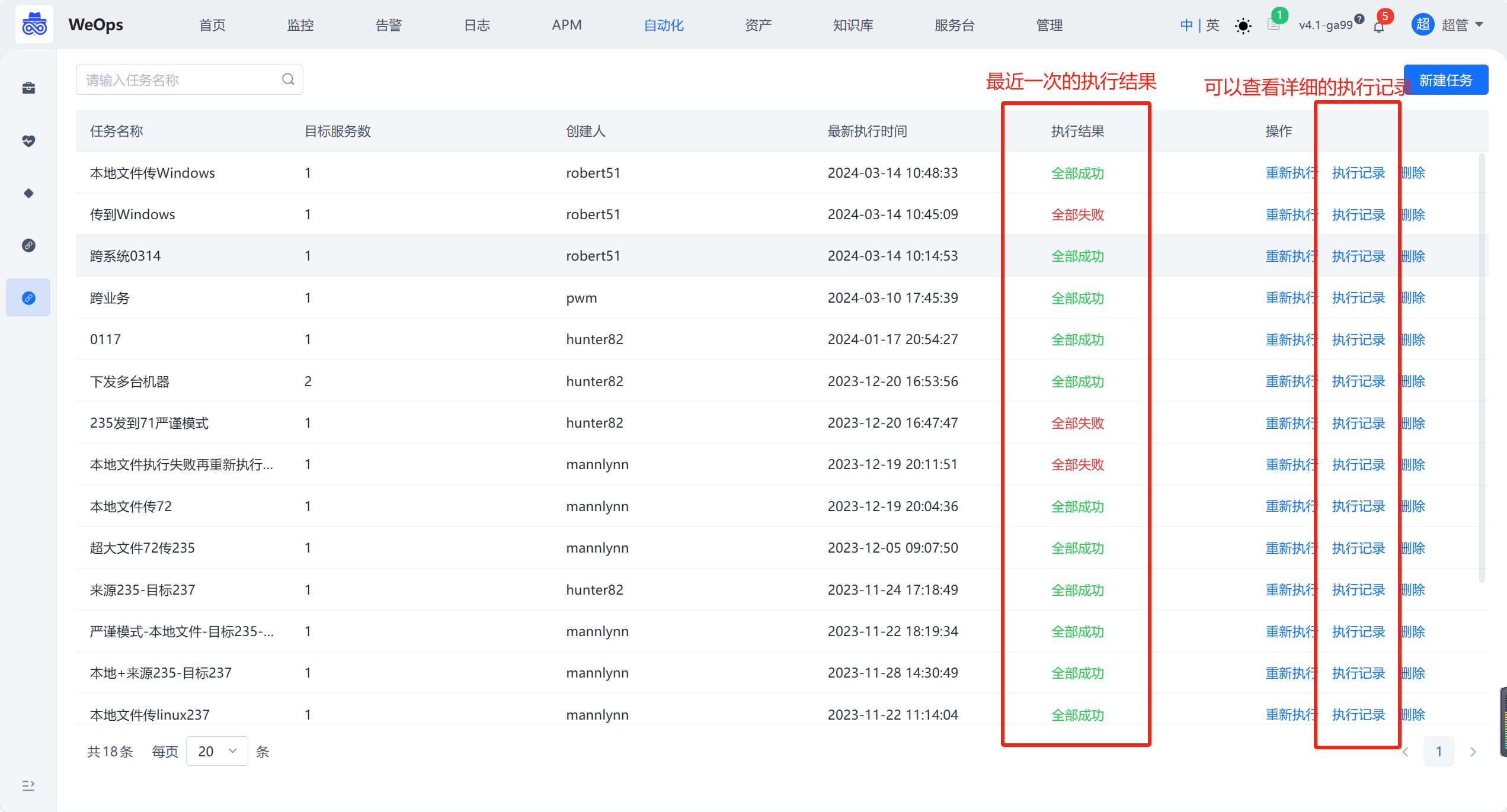
如下图,需要进行一次性传输文件的用户,可以在这里快速的执行任务并进行执行。


填写内容如下
【基本信息】
任务名称:分发文件的任务名,方便后续在执行历史中有迹可循
超时时长:分发文件的超时设置,当文件传输时间超过时将会自动关闭,结果被视为 "执行超时"
上传 / 下载限速:由于蓝鲸管控平台 Agent 默认的配置是会根据服务器带宽和资源使用情况进行限制的,防止出现因为执行的任务导致拖垮业务的机器;所以当用户自己确认机器允许更大限度传输时,通过开启限速设置可以提高传输的速率
【源文件】
分发的源文件选择,支持选择 本地文件 或 其他服务器文件
【传输目录】
目标路径:文件分发到目标服务器的绝对路径地址
传输模式:强制模式不论目标路径是否存在,都将强制按照用户指定的目标路径进行传输(不存在会自动创建);严谨模式严谨判断目标路径是否存在,若不存在将直接终止任务
执行账号:文件分发的目标服务器相关的账号,如 Linux 系统的 root 或者 Windows 系统的 Administrator
目标服务器:从资产管理获取执行的目标服务器任务创建完后,执行点击“确定”,即可立即执行文件批量分发任务。
文件分发任务执行完成后,可以在列表中查看最新一次的执行结果,也可以在“执行历史”中查看执行的详细结果。
服务台
工单列表
如下图,“WeOps-服务台-工单列表”用于展示“我的待办”“所有待办”和“历史工单”的列表信息,可以直接在列表查看工单的提单信息和步骤信息,可进行工单的处理。
- 我的待办:展示所有需要“我”处理的工单列表,点击查看工单详情可以进行工单的处理
- 所有待办:展示所有未完成的工单列表,点击可以查看工单详情
- 历史工单:展示所有已经完成的工单列表,点击可以查看工单详情
- 我的待办/所有待办/历史工单均支持工单导出

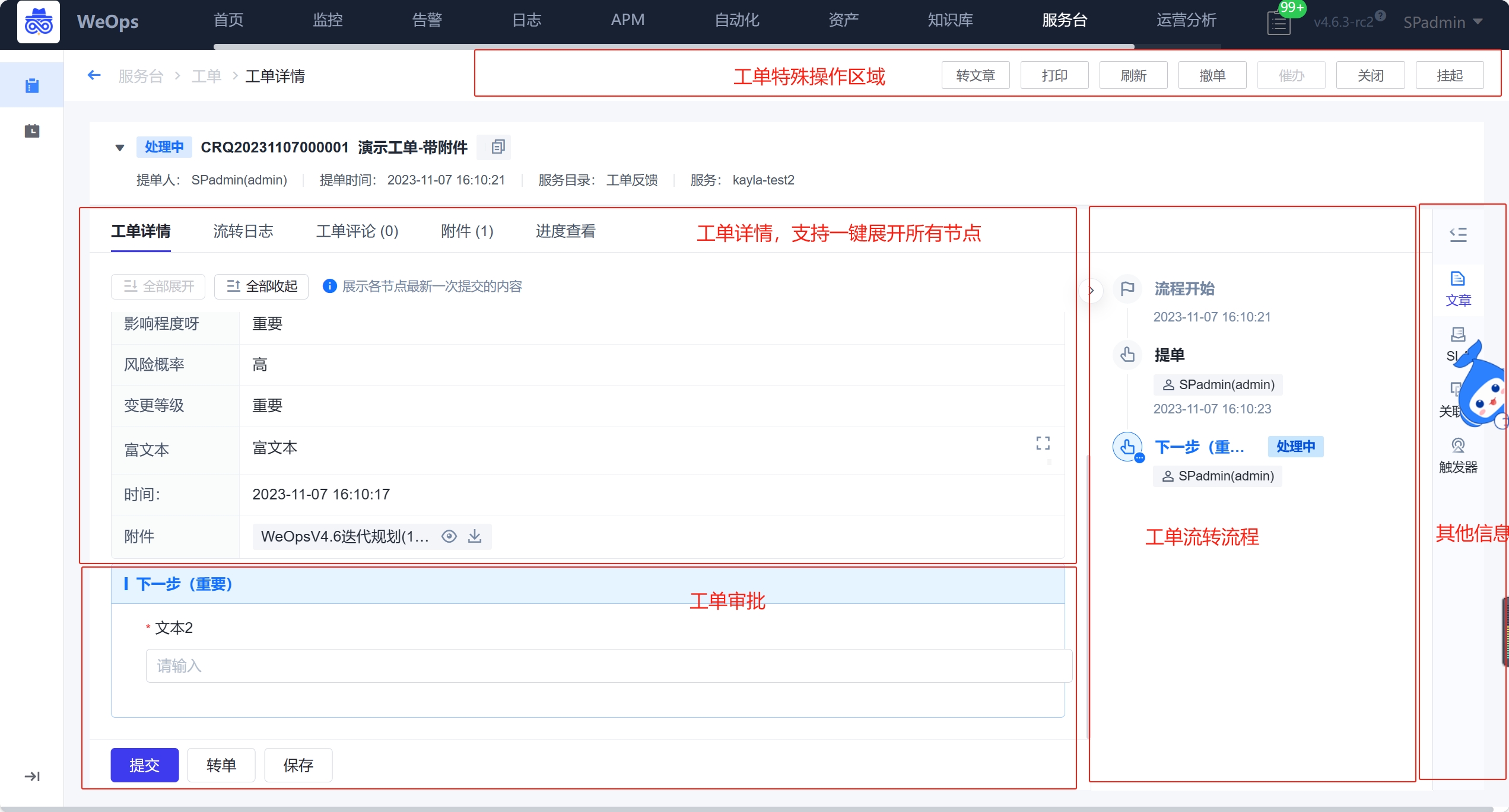
点击可查看每个工单的详情,工单详情包括:工单内容(展示提单各个字段内容)、审批部分(对应审批人审批)和工单流转记录,其他展示区(可进行满意度评价,支持查看SLA等详情),此外可对该工单进行撤单,关闭、催办、挂起等操作。
我的值班
如下图,“WeOps-服务台-我的值班”用于展示我的值班安排和值班记录。
- 我的值班:支持切换“日历视图”和“列表视图”两种视图,根据排班情况展示我的值班情况,可进行签到、签退、工作交接。
- 值班记录:可查询以往值班记录/未来值班安排,可查看详细的值班和交接日志。
知识库
知识库支持文章的撰写、文章批量导入、文章暂存为草稿、文章的分类查看。
所有文章
知识库所有文章展示了所有人写的文章,可进行搜索、以标签进行筛选展示、对关注的文章进行收藏。
点击对应文章,可以查看该文章详情,可以进行该文章点赞、收藏等操作
我的文章
我的文章展示了所有“我”撰写的文章,可以对文章进行搜索和筛选,也可以进行重新编辑和删除的操作。
“文章导入”:知识库支持文章的批量导入,并为文章批量添加标签。

“写文章”可以选择模板进行文章的快速撰写,目前支持“Markdown”、“嵌入页面”、“图片”、“文件”三类组件。文章撰写后可以选择“发布文章”或者“保存草稿”

“我的草稿”:文章撰写时可以手动保存,或者5分钟自动保存为草稿,对于草稿支持再次编辑发布。
我的收藏
我的收藏对“我”关注的文章进行展示,可以点击文章标题前的星号进行收藏/取消收藏。
运营分析
数据大屏
展示所有内置大屏和手动添加的大屏基本情况,目前已经内置4张大屏。
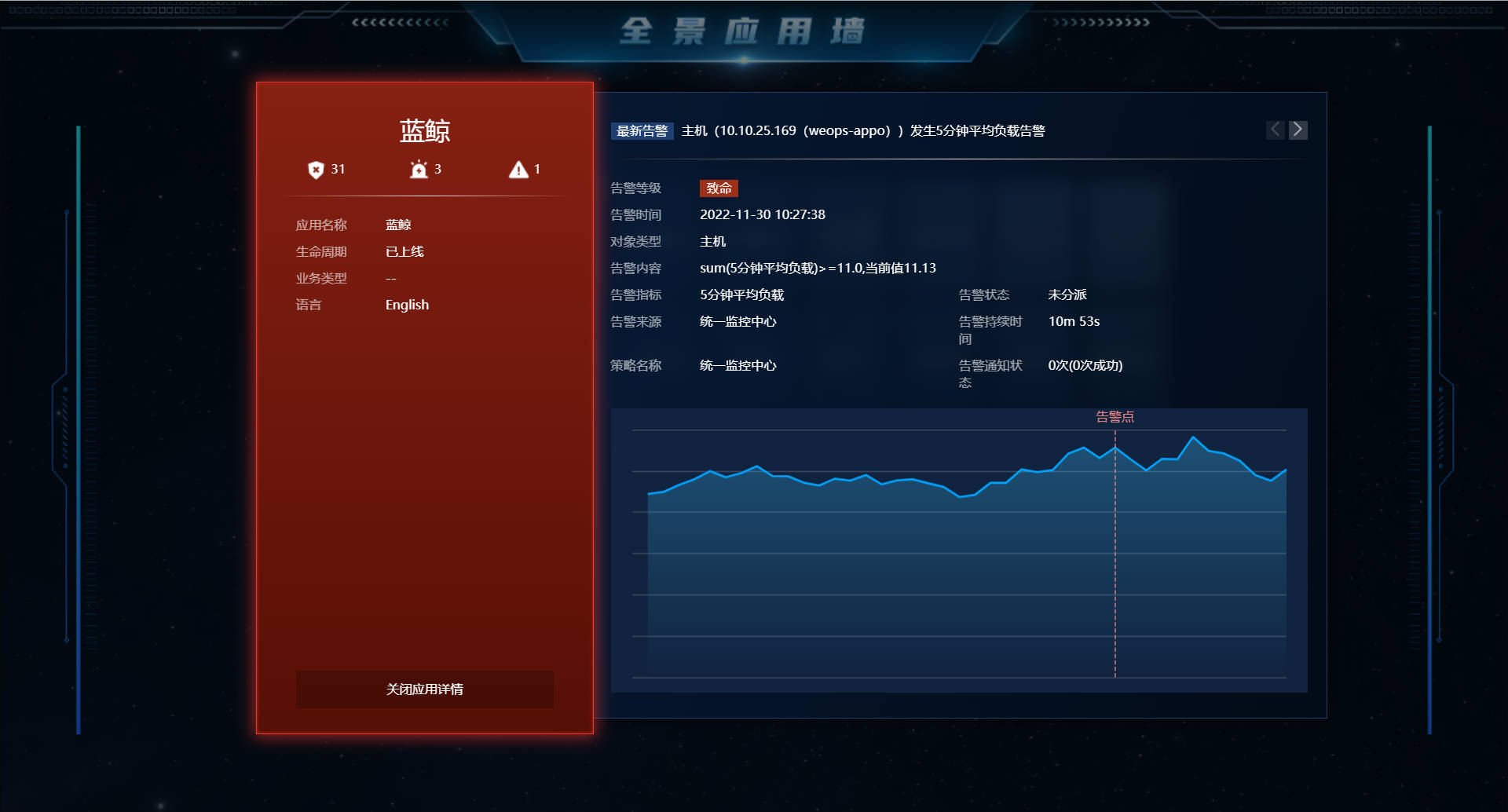
3D应用全景大屏
- 展示全部应用的拓扑情况和告警情况
- 点击应该可查看该应用的告警具体情况,包括告警等级、内容、指标视图等
- 展示该应用的3D拓扑图,便于全景展示应用的整体架构和告警链路。
- 每个应用可以点击进入该应用的APM服务大屏


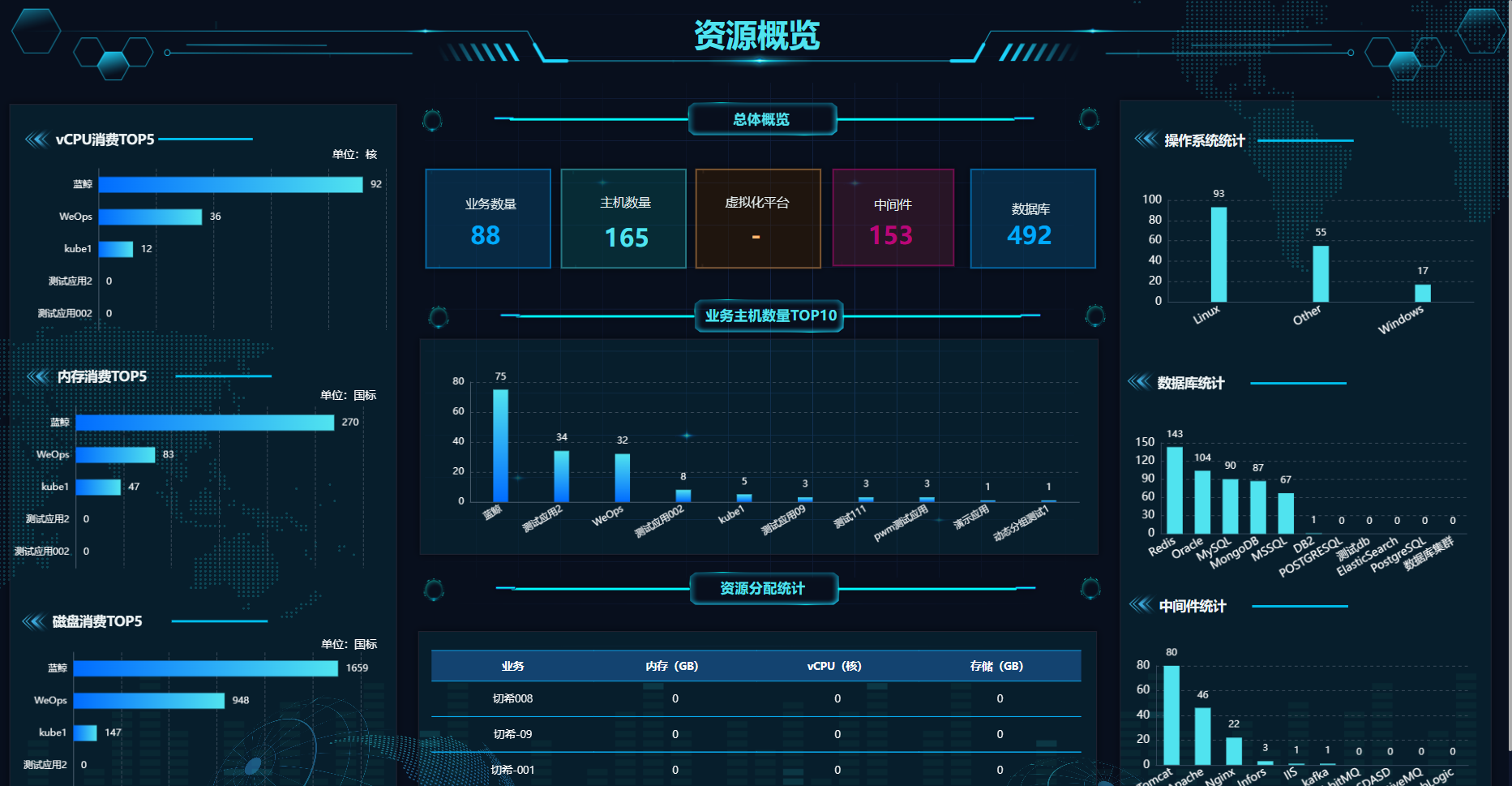
资源大屏
- 展示资源概览数据:业务、主机、虚拟化平台、中间件、数据库。
- 资产分类统计:按操作系统、数据库、中间件统计。
- 主机数量统计:按业务TOP10。
- 资源分配统计:按业务。
- 资源消费统计:内存、vCPU、磁盘消费TOP5。
核心业务监控大屏
- 展示应用拓扑图。
- 告警概况:告警级别分布、告警处理状态分布。
- 实时告警信息:告警级别、分类、实例名、业务、告警描述、时间、状态。
- agent状态:正常、异常。
- 监控覆盖率:主机、数据库、中间件监控覆盖率。
应用墙
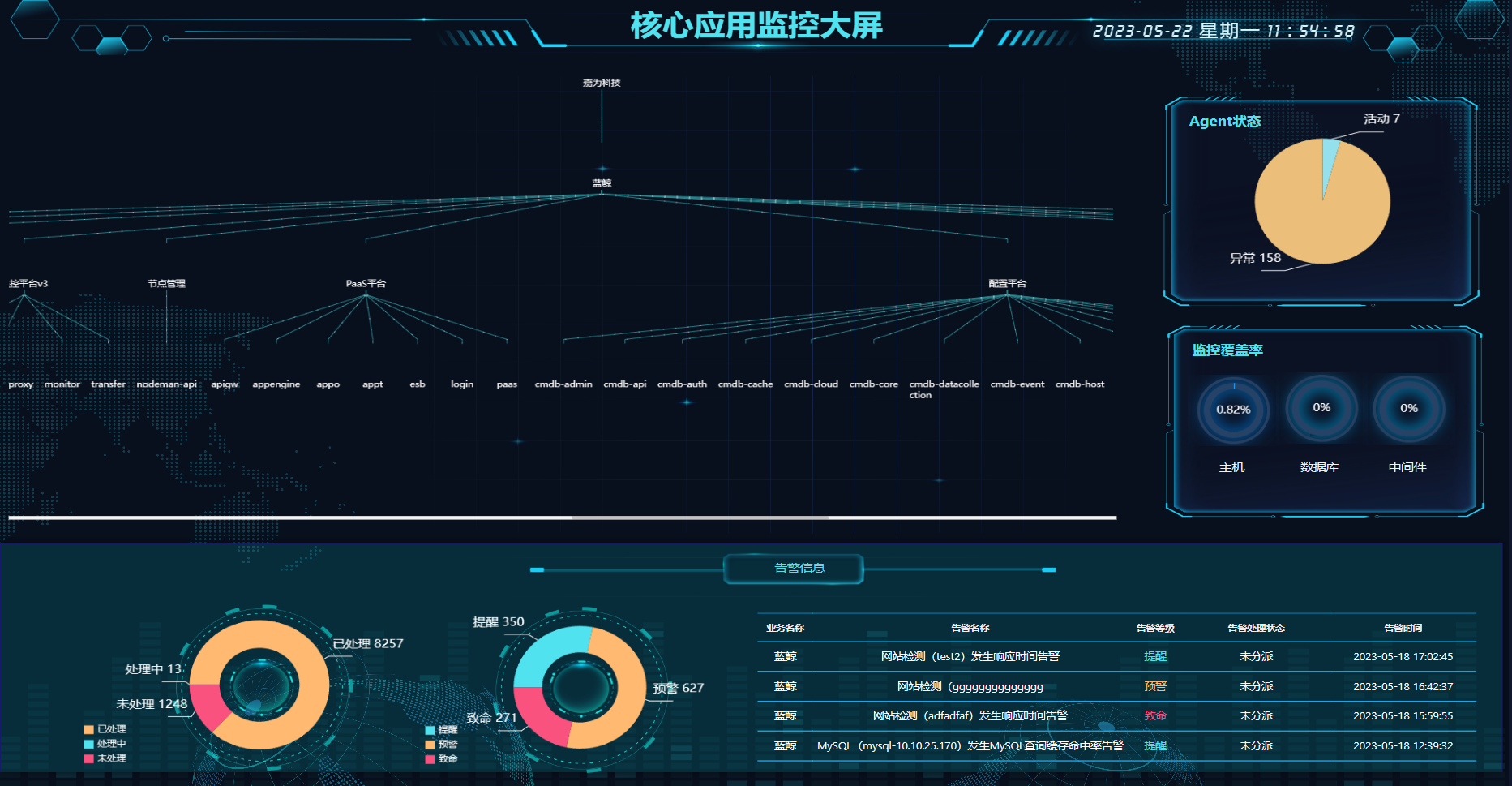
- 应用总览展示了所用应用的基本情况,包括应用总数量、正常应用数量、预警应用数量、预警应用数量
- 展示应用健康状态展示:严重、普通、轻微。
- 告警详情展示:业务名称、告警名称、告警等级、告警处理状态、告警时间。

运营报表
展示所有内置报表和手动添加的报表基本情况,目前已经内置2张报表。
告警数据运营分析表
- 整体展示了WeOps告警相关的关键指标数据,支持切换日期查询范围
- 单值:有效告警数、关闭告警数、未关闭告警数、未响应告警数、危险告警数、MTTR
- 折线图:告警压缩占比趋势图(有效告警、屏蔽告警、抑制告警)、告警处理数量趋势图
- 饼图:告警级别分布(危险、预警、提醒)、告警状态分布(各类告警状态)、告警对象分布(各类对象)
- 表格:应用分析(应用名称、有效告警数、关闭告警数、未关闭告警数、未响应告警数、危险告警数、MTTR)
- 表格:人员分析(姓名、被分派的告警、认领的告警、关闭的告警、MTTR)
工单数据运营分析表
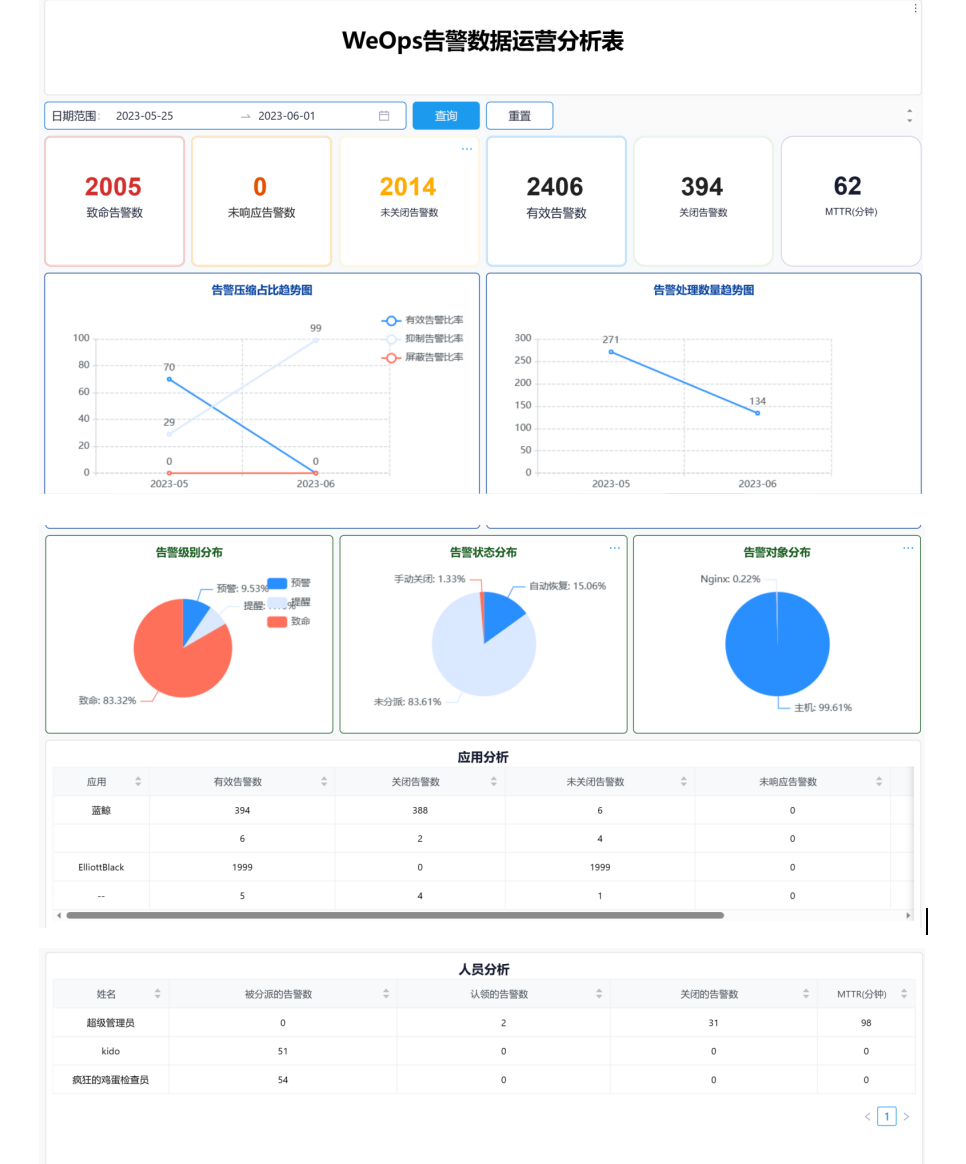
- 整体展示了WeOps工单相关的关键指标数据,支持切换日期查询范围
- 单值:工单总数、关闭工单数、未关闭工单数、未响应工单数、MTTR、在SLA目标时间内解决的事件百分比、满意度(所有被调查满意度的服务请求记录中用户满意度分值总计 / 所有被调查满意度的服务请求总数)
- 柱状图:每日新增工单数、每日关闭工单数
- 表格:服务分析(服务名称、工单总数、关闭工单数、未关闭工单数、未响应工单数、MTTR、在SLA目标时间内解决的事件百分比、满意度)
- 表格:人员分析(姓名、关闭工单数、MTTR、在SLA目标时间内解决的事件百分比、满意度)

业务低负载报表
- 整体展示了业务低负责主机的统计情况
- 支持支持切换日期查询范围、业务选择范围、高峰期范围,支持设置低负载的CPU使用和内存使用情况
- 单值:主机数、Agent正常数、Agent异常数、未安装Agent数
- 表格:低负载主机(IP、主机名、操作系统、应用、CPU使用情况、内存使用情况)、正常负载(IP、主机名、操作系统、应用、CPU使用情况、内存使用情况)

管理
节点管理
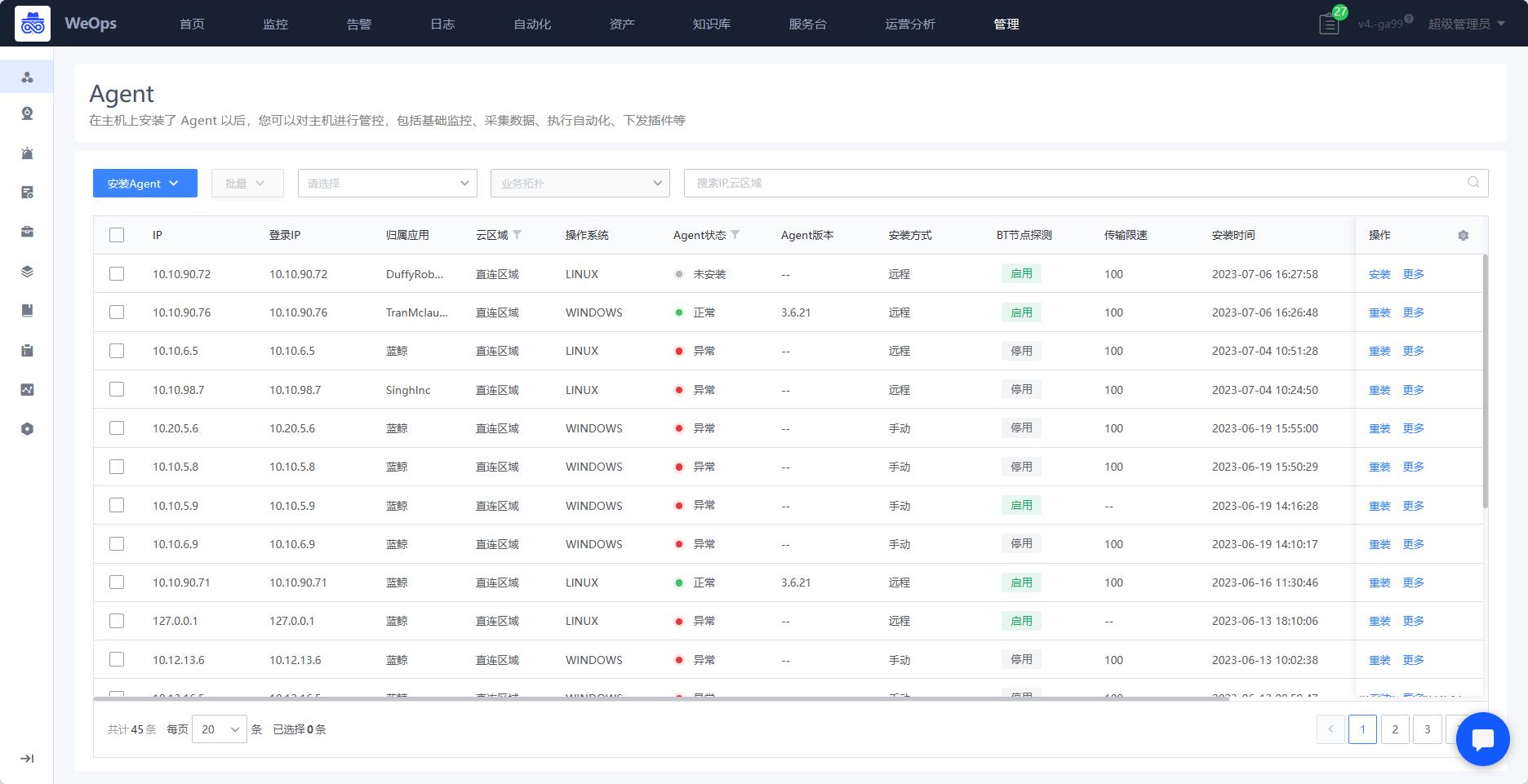
Agent
- 支持主机进行Agent安装,安装后对主机进行管控,可进行主机监控、采集基础信息、执行自动化等操作。
- 对于主机的agent安装,支持普通安装和表格批量导入安装,支持远程安装和手动安装两种方式进行。
云区域
- 云区域是互相之间能直接通信的一组服务器单元,如企业内的局域网、公有云 VPC(虚拟私有网络)。WeOps在刚部署的时候,默认会创建“直连区域”,当主机可以直接与蓝鲸部署所在网络直接进行通讯连接时,Agent 安装到此区域即可。如果企业网络有区域划分,如办公网与生产网络隔离、总公司与分公司网络隔离、国内服务网与国外服务网隔离等情况,可根据实际的网络可连通性规划创建多个云区域。
- 接入点: 云区域对外通信的代理节点。
- 如下图,支持创建云区域,填写云区域名称,选择云服务商用于标识当前网络的提供商,接入点使用默认接入点,后续可以跟进指引进行接入点的安装
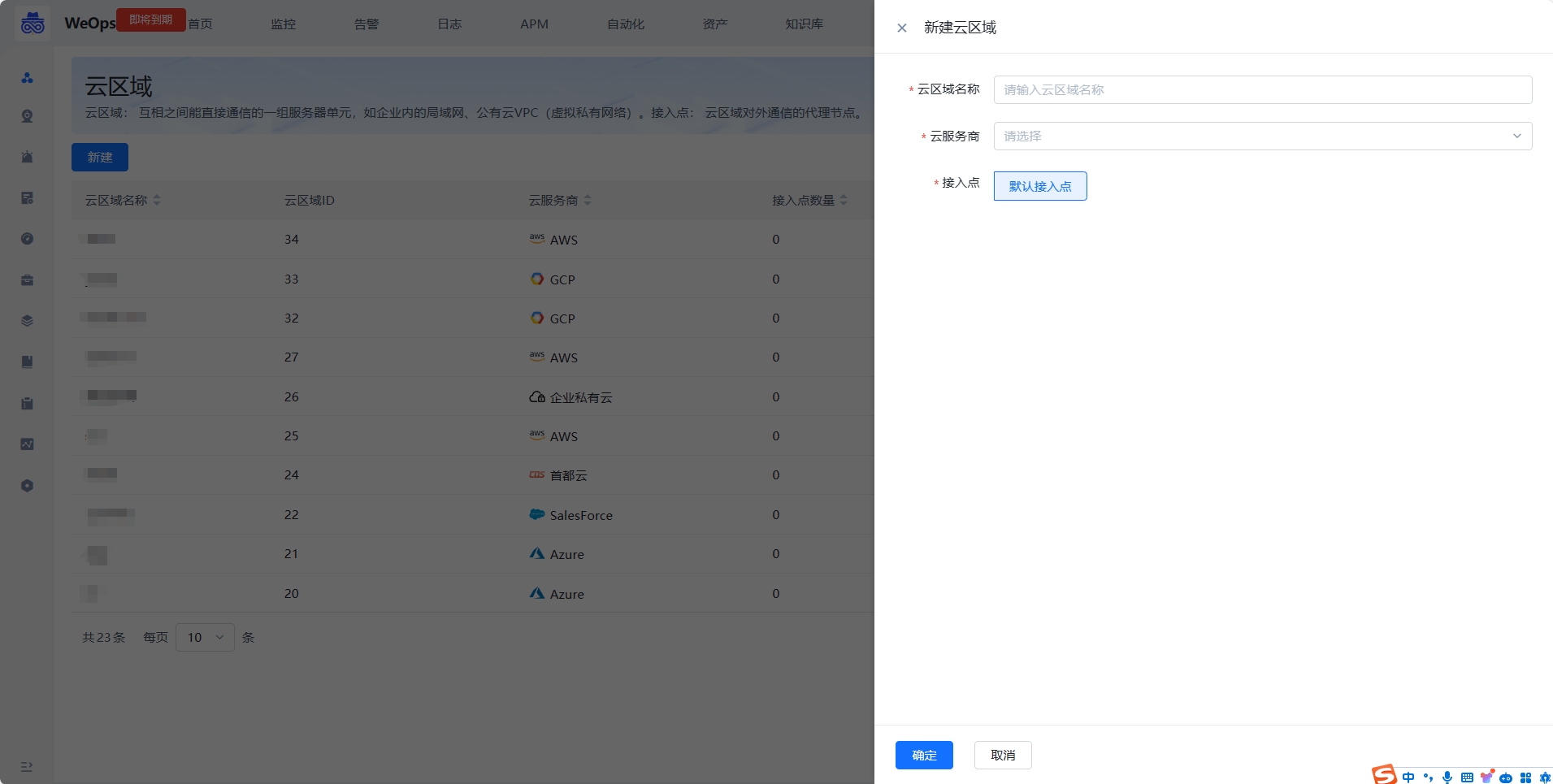
- 云区域创建完成后,可以在主机安装Agent的时候,选择使用。
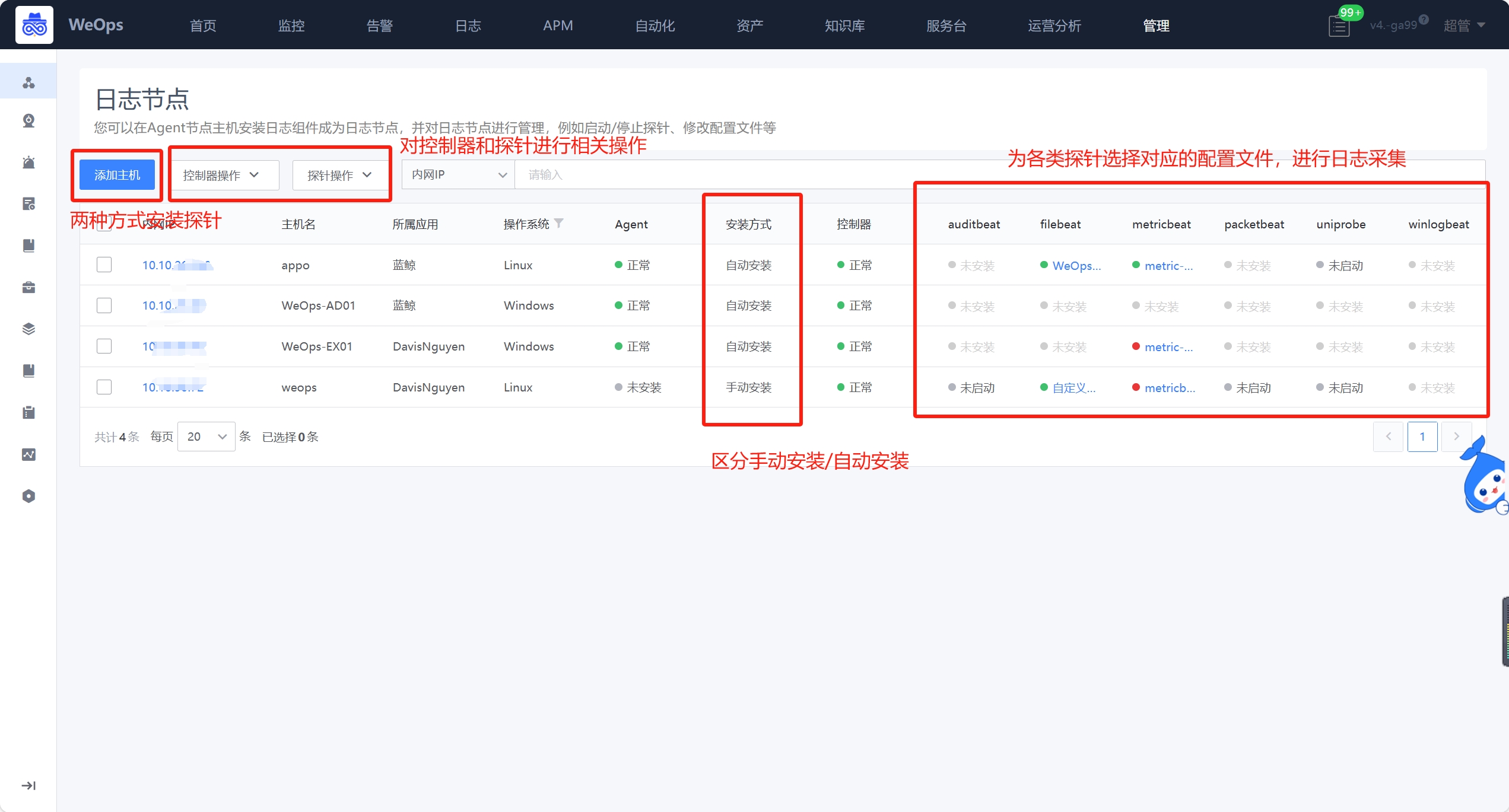
日志节点
- 日志节点支持为已经安装了Agent的服务器安装日志探针控制器和日志探针,并为为日志探针关联对应的配置文件,以便采集不同的日志数据。
- 日志的控制器和探针的安装方式有两种,具体解释如下
自动安装:主机已经安装了agent,可以支持选择主机后,自动安装控制器和探针,以便后续采集日志数据使用。控制器和探针的重启、停止和卸载也支持自动进行。
手动安装:主机没有安装agent,可以采用手动的方式,去服务器上传并安装控制器和探针的安装包,安装成功后,与自动安装一直,可以选择对应的配置文件,进行日志数据的采集。控制器和探针的重启、停止和卸载也需要通过手动进行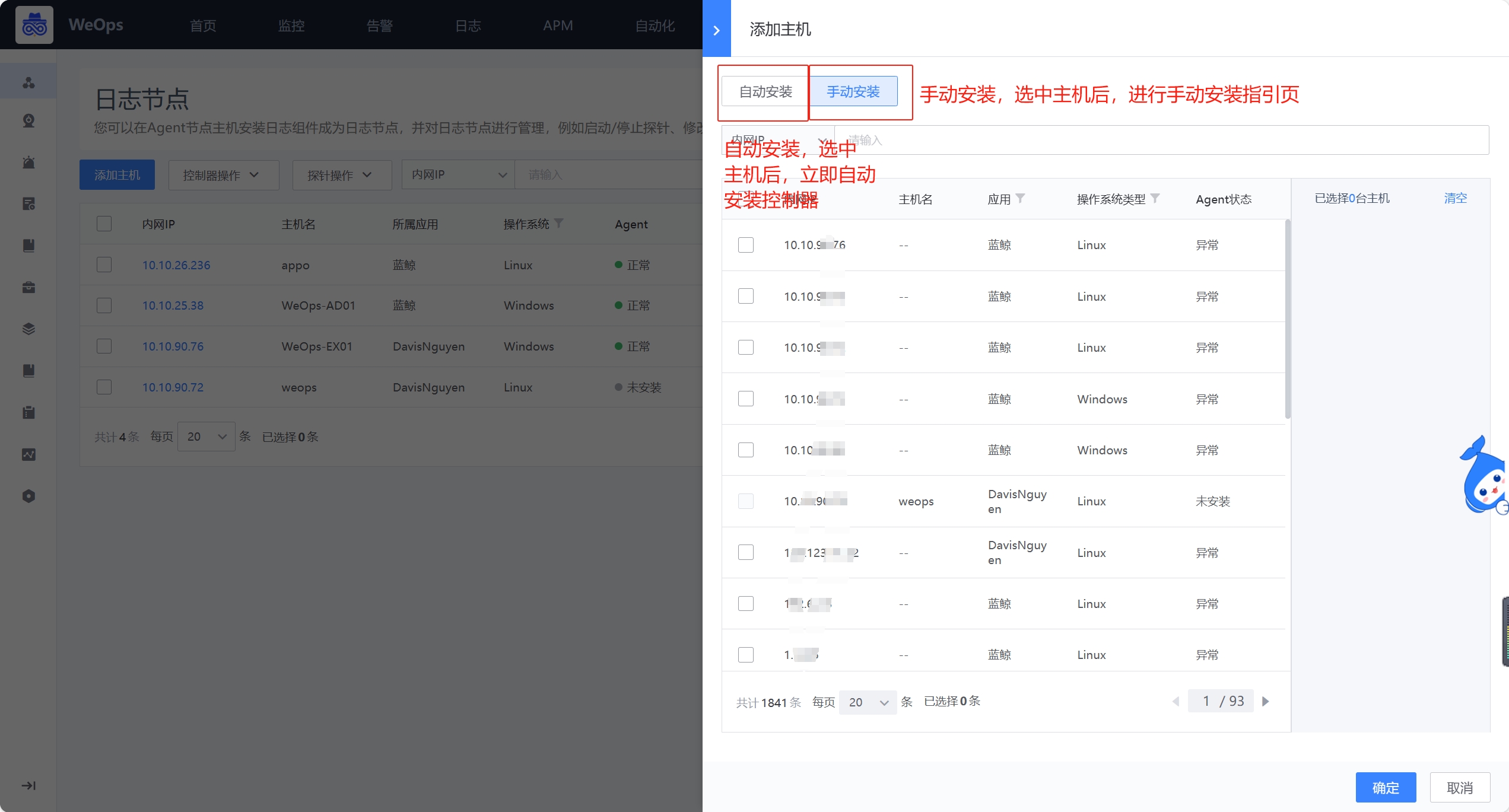
- 日志控制器操作,包括安装、启动、重启、停止、卸载等操作,探针则包括安装探针、启动探针、修改配置、重启探针、修改探针等操作
APM节点
展示所有已经接入的探针,以及这些探针所属的应用/服务,探针名称:接入时自定义;语言/版本:可进行筛选;所属应用/服务:可筛选,可跳转至详情页;最新数据上报时间

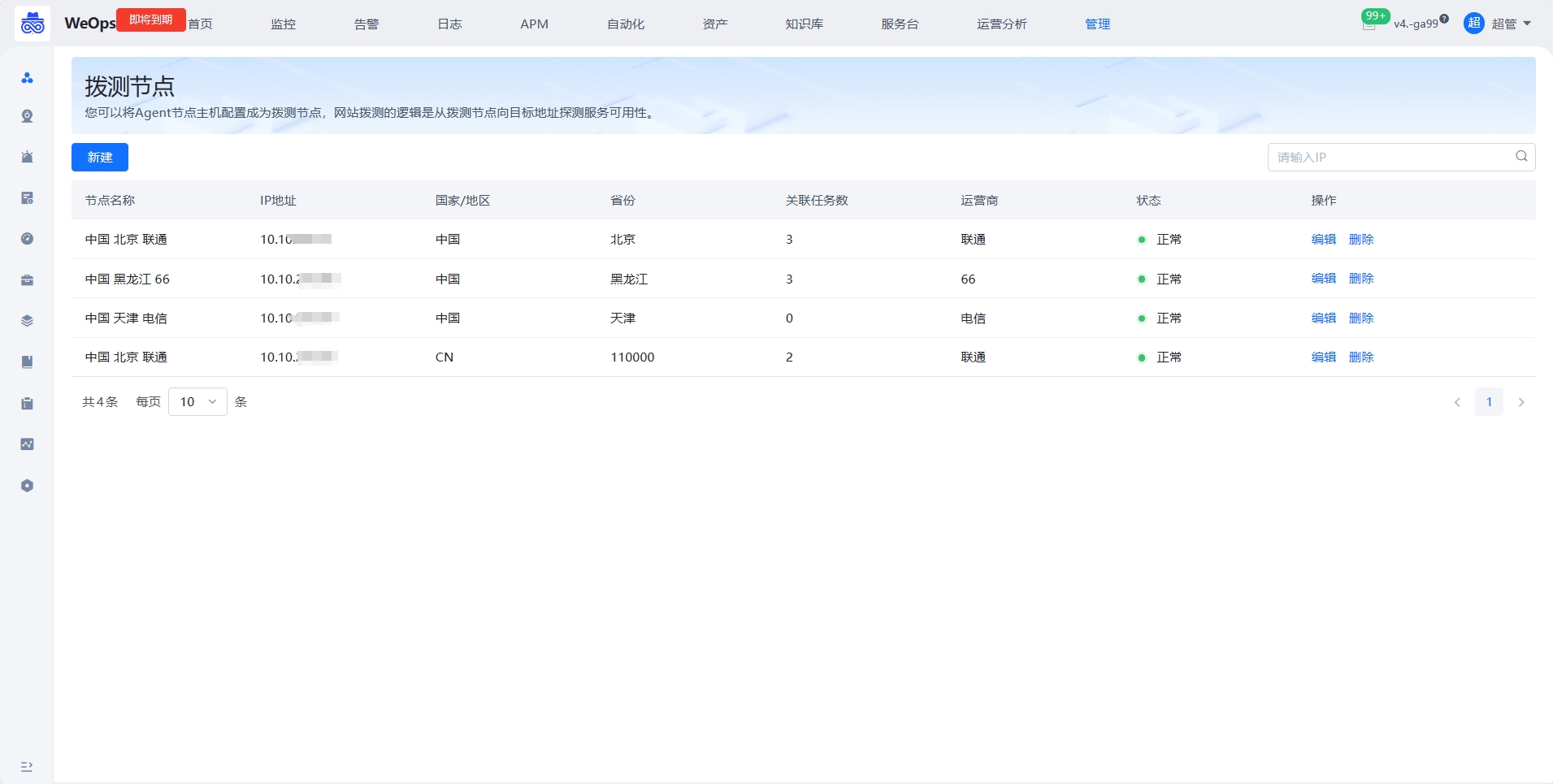
拨测节点
如下图,支持对服务拨测任务设置拨测节点,实现从拨测节点向目标地址探测服务可用性
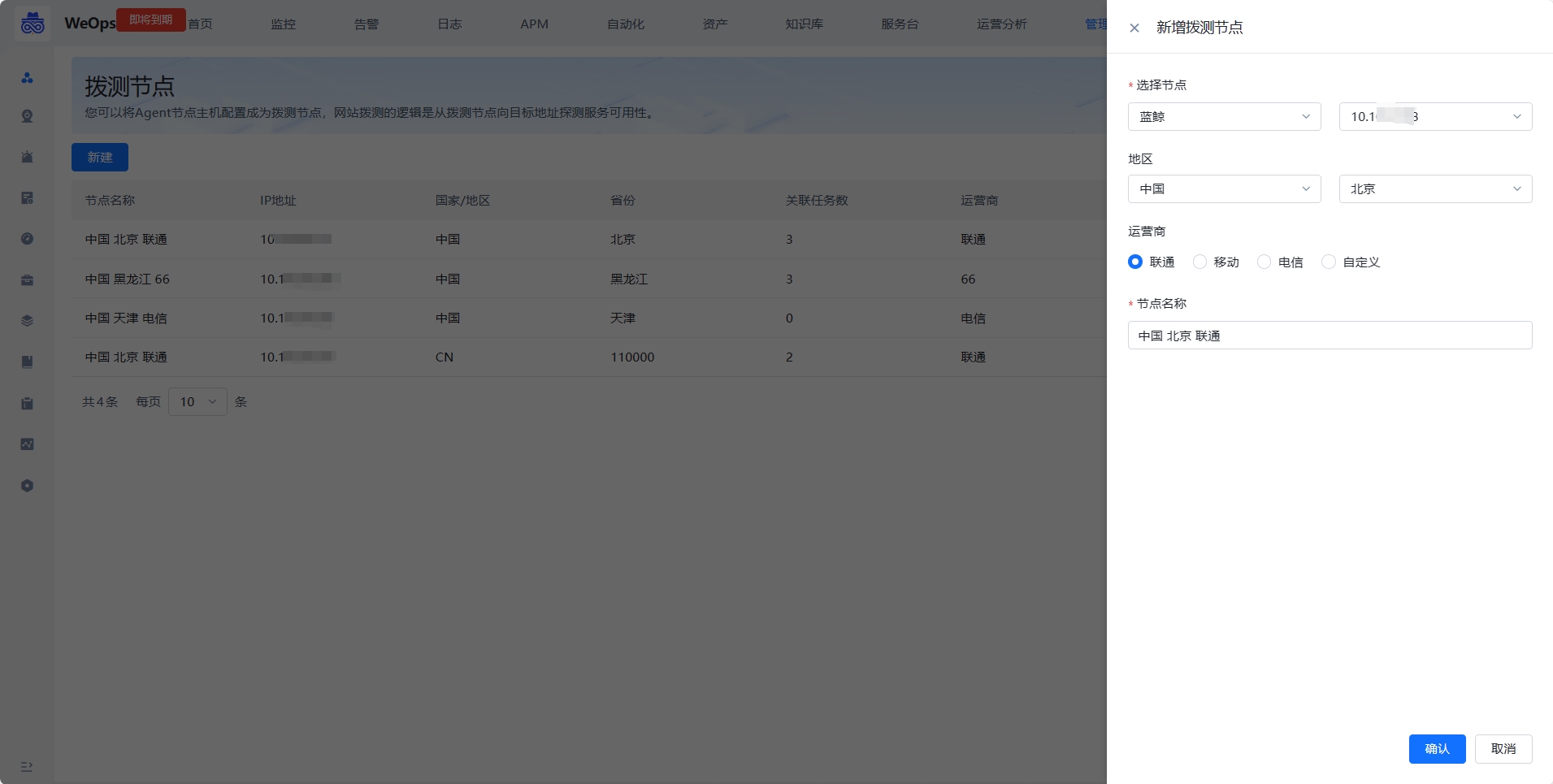
新建拨测节点时,需要选择一个主机作为拨测节点,并且配置这个节点的地区和运营商等信息。
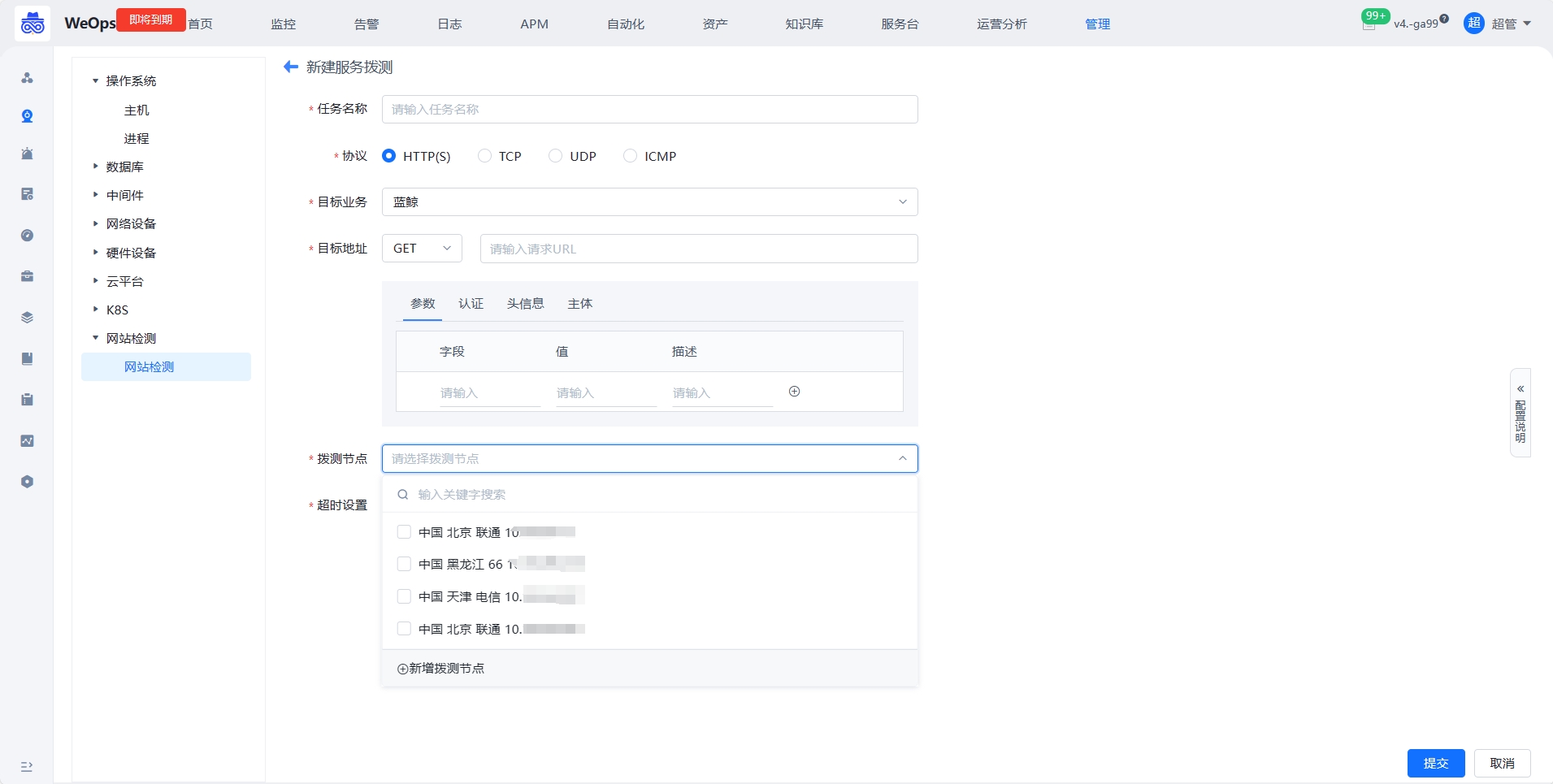
拨测节点配置完成后,可以在“监控管理-监控采集-网络监测”的任务中,选择并使用该节点。
监控管理
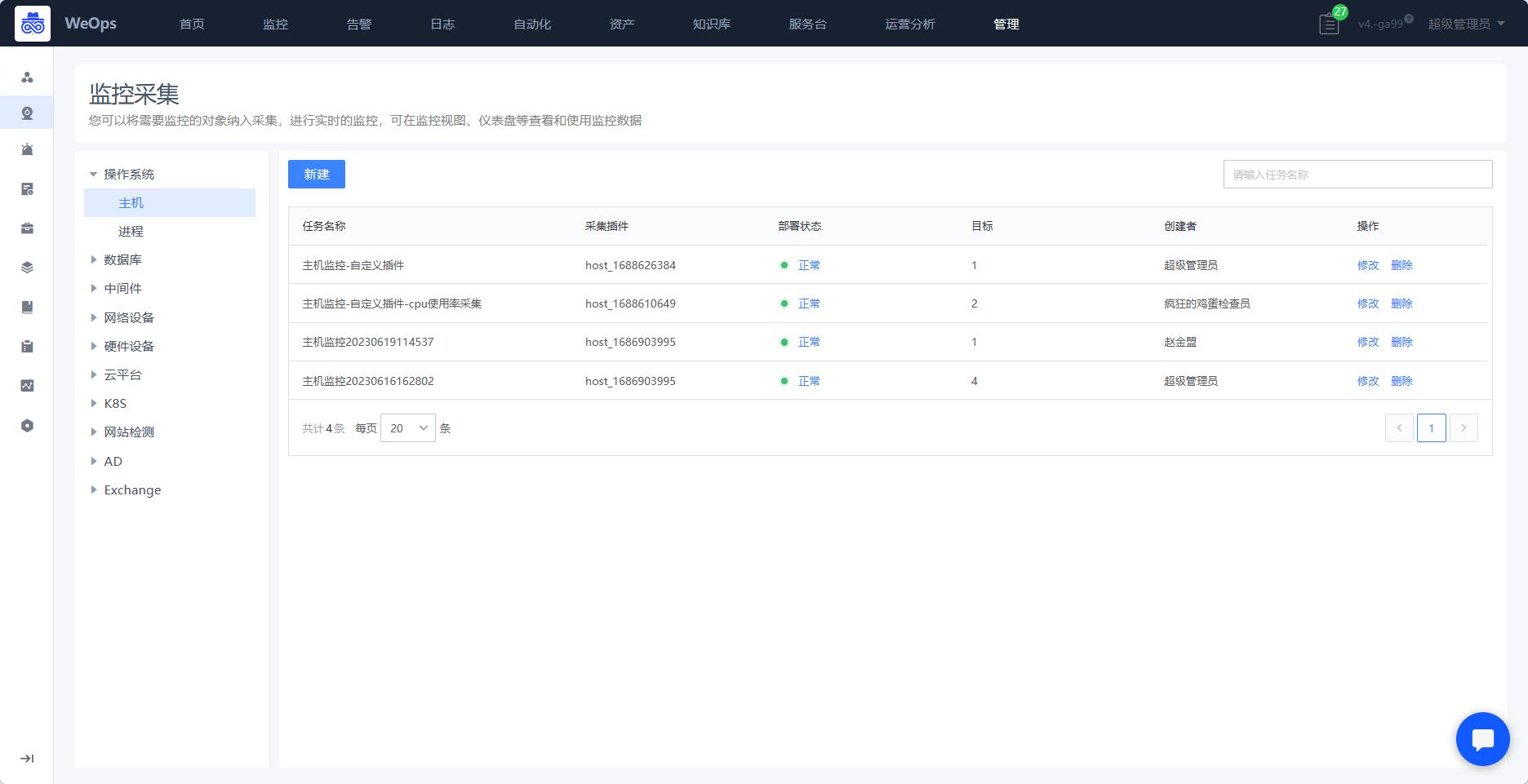
监控采集
- 用于将监控对象纳入采集,主要包括主机、进程、数据库、中间件、K8S、网站监测等等等。可选择不同的监控插件进行采集,支持本地采集和远程采集。
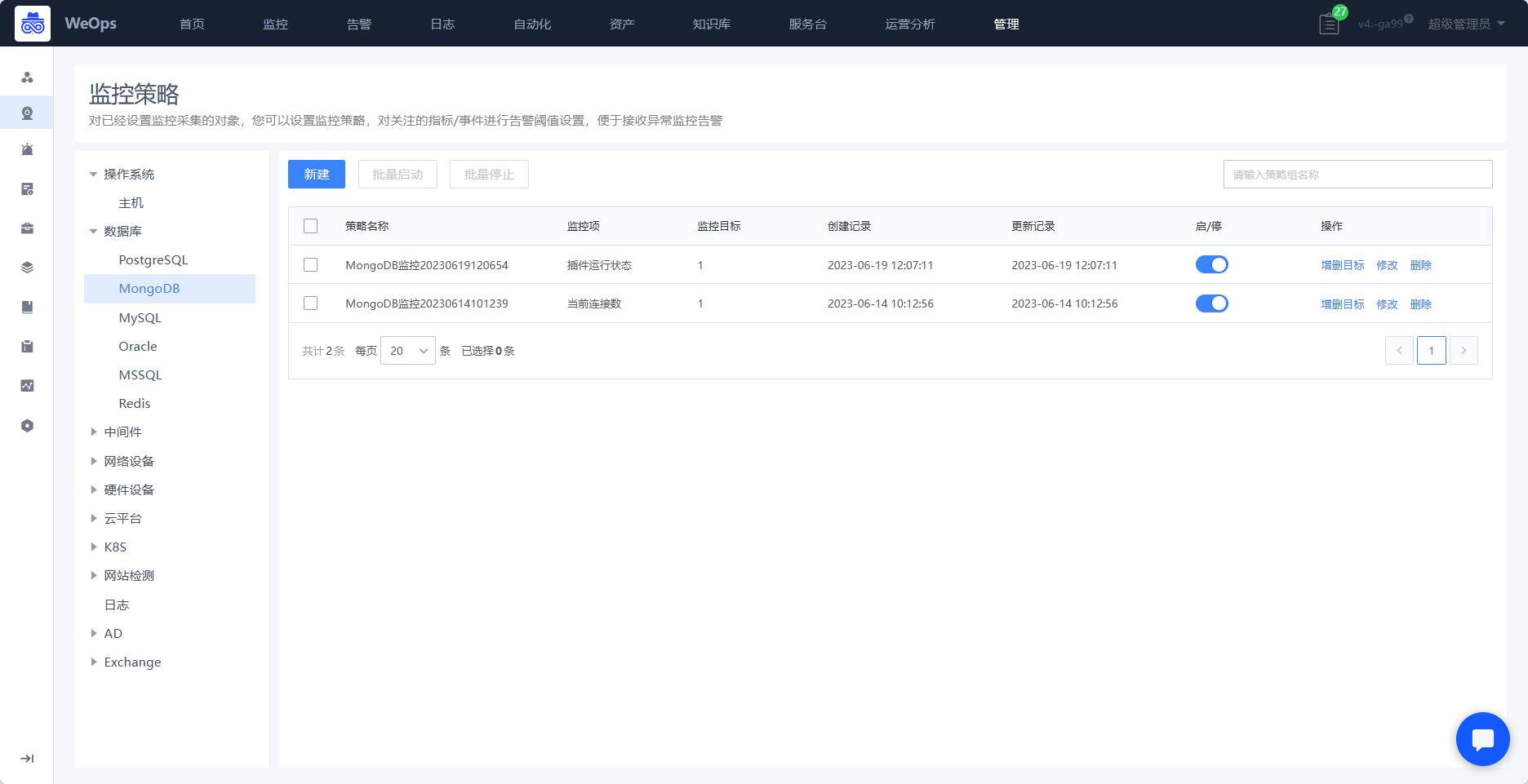
监控策略
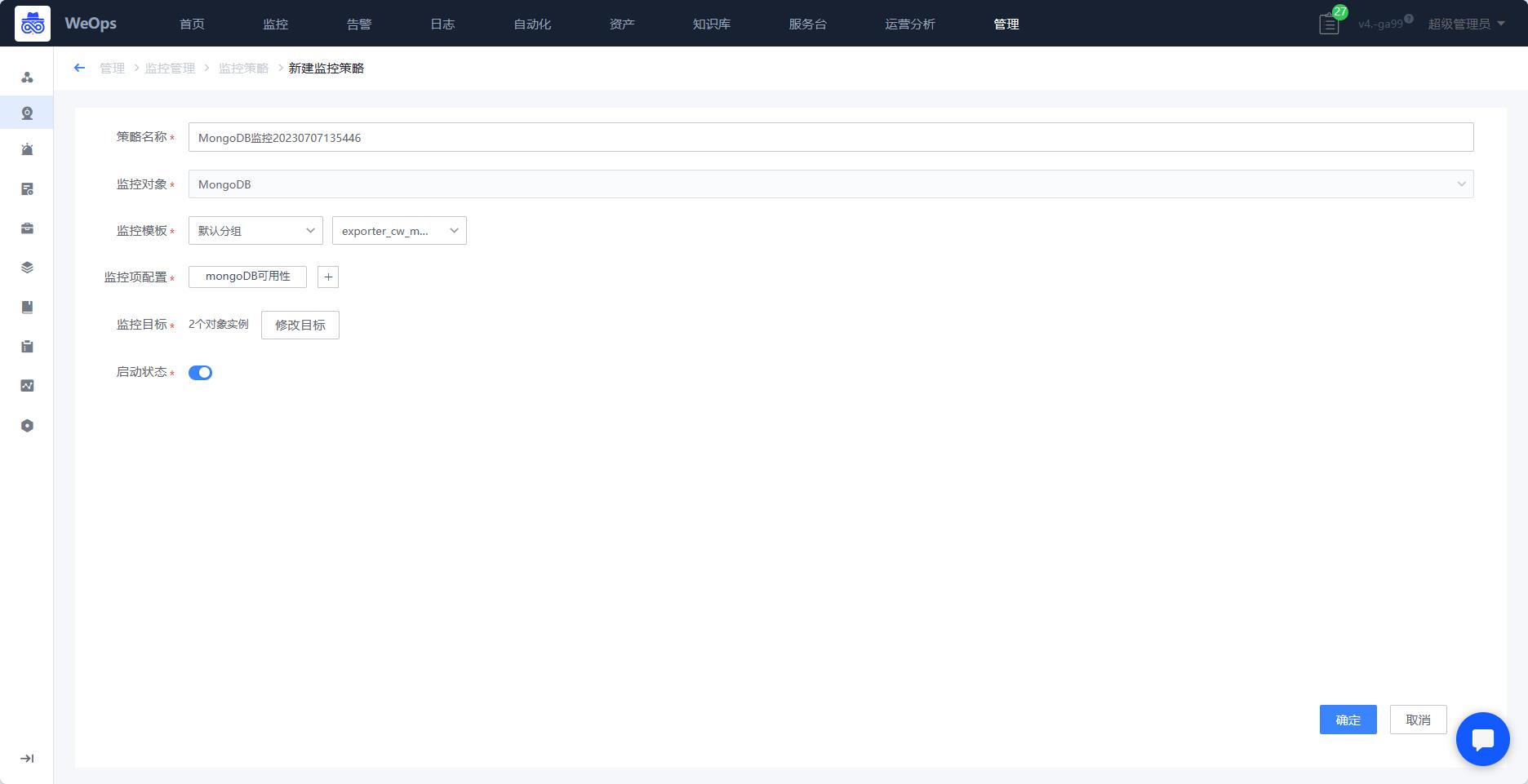
- 对主机、数据库、中间件、网络设备、服务拨测、虚拟化平台等进行告警阈值配置。新建监控策略,需要选择对应的监控目标,监控项配置、通知间隔等信息
监控对象
- 对WeOps的监控对象进行管理,支持监控对象的创建、分组和其他操作,新增的监控对象将在监控采集、监控策略、指标管理和监控视图等配置和显示。
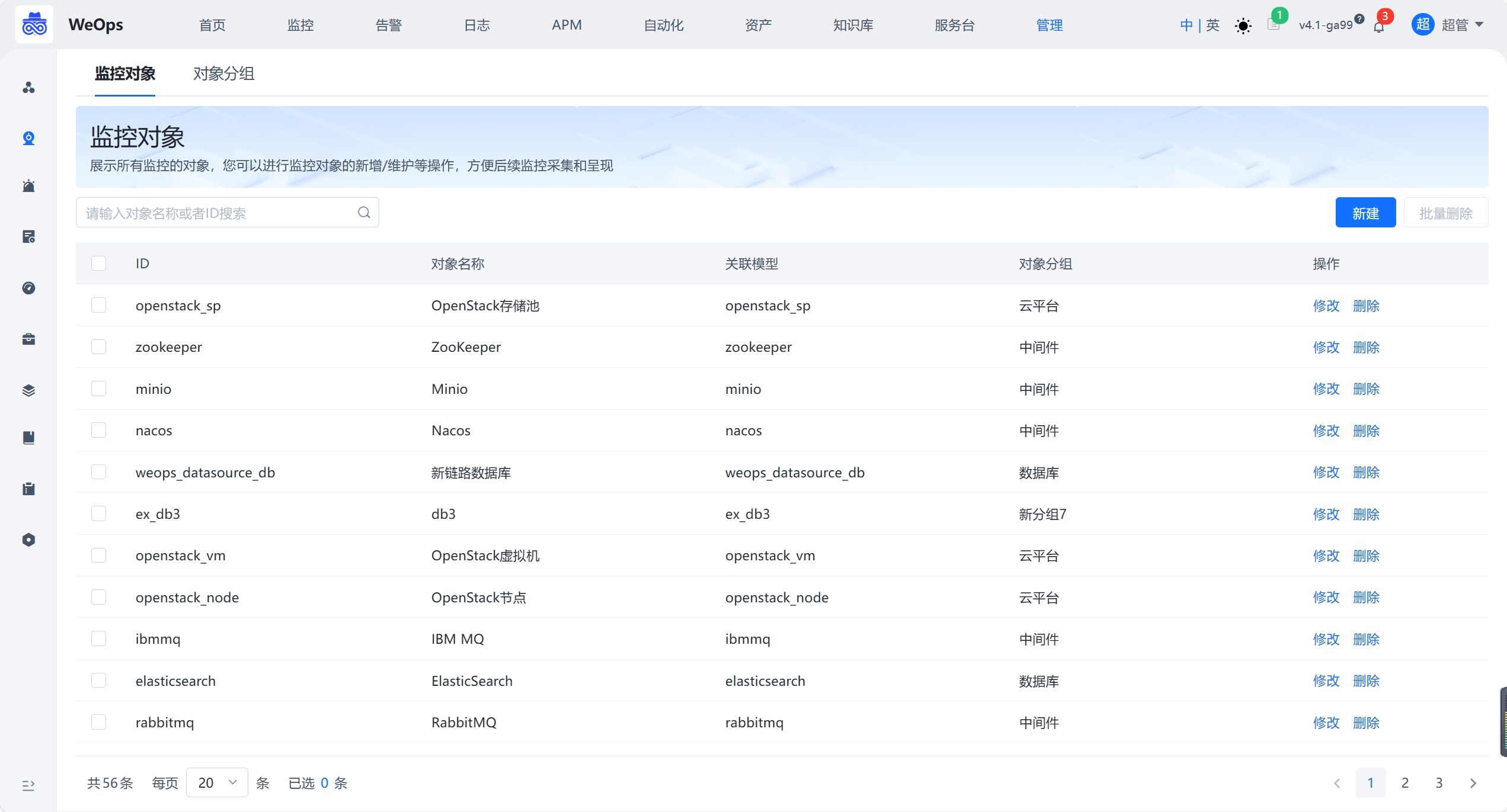
- 支持对监控对象创建分组,在监控视图、监控策略、监控采集等分组中生效。
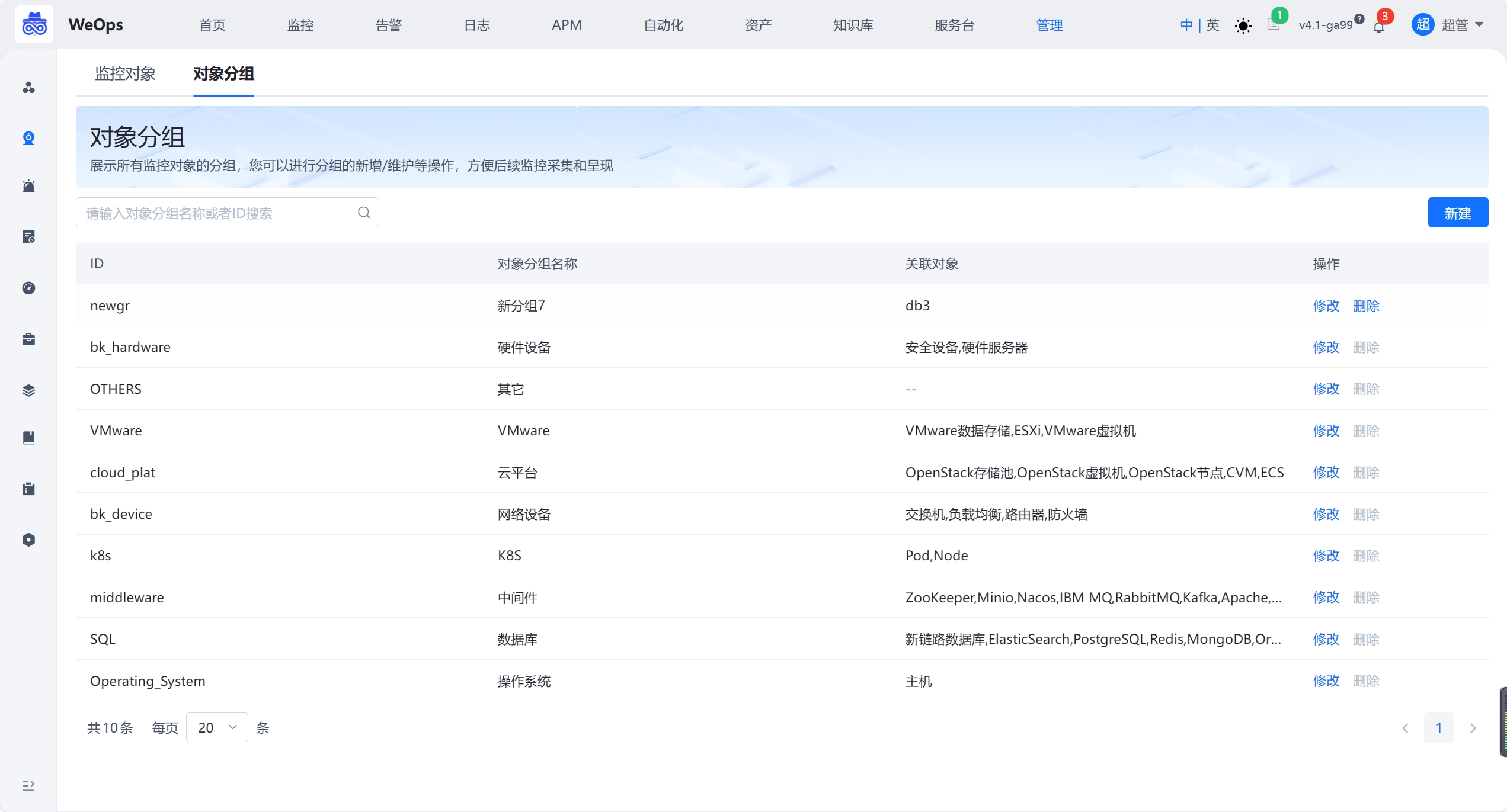
指标管理
- 对主机、数据库、中间件等各类对象的指标进行管理,可设置指标分组,可设置关键指标,支持对指标的阈值和描述进行修改。
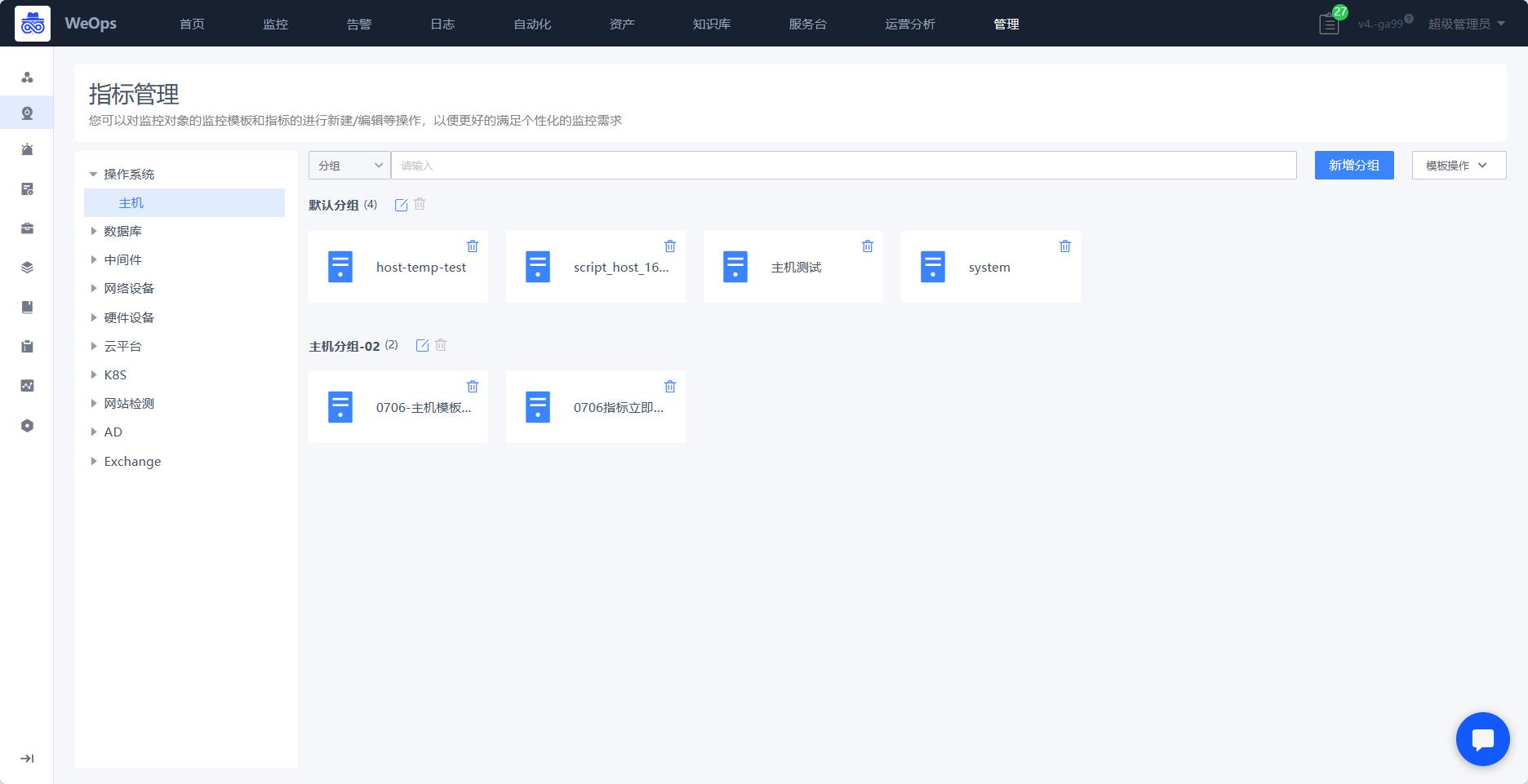
指标管理允许某些对象自定义新建监控模板,如下图,数据库支持SQL、shell和powershell、python类型的自定义监控插件;主机和中间件支持shell和powershell类型的自定义监控插件;网络设备和硬件设备支持snmp协议的自定义监控插件,若内置监控监控插件不满足监控需求,可通过自定义监控模板的方式进行新建
告警管理
告警处理
分为告警抑制、屏蔽策略、自动处理、自动分派,分别可以设置不同情况下告警的产生、通知的策略。
告警通知
用于配置告警通知的策略,包括未响应通知策略、未分派通知策略、通知内容模板设置、用户默认通知方式等。

通知模板:通知渠道管理,支持自定义通知内容,支持对内置的几类模板修改,每种模板下的邮件、短信、企业微信和电话四种渠道都支持修改标题和内容
人员通知
人员通知:可针对不同的用户配置不同的通知方式。

告警源
- 告警源:展示WeOps目前可以对接的告警源,可对告警源进行启用和管理。
自动化管理
WeOps的自动化管理支持运维工具的自定义,扫描包的设置,网站设备脚本模板的设置。
- 运维工具:对WeOps的运维工具模块进行管理,支持操作系统和网络设备两大类运维工具的新增/修改/启停/删除等操作
- 健康扫描:对WeOps健康扫描中的扫描包进行管理,包括以下操作:新增扫描包、对现有的扫描包检查项进行编辑和启停、设置默认参数。
- 扫描包的自定义和使用详见《操作手册-自动化运维——健康扫描》
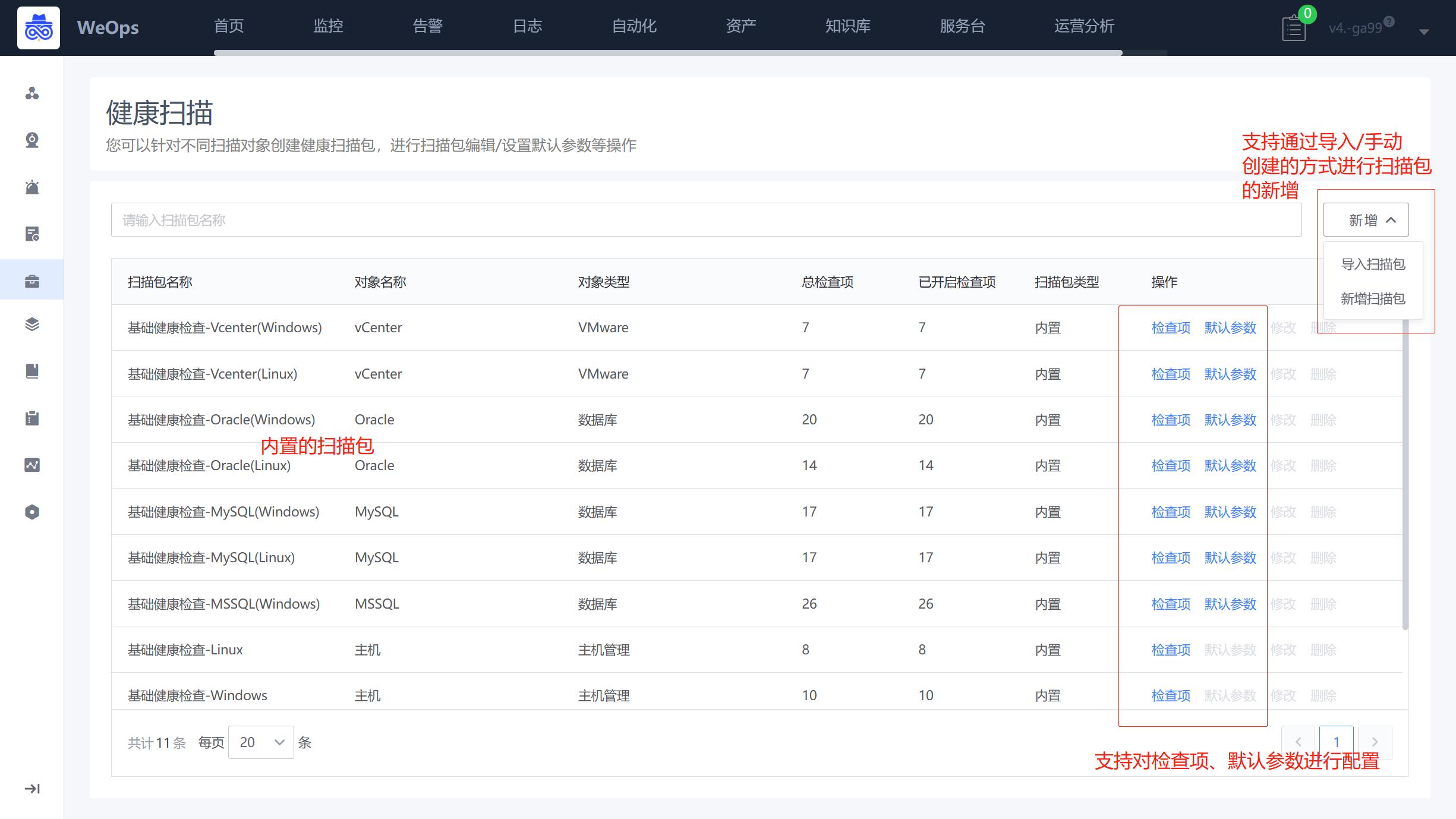
- 网络设备模板:可以针对网络设备的自动化执行设置执行结束语,支持思科/新华三/华为常用品牌
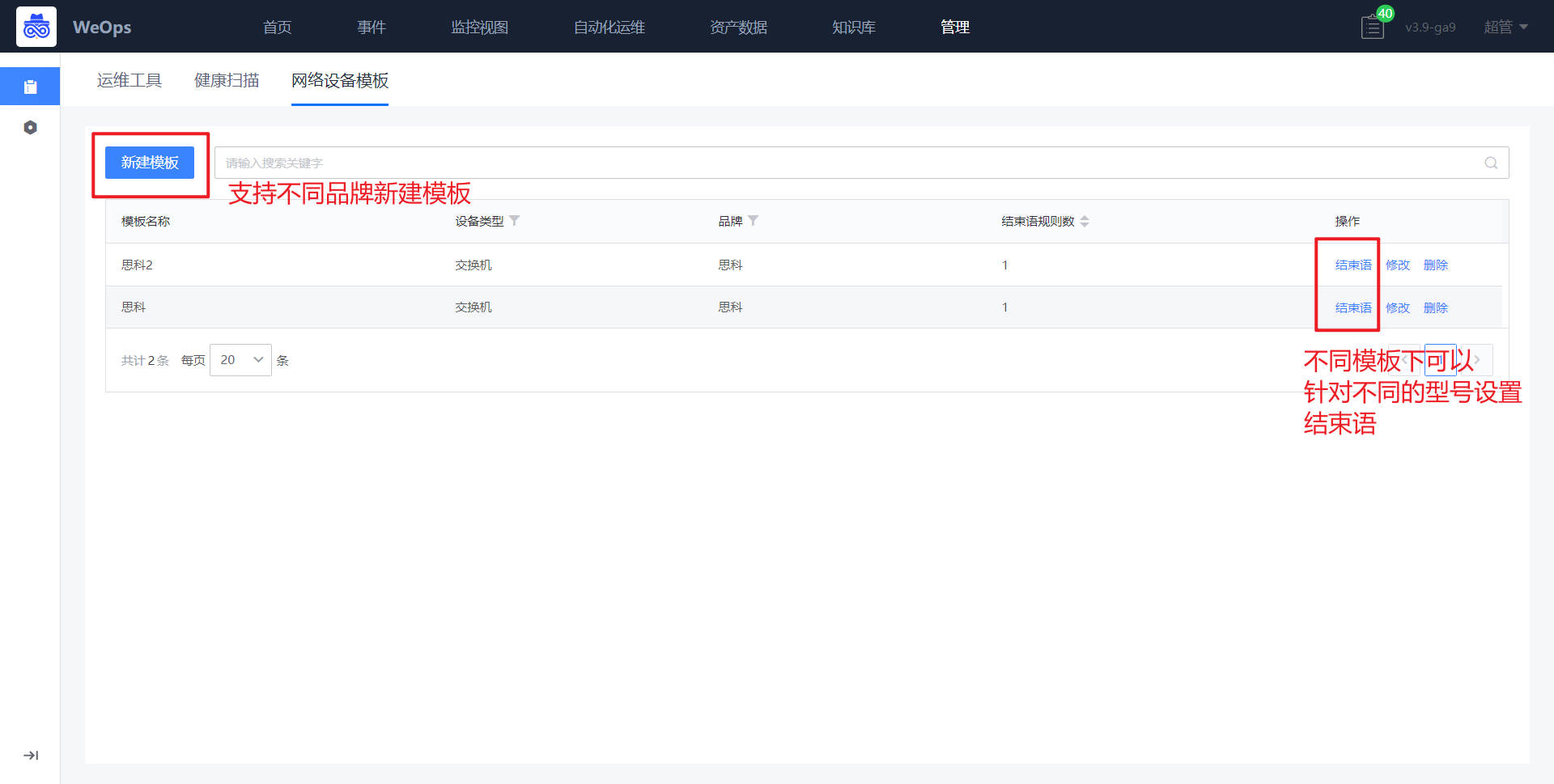
- 自动化编排:流程页面展示了所有的流程列表,支持搜索、新建流程、编辑流程、预览流程、设置“告警自愈流程”、查看执行历史、删除等操作。
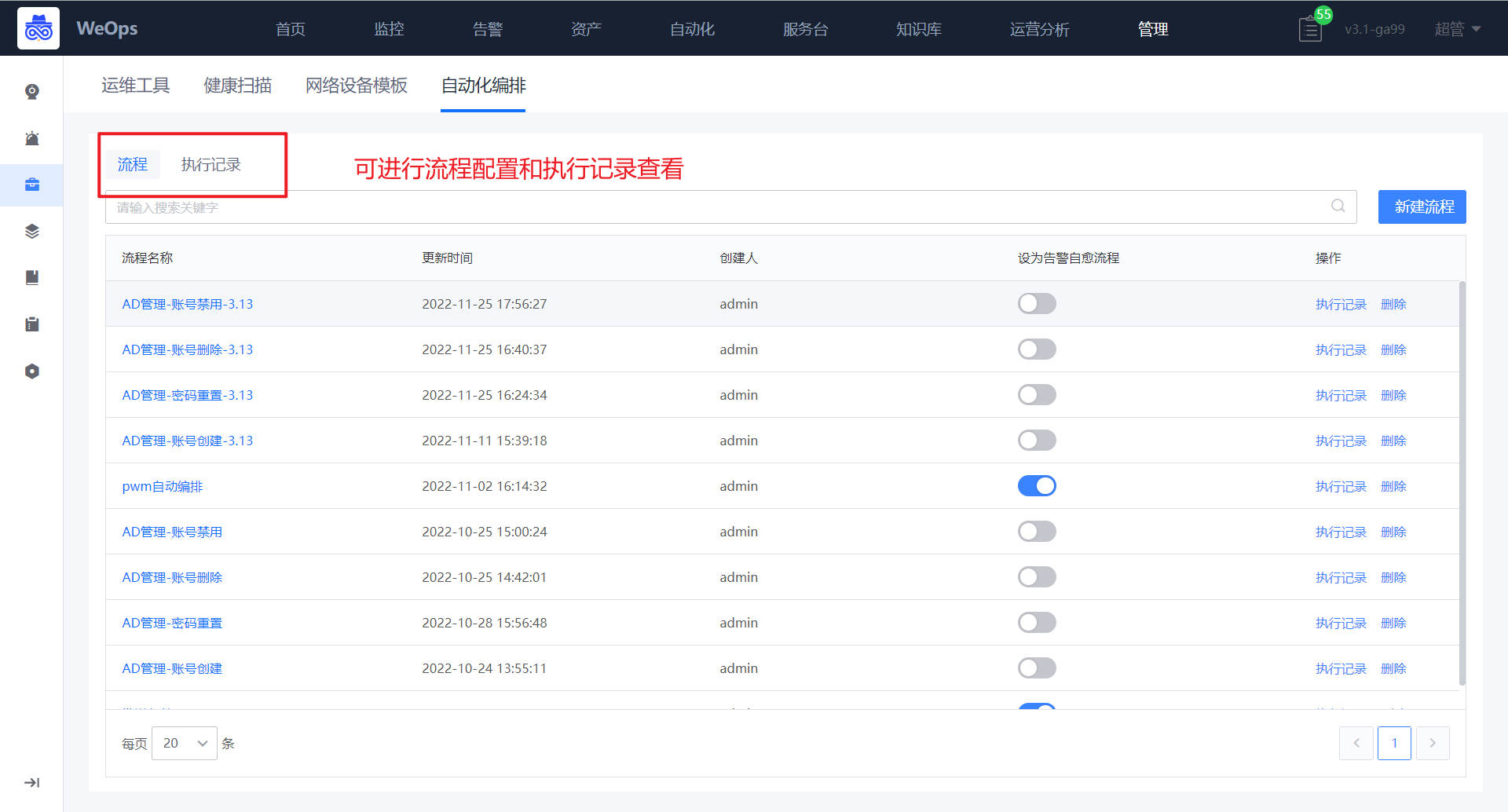
- 可视化任务流程配置。新建流程时,用户可以通过图形界面进行任务流程编排。在编排页面,用户可以通过左侧的工具栏来添加节点
- 任务历史可追溯,用户在任务记录页面,可以追溯之前的任务执行情况,可以对历史记录进行搜索,查看详情等操作。

资产管理
资产管理包括“资产模型管理”、“自动发现preview”、OID库、数据关联
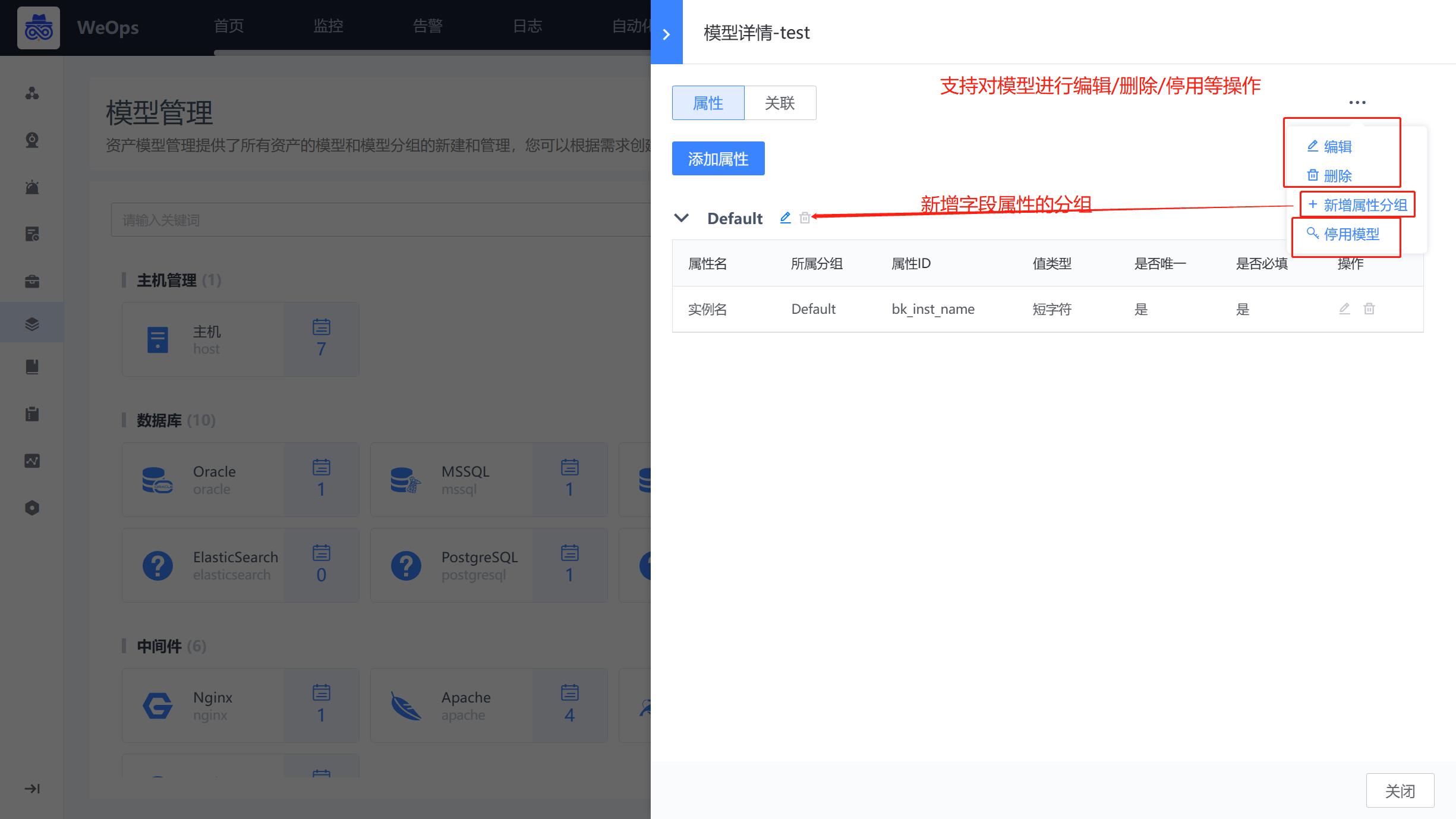
模型管理
- 资产模型管理提供了WeOps所有资产的模型和模型分组的新建和管理,支持以下操作:模型分组的增删改查(内置模型分组不允许删除)、模型的增删改查(内置模型分组不允许删除)、模型属性字段分组的添加、模型的属性字段的添加/编辑、模型之间关联关系的添加/编辑。
- 关于资产模型更为详细的配置和使用详见《操作手册-其他配置-资产模型配置》

资产扫描
资产扫描的场景如下:纳管层面,资产扫描是从空白到扫描出来有资产的,配合配置采集自动更新配置信息;安全层面,全量扫描不在cmdb的资产的异常ip;运营层面,扫描ip不在管理范围内的,进行ip认领或者回收
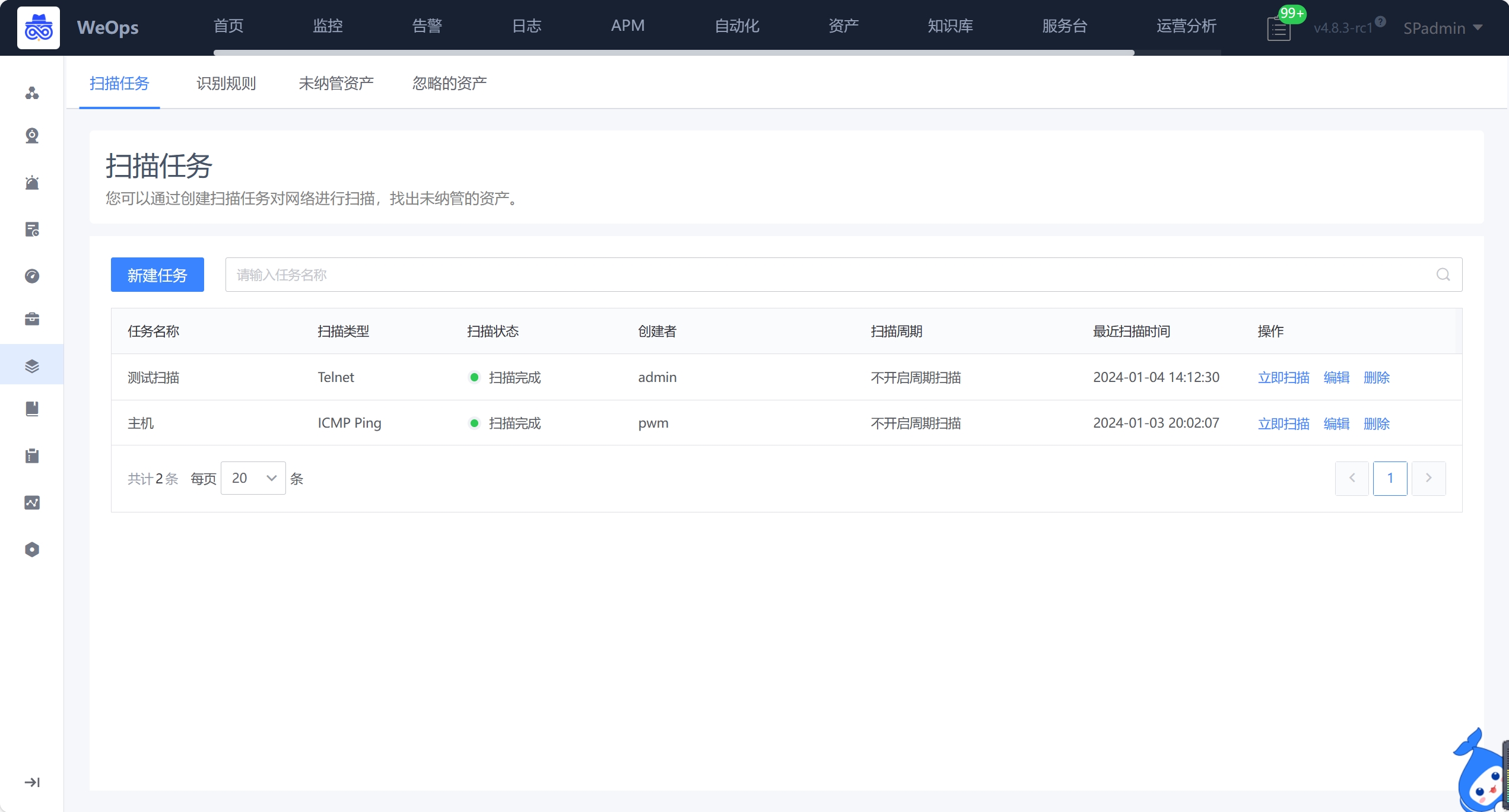
包括扫描任务的创建、识别规则、未纳管资产和忽略资产。
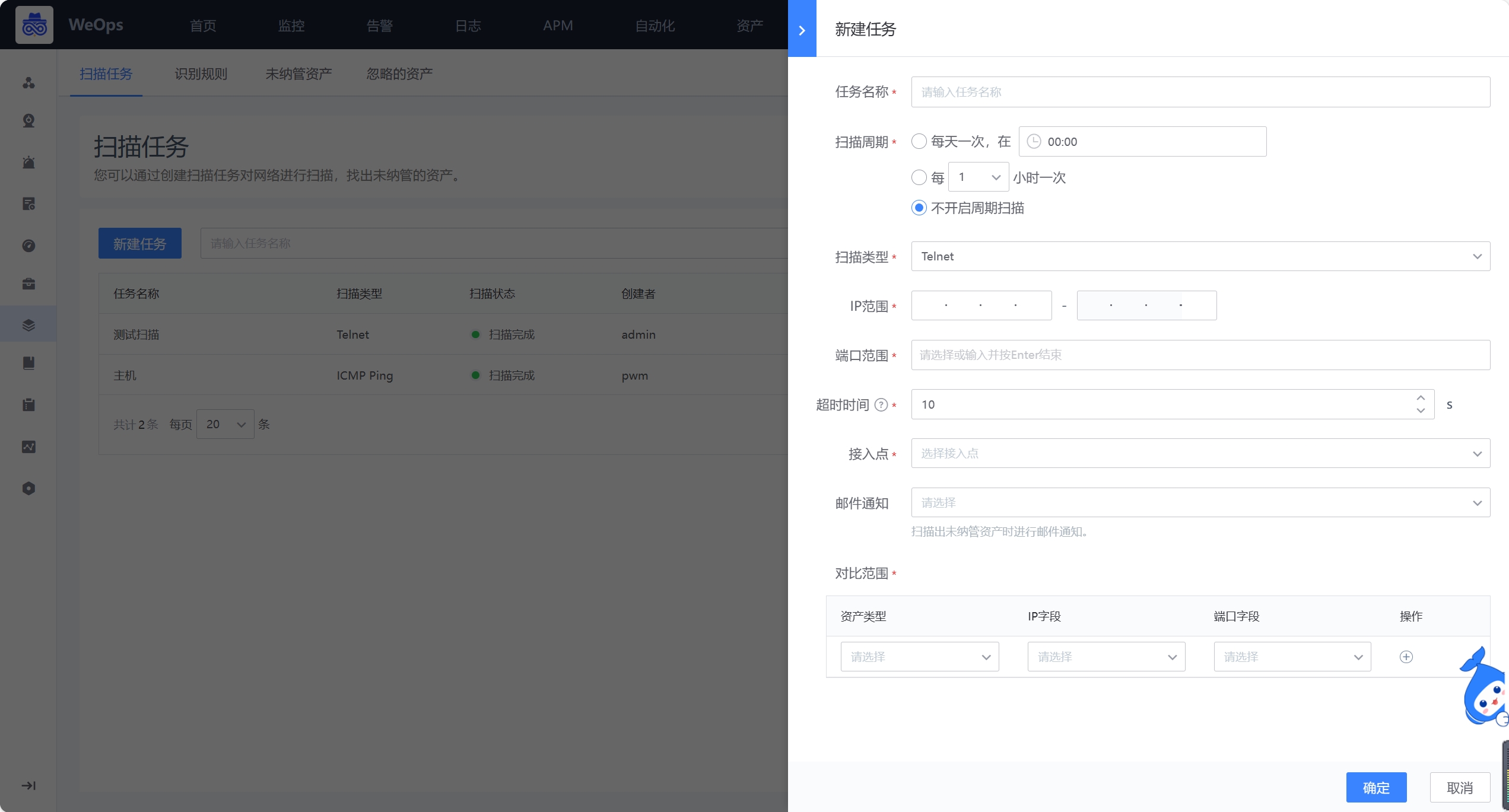
- 扫描任务,如下图,支持资产扫描任务的创建,可设置IP扫范围,支持ping(IP)、telnet(IP+端口)从网络中发现IT资产,支持配置CMDB的对比范围,进行对比。安装扫描的协议扫描出来的资产,会根据cmdb的资产范围进行对比,未纳管的资产,会呈现在“未纳管”列表中。
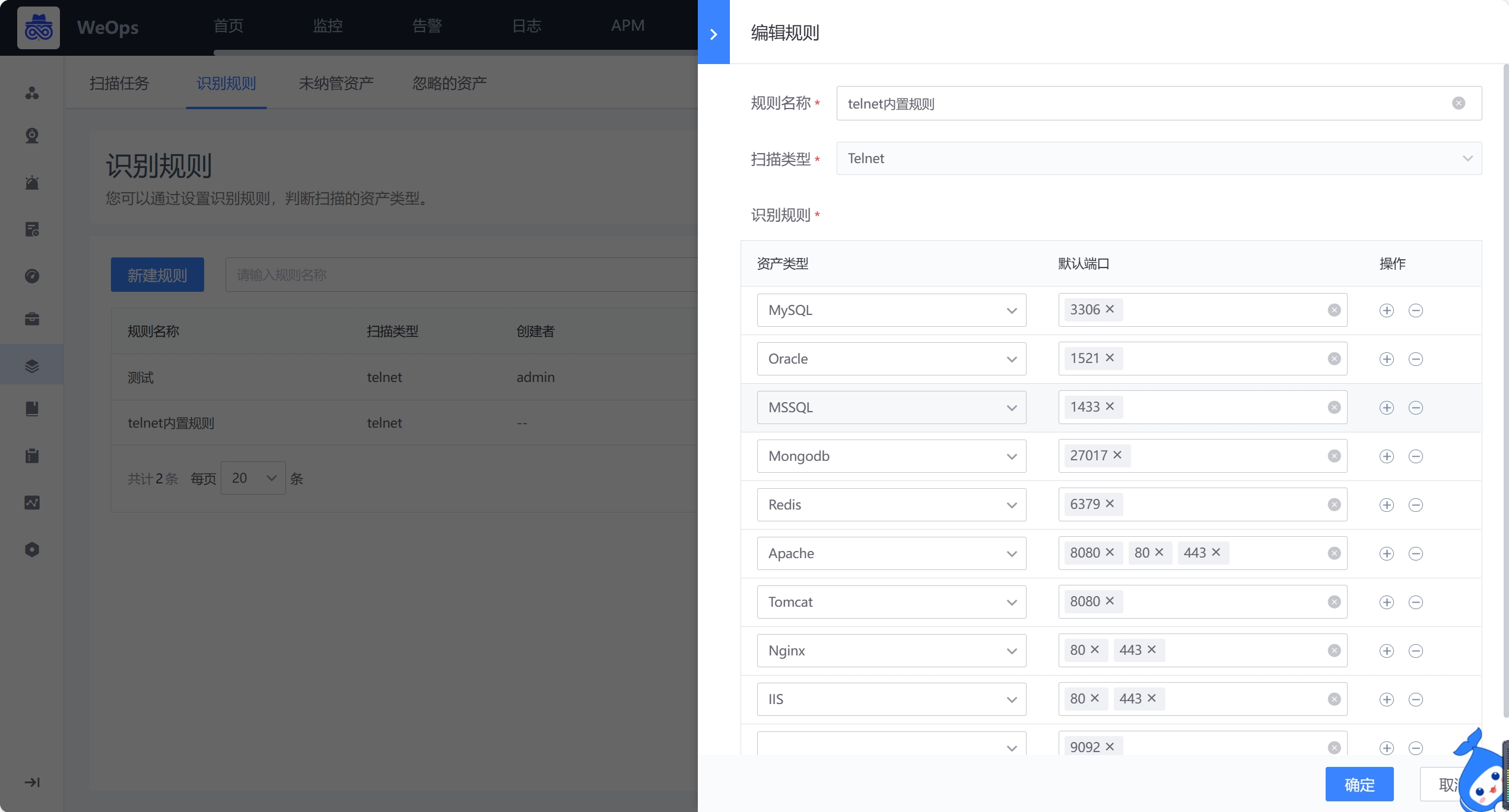
- 识别规则,支持设置Telnet的识别规则
- 未纳管资产,扫描的结果中,和cmdb对比后,cmdb没有纳管的资产会呈现在列表中,并按照识别规则展示资产的类型,对于未纳管的资产,支持一键纳管至cmdb中

配置采集
- 配置采集支持K8S/网络设备/数据库/云平台/SSL证书/配置文件等的自动发现,可通过新建任务的形式,创建自动发现和采集任务并执行
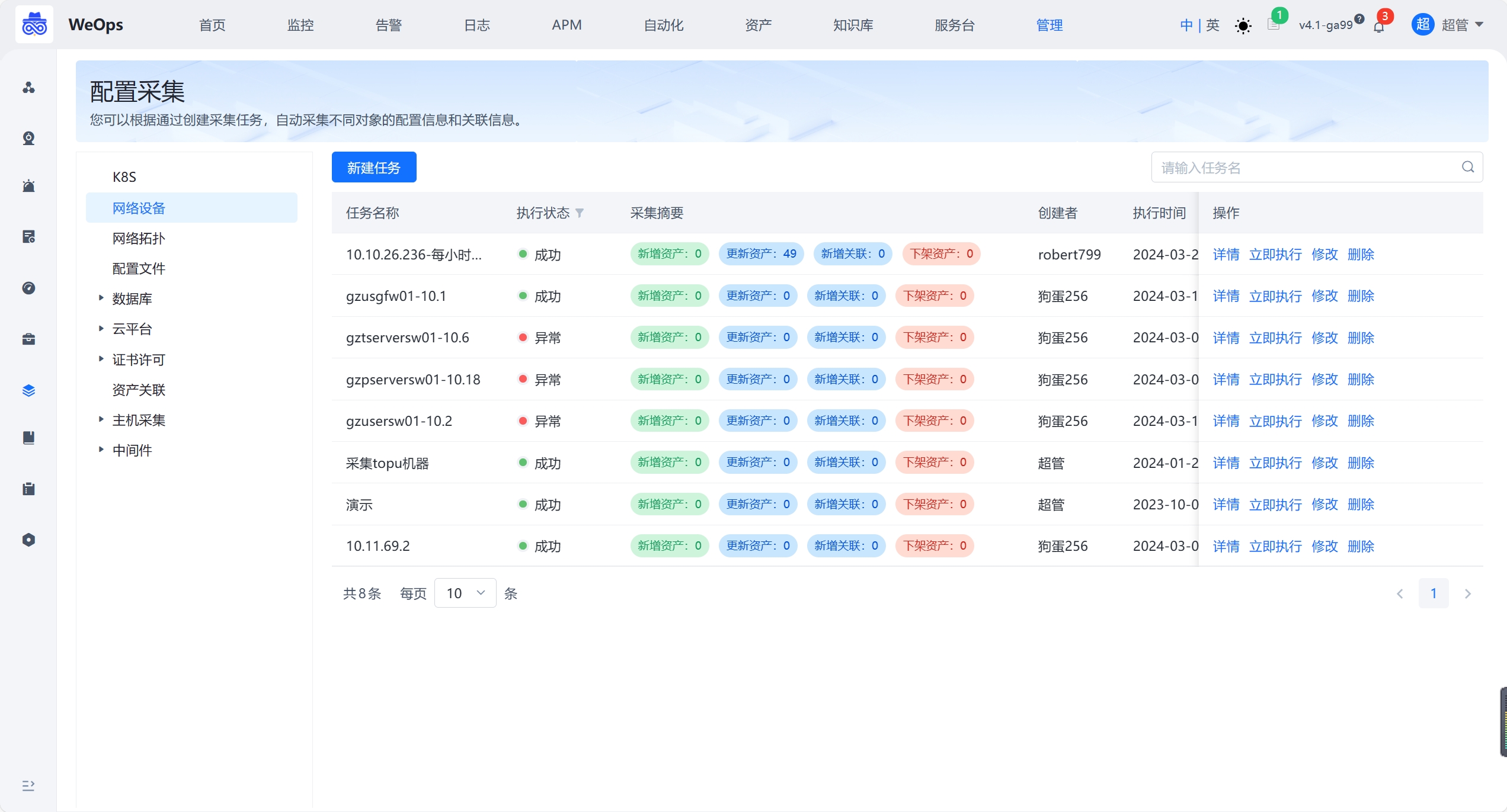
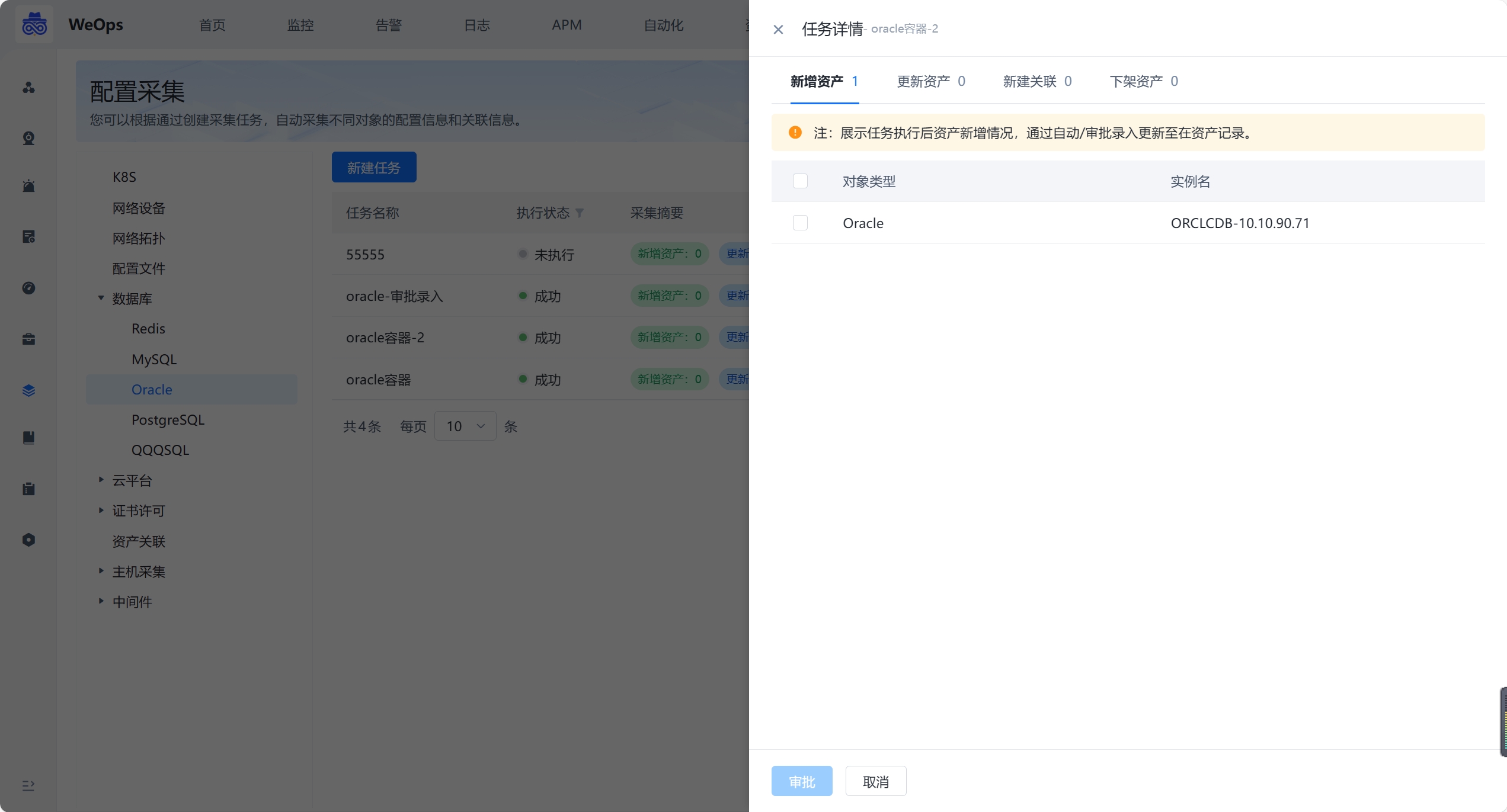
- 对于配置采集情况分为:新增资产、资产更新、新增关联和下架资产,支持查看详情。针对新增资产的情况可以设置“自动录入”和“审批录入”两种方式,通过审批后,新增的资产才可正式录入资产记录中。
- 关于数据库的自动发现和纳管,详见《操作手册-资源纳管配置-数据库/中间件纳管》
- 关于网络设备的自动发现和纳管,详见《操作手册-资源纳管配置-网络设备纳管》
- 关于云平台的自动发现和纳管,详见《操作手册-资源纳管配置-云平台纳管》
- 关于K8S的自动发现和纳管,详见《操作手册-资源纳管配置-K8S纳管》
- 关于SSL证书的自动发现和纳管,详见《操作手册-资源纳管配置-SSL证书纳管》
- 关于配置文件的自动发现和纳管,详见《操作手册-资源纳管配置-配置文件纳管》
- 关于资产关联的自动发现,详见《操作手册-资源纳管配置-资产关联》
- 关于IP的自动发现,详见《操作手册-资源纳管配置-IP》
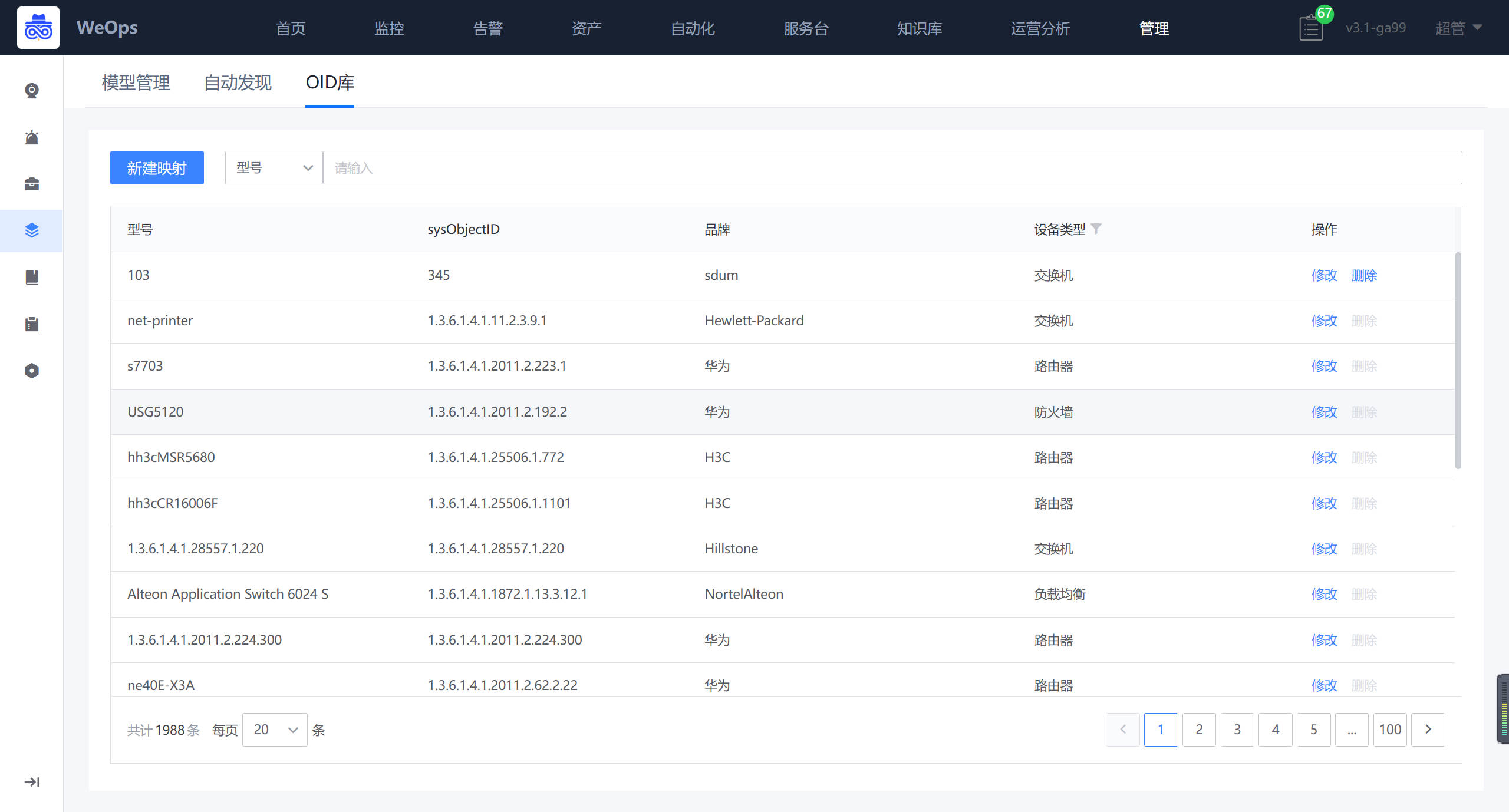
OID库
- OID库支持对网络设备自动发现和采集的设备类型的扩充,将需要自动发现的网络设备的OID和品牌、型号进行映射保存,即可支持对该品牌型号的网络设备的自动发现和采集。
数据关联
- 支持资产实例与日志数据相关联,关联后,可在资产详情/监控视图/告警详情等快捷查看资产相关联的日志信息

知识库管理
知识库管理是对知识库的文章标签和文章模板进行新建和管理。
日志管理
日志管理主要是对日志进行相关配置
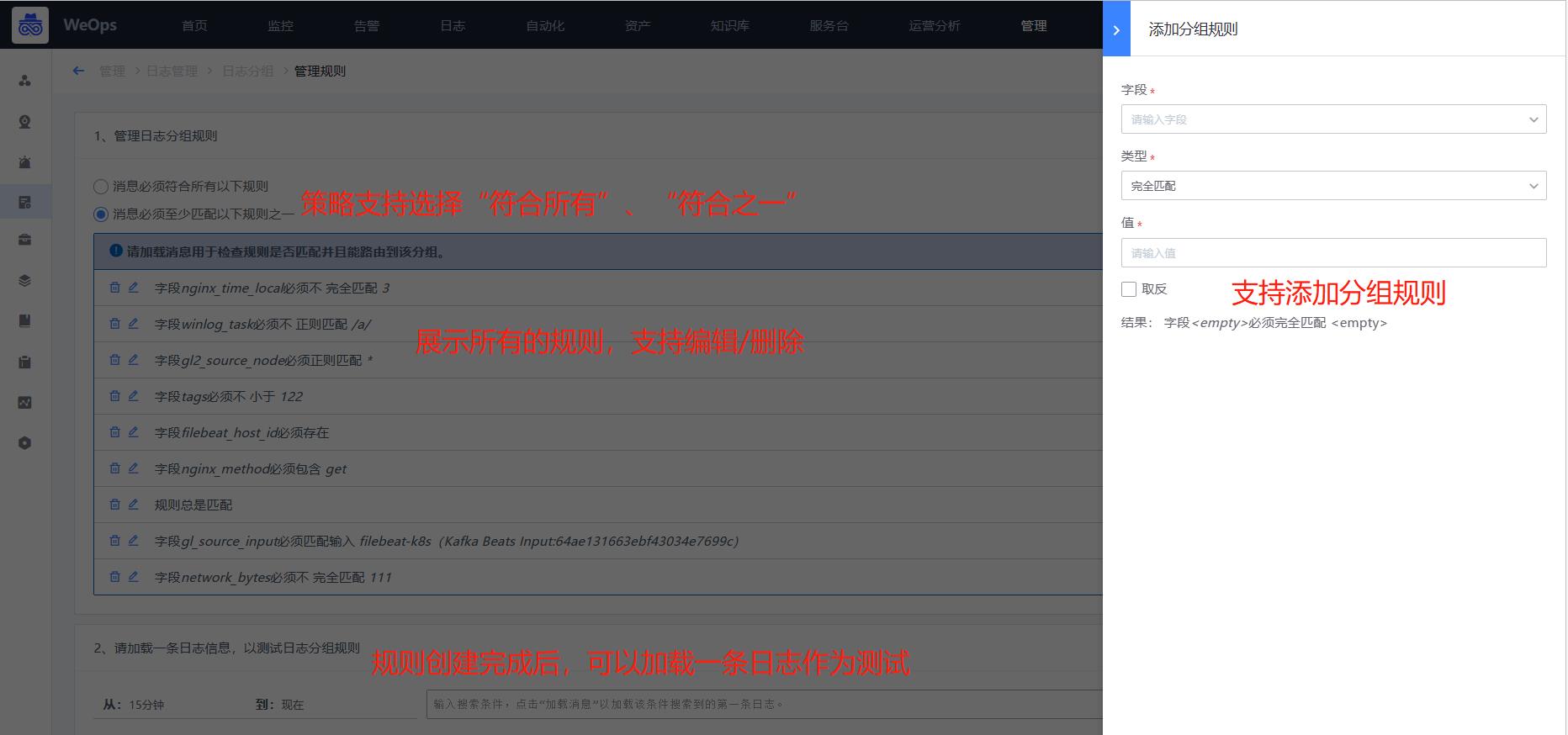
日志分组
- 支持对日志消息进行分组管理,对日志的分组设置分组规则,当满足这一规则的时候,日志将划为这个分组,并通过角色管理-日志分组授权给对应人员搜索/使用。

- 分组规则:一个分组支持多个分组规则,可以在分组中进行创建和管理
- 日志分组的详细介绍步骤详见《操作手册-3、日志设置-日志分组配置》
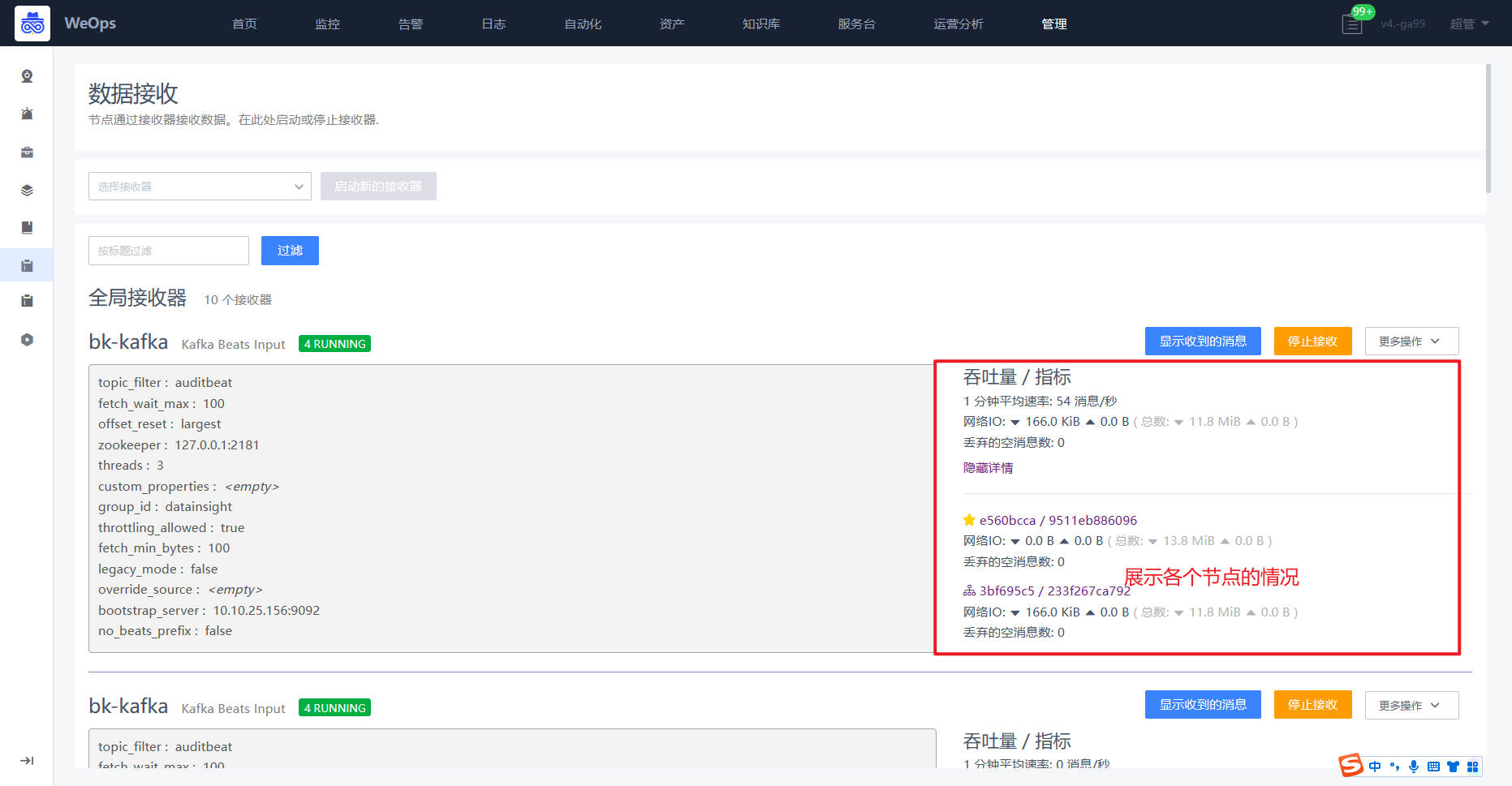
数据接收
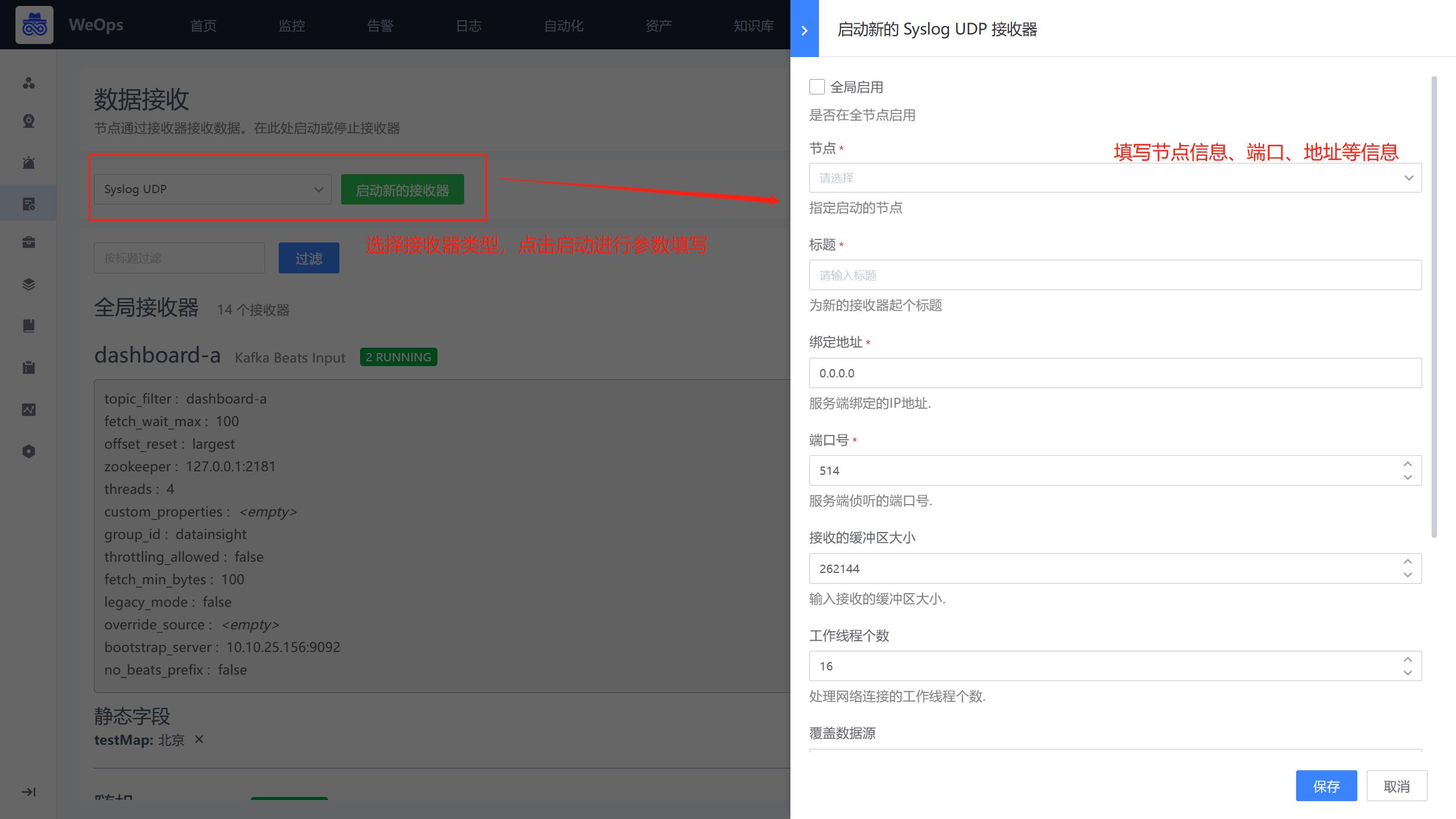
- 展示所有支持的接收器,可以进行相关日志数据的接收配置,并展示所有接收器的基本情况。
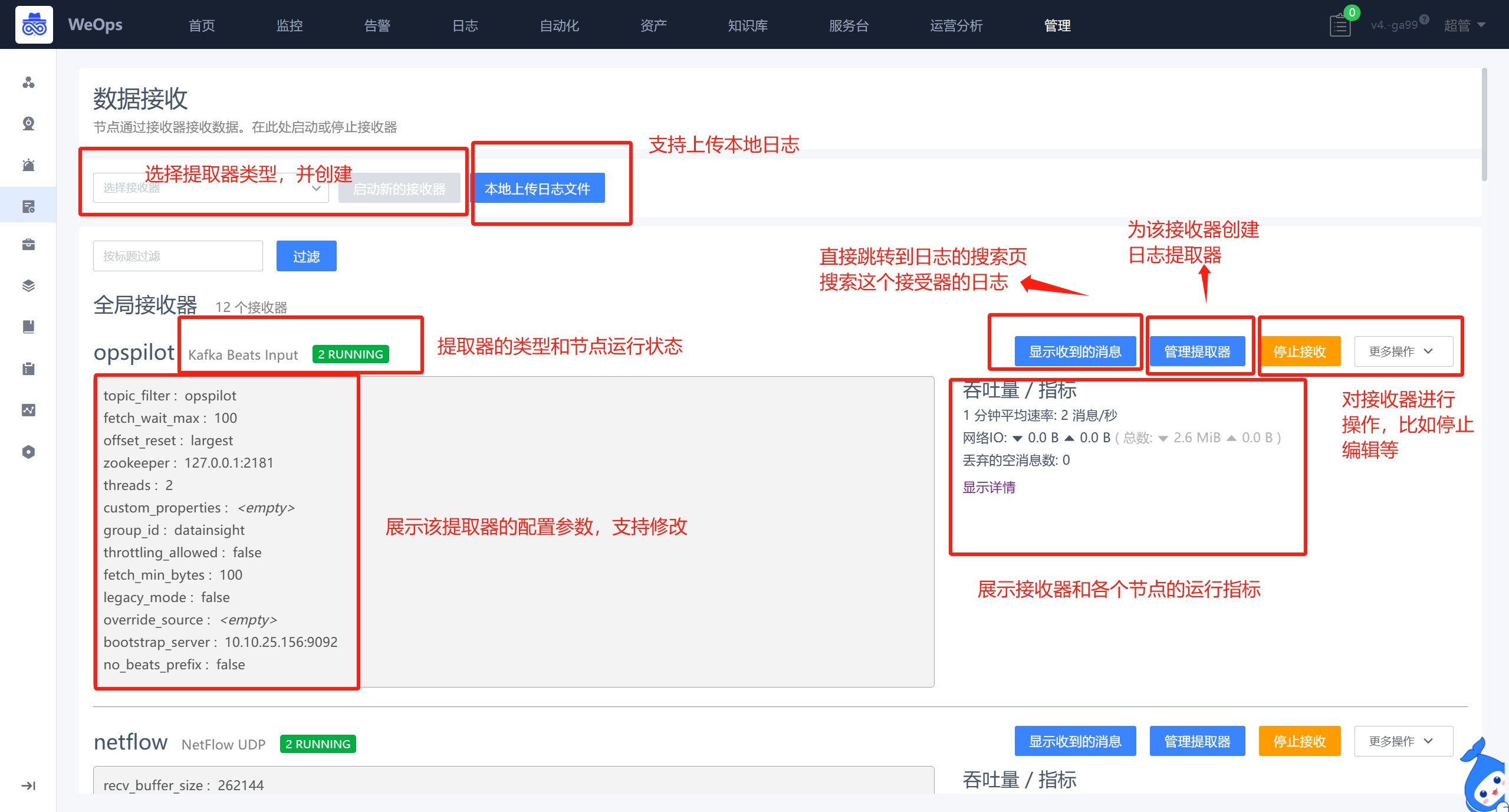
- 根据实际需求,选择适用的提取器进行创建,比如选择syslog UDP提取器对交换机的日志进行提取,填写对应的端口等信息,并启用
- 支持为每个接收器创建提取器,选择提取的字段,为该字段选择适用的提取类型,设置提取规则并保存为新字段,以便后续使用。
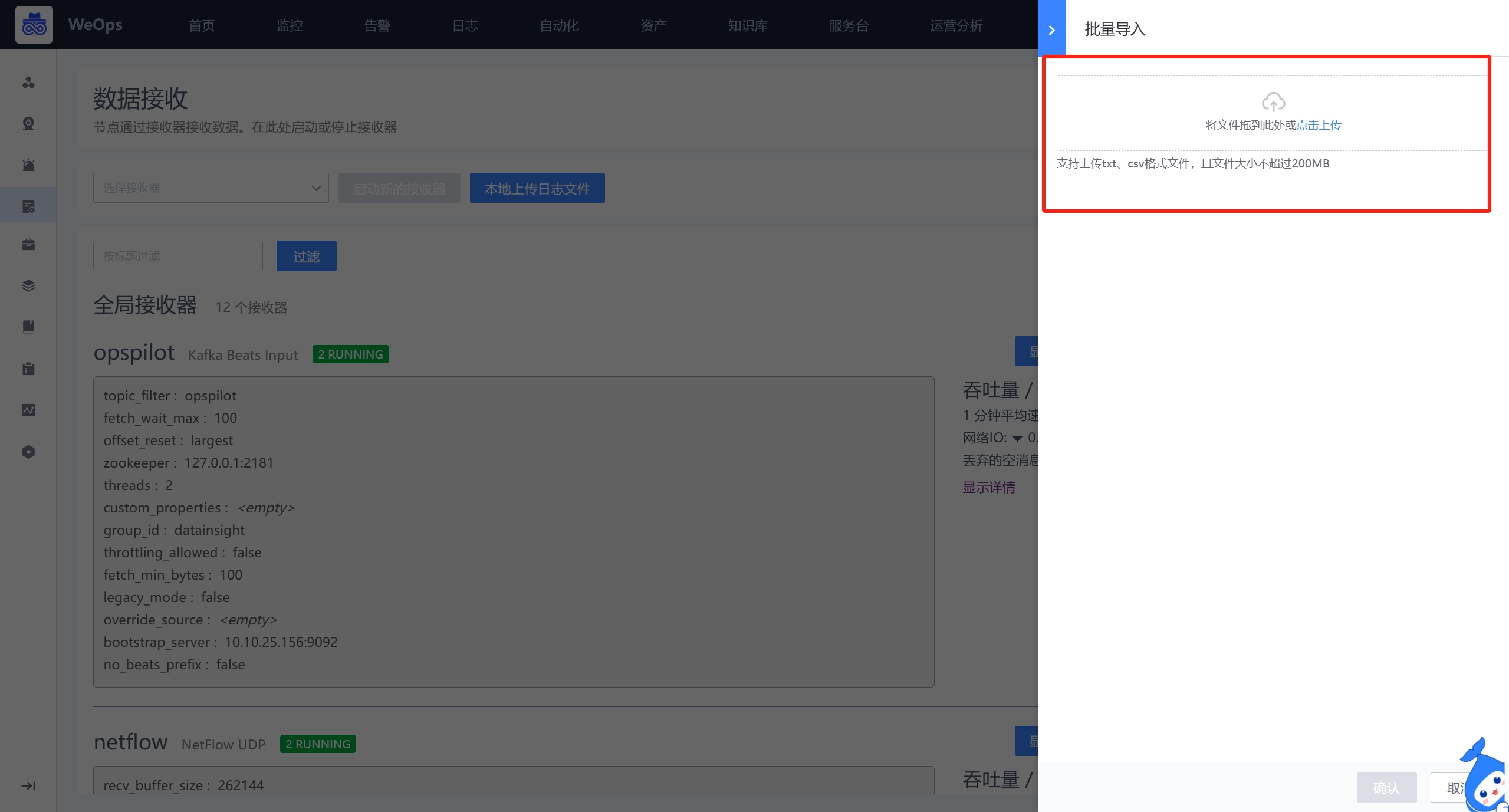
- 支持导入本地的日志,支持的格式txt和CSV格式
- 日志数据接收的相关配置步骤详见《操作手册-3、日志配置-日志数据接入(syslog协议)》
- 日志提取器的详细配置详见《操作手册-3、日志配置-日志提取器配置》
日志监控
- 展示所有日志监控策略,支持日志策略的新建/编辑和启停等操作
- 设置监控告警策略:根据业务需求,设置告警规则,如错误码出现次数、异常信息出现频率等,当监控到的日志数据符合告警规则时,自动发送告警通知,通知相关人员及时处理问题。
- 日志分组的详细介绍步骤详见《操作手册-3、日志设置-日志监控告警配置》
索引集
- WeOps为了存储日志原始数据,降低资源消耗,支持设置日志索引集,可以为每个索引集设置轮转规则,形成一组索引,即对应 Elasticsearch的索引分片。
- 如下图,是索引集列表页面,展示了所有的索引集的信息,点击进入,可以查看这个索引集的详细信息和索引信息。

- 索引集详情页如下图。

索引集操作:新建索引(手动循环此索引集上的当前活动写入索引);更新索引范围(使用后台系统作业重新计算此索引集的索引范围);编辑索引集(编辑索引集的信息,包括索引基础信息/轮转规则/操作配置等)
索引列表:展示这个索引集的各个索引的基本信息,并标明“当前可写入索引”(当前可写入索引不能被关闭和删除),其他索引(支持重新计算该索引的索引范围,支持手动关闭/删除)- 新建索引集,设置索引集的规则

标题:索引集的描述性名称
描述 :索引集的描述
索引前缀:用于由索引集管理的 Elasticsearch 索引的唯一前缀。前缀必须以字母或数字开头,并且只能包含字母、数字和支持的字符。
分词器 :(默认值standard)索引集的 Elasticsearch 分析器
索引分片:(默认值4)每个索引使用的 Elasticsearch 分片数量
索引副本:(默认值0)每个索引使用的 Elasticsearch 副本数
最大段数 :(默认1)ElasticSearch强制合并的段数量
轮转后索引优化:在索引轮转后禁用
字段类型刷新间隔:(默认5秒)多久刷新活跃索引的字段类型
轮转规则:支持按照索引时间/索引记录数/索引时间进行轮转,可设置轮转周期
轮转操作:轮转后的索引操作,包括删除索引,关闭索引/不操作。- 索引集创建完成后,日志分组支持选择存储到的索引集,并按照索引集的规则进行日志数据的轮转。

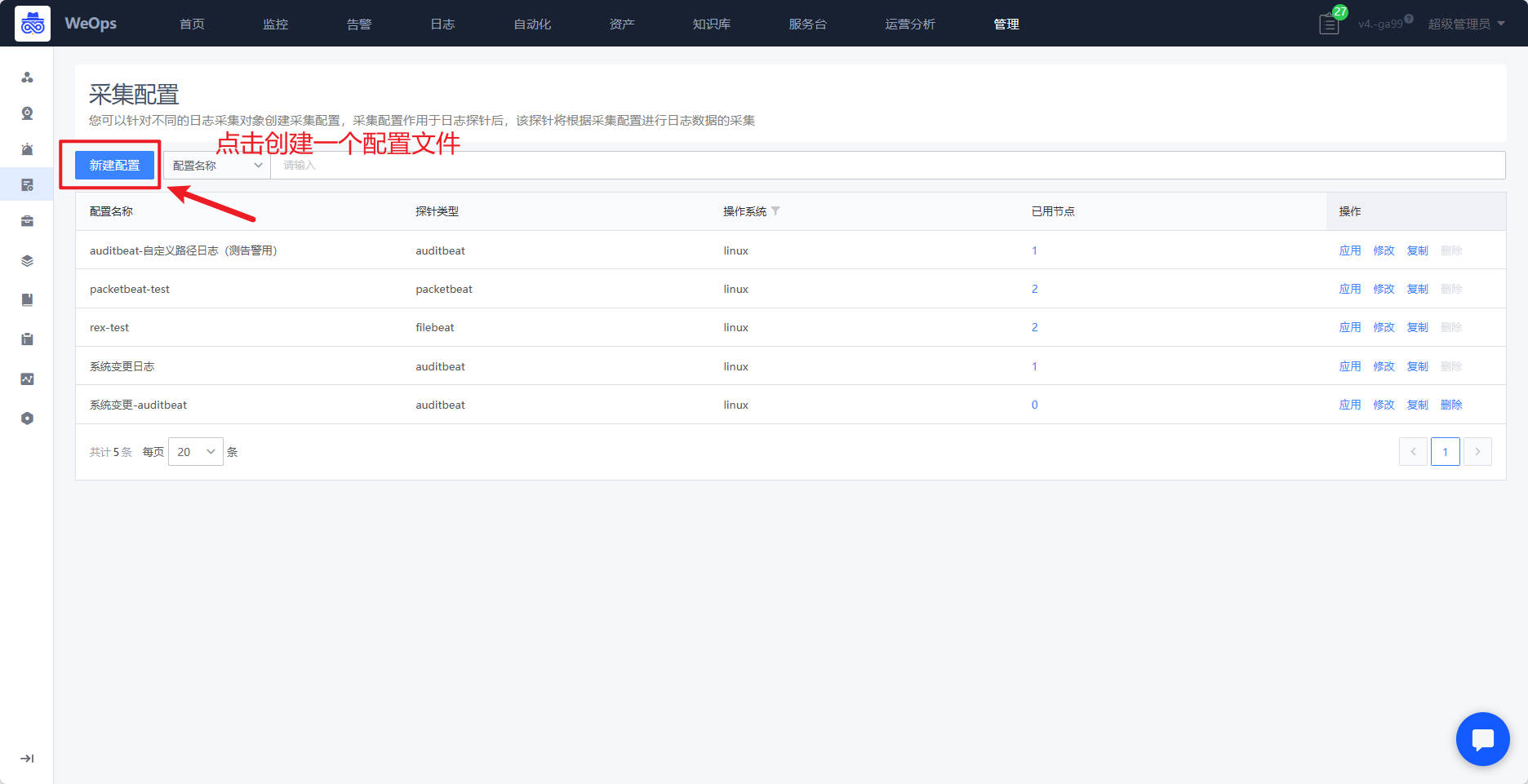
采集配置
- 可以针对不同的日志采集对象创建采集配置,采集配置作用于日志探针后,该探针将根据采集配置进行日志数据的采集
- 目前已经内置5类探针的数十种配置文件,可以根据需要采集的日志配置文件,进行采集
- 探针类的日志数据接入步骤详见《操作手册-3、日志设置-日志数据接入(探针模式)》
日志备份
- 日志数据的冷热分离是一种常见的数据管理策略,用于优化存储和检索大量日志数据,WeOps将日志数据分为两个类别:热数据和冷数据,并将它们存储在不同的存储介质上,可以实现更高效的存储和检索,同时减少存储成本。
- WeOps配置日志存储,并支持日志备份和恢复

APM管理
应用接入
应用接入用于管理接入APM的应用,进行数据接入以及查看接入服务的数据上报情况。
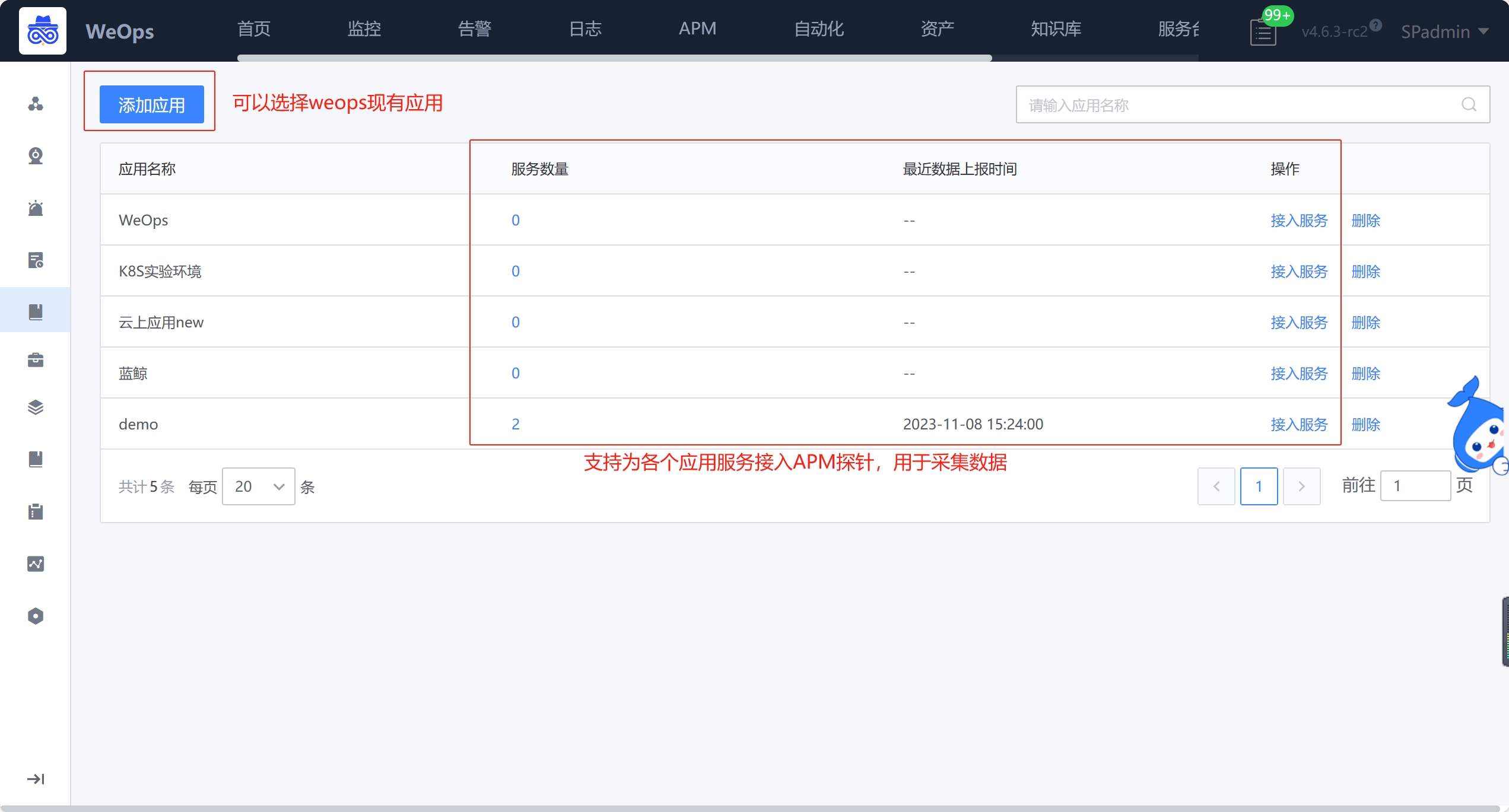
- 添加应用:支持选择WeOps现有应用,加入列表后,并为该应用接入服务
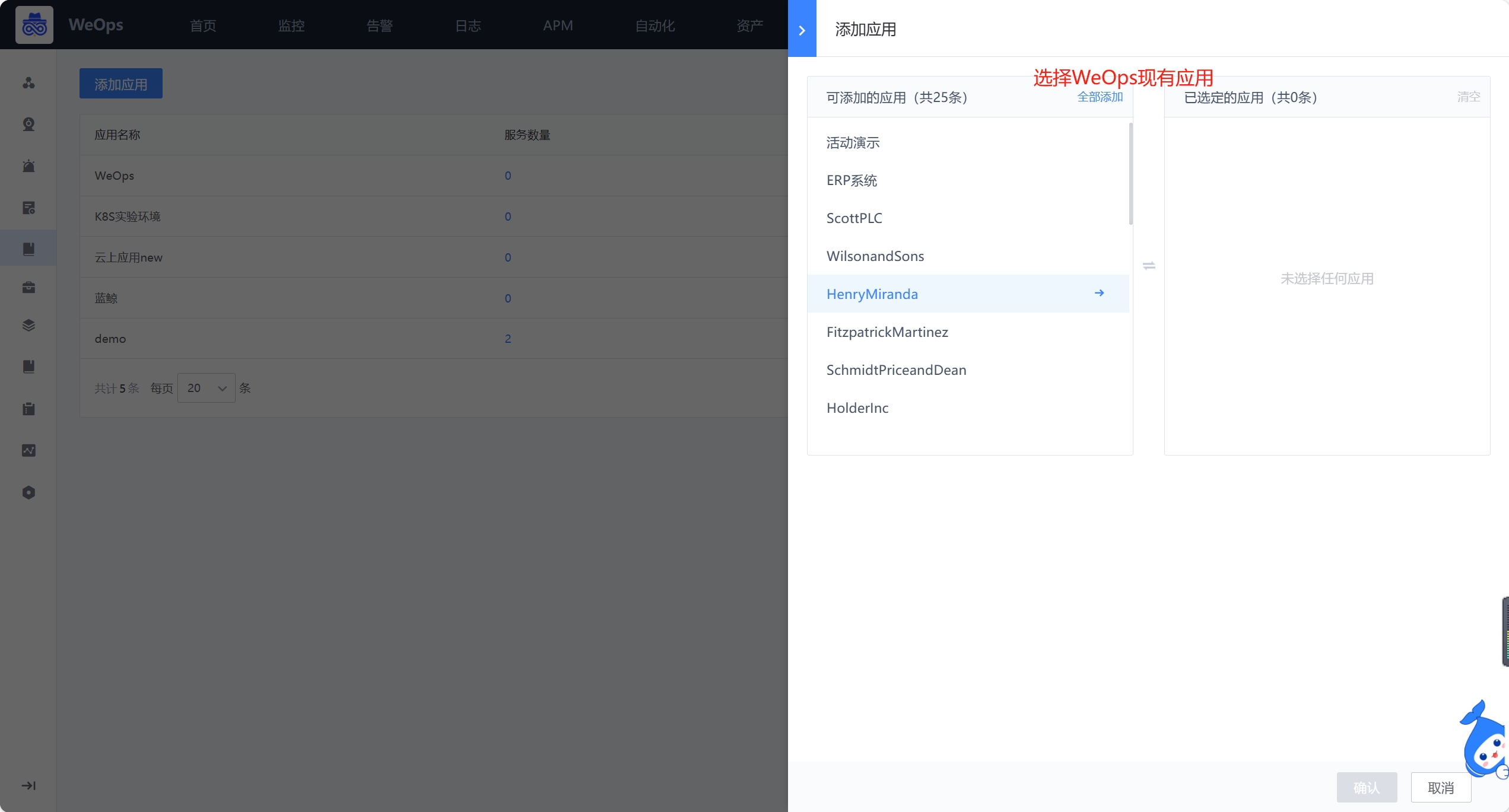
- 为应用进行服务的接入,WeOps采用无代码入侵的方式进行探针的安装和采集,支持java、python等开发语言和数十种开发框架(具体开发框架详见《内容说明——4、APM内容说明》),接入成功后,可以查看各个服务的数据上报情况。


- 健康配置:为了呈现应用/服务/接口的健康状态,支持以“平均时延P95”作为指标,进行阈值的设置和健康状态的展示,分为三个等级“正常、缓慢、异常”,设置成功后,在应用/服务的拓扑图展示每个服务的健康状态,在接口分析中展示接口整体健康状态,并以折线图展示健康状态变化。
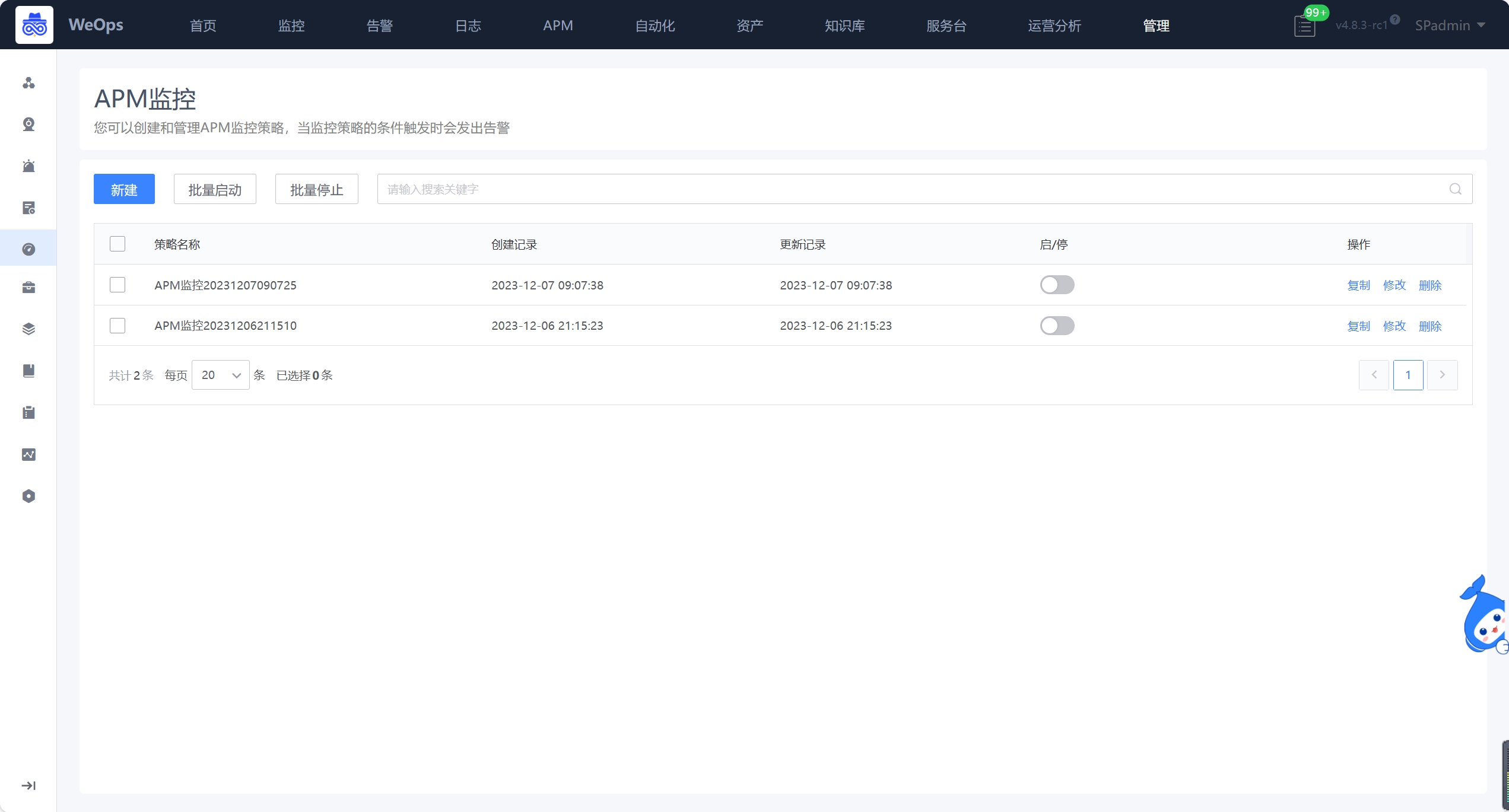
APM监控
- 可以创建和管理APM监控策略,当监控策略的条件触发时会发出告警
服务台管理
服务台管理主要进行IT服务台的后台配置,包括“流程”、“服务”、“服务目录”、“SLA”、“运营分析”、“值班管理”、“公告”
- 流程:如下图主要进行服务流程的管理和新建,包括流程设计和流程版本两项
- 流程设计主要分为三个步骤:填写流程信息、配置流程、流程启用设置


- 服务:如下图,展示所有新建的服务列表,需要绑定流程版本,只有关联服务目录并且启用的服务,才可以在IT服务台查看并使用。

- 服务目录:如下图,主要展示各个服务流程的层级关系,可以进行流程的新增和移除
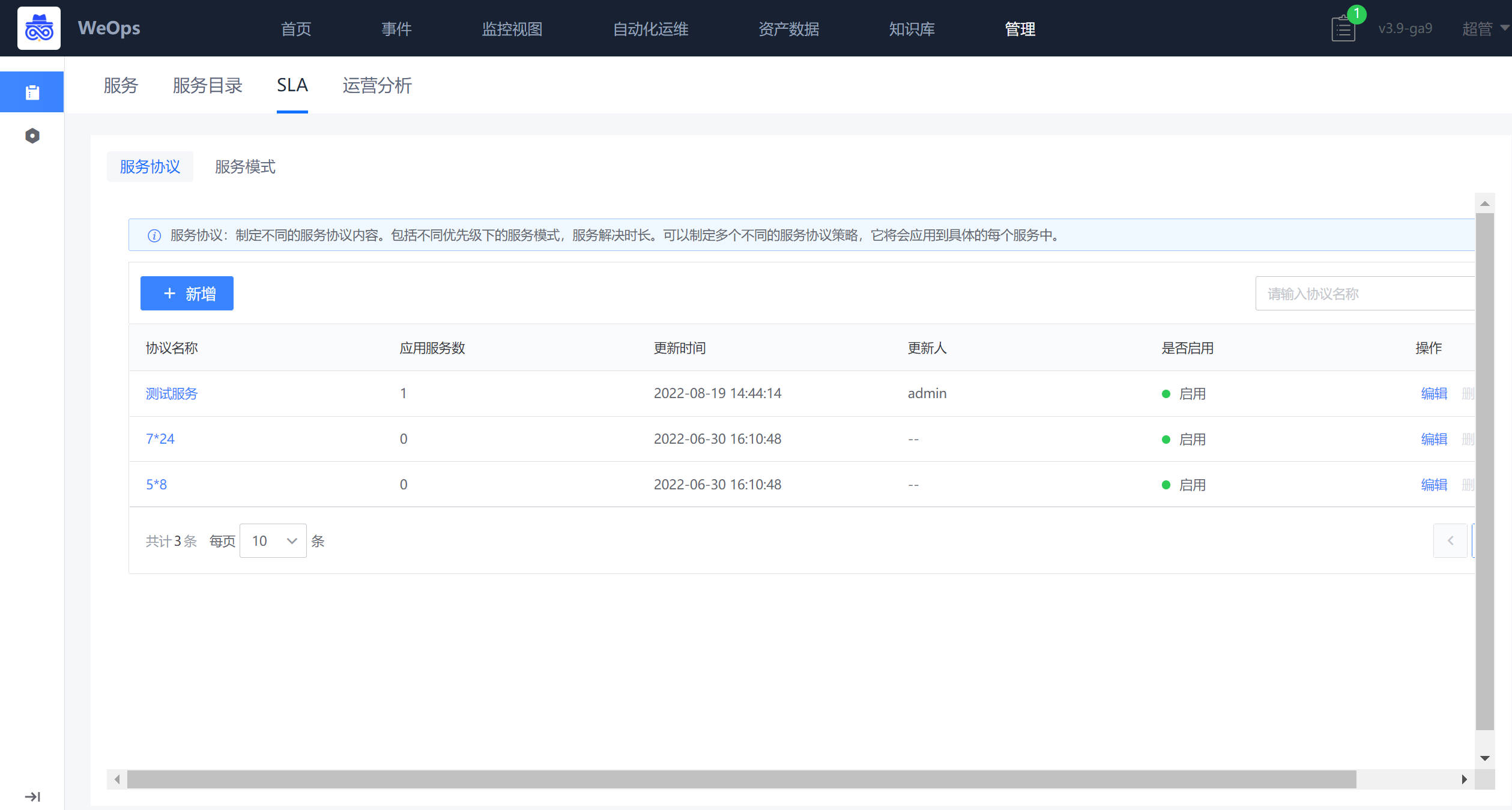
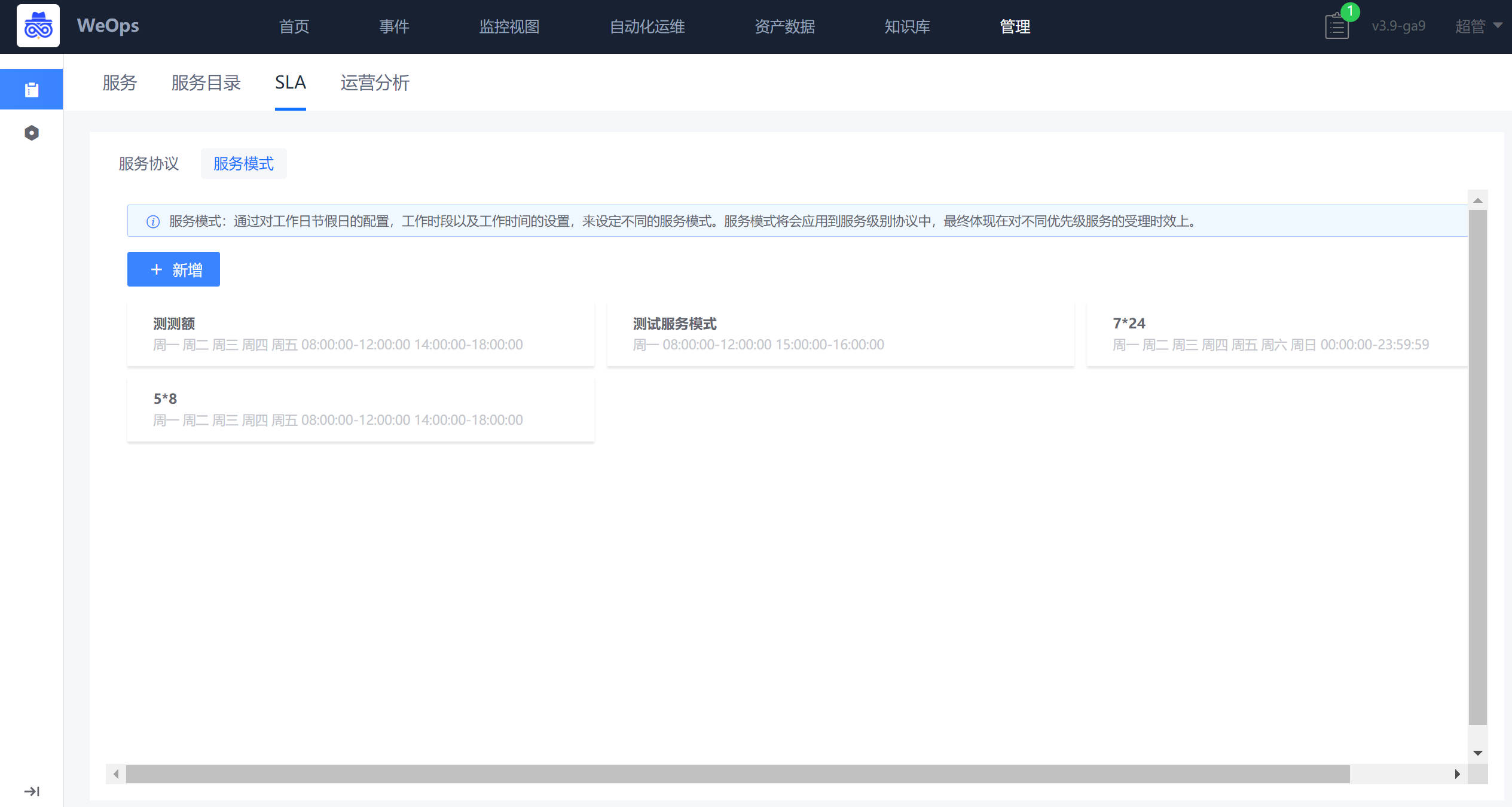
- SLA:如下图,主要用于服务模式创建(设置工作时间/加班时间/假期时间)和服务协议创建(SLA条件设置和提供设置)
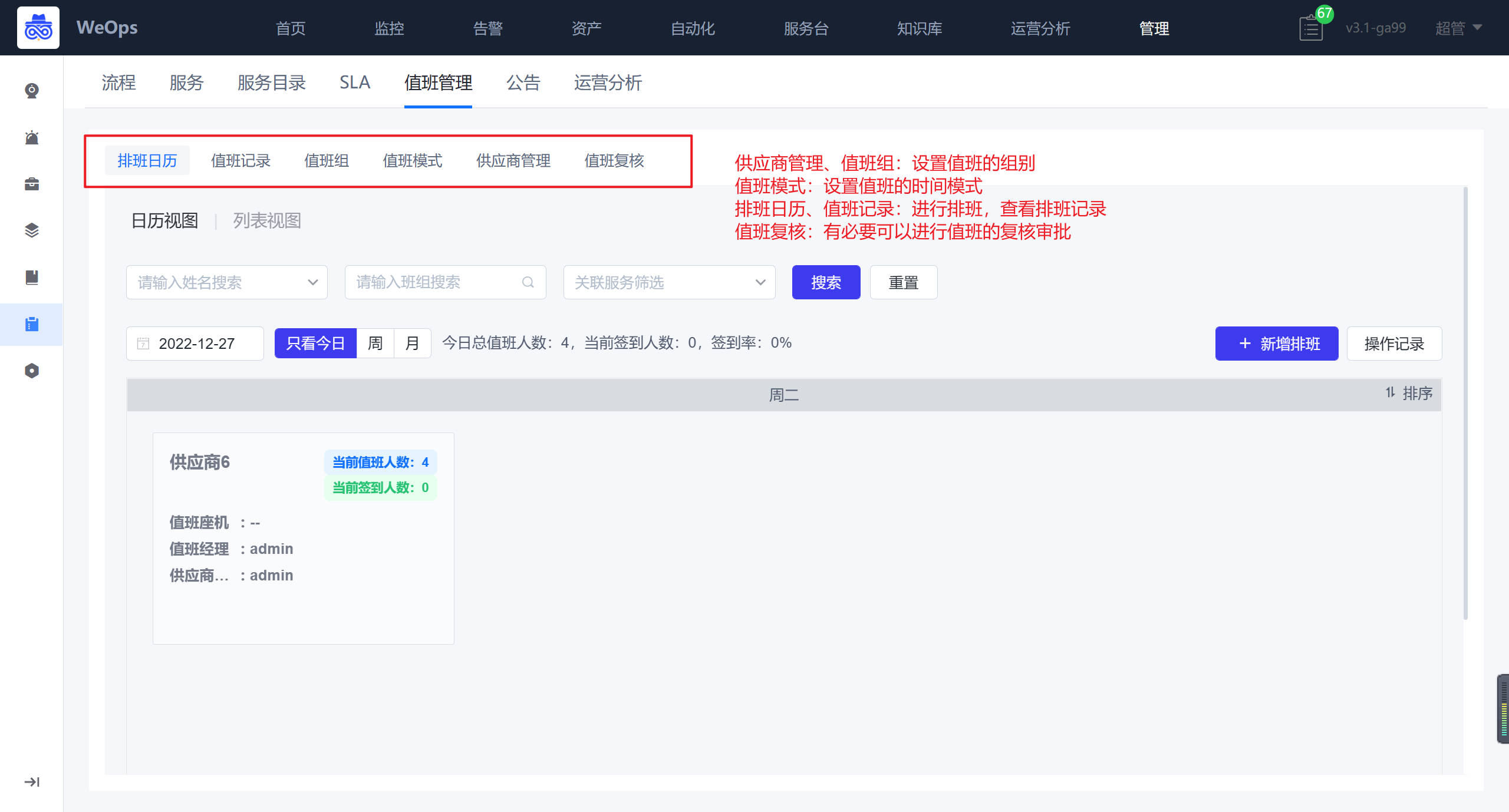
- 值班管理:对服务台各个值班组的值班进行排班,排班完成后可以按照当值人员进行工单的分派和处理。
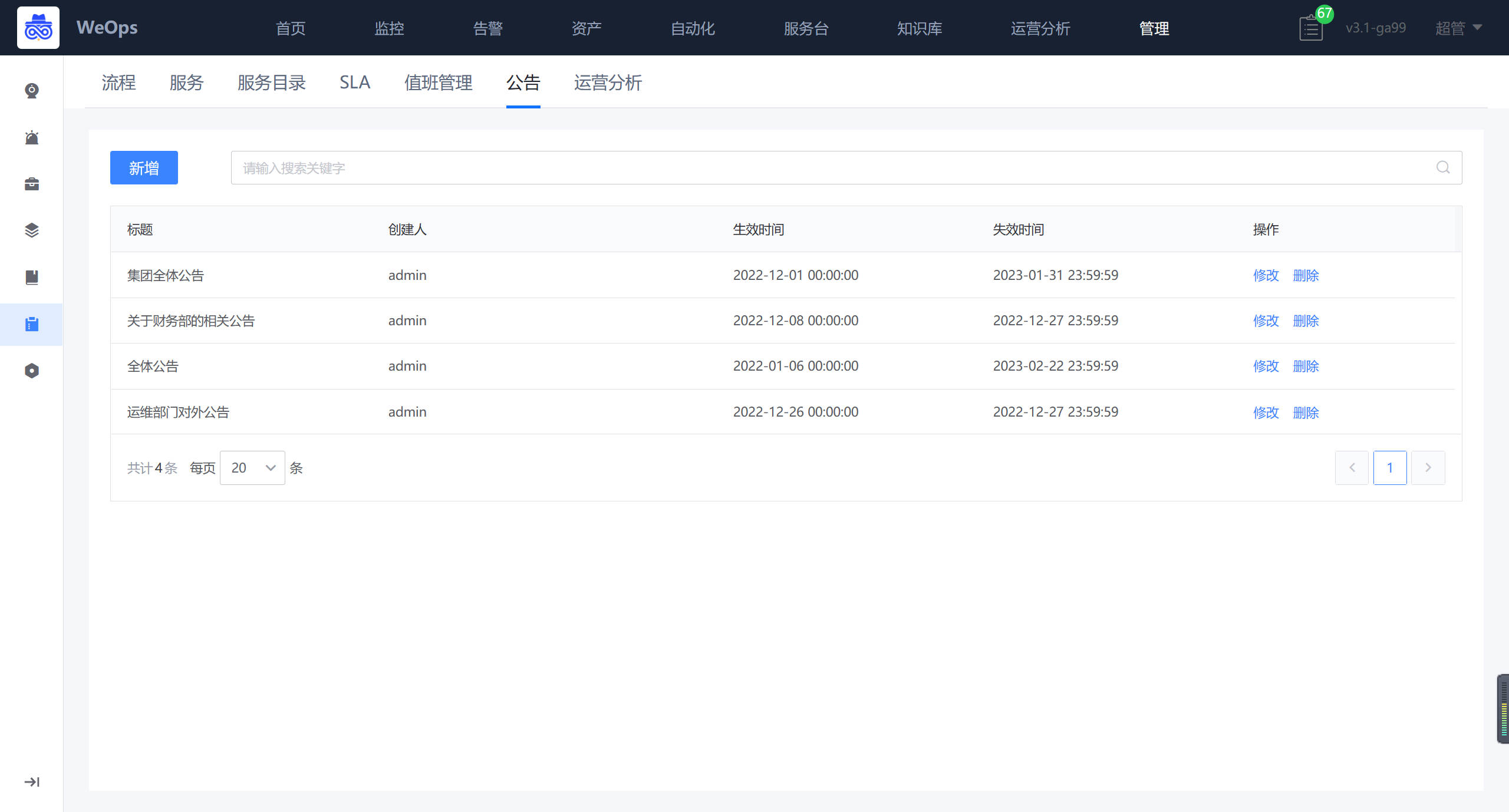
- 公告:对服务台的公告进行设置,可设置公告的内容、有限期、附件等
- 运营分析:对IT服务台的单据进行分类分析,包括服务使用统计、单据类型统计、单据状态统计等

- 例行工作:可设置按照不同频率,设置工单的自动提交

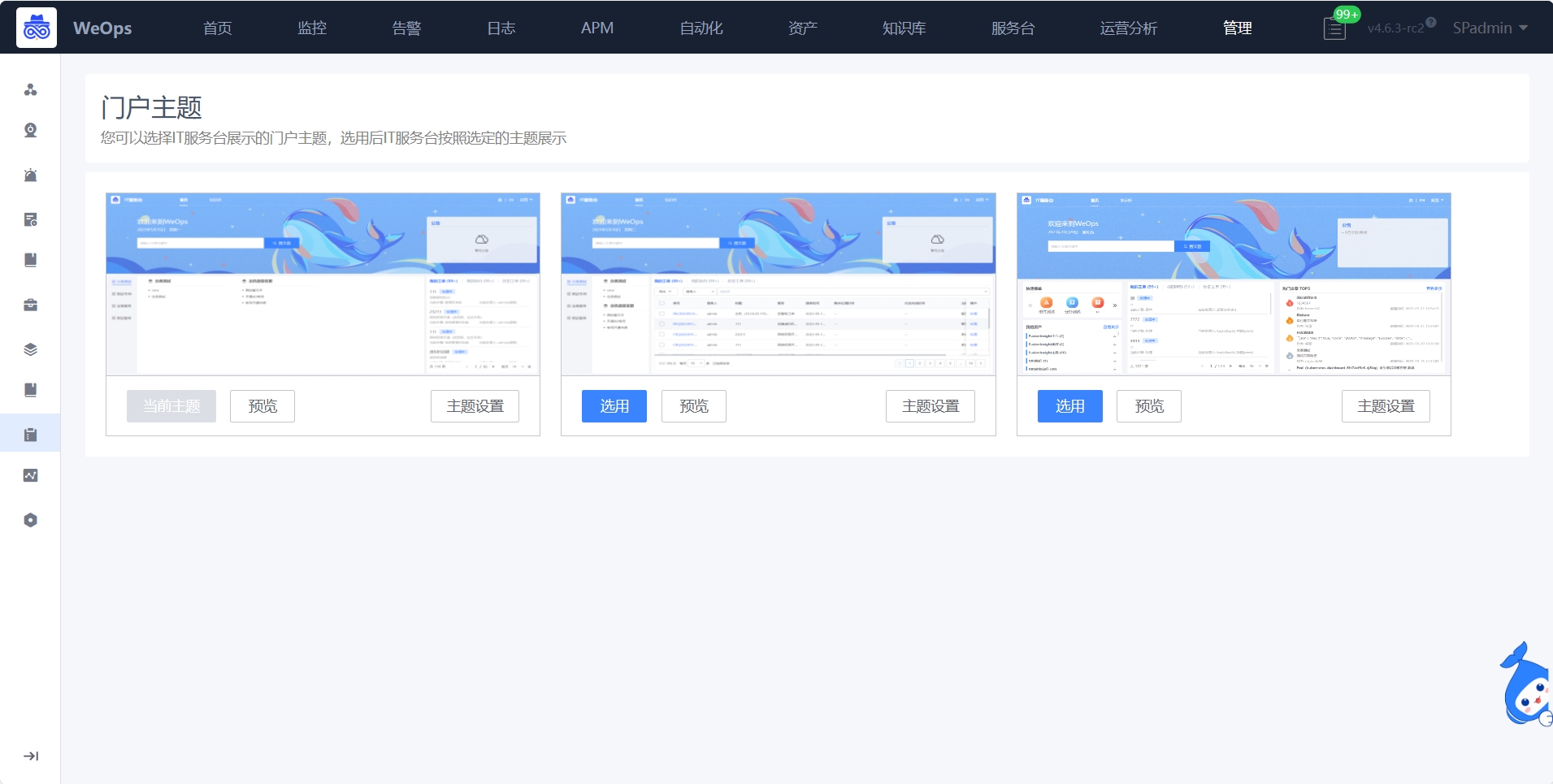
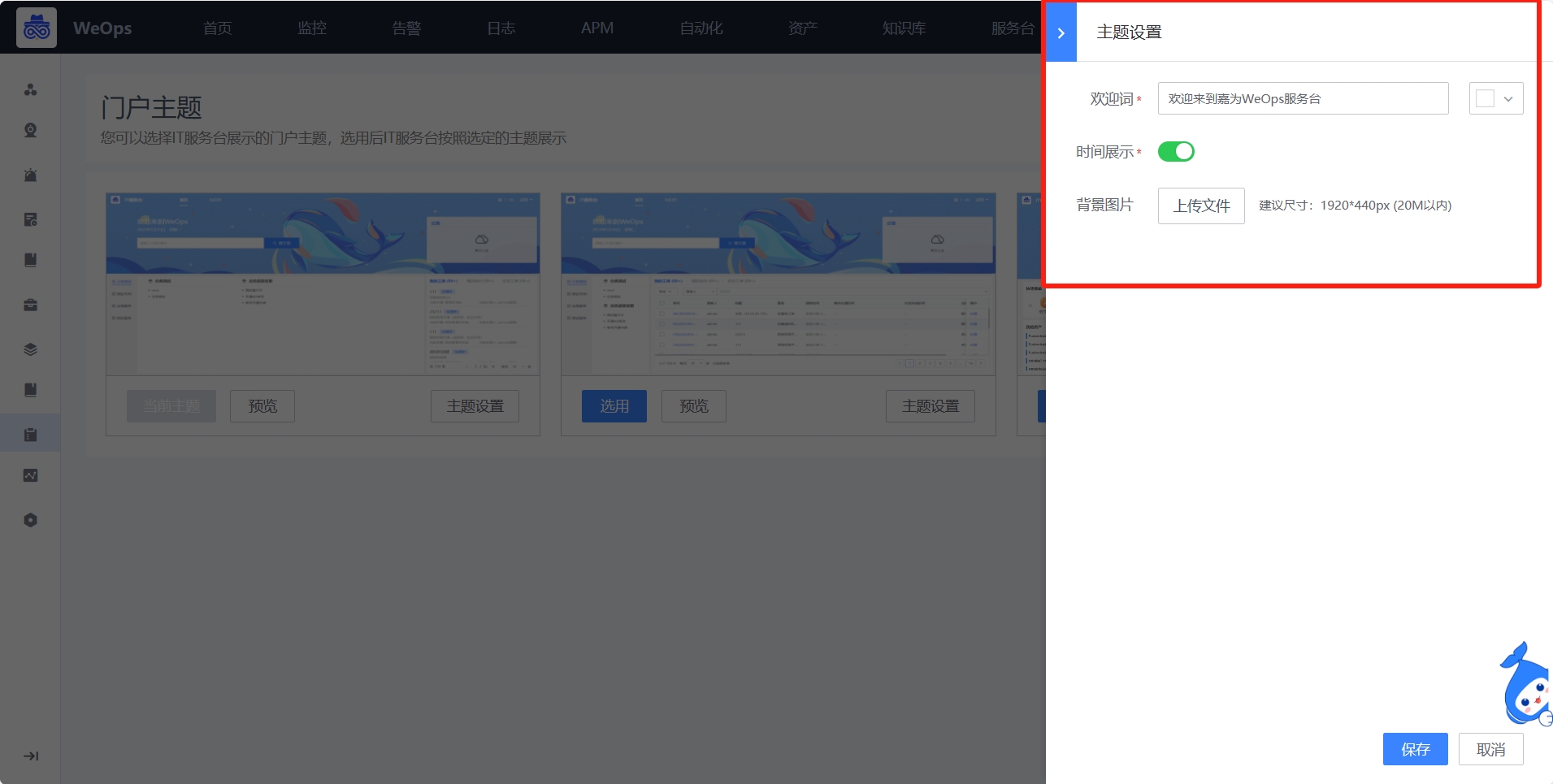
- 门户主题:内置不同风格的主题,可为IT服务台切换不同的门户风格,针对不同的主题,可以设置主题的背景色和欢迎语等
系统管理
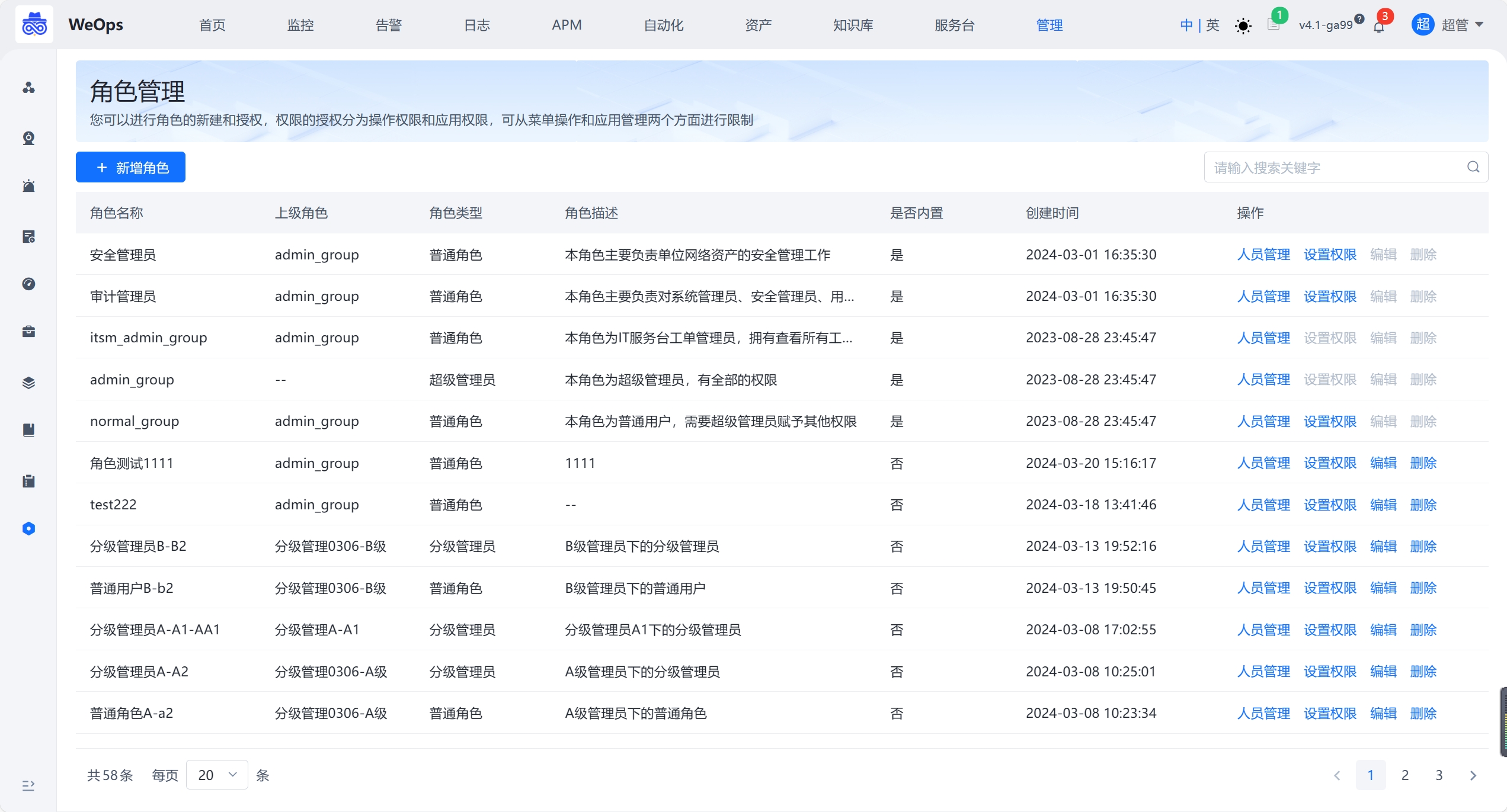
角色管理
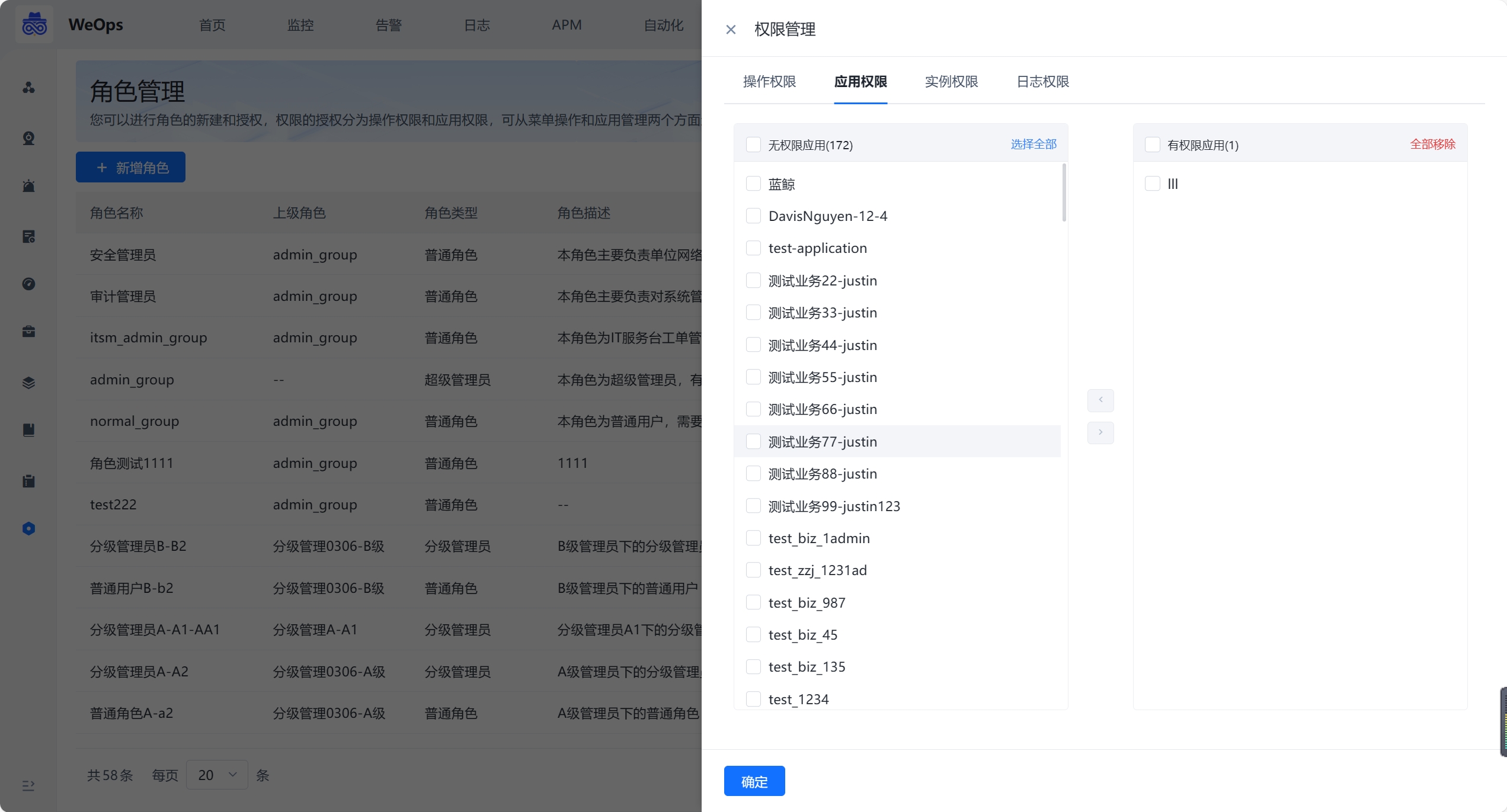
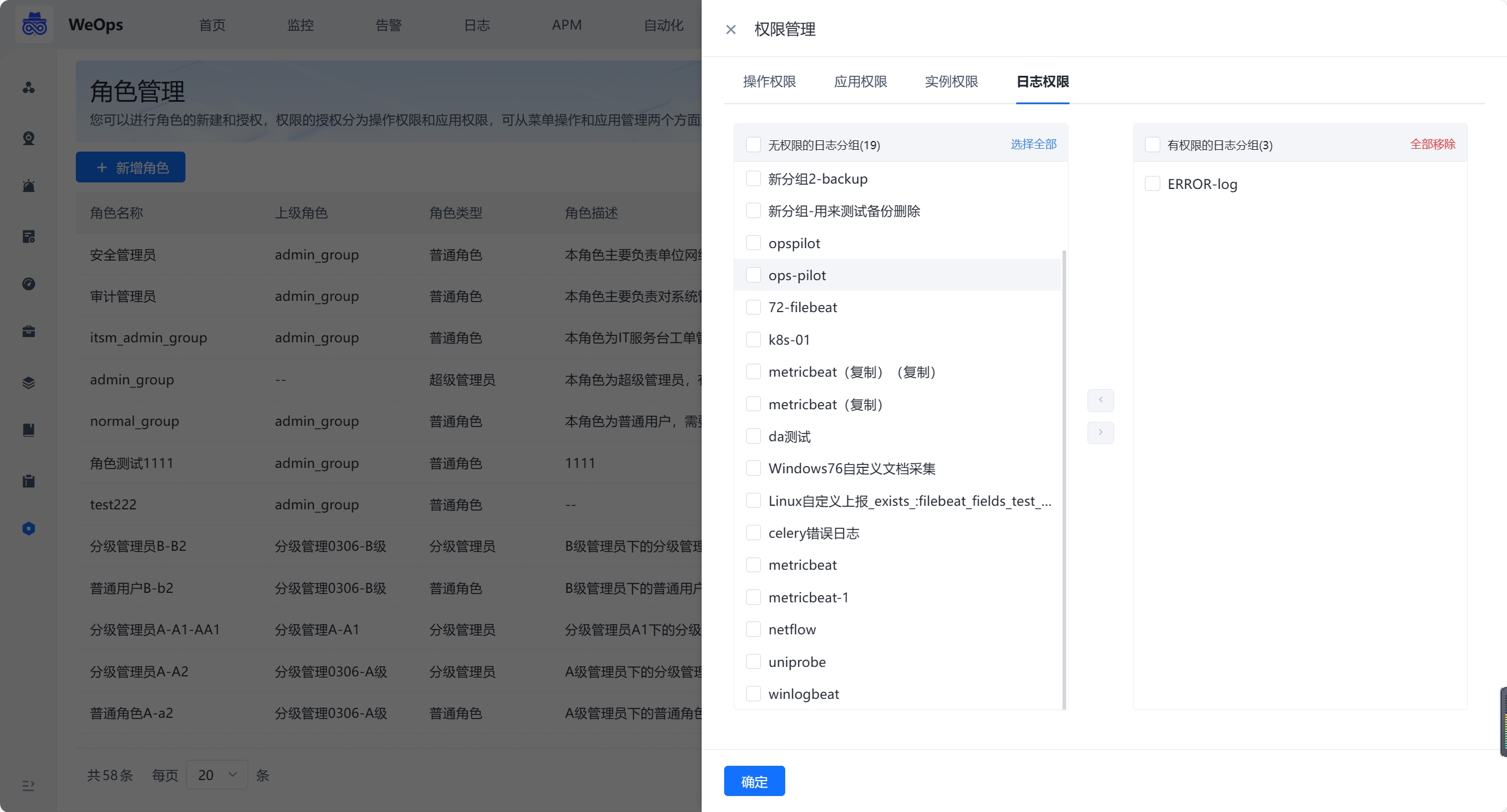
- 进行WeOps的用户角色管理,可以进行角色的新建和授权,权限的授权分为操作权限、应用权限、实例权限(拓扑图、仪表盘、文章、运维工具、监控采集任务、监控策略任务、数据大屏、运营报表),可从菜单操作、应用管理、实例、日志分组四个方面进行限制

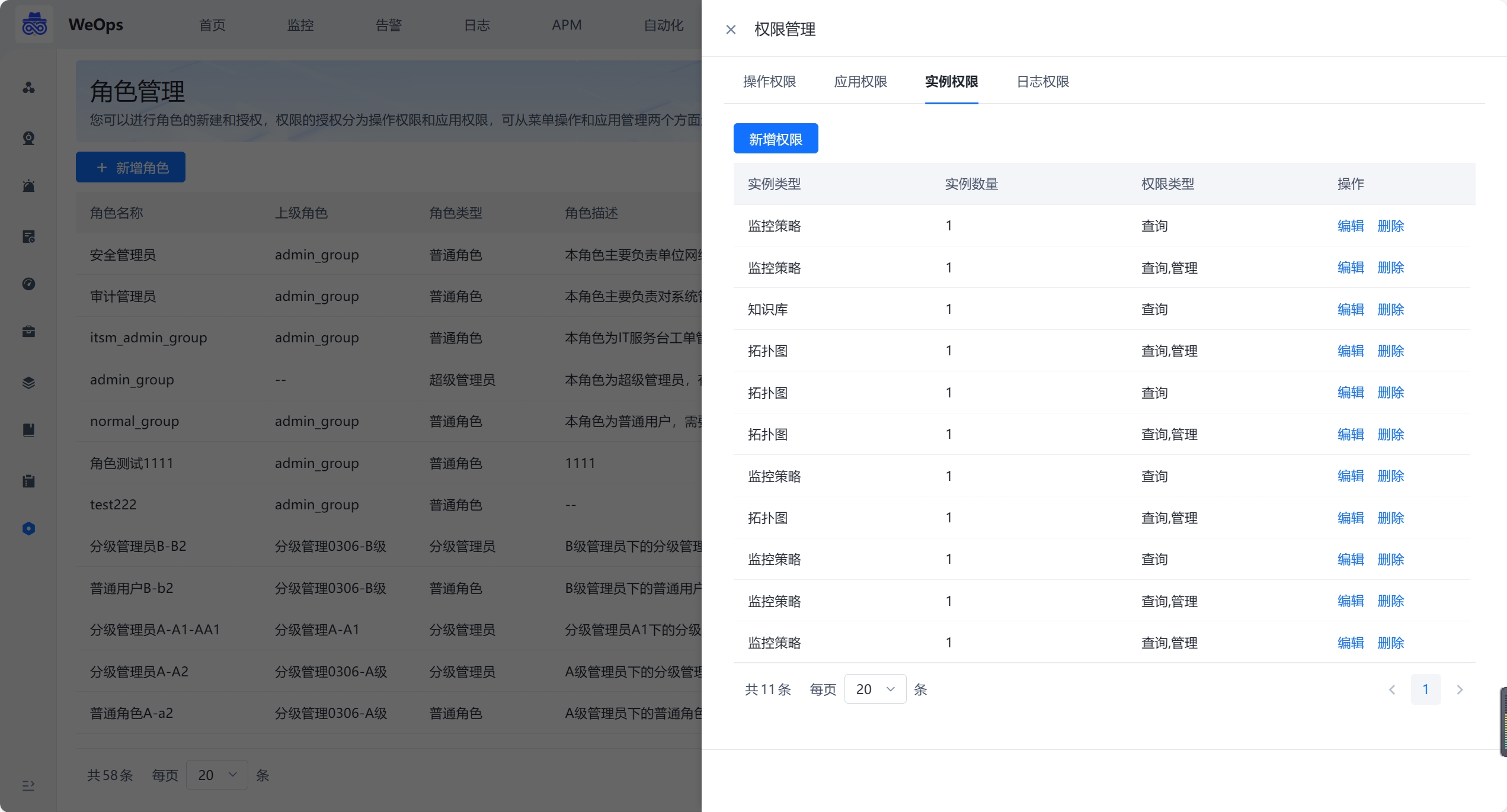
- 还支持“分级管理员”功能,作为分级管理员,支持再次创建角色,并进行二次授权。
- 还支持“分级管理员”功能,作为分级管理员,支持再次创建角色,并进行二次授权。
用户管理
- 用户管理接入AD/LDAP需要开放用户组织权限。管理员能够在WeOps中维护AD/LDAP用户的上级信息,并且不会因每次同步用户所覆盖。
- 进行用户的新建,用户角色的配置,同时展示用户所属组织的管理。
- 用户管理支持双因子认证的设置,可将用户/角色组添加双因子认证的白名单。

- 支持查看和恢复已删用户。
通知渠道
- 通知渠道设置可对WeOps的对外通知渠道的进行配置,包括邮件、短信、电话和企业微信。

许可管理
- 展示了weops系统的节点数量、有限期等信息,可进行到期提醒,到期提醒设置成功后,可在左上角进行提示。
操作日志
- 展示WeOps相关的增删改等历史记录。

系统设置
- 自定义菜单:支持灵活配置菜单,包括菜单项、菜单层级、菜单顺序等,可以根据需要自定义菜单并启用,以便更好使用系统功能。

- 自定义产品名称:支持修改运维门户、服务台门户的产品名称。
- 自定义产品LOGO:支持上传修改运维门户、服务台门户的产品LOGO。
- 页面水印:支持为运维门户、服务台门户所有页面配置水印。
操作手册
资源纳管配置
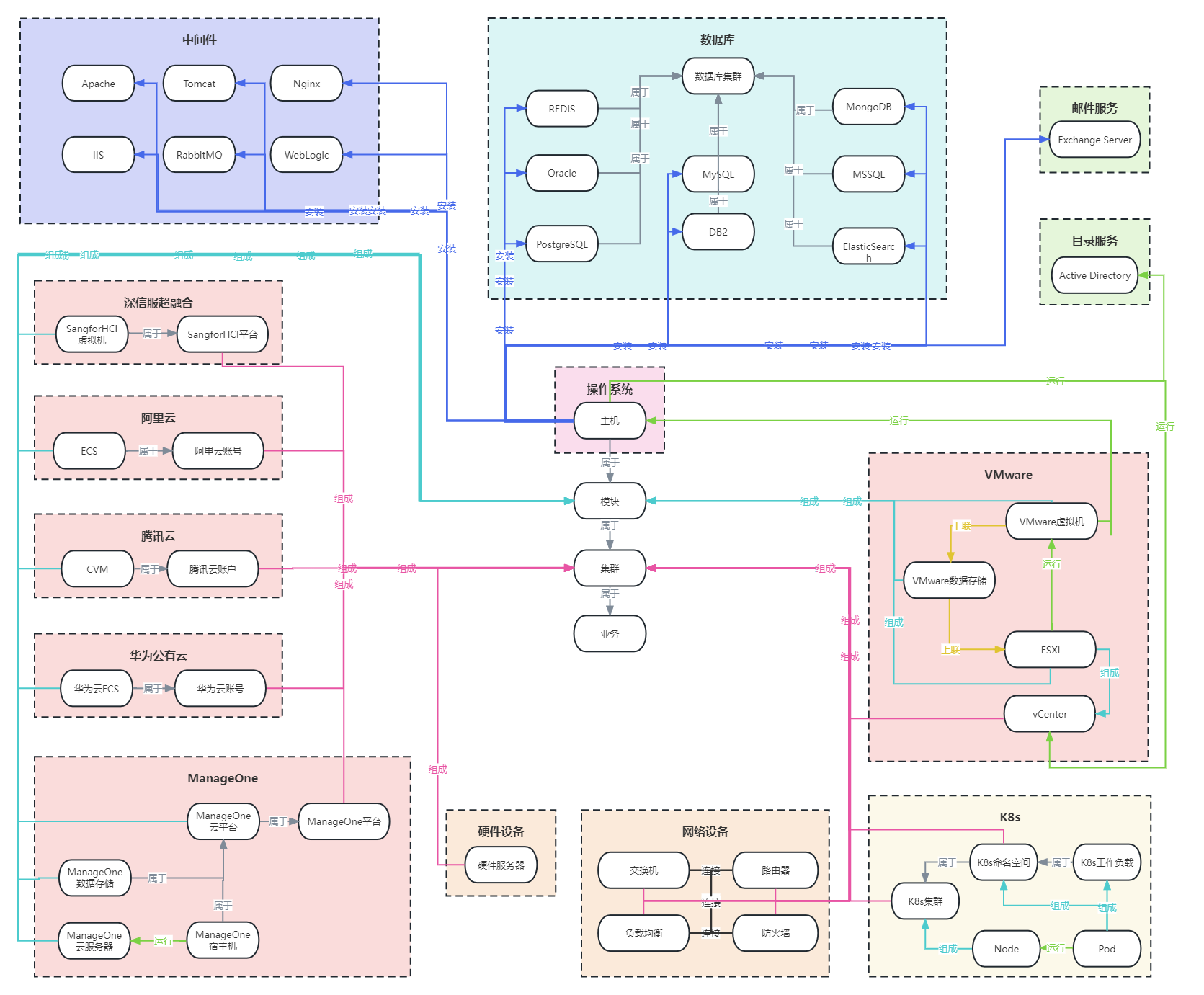
资产和应用关系说明
WeOps所有资源模型之间的关联关系如下:
不同客户不同资产的应用归属链路略有不同,为了满足不同客户的特殊需求,支持对各个资产的应用归属链路进行自定义。
- 应用链路配置页面:每个资产只能开启一条应用链路,并依据该链路寻找归属应用(k8s的workload、pod支持同时开启所有默认链路规则)

- 内置各资产应用链路:各内置资产模型均内置默认应用链路规则,具体内置链路说明如下
主机
如下图,主机直接与“模块”关联,其应用归属来自于所属的模块的应用。
数据库/中间件
如下图,数据库/中间件与主机关联,其应用归属来自于关联的主机应用属性。
K8S
如下图,K8S集群、命名空间、工作负载、pod、node的关联关系如图,各个模型的应用属性描述如下:
K8S集群:直接与集群关联,从而获得应用属性
命名空间:直接与集群关联,从而获得应用属性
node:来自于关联的K8S集群的应用属性
工作负载:共有两条链路,“K8S工作负载-K8S命名空间-集群”、“K8S工作负载-K8S工作负载-K8S命名空间-集群”
pod:共有三条链路,“Pod-K8S工作负载-K8S命名空间-集群”、“ Pod-K8S命名空间-集群”、“Pod-K8S工作负载-K8S工作负载-K8S命名空间-集群”

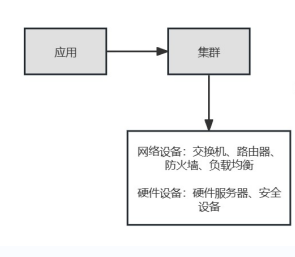
网络设备&硬件设备
如下图,交换机、路由器、负载均衡、防火墙等网络设备,硬件服务器、安全设备等硬件设备都直接与集群关联,从而获得对应的应用属性。
云平台-VMware
如下图,Vcenter、虚拟机、ESXI、数据存储直接的关联关系如图,各个模型的应用属性描述如下
vcenter:直接与集群关联,从而获得应用属性
虚拟机、ESXI、数据存储:各自直接与模块关联,从而获得应用属性

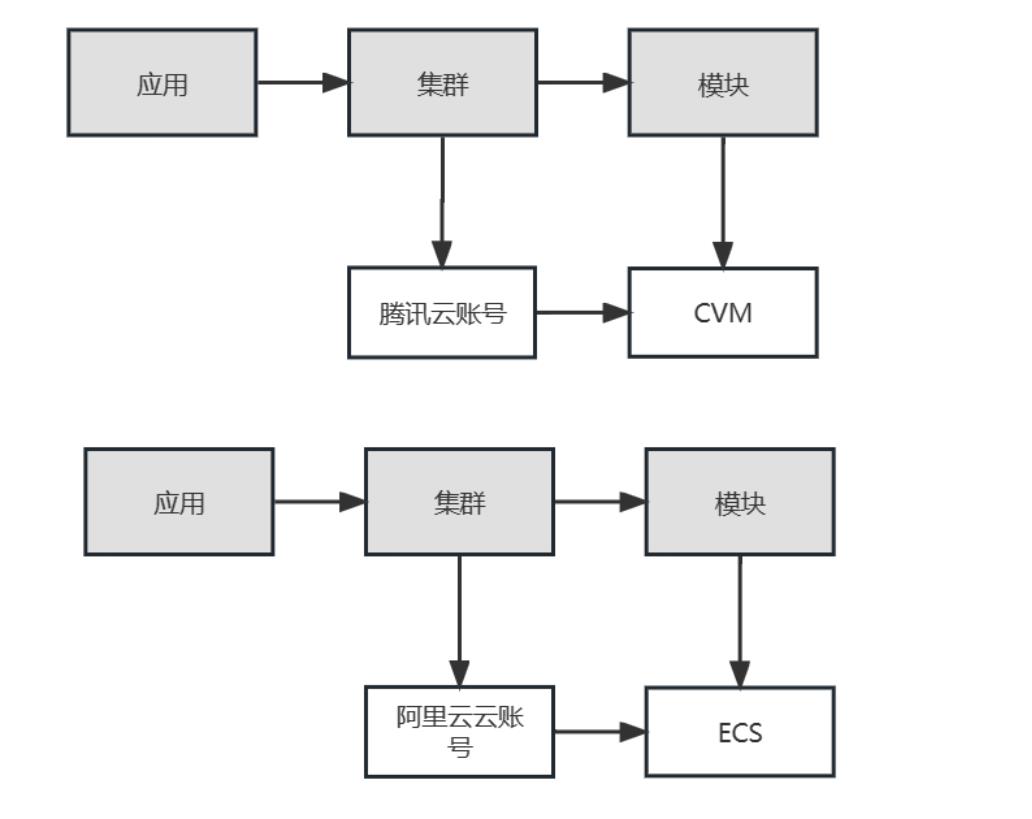
云平台-腾讯云/阿里云
如下图,云账户直接与集群关联,从而获得应用属性,云服务器(CVM、ECS)直接与模块关联,从而获得应用属性。
云平台-manageone
如下图,华为云Manageone平台的关联关系如下,各类对象的的应用归属描述如下
- ManageOne平台:与集群管理,从而获得应用属性
- 云服务器、云平台、宿主机、数据存储:直接与模块关联,从而获得应用属性

云平台-SangforHCI
如下图,SangforHCI平台的关联关系如下,各类对象的应用归属米搜狐如下
- SangforHCI平台:直接与集群关联,从而获得集群的应用属性
- 虚拟机:直接与模块关联,从而获得应用属性

云平台-FusionInsight
如下图,FusionInsight平台的关联关系如下,各类对象的应用归属米搜狐如下
- FusionInsight平台:直接与集群关联,从而获得集群的应用属性
- FusionInsight集群/主机:直接与模块关联,从而获得应用属性

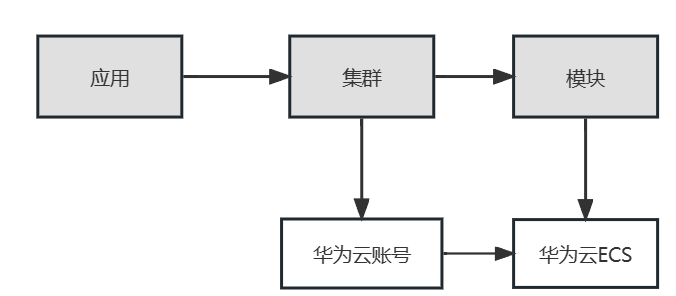
云平台-华为云
如下图,华为云平台的关联关系如下,各类对象的应用归属米搜狐如下
- 华为云账号:直接与集群关联,从而获得集群的应用属性
- 华为云ECS:直接与模块关联,从而获得应用属性
主机纳管
背景介绍:需要把主机纳入到WeOps的管理中,有两种方式进行:一是手动创建仅记录主机信息,二是安装Agent进行主机信息的自动采集
方式一:手动创建
路径:资产-资产记录-主机
手动创建仅录入主机的相关信息,进行主机的信息管理和拓扑展示,若需要对手动创建的主机进行监控数据采集,需要对其进行Agent安装。
Step1:进入界面,点击“新建”
Step2:填写主机相关信息
在弹出的抽屉中填写相关主机信息,必填字段包括:内网IP、云区域

手动创建的主机agent状态为“未安装”,若需要安装agent,则前往“管理-管理中心-监控管理-监控采集”进行agent的安装。
方式二:安装Agent
路径:管理-监控管理-监控采集
以安装agent的方式进行主机的纳管,在agent安装后,可在“资产数据-资产记录(主机)”中形成对应的主机信息,同时支持监控数据的采集。可以选择手动单个agent安装,或者利用表格导入进行批量安装,安装步骤基本一致。
Step1:进入界面,点击安装Agent
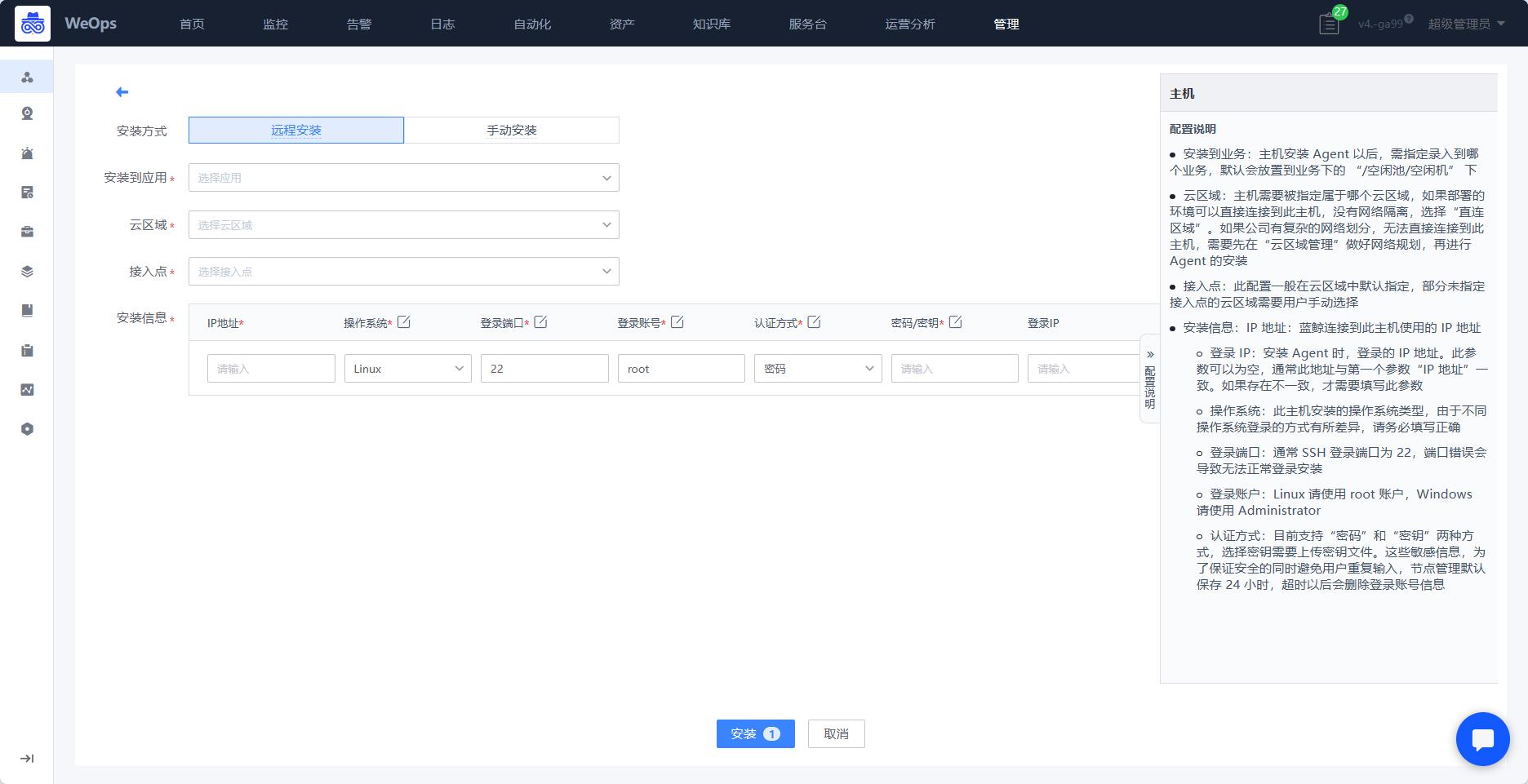
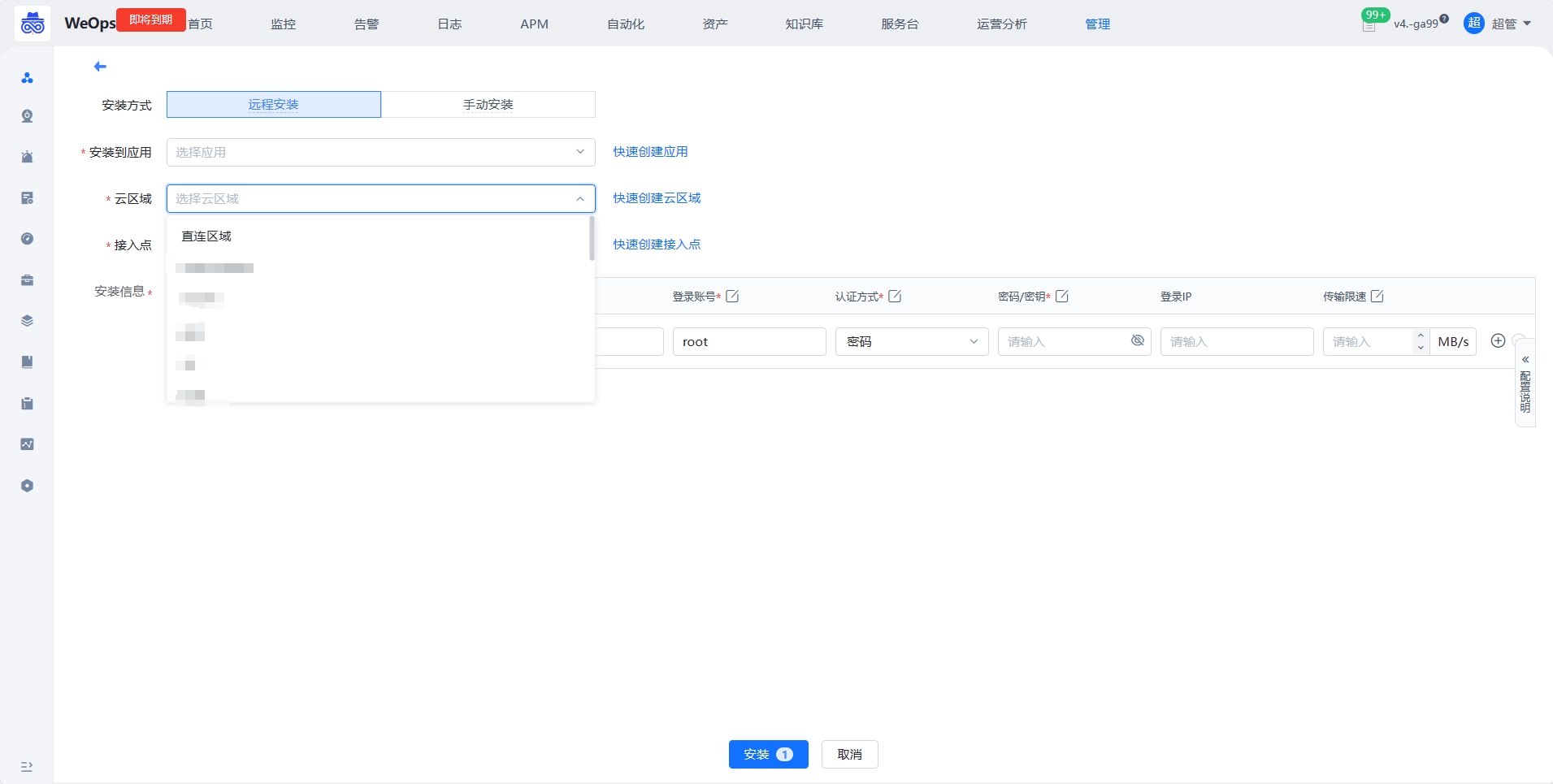
如下图所示,选择“操作系统-主机”,进入主机Agent安装界面,点击“安装Agent”
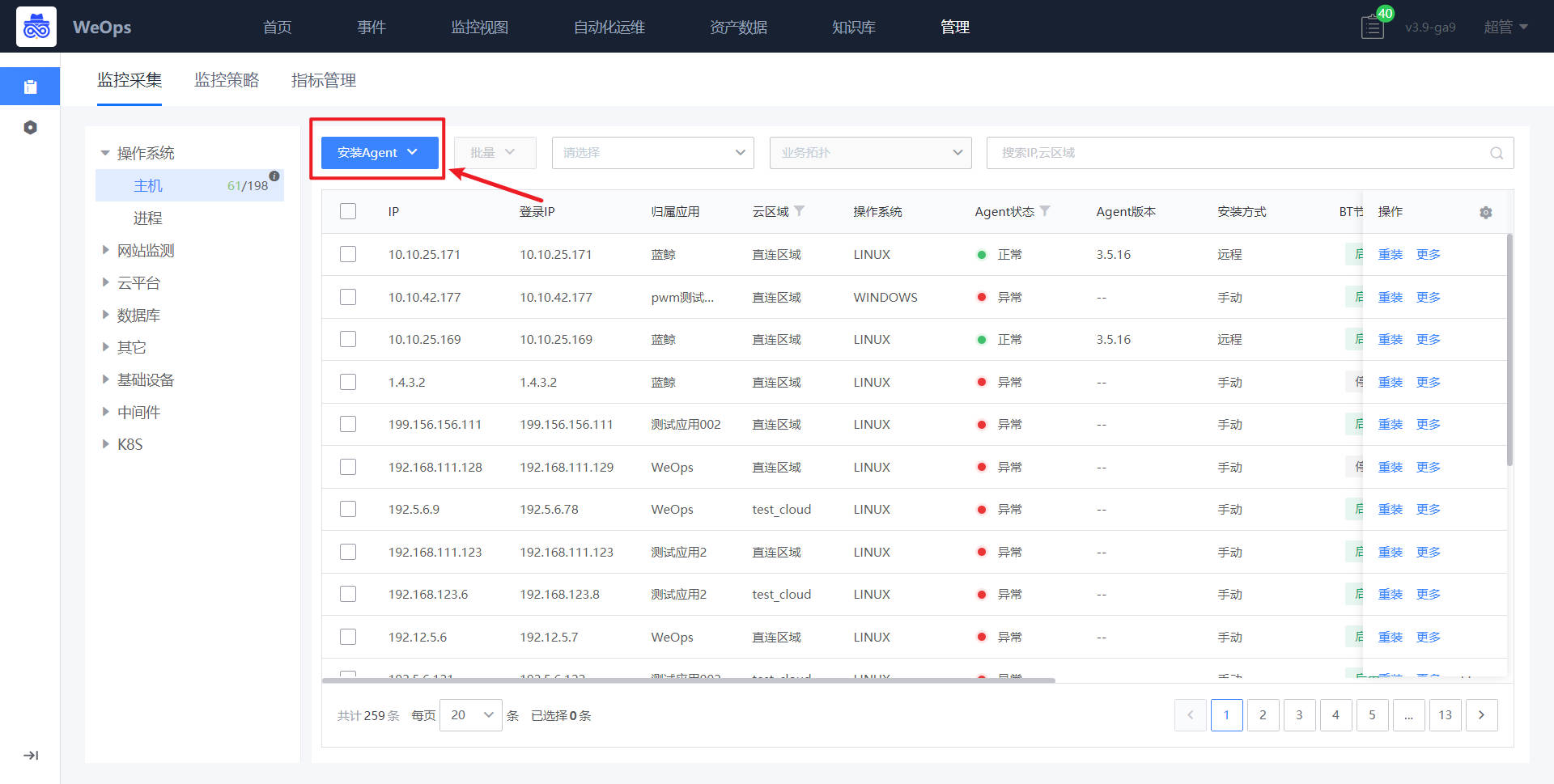
Step2:填写相关信息
在安装的界面,选择该主机归属的业务、云区域以及接入点。随后在安装信息输入该纳管主机的IP地址,登录账号和密码等核心配置。输入完成之后点击[安装]按钮即可将agent部署至该主机。
Step3:等待安装成功
上一步骤点击安装将会跳转至安装界面,可以查看执行状态,点击查看日志可以查阅安装过程。
安装完成回到主机纳管的界面可以看到该主机的Agent已经顺利安装。
应用新建
背景介绍:当有新应用上线时,需要在WeOps的应用管理对该应用进行纳管,具体步骤如下:新建应用,填写该应用相关信息→确定该应用层级并配置拓扑→添加主机,进行管理。
Step1:新建业务
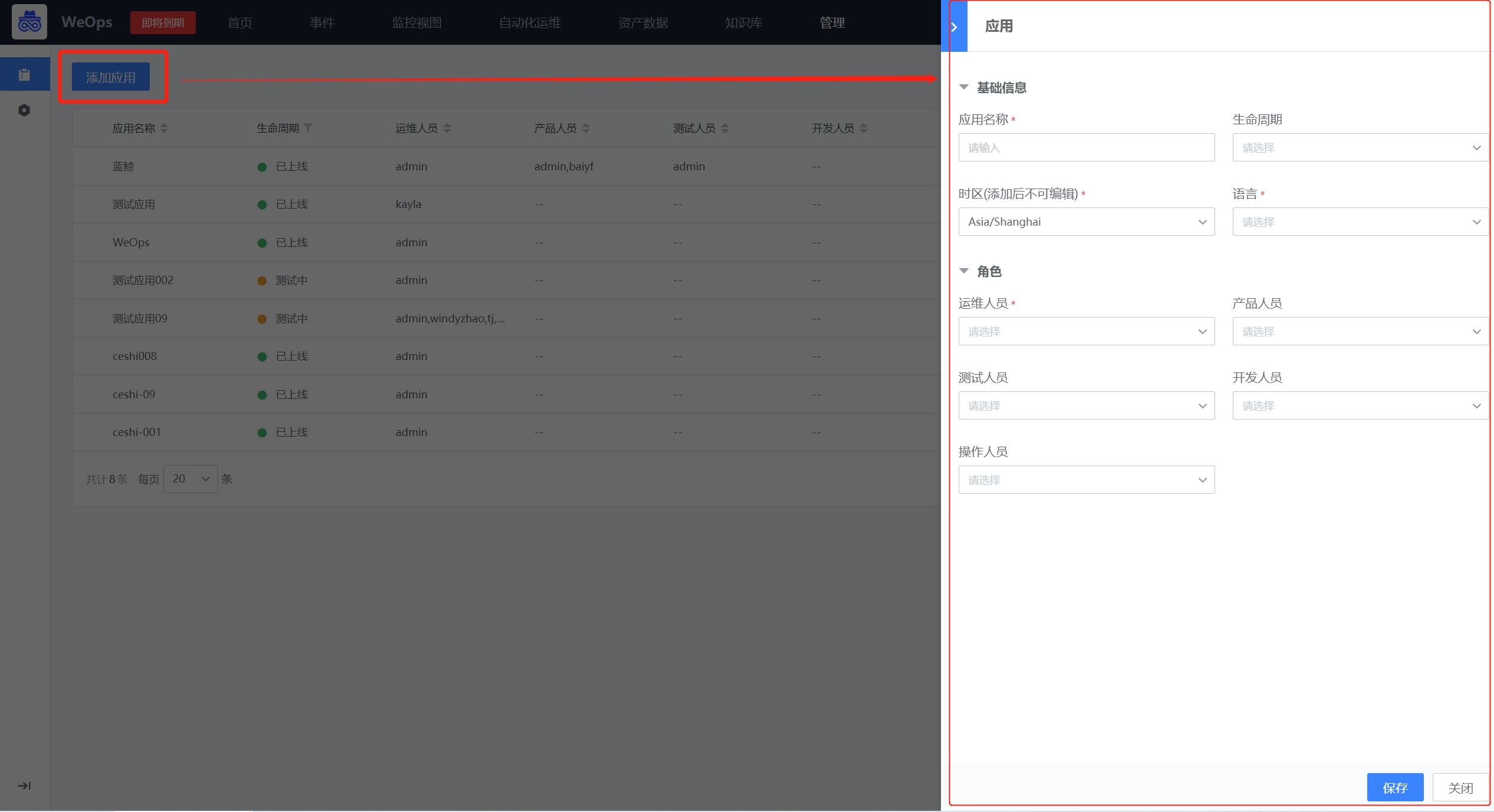
路径:资产-应用
在应用列表页面,点击“添加应用”按钮,可以进行应用的新建。需填写基础信息和角色信息。
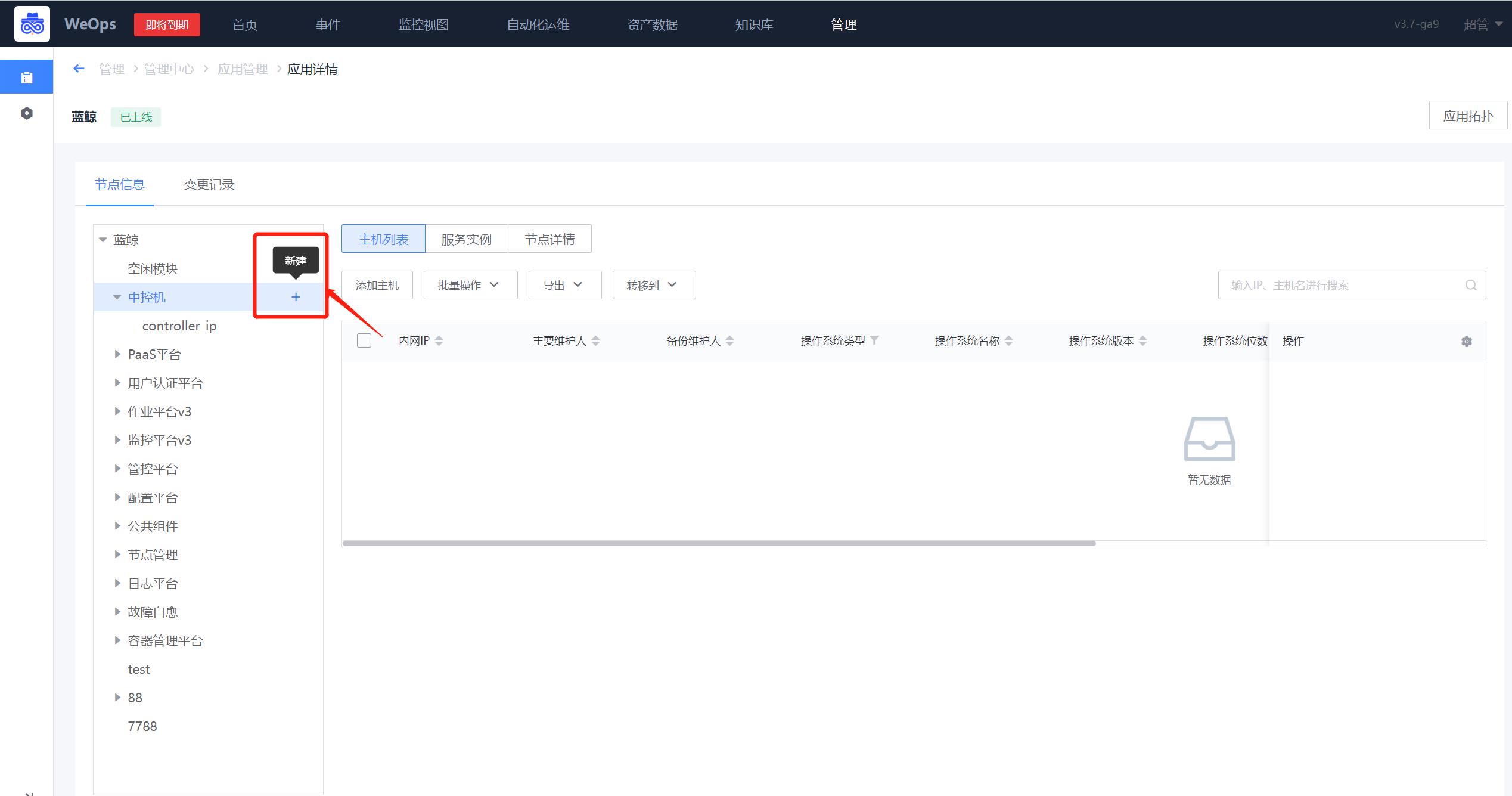
Step2:配置应用拓扑
路径:资产-应用
- 进入新创建的应用的详情页面,点击左侧的节点信息,展示该应用的拓扑
- 点击页面左侧的拓扑的对应节点,可依据实际情况依次添加“子应用”、“集群”和“模块”等层级
Step3:主机分配和移动
路径:资产-应用
应用的拓扑新建完成后,可以向各个节点添加主机。选中需要添加的节点,点击“主机列表”下的“添加主机”按钮,这里展示了所有没有归属应用的主机列表(展示手动创建/安装Agent两种方式下未归属应用主机),选择需要加入的主机,点击下一步,选择模块即可添加成功。

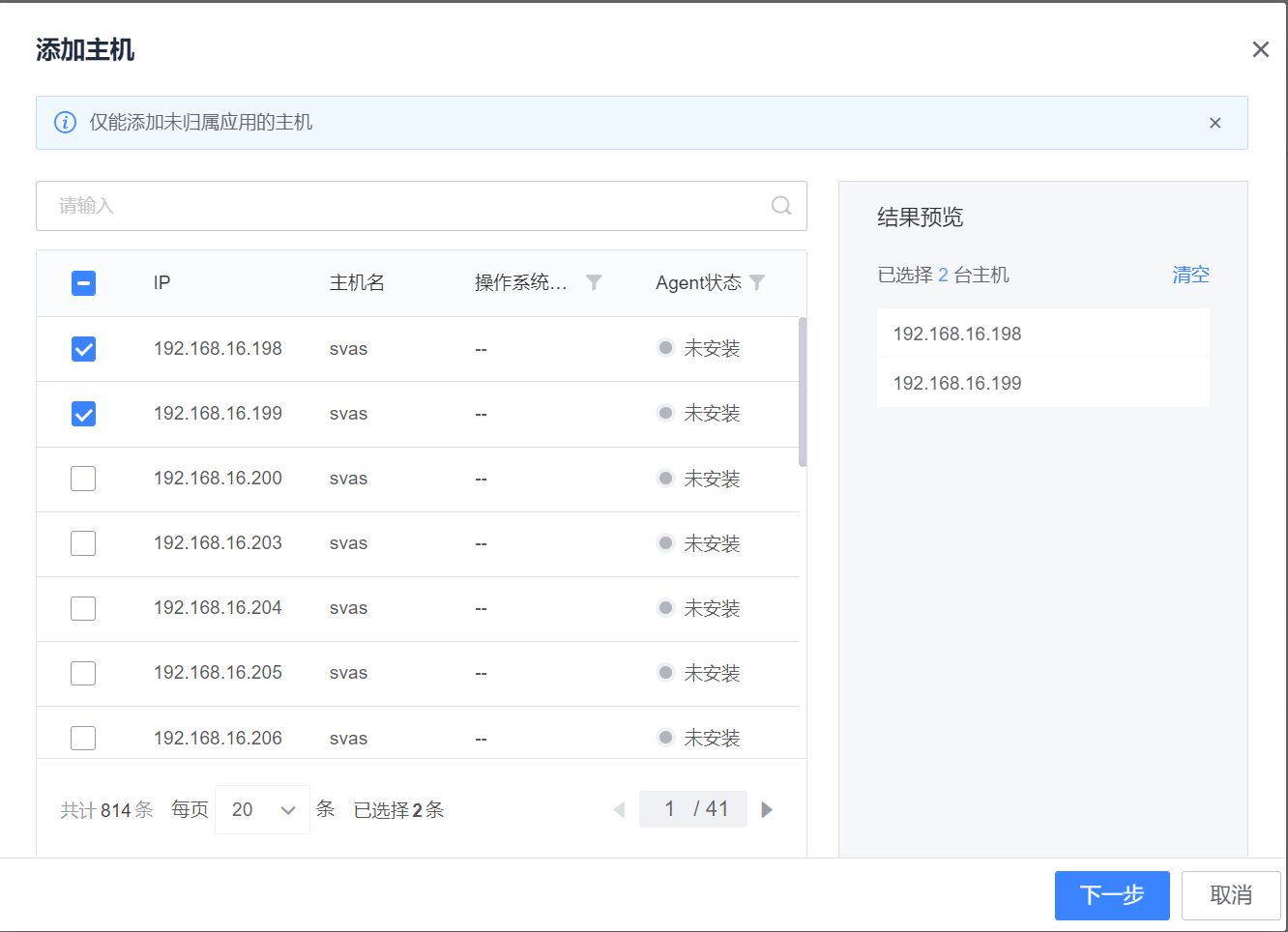
数据库/中间件纳管
背景介绍:关联主机已经进行Agent的安装,并且Agent正常(主机Agent安装详见1.1主机纳管),这里以Oracle为例进行介绍,有两种方式进行资源的纳管,一种是手动纳管,一种是创建自动发现任务进行资产纳管。
方法一:手动纳管
路径:资源-资源记录-数据库(Oracle)
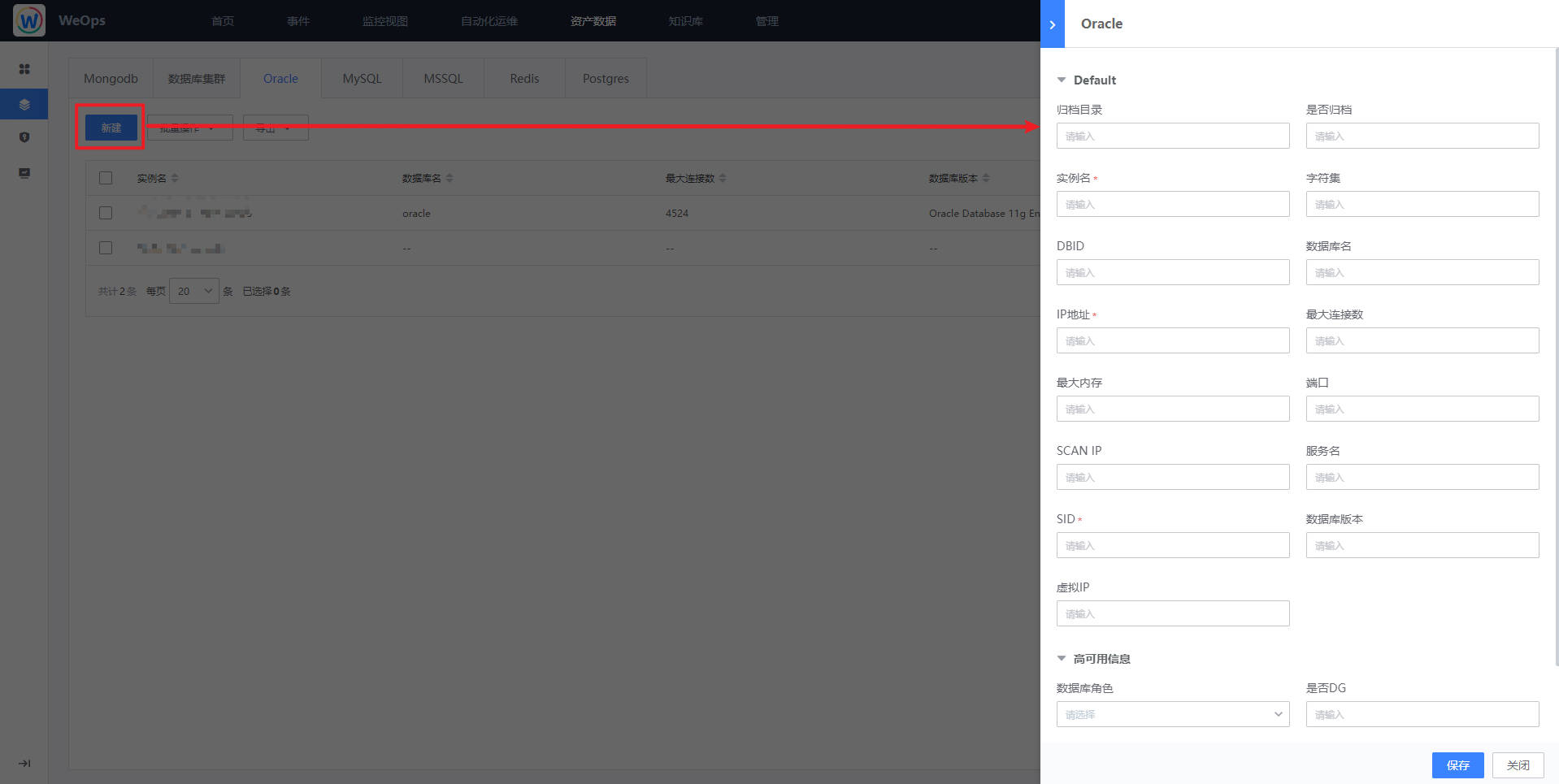
Step1:进入界面,点击“新建”,进行实例信息录入
点击“新建”按钮后,在弹出的抽屉中,填入Oracle的相关信息。
Step2:建立与主机的关联
实例新建完成后,点击“查看”按钮,进入到该实例的详情页。
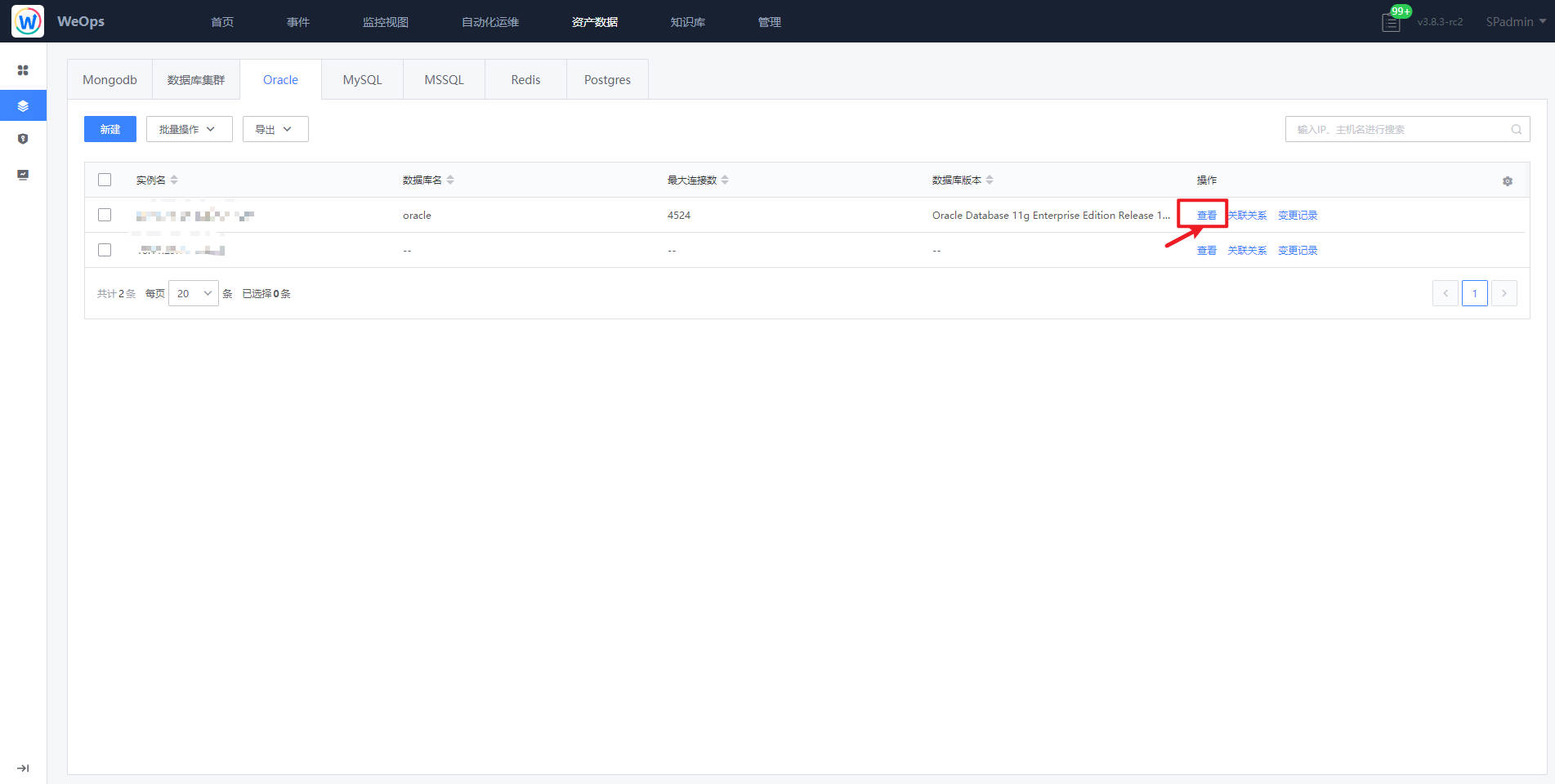
点击“关联信息”中的“关联管理”,建立该Oracle数据库和对应主机的关联关系。

手动创建的资产的配置信息需求手动维护和更新。
方法二:自动发现
路径:管理-资产管理-自动发现
选择数据库-Oracle,创建自动发现任务,新建任务时,选择资产的IP范围、输入对应凭据
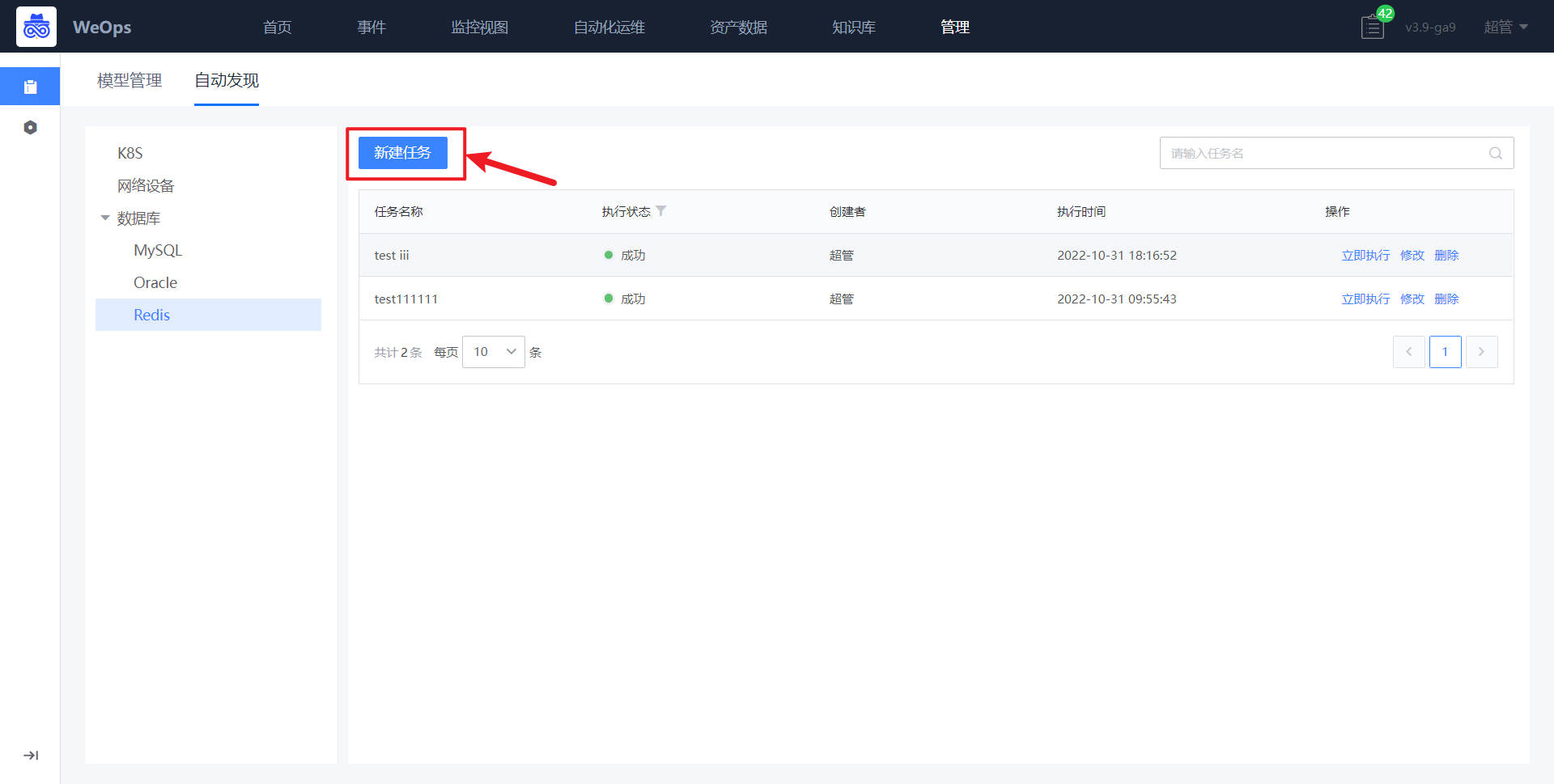
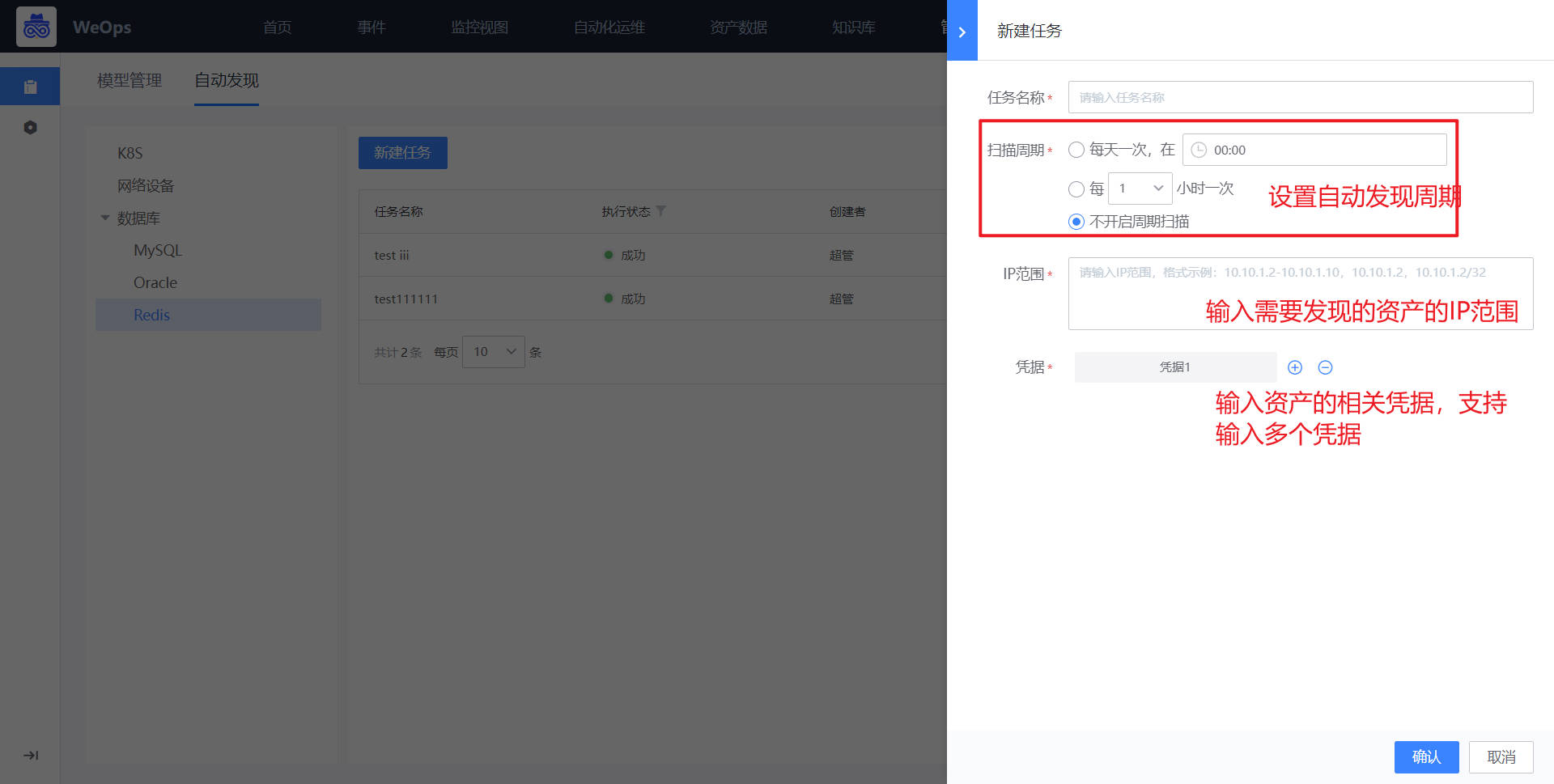
自动发现任务执行完成后,资产数据有如下更新:新增Oracle资产、根据周期实时更新资产配置信息、自动关联对应主机。


云平台纳管(以腾讯云为例)
背景介绍:运维部门需要对云平台(VMware/阿里云/腾讯云)进行资产管理,并展示其直接的关联关系,可以在WeOps的资产数据进行管理,进行云平台的纳管,有两种方式进行:一是手动纳管,手动维护资产信息和关联关系,二是自动发现,自动发现资产信息、关联关系,并自动更新。这里以阿里云为例进行介绍。
方法一:手动纳管
路径:资源-资源记录-腾讯云
如下图,在“腾讯云—云账户”页面,点击“新建”按钮,进行腾讯云账号的创建,这里的“腾讯云账号”是为了区分不同账号下的云服务器而创建的资产模型

如下图,在“腾讯云-CVM”页面,点击“新建”按钮,进行云服务器的创建,并手动填写对应信息。
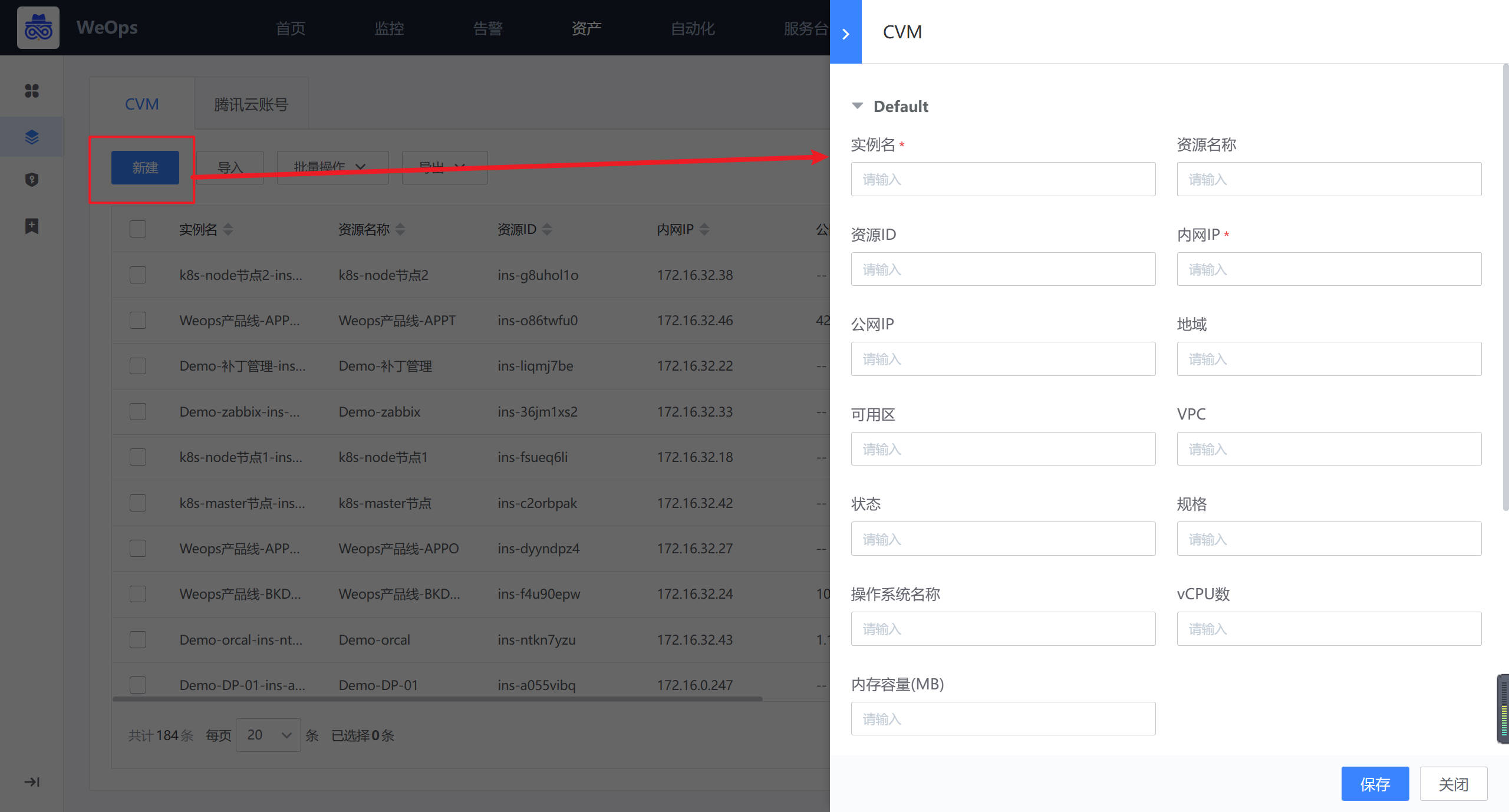
创建完成后,在CVM的实例详情中,进行其与云账户的关联。
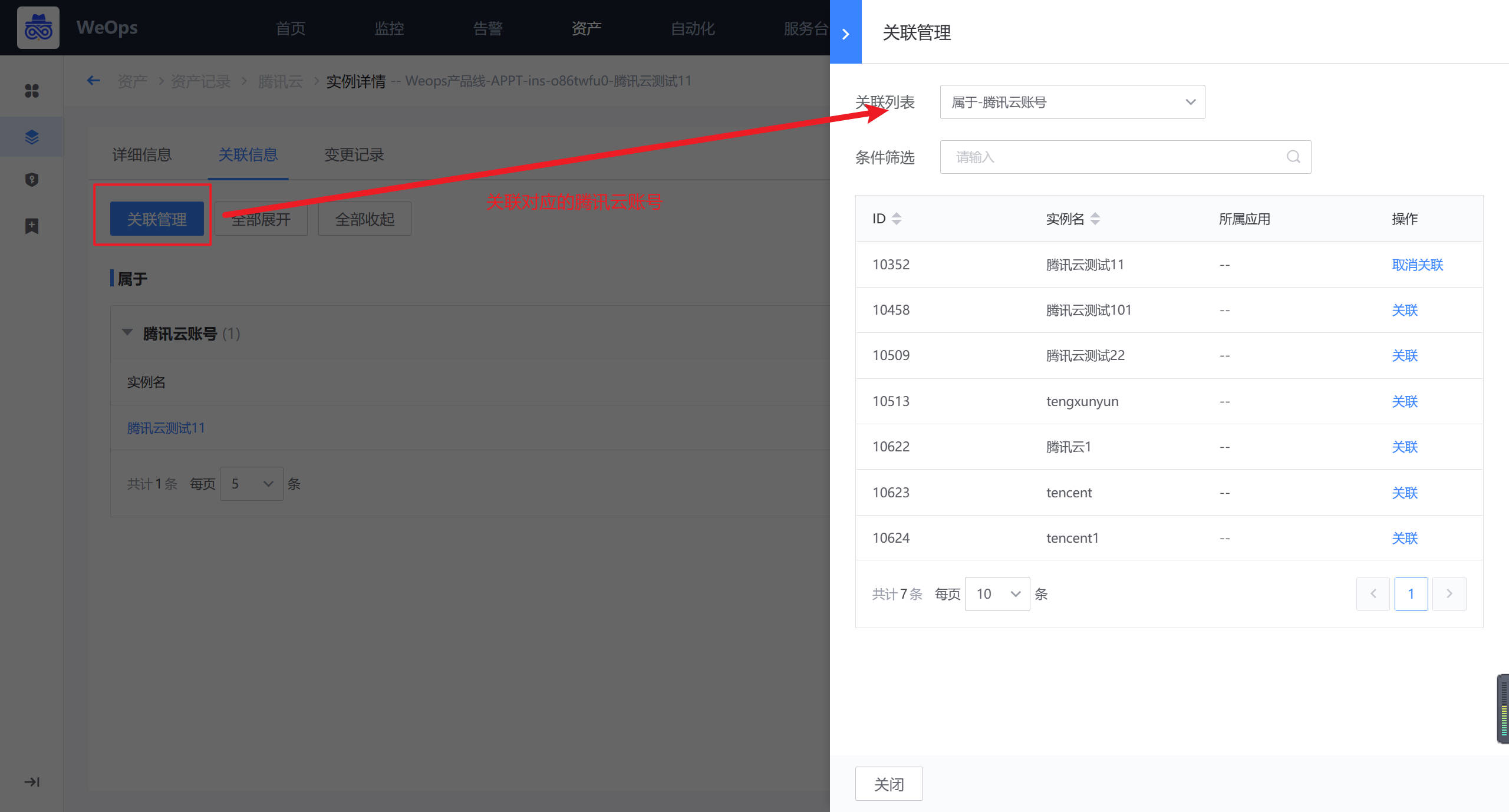
方法二:自动发现
路径:资源-资源记录-腾讯云
如下图,在“腾讯云—云账户”页面,点击“新建”按钮,先进行腾讯云账号的创建。
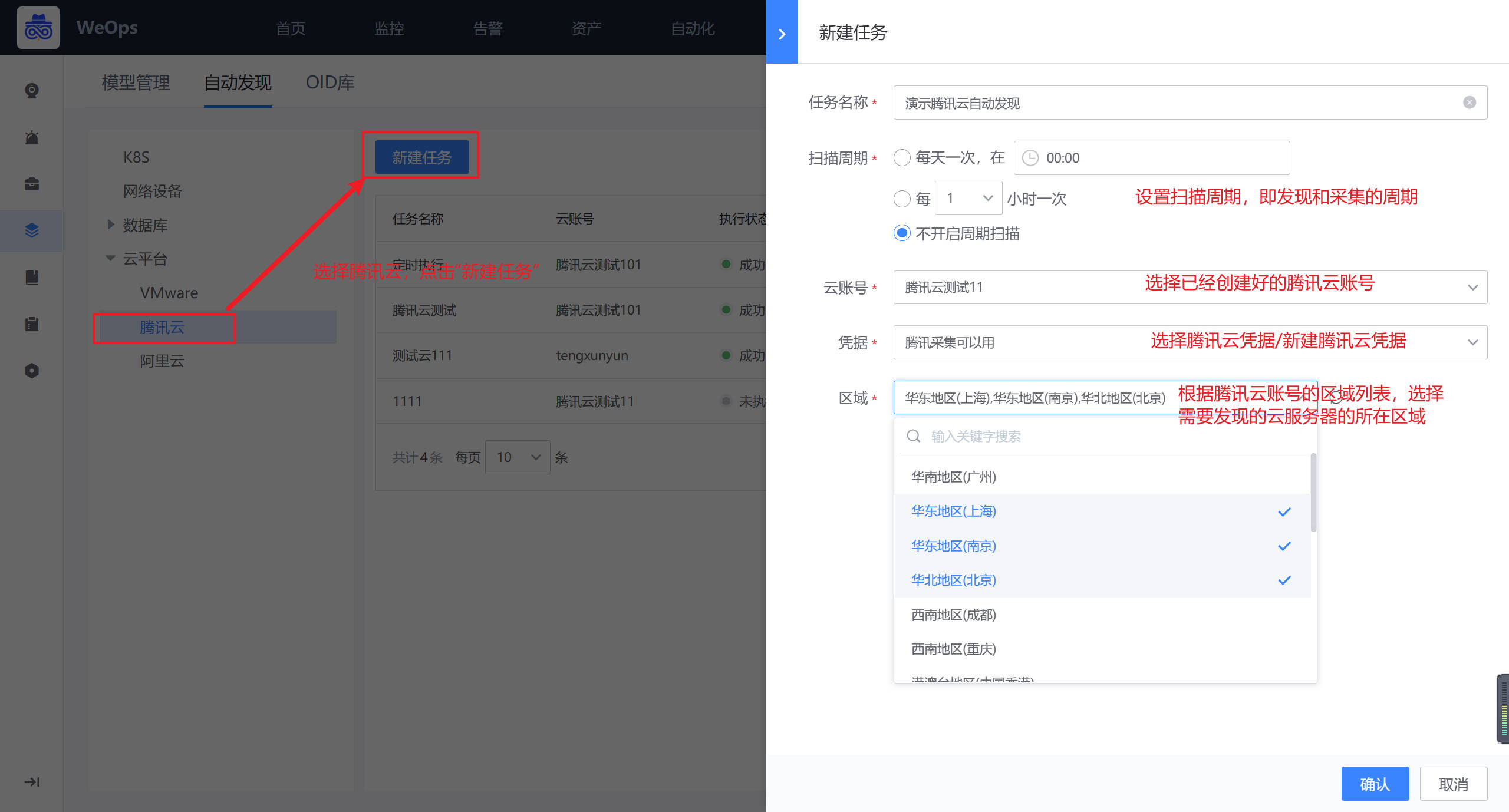
路径:管理-资产管理-自动发现(腾讯云)
在自动发现页面,选择腾讯云,进行腾讯云某个账号下云服务器的发现和采集。在创建采集任务时,可以选择使用已有的凭据,云平台的凭据可在“资产-凭据管理-云平台”中维护,若无关联凭据,在新建自动发现任务时可以新建凭据。
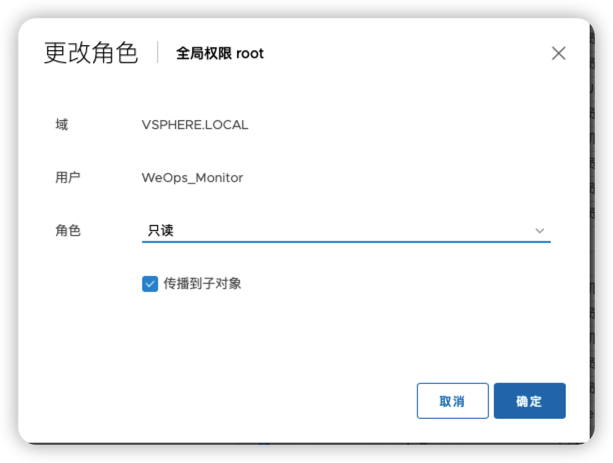
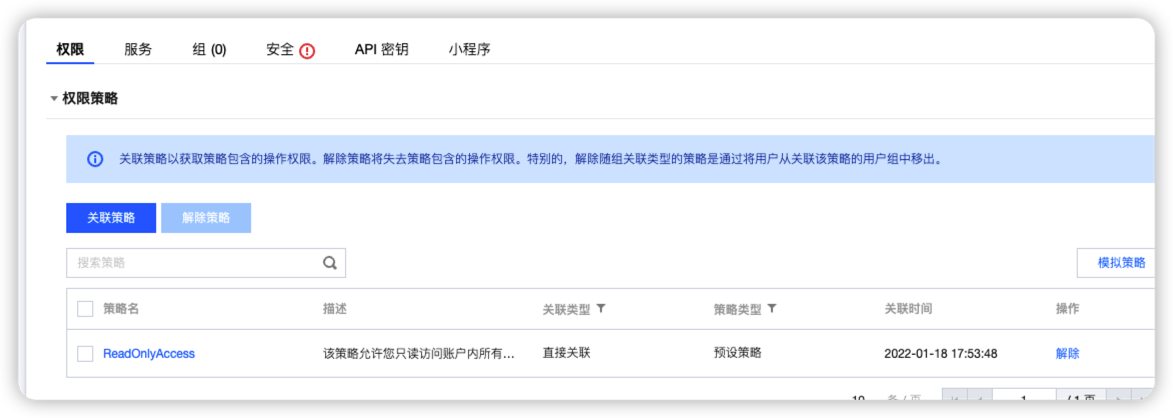
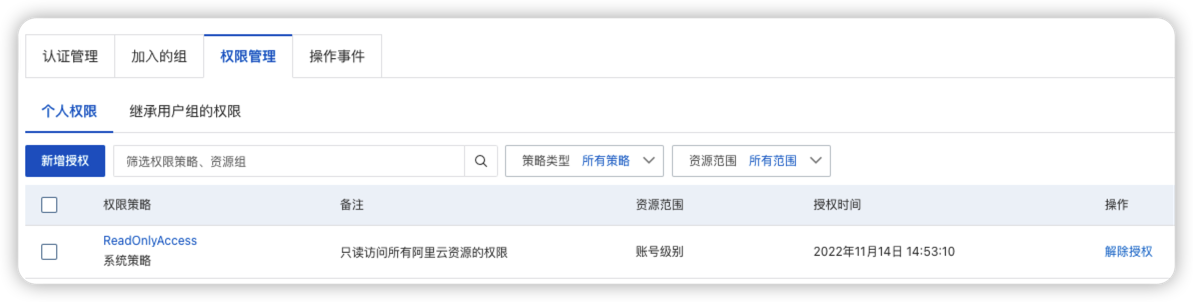
- 阿里云/腾讯云/VMware设置自动发现的账号需要的最小化权限为:只读权限,具体如下
- 域名配置如下:阿里云的域名都是带{资源}+{region}的,例如ecs.cn-guangzhou.aliyuncs.com。腾讯云的域名带{资源}的,例如cvm.tencentcloudapi.com
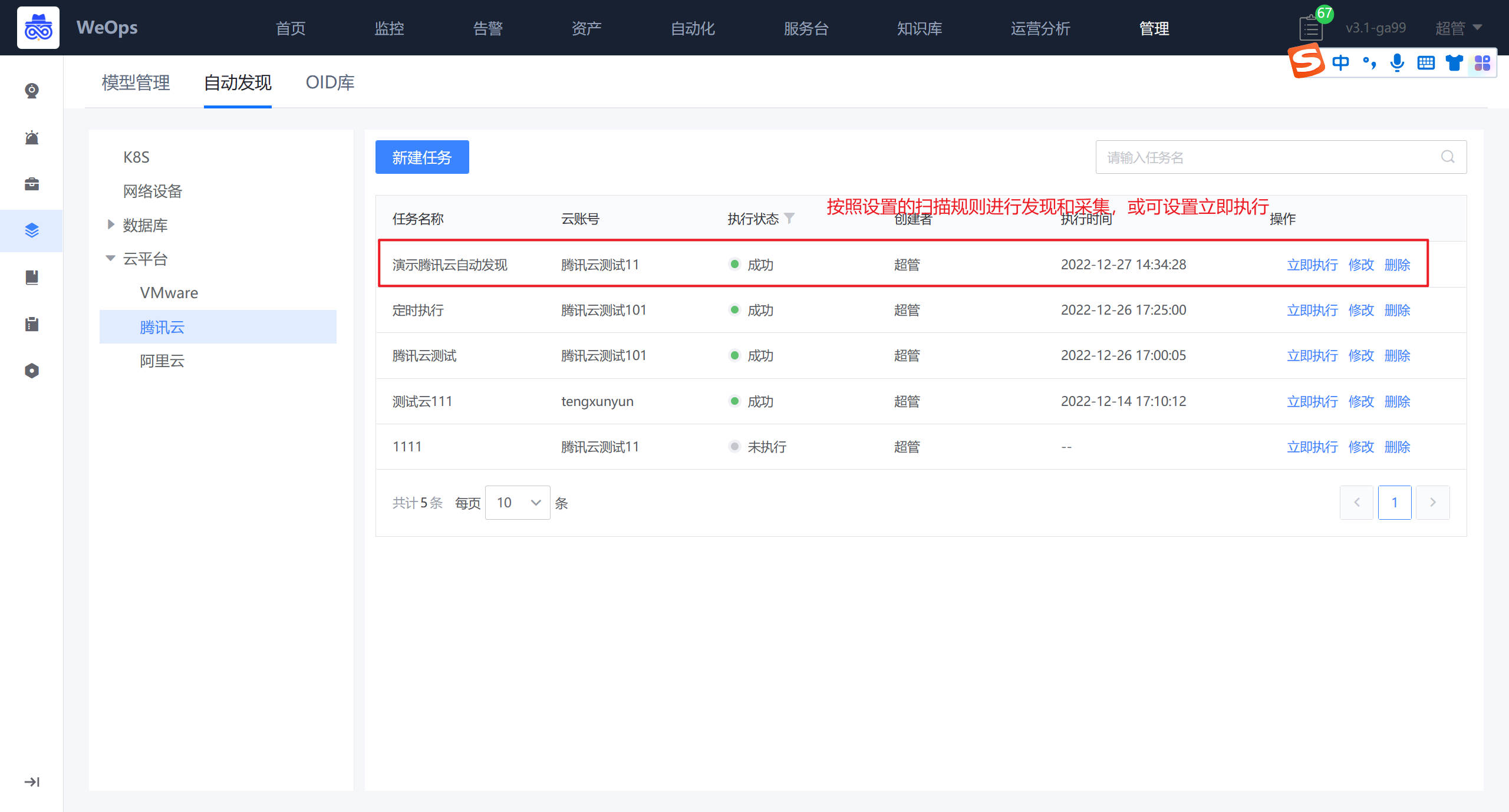
自动发现完之后,自动采集该腾讯云账号下的所有的CVM及其信息,并在“资产记录-腾讯云-CVM”中自动新增/更新信息。
K8S纳管
背景介绍:需要对K8S集群以及相关的命名空间、工作负载、pod、node的信息进行采集和呈现。“WeOps-资产记录”已经内置K8S五项模型及关联关系,包括“K8S集群”、“K8S命名空间”、“K8S工作负载”、“Pod”、“Node”
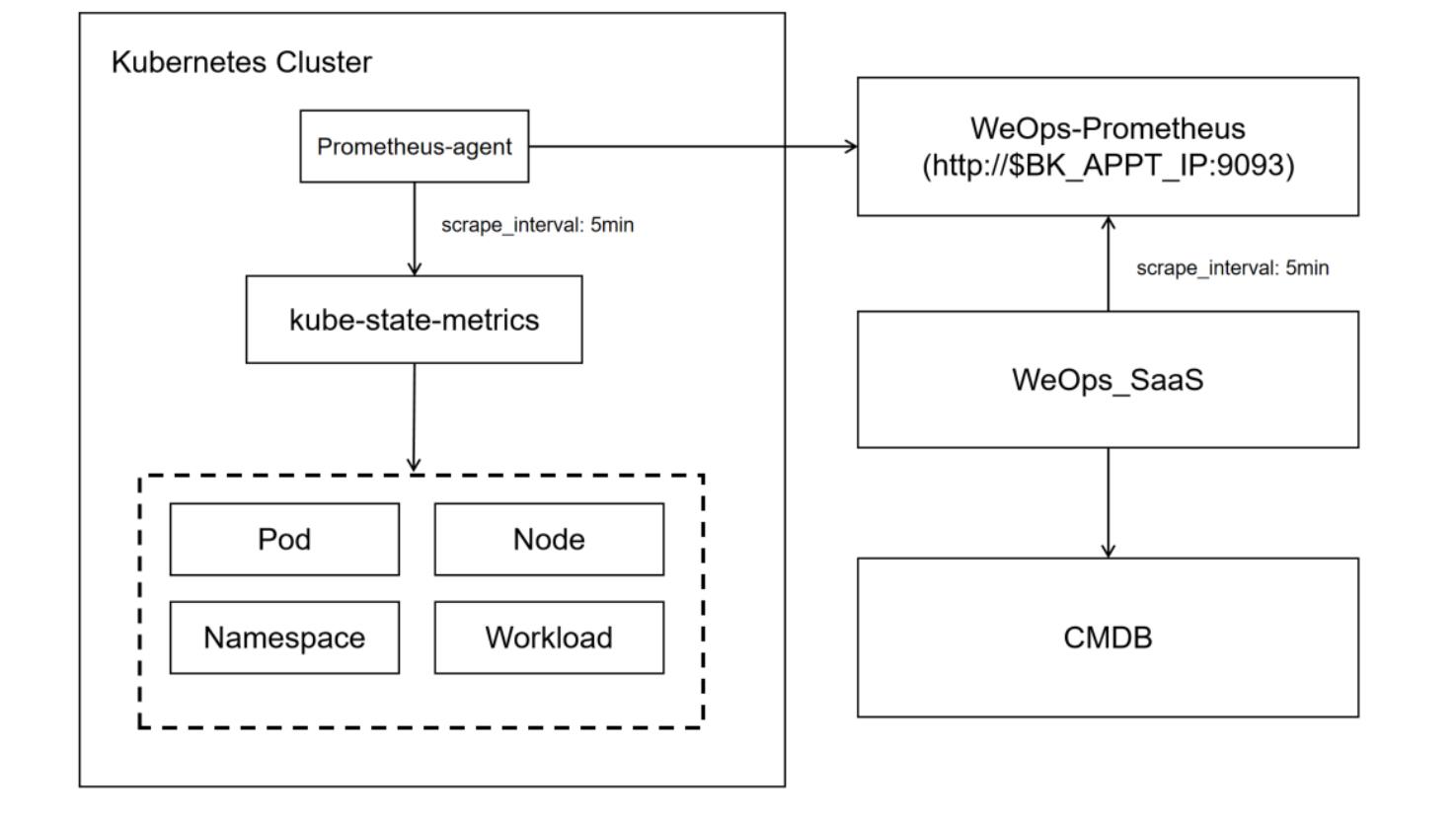
原理介绍:
WeOps对k8s进行配置发现与采集的原理如图
需要额外部署的组件和功能:
1、kube-state-metrics: 集群配置信息的发现采集,需要其他服务主动调取,采用helm的形式在k8s中部署
2、Prometheus-agent: 从kube-state-metrics中获取数据,并推送到weops-prometheus,用helm chart的形式在k8s中部署
3、weops-promtheus: 数据临时存储,weops从此获取原始的资产数据,用docker的形式部署在appt
整体步骤:K8S部署操作——手动创建K8S集群实例——设置自动采集任务——自动采集K8S命名空间、工作负载、pod、node信息,并形成关联拓扑图
Step1:K8S部署操作
1、环境准备(basic auth的用户名密码默认为admin:admin,可按需调整)
在蓝鲸配置平台导入k8s模型组(关联关系必须准确)
#!/bin/bash
mkdir /data/weops/prometheus/tsdb -p
cd /data/weops/prometheus
cat << "EOF" > prometheus-web.yml
basic_auth_users:
admin: $2y$12$Dx1PAPXkUcW10NhuRh.3iuHHDzmT7h6sgv1siHXksRbYk8RrqKkvC
EOF
cat << "EOF" > prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
EOF
docker load < prometheus.tgz2、在appt启动weops附带的prometheus实例:
docker run -d --net=host -v /data/weops/prometheus/prometheus-web.yml:/opt/bitnami/prometheus/conf/prometheus-web.yml -v /data/weops/prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml bitnami/prometheus --name=prometheus --web.listen-address=0.0.0.0:9093 --web.enable-remote-write-receiver --web.config.file=/opt/bitnami/prometheus/conf/prometheus-web.yml --config.file=/opt/bitnami/prometheus/conf/prometheus.yml --storage.tsdb.retention.time=30m运行后telnet localhost 9093 验证部署是否成功
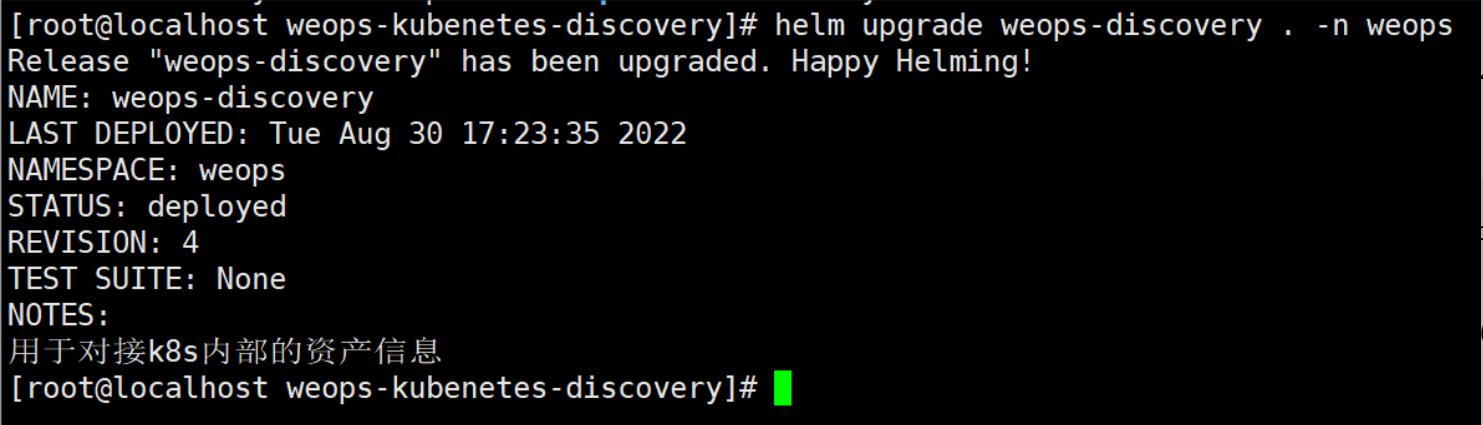
3、在k8s集群中部署kube-state-metrics和promtheus(要求客户的镜像仓库中已有kube-state-metricsd:v2.5.0和prometheus:2.38.0镜像)
在k8s的control-plane上解压helm chart并部署,具体操作步骤可以查看gihub具体解释和操作步骤:https://github.com/WeOps-Lab/WeOps-Charts/
正常应输出(REVISION: 1):
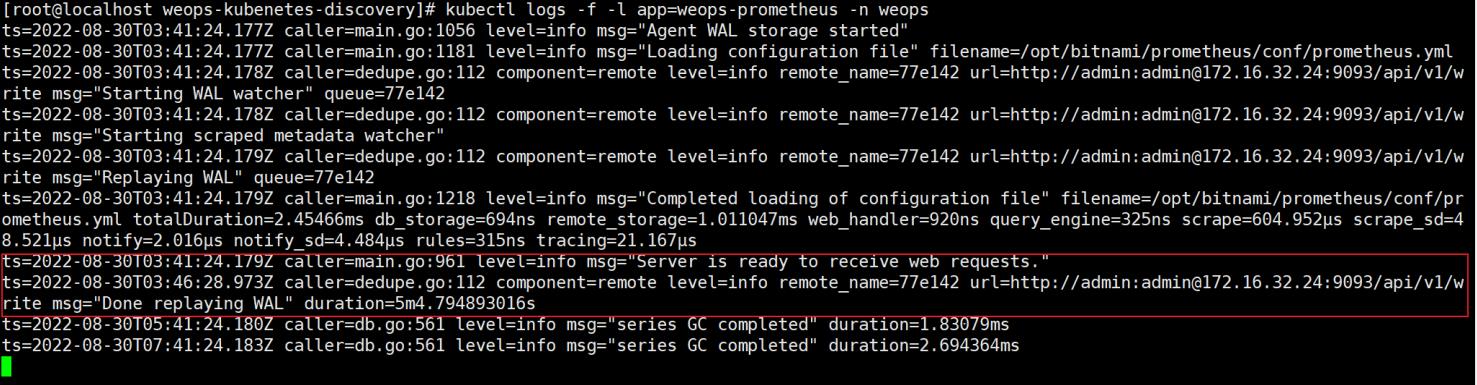
检查pod状态:
kubectl get po -n weops
检查prometheus-agent状态:
Step2:创建K8S集群实例
路径:资源-资源记录-K8S(K8S集群)
如下图,在K8S集群页面中点击“新建”按钮,进行K8S集群实例的创建
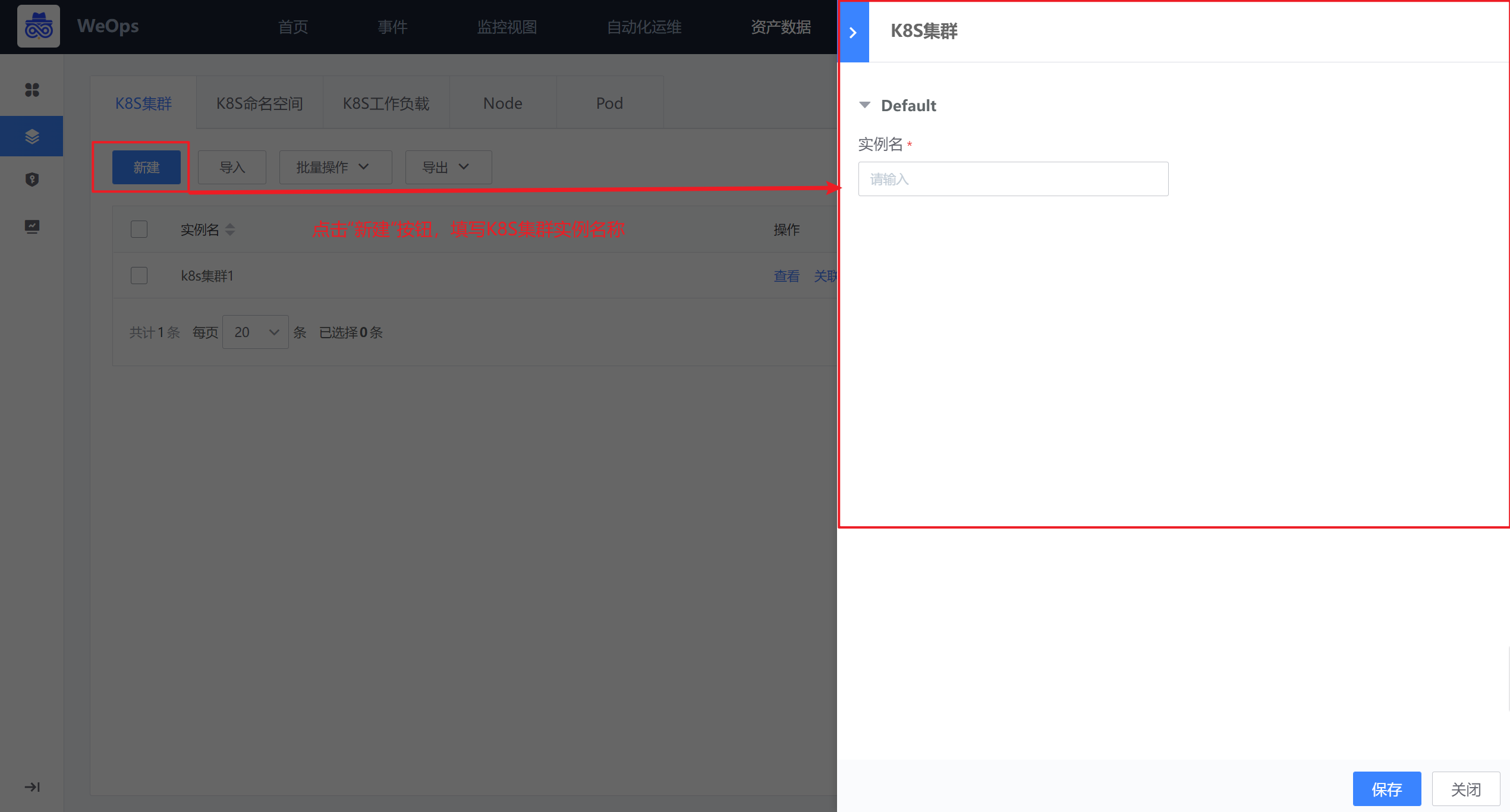
Step3:创建K8S集群自动发现
路径:管理-资产管理-自动发现
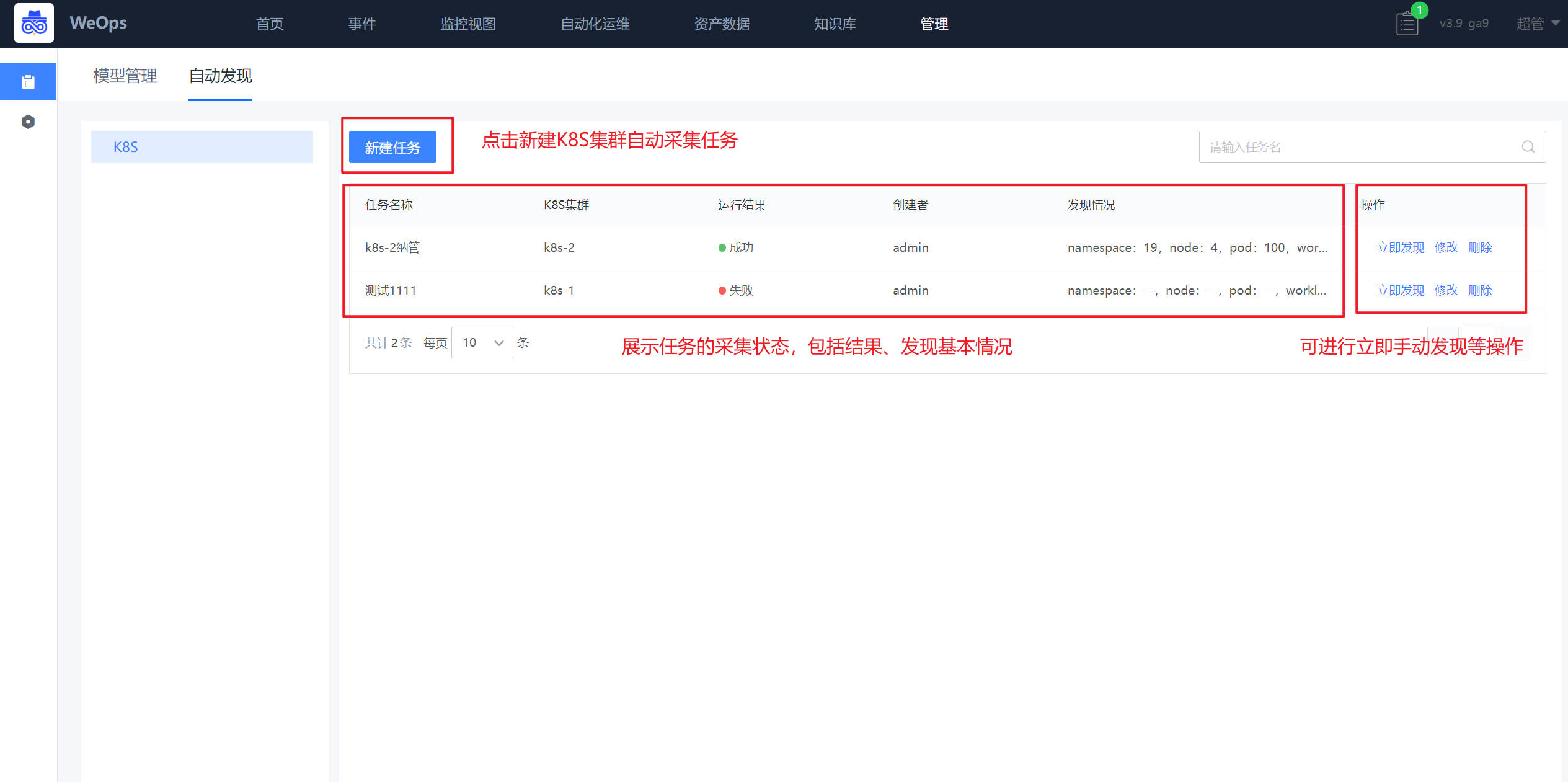
如下图,在自动页面中点击“新建”按钮,进行K8S集群自动发现的任务的创建,创建时仅需要填写任务名称、选择需要采集K8S集群实例名称、设置采集频率即可。
任务创建完成后,可根据设置的采集频率进行采集,也可点击“立即发现”

Step4:自动发现相关信息
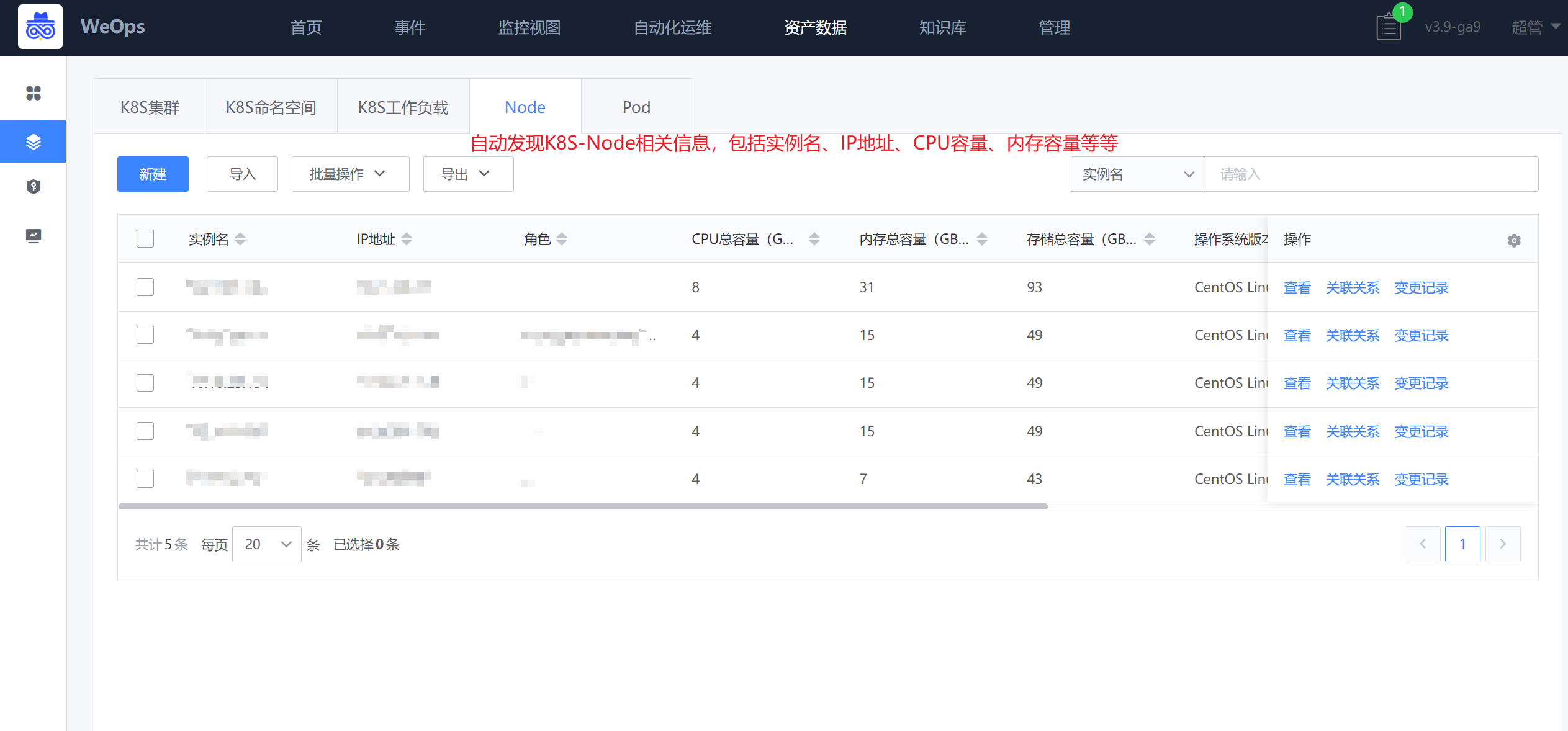
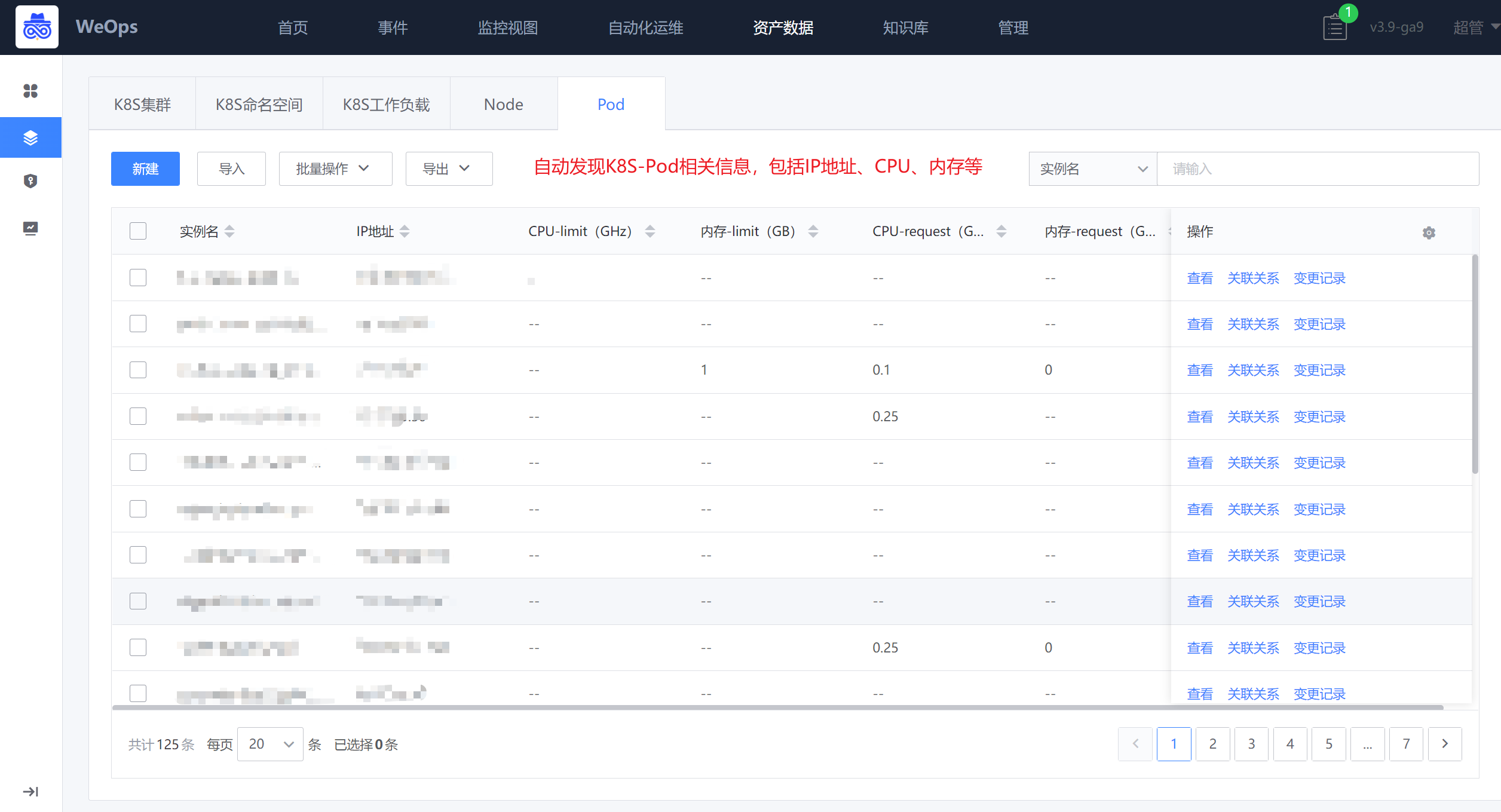
路径:资源-资源记录-K8S(K8S命名空间、K8S工作负载、Pod、Node)
设置自动发现任务后,自动发现该K8S集群下的命名空间、工作负载、Pod、Node相关实例信息,及其关联关系


网络设备纳管
背景介绍:运维部门需要对网络设备(交换机/路由器/负载均衡/防火墙)进行资产管理,并展示其直接的关联关系,可以在WeOps的资产数据进行管理,第一步需要进行网络设备的纳管,有两种方式进行:一是手动纳管,手动维护资产信息和关联关系,二是自动发现,自动发现资产信息、关联关系,并自动更新。这里以交换机为例进行介绍。
方法一:手动纳管
路径:资源-资源记录-基础设备(交换机)
在交换机的页面,点击“新建”按钮,进行资产的新建,填写必要的信息,包括品牌/型号等等,手动创建的资产需要手动维护/更新配置信息。
方法二:自动发现
路径:管理-资产管理-自动发现(网络设备)
在自动发现页面,选择网络设备,进行网络设备的自动发现任务的创建。
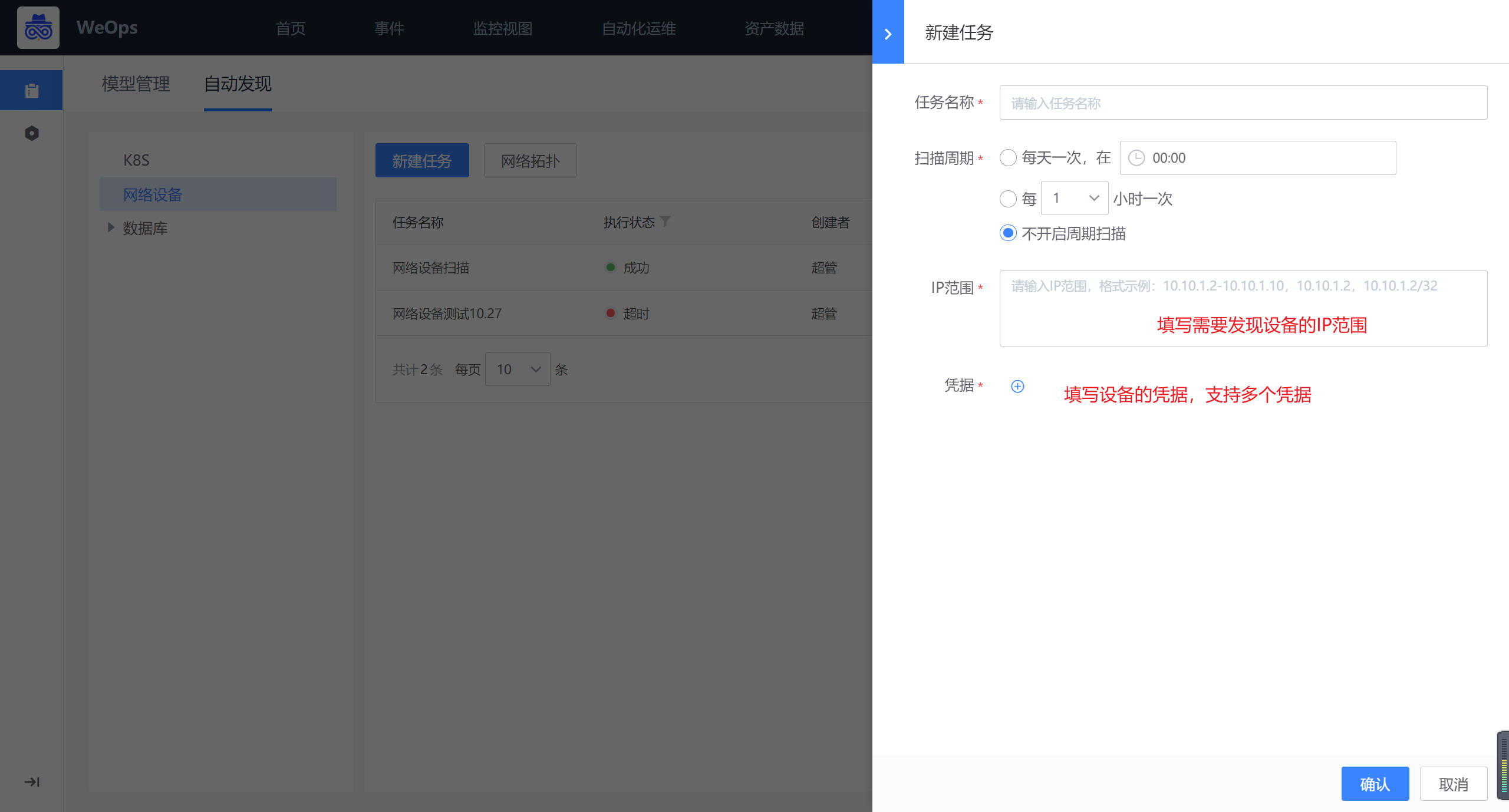
任务创建完成后,任务将会按照填写的信息和时间进行执行,执行完后,若有未识别到的OID,建议点击按照提示添加到OID库,以便后续可以直接自动发现和采集相关的信息。



【特殊说明如下】
在网络设备自动发现过程中,只有网络设备的品牌和型号在OID库的,才能自动发现和采集到相关的信息。如果需要拓展自动发现的范围有两种方式
(1)在管理-资产管理-OID库手动添加需要自动发现的网络设备的品牌型号的OID,添加完成后,自动发现即可发现相关信息。
(2)创建自动发现任务后,经过一次扫描,若有未识别到的OID,根据提示,在OID库中添加,添加完成后,自动发现即可发现相关信息自动发现完成以后,自动采集到的网络设备已经对应的品牌、型号会自动更新到“资产数据-资产记录-交换机“里面
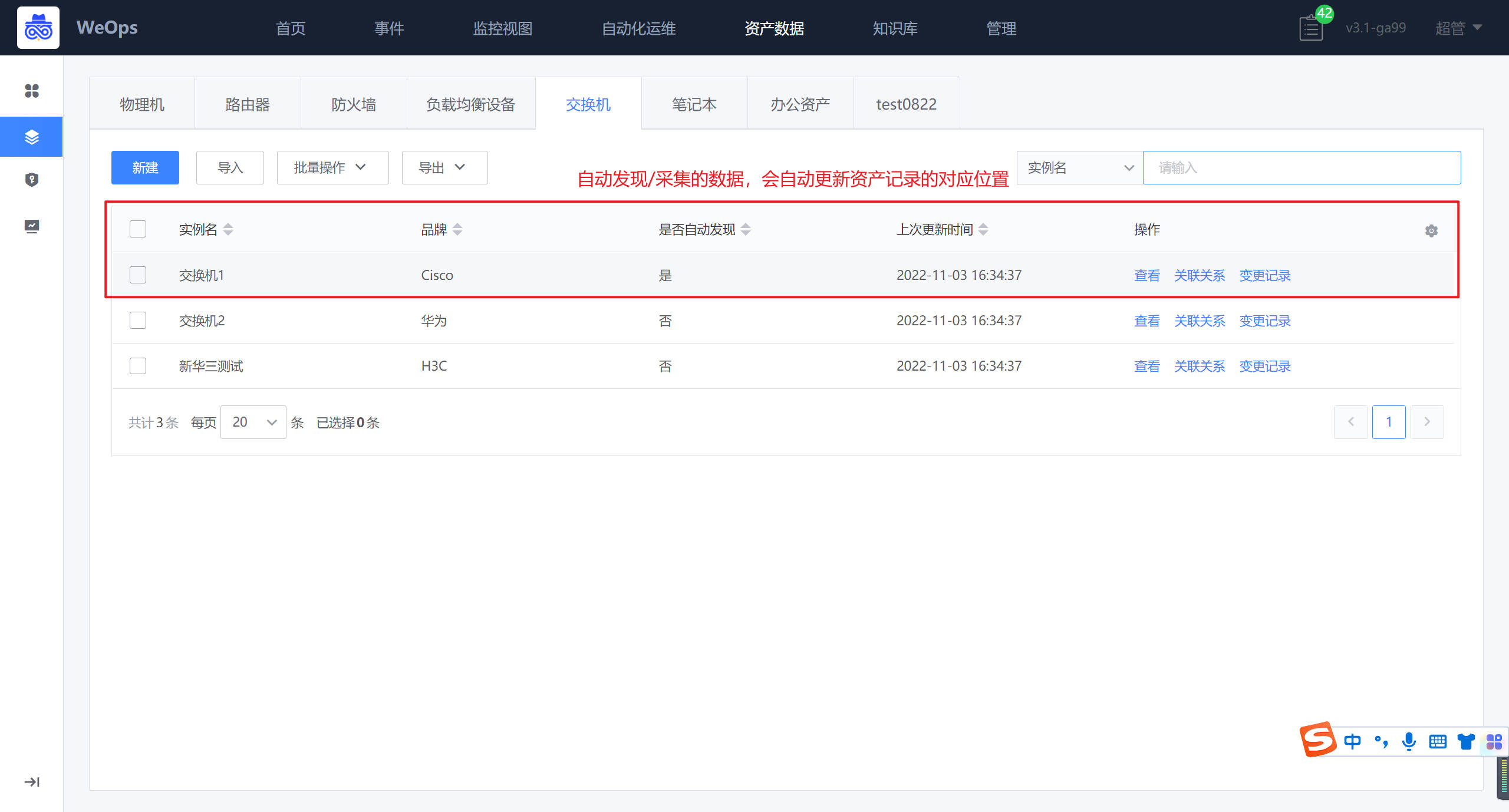
网络拓扑,对于自动发现的网络设备,展示了各个设备的拓扑图,可以通过自动关联/手动关联的方式,完善网络设备的拓扑图。

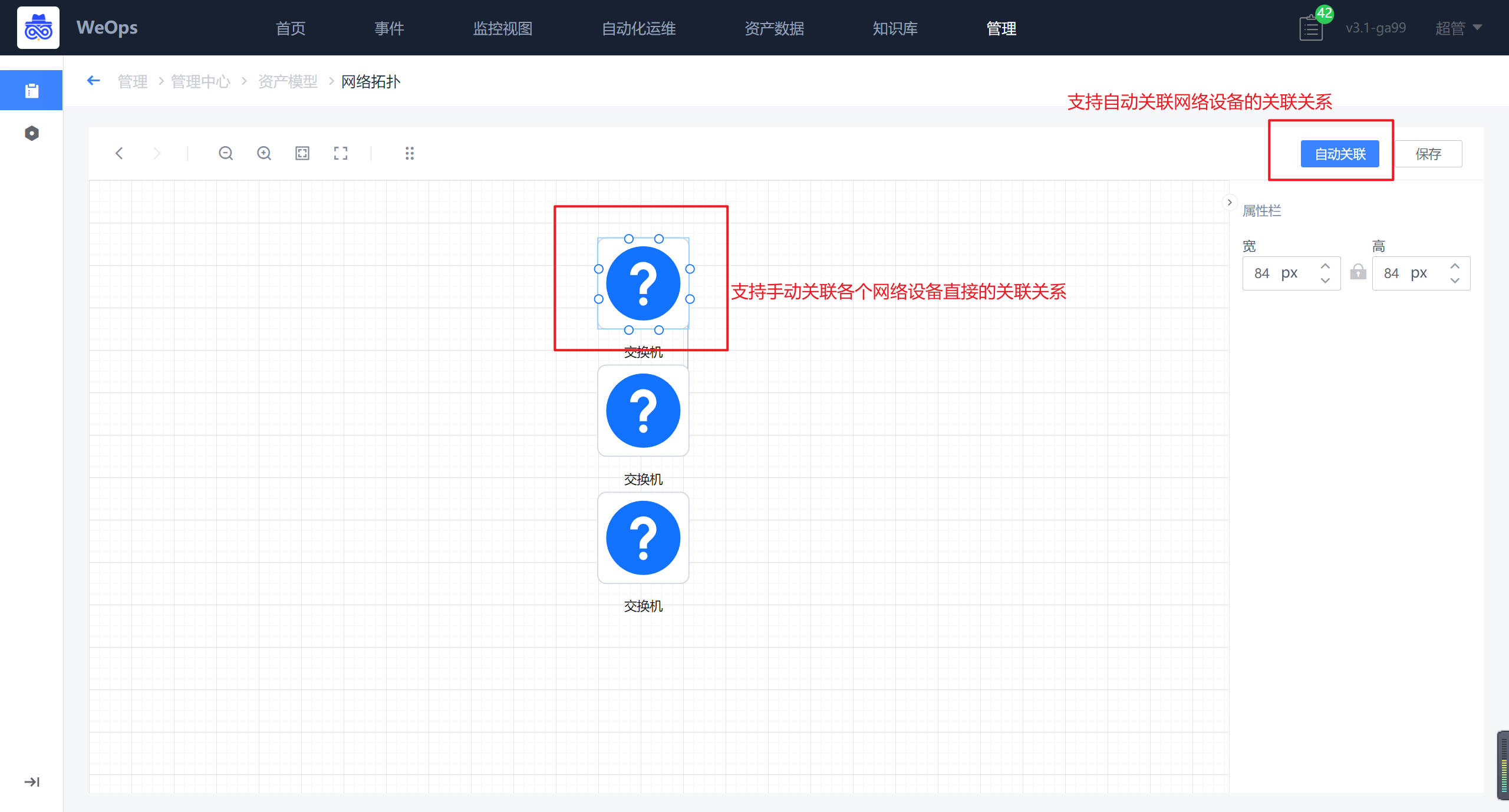
- 注:只有符合内置OID库的网络设备品牌和型号的设备才可以被自动发现,若需要拓展OID库,如下图,可进行不同品牌型号的网络设备的OID新增,新增完成后,可进行自动发现和采集。

配置文件纳管(以主机配置文件为例)
背景介绍:运维部门需要对资源的配置文件进行资产管理,方便查看和使用,目前WeOps已经内置好“配置文件”的模型,已经与各个资产模型相关联,支持对各个资源的配置文件上传和管理,另外WeOps支持对主机类/网络设备类的配置文件自动发现和更新。
Step1:前提条件,确认关联
路径:管理-资产管理-模型管理
如下图,以主机为例,在资产管理-模型管理中,点击“配置文件”模型的按钮,在“关联”中,检查关联情况
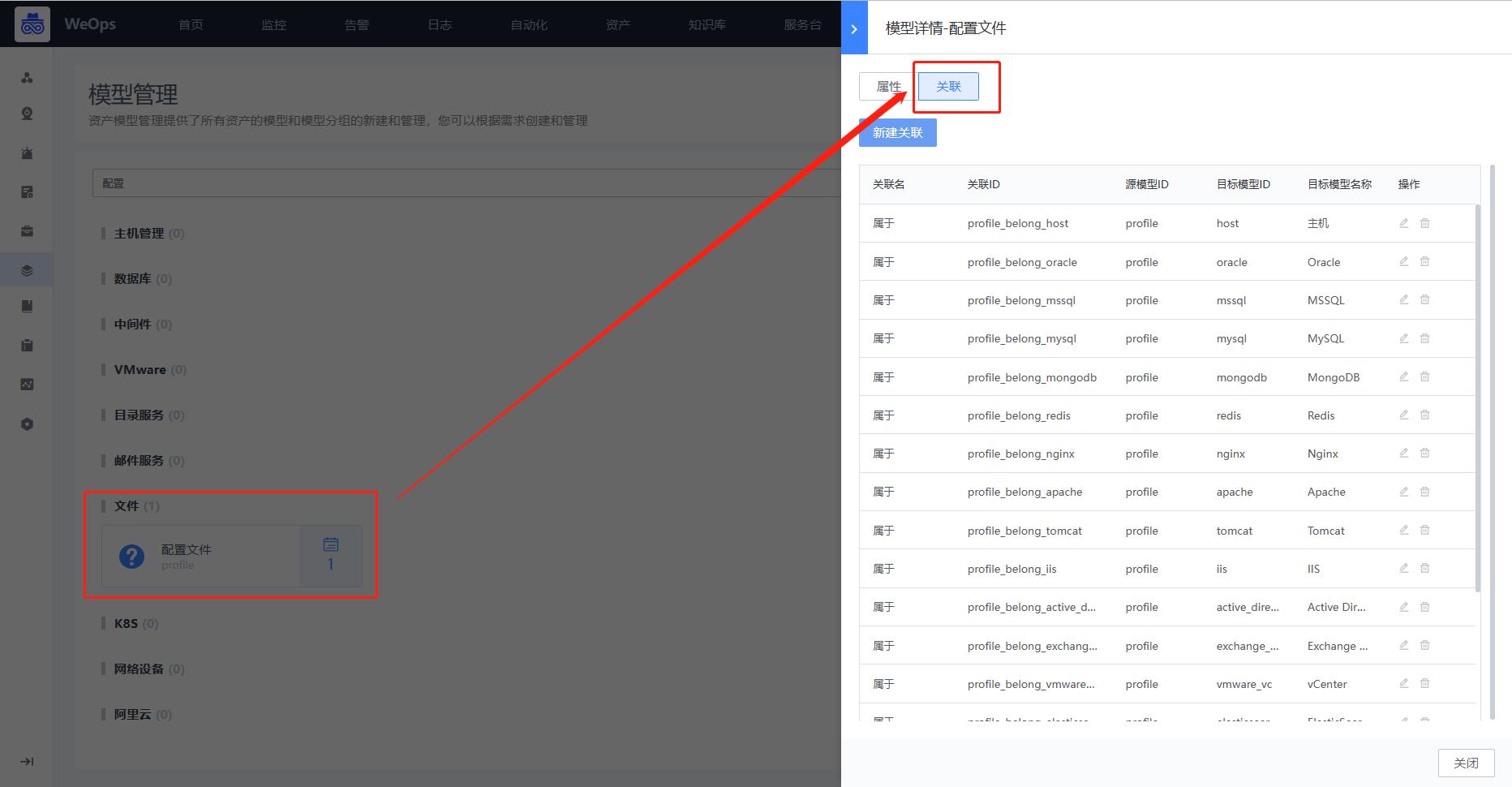
Step2:配置文件创建
路径:资源-资产记录-主机
当资源模型的关联配置完成以后,就可以在主机的详情页看到配置文件的tab,如下图,在主机列表中,点击“查看”按钮
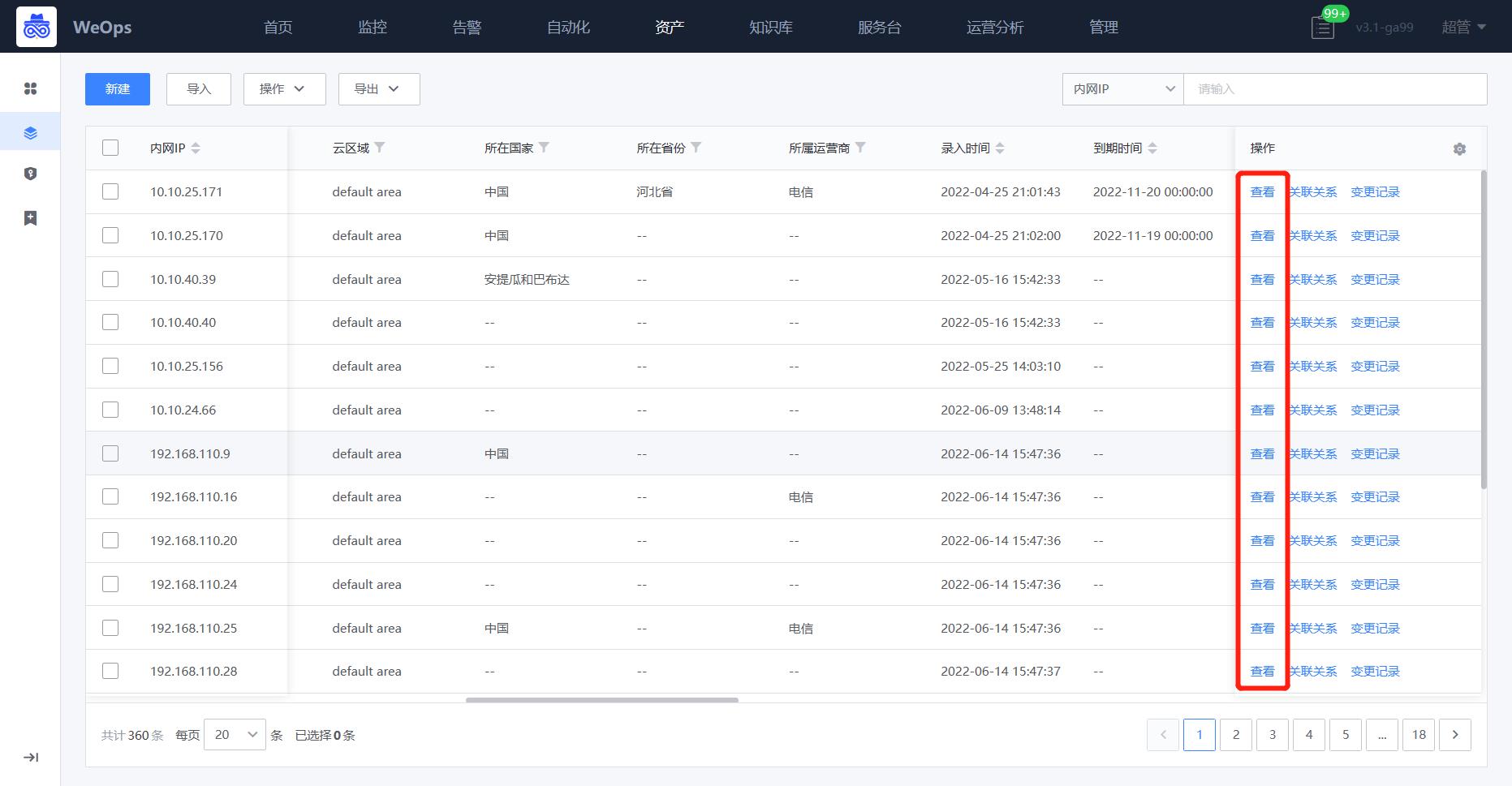
如下图,可以进行配置文件的创建,选择对应的维护人,每个配置文件点击详情后,可以查看这个配置文件的具体内容
- 关于文件的上传有两种方式,对于主机/网络设备类的资产,已经支持自动采集的能力,可以创建配置文件的自动采集任务进行文件的采集和版本的更新;对于其他资产的配置文件来说,需要进行手动的上传和版本的维护。
Step3:配置文件自动采集
路径:管理-资源管理-自动发现
- 对于主机/网络设备来说,配置文件支持自动发现和自动采集,所以在自动发现页面,选择配置文件进行配置文件自动采集任务的创建,这里以主机为例进行介绍

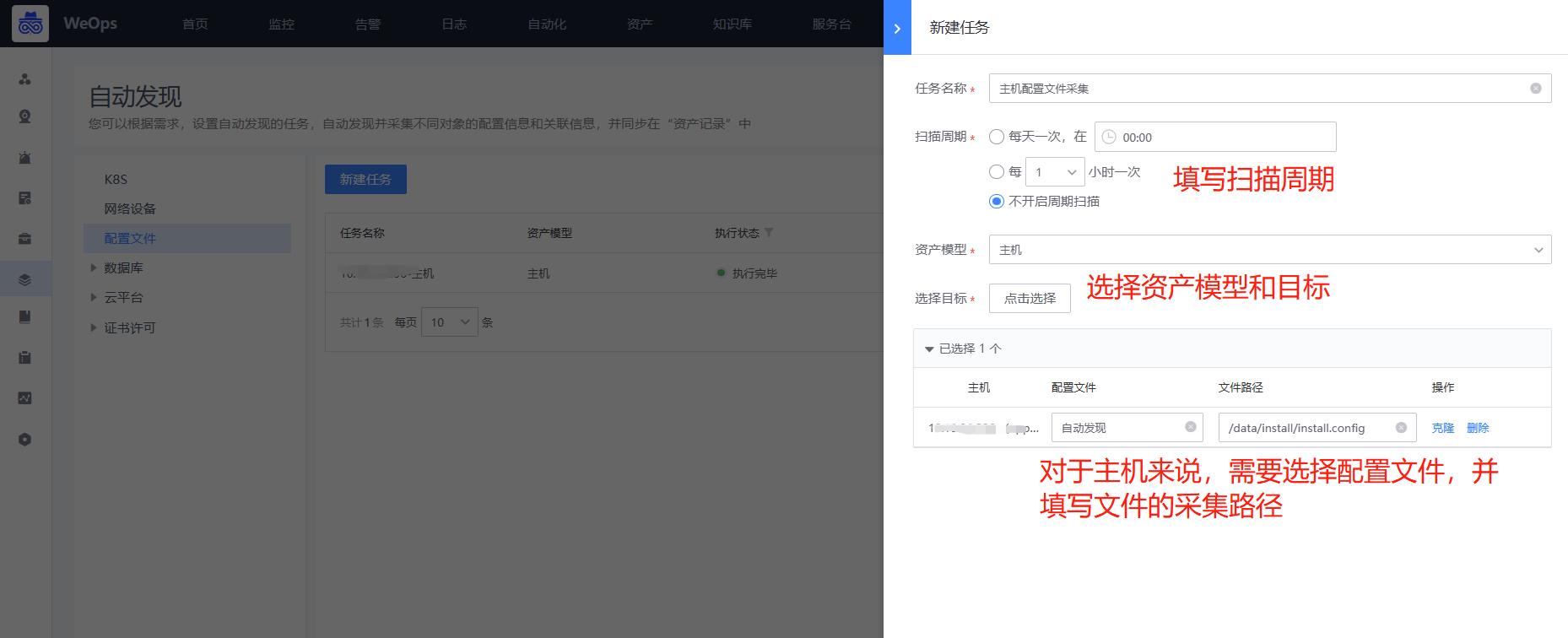
- 任务执行后,可以在“资源-资产记录-主机-配置文件”中,查看这个主机的这个配置文件的采集信息

Step3:配置文件手动维护
路径:资源-资产记录-主机
- 对不同版本的配置文件进行手动上传文件,修改/删除等操作,也可以支持预览
Step4:配置文件使用
- 针对不同版本的文件,支持选择两个版本的文件进行对比,并标出差别之处

- 针对变更记录,可查看每个配置文件的变更情况,以及变更前后的对比。
SSL证书纳管
背景介绍:运维部门关于多个域名,对于域名的证书相关信息的管理也尤为重要,尤其是证书的到期时间,WeOps提供SSL证书自动发现和采集能力,支持定期采集/更新证书的信息,结合事件到期提醒功能,即将到期的证书发送提醒。
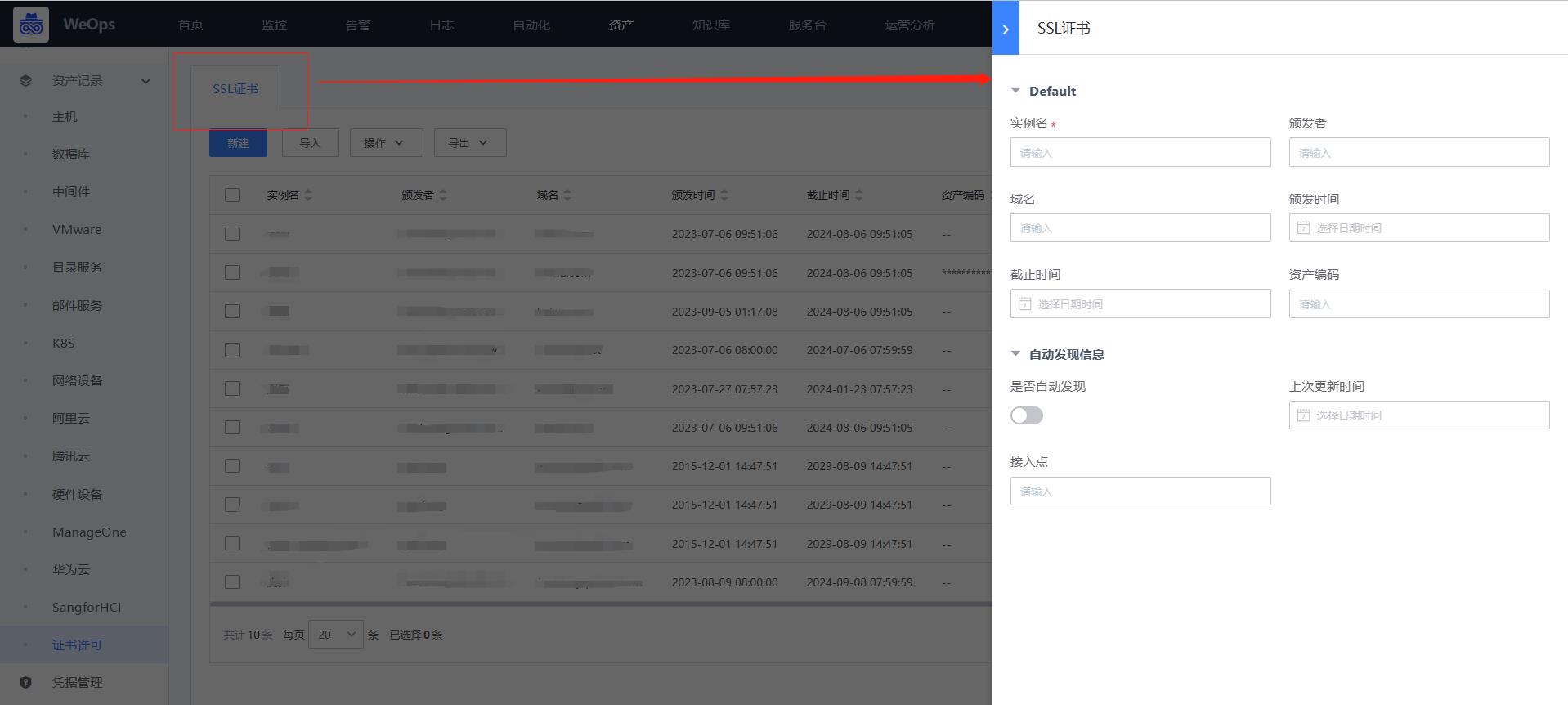
Step1:创建证书实例
路径:资源-资产记录-证书
- 如下图,在资产记录中创建一个SSL证书的实例,以便后续自动发现使用。
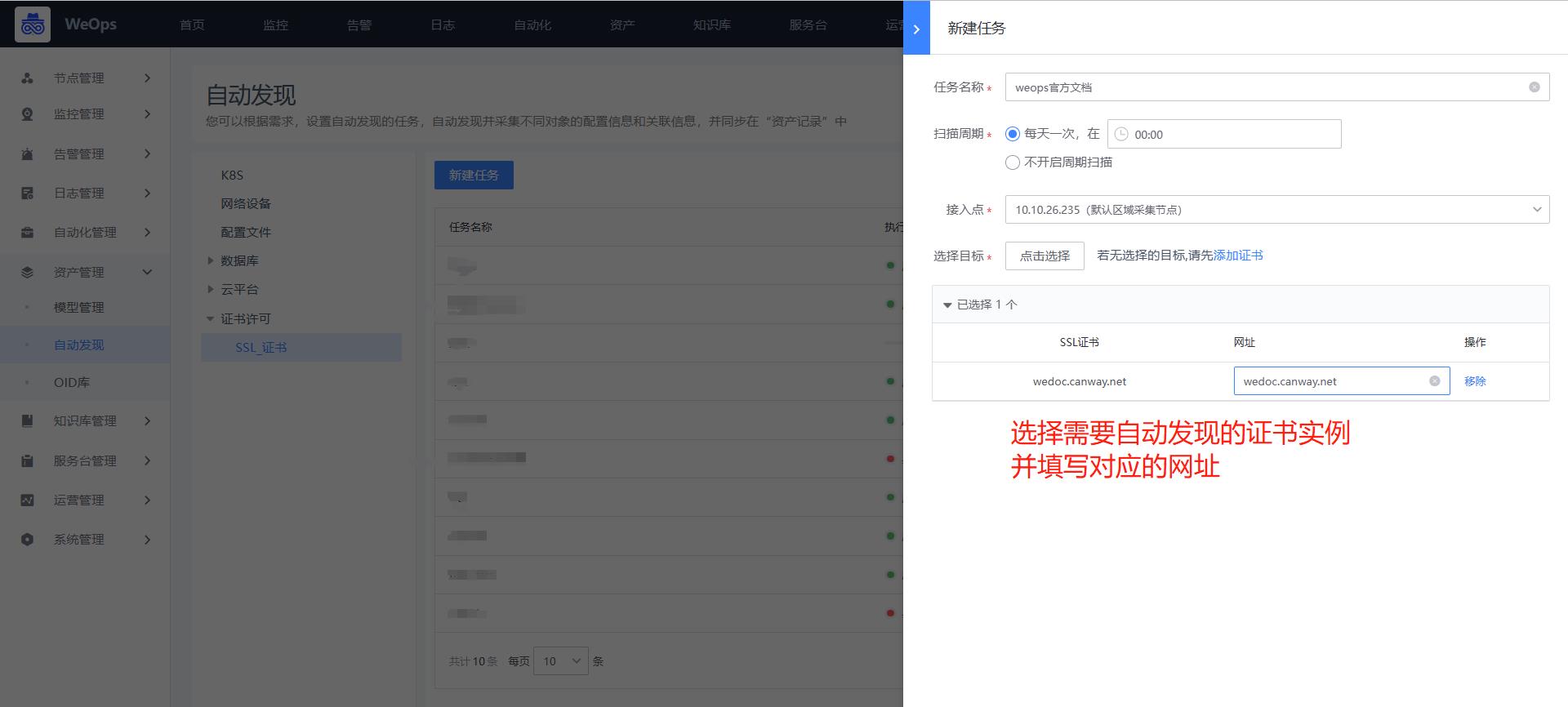
Step2:创建证书自动发现
路径:管理-资产管理-自动发现
- 如下图,选择自动发现-SSL证书,选择刚才创建的正式实例,并为这个证书填写域名,比如“wedoc.canway.net”,填写完成,选择对应的扫描周期,即可按照周期进行扫描。当证书更新后,也会根据最新的扫描情况,进行更新相关信息。
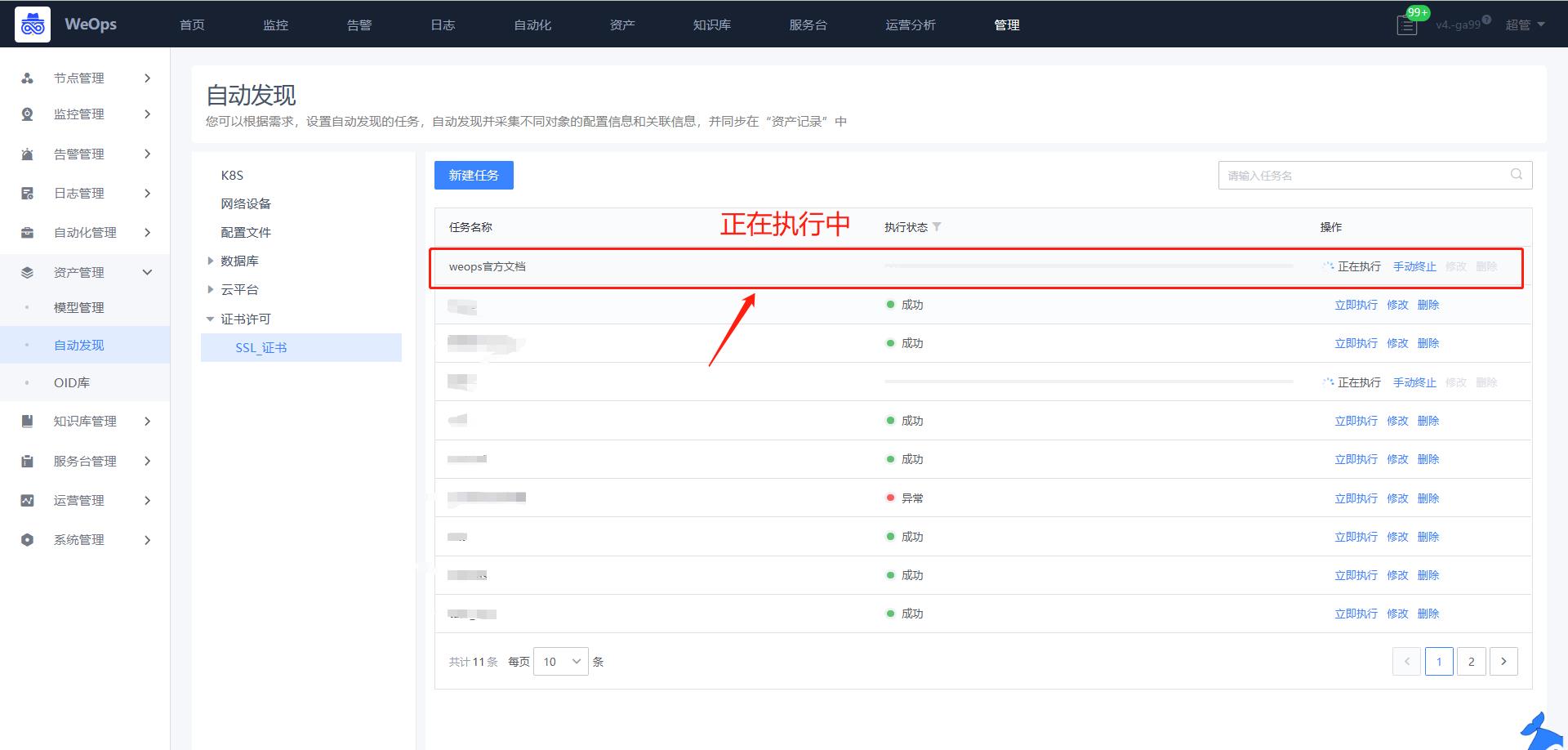
Step3:证书自动发现/更新
路径:资源-资产记录-证书
*任务执行完成后,在资产记录的列表,可以看到采集的证书信息,包括“颁发者”、“域名”、“颁发时间”、“截止日期”等信息。

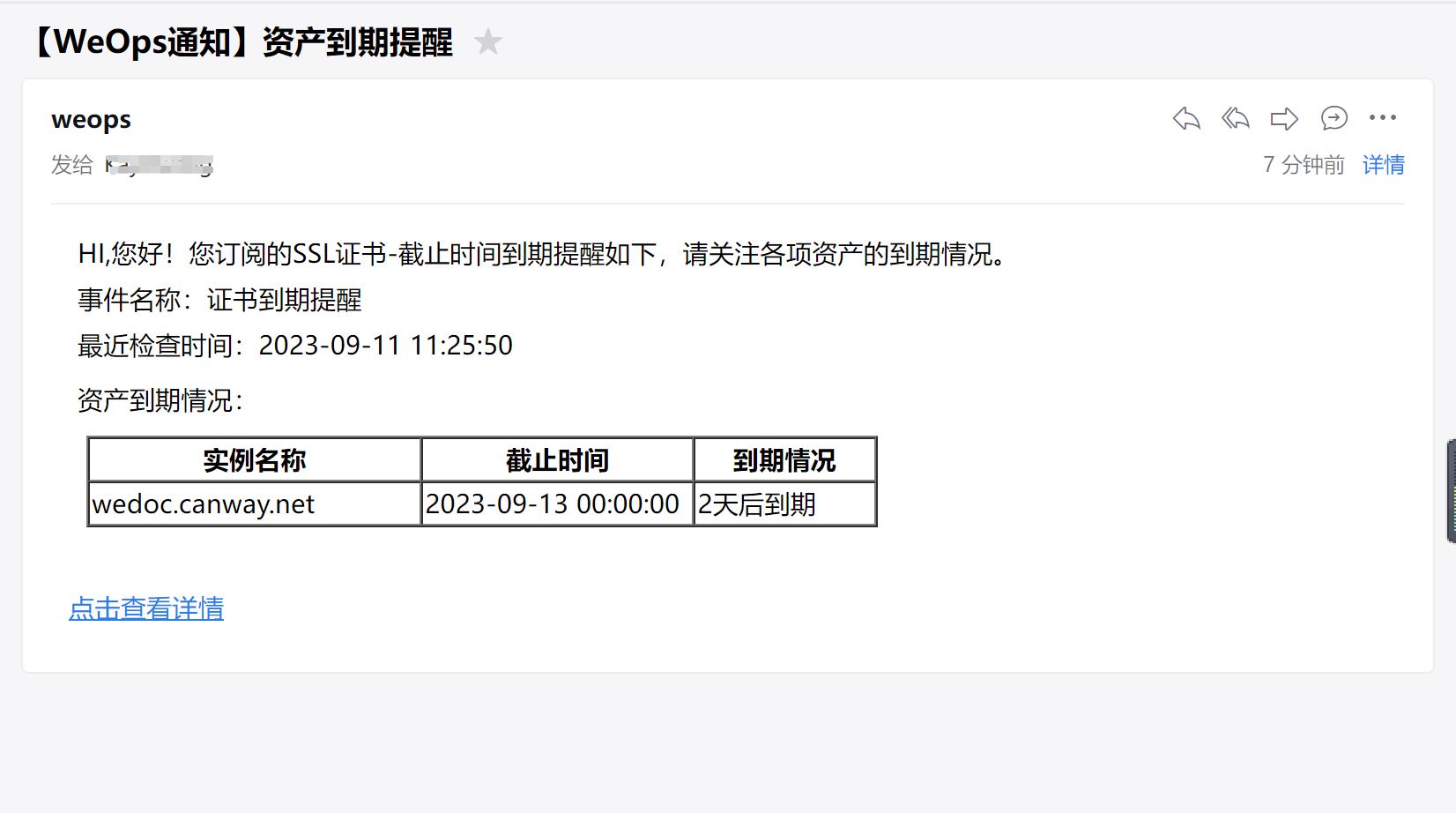
Step4:到期提醒
路径:资源-事件订阅
- 当证书自动发现和采集创建完成之后,可以针对需求,对证书的到期时间进行订阅,在“事件订阅”中创建任务,选择证书的“截止日期”字段,创建扫描和提醒的时间,配置完后,会安装配置的提醒时间,发送邮件提醒。

IP发现
背景介绍:适用于以下场景
1、查看资产IP:自动发现的IP和资产关联,可以查看资产使用的IP情况 2、判断IP是否空闲:查看IP列表,确定IP是否被使用 3、查看子网IP的使用情况:通过子网的关联情况和剩余量等数据,查看子网使用情况
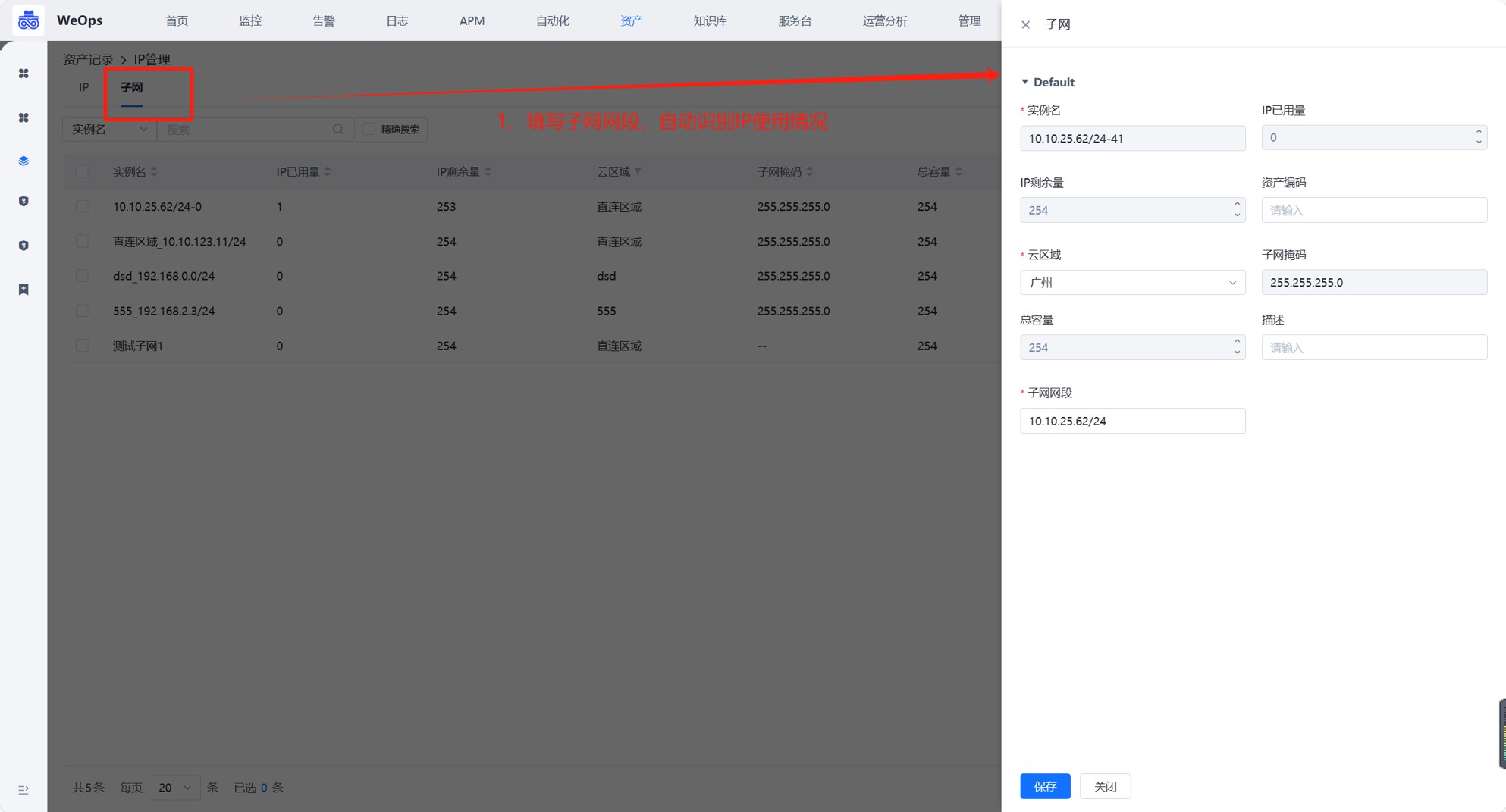
step1:手动录入子网
路径:资产-资产记录-IP管理-子网
录入子网的网段,比如192.168.0.0/24,录入后:自动识别子网总容量、自动识别子网掩码
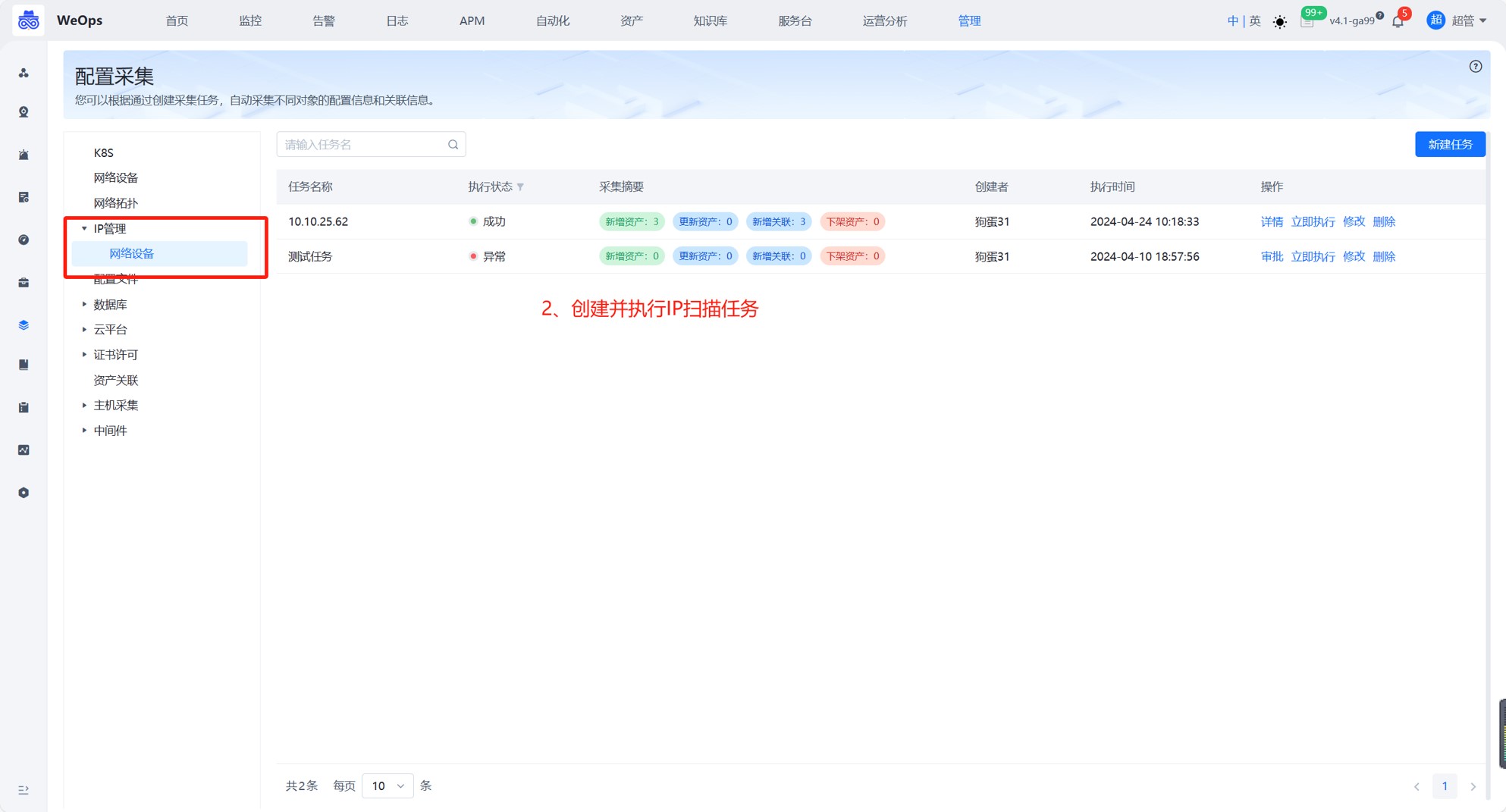
step2:创建IP自动扫描任务
路径:管理-资产管理-配置采集-IP
选择对象类型(目前支持网络设备的),选配扫描周期,选配凭据等信息
step2:效果查看
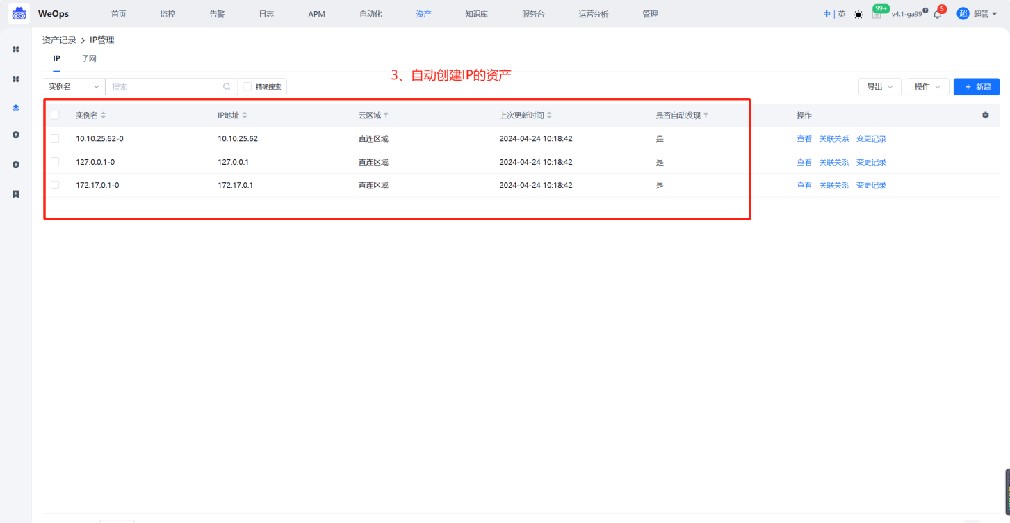
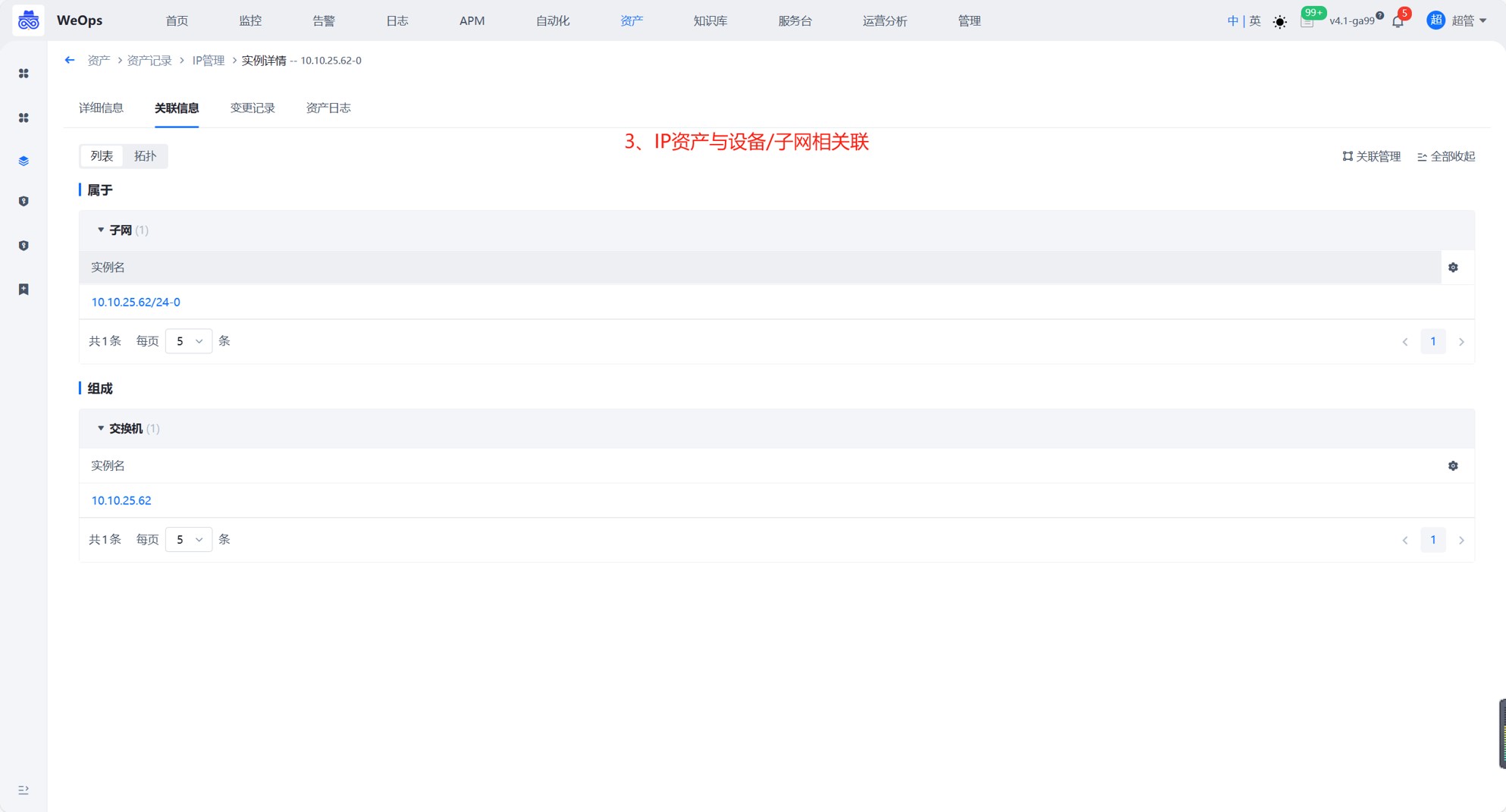
路径:资产-资产记录-IP管理-子网/IP
1、自动录入IP信息和关联关系
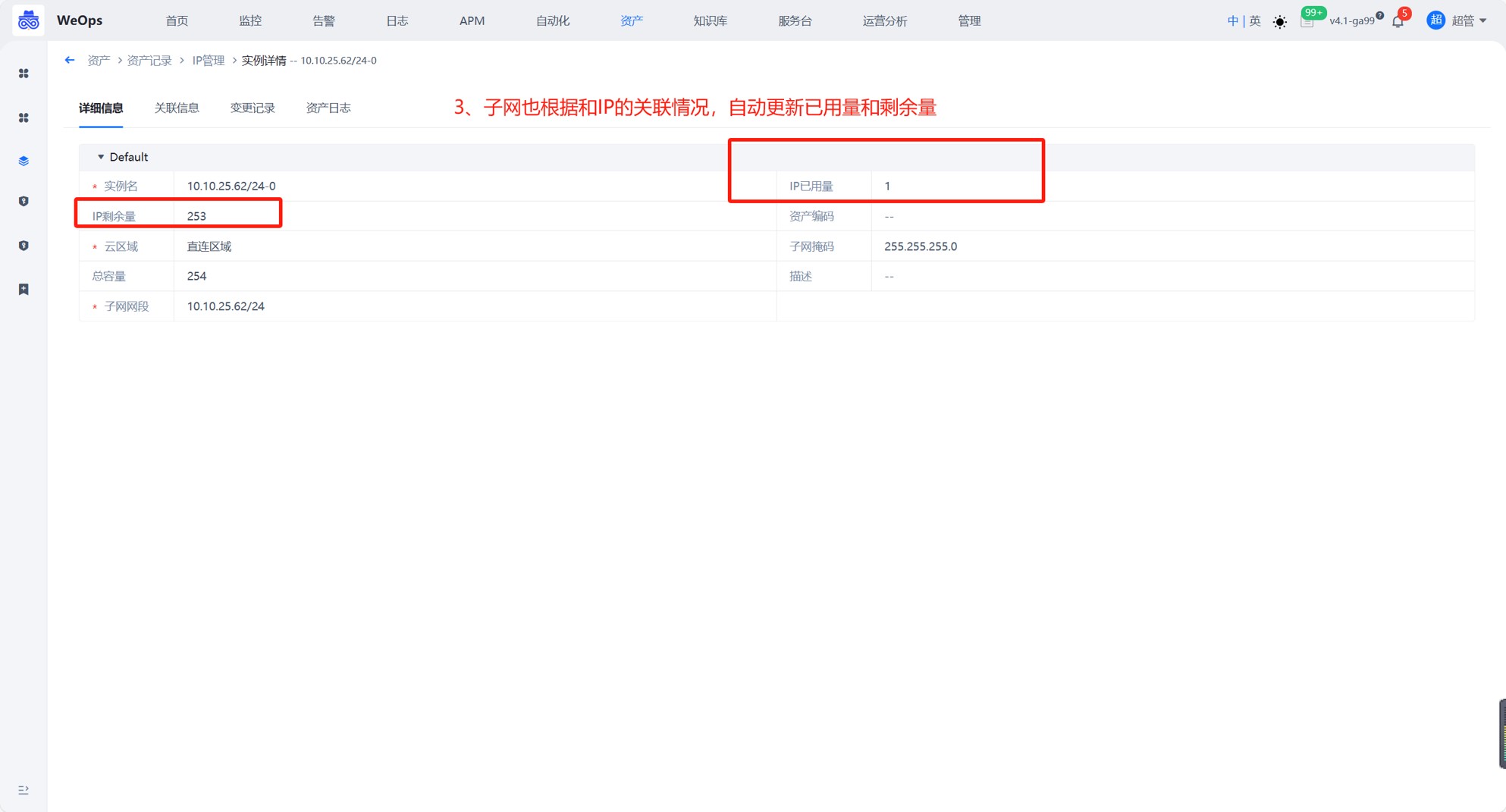
2、子网根据关联的IP地址情况,自动更新余量信息
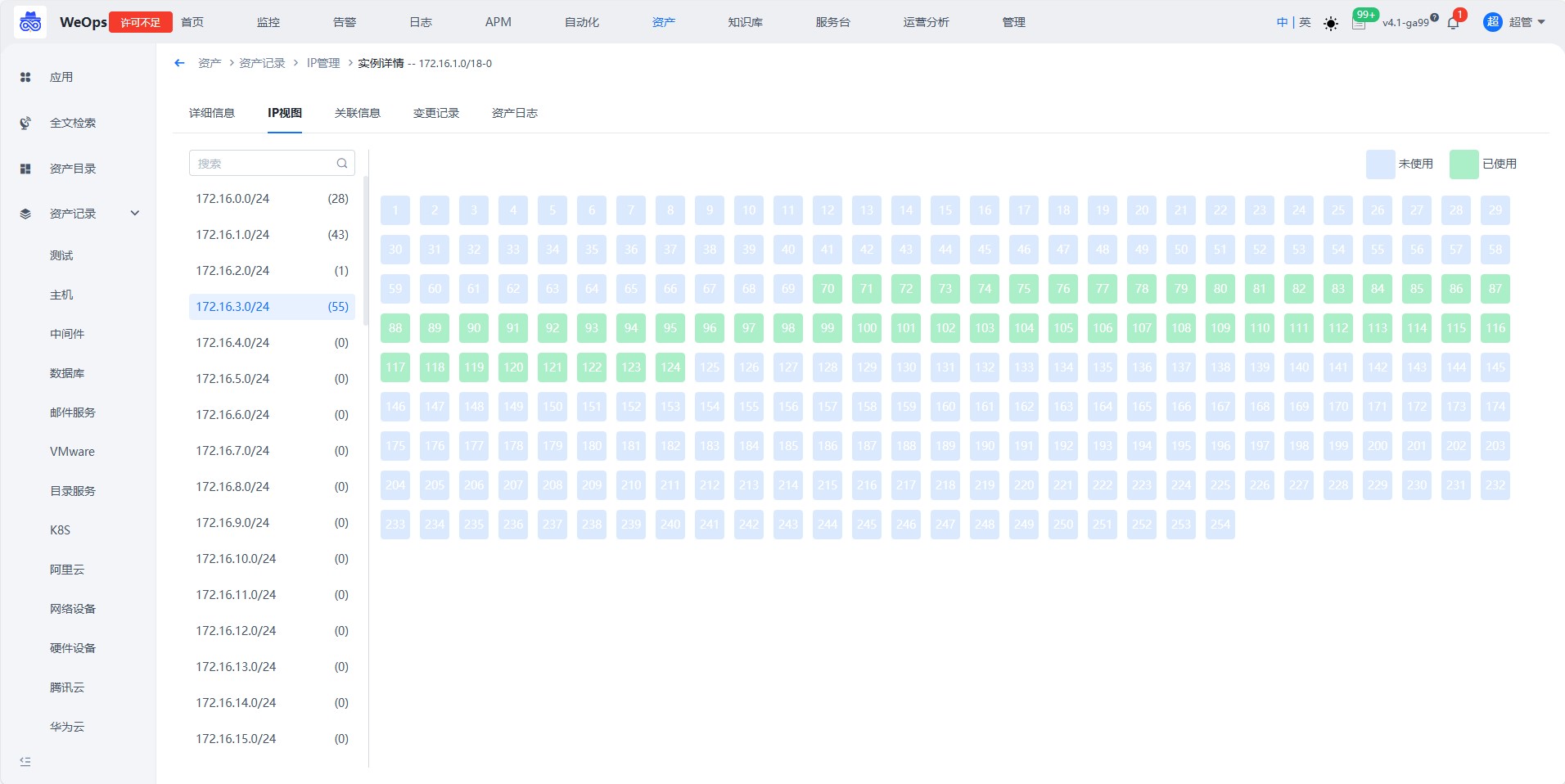
3、根据子网和IP的关联信息,自动生成IP视图,展示该子网下所有IP地址的使用情况
资产扫描
背景介绍:资产扫描一般有以下几种应用场景:一、纳管层面:资产扫描是从空白到扫描出来有资产的,然后进行配置发现,自动更新配置的;二、安全层面,比如护网全量扫描不在cmdb的资产,扫出来异常的ip进行重点关注;三、运营层面,扫描ip不在管理范围内的,进行ip认领或者回收
- 目前WeOps资产扫描支持的协议有telnet和ICMP ping。
- ICMP Ping扫描:ICMP是Internet控制报文协议,其中的Ping命令可以用于检测目标主机的可达性。Ping扫描程序会向目标主机发送ICMP Echo Request包,如果目标主机响应了ICMP Echo Reply包,就表示目标主机是可达的。
- Telnet是一种远程登录服务,在扫描中常用于探测目标主机的开放端口。扫描程序会发送一个特定的Telnet请求到目标主机的目标端口,如果返回的响应表明该端口是开放的,就表示目标主机上运行着相应的服务
step1:设置好识别规则
路径:管理-资产管理-资产扫描
telnet协议需要扫描特定的端口,需要提前定义好端口和资产类型之间的关系,便于根据开放的端口识别资产类型。如下图,weops根据数据库和中间件默认的端口内置了一条规则,支持调整。
step2:创建扫描任务
路径:管理-资产管理-资产扫描
扫描任务,如下图,支持资产扫描任务的创建,可设置IP扫范围,支持ping(IP)、telnet(IP+端口)从网络中发现IT资产,支持配置CMDB的对比范围,进行对比。安装扫描的协议扫描出来的资产,会根据cmdb的资产范围进行对比,未纳管的资产,会呈现在“未纳管”列表中。
- 未纳管资产,扫描的结果中,和cmdb对比后,cmdb没有纳管的资产会呈现在列表中,并按照识别规则展示资产的类型,对于未纳管的资产,支持一键纳管至cmdb中
机房视图
背景介绍
为了直观的展示机柜内设备的布局和状态,新增机房视图,用于各类IT设备的集中管理和展示。
step1:资产设置
路径:资产-资产记录-数据中心
在资产记录中已经内置常用资产模型“数据中心-机房-机柜-设备(网络设备/硬件设备等)”,需要在资产记录的对应位置创建资产实例、填写位置信息并创建关联,步骤如下
①:创建数据中心实例并填写信息。比如“深圳数据中心”
②:创建机房实例,并且关联到数据中心。比如创建“2号机房”,并且创建它与“深圳数据中心”的关联
③:创建机柜实例,必须填写“机柜位置”字段,并且创建机柜与机房的关联关系。比如2楼机房放置了10个机柜,需要填写机柜的基本信息,必填“机柜位置”(机柜位置的填写标准格式为“A01”、“B11”等),创建机柜与机房的关联。通过机柜的位置和关联关系,可在机房视图中渲染出位置。
④:创建设备实例,支持“网络设备”和“硬件设备”分组下的实例,放置在对应机柜中,设备需要填写开始U位和结束U位,并创建与机柜的关联,可以渲染出机柜视图。
step2:查看视图
路径:资产-机房视图
根据“机房-机柜”关联和填写机柜的位置,在视图中按照机柜的位置和类型展示。
根据“机柜-设备”关联和设备的开始U位和结束U位,在机柜视图中展示设备的位置和信息
自动发现插件拓展
背景介绍
企业通常使用各种不同类型的技术和工具,涉及到中间件、数据库等多种资产。手动收集这些配置信息不仅费时费力,而且容易出错。因此,引入了自动发现和采集资产配置信息的功能,针对不同的对象,可以通过撰写脚本插件的方式拓展自动发现的支持的模型
自动发现插件
step1:创建插件
路径:管理-系统管理-插件管理
针对不同的对象,可以通过撰写脚本插件的方式拓展自动发现的支持的模型,自动发现主要用于发现未纳管的资产以及资产少数的配置信息,并自动更新至CMDB中。
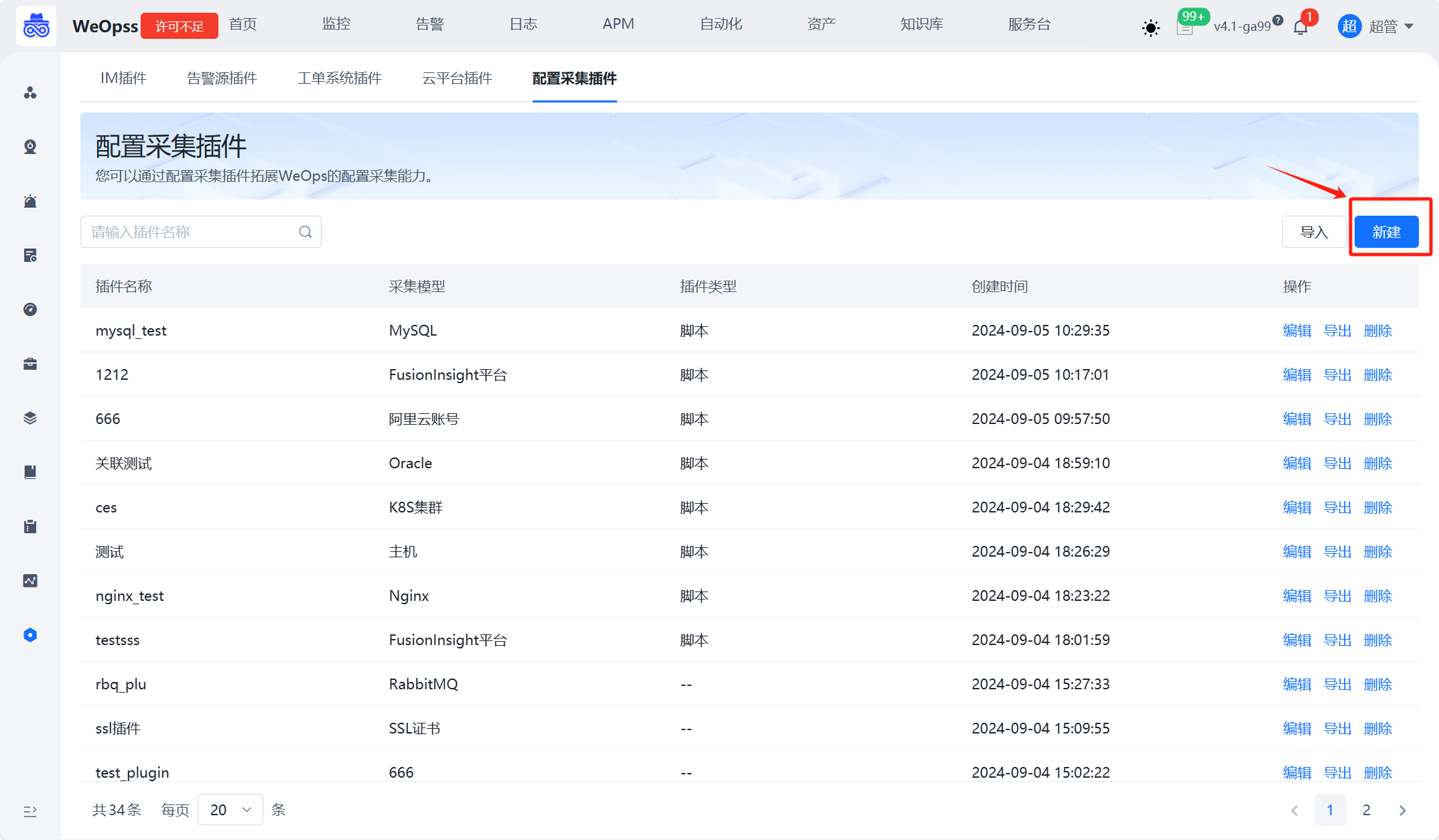
新建插件需要填写的信息如下
插件名称:自定义,便于识别
采集模型:选择需要采集的模型,可以自动发现该资产的相关信息
插件类型:目前只支持“脚本”类
采集关联:采集到的该资产的关联关系,脚本执行完后,可以自动创建关联
操作系统:支持Windows和linux两类,以及对应的脚本撰写的语言
脚本内容:定义脚本执行的参数、脚本采集的内容、输出格式等信息,详见下方详细介绍
参数定义:在脚本执行过程中需要输入的参数,采用位置参数的形式,$1、$2确定位置采集脚本的编写内容主要包括:
1、脚本参数:脚本支持定义位置参数,如shell脚本通过$1、$2定义。在脚本内容中的定义的参数需同时在“参数定义”中定义好,以便创建采集任务时填写和传入参数.
2、脚本采集内容:采集信息需要执行的命令.
3、脚本输出格式:为了在CMDB中存储,需要对输出的格式进行规范化,以便WeOps识别和存储。输出格式的定义可查看如下示例,其中 bk_inst_name、bk_obj_id是必填项,bk_inst_name作为示例的唯一值,通过实例名,将输出的字段信息更新到CMDB中, bk_obj_id则是该采集对象的资产模型ID。
4、关联关系:如果该资产模型是与主机相关联,直接在页面上填充字段“采集关联”即可,脚本中不必特殊定义。执行脚本后,可以自动采集并关联对应的主机。
Shell示例
以Shell脚本为例,发现Apache的实例和对应信息,定义输出格式的示例如下:
#!/bin/bash
bk_host_innerip={{bk_host_innerip}}
...
# =============can extend key=================
json_template='{ "bk_inst_name": "%s-apache-%s", "bk_obj_id": "apache", "ip_addr": "%s", "listen_port": "%s", "httpd_path": "%s", "version": "%s", "doc_root": "%s" }'
json_string=$(printf "$json_template" "$bk_host_innerip" "$port_str" "$bk_host_innerip" "$port_str" "$exe_path" "$apache_version" "$document_root")
echo "$json_string"
...json_template='{ "bk_inst_name": "%s-apache-%s", "bk_obj_id": "apache", "ip_addr": "%s", "listen_port": "%s", "httpd_path": "%s", "version": "%s", "doc_root": "%s" }'···定义了一个JSON模板字符串,其中的占位符(例如%s)将被具体的变量值替换。该模板包含以下字段: ●bk_inst_name: 实例名称,格式为 “主机内网IP-apache-端口号”,必填,可自行用采集字段拼接 ●bk_obj_id: 固定值 “apache”,必填,根据采集的模型定义 ●ip_addr: 主机内网IP,根据发现字段自定义 ●listen_port: 监听端口,根据发现字段自定义 ●httpd_path: Apache可执行文件路径,根据发现字段自定义 ●version: Apache版本,根据发现字段自定义 ●doc_root: 文档根目录,根据发现字段自定义
json_string=$(printf "$json_template" "$bk_host_innerip" "$port_str" "$bk_host_innerip" "$port_str" "$exe_path" "$apache_version" "$document_root")使用printf命令将模板字符串中的占位符替换为实际的变量值,具体替换如下: ● “$bk_host_innerip”: 主机内网IP。 ●”$port_str”: 端口号。 ●”$exe_path”: Apache可执行文件路径。 ●”$apache_version”: Apache版本。 ●”$document_root”: 文档根目录。 最终生成一个完整的JSON字符串,并将其赋值给json_string变量。
echo "$json_string"输出生成的JSON字符串。
PowerShell示例
以PowerShell脚本为例,发现Apache的实例和对应信息,定义输出格式的示例如下:
...
foreach ( $httpd_instance in $httpd_instance_list){
...
$output = @{
"version" = $httpd_version.trim()
"listen_port" = $httpd_port
"ip_addr" = "{{bk_host_innerip}}"
"documentroot" = $httpd_DocRoot
"httpd_root" = $httpd_root
"errorlog" = $error_log
"customlog" = $custom_Log
"include" = $httpd_include
"httpd_conf_path" = $httpd_confile
"httpd_path" = $httpd_path
"bk_inst_name" = "apache-{{bk_host_innerip}}-$httpd_port"
"bk_obj_id" = "apache"
}
$outputJson = ConvertTo-Json $output
Write-Output $outputJson
}
...$output = @{ ... }定义了一个哈希表$output,其中包含多个键值对,每个键值对对应Apache服务的一个配置信息字段。 ●”version” = $httpd_version.trim(): Apache版本,去除空白字符后存储。 ●”listen_port” = $httpd_port: 监听端口。 ●”ip_addr” = “{{bk_host_innerip}}”: 主机内网IP,使用占位符表示。 ●”documentroot” = $httpd_DocRoot: 文档根目录。 ●”httpd_root” = $httpd_root: Apache根目录。 ●”errorlog” = $error_log: 错误日志路径。 ●”customlog” = $custom_Log: 自定义日志路径。 ●”include” = $httpd_include: 包含的配置文件路径。 ●”httpd_conf_path” = $httpd_confile: Apache配置文件路径。 ●”httpd_path” = $httpd_path: Apache可执行文件路径。 ●”bk_inst_name” = “apache-{{bk_host_innerip}}-$httpd_port”: 实例名称,格式为 “apache-主机内网IP-端口号”,必填,可自行用采集字段拼接 ●”bk_obj_id” = “apache”: 固定值 “apache”,必填,根据采集的模型定义
$outputJson = ConvertTo-Json $output使用ConvertTo-Json命令将哈希表$output转换为JSON格式,并将结果赋值给变量$outputJson。 Write-Output $outputJson输出转换后的JSON字符串。
通过上述定义后,执行脚本可得到对应的结果,输出结果示例如下。可按照如下结果保存在CMDB中。
{
"bk_inst_name": "abcsql-1",
"bk_obj_id": "abcsql",
"ip_addr": "10.10.10.10",
"version": "6.7"
}
{
"bk_inst_name": "abcsql-2",
"bk_obj_id": "abcsql",
"ip_addr": "10.10.10.11",
"version": "6.8"
}
step2:创建采集任务
路径:管理-资产管理-配置采集
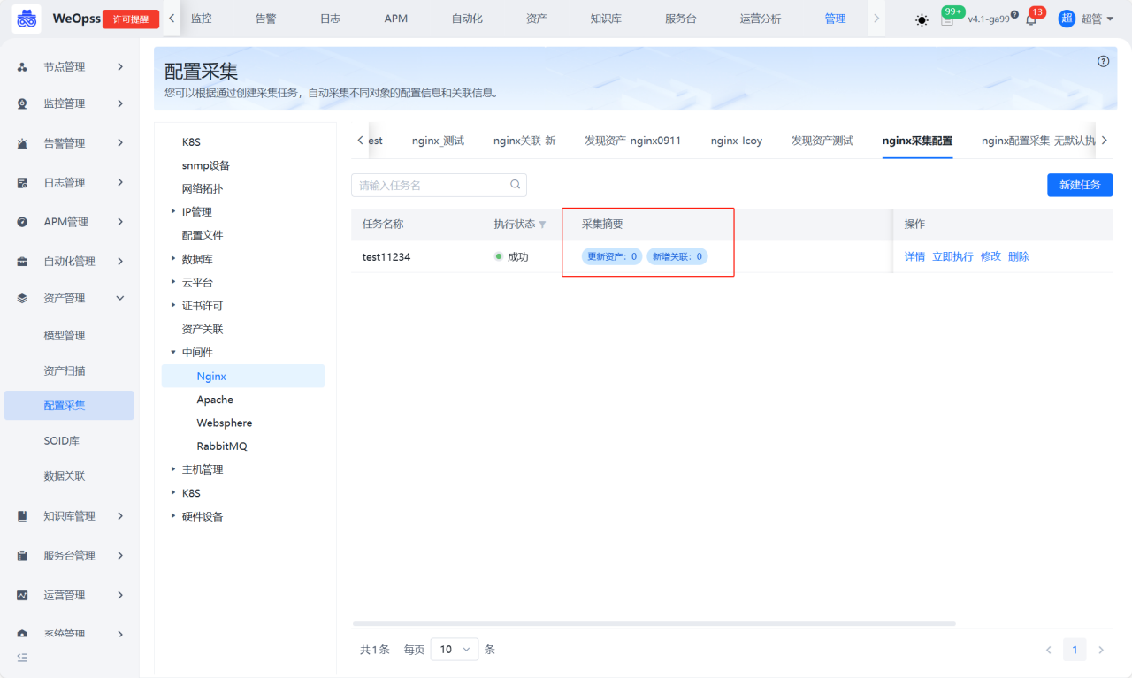
通过配置采集页面左侧,找到需要采集的类型(Kubernetes、网络设备、数据库、云平台、SSL证书、配置文件等)。通过右侧按钮创建并配置采集任务,可以使用刚才创建的脚本插件进行采集。
支持通过配置录入方式选择自动录入或审批录入,其中自动录入为当任务执行后发现新的资产,自动录入到CMDB,审批录入则需要人工在页面审批后录入资产。任务执行过程中,支持手动终止该任务。
step3:采集结果
路径:资产-资产目录-对应资产
采集任务执行后,可以在任务列表中的采集摘要中查看任务的采集情况。
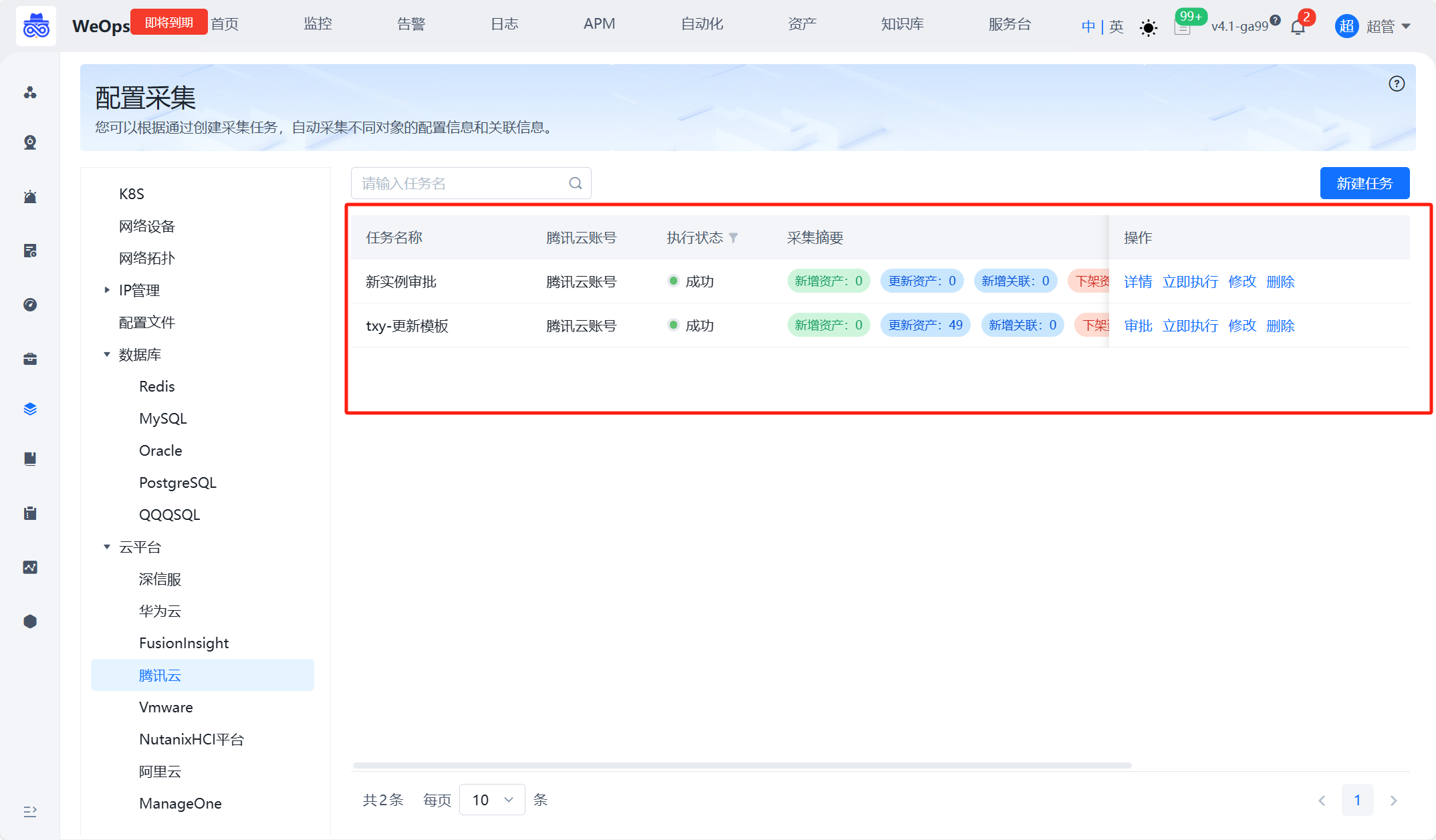
任务详情:展示任务执行后资产新增、更新和下架等情况,具体说明如下
新增资产:通过对比实例名识别出的新增资产,可自动/审批录入至CMDB
资产更新:通过对比实例名识别出的已有资产,自动更新该资产的配置信息
新增关联:该任务采集到的资产之间新的关联关系数,若任务为审批录入,则需审批录入后再执行采集任务补充关联关系
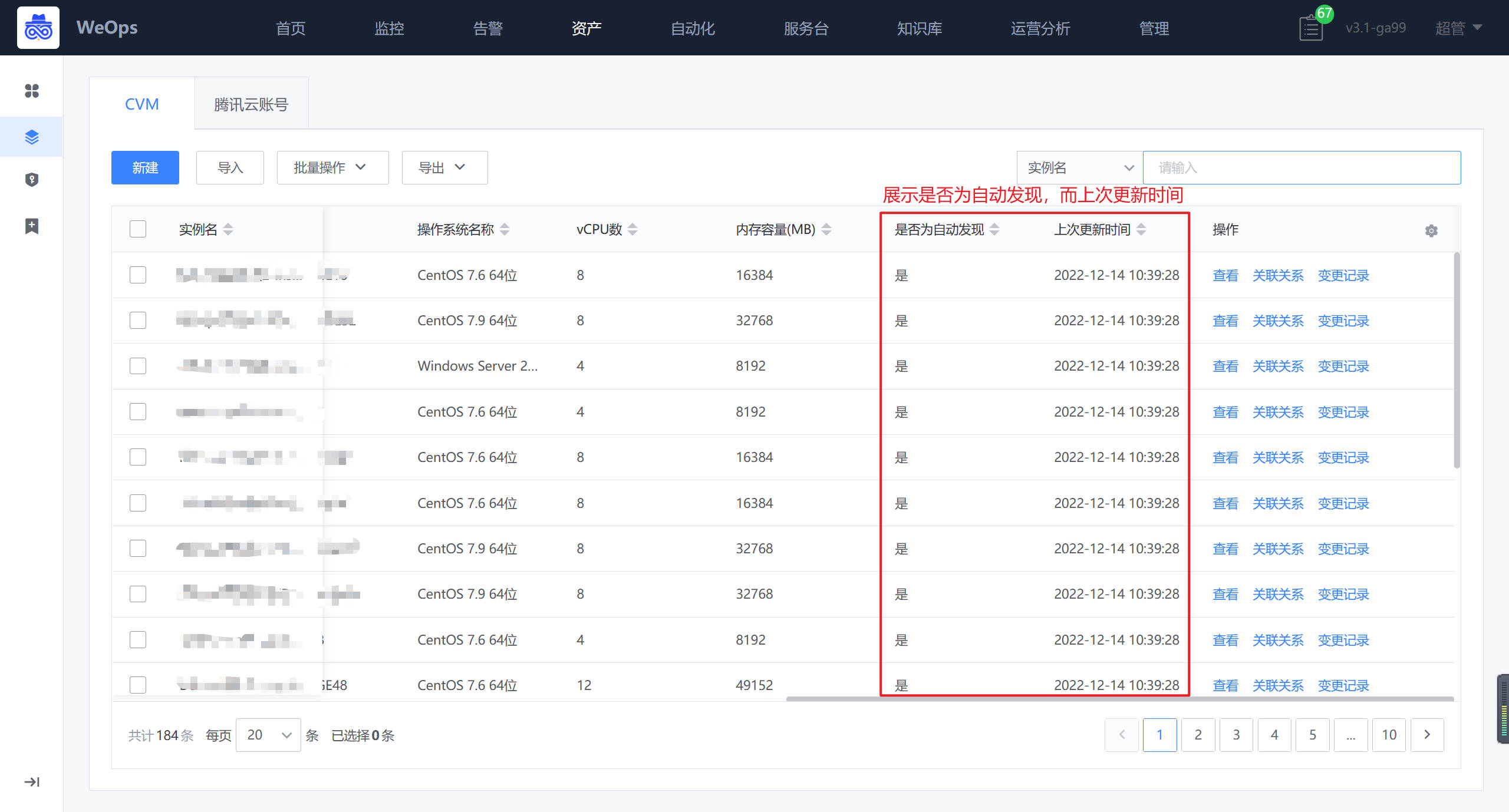
下架资产:通过对比该采集任务以往录入的实例识别出已经下架的资产,需要手动确认,才会在CMDB删除资产记录更新:当任务执行完成后,或者通过手动审批/手动下架后,“资产记录”会更新到最新的资产列表、资产字段值、资产关联关系,并用字段“上次更新时间”、“是否自动发现“和”采集任务“标识本次自动更新的信息。
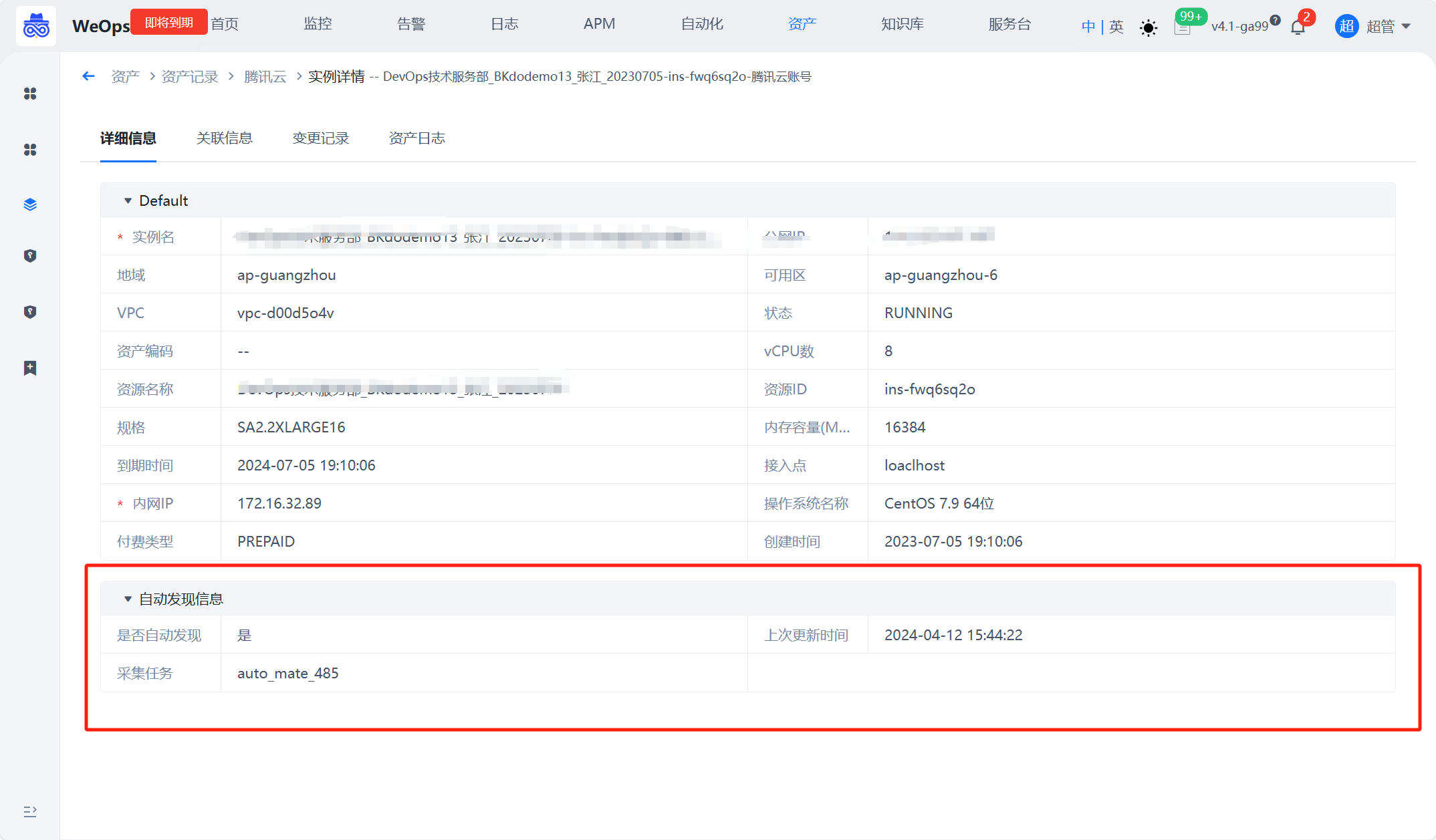
配置采集插件
针对不同的对象,可以通过撰写脚本插件的方式拓展配置采集支持的模型,配置采集主要用于发现已经纳管的资产更详细的配置信息,并自动更新至CMDB中。 在插件管理-配置采集插件中支持创建“配置采集”类的插件,采集配置模式下,需要勾选“默认采集主机”,用于下发采集。
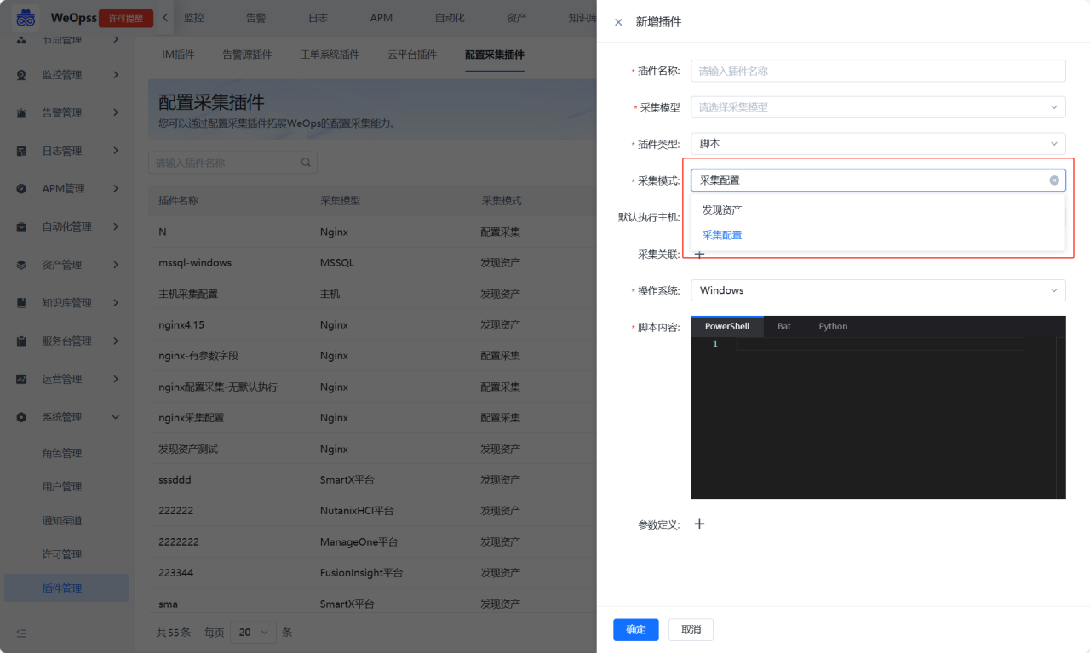
采集任务:创建配置采集任务,选择执行对象和主机,执行结果仅展示“更新资产+新建关联”,并更新至CMDB中。
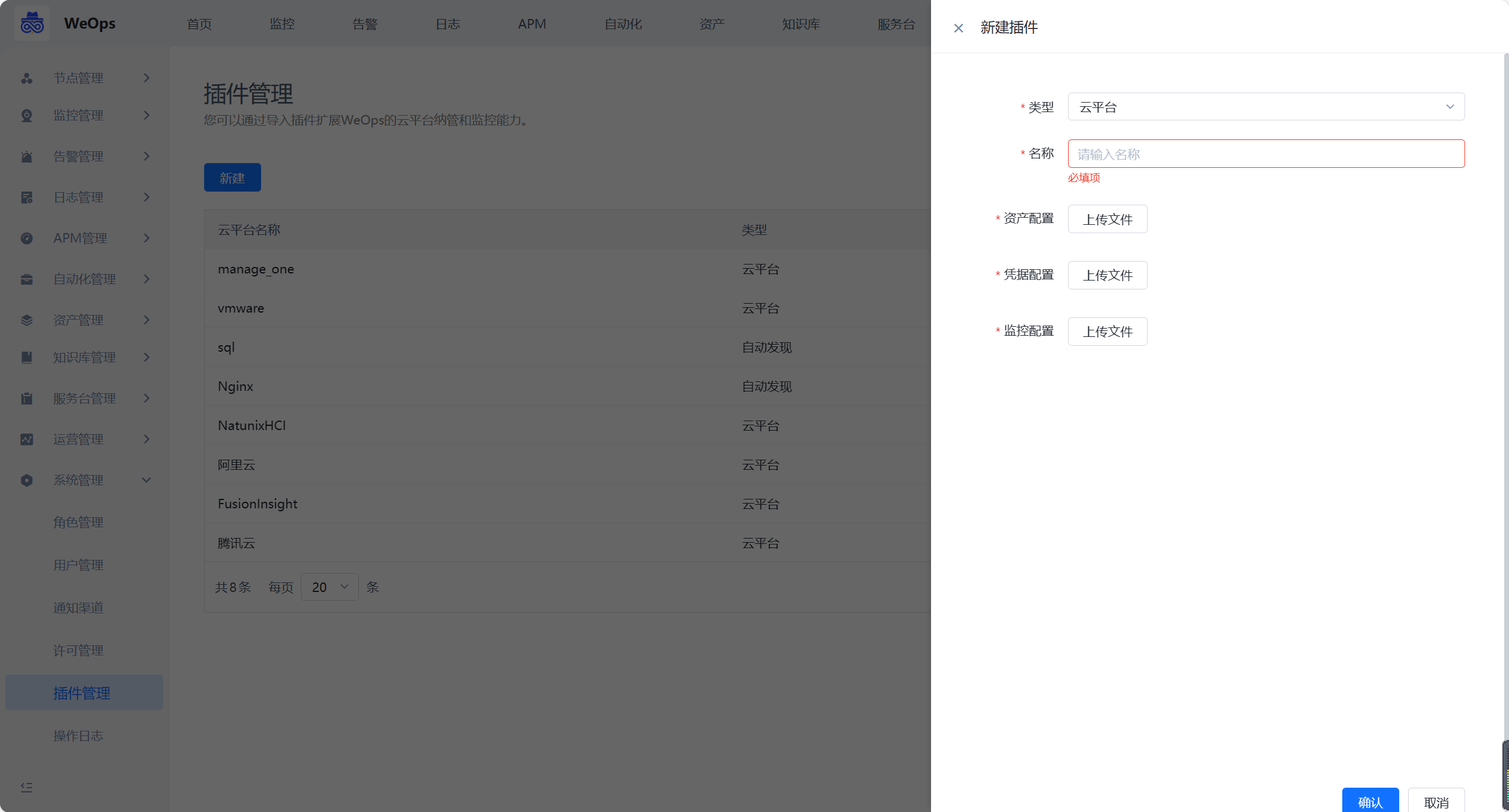
云平台插件
如下图,需要编写并导入云平台的资产配置文件、凭据文件、监控配置文件。(配置文件的编写和模板详见《WeOps高级开发指南》)
监控告警配置
关于WeOps各个对象的监控告警配置总示意图如下
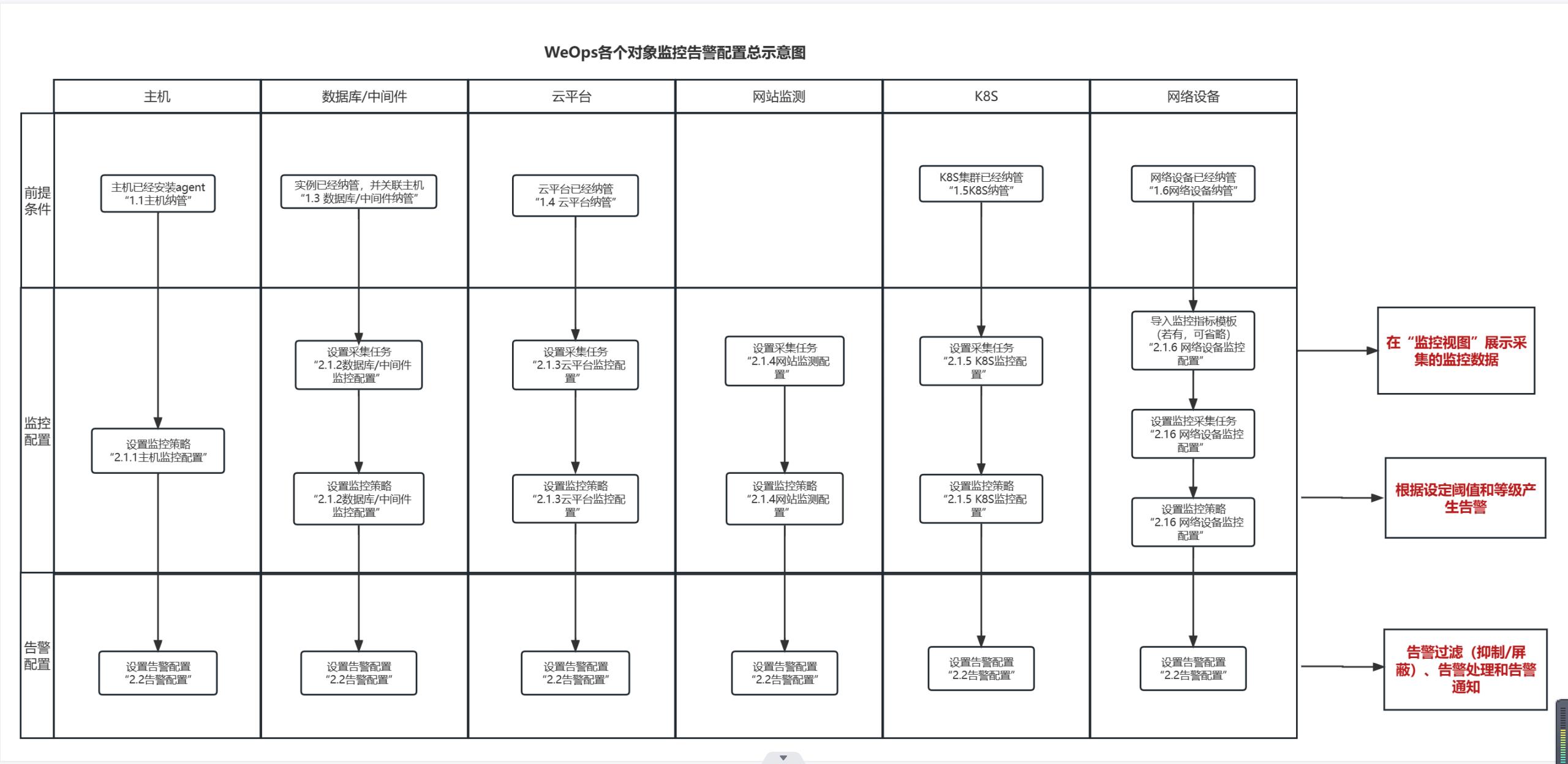
- 关于主机/数据库/中间件/k8s/云平台/网络设备的纳管,详情可参考“1、资源纳管”
- 各类对象的监控采集和监控策略配置,详情可参考“2.1 监控配置-分对象介绍”
- 各类对象的告警配置,包括告警抑制/告警屏蔽/自动处理/自动分派、人员通知,详情可参考“2.2告警配置”,各对象配置方法通用
监控配置
主机监控配置
背景介绍:主机已经安装完Agent,已经完成纳管,纳管的步骤详情可见“1、资源纳管-主机纳管”,现需要对主机的监控策略进行配置。
Step1:监控采集
主机已经安装完Agent,就已经可以进行监控数据的采集,详情可见“1、资源纳管-主机纳管”这里不在赘述。
Step2:监控策略配置
路径:管理-监控管理-监控策略-主机
- 进入WeOps的管理中心的监控管理,找到监控策略。
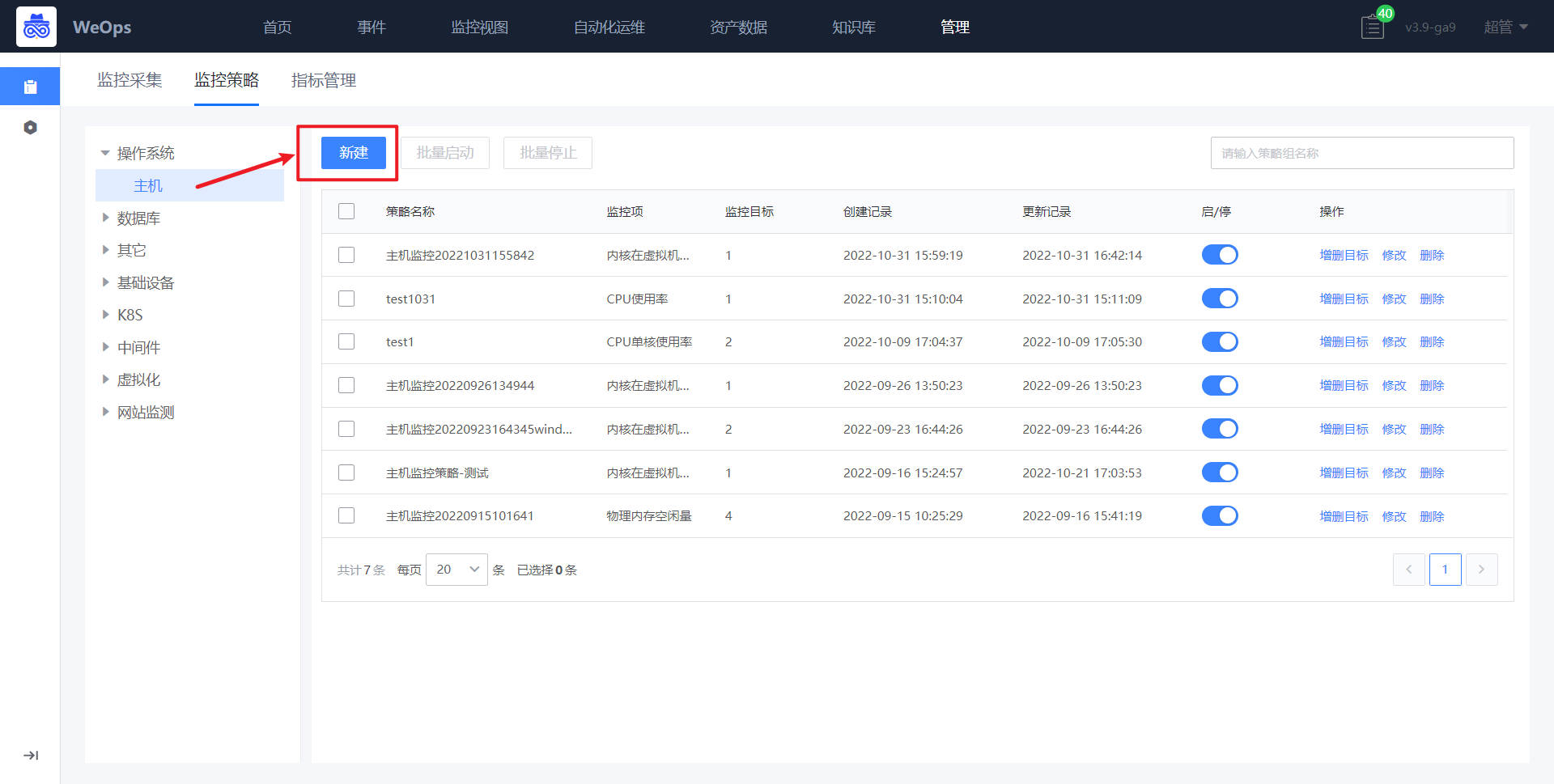
- 如下图所示,进入新建监控模板配置界面,默认填写策略名称、监控对象
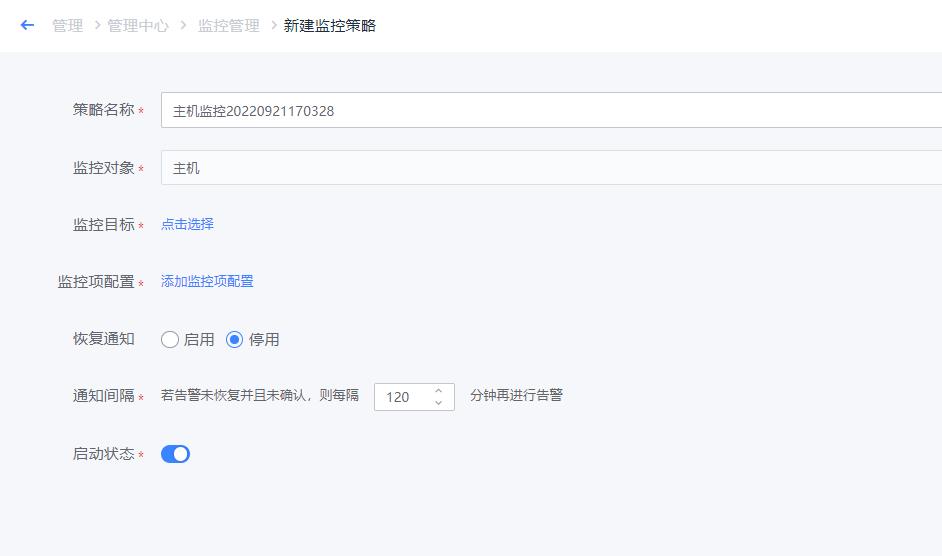
- 如下图所示,点击“选择监控目标”,可以采用列表选择/静态拓扑选择的方式,选择需要监控的目标。

- 如下图所示,点击蓝色字体【添加监控项配置】即会弹出对应界面。主机监控项分为“指标”和“事件”两类。指标主要为常见的CPU、内存、磁盘、进程等监控指标。而事件则是指Agent心跳、Ping可达、主机重启等。

- 选择监控项为指标类,搜索监控项
- 选择汇聚方式为平均数,即AVG方式。SUM代表总数,AVG代表平均数,MAX代表最大值,MIN代表最小值,COUNT代表计数/总数。
- 选择汇聚周期,汇聚周期即采集数据的周期。(注:汇聚1min即是服务端每分钟向Agent采集1次数据。若是汇聚周期设置为5min则表示服务端向Agent每5分钟采集1次数据,此刻的Agent已经采集到了5次数据。之后,并根据汇聚方式将这5个数据进行计算(AVG/MAX/MIN等),计算得出的数值再于检测算法设置的阈值进行比较。)
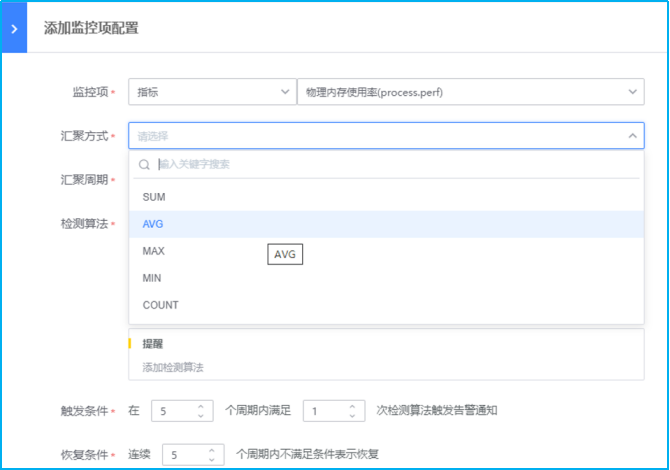
- 如下图所示,点击蓝色字体添加检测算法,进行不同监控等级阈值的设置。以下示例采用检测静态阈值触发告警。此外还有高级的阈值检测方式可选择:各种同比/环比策略,共有8种算法
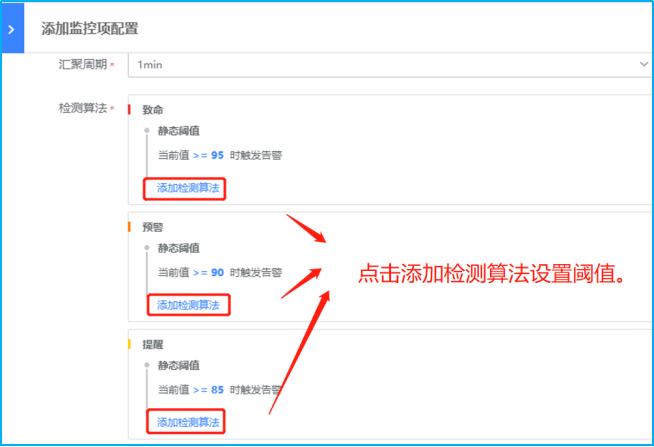
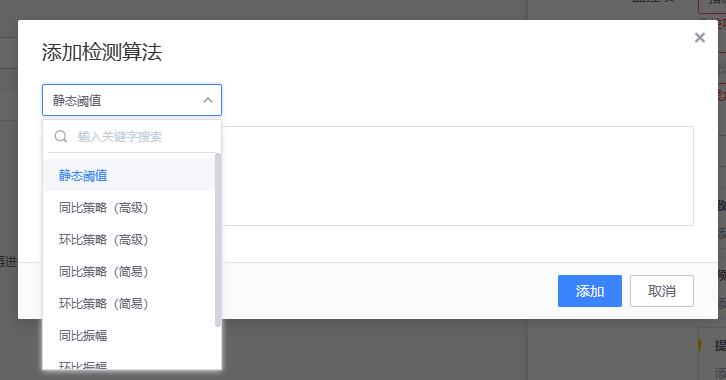
- 8种算法具体解释如下
- 【1、静态阈值】静态阈值是最简单也是使用最普遍的检测算法,只要值满足条件即为异常。是一种固定的设定方法。大多数的都是以静态阈值为主。
- 适用场景: 适用于许多场景,适用可以通过固定值进行异常判断的。如磁盘使用率检测,机器负载等。
- 配置方法
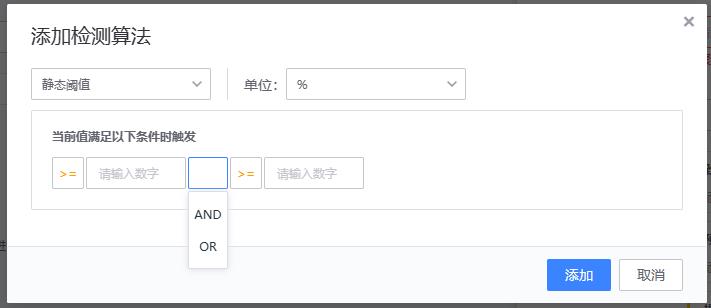
- 实现原理
{value} {method} {threshold}
# value:当前值
# method:比较运算符(=,>, >=, <, <=, !=)
# threshold: 阈值
# 当前值 (value) 和阈值 (threshold) 进行比较运算
多条件时,使用and或or关联。 判断规则:or 之前为一组
例:
>= 10 and <= 100 or = 0 or >= 120 and <= 200
(>= 10 and <= 100) or (= 0) or (>= 120 and <= 200) - 【2、同比策略(简易)/同比策略(高级)】
- 适用场景:适用于以周为周期的曲线场景。比如 pv、在线人数等
- 配置方法
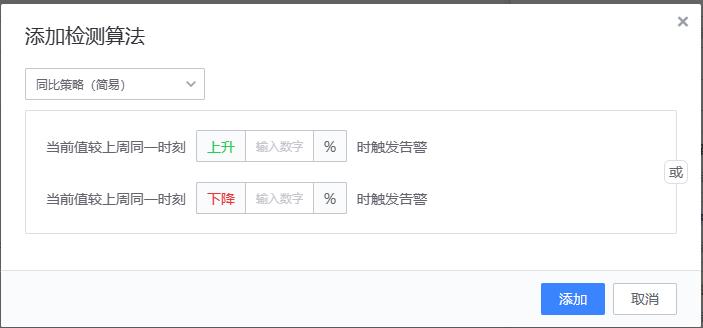
- 实现原理
同比策略(简易)
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:上周同一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与上周同一时刻值 (history_value)进行升幅/降幅计算示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
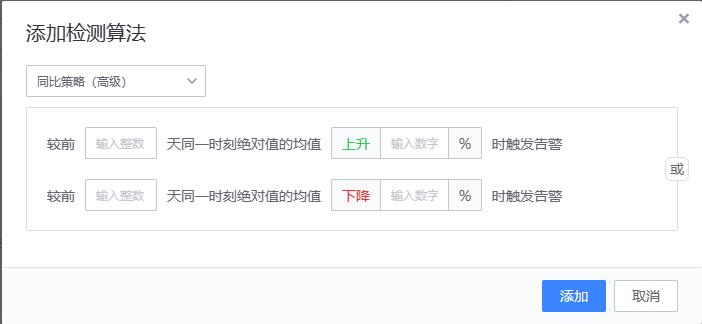
同比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n天同一时刻绝对值的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前n天同一时刻绝对值的均值 (history_value)进行升幅/降幅计算
# 前n天同一时刻绝对值的均值计算示例
以日期2019-08-26 12:00:00为例,如果n为7,历史时刻和对应值如下: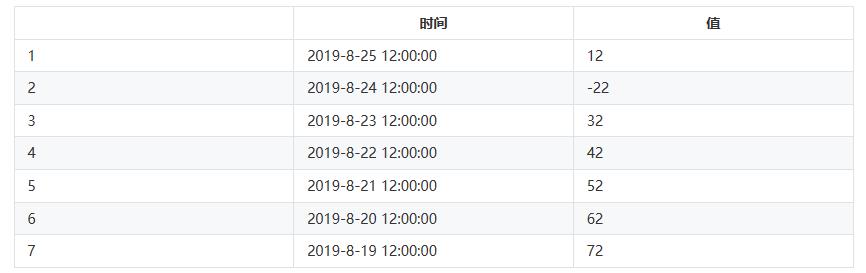
取绝对值,因此所有的值为正数
history_value = (12 + 22 + 32 + 42 + 52 + 62 +72) / 7 = 42示例:当 value(90),ceil(100),history_value(42)时,则判断为异常
- 【3、环比策略(简易)/环比策略(高级)】
- 适用场景:适用于需要检测数据陡增或陡降的场景。如交易成功率、接口访问成功率等
- 配置方法
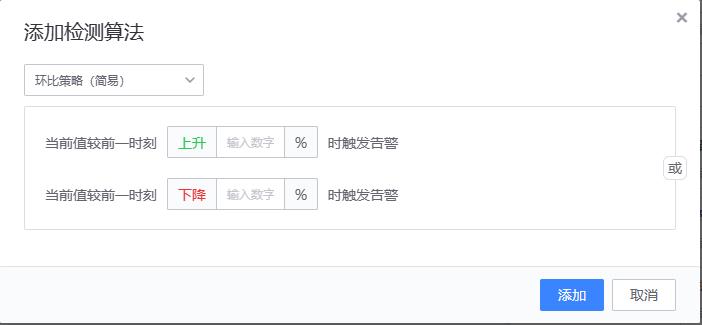
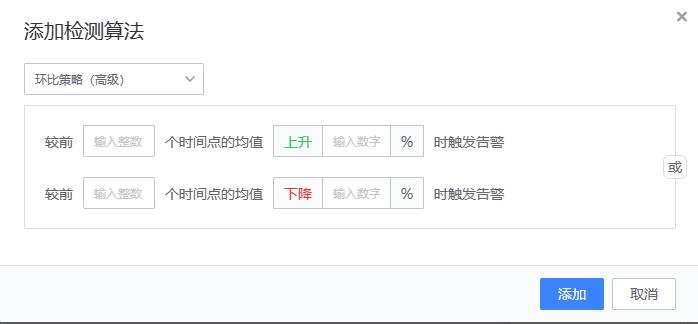
- 实现原理
环比策略(简易)
算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前一时刻值 (history_value)进行升幅/降幅计算示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
环比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n个时间点的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前个时间点的均值 (history_value)进行升幅/降幅计算
# 前n个时间点的均值计算示例(数据周期1分钟)
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
history_value = (12 + 22 + 32 + 42 + 52) / 5 = 32示例:当 value(90),ceil(100),history_value(32)时,则判断为异常
- 【4、同比振幅】
- 适用场景:场景:适用于监控以天为周期的事件,该事件会明确导致指标的升高或者下降,但需要监控超过合理范围幅度变化的场景。比如每天上午 10 点有一个抢购活动,活动内容不变,因此请求量每天 10:00 相比 09:59 会有一定的升幅。因为活动内容不变,所以请求量的升幅是在一定范围内的。使用该策略可以发现异常的请求量。
- 配置方法
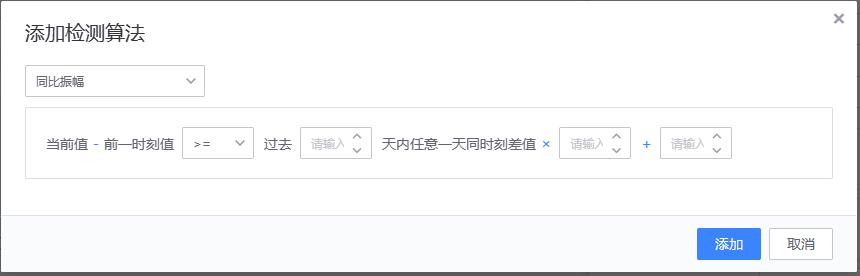
- 实现原理
# 算法示例:
当前值 − 前一时刻值 >= 过去 5 天内任意一天同时刻差值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 26
# 前一时刻值
prev_value = 10
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
# 当前值一前一时刻值的差值
current_diff = 16
# 5天内同时刻差值
prev5_diffs = [7, 6, 8, 10, 12]
前第二天(2019-8-24)同时刻差值: 6 * ratio(2) + shock(3) = 15
current_diff(16) >= 15
# 当前值(26) - 前一时刻值(10) >= 2天前的同一时刻差值6 * 2 + 3
此时算法检测判定为检测结果为异常:
- 【5、同比区间】
- 适用场景:温水煮青蛙型 – 数据缓慢上升或下降,适用于以天为周期的曲线场景。由于该模型中数据是缓慢变化的,所以使用【环比策略】、【同比振几幅】都检测不出告警,因为这两种模型主要使用于突升、突降、大于或小于指定值的情况。【同比区间】才适用于这种情况,因为随着数据的变化,当前值和模型值差距越来越大,而区间比较主要就是那当前值和历史模型值做比较。
- 配置方法

- 实现原理
# 算法示例:
当前值 >= 过去 5 天内同时刻绝对值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 11
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
前第3天(2019-8-23)同时刻值: 13 * ratio(2) + shock(3) = 26
value(26) >= 26
# 当前值(26) >= 3天前的同一时刻绝对值13 * 2 + 3
此时算法检测判定为检测结果为异常: - 【6、环比振幅】
- 适用场景:适用于指标陡增或陡降的场景,如果陡降场景,ratio(波动率)配置的值需要 < -1 该算法将环比算法自由开放,可以通过配置 波动率 和 振幅,来达到对数据陡变的监控。同时最小阈值可以过滤无效的数据
- 配置方法

- 实现原理
# 当前值(value) 与前一时刻值 (prev_value)均>= (threshold),且之间差值>=前一时刻值 (prev_value) * (ratio) + (shock)
# value:当前值
# prev_value:前一时刻值
# threshold:阈值下限
# ratio:波动率
# shock:振幅
以日期2019-08-26 12:00:00为例:
# 当前值
value = 46
# 前一时刻值
prev_value = 12
# 波动率
ratio = 2
# 振幅
shock = 3
value(46) >= 10 and prev_value(12) >=10
value(46) >= prev_value(12) * (ratio(2) + 1) + shock(3)
此时算法检测判定为检测结果为异常:
# 当前值(46)与前一时刻值(12)均>= (10),且之间差值>=前一时刻值 (12) * (2) + (3)- 如下图所示,进行“触发条件”、“恢复条件”、“无数据告警”、“监控纬度”以及“监控条件”的设置。
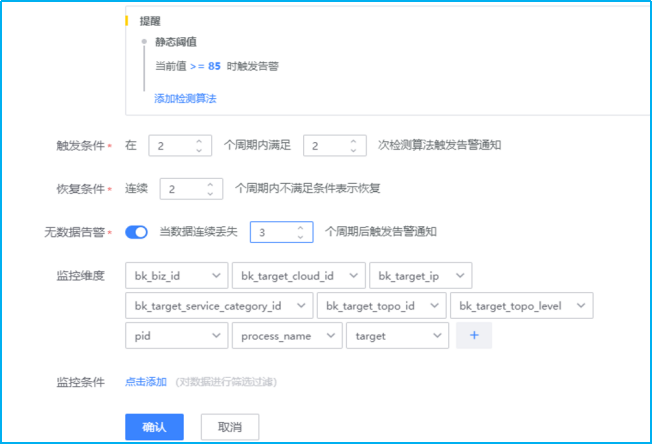
触发条件:2个周期内满足2次检测算法触发告警。结合以上汇聚周期1min(监控数据采集周期也是1min),汇聚方式设置为AVG平均数(1个数的平均数亦是其本身)。综上,每分钟检测1次,连续2次检测满足检测算法设置的阈值即会触发对应的告警等级。
恢复条件:连续2个周期内不满足条件表示恢复。表示:每分钟检测1次,连续2次检测不满足即表示恢复。
无数据告警:开启。当数据连续丢失3个周期后触发告警通知。表示:每分钟检测1次数据汇聚情况,若是连续3次(即3分钟内无任何数据),则触发无数据告警通知。
监控纬度:不同的监控项有不同的监控纬度。默认监控所有纬度,可以根据需求进行增删。默认情况下是监控所有纬度。例如监控项磁盘空间,那么windows的监控纬度则会是自发现的C:\ D:\ E:\等,而Linux则会是/、/root、/dev等。
监控条件:监控条件是对监控纬度的筛选,若是不选择则代表监控所有纬度。磁盘监控项中若是监控条件选择C:\则代表只监控磁盘C分区。- 如下图所示,对监控项进行一一添加后再进行其他配置即可完成监控策略的配置。
- 主机监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
进程监控配置
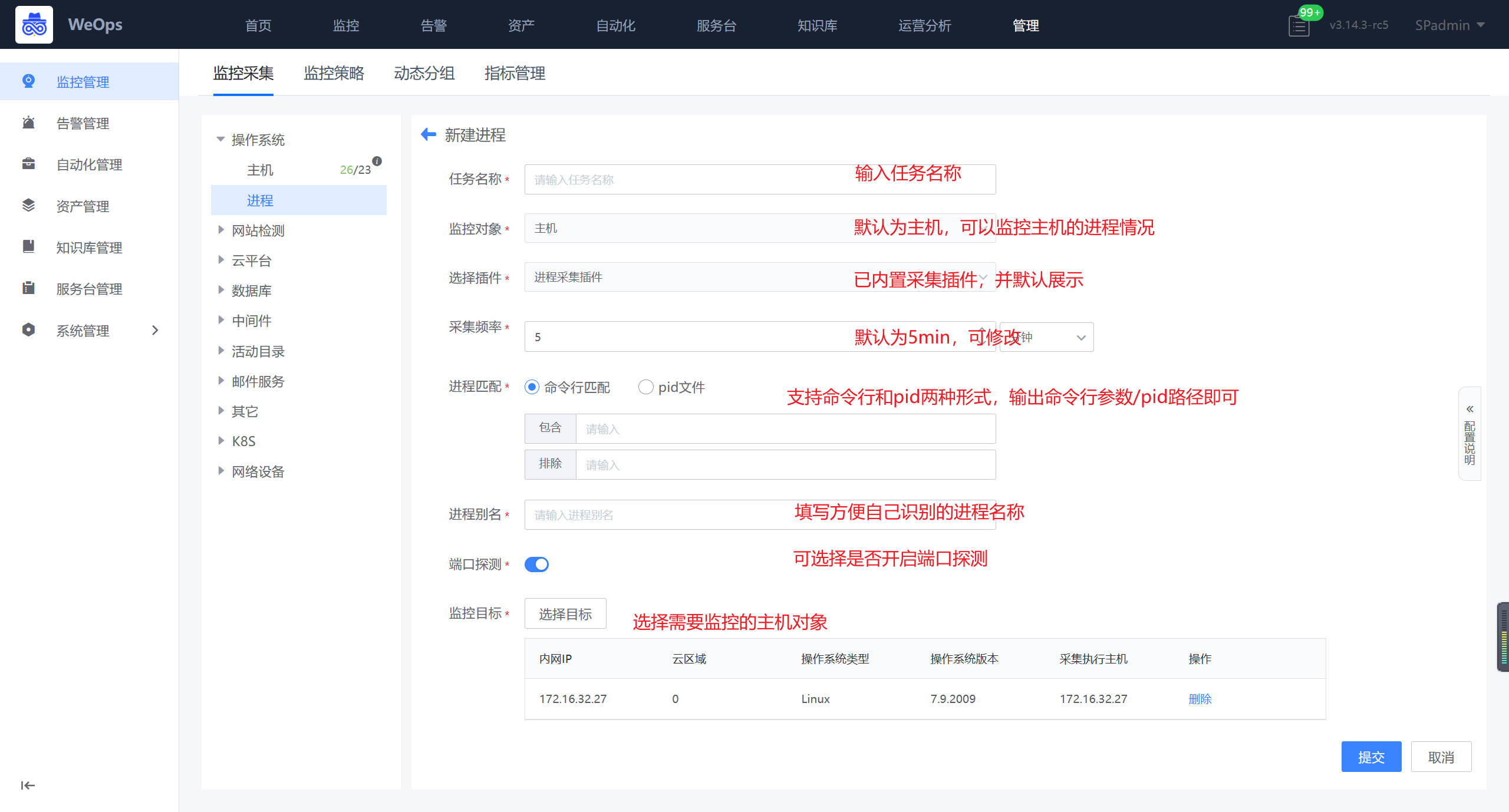
背景介绍:进程监控采集任务配置好下发到目标机器后,会基于采集的任务信息进行工作。通过配置需要监控的进程名,条件可以选择包含/不包含(排除)某些命令行的关键字,过滤出需要的进程,然后探测该进程是否开启端口(可选功能),同时会采集该进程的相关使用情况。
Step1:监控采集
监控采集的创建有两种路径进入
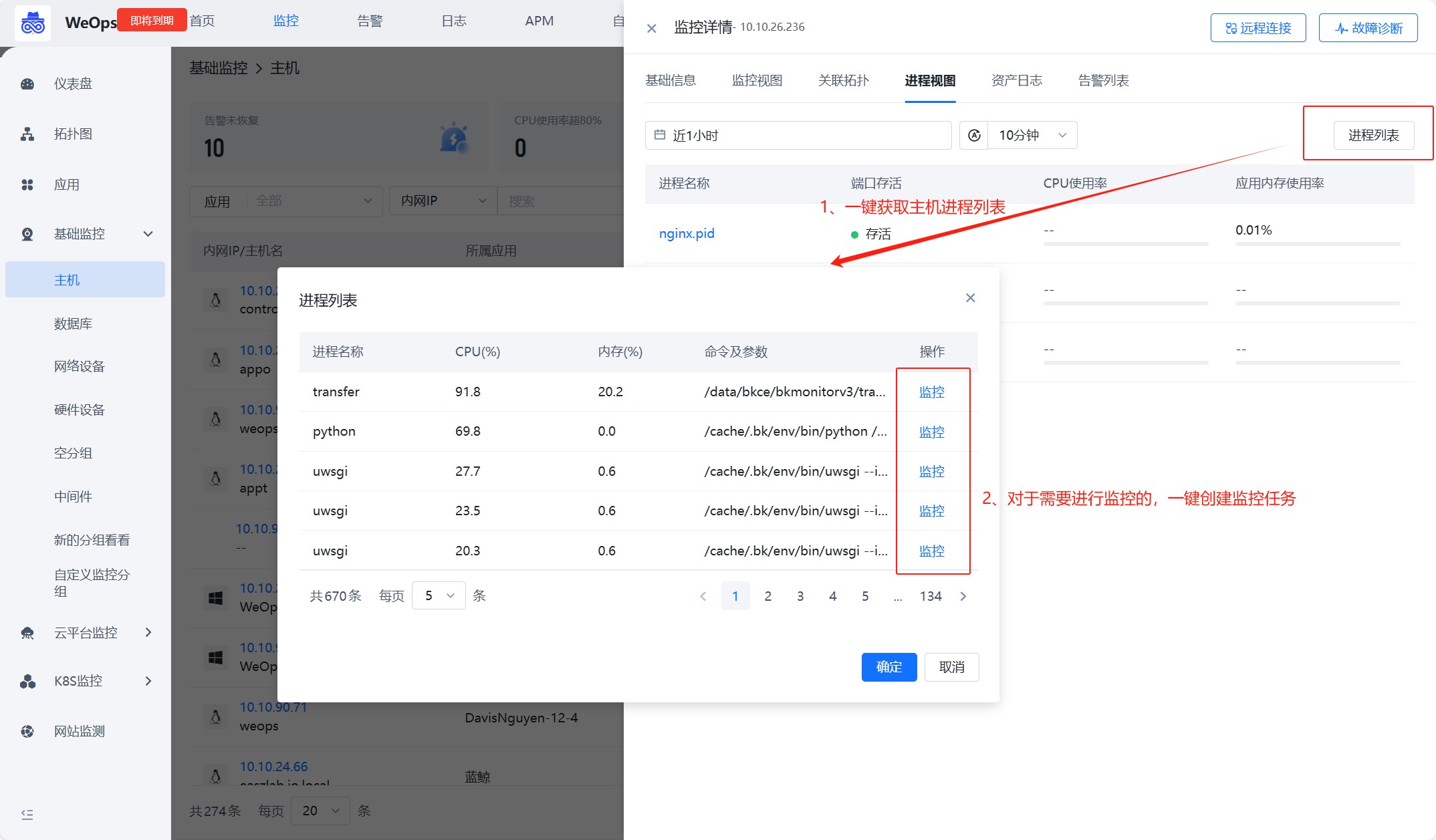
- 第一种,通过主机监控视图进入
路径:监控-基础监控-主机
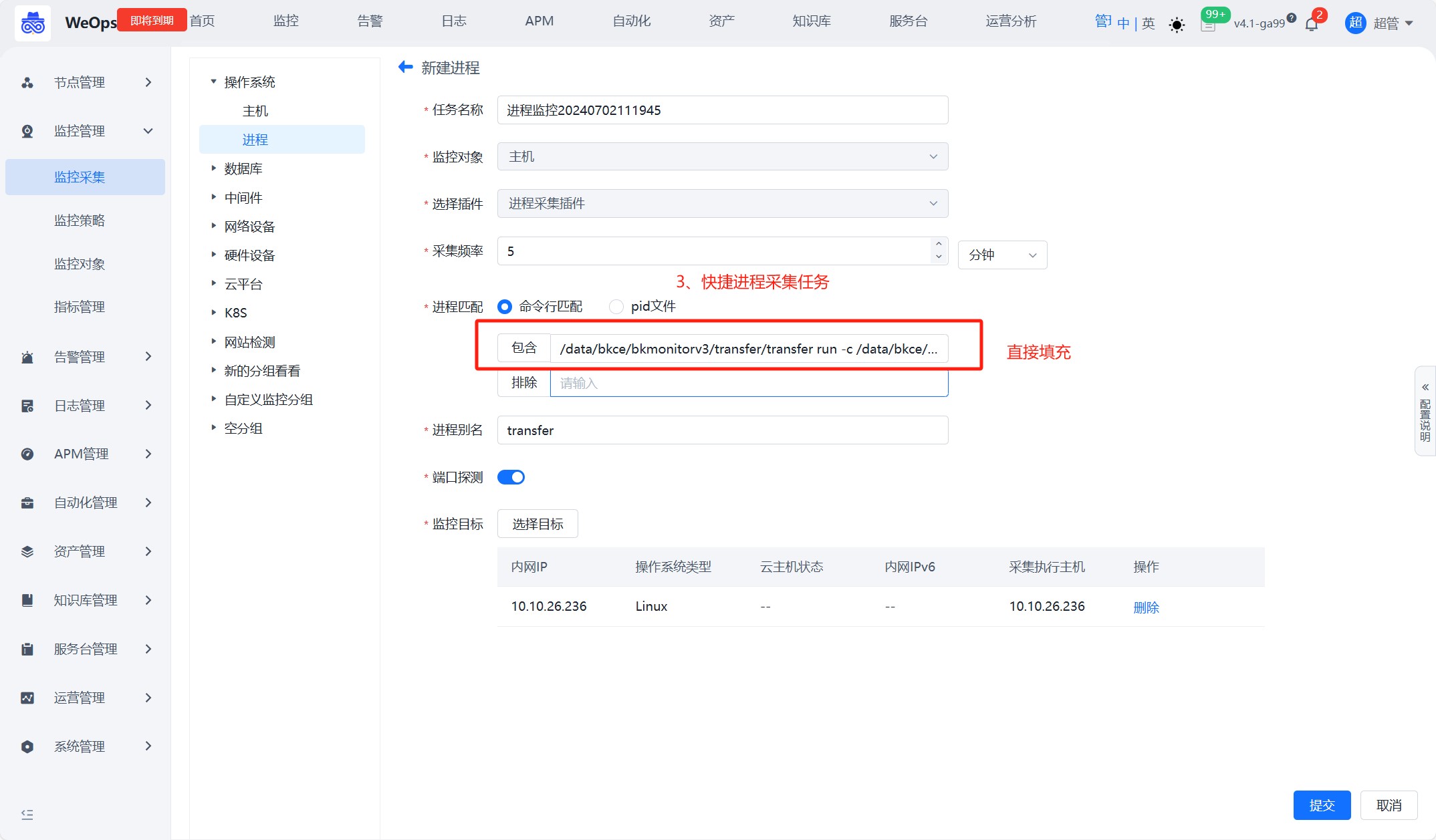
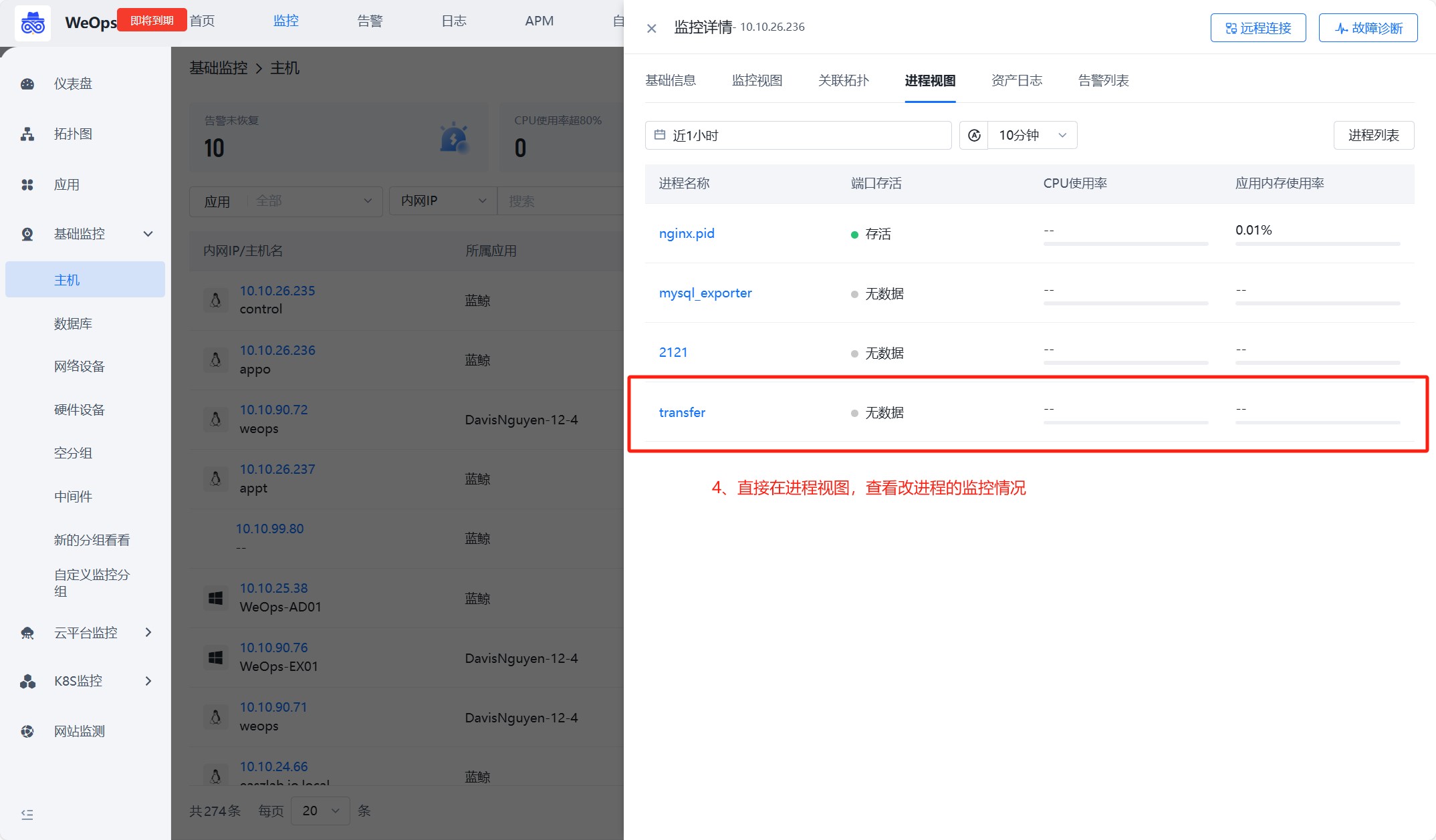
如下图,第一步,一键获取主机进程列表:在主机监控中,可以直接获取进程列表。二三步,快捷创建监控任务:对需要监控的进程,快捷创建监控采集任务,并且自动填充关键信息。第四步,任务创建完成后,可以在进程视图中,正常查看该进程的监控情况
- 第二种,直接在监控采集创建
路径:管理-监控管理-监控采集
如下图,进入到进程采集的页面,点击进行端口采集新建。目前仅支持主机的进程采集和监控。

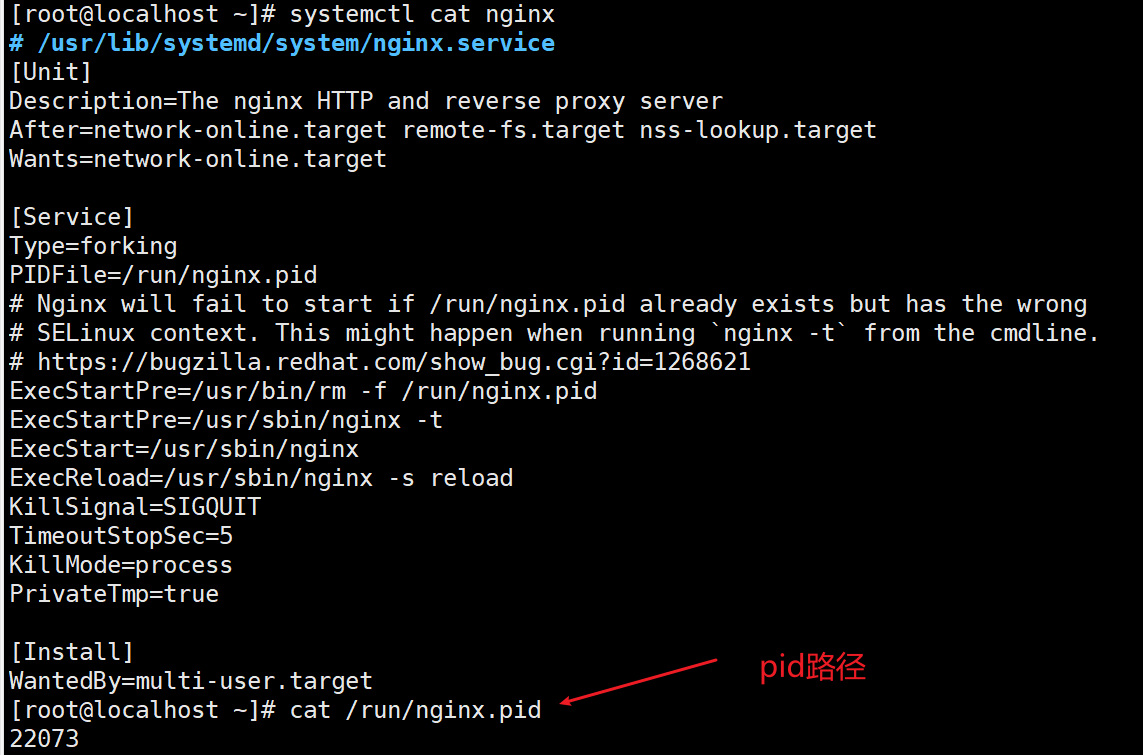
- 两种匹配方式,一种是命令行匹配,查询到命令行关键词,把参数复制进来就可以了,一种是pid路径匹配,把pid路径复制进来,命令行和pid两类详细说明如下
1、命令行参数:通过命令 ps -ef 获取到需要监控的进程的命令参数,在进程监控配置中,填写命令行参数,如果出现命令行参数无法区分两个进程的情况,可以采用排除关键词的方式,准确定位到需要监控测进程。
包含:进程匹配字符串,一般是进程的名称,注意Linux是cmdline, windows是匹配进程名。
排除:即不上报的进程,可以填写正则表达式,如(\d+),不采集匹配数字的进程。
如下图是通过命令 ps -ef 搜索到所有进程,以及进程的命令行参数(linux)

2、pid比较准确,可以准确识别到需要监控的进程,但是对程序的运行有要求,并非每个进程都会有pid文件,所以建议使用命令行的方式进行监控进程。
- 主机的进程采集设置完成后,可以在主机的对应监控视图中,查看该主机所有进程的监控情况,如下图

Step2:监控策略配置
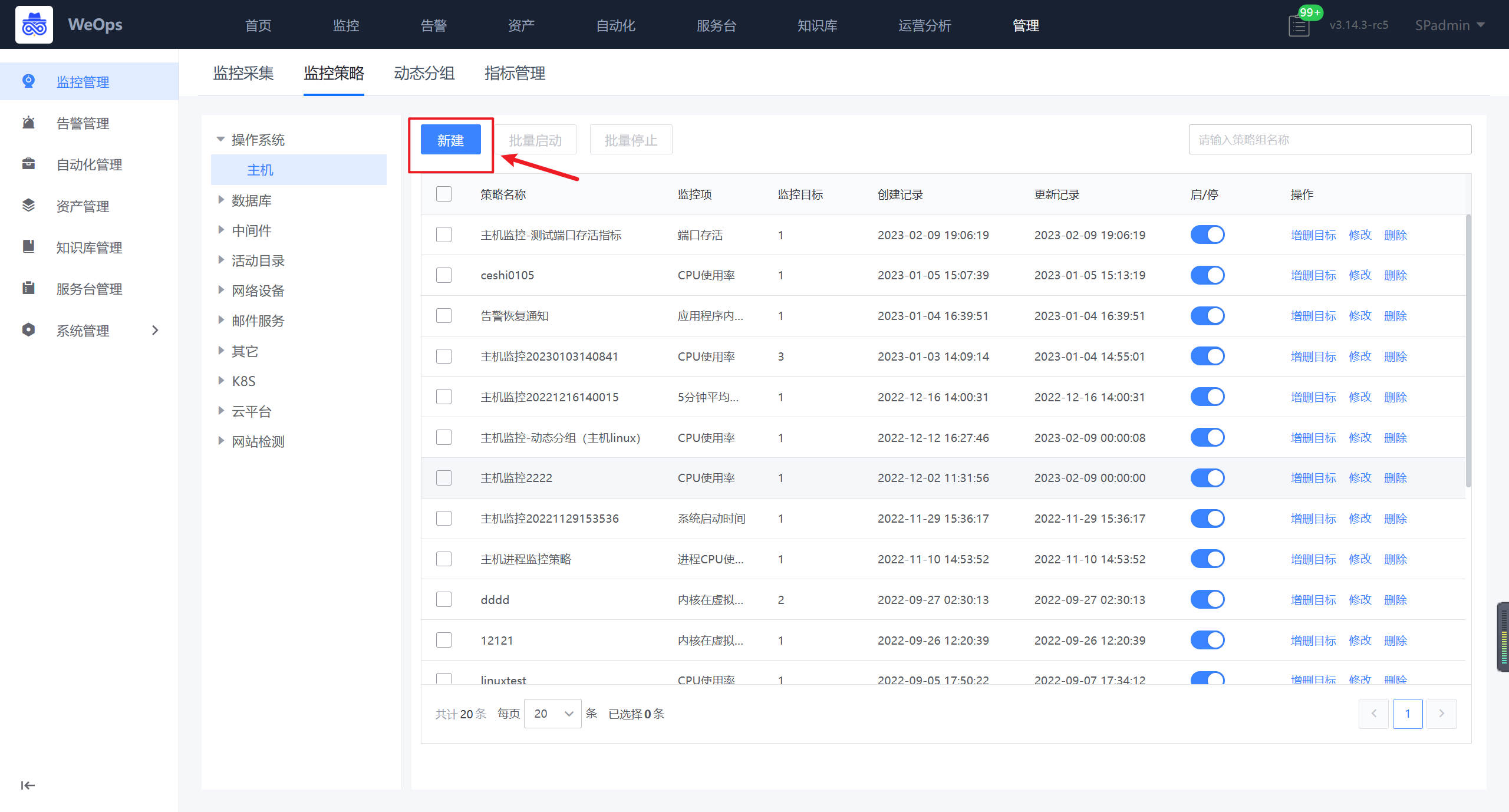
路径:管理-监控管理-监控策略
如下图,在监控策略页面,找到主机,点击“创建”按钮,进行主机进程的监控策略的创建
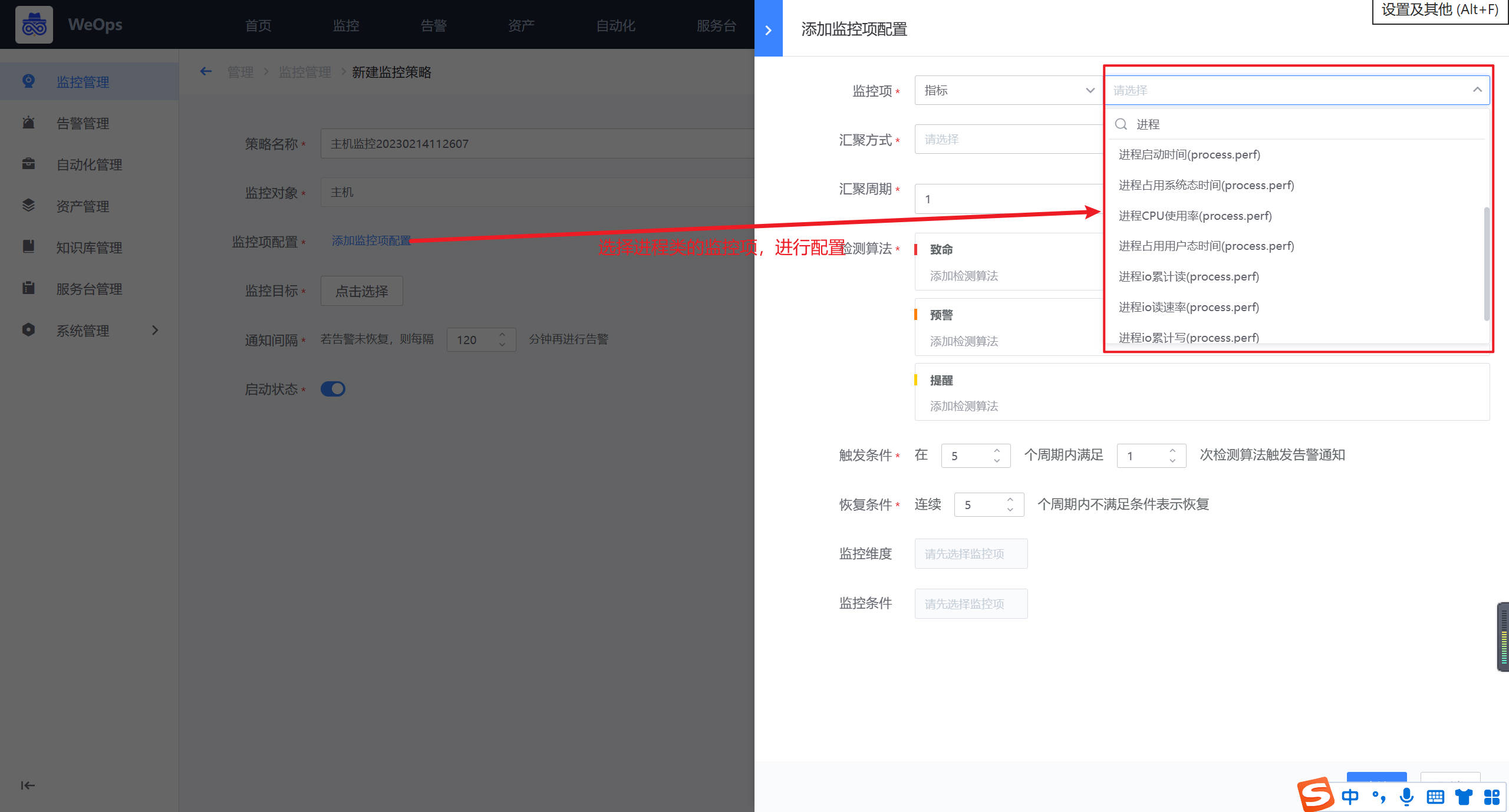
- 如下图所示,填写策略名称,进行监控项的添加(选择进程类的指标)、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
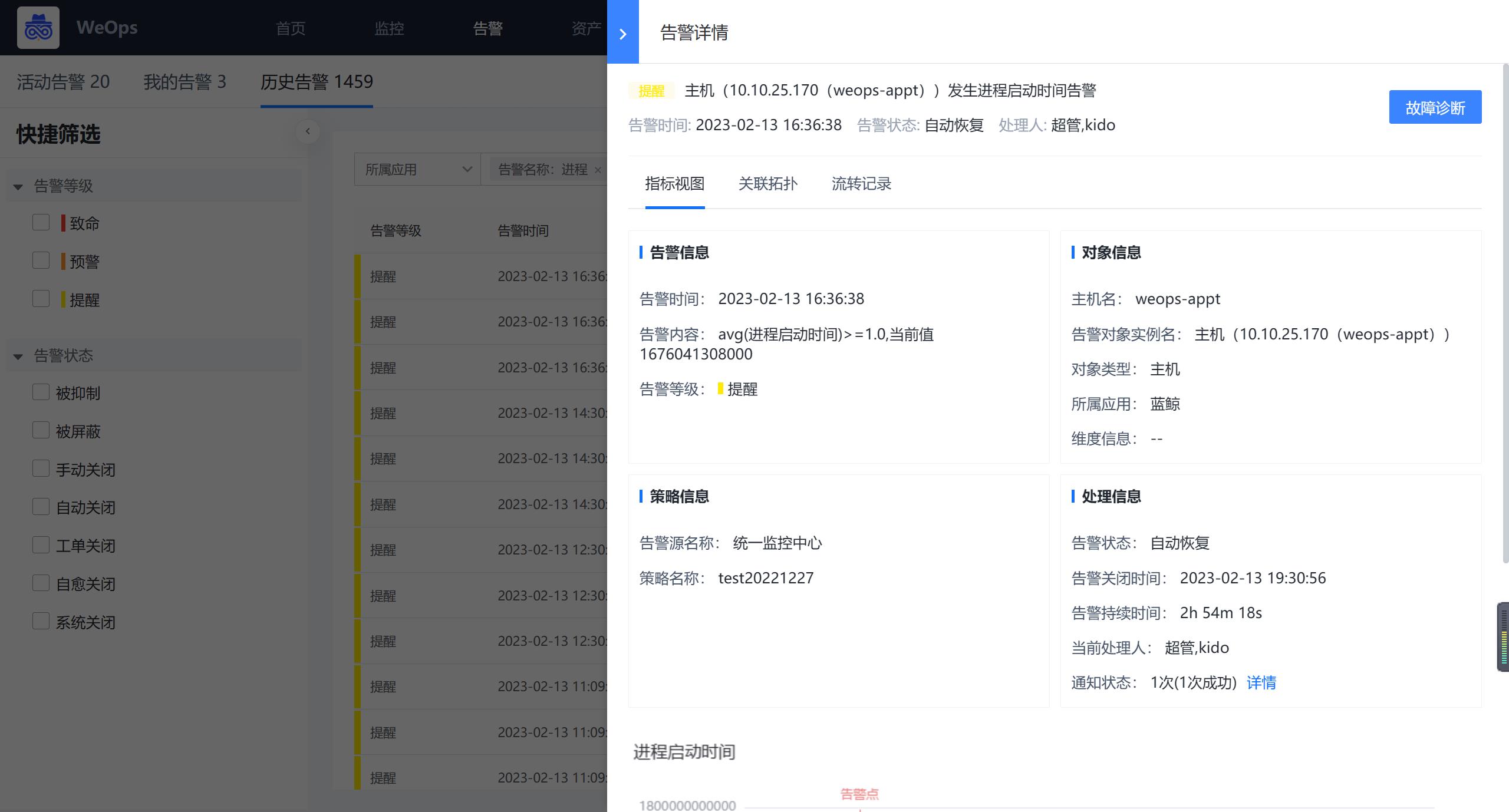
配置完成后,可以根据设定的指标、阈值和告警等级等产生对应的告警。
数据库/中间件监控配置
背景介绍:需要将数据库/中间件的实例已经新建完成,并且与对应主机已经建立了关联,数据库/中间件纳管的步骤详情可见“1.3 数据库/中间件纳管”,现需要对该实例进行监控采集和监控策略的设置。(这里以oracle为例进行介绍。)
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入监控采集页面,点击数据库-oracle,进行oracle监控采集任务新建。
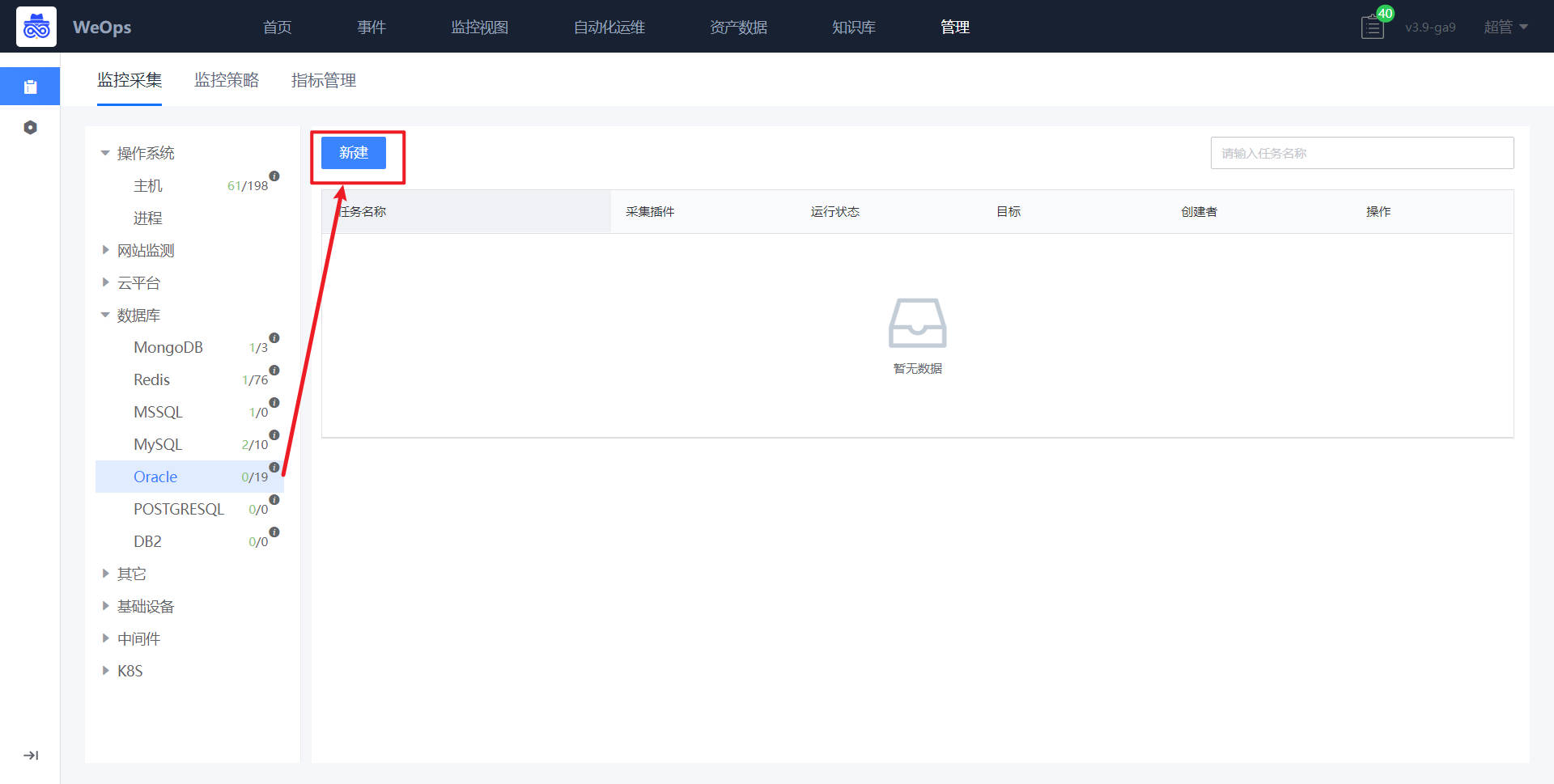
- 如下图所示,采集任务、监控对象、采集插件、采集频率等信息已经默认填写,只需要选择目标(监控oracle主机)
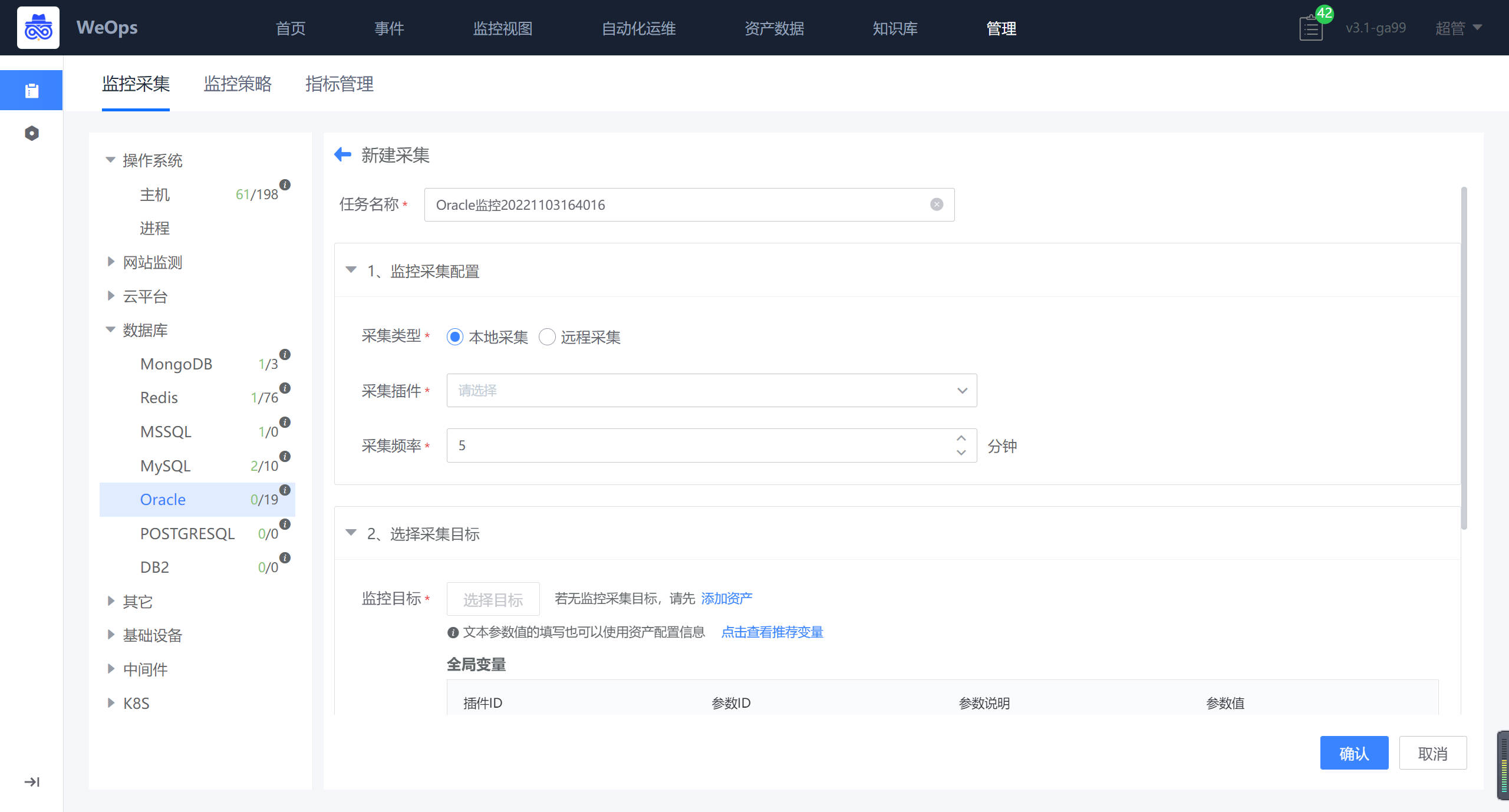
- 如下图所示,在选择完监控目标后,若所有目标的监控采集参数一致,则在全局参数中填写,若是特殊oracle主机节点有不同的监控采集参数,例如账号密码等,则在对应监控目标后填写。
- 数据库/中间件的监控采集配置完成后,可在“监控视图-基础监控-数据库/中间件”中查看对应的监控情况和监控视图。
Step2:监控策略配置
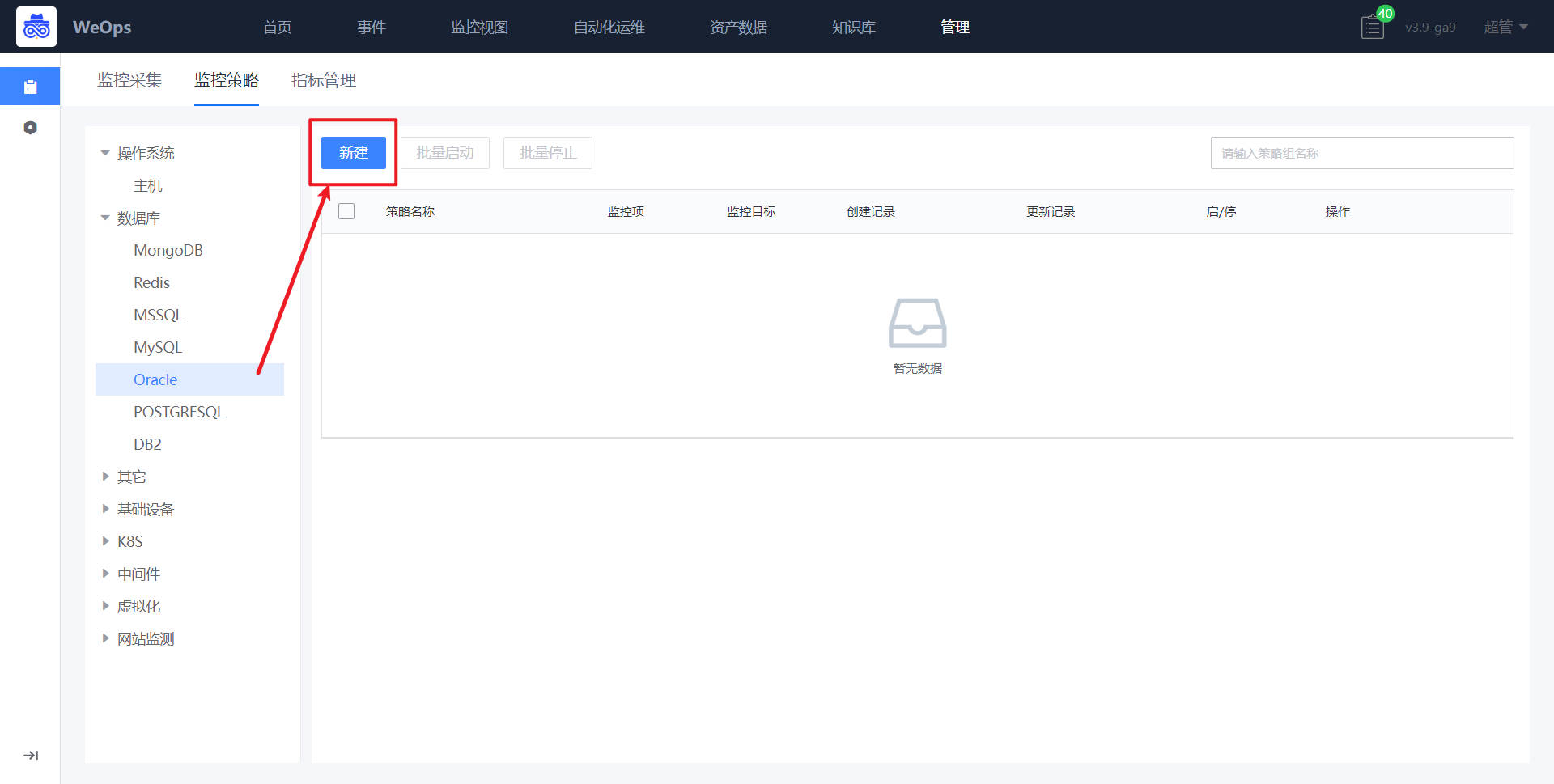
路径:管理-监控管理-监控策略
- 如下图所示,进入到监控管理的监控策略页面,点击新增监控配置。
- 如下图所示,依照主机监控配置方式(可参见“1、资源配置-监控配置-主机监控配置”),进行监控项的添加、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
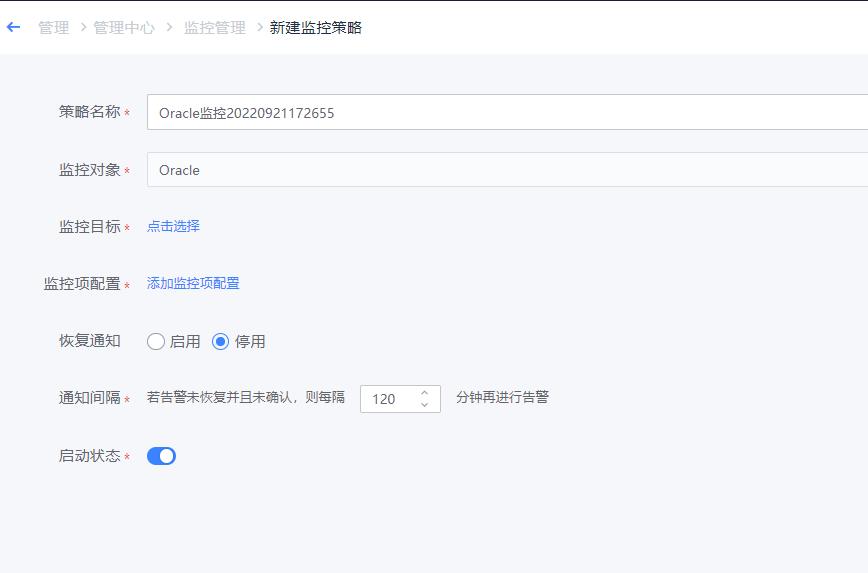
- 数据库/中间件监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
云平台监控配置(以腾讯云为例)
背景介绍:需要将云平台纳入监控数据采集中,包括VMware、腾讯云和阿里云等,并设置对应监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入云平台的监控采集界面,进行新增。
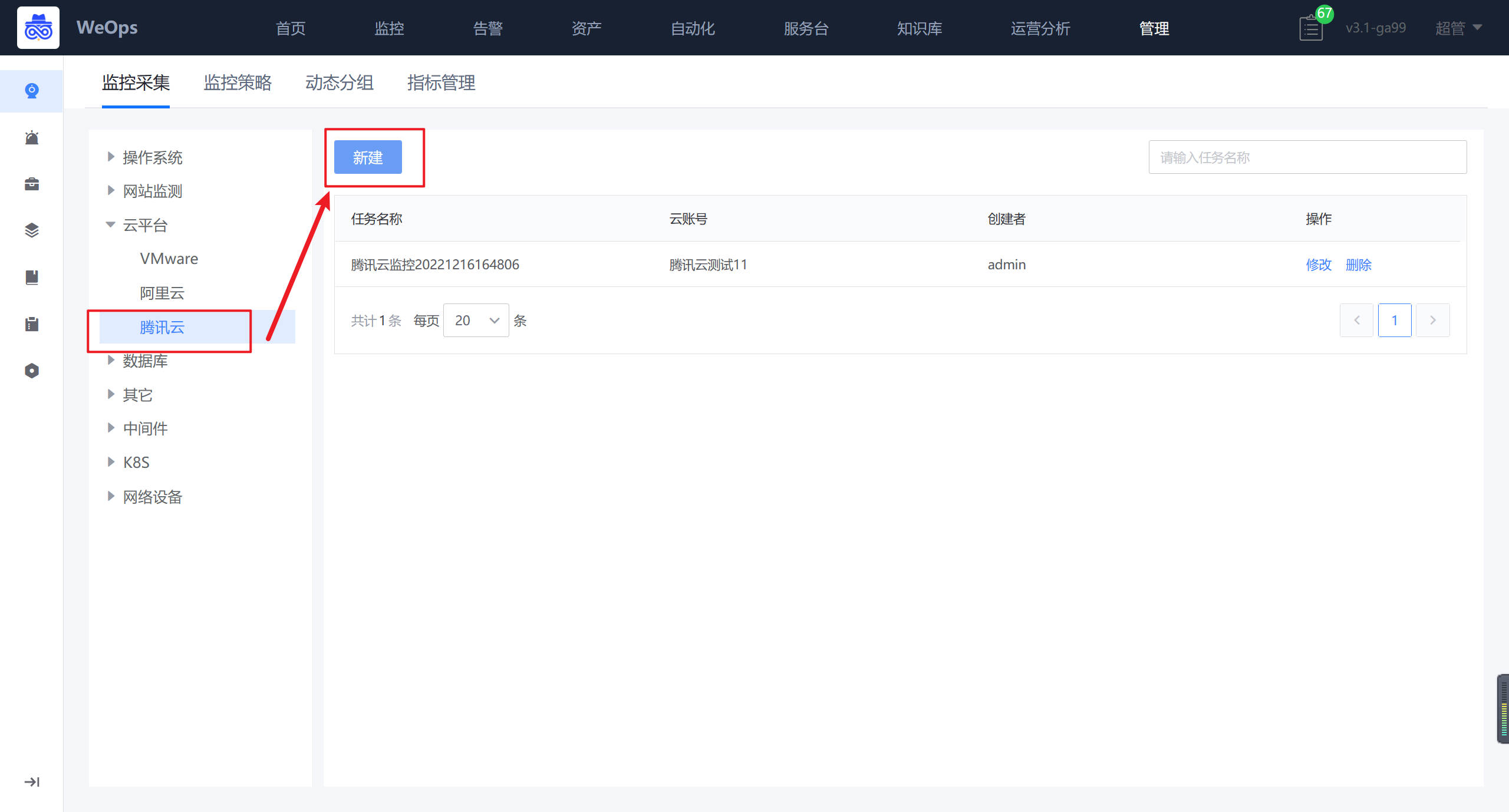
- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等

- 新建完成后,,可对该腾讯云账号下所有的CVM进行监控数据的采集,并可以在WeOps-监控视图-云平台监控-腾讯云(CVM)中查看已经采集监控数据和监控视图
Step2:监控策略配置
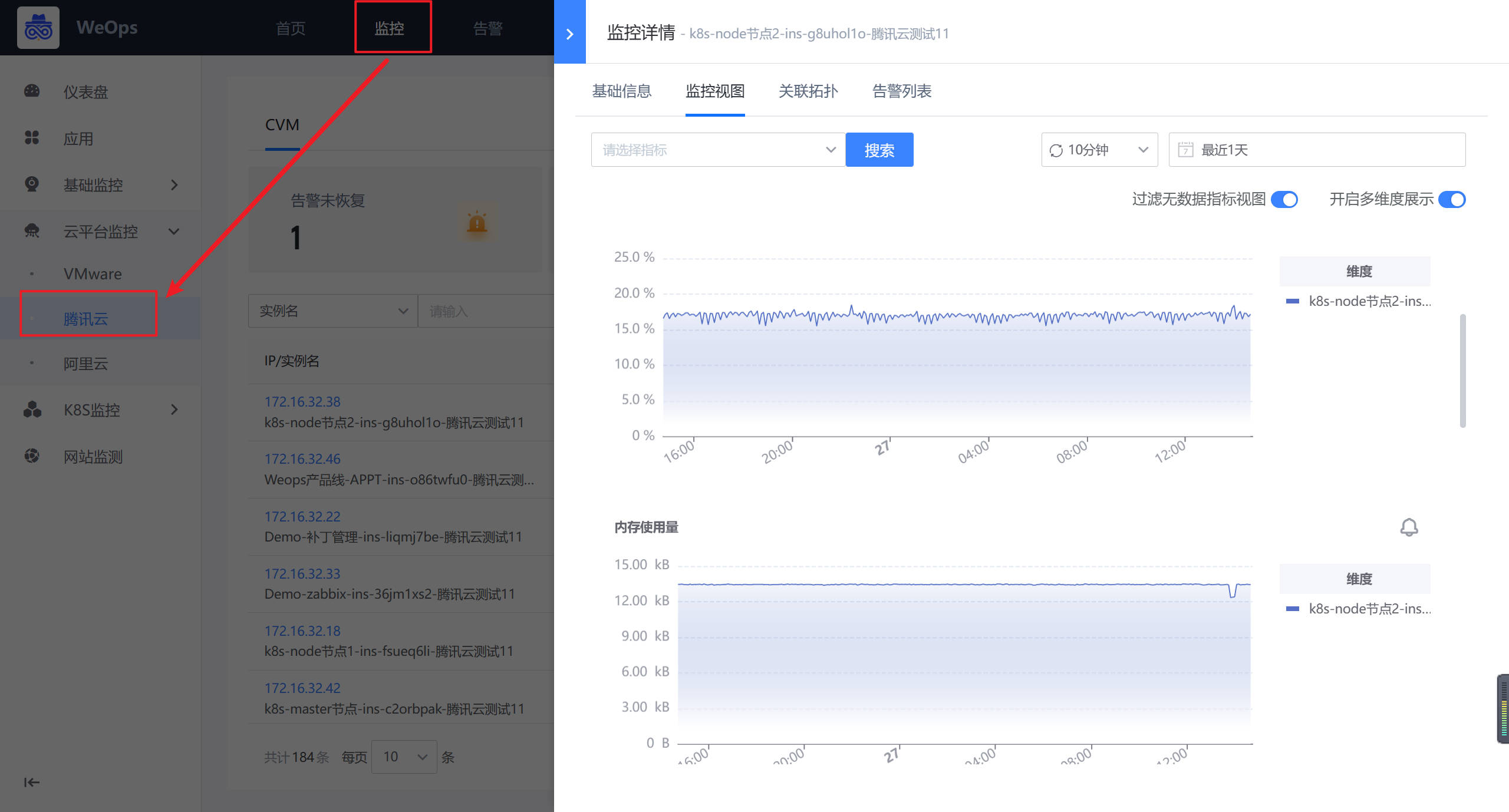
路径:管理-监控管理-监控策略(虚拟化监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增云平台-腾讯云监控策略。

- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)

- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。

- 下一步“告警配置”可查看“2.2告警配置”
网站监控配置
背景介绍:需要将新的网站纳入拨测监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-网站监测
- 如下图所示,进入网站监测的纳管界面,进行新增拨测任务。
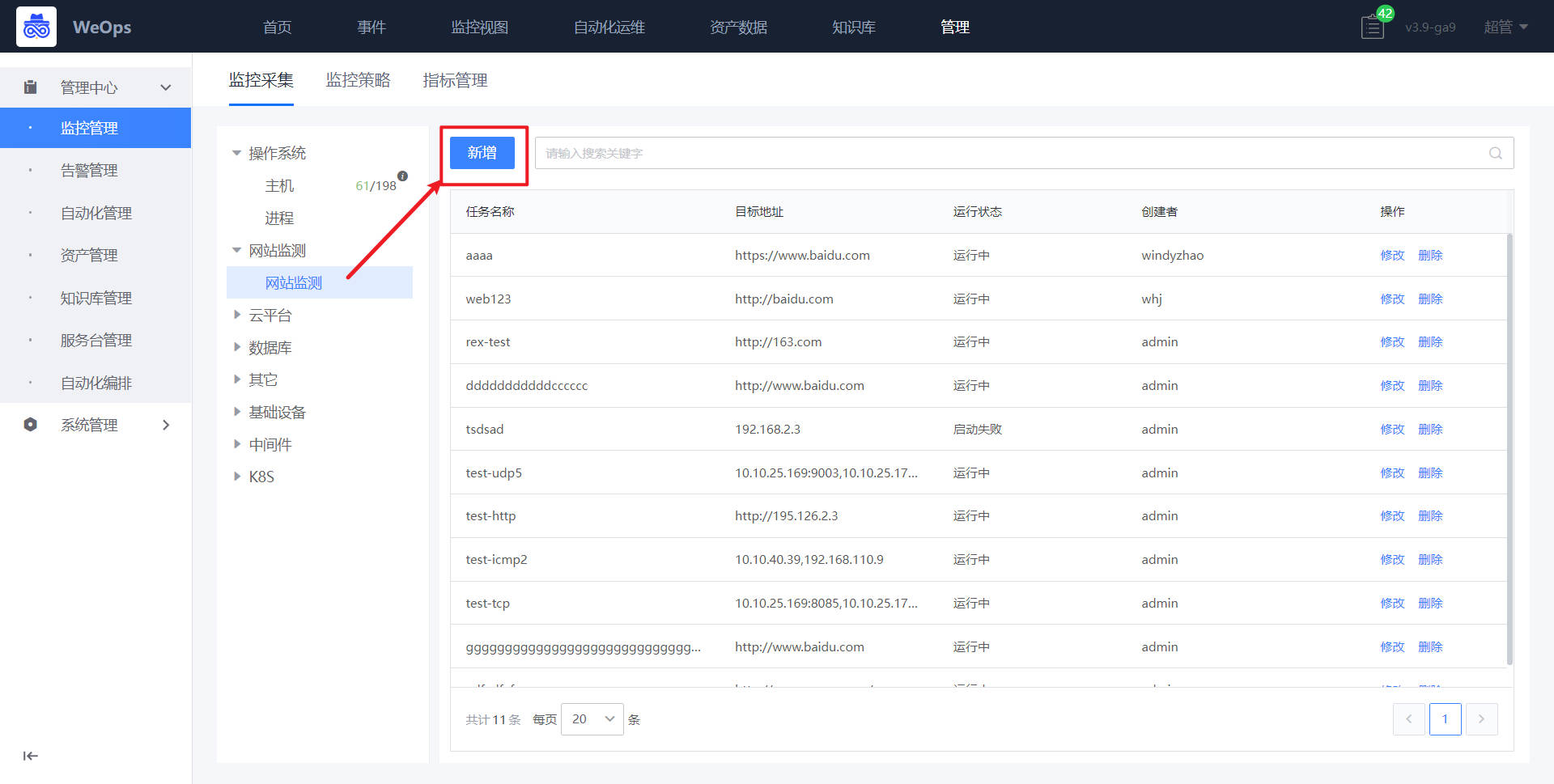
- 如下图所示,对任务进行配置后点击提交。提交之际系统会进行一次拨测,拨测成功后该任务才算创建成功,否则无法创建。若是创建失败请检查相关配置。

- 新建完成后,可以在监控视图-网站监测中查看已经采集监控数据和监控视图
Step2:监控策略配置
路径:管理-监控管理-监控策略(网站监测)
- 如下图所示,进入网站监测的配置界面,进行新增拨测监控。
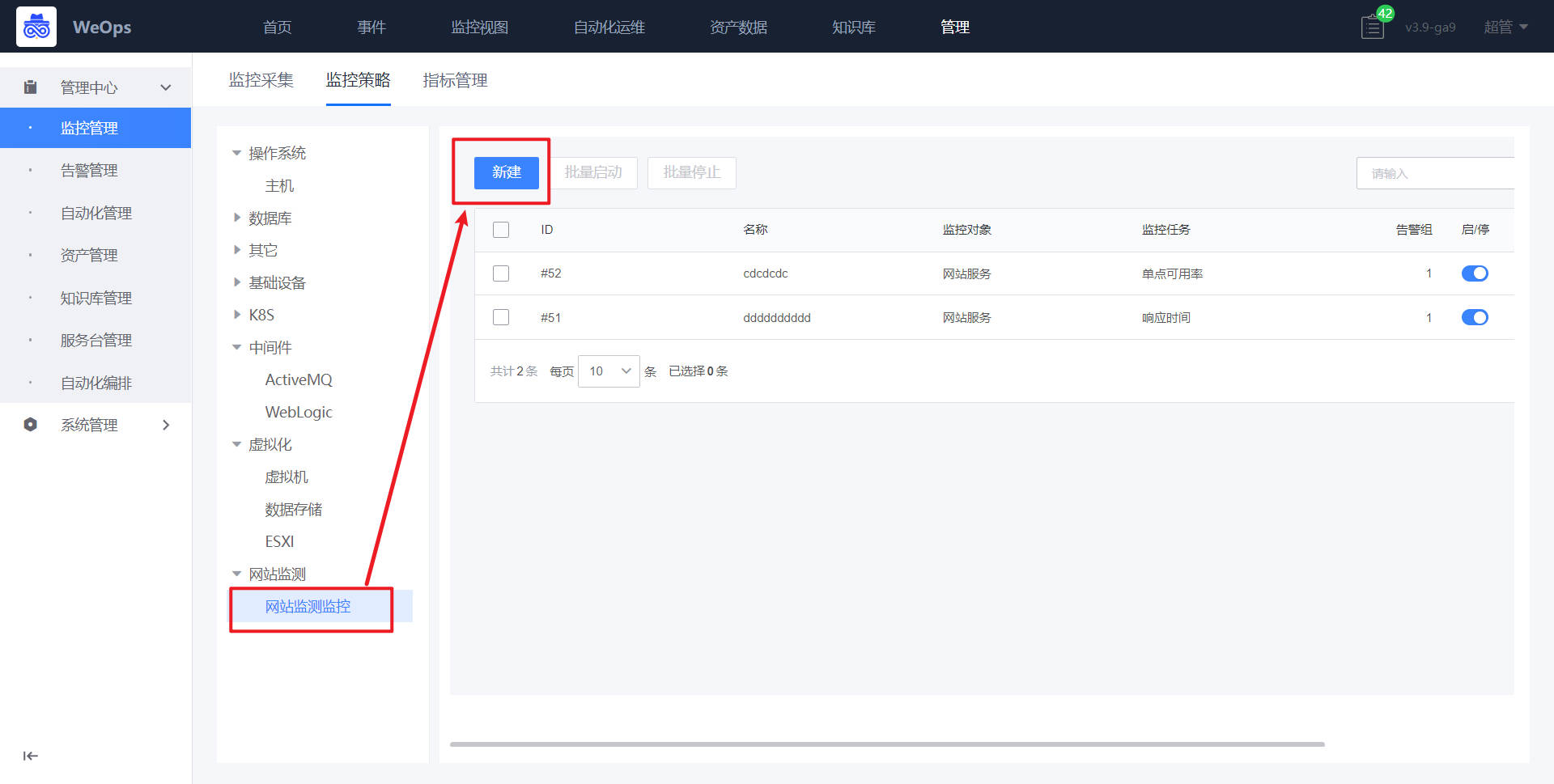
- 如下图所示,进行监控项的相关配置,并配置触发和恢复规则,以及选择监控对象,点击确定,即完成对应服务拨测的监控配置
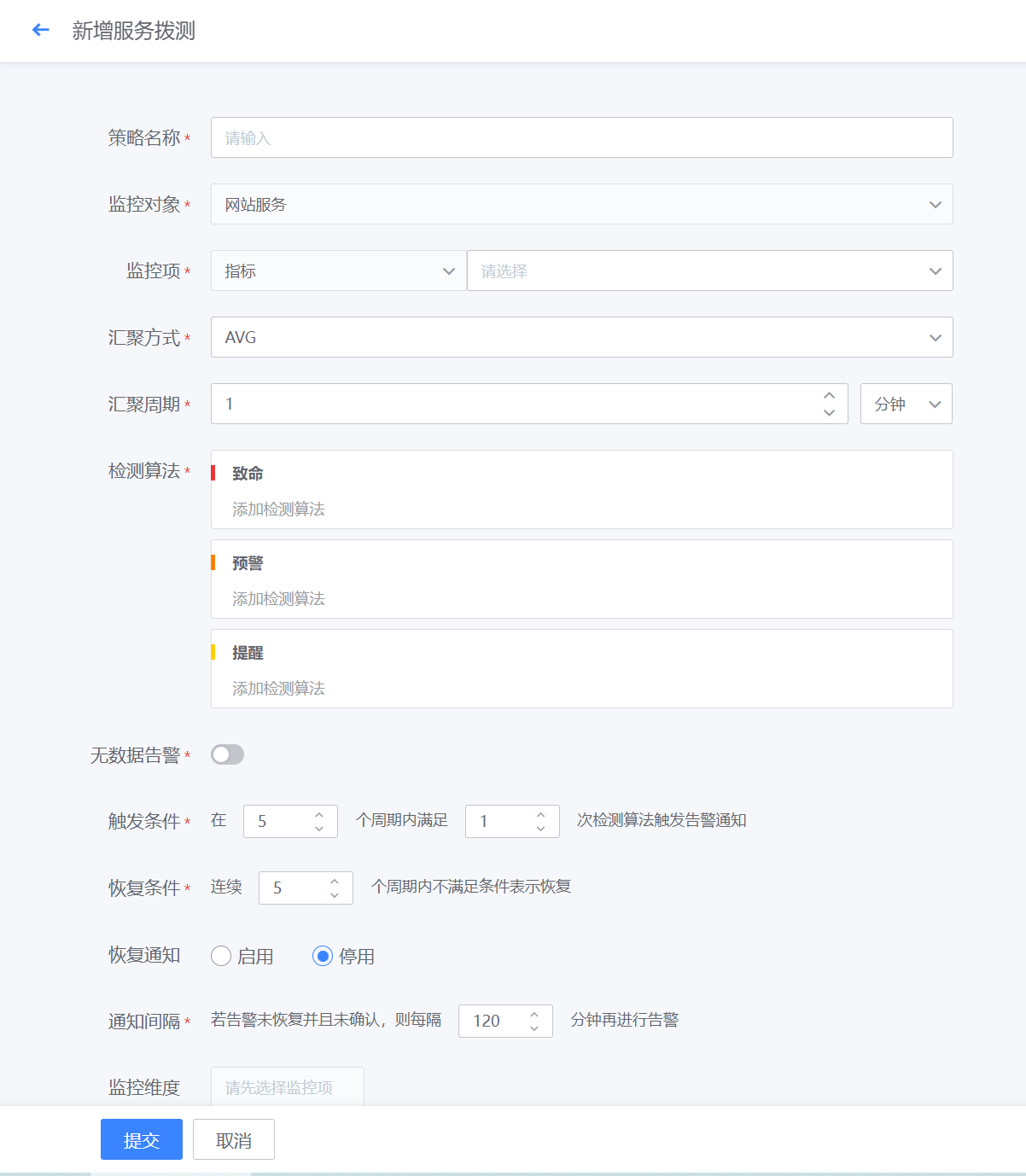
- 网站监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
K8S监控配置
背景介绍:需要将K8S集群中的pod/node纳入监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图,进入监控采集页面,选择K8S,K8S采集任务的新建。

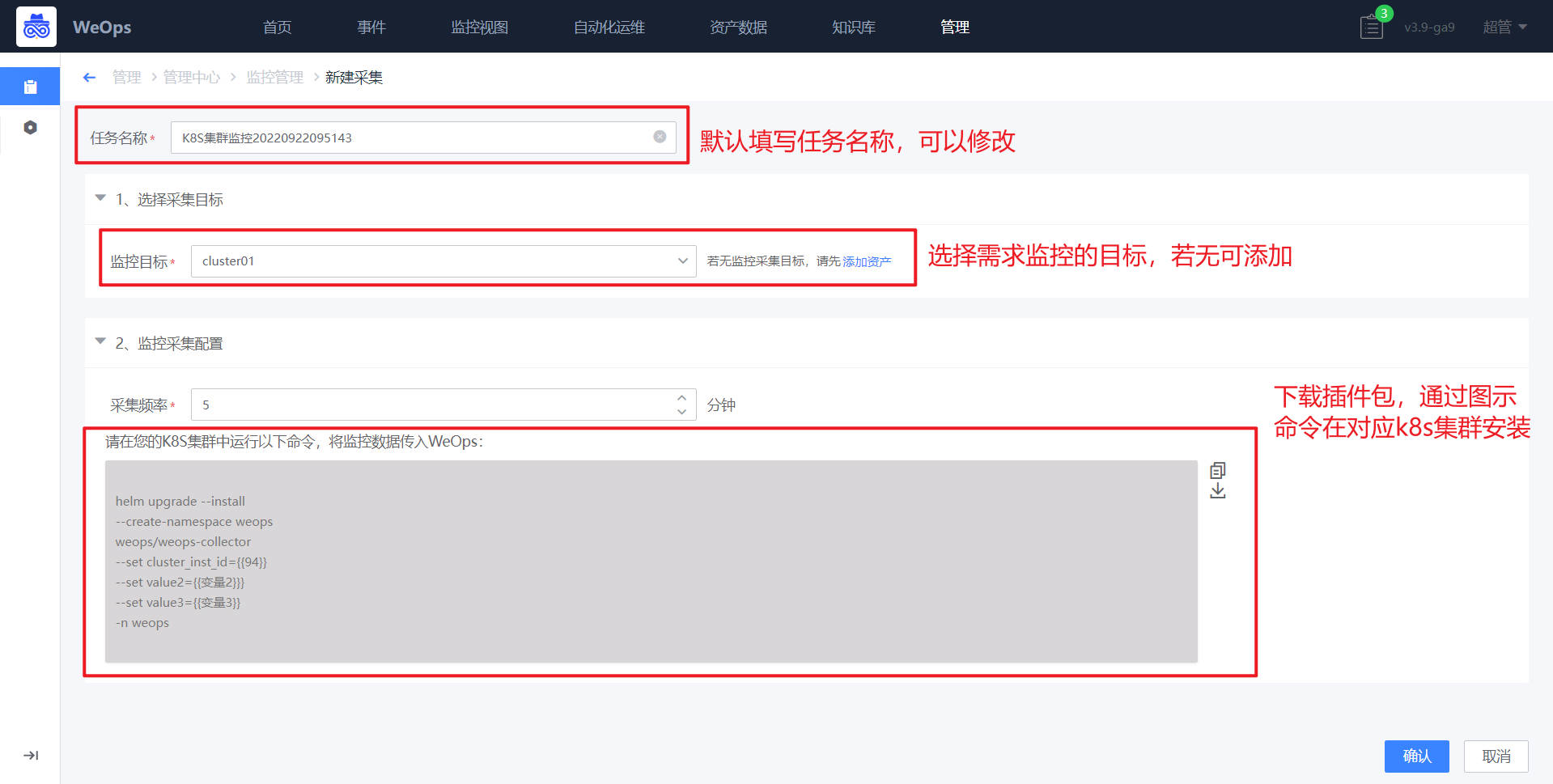
- 如下图,在采集新建界面,选择需要采集的K8S集群名称(若无可以在该页面进行添加)、配置采集频率,进行K8S监控需要将对应的安装包安装到对应的k8s集群里面,可以从该界面下载安装包,并运行一下命令进行部署
- 【注】 监控的采集安装包和自动发现的一样的,如果该K8S已经在自动发现时进行了的部署,配置监控采集时可以省去“部署安装包”这一步操作
注:有以下两种情况
(1)若集群可以使用公网镜像源时,解压安装包,进行安装即可
tar -zxvf weops-kubernetes.tgz
helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace --set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一版为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write
(2)若不能使用公网镜像源时,需要先手动导入镜像并推送到私有仓库中,当集群不能使用公网镜像源时,需要手动导入镜像并推送到私有仓库中,压缩包里附带了需要用到的镜像文件,kube-state-metrics.tgz,node_exporter.tgz,cadvisor.tgz,prometheus.tgz
需要在helm install时指定本地仓库镜像helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace \
--set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一般为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write \
--set image.repository=$(prometheus的私有仓库,如10.10.10.10:5000\prometheus) \
--set kube-state-metrics.image.repository=$(kube-state-metrics的私有仓库,如10.10.10.10:5000\kube-state-metrics) \
--set cadvisor-exporter.image=$(cadvisor的私有仓库,如10.10.10.10:5000\cadvisor):latest \
--set node-exporter.image=$(node-exporter的私有仓库,如.10.10.10:5000\cadvisor):latestStep2:监控策略配置(以node为例)
路径:管理-监控管理-监控策略(K8S)
- K8S集群监控采集新建完成以后,可以对pod和node进行监控策略的配置。
- 如下图,进入到监控策略页面,选择K8S-node,点击“新建”按钮
- 在新建界面,策略名称、和监控对象已经默认填写。
- 如下图,点击“选择监控目标”,进行监控对象的选择
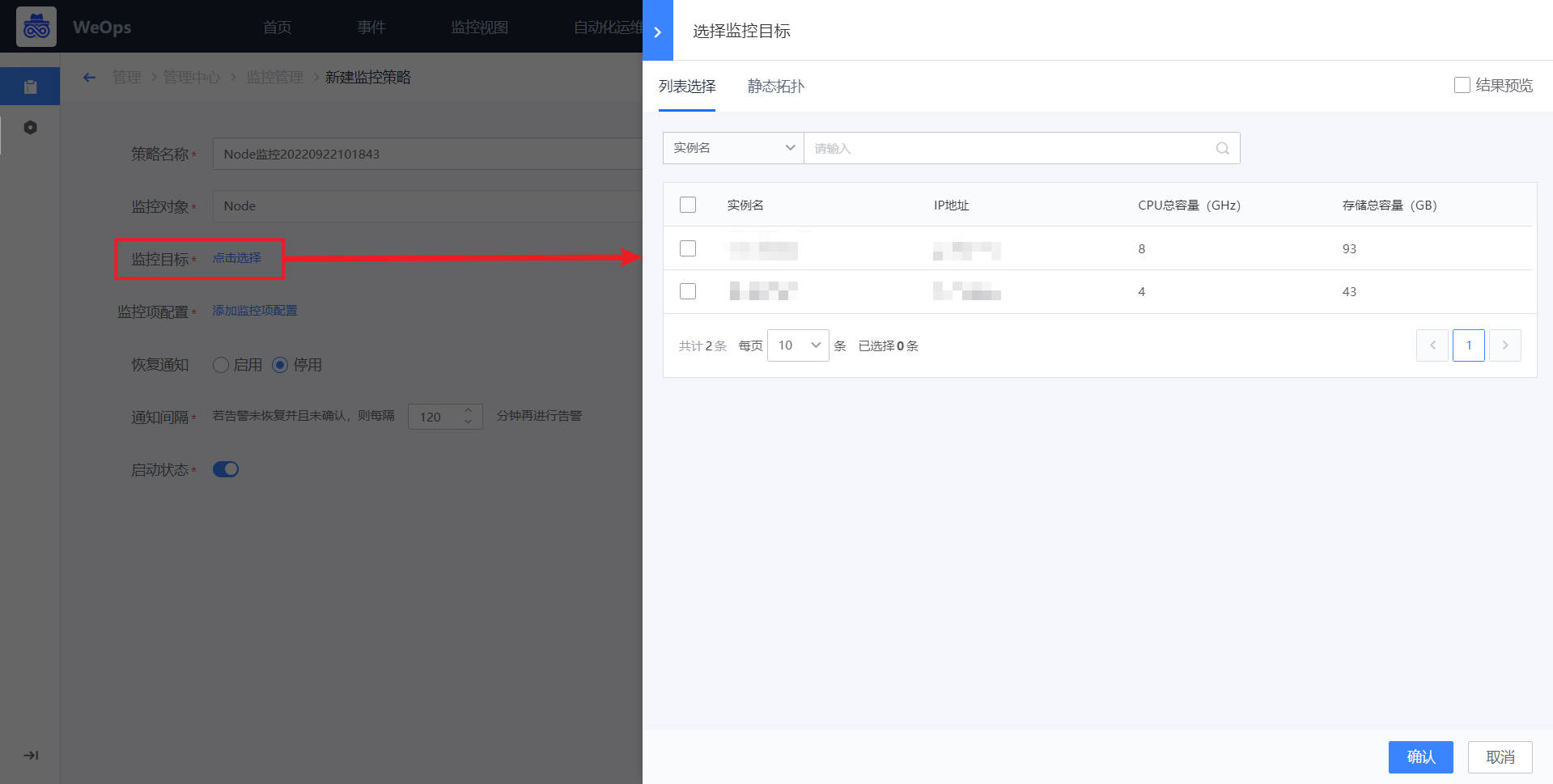
*如下图,点击“添加监控项配置”,可进行监控项的选择和配置,这里需要说明的是,由于K8S的特性,监控目标(pod和node)常常处于变化中,可以采取设置监控维度的方式,对某个集群/某个命名空间/某个工作负载下的pod/node进行监控策略的配置,配置成功后,无需选择具体的监控目标,该策略即可生效。
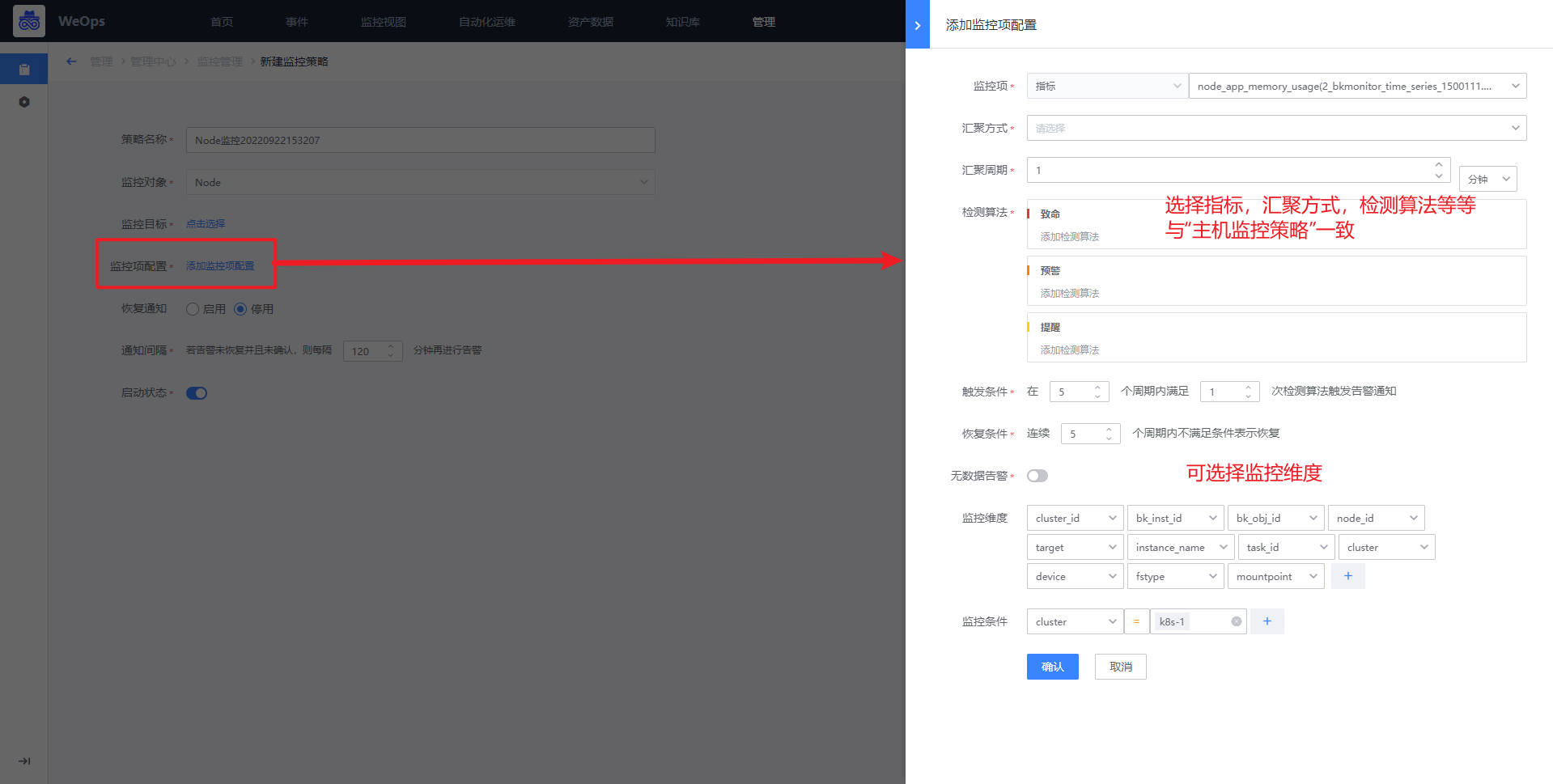
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
网络设备监控配置(以交换机为例)
背景介绍:需要将网络设备纳入监控中,并配置相应的监控策略,前提是已经将网络设备手动/自动发现纳入到资产中了
Step1:导入/新建网络设备指标模板
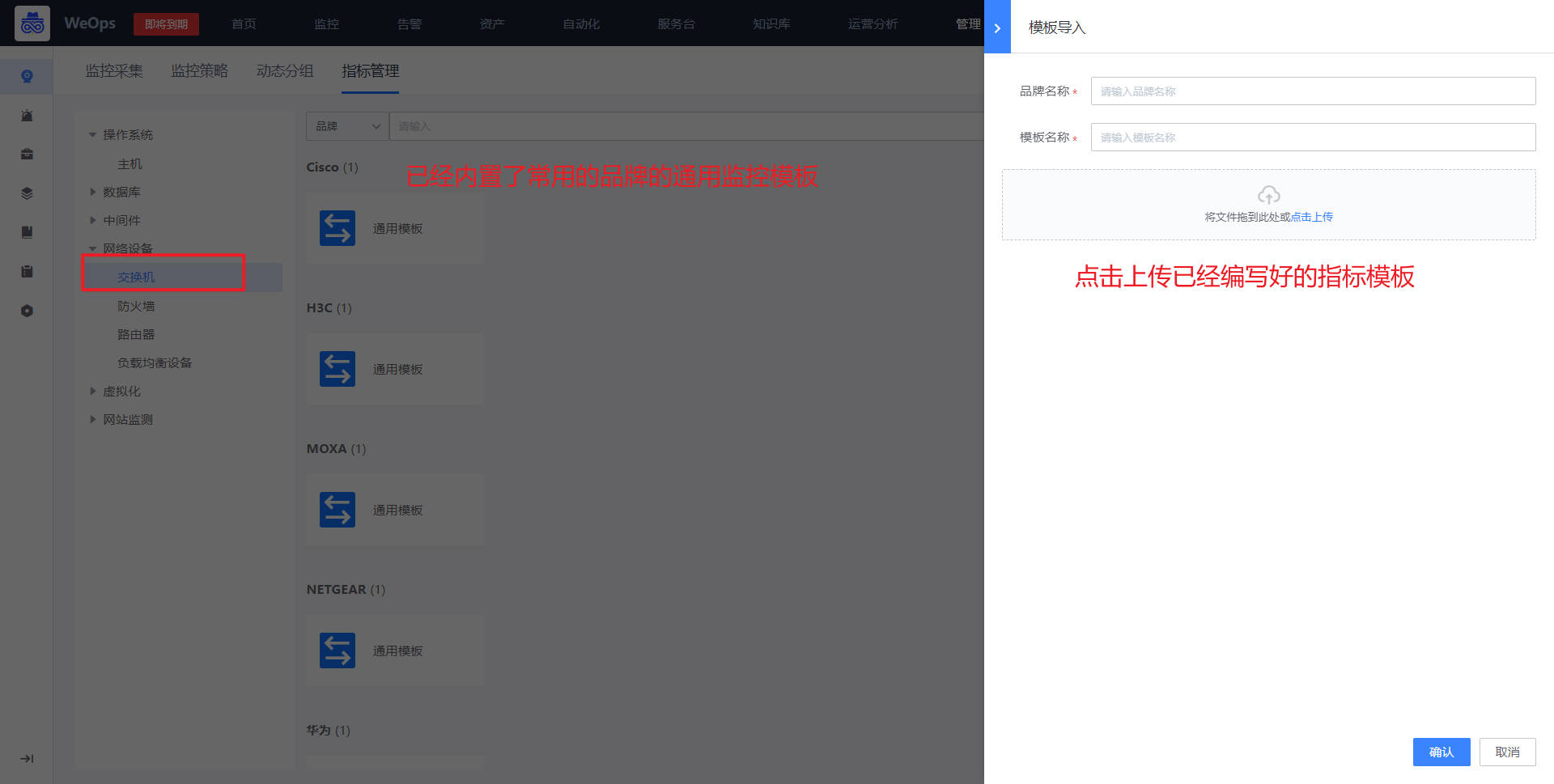
路径:管理-监控管理-指标管理
如下图,在指标管理中,选择网络设备-交换机,点击导入模板,可以进行不同品牌和型号的指标模板导入(WeOps提供了网络设备指标模板导入的入口,可监控的设备品牌、型号等支持拓展。)
如下图,对于导入好的指标模板可以进行对应维度/指标的编辑,便于后续使用。
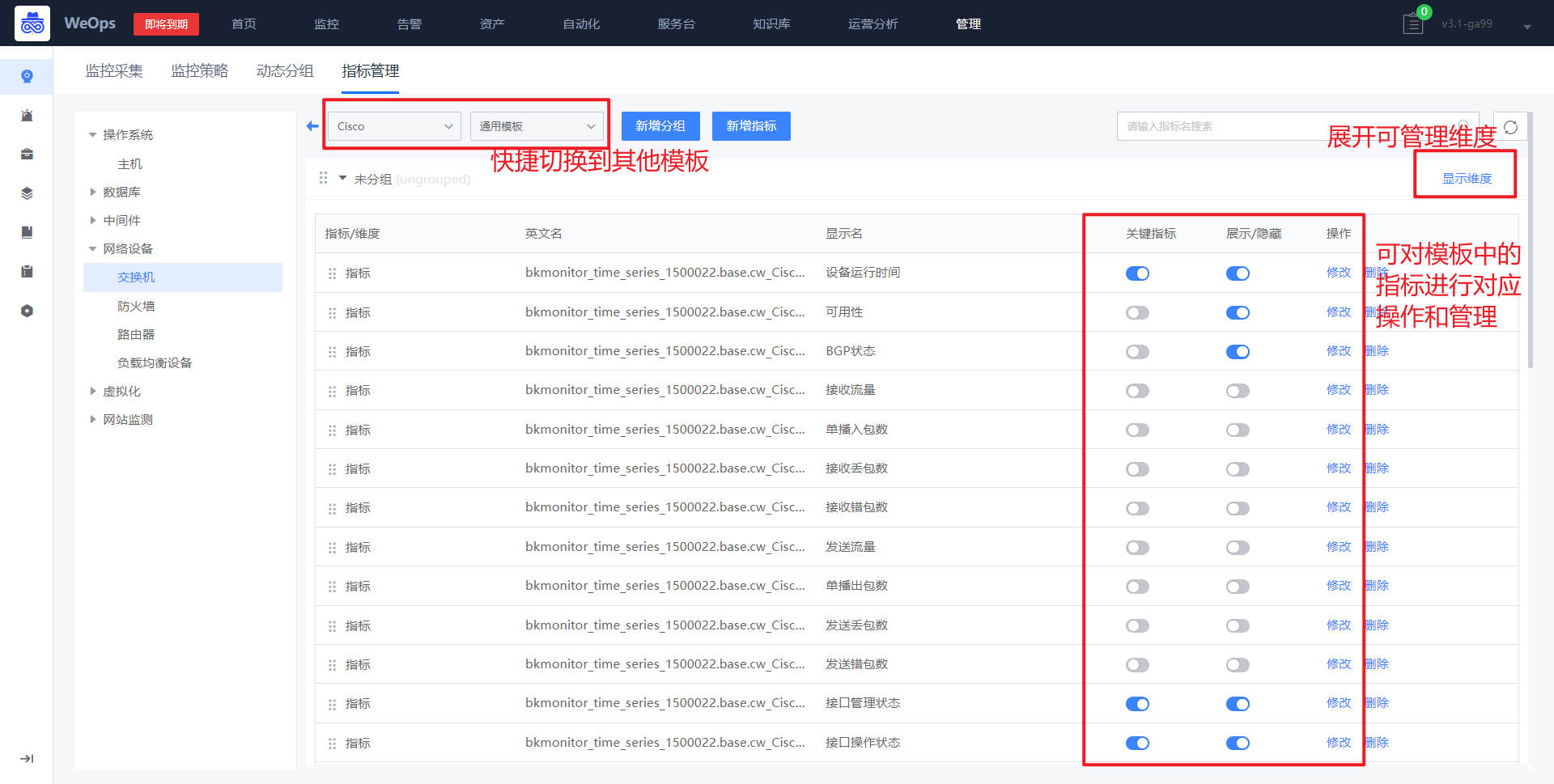
也可以进行指标的新建,具体说明如下
(1)指标型:指标型指标是通过设备的OID(对象标识符)来采集设备的实际数值。所以当某个指标可以找到对应oid进行数据采集时,可以创建指标型指标进行采集。
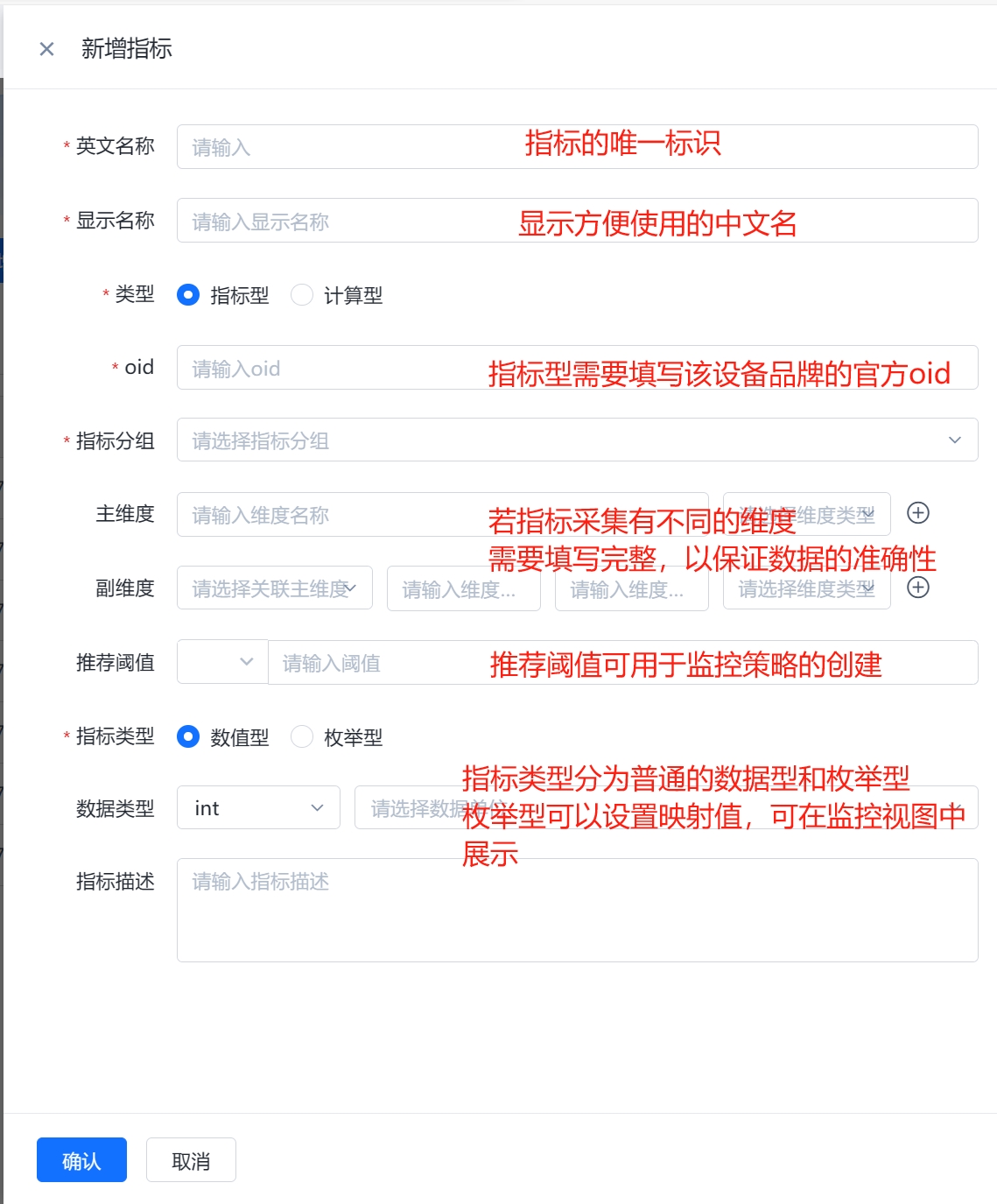
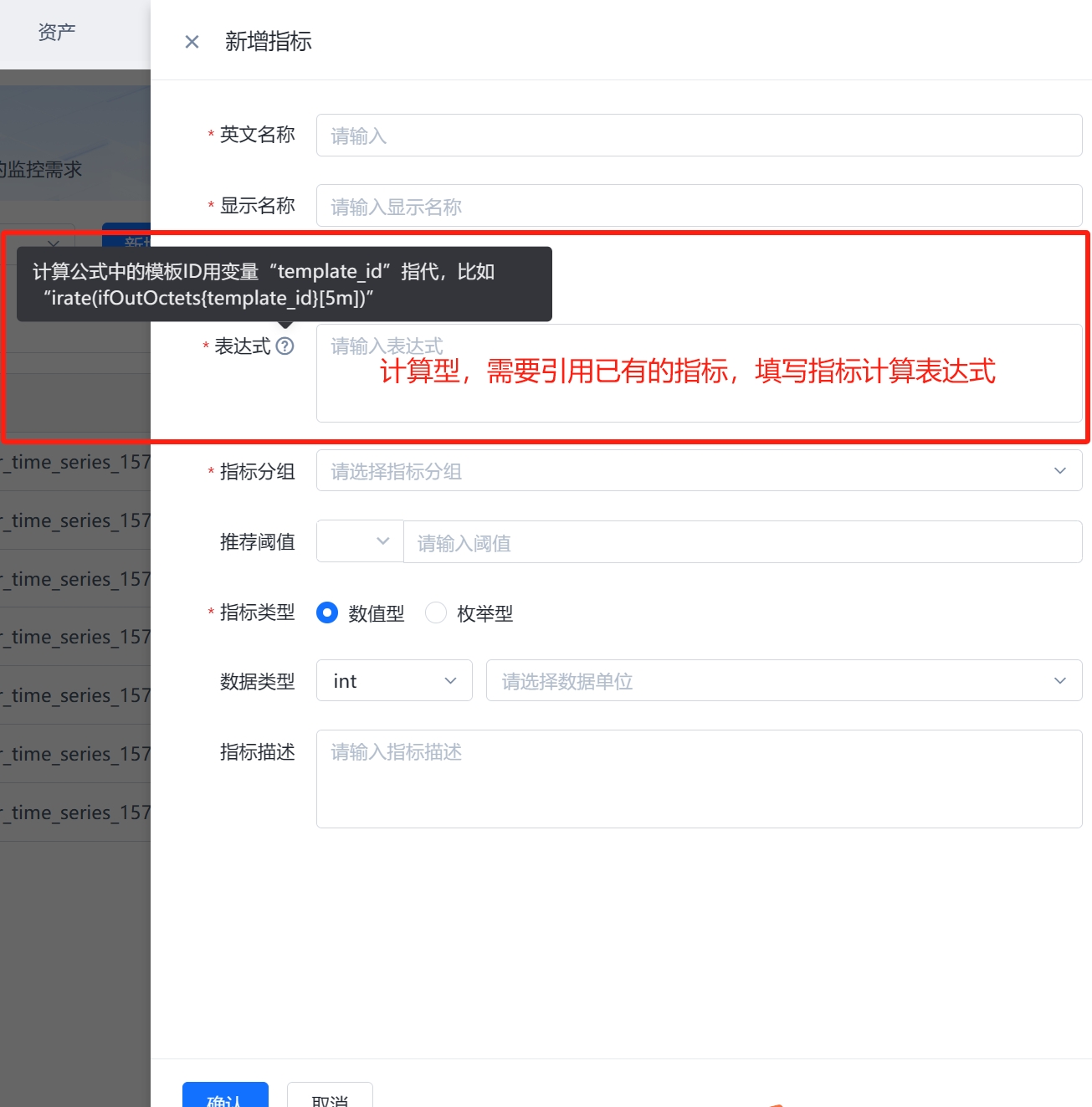
(2)计算型:对指标型指标的数值进行计算得到的指标。计算型指标可以用于更细粒度地监控设备性能,在计算型指标的公式中,需要引用现有指标,可以采用(指标英文名{template_id})的格式进行引用,公式中固定变量“template_id”为指标所在的模板ID,固定不变。比如“irate(ifOutOctets{template_id}[5m])”。
Step2:监控采集
当需要监控的网络设备已经纳管,并且有适用的监控指标模板(可以是内置的,也可以是导入创建的),可以对网络设备进行监控采集的创建,选择对应的目标,适用的指标模板,并填写凭据信息。


如下图,监控采集创建完成以后,可以在监控视图中,查看对应监控对象的监控信息
Step3:监控策略配置(以交换机为例)
- 网络设备监控采集新建完成以后,可以网络设备进行监控策略的配置。
- 如下图,进入到监控策略页面,选择网络设备-交换机,点击“新建”按钮
- 在新建界面,策略名称、和监控对象已经默认填写。点击“选择监控目标”,进行监控对象的选择点击“添加监控项配置”,可进行监控项的选择和配置
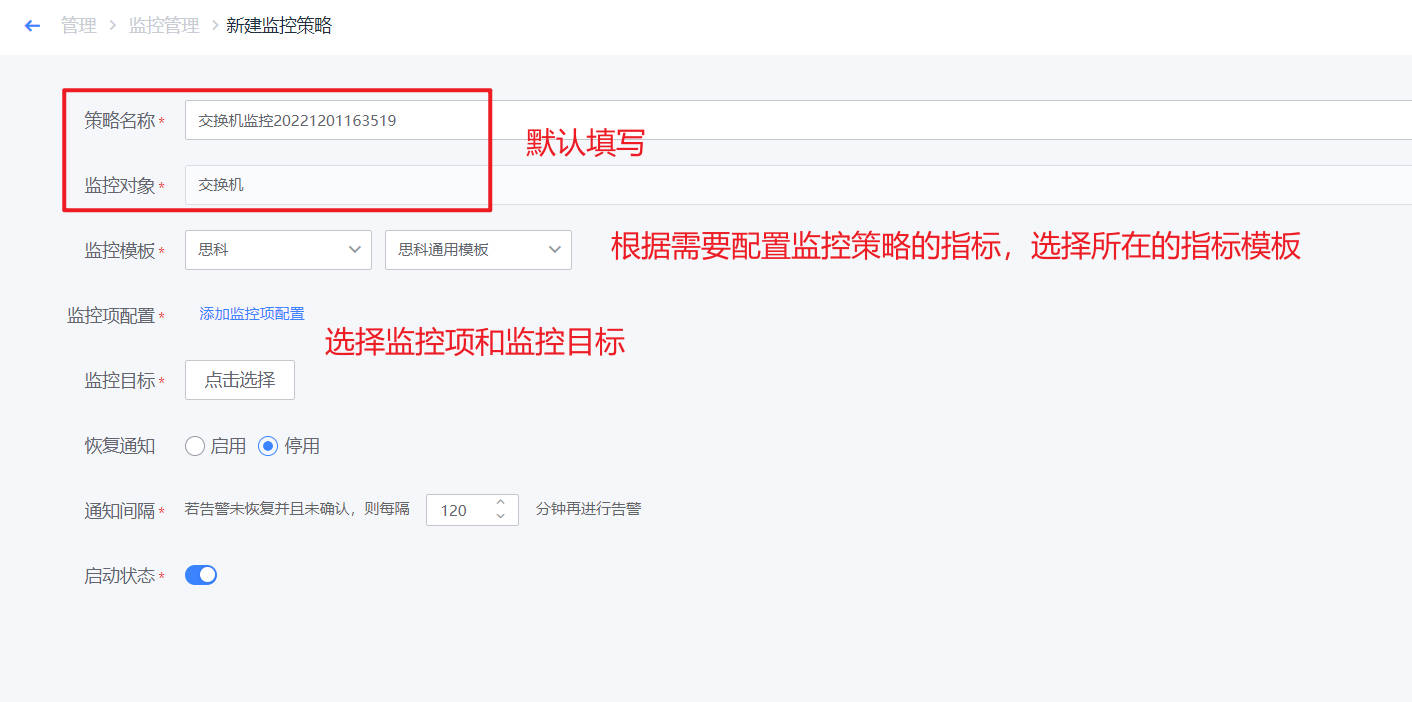
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
硬件设备监控配置
背景介绍:需要将硬件设备纳入监控数据采集中,并设置对应监控策略。
注意:ipmi采集暂时不支持自定义端口Step1:监控采集
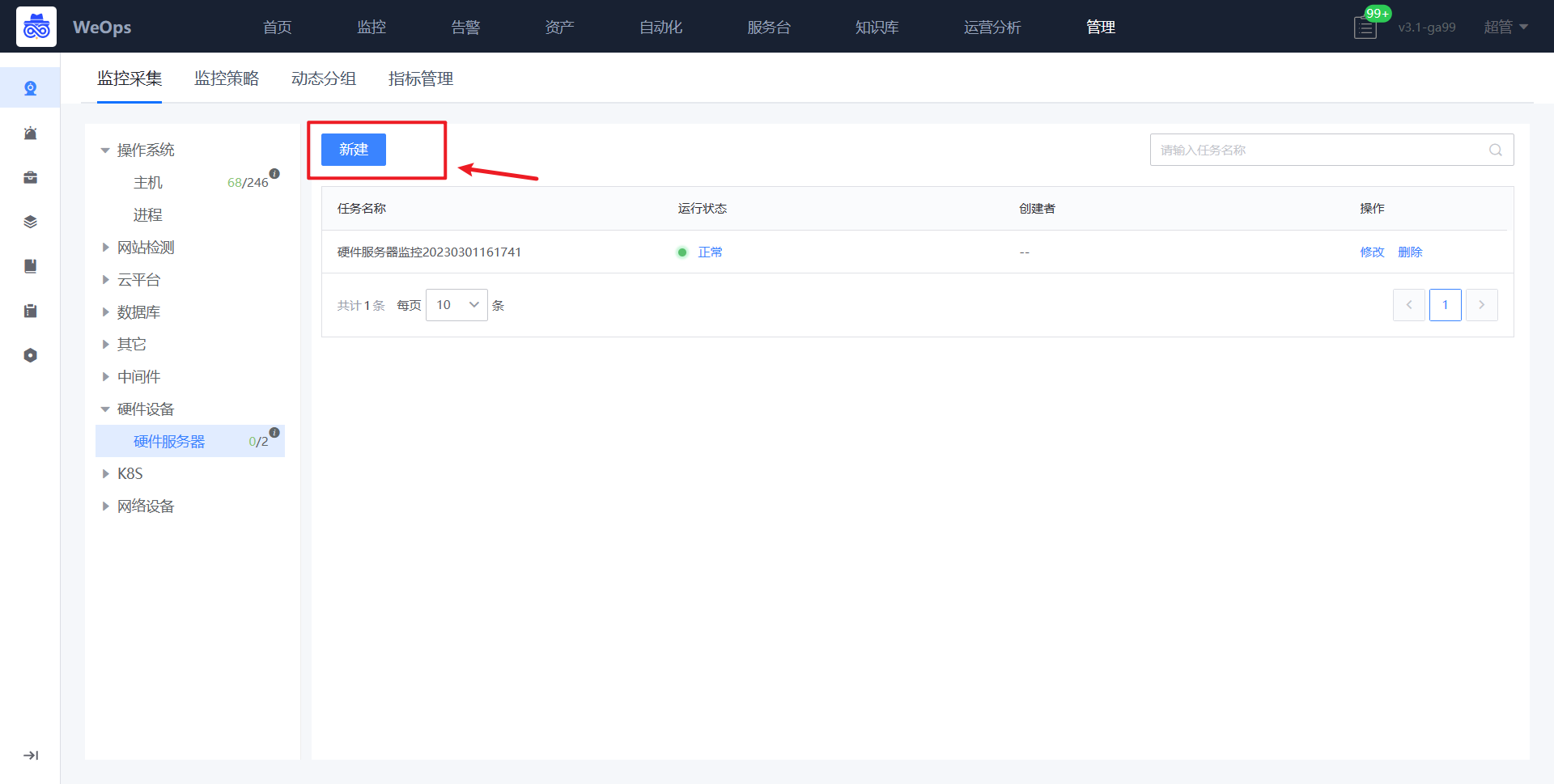
路径:管理-监控管理-监控采集
- 如下图所示,进入硬件服务器的监控采集界面,进行新增。
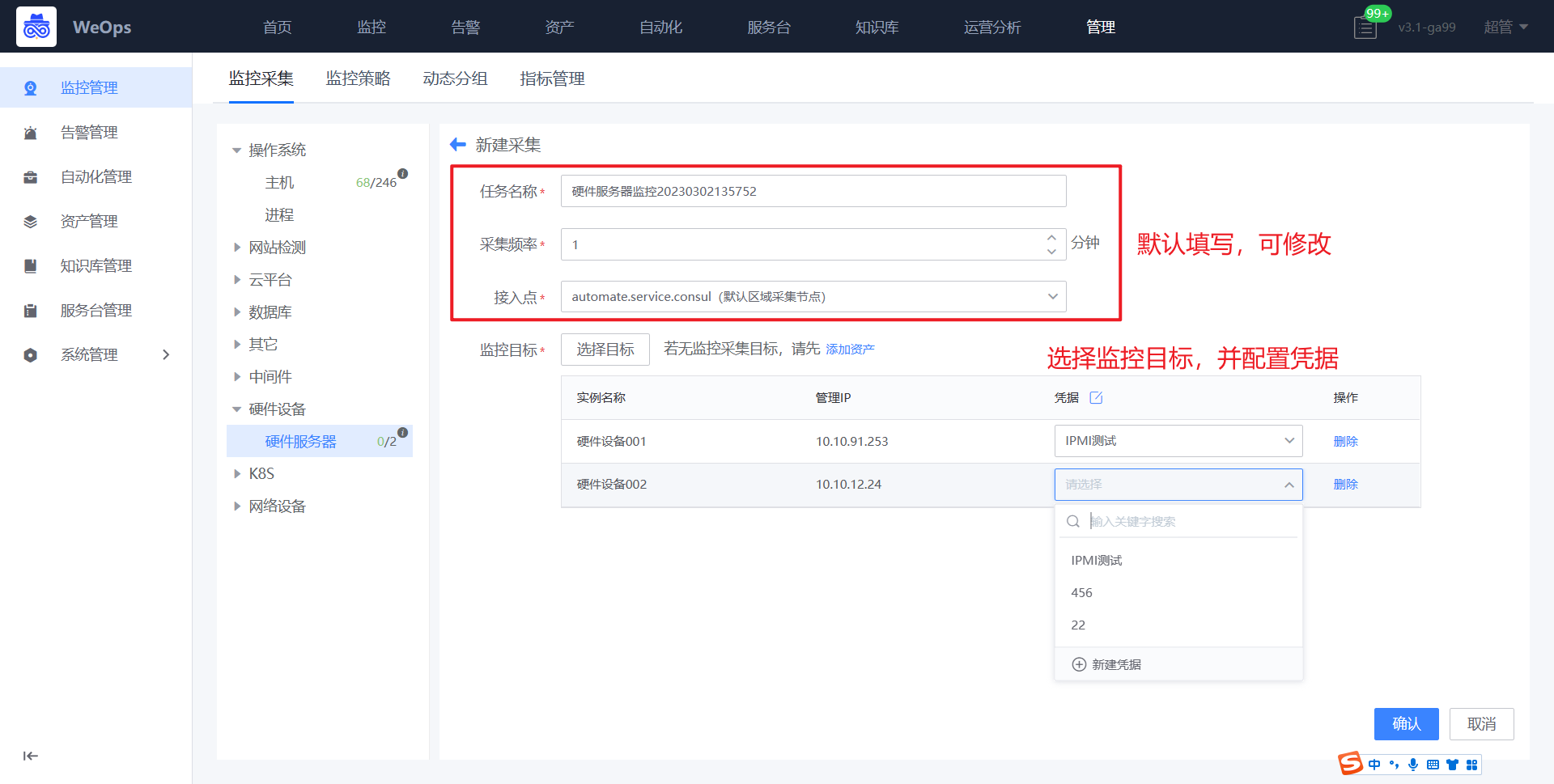
- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等
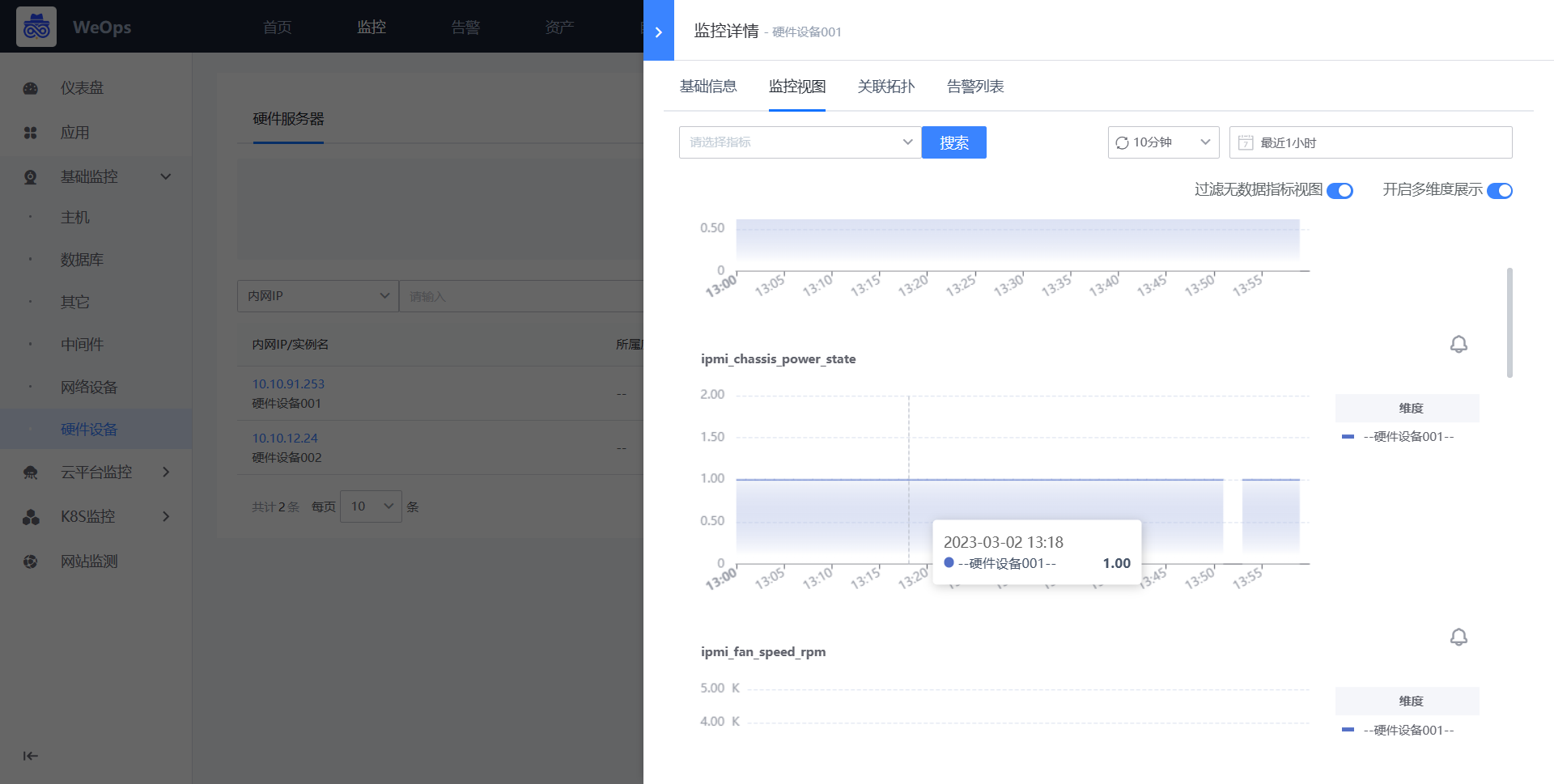
- 新建完成后,可对该设置的硬件设备进行监控数据的采集,并可以在WeOps-监控视图-基础监控-硬件设备中查看已经采集监控数据和监控视图
Step2:监控策略配置
路径:管理-监控管理-监控策略(硬件监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增硬件设备-硬件服务器监控策略。
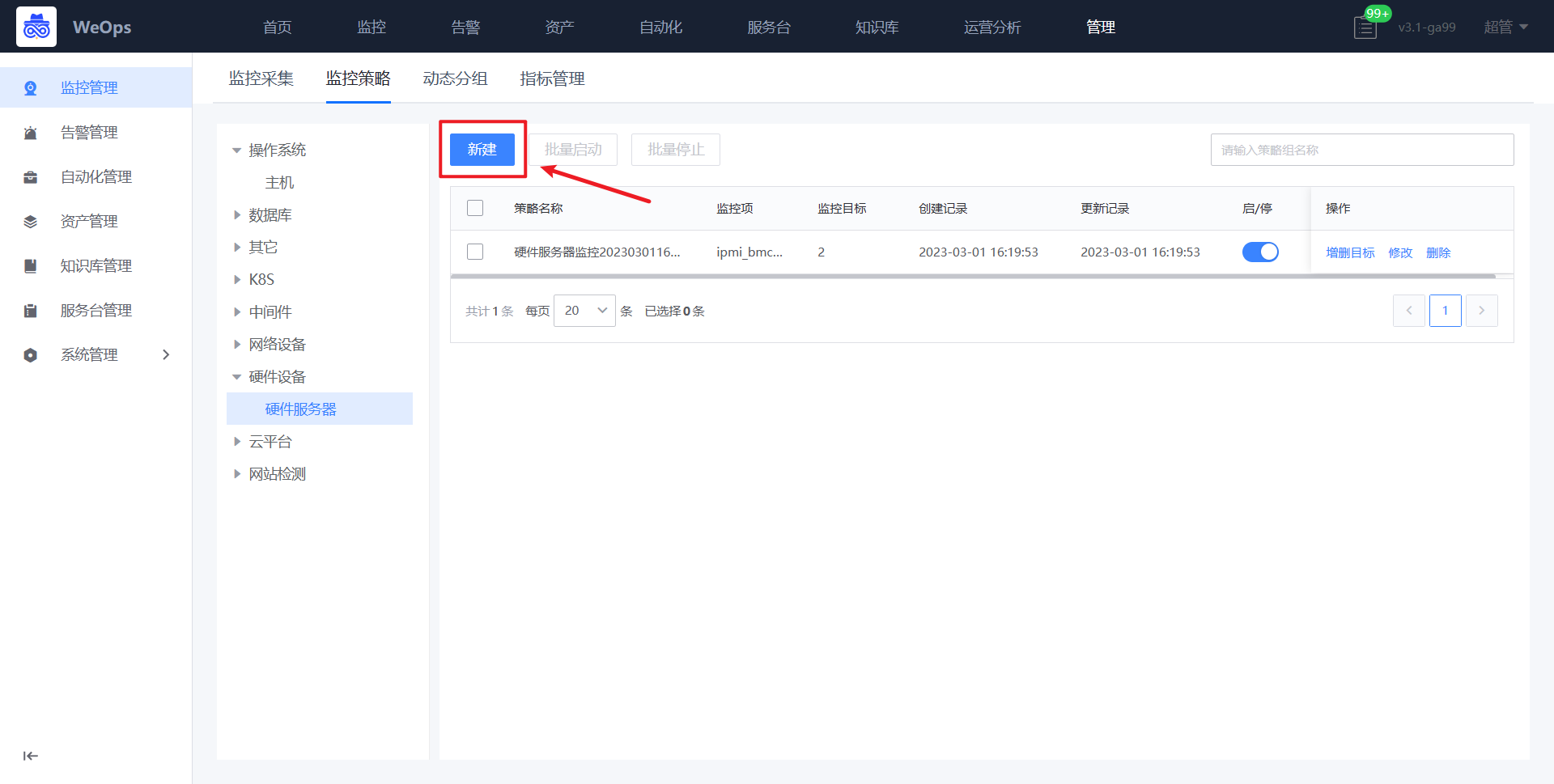
- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
告警配置
背景介绍:监控对象已经进行监控数据采集,并配置好相关的监控策略,需要对产生的告警配置抑制、屏蔽、自动分派、自动处理等策略,或设置人员通知。各个对象的告警配置一致,此处介绍通用方法。
告警抑制
通过用户自定义配置告警抑制策略,让符合筛选条件的告警被抑制(即不会成为有效告警)。
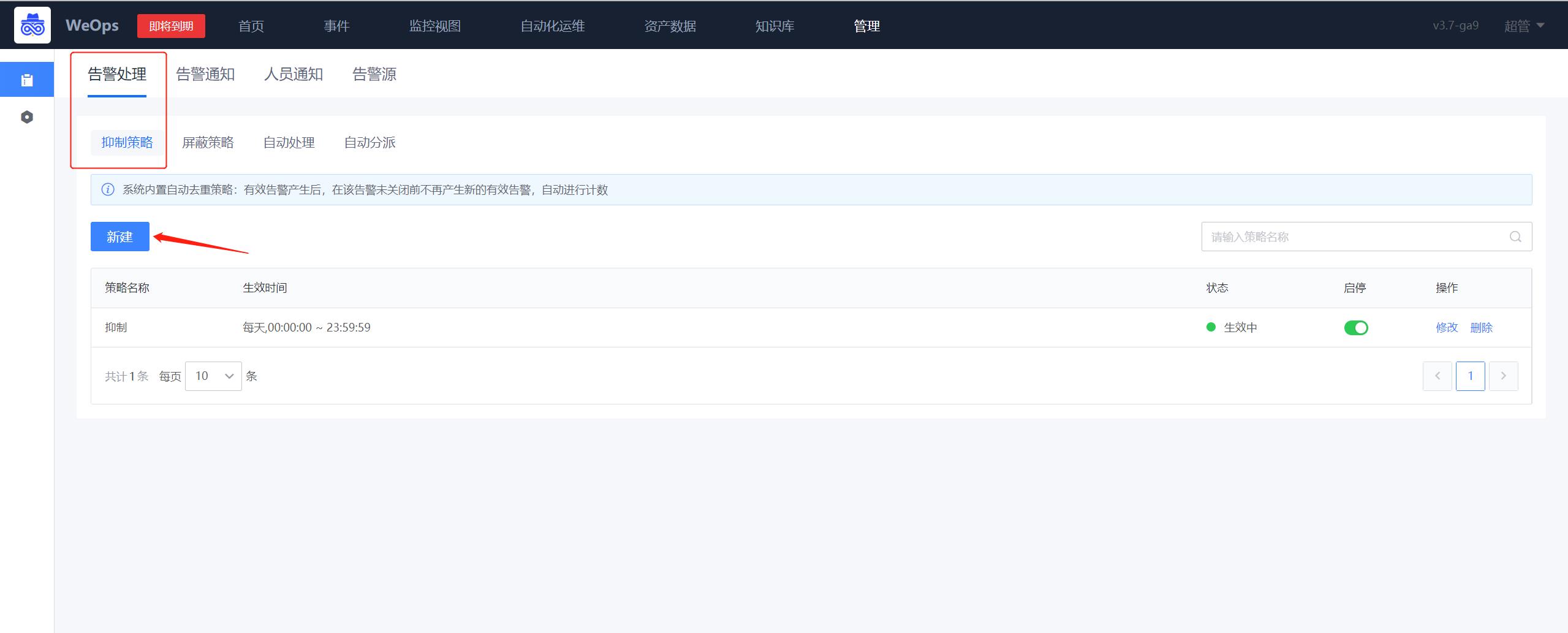
路径:管理-告警管理-告警处理-抑制策略
- 如下图所示,点击新增告警抑制策略规则。
- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。

注:目前有三种抑制策略
【第一种,内置的自动去重策略】:统一告警中心的告警都有一个告警事件 ID 字段,由告警源插件来设定这个字段的清洗规则,当一条告警成为有效告警后,在此条告警未关闭也未恢复的情况下,相同告警事件 ID 的告警自动被收敛。
【第二种,防抖抑制】:抑制抖动类指标偶发性产生的告警事件,如: CPU 使用率、内存使用率、磁盘 IO、网卡流量等
抑制规则: n 时间内出现 x 次则产生一条有效告警, 且告警关闭前不再产生新的告警。假设用户设定, 5min 内出现 4 次则产生一条有效告警;那么当告警中心接收到 1 条告警后,没有被自动去重,它会等待 5min,如果这 5 分钟内再次产生了 3 条及以上告警(除告警时间外,其他字段都相同),才会产生有效告警,5min 内产生的告警数量不足以达到数量要求,那这些告警全部被收敛,不会产生有效告警。
【第三种,关联聚合】:将关联字段相同的告警聚合,如: 7 分钟内“ 告警源+告警指标+告警对象+CMDB 业务+告警等级” 告警相同的告警聚合为 1 条有效告警。
聚合:第一条有效告警产生后,如果设定的时间窗口内产生关联字段相同的告警,那么这些告警被收敛。
执行顺序:如果一条告警被接收到后,之前没有相同告警事件 ID 的有效告警,则自动去重无法生效,执行告警抑制策略匹配,待产生有效告警后,后续接收的,相同告警事件 ID 的告警,会被自动去重;如果一条告警被接收到后,之前已有相同告警事件 ID 的有效告警,则优先执行自动去重,不会也不必再去执行抑制策略。告警屏蔽
某些主机在执行一些日常任务的时候,例如定时备份任务,会导致CPU或是磁盘IO超过监控阈值。生成了”无效”告警,故可以采取该功能进行将特定条件下生成的告警事件进行屏蔽。
路径:管理-告警管理-告警处理-屏蔽策略
- 如下图所示,点击新增告警屏蔽策略规则。

- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。
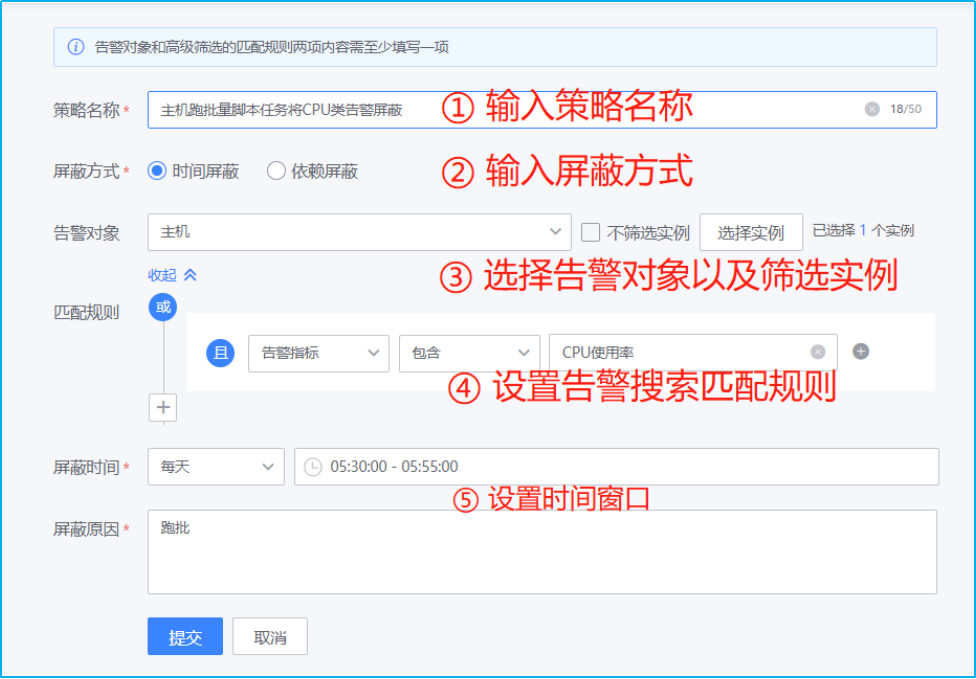
注:支持两种屏蔽方式:时间屏蔽(即维护期屏蔽,按时间段屏蔽符合筛选条件的告警)、依赖屏蔽(当符合 A 筛选条件的告警产生时,屏蔽之后 XX 时间段内的符合B 筛选条件的告警)。告警自动处理
管理-告警管理-告警处理-自动处理
- 如下图所示,点击新增告警处理策略规则

- 如下图所示,新建页面,配置自动处理策略,让符合筛选条件的告警,根据策略优先级执行自动处理方案(包括自动转工单、自愈处理、自动关闭),可设置策略优先级、生效时间、分派人员、通知方式等
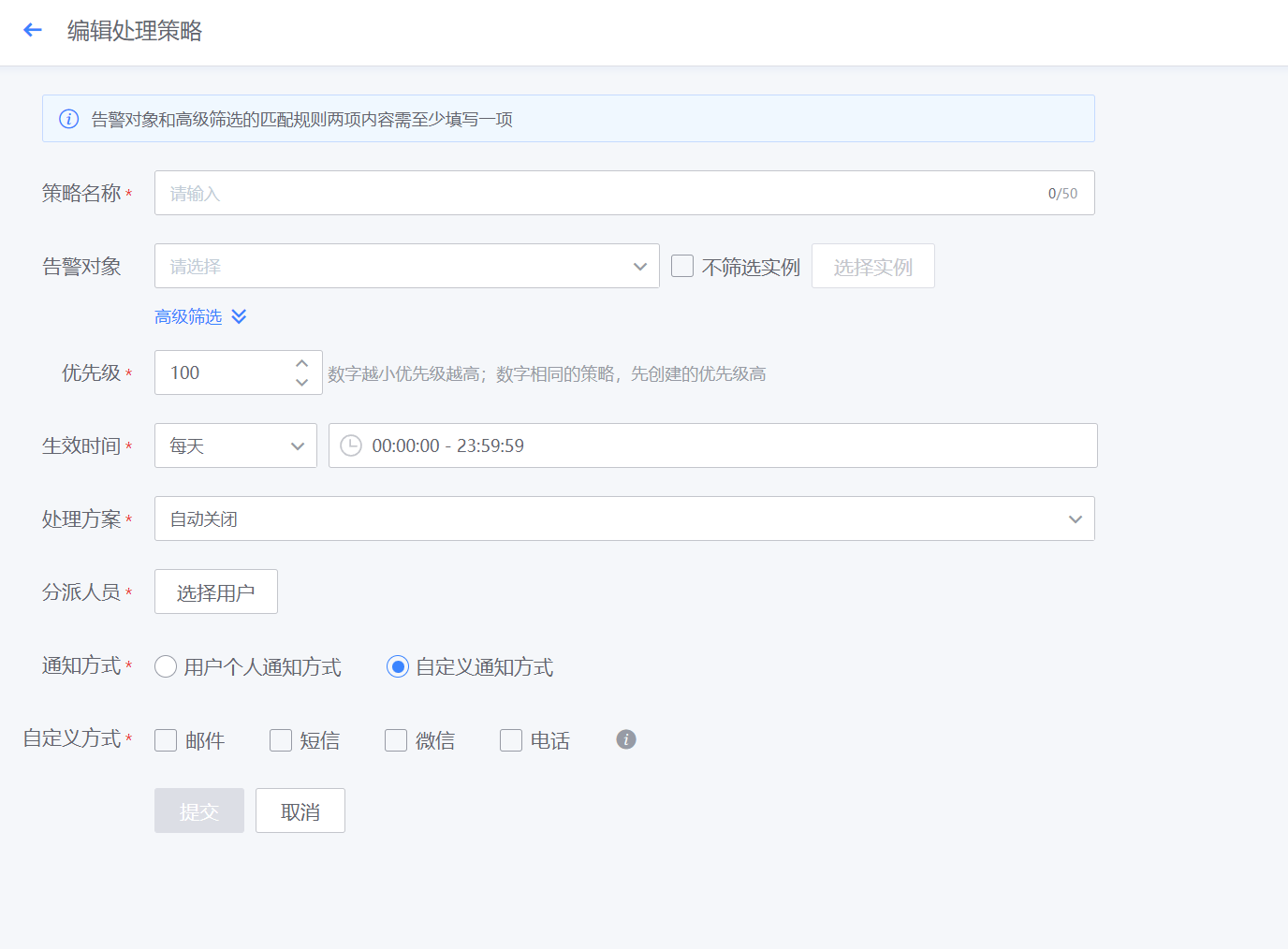
优先级: 1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
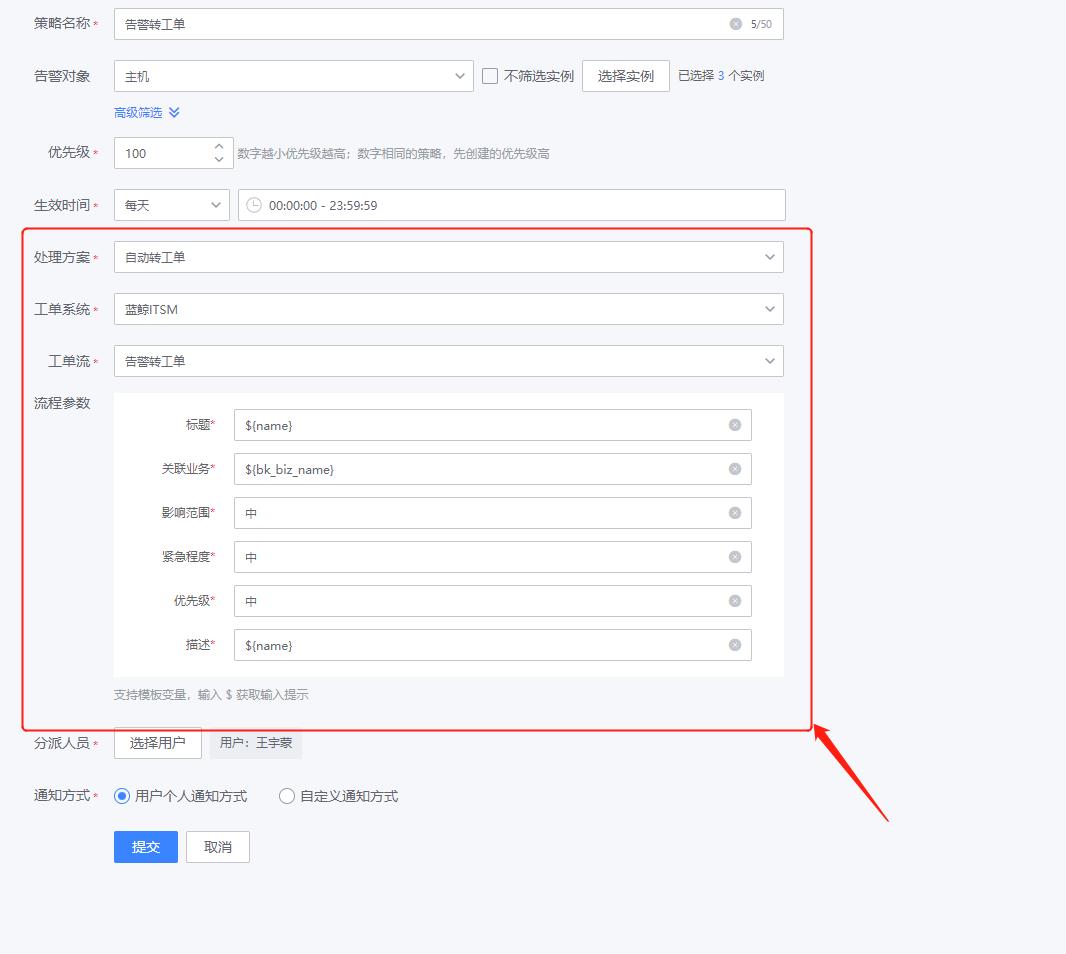
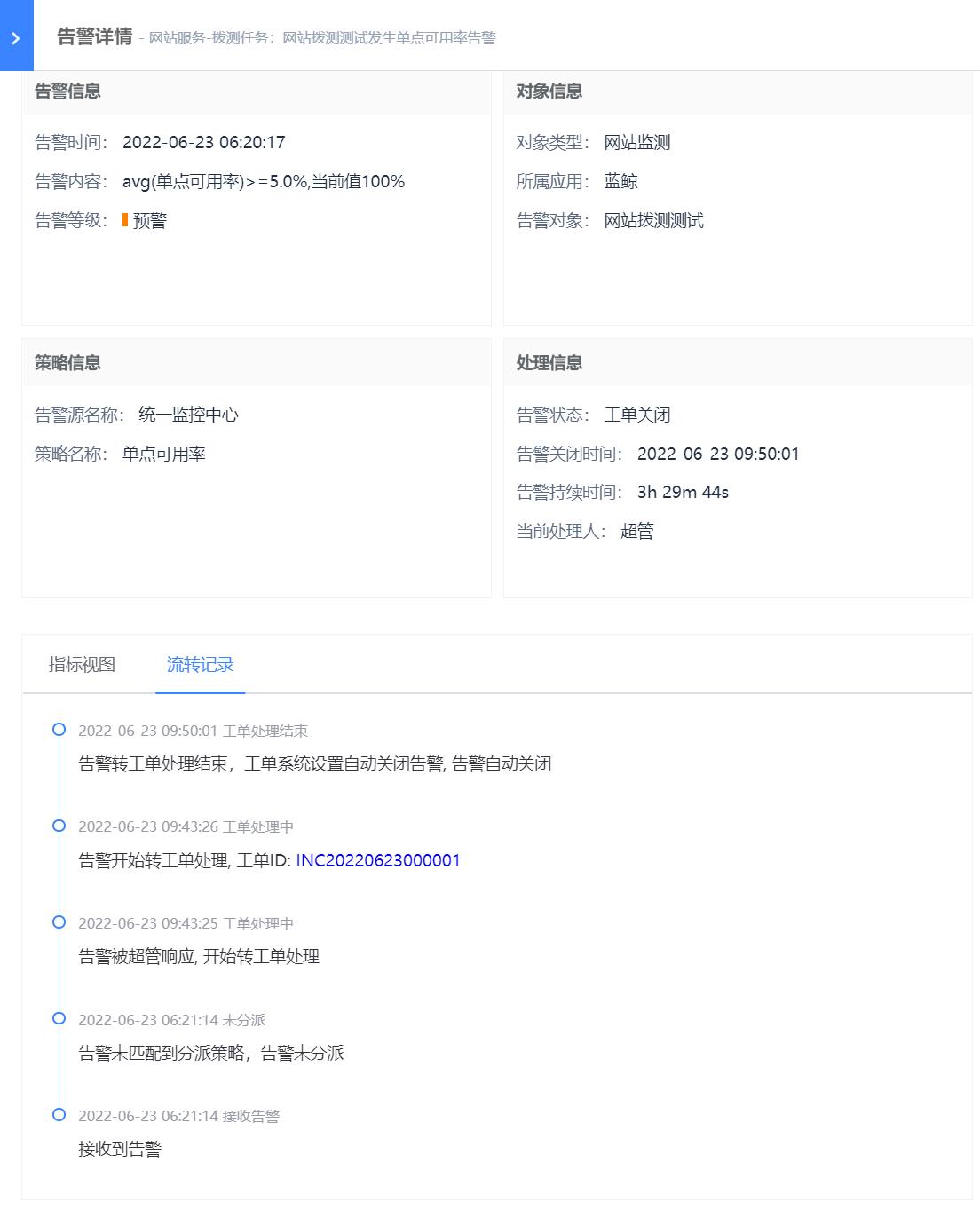
分派人员:可根据组织目录的展开,选择用户;也可切换为全部用户,对用户名进行模糊搜索;还可以选择用户组(包括内置通知用户组和统一告警中心用户与组页面创建的用户组)。这里特殊说明下告警转工单,在“自动处理”中选择处理方案为“自动转工单”,按照工单模块内置的告警转工单流程进行相关字段的填写,设置完成后,符合该策略的告警将会转为工单处理,工单处理结束后,告警会自动关闭。
告警自动分派
配置告警自动分派策略,让符合筛选条件的告警,分派给指定人员或用户组,并可选添加附言、是否通知、通知方式等,这里以【短信】通知的形式来进行介绍
路径:管理-告警管理-告警处理-自动分派
- 如下图所示,进入到告警分派的界面,点击新增告警分派规则。
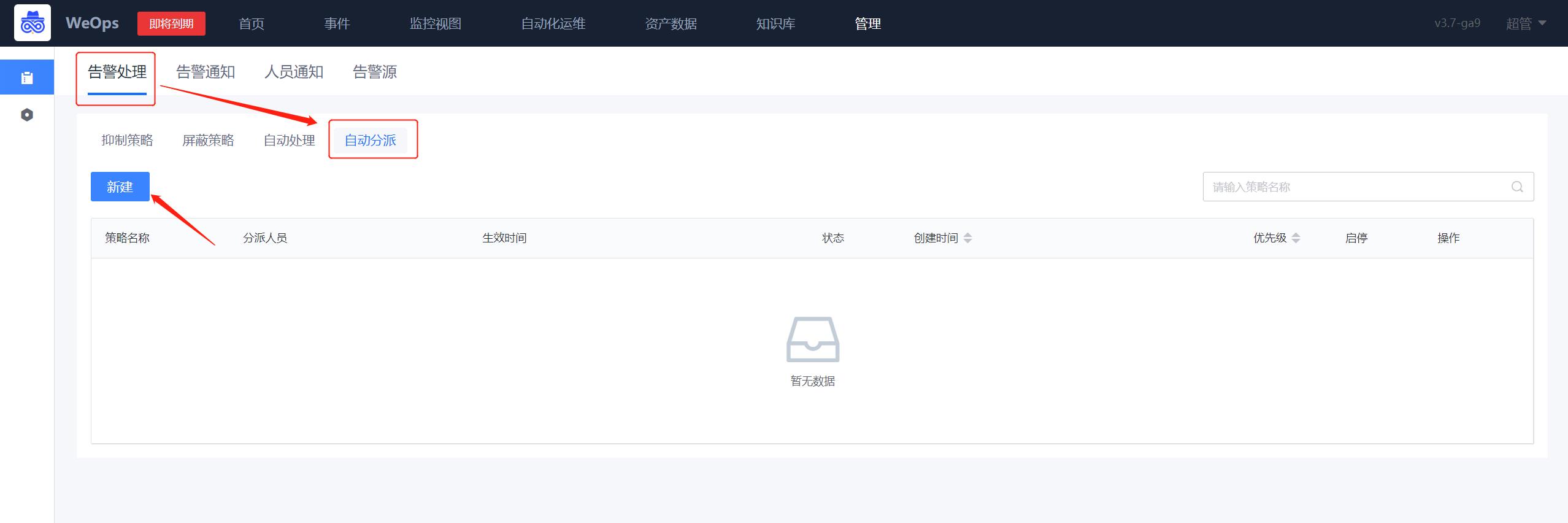
- 如下图所示,在第②步选择告警对象,若是不筛选实例则勾选【√不筛选实例】,若是需要筛选则按照第③步进行oracle主机的选择。随后按照第④步添加告警通知人员。在第⑤步选择“自定义通知方式-短信“。随后点击保存即可完成配置。

*分派策略优先级,同处理策略,优先级1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
*优先执行告警处理策略,其后再执行告警分派策略。
*支持分派升级,当告警被分派,且分派用户在设定时间内未响应,可以升级分派给其他人,支持多级升级通知。还可设置分派通知规则,当告警未响应/未关闭时,重复通知给被分派用户。
*可设置通知频率,当告警未响应/未关闭时,重复发送通知。
*当告警的触发时间与恢复时间间隔少于一分钟,我们将其视为偶发且无效的告警,并不会发送告警通知。告警转工单
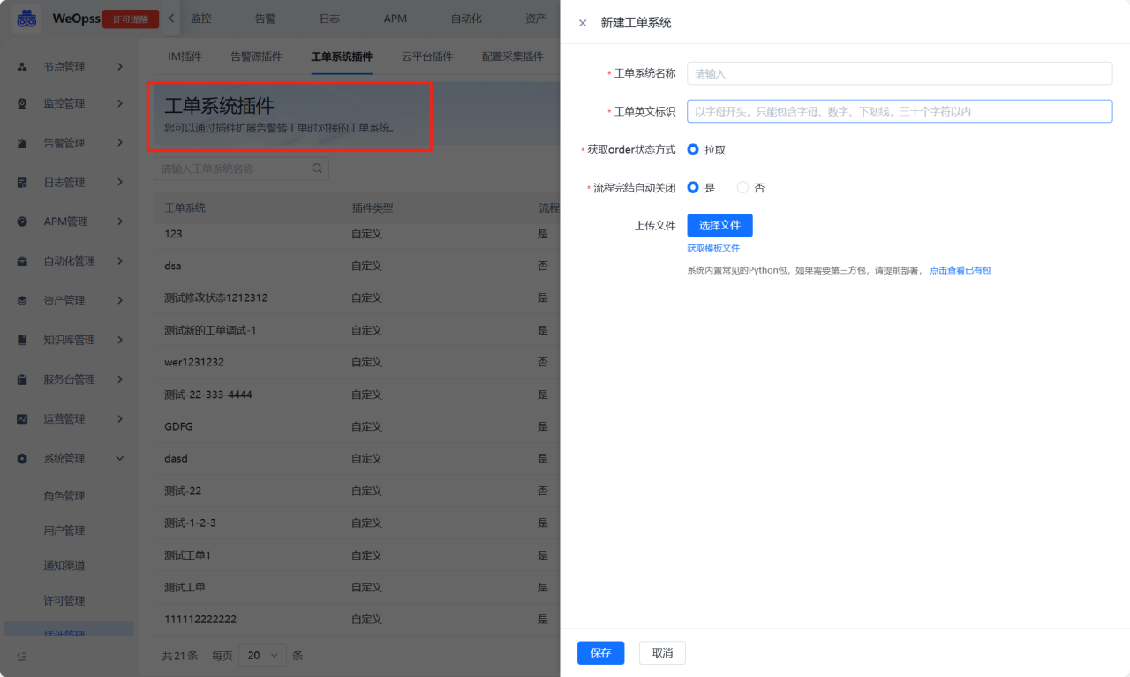
为了让告警故障处理更加规范化,可以在工单系统留存相关信息和处理方案,WeOps支持接入不同的工单系统,并支持使用该工单系统的流程服务作为告警转工单的流程。
(1)工单系统插件
支持通过插件的方式新增工单系统,以便转工单时选择
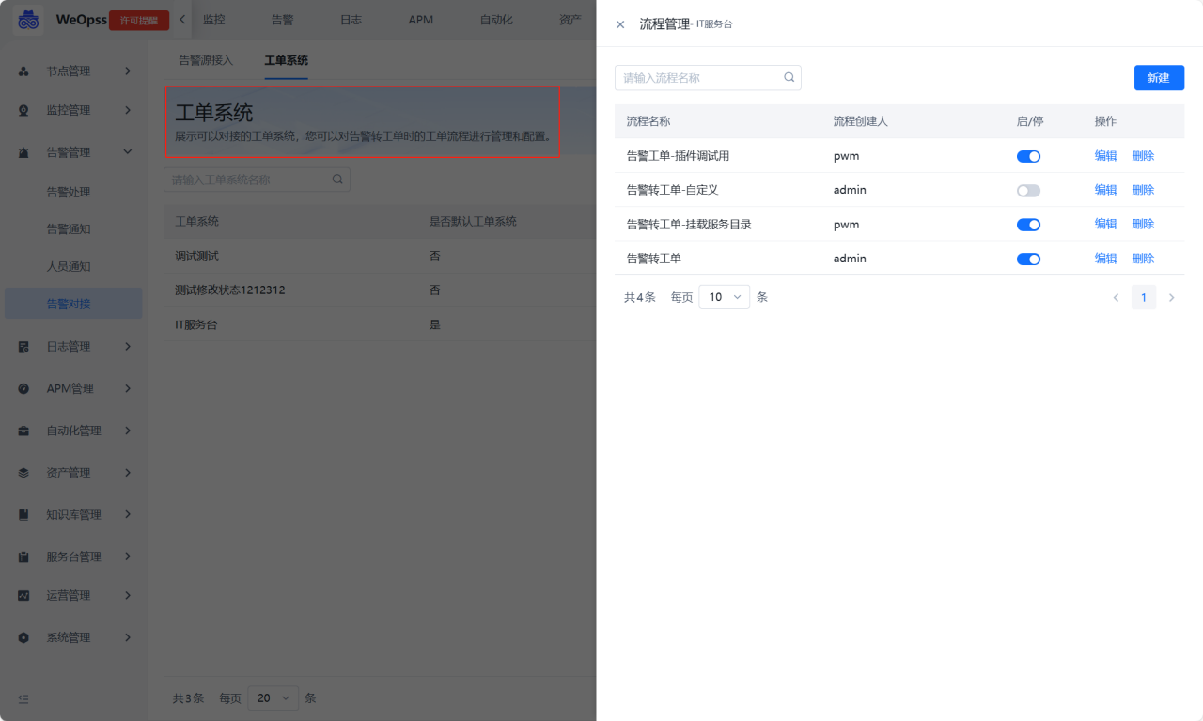
(2)系统配置
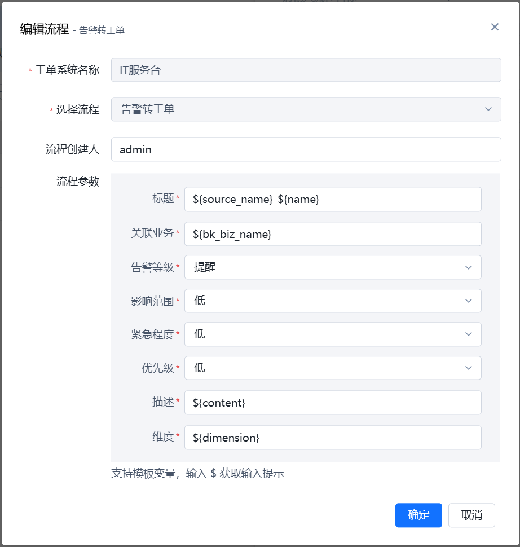
支持选择使用的工单流程,并对系统的工单选择使用。已经内置的IT服务台系统,只能选择使用“事件类”的服务。
针对各个流程服务支持定义流程的默认参数,定义好后,在手动转工单时,就不需要填写参数,可以直接使用默认参数进行调整即可。
(3)手动转工单
PC端和移动端均支持转工单,两类情况下支持手动转工单: ①状态为未分派、待响应的告警 ②状态为手动处理中,且处理人是我的告警
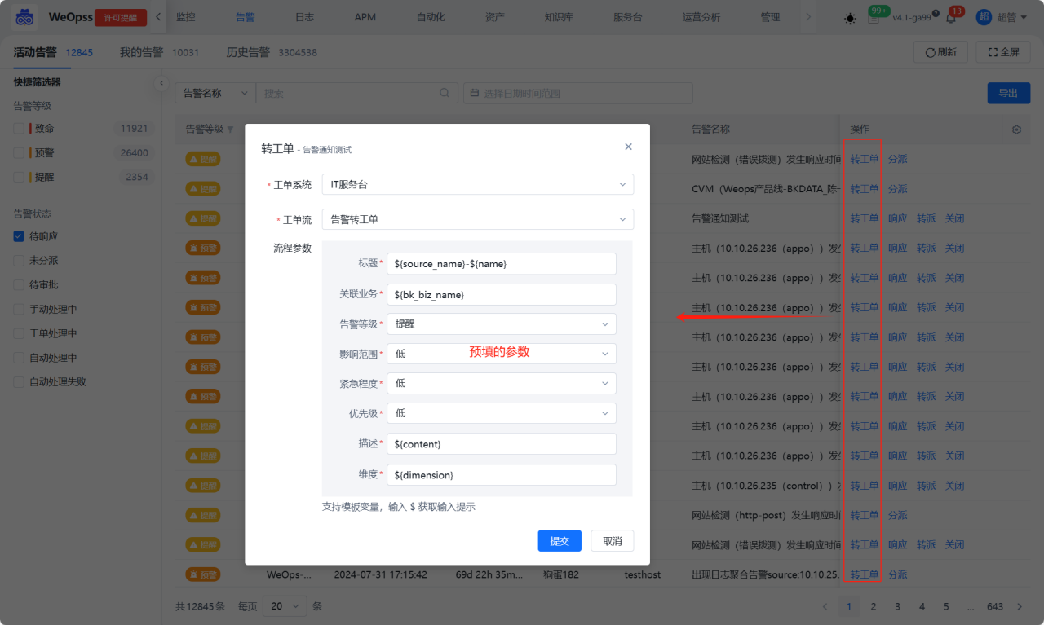
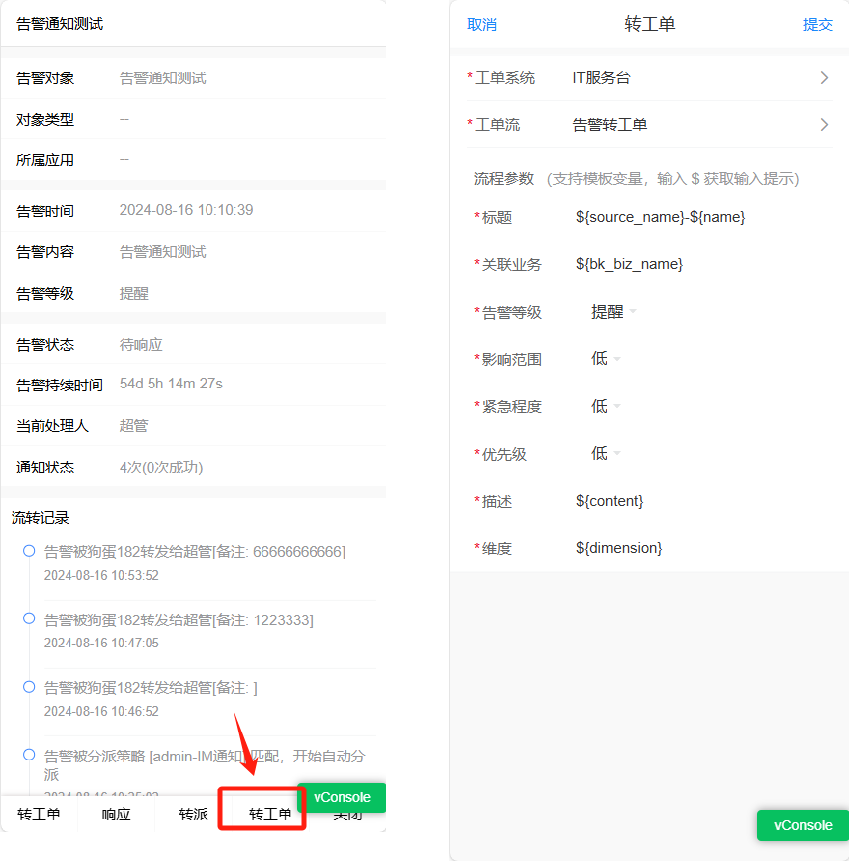
人员通知
路径:管理-告警管理-人员通知
- 如下图,进入通知配置界面,选择对应的用户,点击“配置”按钮,可以进行通知方式的配置,可选“邮件、短信、企业微信、电话”等形式


动态分组配置
背景介绍:当监控策略的监控对象经常变动的时候,可以采用动态分组的方式,设置动态分组并设置监控策略。
分组设置
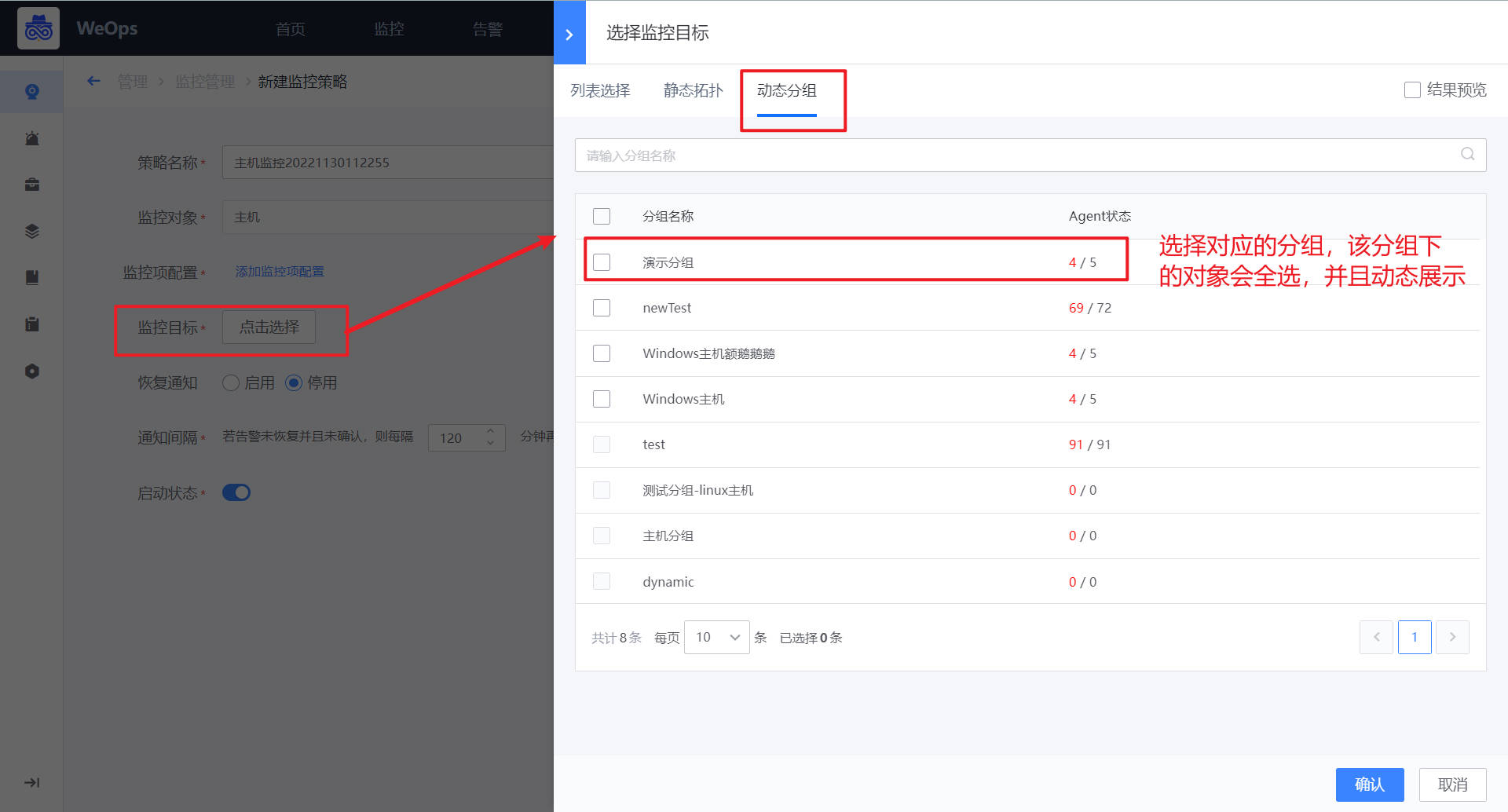
路径:管理-监控管理-动态分组
如下图,点击“新建“按钮,可以针对不同的对象,设置不同的分组条件。设置完成后,符合添加的对象会动态展示,一旦对象发生变化,该动态分组也会发生变化

分组效果
路径:管理-监控管理-监控策略
如下图,在监控策略中,选择监控目标的时候,可以选择该分组,当对象发生变化的时候,动态分组里面的对象也会对应变化,保证该监控策略始终监控的是符合条件的对象。
监控指标配置
监控指标通用配置
背景介绍:监控对象已经纳管进来,并进行监控指标采集,需要对监控指标进行管理和分组,便于在监控视图中更方便的查看各个指标视图。
指标管理设置
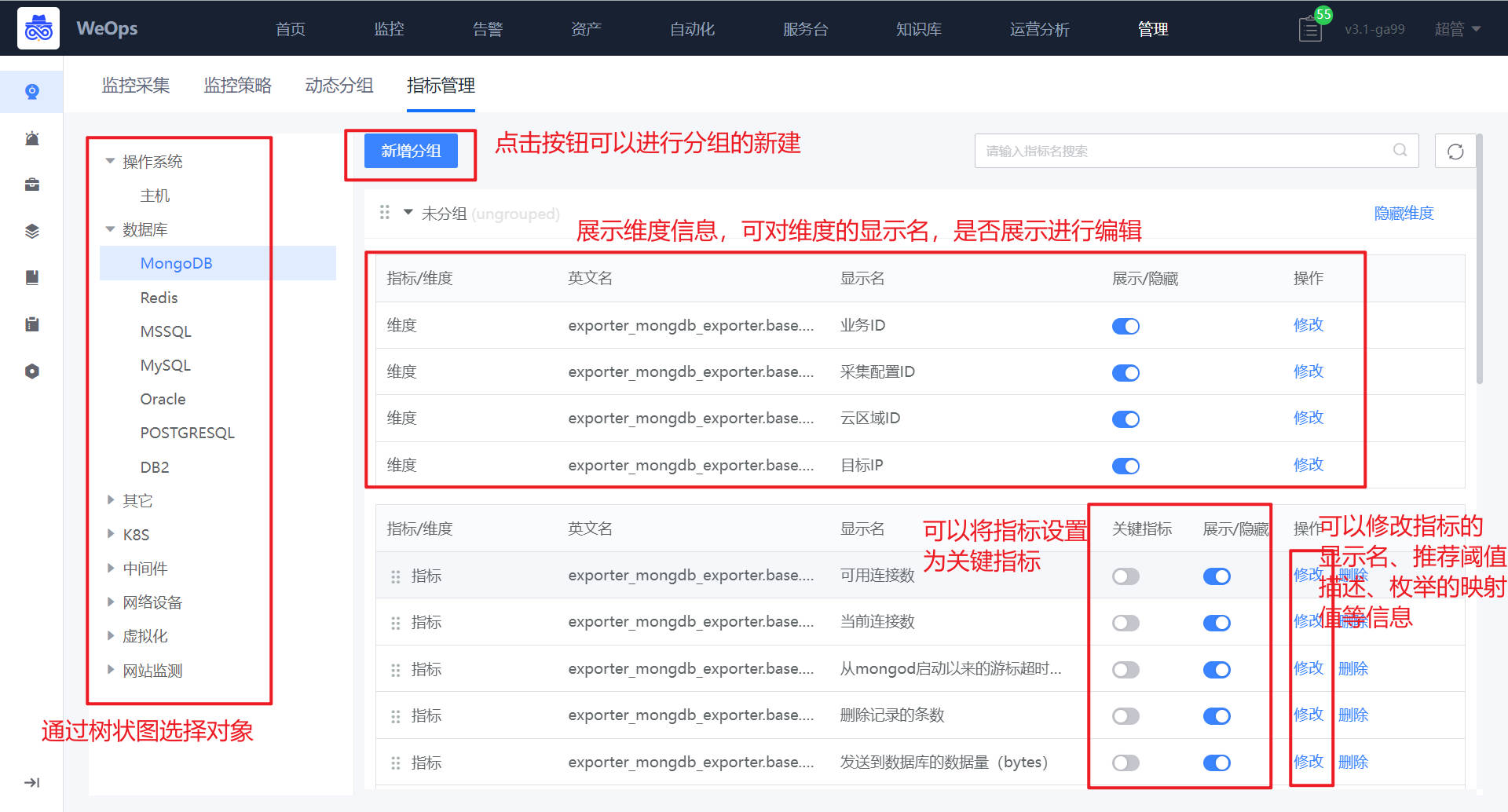
路径:管理-监控管理-指标管理
如下图可以对指标的分组、设置关键指标、指标内容等方面的设置/编辑
- 指标分组:针对不同对象可以进行指标分组新建,分组创建完成后,可以通过拖拽的方式把指标拖拽至对应分组中。
- 设置关键指标:可以将指标设置为“关键指标”,设置成功后,在监控视图的顶端就可以看到“关键指标”的分组。
- 指标编辑:支持对指标的显示名、分组、推荐阈值和描述进行编辑,可以修改指标类型,对于枚举值的指标可以设置映射值,设置成功后可以在对应的监控视图看到设置的映射值。
- 指标维度:展示对应指标的维度,可以对维度的显示名,是否显示等进行编辑
指标视图展示
路径:监控视图-应用/基础监控-主机/数据库/中间件等
如下图,指标管理配置完成后,在“监控视图-应用/基础监控”中的监控视图抽屉中,可以看到分组后的监控视图。
- 关键指标:标为关键指标的指标,在监控视图中的顶端可以看到“关键指标”的分组以及对应指标视图
- 指标分组:按照后台设置的分组情况进行展示,可进行搜索和条件筛选等操作
自定义监控插件(脚本插件)
背景介绍:脚本的是一种灵活和快速的监控采集方式,不同层的监控对象都可以用本来完成。只要目标对象能够提供对应的脚本运行环境,就有对应的命令或脚本方法能够获取相应的指标数据; 此类型插件由于是调用已经封装好的命令,导致性能较低,采集耗时和资源占用多。
支持的脚本有:
Linux:Shell,Python
Windows:Shell,Python,PowerShell
脚本(Script)适用的对象有:操作系统、数据库、中间件
Step1:自定义插件制作
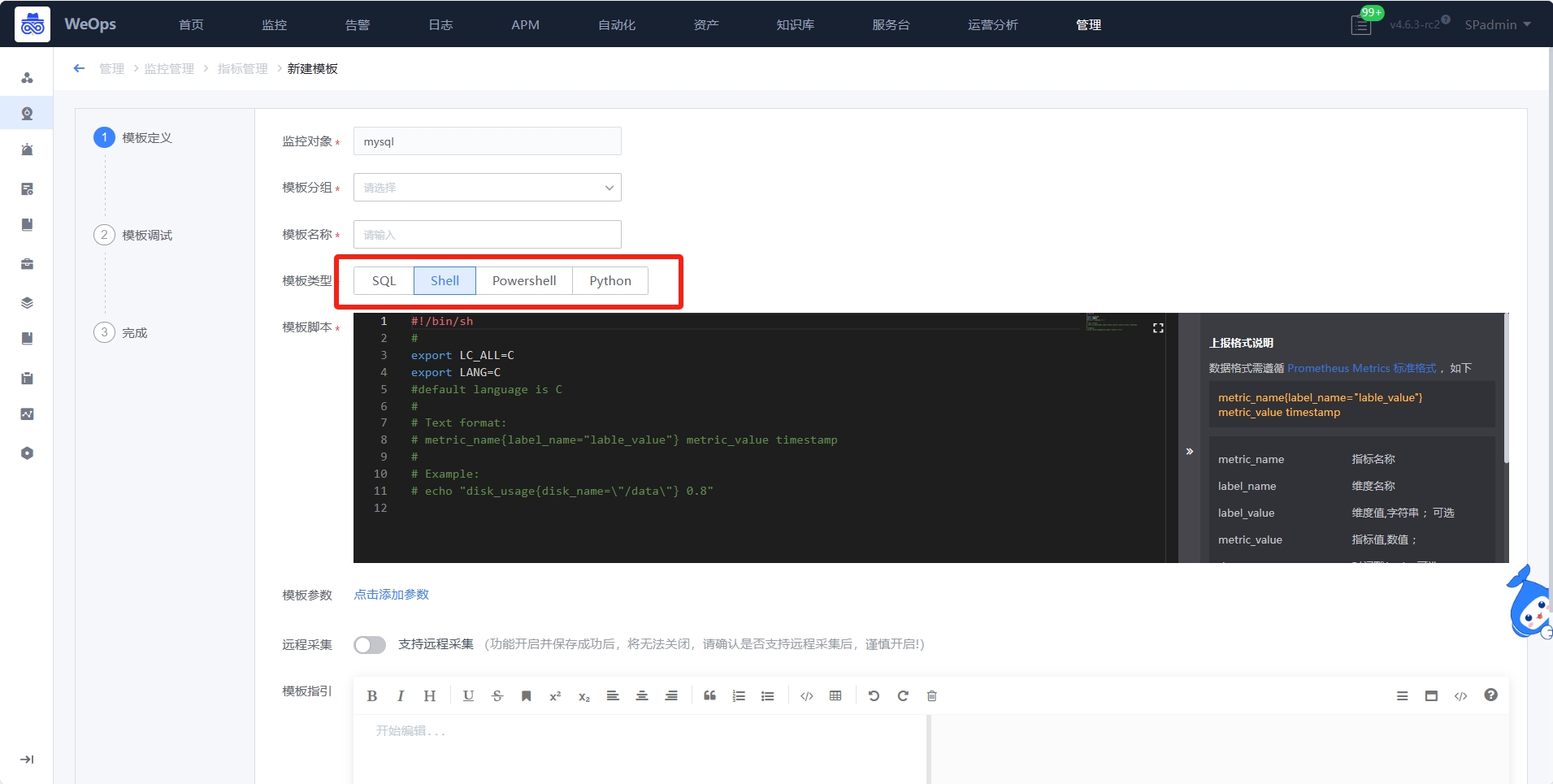
路径:管理-监控管理-监控指标-新建模板
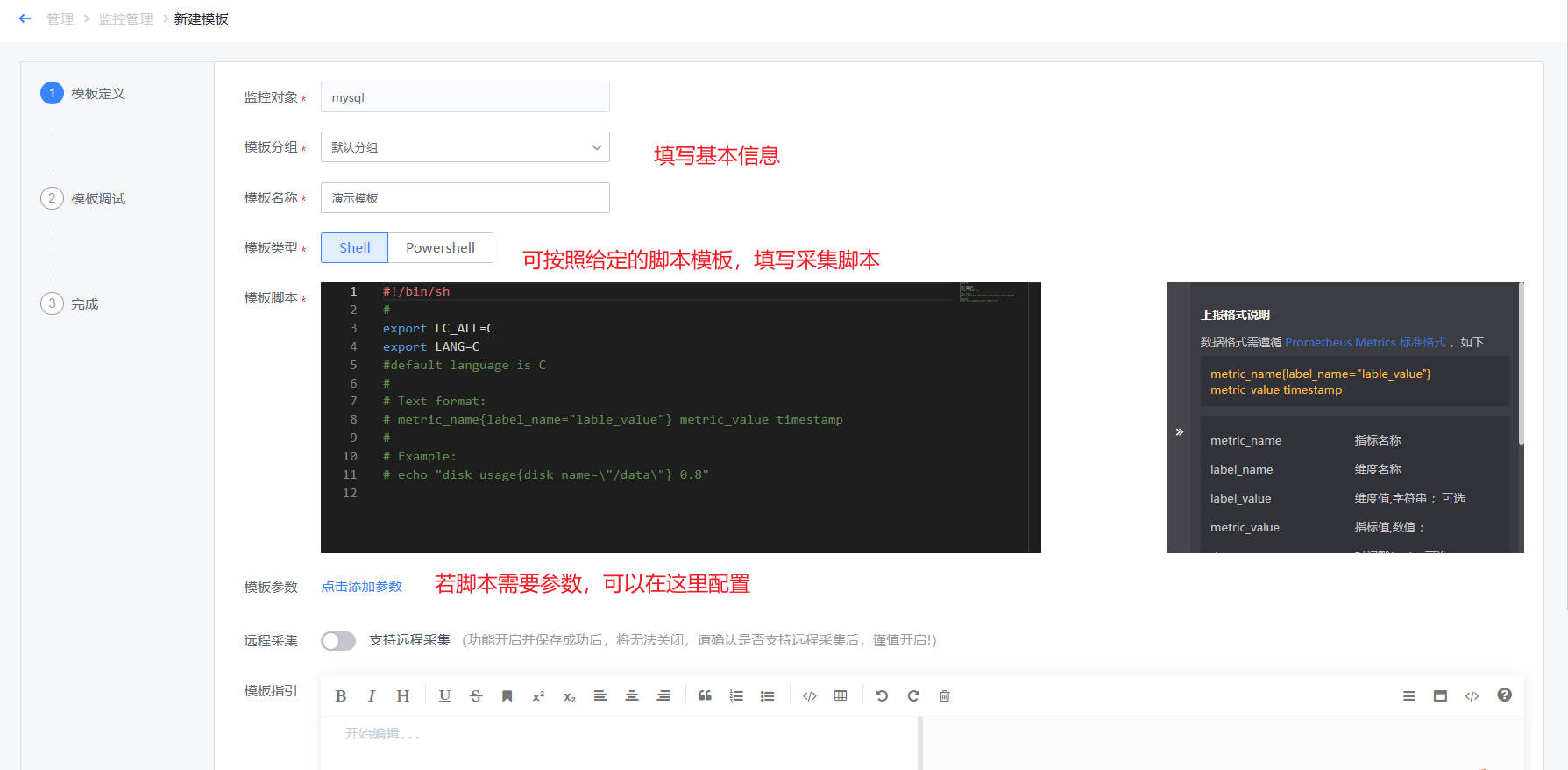
如下图,点击“新建模板”,进入到插件定义页面,脚本插件的制作分为三步:插件定义、插件调试、编辑指标和维度等信息
- 第一步,插件定义:如下图,需要填写插件基本信息、脚本内容、参数信息等。若需要定义监控采集时需要的参数,可以点击新增参数,并在脚本中用$1、$2来确定位置参数
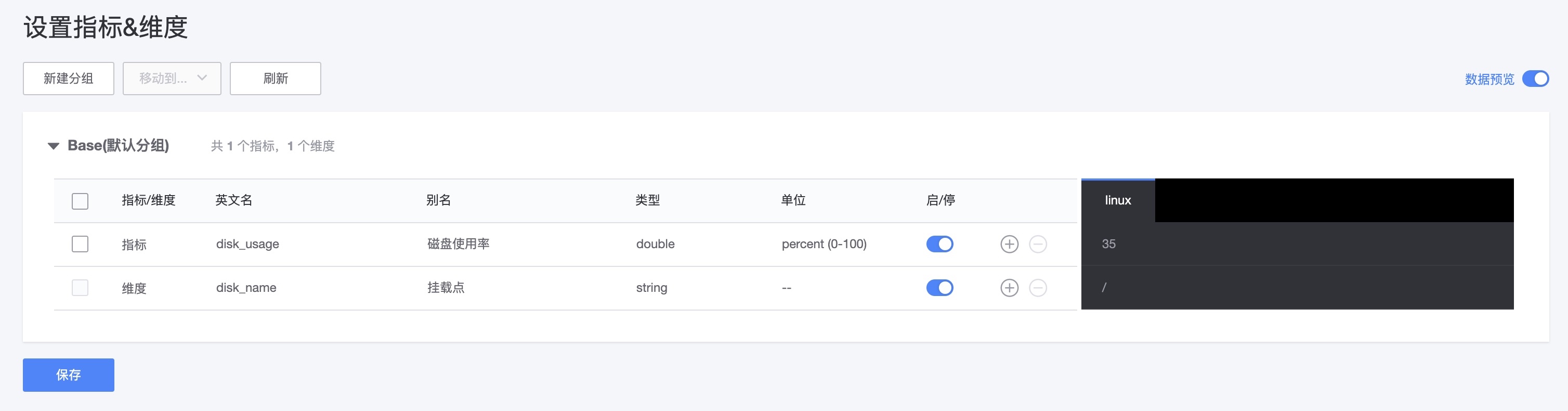
接下来以 磁盘使用率为例 为例实现脚本采集以及指标监控,脚本内容可参考如下脚本格式
#!/bin/bash
#获取磁盘使用率
disk_name="$1"
diskUsage=`df -h | grep ${disk_name} | awk -F '[ %]+' '{print $5}'`
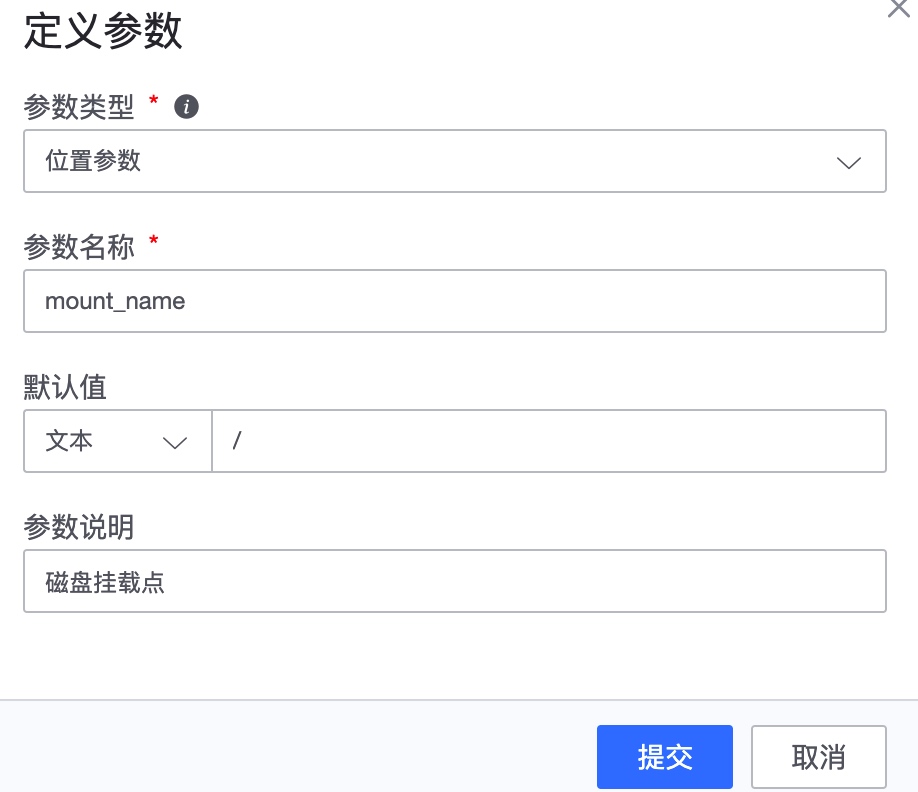
echo "disk_usage{disk_name=\"${disk_name}\"} ${diskUsage}"- 脚本参数,脚本中使用到的参数以$1、$2等来确定位置参数,并填写在参数定义中,以便后续下发时填写。
- 输出格式
echo "disk_usage{disk_name=\"${disk_name}\"} ${diskUsage}"●指标名:disk_usage 是一个自定义的指标名称,表示磁盘使用率。
●维度 :{disk_name=\”${disk_name}\”} 是一个维度部分,用于进一步描述或区分指标。包含一个键值对:disk_name 是标签的键。\”${disk_name}\” 是值,表示传入的磁盘名称。注意,这里使用了反斜杠 \ 来转义双引号,使得双引号作为字符串的一部分被保留下来。
●指标值 :${diskUsage} 是实际的指标值,即磁盘的使用率。它是通过前面的命令(df -h | grep ${disk_name} | awk -F ‘[ %]+’ ‘{print $5}’)提取出来的。
执行结果示例如下
disk_usage{disk_name="/dev/sda1"} 75%- 第二步,进行调试,这里的服务和下发都是测试联调的。填写的内容在后面的监控采集配置是一样的,主要就是为了验证插件制作是否合理,结果是否如预期。
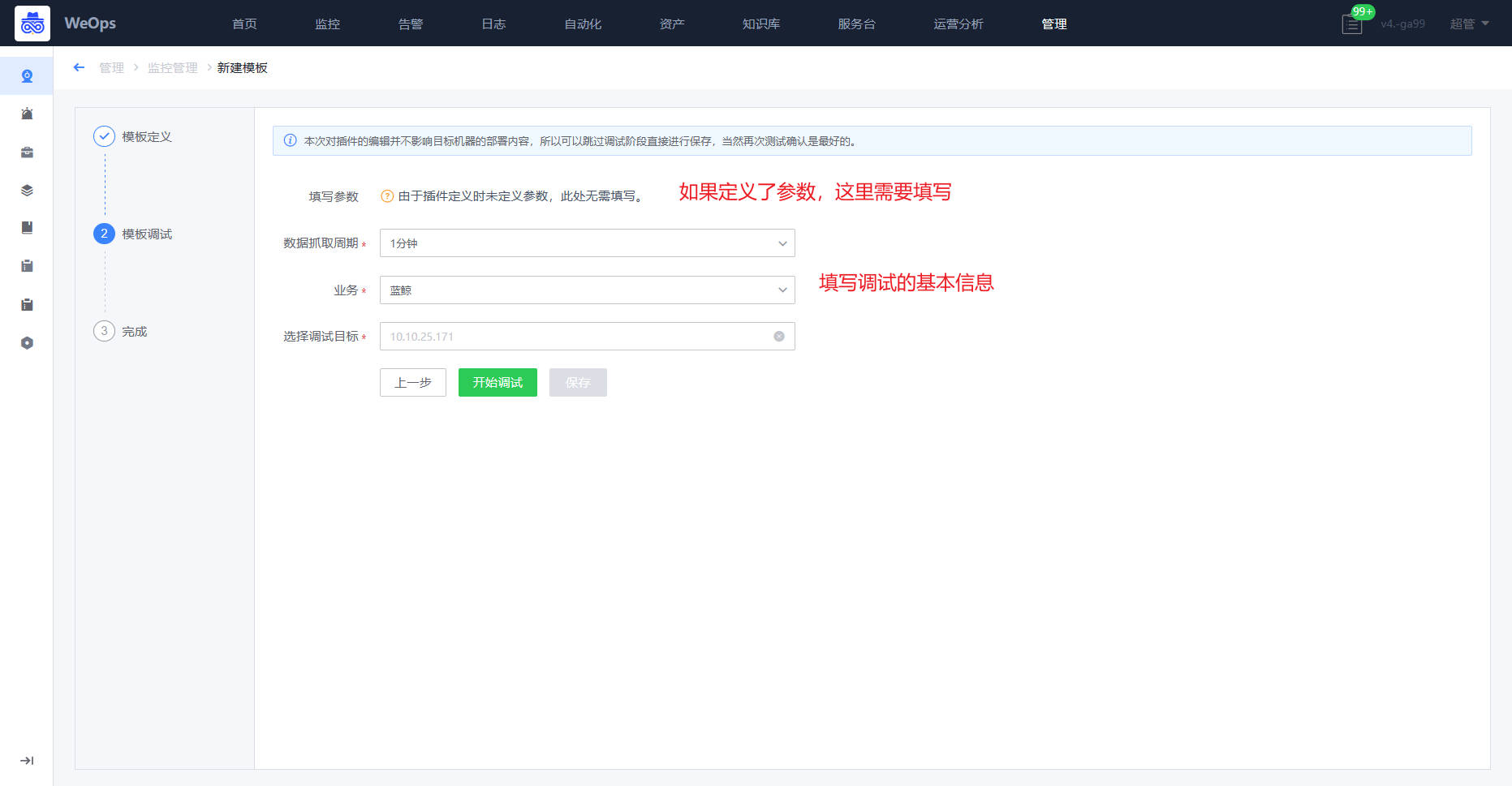
- 注意:整个调试过程超时时间为 600 秒,如果 600 秒内没有保存就会关闭这个调试过程,保证服务器上不会有残留的调试进程。
- 当联调获取到数据后会进行指标维度的设置确认。
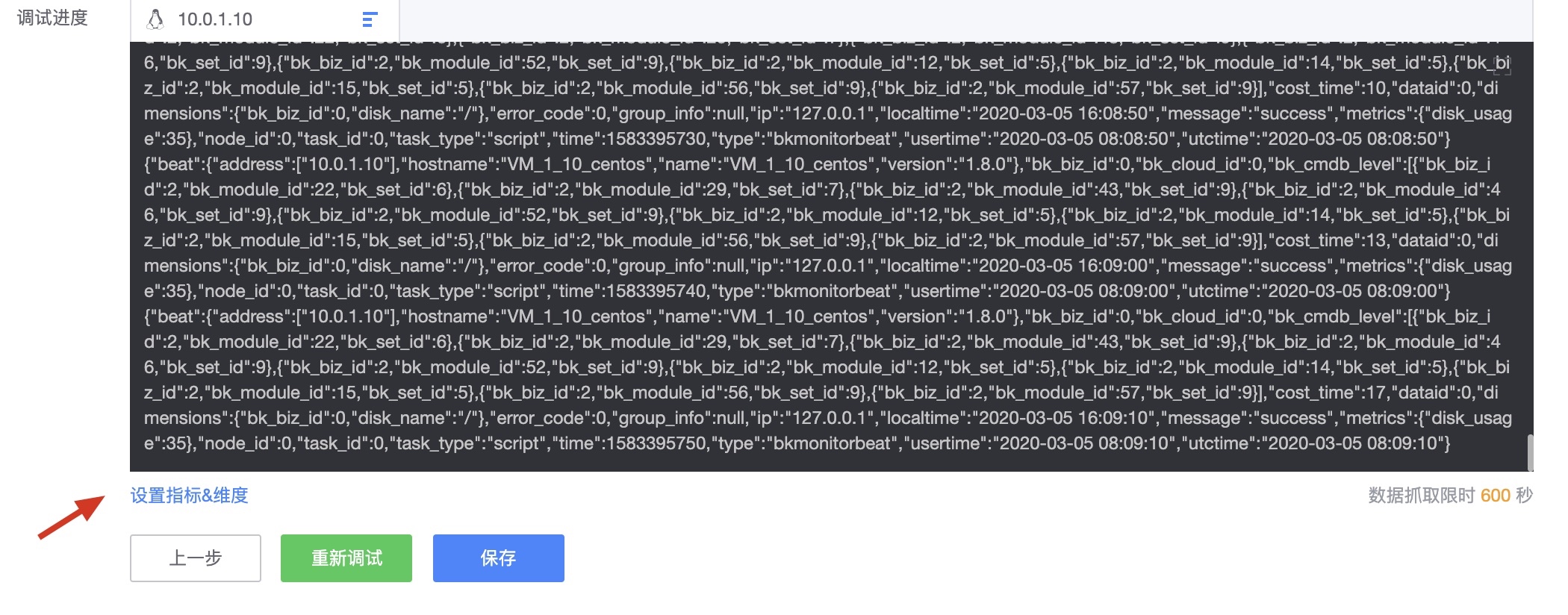
- 确认联调结果并设置指标和维度,WeOps可识别脚本中的指标和维度,可以进行编辑和设置,比如设置中文名称等。此外,支持数据预览,方便的看到调试获取的数据值是否符合预期
- 第三步,保存插件。后续可在监控采集中使用该监控插件进行采集
Step2:设置监控采集
路径:管理-监控管理-监控采集
自定义插件制作完成后,可以在“监控采集”中对监控目标进行监控插件的下发和采集。
Step3:设置监控数据呈现
路径:监控视图-仪表盘/基础监控
监控采集设置完成后,和内置的监控插件一样,监控数据就可以上报,在监控视图、仪表盘可以展示出该插件采集上来的数据。
自定义监控插件(JMX插件)
背景介绍:可以采集任何开启了JMX服务端口的Java进程的服务状态,通过JMX采集Java进程的JVM信息;使用前提目标对象能够支持远程JMX协议连接,配置JMX远程支持需要重启中间件。 适用于所有的Java类型中间件软件的监控,无需开发,仅需提供配置信息;
step1:开启 JMX 远程访问功能
java 默认自带的了 JMX RMI 的连接器。所以,只需要在启动 java 程序的时候带上运行参数,就可以开启 Agent 的 RMI 协议的连接器。
- 对于自研 java 程序,例如 java 程序为 app.jar,其启动命令为:
java -jar app.jar - 对于第三方组件:各个组件的远程 JMX 开启方式,请参考各组件文档。
- 检查是否启动成功
客户端可以通过以下 URL 去远程访问 JMX 服务。其中,hostName 为目标服务的主机名/IP,portNum 为以上配置的 jmxremote.port。
service:jmx:rmi:///jndi/rmi://${hostName}:${portNum}/jmxrmi
可通过以下两种方式检查是否已经配置成功:
1.简单地可通过检查端口是否存在,以及 PID 是否匹配,来确认 JMX 远程访问是否已经成功启动
netstat -anpt | grep ${portNum}
2.如果安装了 JConsole,也可直接连接测试
Step1:自定义插件制作
路径:管理-监控管理-监控指标-新建模板
如下图,点击“新建模板”,进入到插件定义页面,脚本插件的制作分为三步:插件定义、插件调试、编辑指标和维度等信息
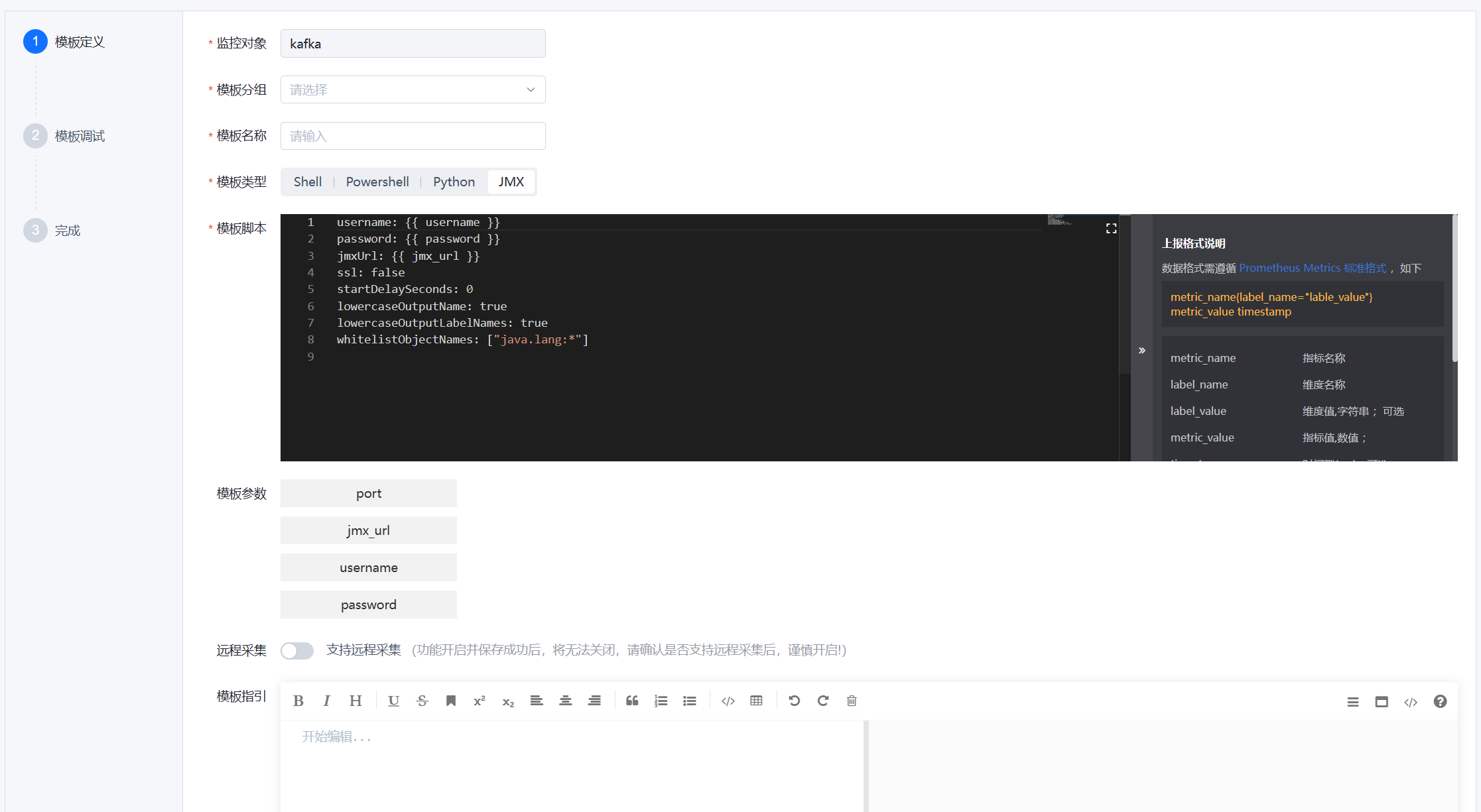
- 第一步,模板定义,填写对应采集配置,可参考以下示例:
# ==== 固定配置开始 ====
username:
password:
jmxUrl:
ssl: false
# ==== 固定配置结束 ====
# ==== 自定义配置开始 ====
startDelaySeconds: 0
lowercaseOutputName: false
lowercaseOutputLabelNames: false
whitelistObjectNames: ["Catalina:*", "java.lang:*"]
blacklistObjectNames: ["Catalina:j2eeType=Servlet,*"]
rules:
- pattern: 'Catalina<type=ThreadPool, name="(\w+-\w+)-(\d+)"><>(currentThreadCount|currentThreadsBusy|keepAliveCount|pollerThreadCount|connectionCount):(.*)'
name: tomcat_threadpool_$3
value: $4
valueFactor: 1
labels:
port: "$2"
protocol: "$1"
自定义配置结束 - 固定配置都必须严格包含以下属性。否则将无法正确地进行指标采集。
username:
password:
jmxUrl:
ssl: false- 自定义配置的字段的说明如下
| 字段名 | 含义 |
|---|---|
| startDelaySeconds | 启动延迟。延迟期内的任何请求都将返回空指标 |
| lowercaseOutputName | 小写输出指标名称。适用于 name。默认为 false |
| lowercaseOutputLabelNames | 小写输出指标的标签名称。适用于 labels。默认为 false |
| whitelistObjectNames | 要查询的 ObjectNames 列表。默认为所有 mBeans |
| blacklistObjectNames | 要查询的 ObjectNames 列表。优先级高于 whitelistObjectNames。默认为 none |
| rules | 要按顺序应用的规则列表,在第一个匹配到的规则处停止处理。不收集不匹配的属性。如果未指定,则默认以默认格式收集所有内容 |
| pattern | 用正则表达式模式匹配每个 bean 属性。匹配值(用小括号标识一个匹配值)可被其他选项引用,引用方式为$n(表示第 n 个匹配值)。默认为匹配所有内容 |
| name | 指标名称。可以引用来自 pattern 的匹配值。如果未指定,将使用默认格式:domainbeanPropertyValue1_key1_key2…keyN_attrName |
| value | 指标的值。可以使用静态值或引用来自 pattern 的匹配值。如果未指定,将使用 mBean 值 |
| valueFactor | 用于将指标的值 value 乘以该设置值,主要用于将 mBean 值从毫秒转换为秒。默认为 1 |
| labels | 标签名称到标签值的映射。可以引用来自 pattern 的匹配值。使用该参数必须先设置 name。如果使用了 name 但未指定该值,则不会输出任何标签 |
- 定义参数,JMX 插件不支持自定义参数,均为固定参数,各固定参数含义如下:
监听端口:JMX Exporter 启动时监听的 HTTP 端口,注意不是 JMX 端口
连接字符串:JMX RMI 的 URL,格式为 service:jmx:rmi:///jndi/rmi://${hostName}:${portNum}/jmxrmi。hostName 为目标服务的主机 IP,portNum 为 JMX 监听的端口号。将替换采集配置中的
用户名:若开启了用户认证,则需要输入,否则置空。将替换采集配置中的
密码:若开启了用户认证,则需要输入,否则置空。将替换采集配置中的 - 第二步,模板调试
填写相关参数,然后点击“开始调试”,稍等片刻后可查看调试输出。
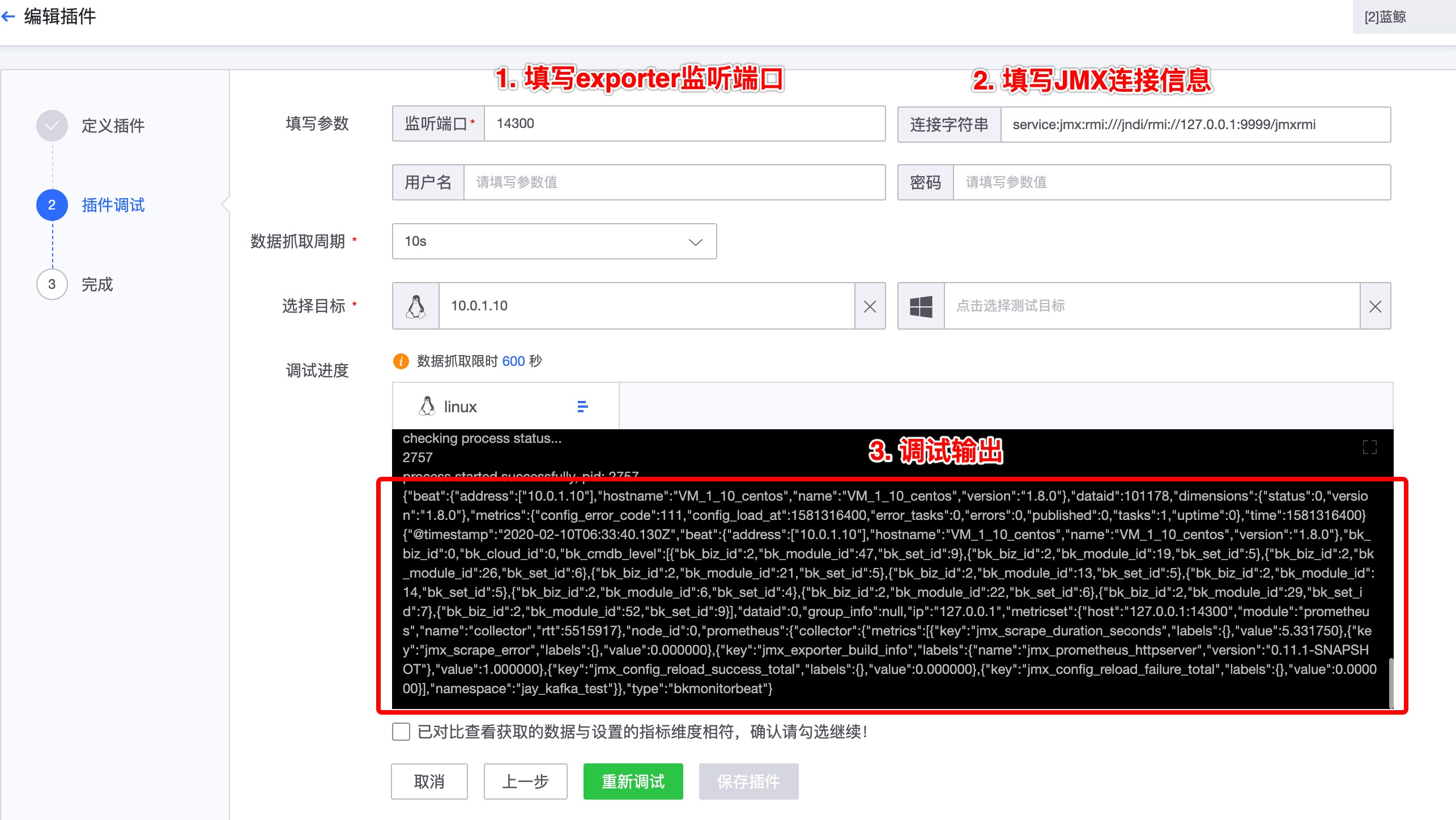
指标维度,在插件调试获取到结果后,根据实际需要定义指标和维度。
- 第三步,保存插件,调试并确认数据上报正常后,可进入下一步进行保存。自此,一个 JMX 插件即制作完成。
Step2:设置监控采集
路径:管理-监控管理-监控采集
自定义插件制作完成后,可以在“监控采集”中对监控目标进行监控插件的下发和采集。
Step3:设置监控数据呈现
路径:监控视图-仪表盘/基础监控
监控采集设置完成后,和内置的监控插件一样,监控数据就可以上报,在监控视图、仪表盘可以展示出该插件采集上来的数据。
自定义监控插件(snmp插件)
背景介绍:SNMP是一个被业界广泛接受的,用于监测网络设备(计算机、路由器)甚至其他设备(例如UPS)的网络协议,属于应用层协议。
使用前提:用户具备可用的MIB库和被监控设备的oid值,用于生成采集监控模板。OID:设备通用的SNMP标识,格式是一段数字如1.3.6.1,使用snmp协议并通过oid访问 设备,即可获取对应oid下的设备信息,如启动时间等。MIB库:各设备官方提供的 设备oid描述文件,可以根据该文件得到能够用于监控的oid以及oid的内容描述信息
SNMP模板的适用对象:网络设备、硬件设备
1:导入SNMP指标模板
路径:管理-监控管理-指标管理
如下图,在指标管理中,选择网络设备-交换机,点击导入模板,可以进行不同品牌和型号的指标模板导入(WeOps提供了网络设备指标模板导入的入口,可监控的设备品牌、型号等支持拓展。可直接使用WeOps产研提供的文件进行导入拓展)
2:创建SNMP指标模板
路径:管理-监控管理-指标管理
点击进行snmp模板的新建,对于snmp模板可以进行对应指标的新增,便于后续使用。
具体说明如下
(1)指标型:指标型指标是通过设备的OID(对象标识符)来采集设备的实际数值。所以当某个指标可以找到对应oid进行数据采集时,可以创建指标型指标进行采集。
(2)计算型:对指标型指标的数值进行计算得到的指标。计算型指标可以用于更细粒度地监控设备性能,在计算型指标的公式中,需要引用现有指标,可以采用(指标英文名{template_id})的格式进行引用,公式中固定变量“template_id”为指标所在的模板ID,固定不变。比如“irate(ifOutOctets{template_id}[5m])”。
Step2:监控采集
当需要监控的网络设备已经纳管,并且有适用的监控指标模板(可以是内置的,也可以是导入创建的),可以对网络设备进行监控采集的创建,选择对应的目标,适用的指标模板,并填写凭据信息。
如下图,监控采集创建完成以后,可以在监控视图中,查看对应监控对象的监控信息
Step3:监控策略配置(以交换机为例)
- 网络设备监控采集新建完成以后,可以网络设备进行监控策略的配置。
- 如下图,进入到监控策略页面,选择网络设备-交换机,点击“新建”按钮
- 在新建界面,策略名称、和监控对象已经默认填写。点击“选择监控目标”,进行监控对象的选择点击“添加监控项配置”,可进行监控项的选择和配置
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
日志配置
日志数据接入(syslog协议)
背景介绍:公司有许多的设备,这些运维设备/系统的日志比较分散,存储和搜索等不方便,可以统一接入WeOps的日志管理中,进行统一存储,统一查询、统一使用。
整体步骤:交换机配置——日志接入——日志展示
Step1:交换机配置
- 开通交换机和日志服务器的相关策略,包括开通端口和协议。(注意:使用syslog协议进行日志收集,需要开通【网络设备→日志服务器】的UDP协议,端口为514。)
- 使用以下命令对交换机进行配置,配置传输日志的级别,使用的VLAN和日志服务器。
info-center source default channel 7 log level warning
info-center loghost source Vlanif30
info-center loghost 10.10.xx.xx
Info-center enable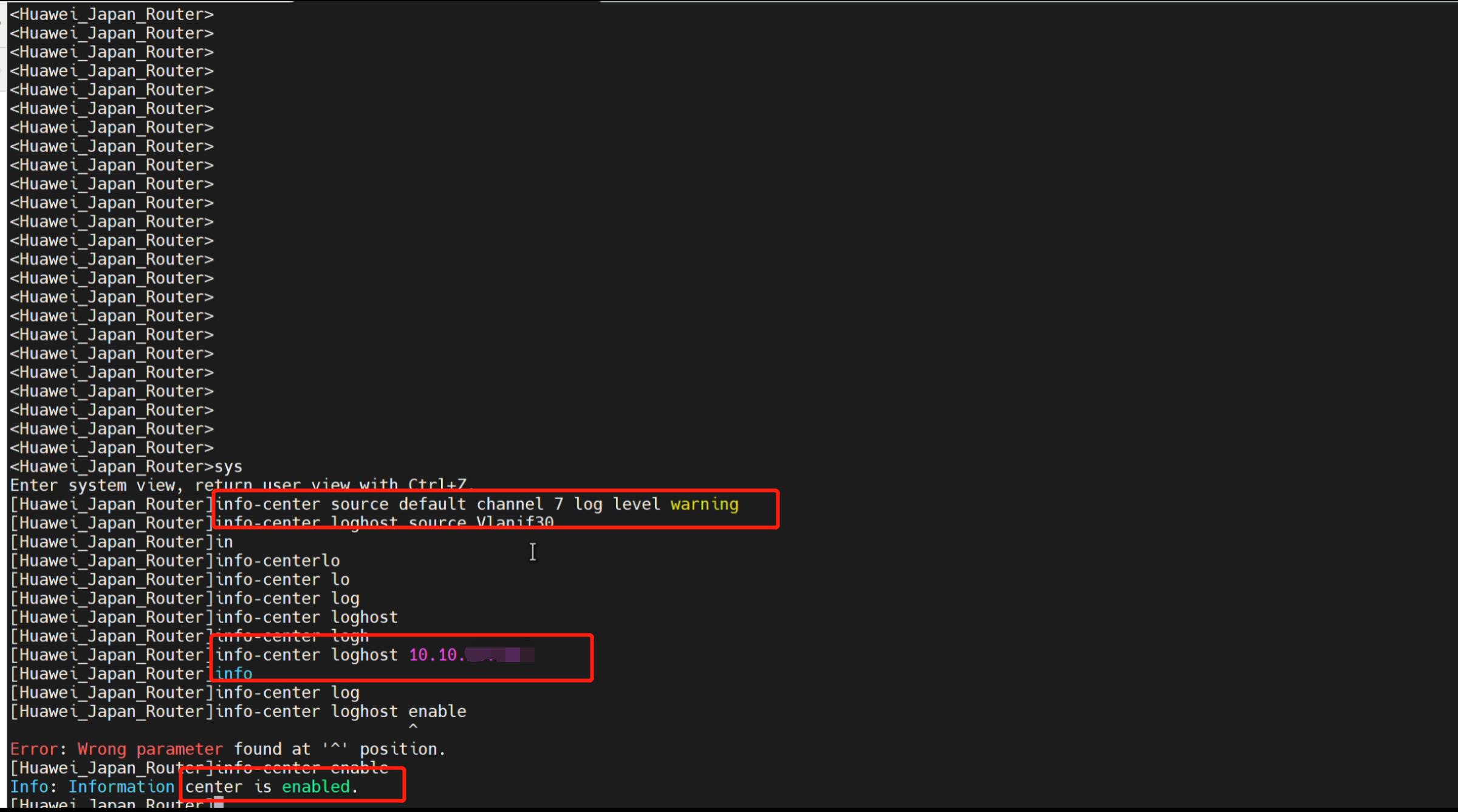
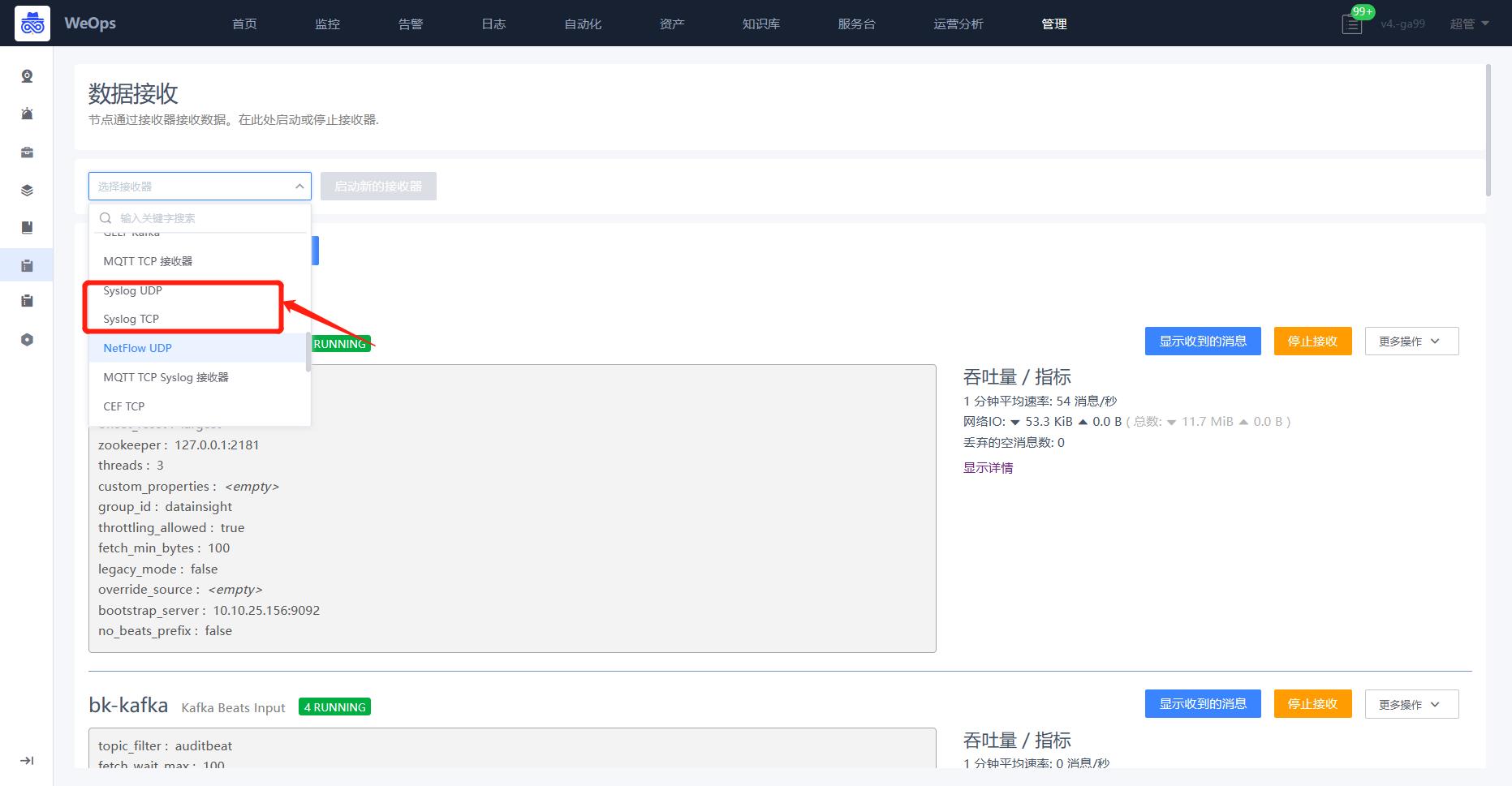
Step2:日志接入
路径:管理-日志管理-数据接收
- 交换机配置完成后,如下图,在WeOps中进行日志的接入,选择syslog UDP/TCP(适用于网络设备和安全设备的日志接入),填写相关信息,注意协议和端口要和第一步开通的策略一致。
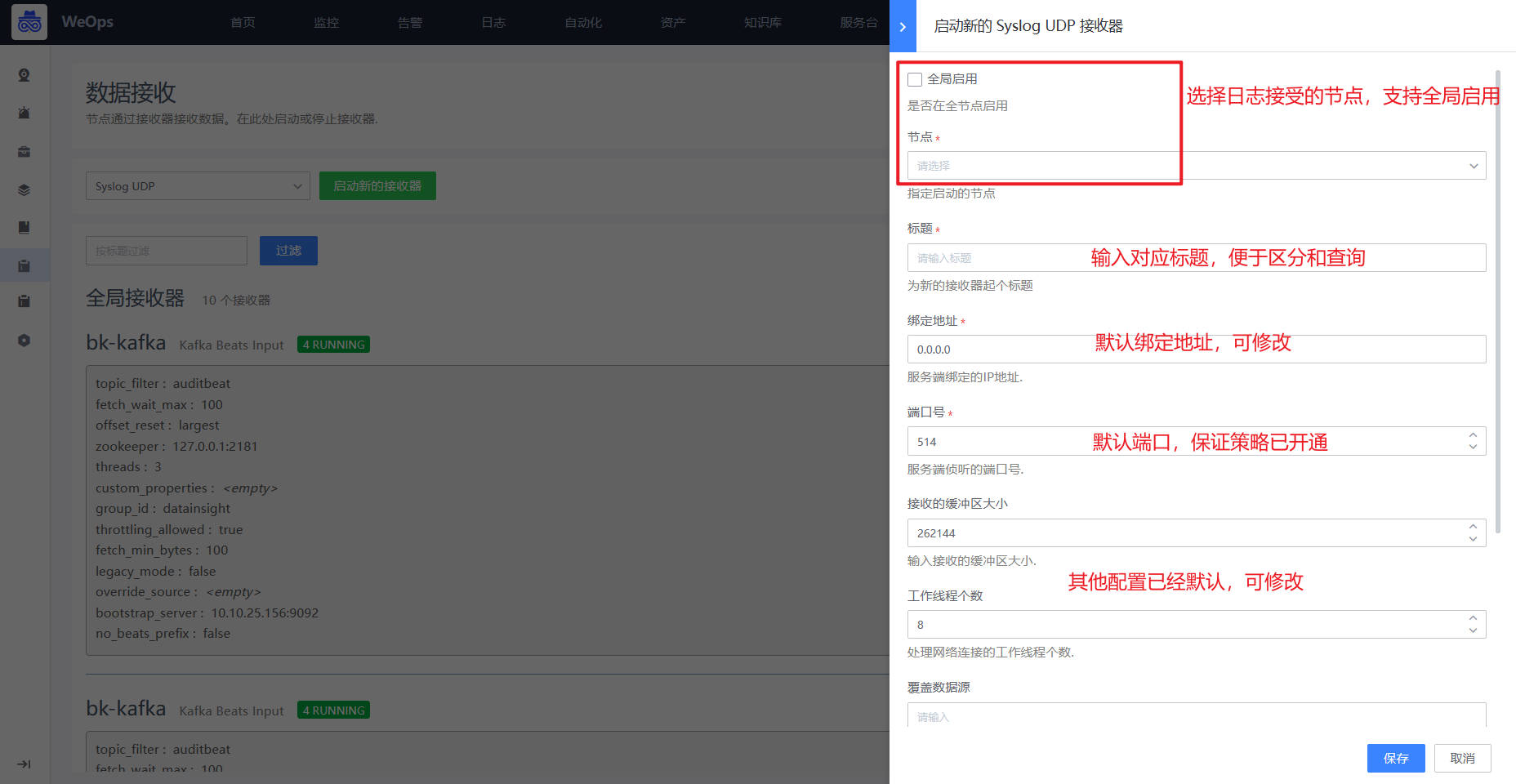
设置完成之后,符合该协议该端口下的所有设备的日志信息会通过该接收器被WeOps的日志管理接收,可以查看日志接收的速率等情况。
Step3:日志展示
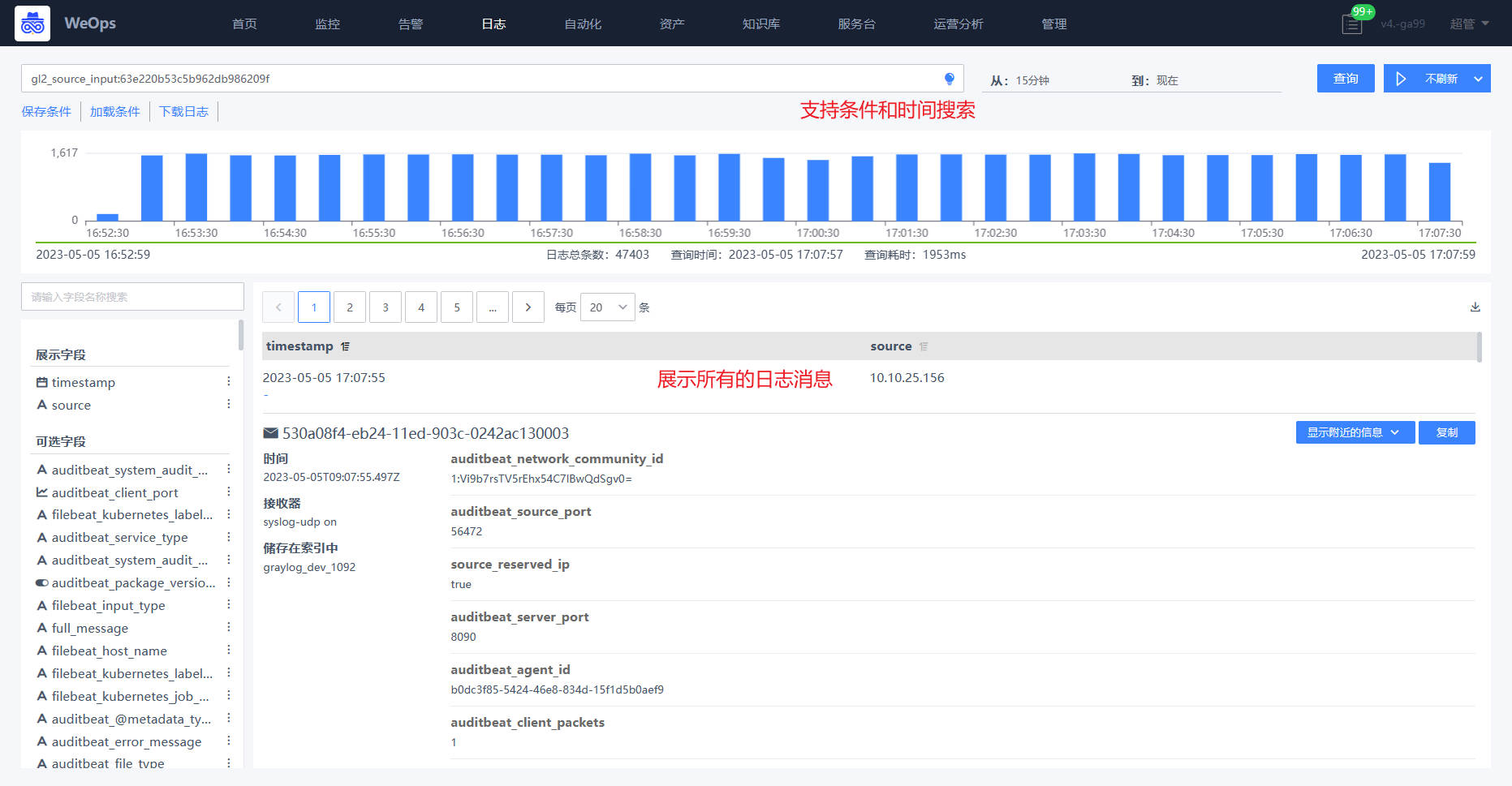
路径:日志
日志数据接收完成之后,可以在“日志”中查看这个接收器的日志情况,支持进行搜索。
日志数据接入(探针模式)
背景介绍:公司需要接入一批日志数据,需要通过安装探针的方式进行采集,可以使用WeOps-日志探针安装和下发模块进行。对于探针的安装支持agent和无agent两种模式
(1) agent模式(自动安装)
整体步骤:主机安装agent——安装控制器——安装探针——创建配置文件——安装探针、关联配置文件进行下发。
Step1:前提条件,开通对应网络策略,主机安装agent
- 使用探针的方式进行日志数据的接入,需要开通对应的网络策略,需要开通的策略具体如下。
| 源 | 目标 | 协议 | 端口 | 用途 |
|---|---|---|---|---|
| 采集服务器 | 日志服务器 | tcp | 9000 | 配置同步 |
| 采集服务器 | 采集kafka | tcp | 9092 | 数据传输 |
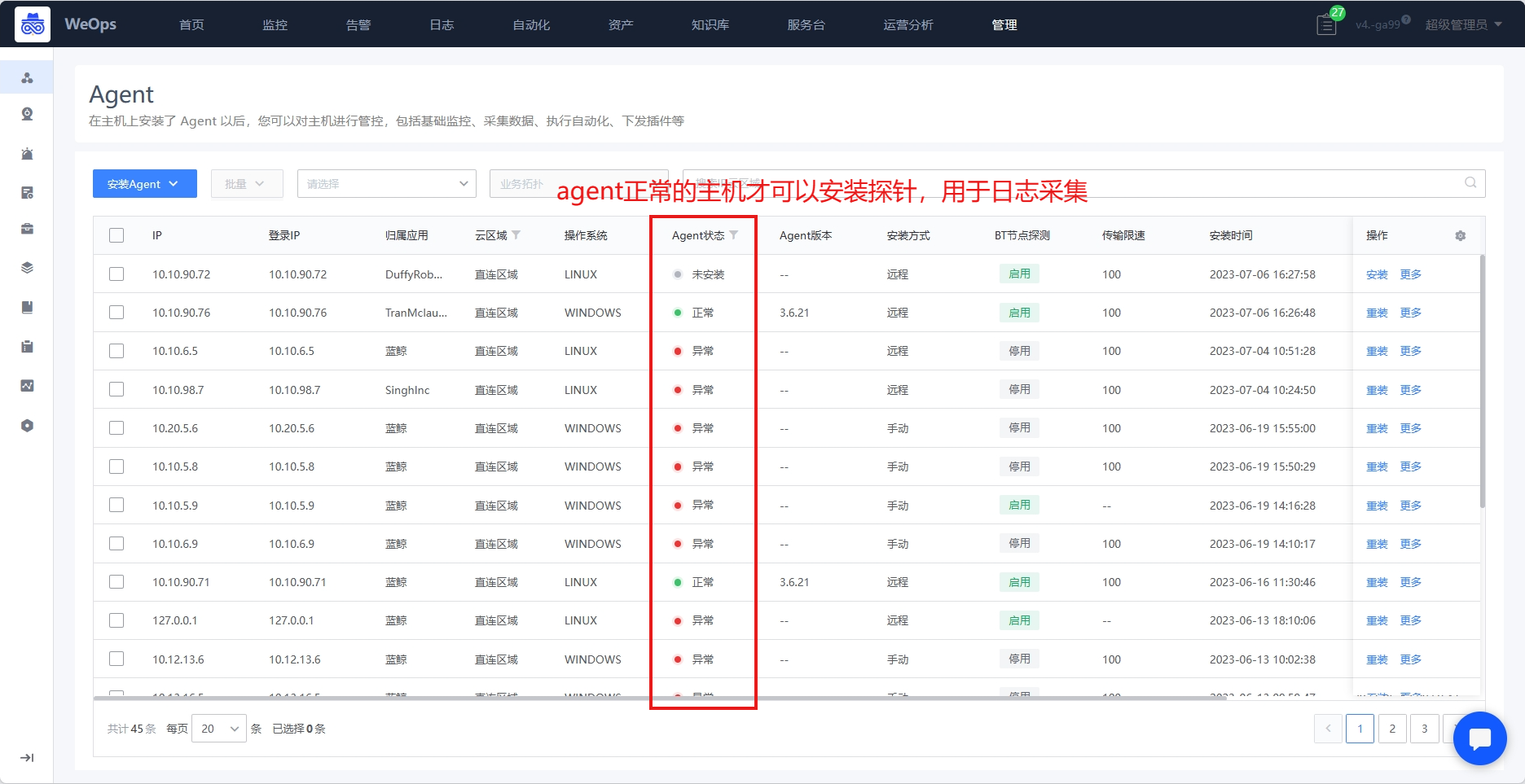
路径:管理-节点管理-Agent
- 使用的主机已经安装了agent,具体安装方法可见《操作手册-资源纳管-主机纳管》
Step2:安装控制器
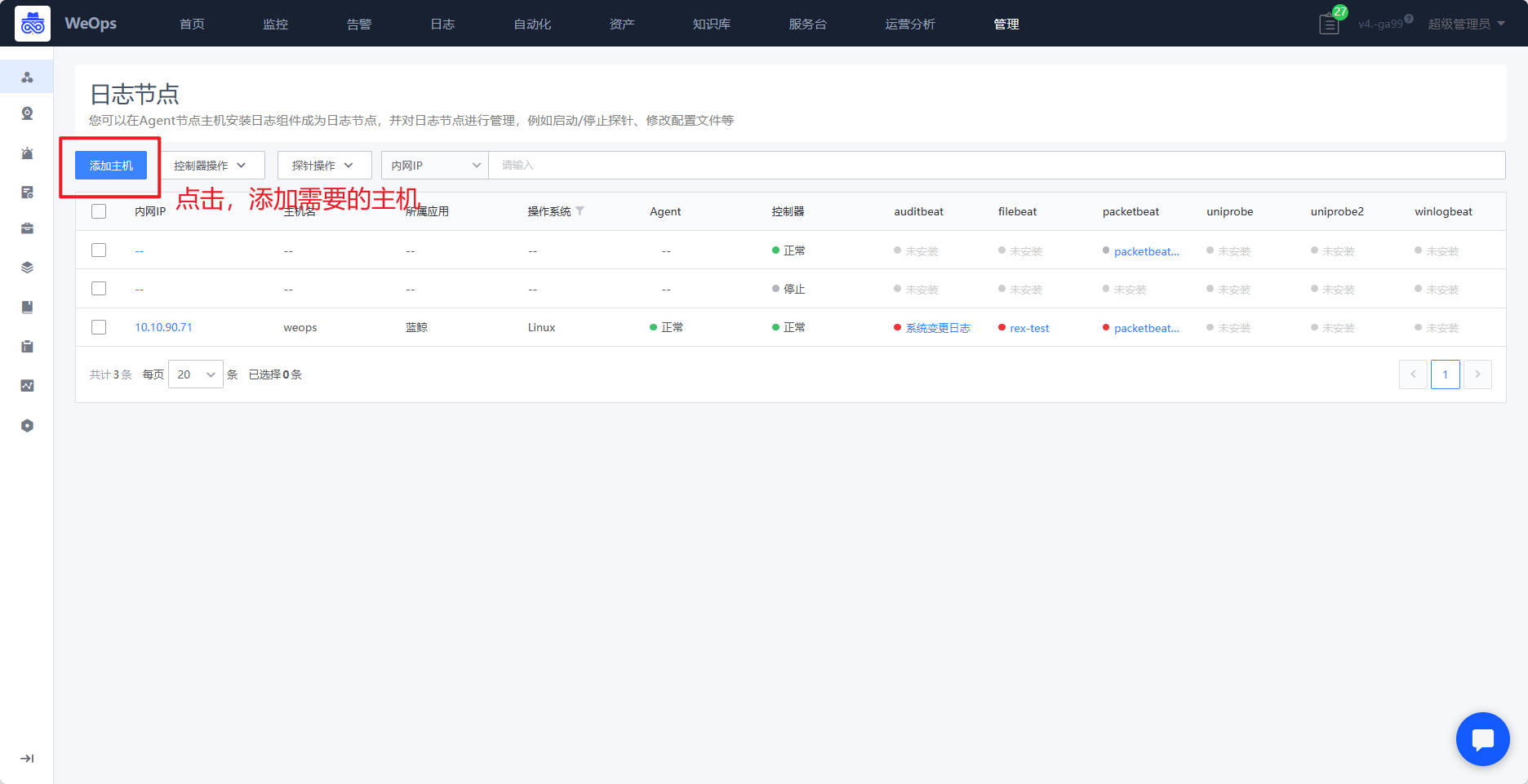
路径:管理-节点管理-日志节点
- 对需要使用到的服务器,安装控制器,控制器的作用是控制探针的一些操作,所以安装探针之前需要对服务台安装控制器
- 如下图,进入日志节点页面,点击“添加主机按钮”选择需要安装控制器的主机,加入到列表后,同时进行控制器的安装,控制器的状态为“正常”可进行下一步。
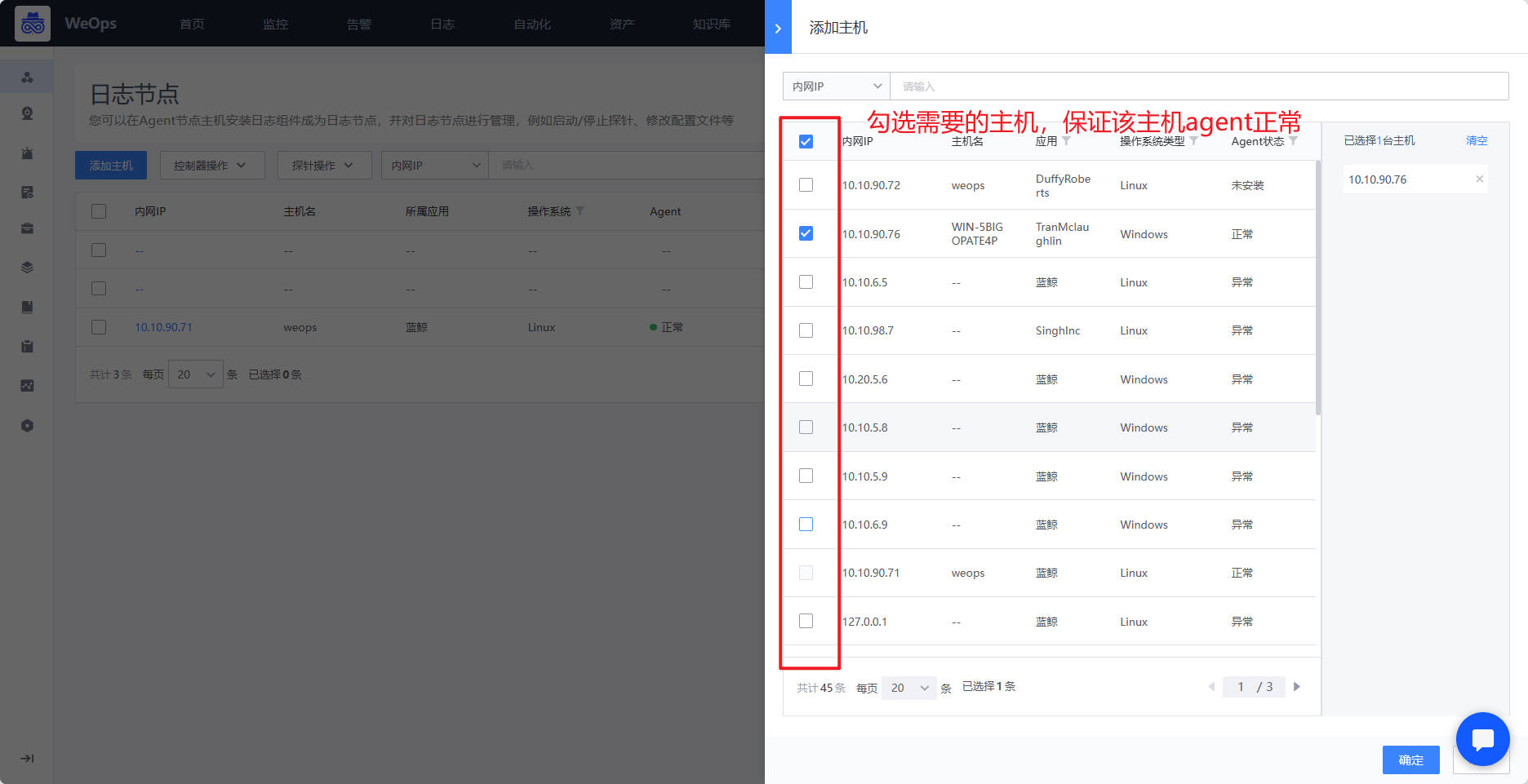
Step3:安装探针
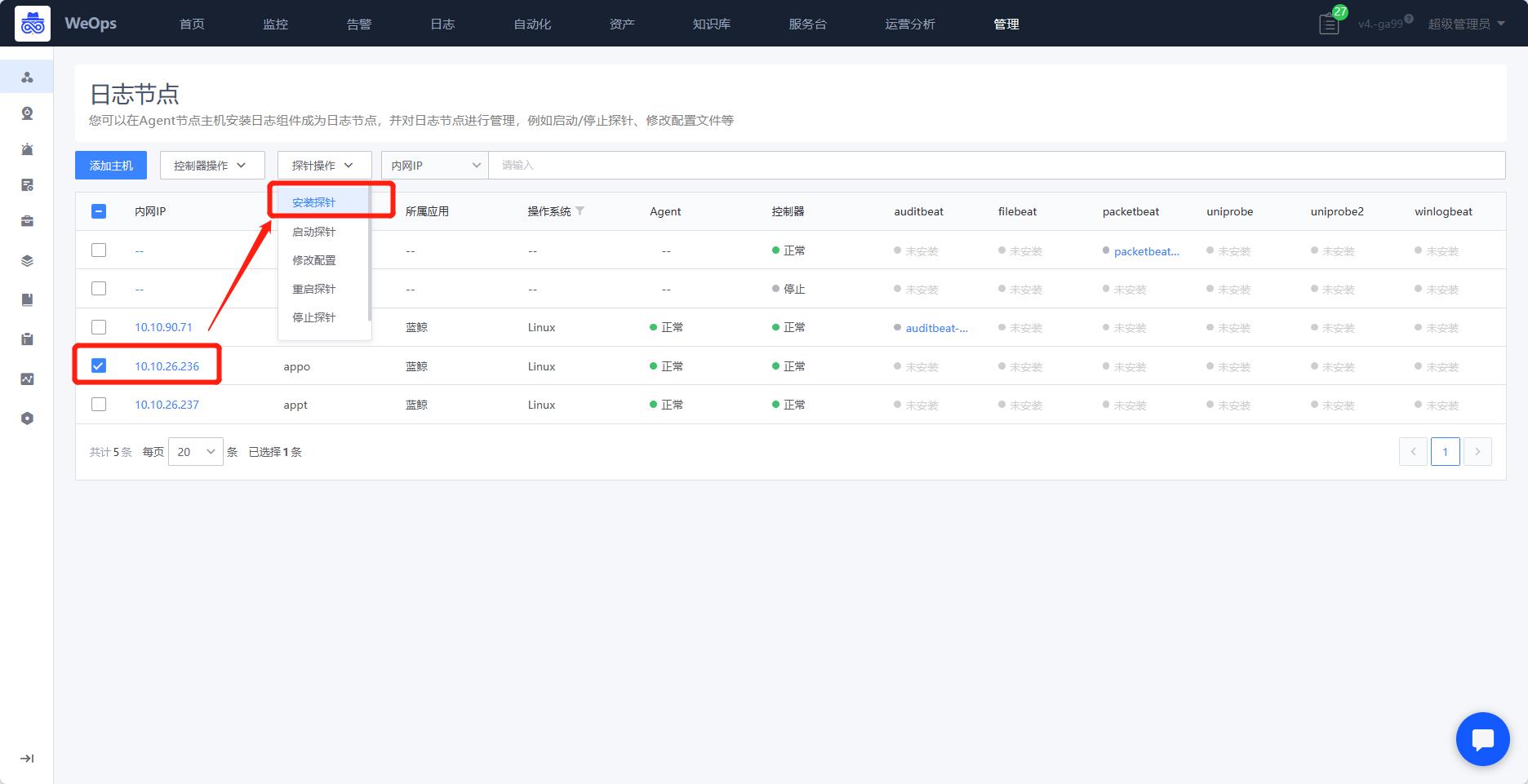
路径:管理-节点管理-日志节点
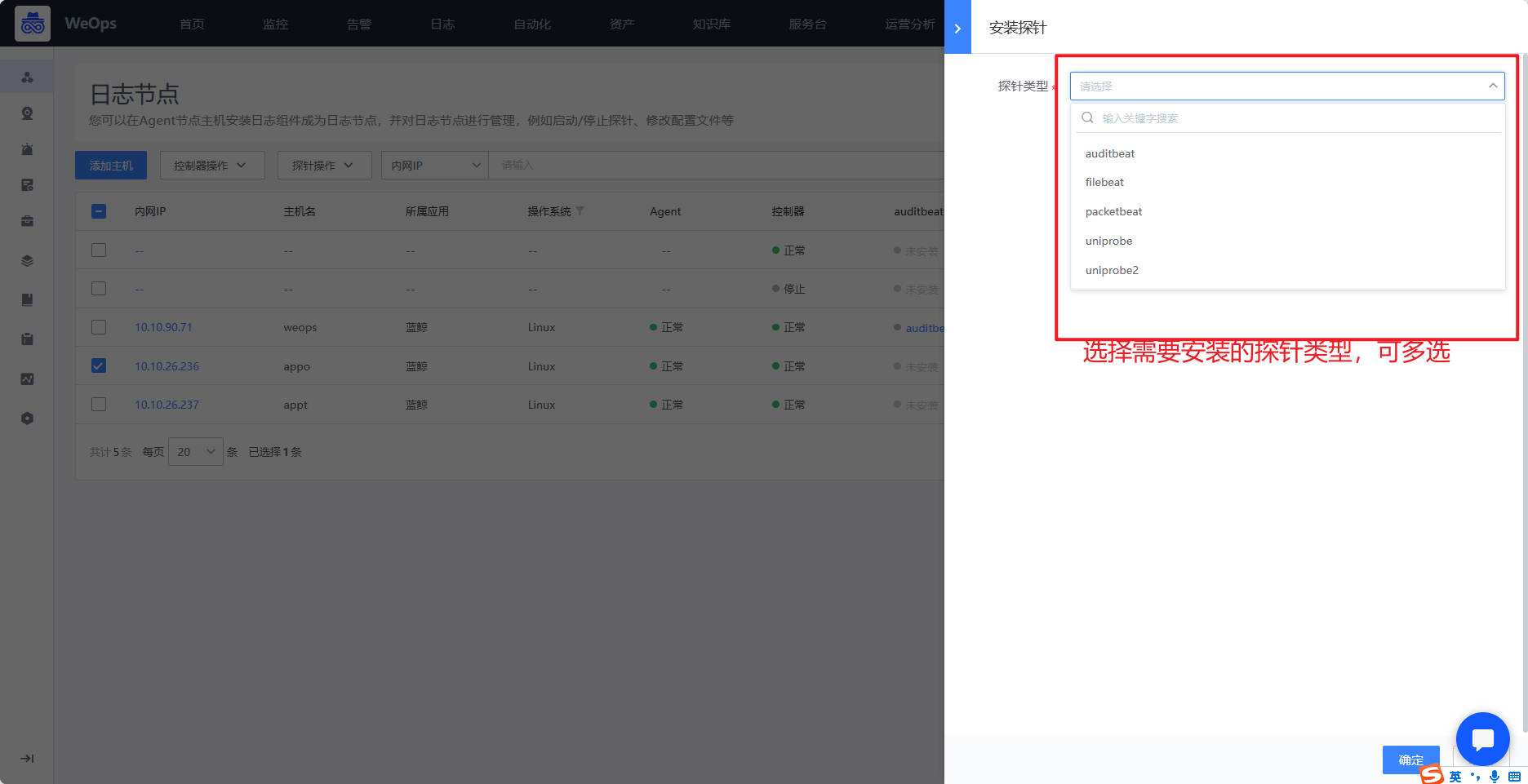
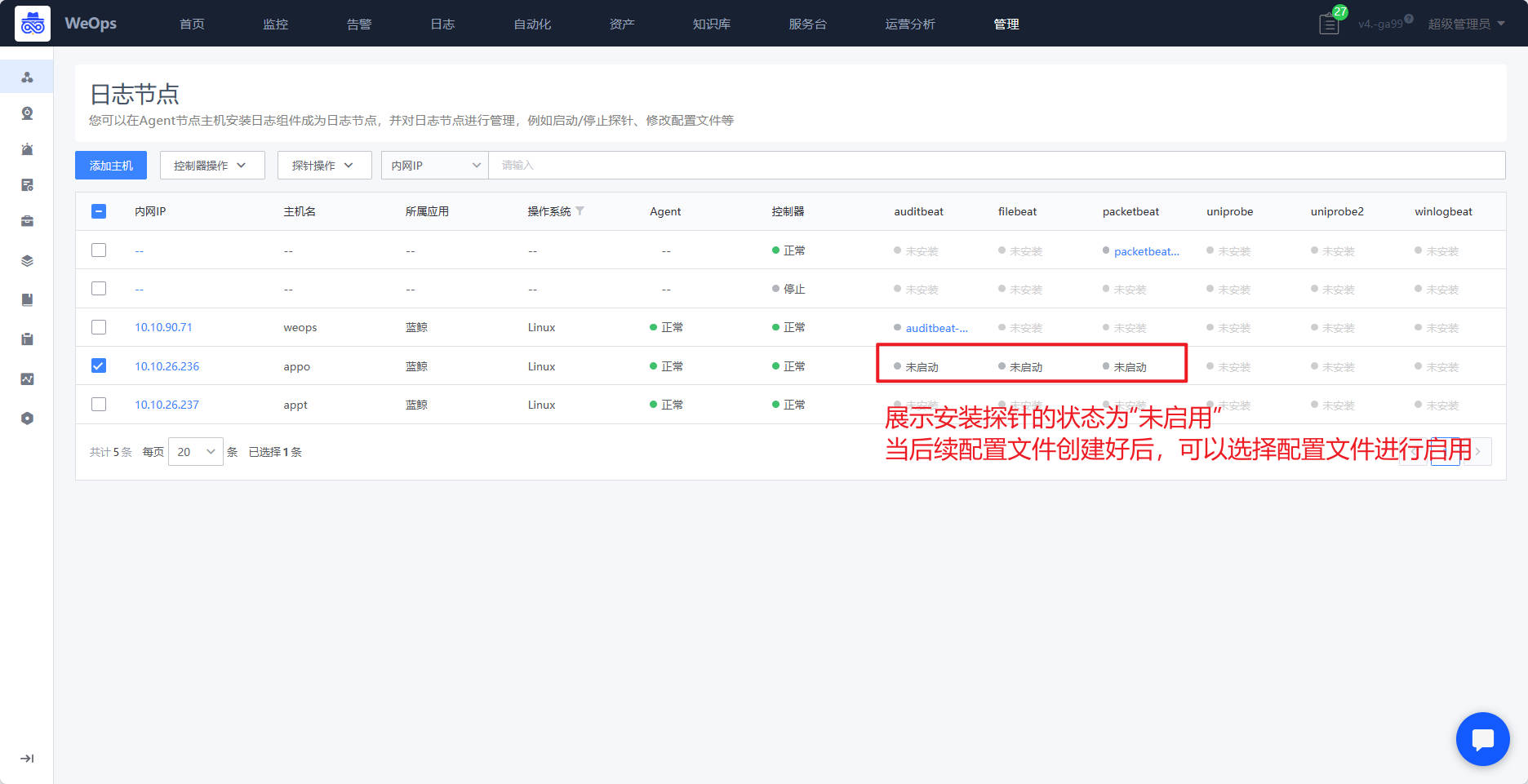
- 控制器安装好了以后,需要安装探针,目前WeOps内置了5类探针,auditbeat、packetbeat、filebeat、uniprobe、winlogbeat,需要使用哪类探针,勾选目标服务器后,点击“安装探针”按钮,选择给这个服务器安装探针,探针安装完后,显示“未启用”状态,需要后续关联配置文件方可启用。
Step4:创建配置文件
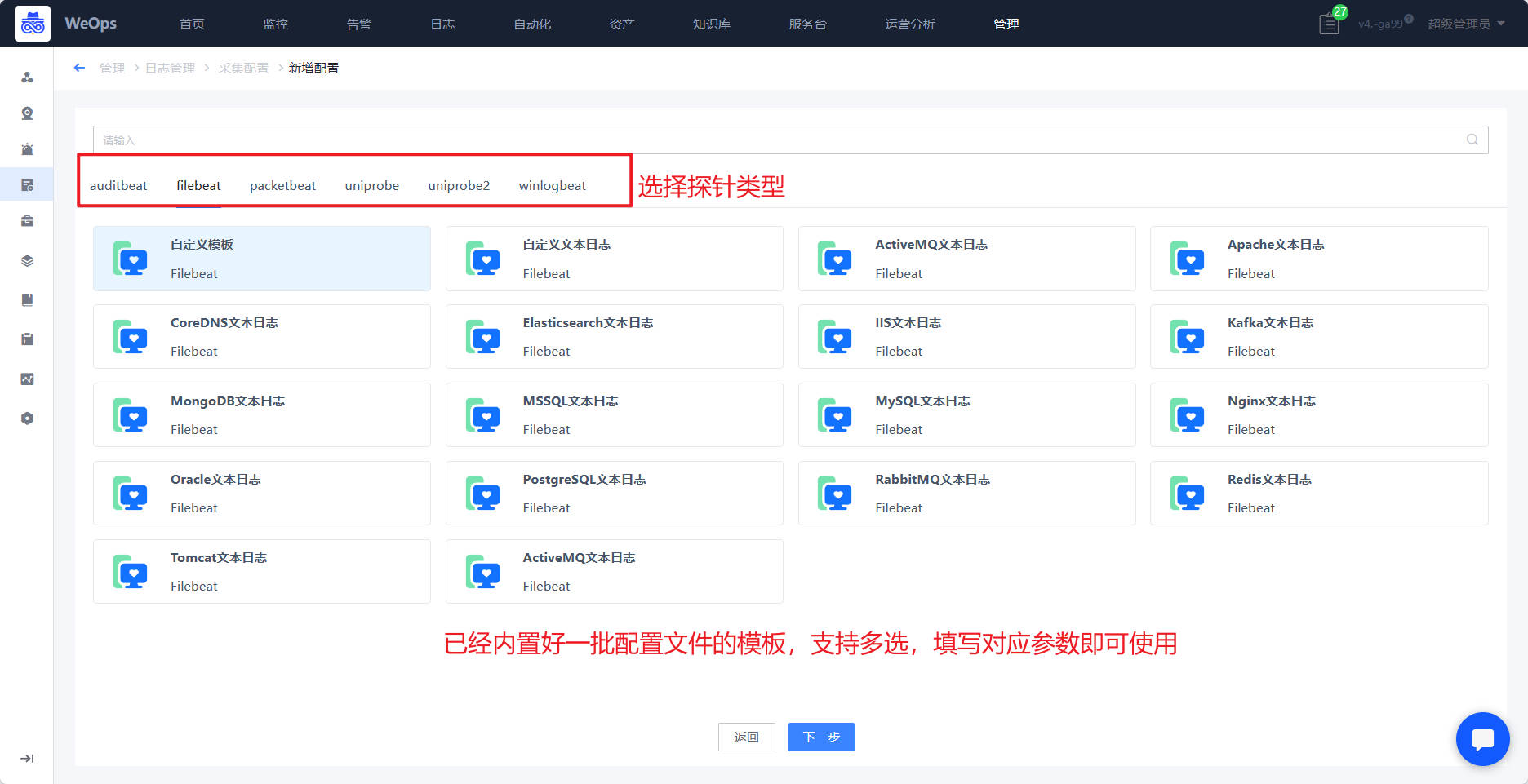
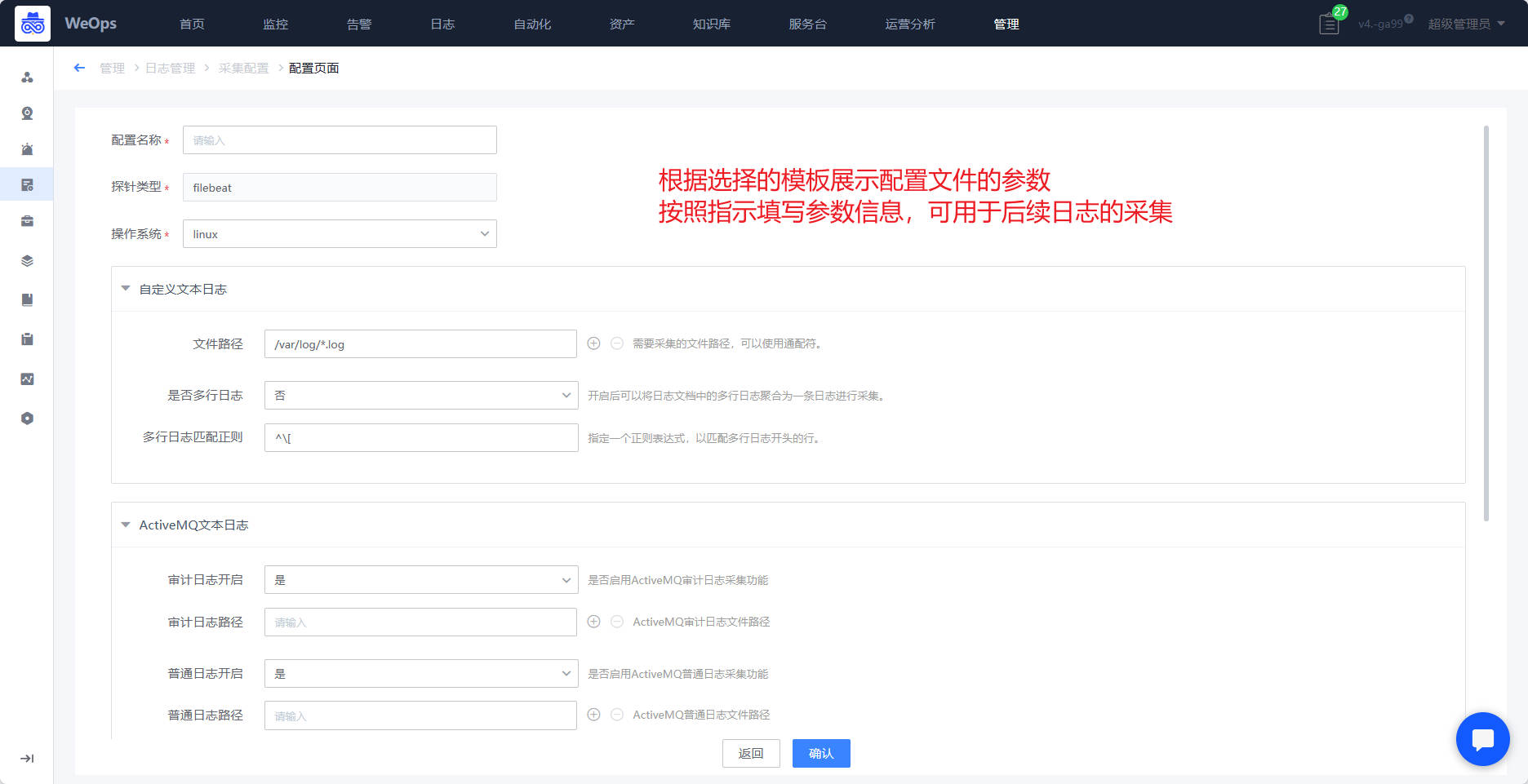
路径:管理-日志管理-采集配置
- 探针的启用需要关联对应的配置文件,WeOps支持对不同的探针设置配置文件,具体如下图
Step5:启动探针、关联配置文件进行下发
路径:管理-日志管理-采集配置
路径:管理-节点管理-日志节点
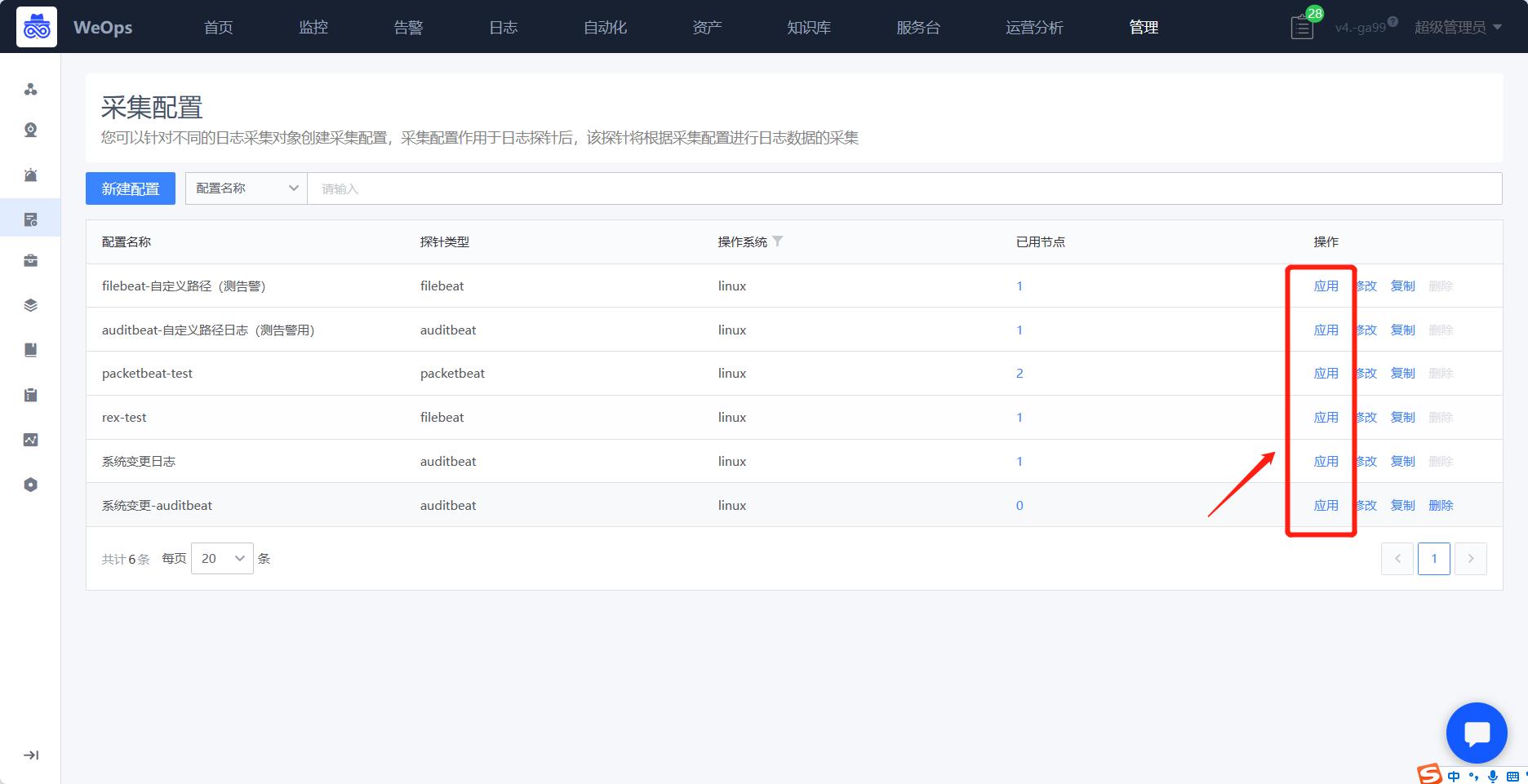
- 配置文件创建完成之后,需要把配置文件启用在具体探针上,有两种方式进行,一种是在配置文件列表点击“启用”按钮,把该配置文件启用在对应服务器的探针上面,如下图。第二种,是在日志节点页面,选择需要启动的服务器,选择需要启动的探针,为这个探针选择对应的配置文件。
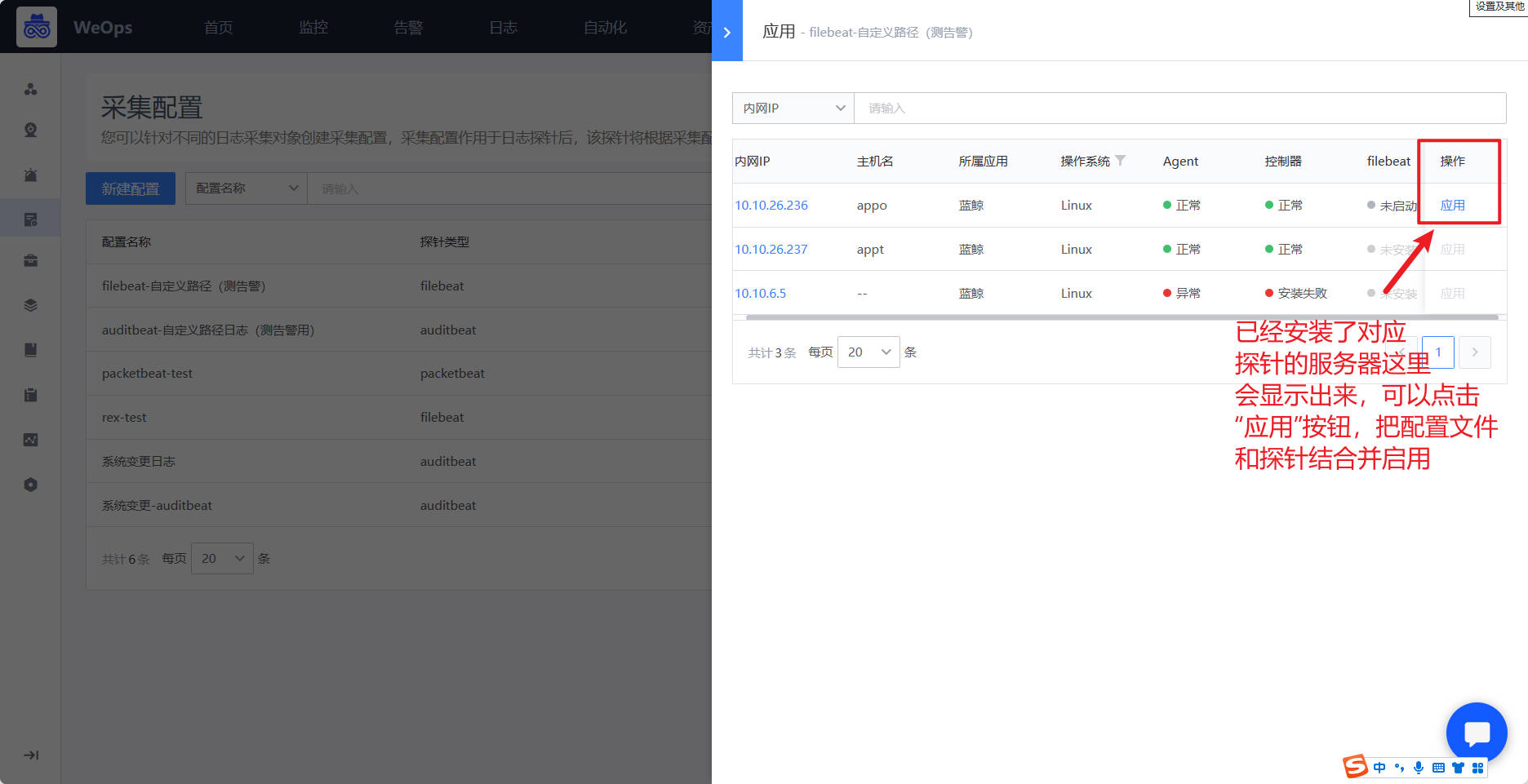
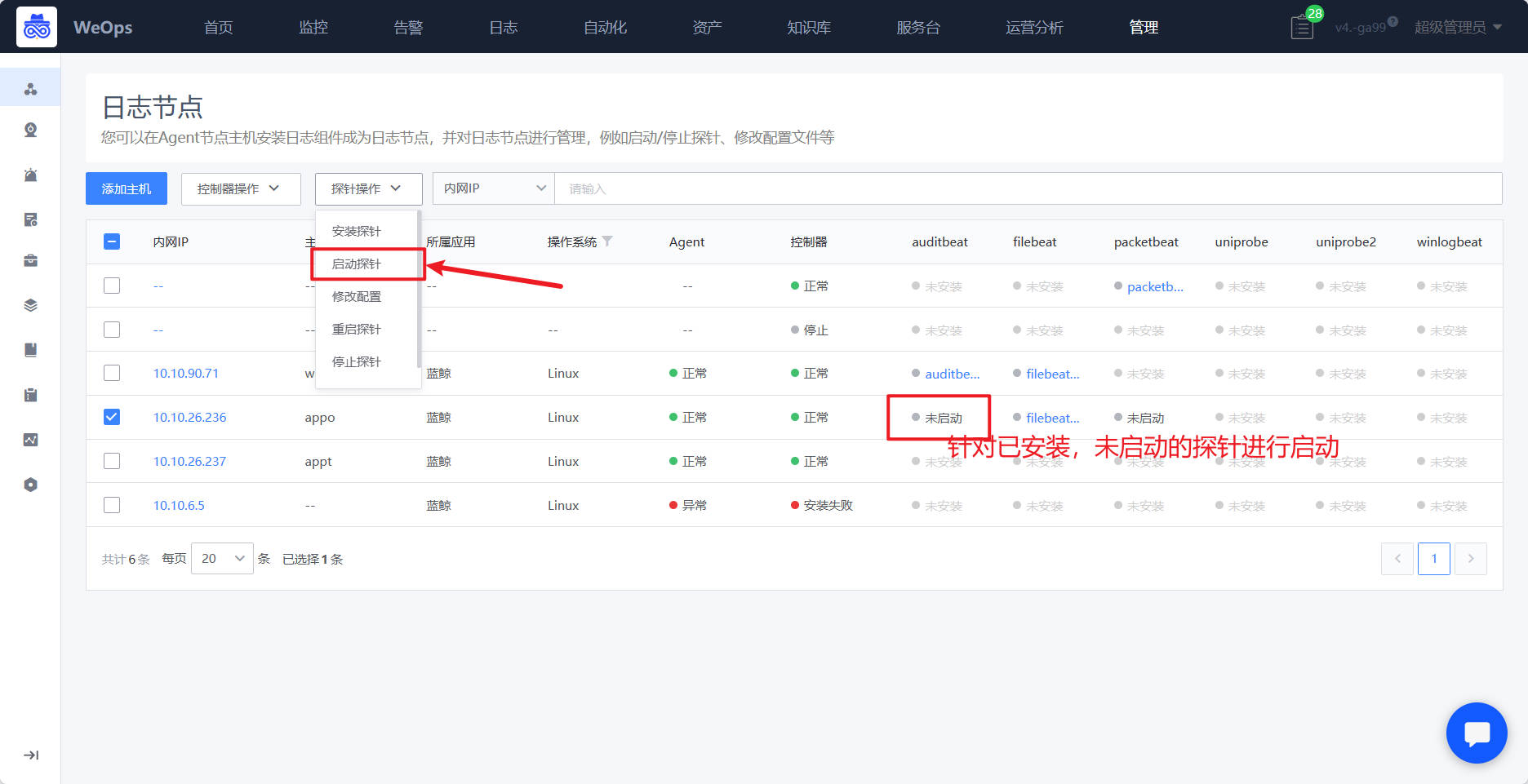
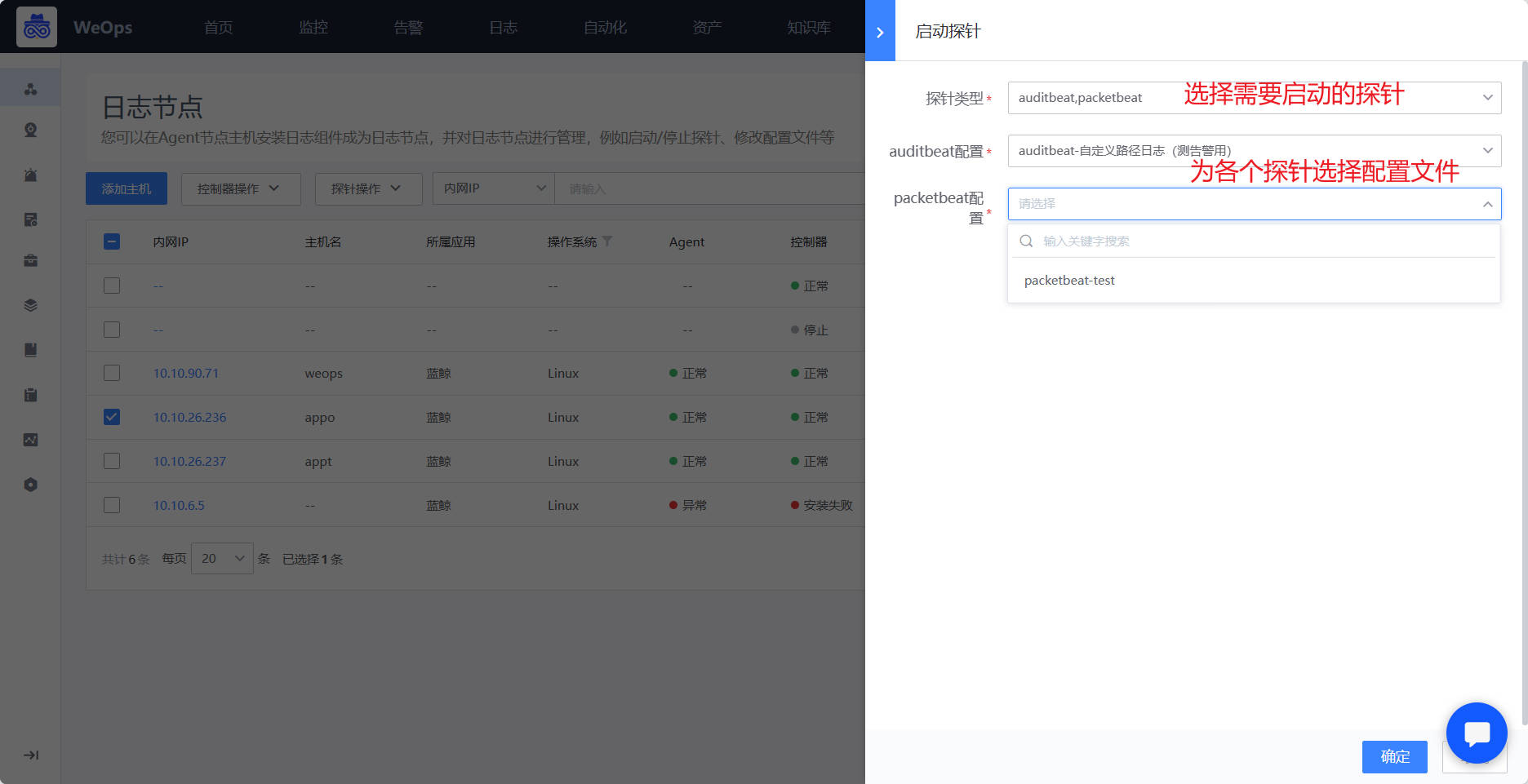
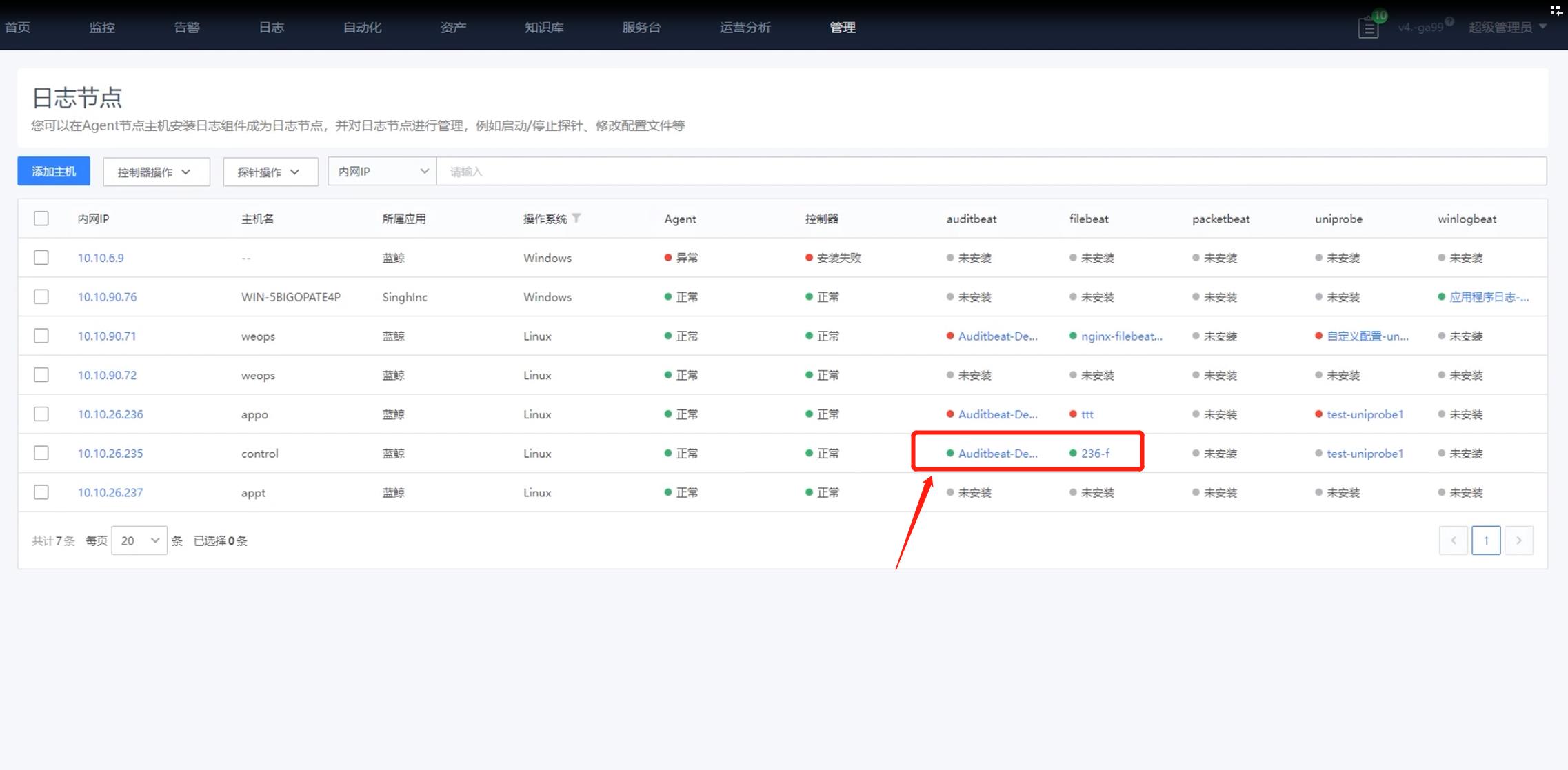
- 当探针的状态为“绿色”则表明采集正常,可以在“日志搜索”页面查看接收到的日志信息
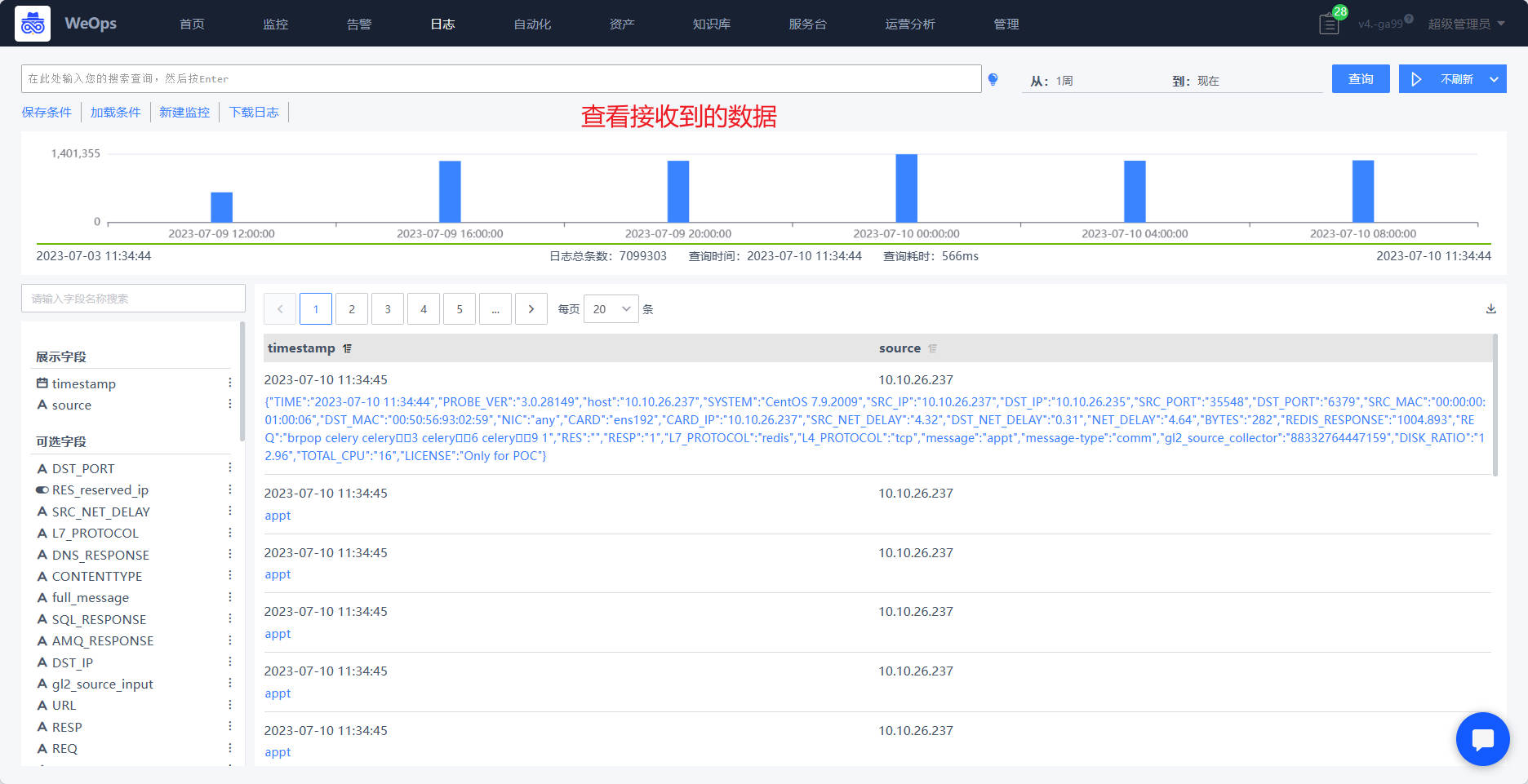
(2) 无agent模式(手动安装)
主机无需安装agent,采用手动的方式在服务器直接安装控制器和探针的安装包,并进行后续的使用。
整体步骤:手动安装————创建配置文件——关联配置文件进行下发。
Step1:安装控制器
- 如下图,点击“添加主机”,选择“手动安装”,这里可以选择没有安装agent/agent异常的主机,进入到手动安装页面,根据各个操作系统的指引进行安装(每个主机的步骤和参数略有不一样),安装成功后,自动获取状态为“安装成功”
- 安装成功的主机会自动呈现在外层的列表中,标识为“手动安装”,这是控制器状态为“正常”,其他所有探针状态为“未启动”,选择对应配置文件即可启动对应探针。
Step2:创建配置文件 Step3:关联配置文件进行下发
配置文件的创建和配置文件的关联和下发同“(1)agent模式(自动安装)”
- 日志控制器操作,包括安装、启动、重启、停止、卸载等操作可以根据指引进行手动操作,探针则包括安装探针、启动探针、修改配置、重启探针、修改探针等操作和自动安装的服务器一样,可以选择后自动操作。
日志分组配置
背景介绍:某公司接入的日志数据过多,对于日志的权限控制比较严格,可以通过日志分组的功能,对所有的日志消息进行划分不同的分组,并授权给不同的人员查看和使用。
整体步骤:设置日志分组——日志分组授权——日志分组使用
Step1:设置日志分组
路径:管理-日志管理-日志分组
- 如下图,创建日志分组,并为该分组创建符合的规则
- 分组规则:一个分组支持多个分组规则,可以在分组中进行创建和管理,分组创建完成之后,所有的原始日志会根据规则流入不同的分组,以便后续根据分组进行授权和使用。
Step2:日志分组授权
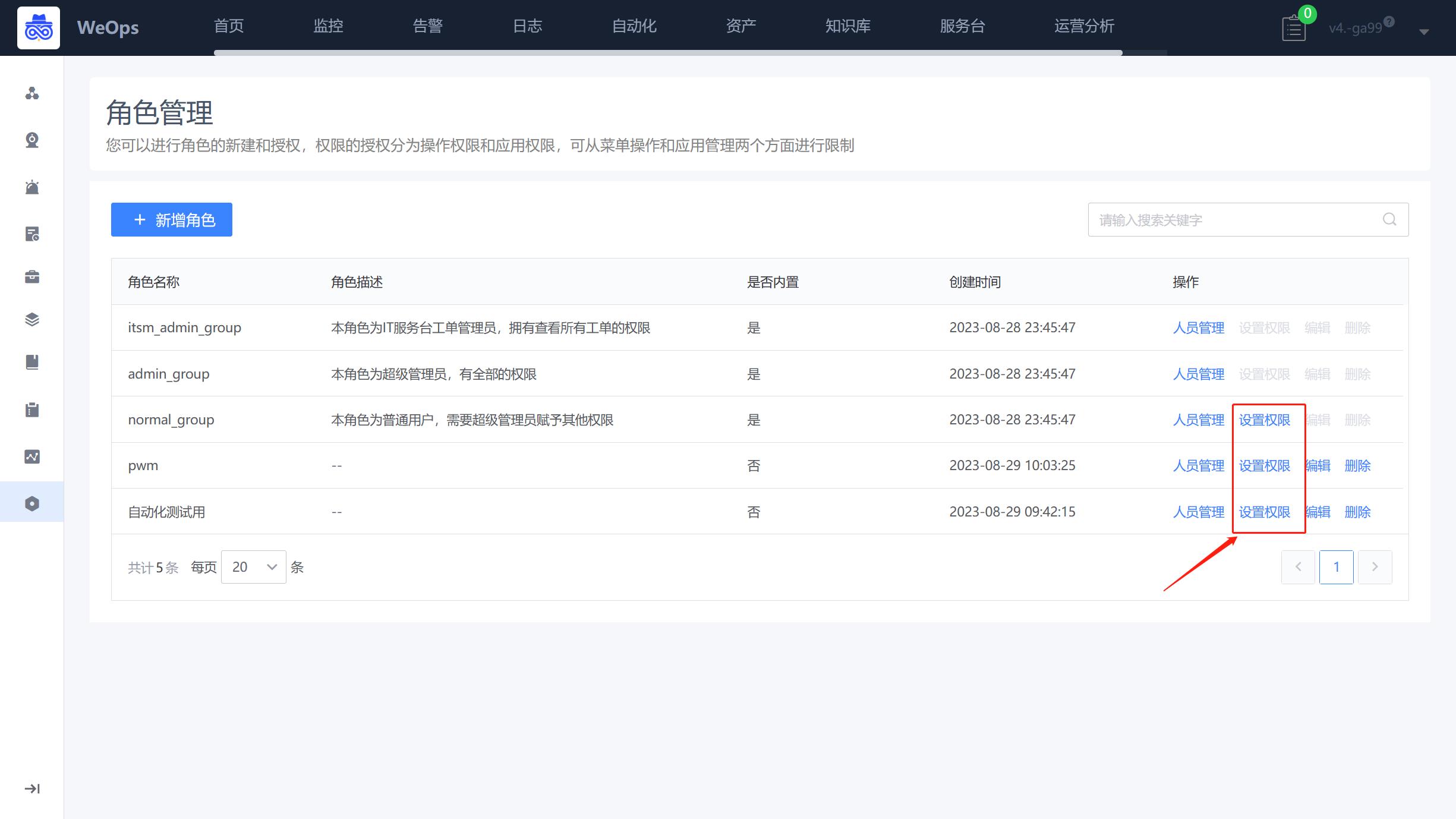
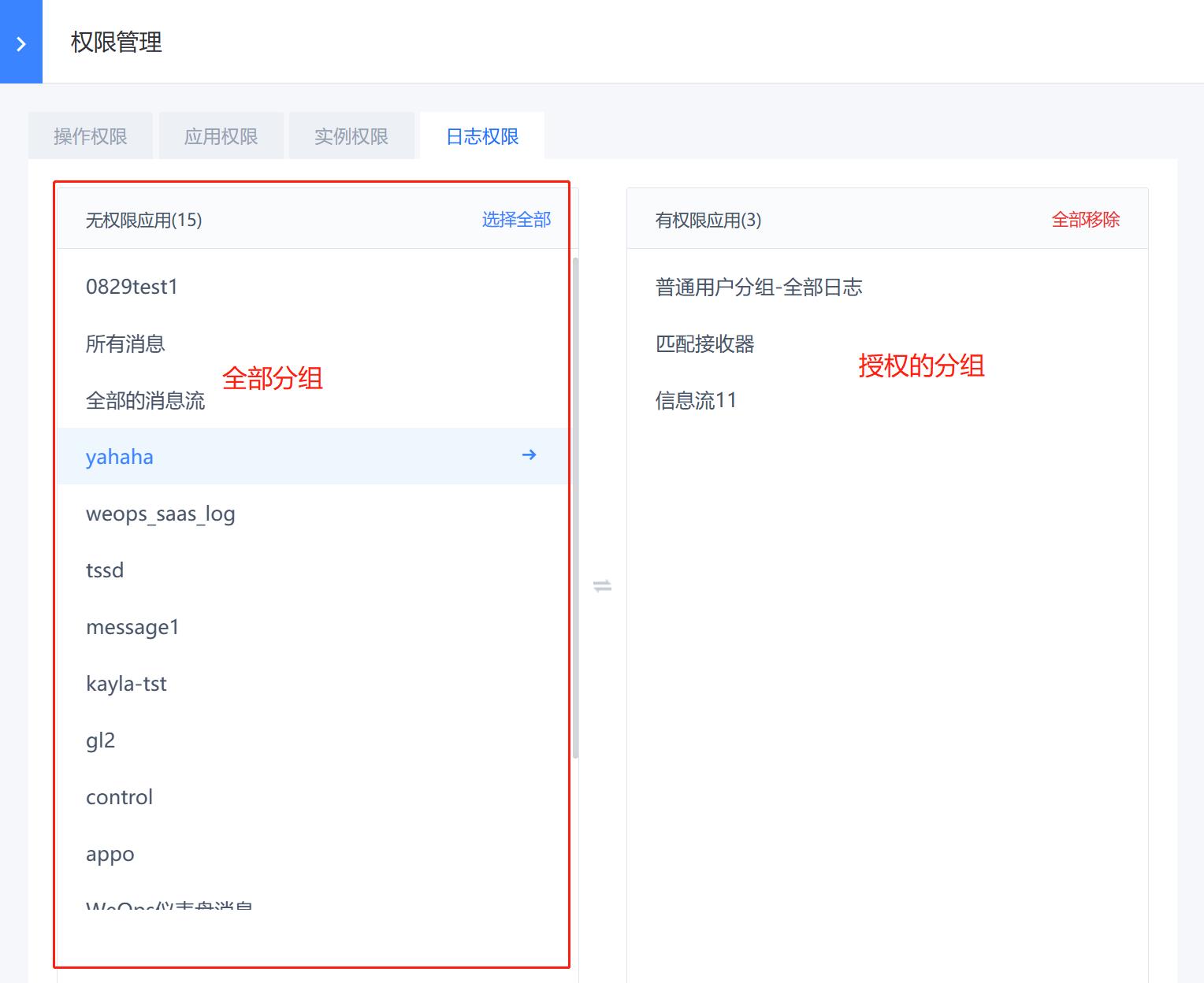
路径:管理-系统管理-角色管理
- 当日志分组创建完成之后,对不同角色进行授权,该角色即有该日志分组内日志的搜索和使用权限,授权过程如下:
Step3:日志分组使用
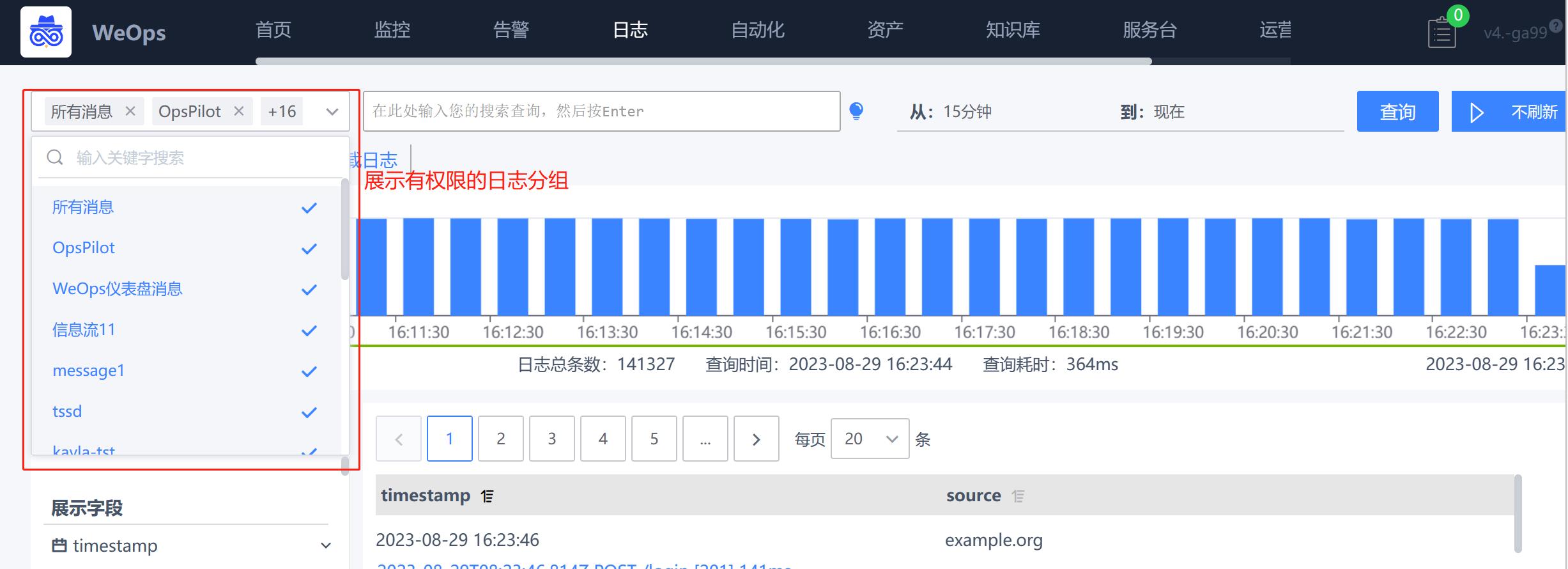
- 当普通用户拥有部分分组的权限时,将会体现在在以下位置
(1)日志搜索:普通用户在进行日志搜索的时候,可以选择自己有权限的分组和分组下的日志。
(2)日志监控策略创建:普通用户在创建日志的监控策略时,支持选择有权限的日志分组。
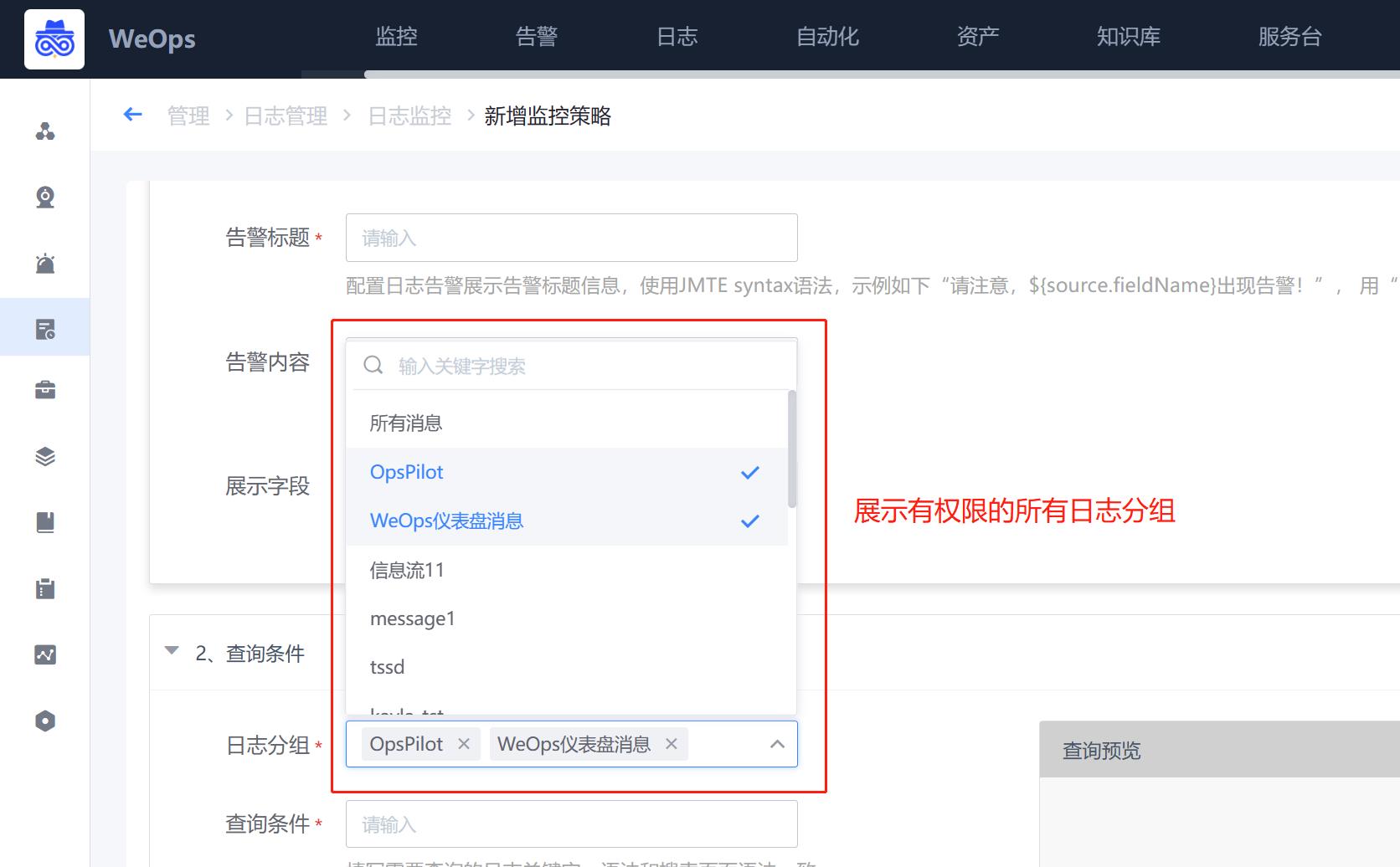
(3)仪表盘-日志组件:普通用户在使用仪表盘的日志组件的时候,支持选择有权限的日志分组。
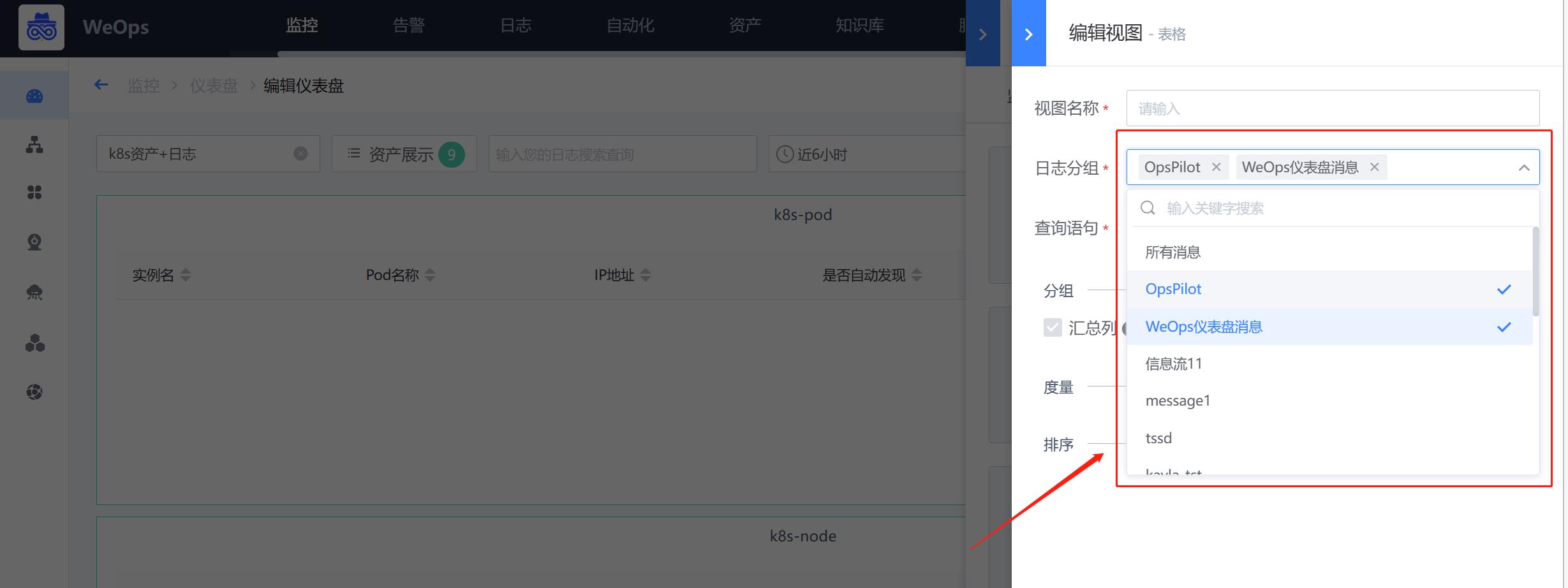
日志提取配置
背景介绍:接入的日志数据比较原始,是非结构化/半结构化的数据,需要进一步进行提取,形成方面搜索/统计的字段,可使用日志提取功能
整体步骤:添加提取器(两种方式)——提取器效果
Step1:添加提取器(搜索页面进入)
路径:日志
- 在日志的搜索页,根据搜索条件展示出来需要的原始日志,在原始日志的字段值上可以进行创建提取器
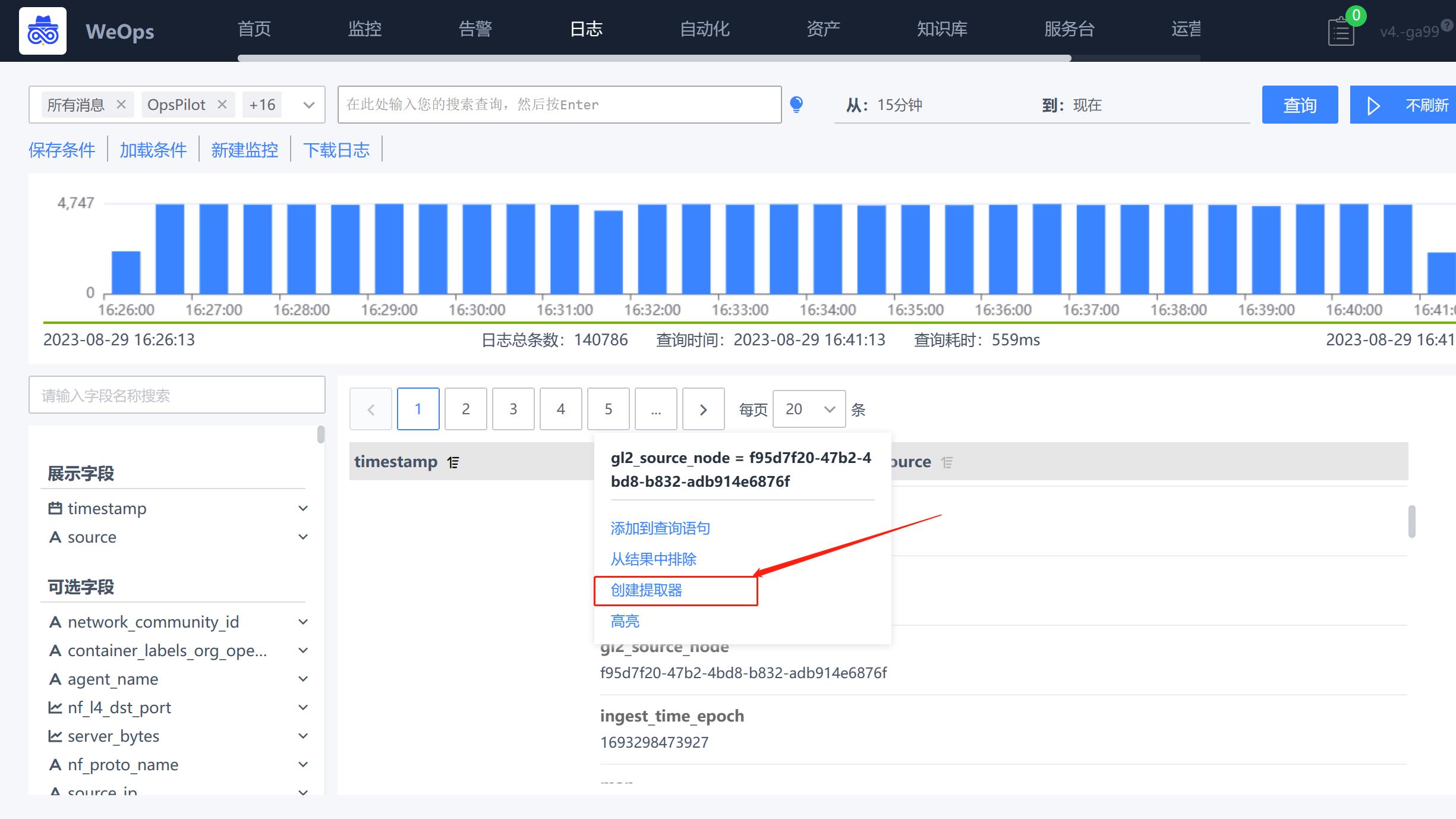
- 支持复制输入、Grok模式等类型的提取器,以正则表达式为例,设置提取器支持填写正则表达式、设置条件(什么情况下进行提取)、存储字段、提取策略(复制一个新的,剪切成为一个新的)、添加特殊格式的转换器
Step1:添加提取器(数据接收进入)
路径:管理-日志管理-数据接收
- 支持为每个接收器创建提取器,选择提取的字段,为该字段选择适用的提取类型,设置提取规则并保存为新字段,以便后续使用。
- 在数据接收页面,点击“管理提取器”,进入到提取器管理页面,
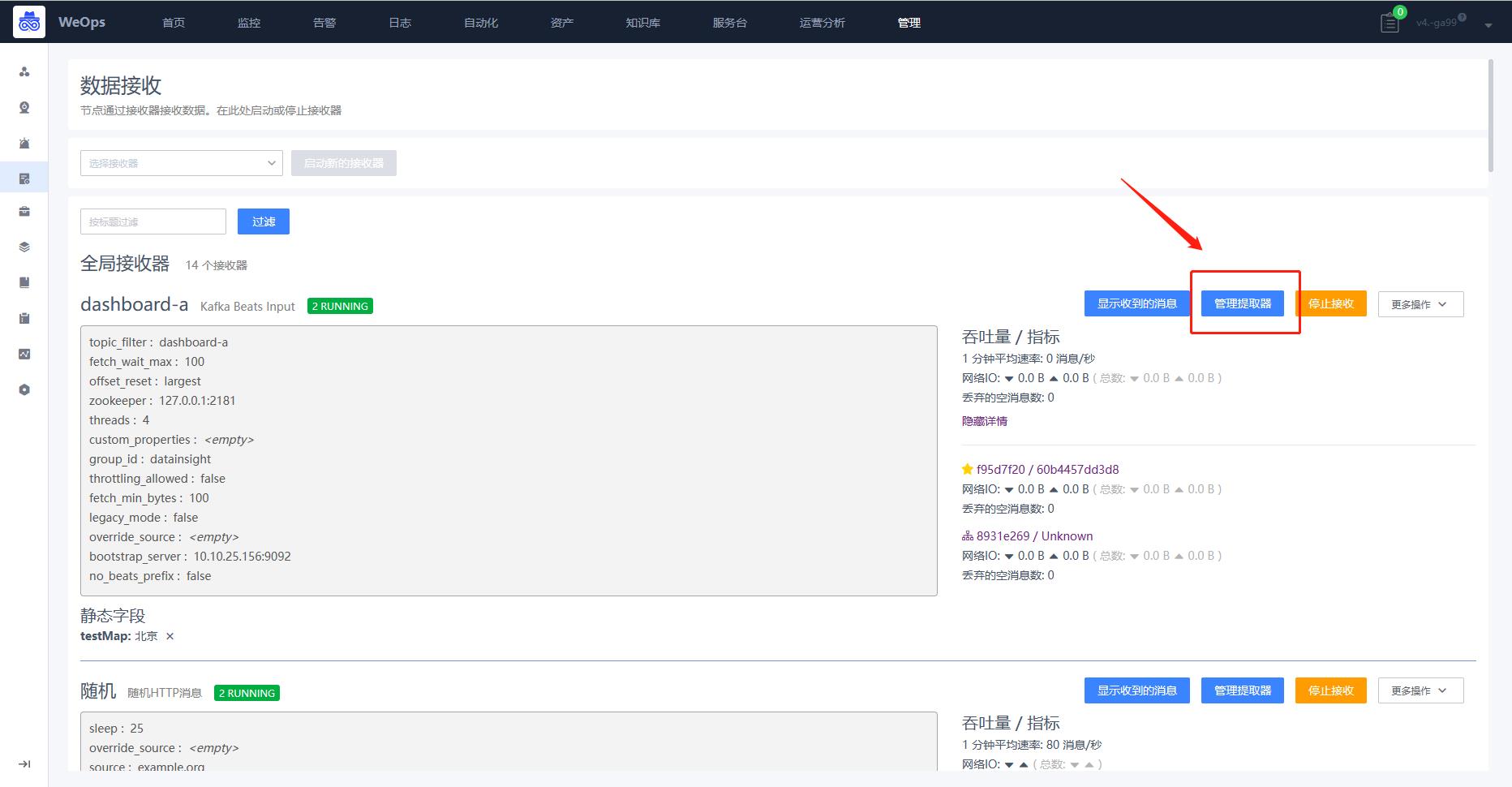
- 在提取器管理页面,点击“开始提取”,通过最新数据/条件搜索两种方式,展示原始日志字段,用于创建提取器
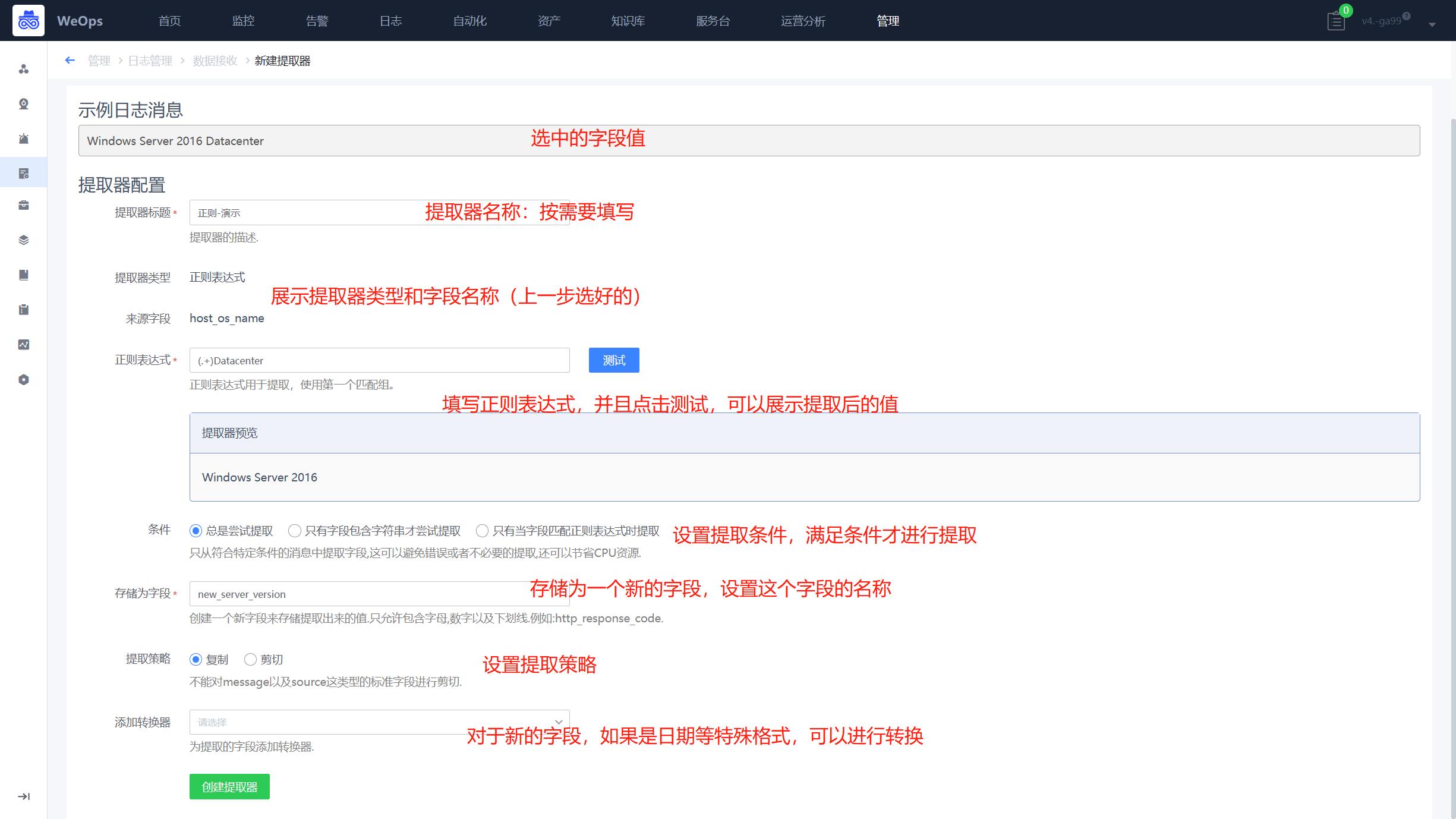
- 这里以“正则为例”,展示提取器需要填写基础信息、提取规则,提取策略等相关信息,如下图,提取器设置完后,可以查看该提取器的性能情况。
- WeOps支持的提取器如下表
| 提取器名称 | 适用 | 说明 |
|---|---|---|
| 复制输入 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 将原始消息中的一部分数据复制到提取器的规则中,并将其存储在结构化的数据字段中 |
| Grok模式 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 用于从非结构化的日志数据中提取结构化数据。它使用预定义的Grok模式或自定义Grok模式来匹配和提取数据,包括一些特殊的模式,用于匹配常见的数据格式,如IP地址、日期、时间戳等。(WeOps内置常用的Grok表达式)(Grok表达式是一种用于解析非结构化或半结构化数据的模式匹配工具。它是由Elasticsearch社区开发的一种基于正则表达式的模式匹配语言) |
| JSON | 适用于处理JSON格式的日志数据的场景。 | 可以从JSON格式的数据中提取特定的字段,并将它们存储在结构化的数据字段中。 |
| 正则表达式 | 适用于需要从未结构化的日志数据中提取特定字段或值的场景。 | 使用正则表达式从数据中提取特定的字段,并将它们存储在结构化的数据字段中 |
| 正则表达式替换 | 适用于需要替换日志数据中特定字符串的场景。 | 正则表达式替换器可以使用正则表达式从数据中匹配特定的模式,并将其替换为指定的字符串 |
| 分隔 | 适用于需要从日志数据中提取特定字段或值的场景。 | 使用指定的分隔符将数据分割成多个部分,并将它们存储在结构化的数据字段中 |
| 子窜捕获 | 适用于需要从日志数据中提取特定子字符串的场景。 | 使用指定的开始和结束字符串或位置来捕获数据中的子串,并将它们存储在结构化的数据字段中 |
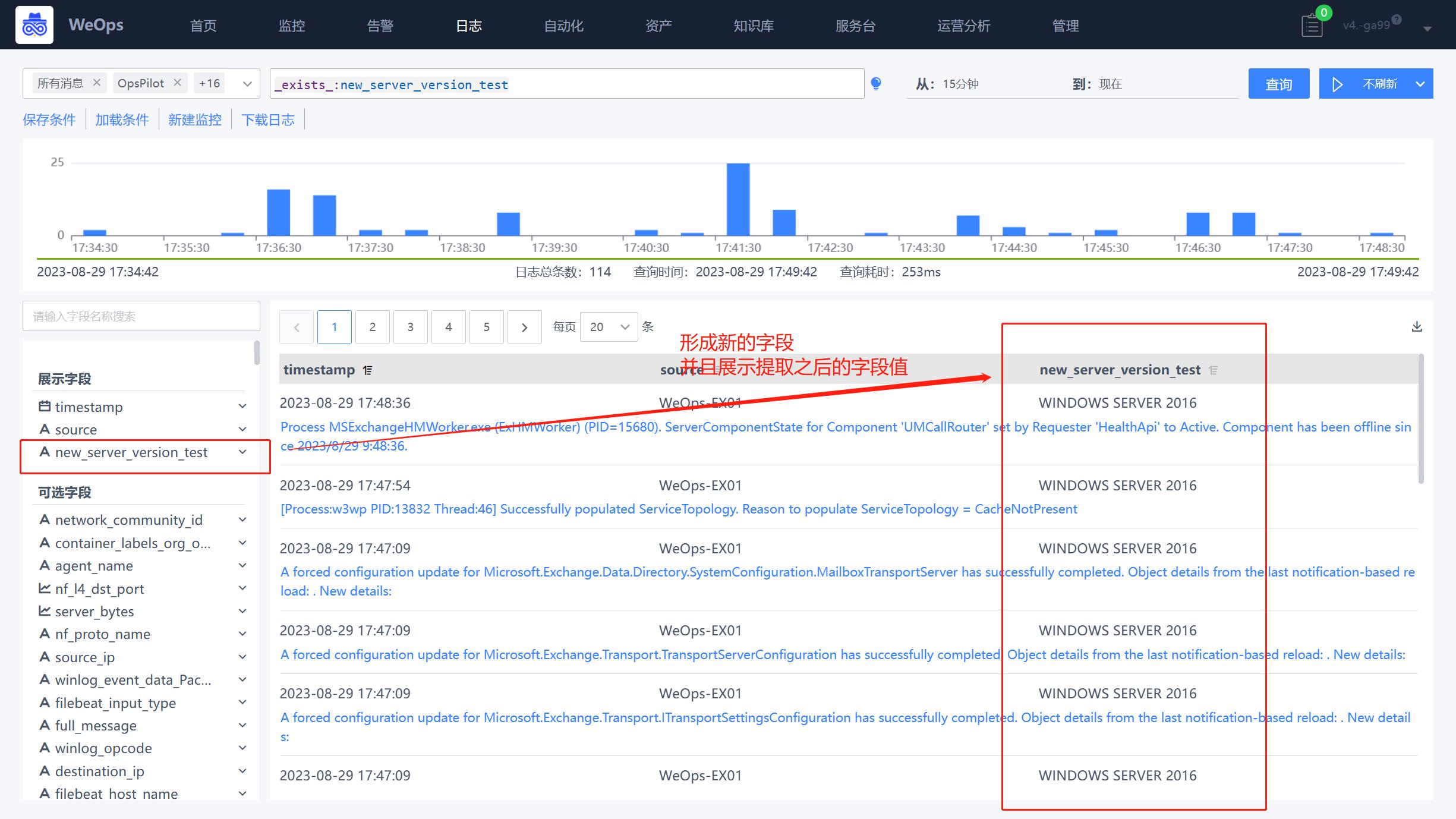
Step2:日志字段使用
路径:日志
- 在日志搜索页,可以查看提取后的字段和字段值,进行搜索和统计使用。
日志监控告警配置
背景介绍:公司的设备已经接入WeOps-日志,需要对某些设备日志监控监控,一旦发现异常情况,发出告警通知对应人员及时进行处理。
整体步骤:日志监控策略配置——日志告警查看和处理
Step1:日志监控策略配置
日志监控策略配置的入口有以下三种
- (1)日志搜索快捷创建:如下图,当日志搜索时,需要将搜索的关键词直接设置为日志监控搜索语句,可以通过
路径:日志-新建监控
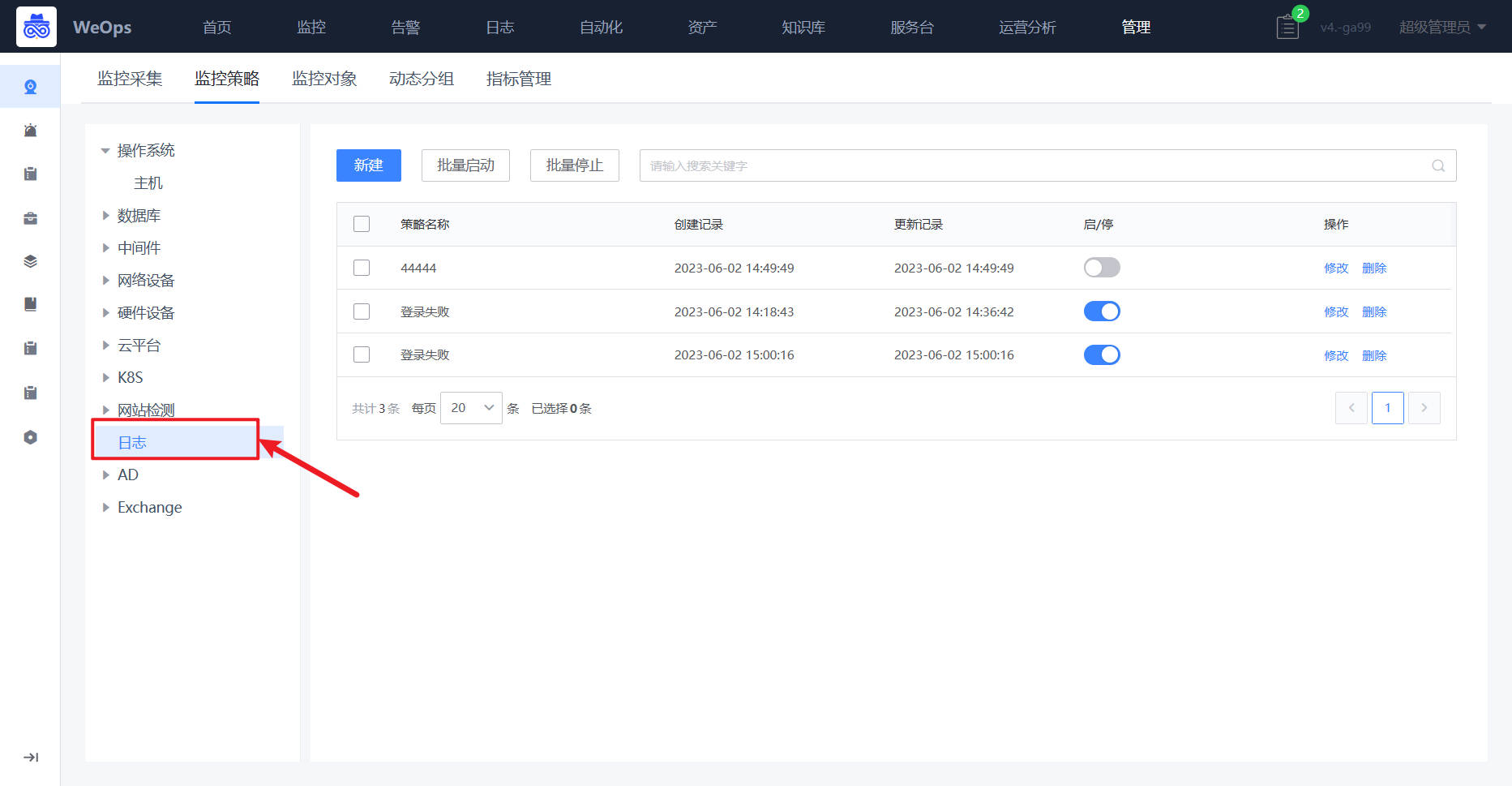
- (2)监控策略:如下图,在监控管理-监控策略中也可以直接找到日志监控策略进行创建
路径:管理-监控管理-监控策略-日志策略
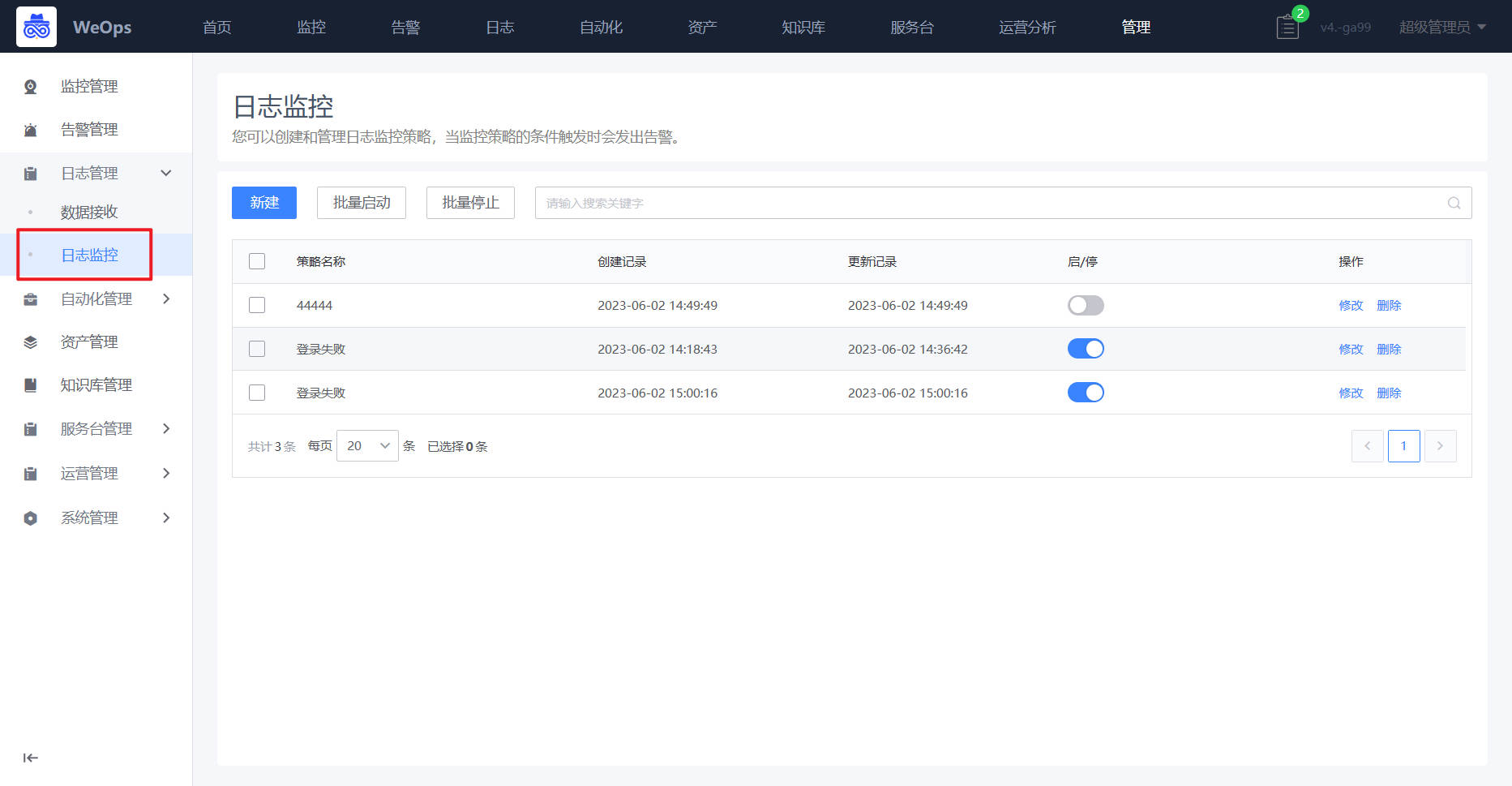
- (3)日志监控:如下图,在日志的管理的日志监控中,也可进行日志监控策略的创建
路径:管理-日志管理-日志监控
- 三个入口的日志监控创建策略页面一致,具体如下图
- (1)基本信息:
- (2)查询条件:支持
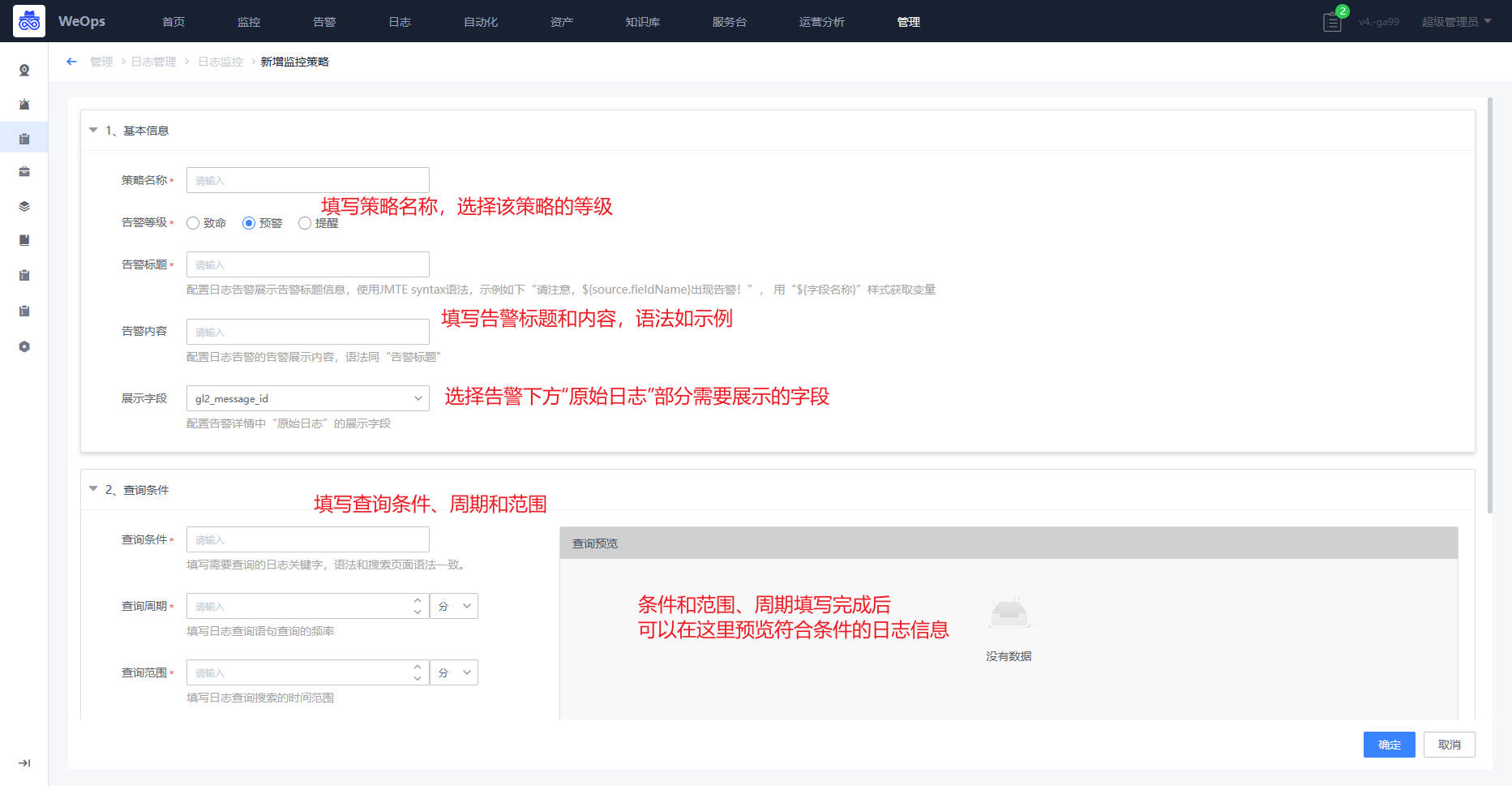
- (3)关联资产
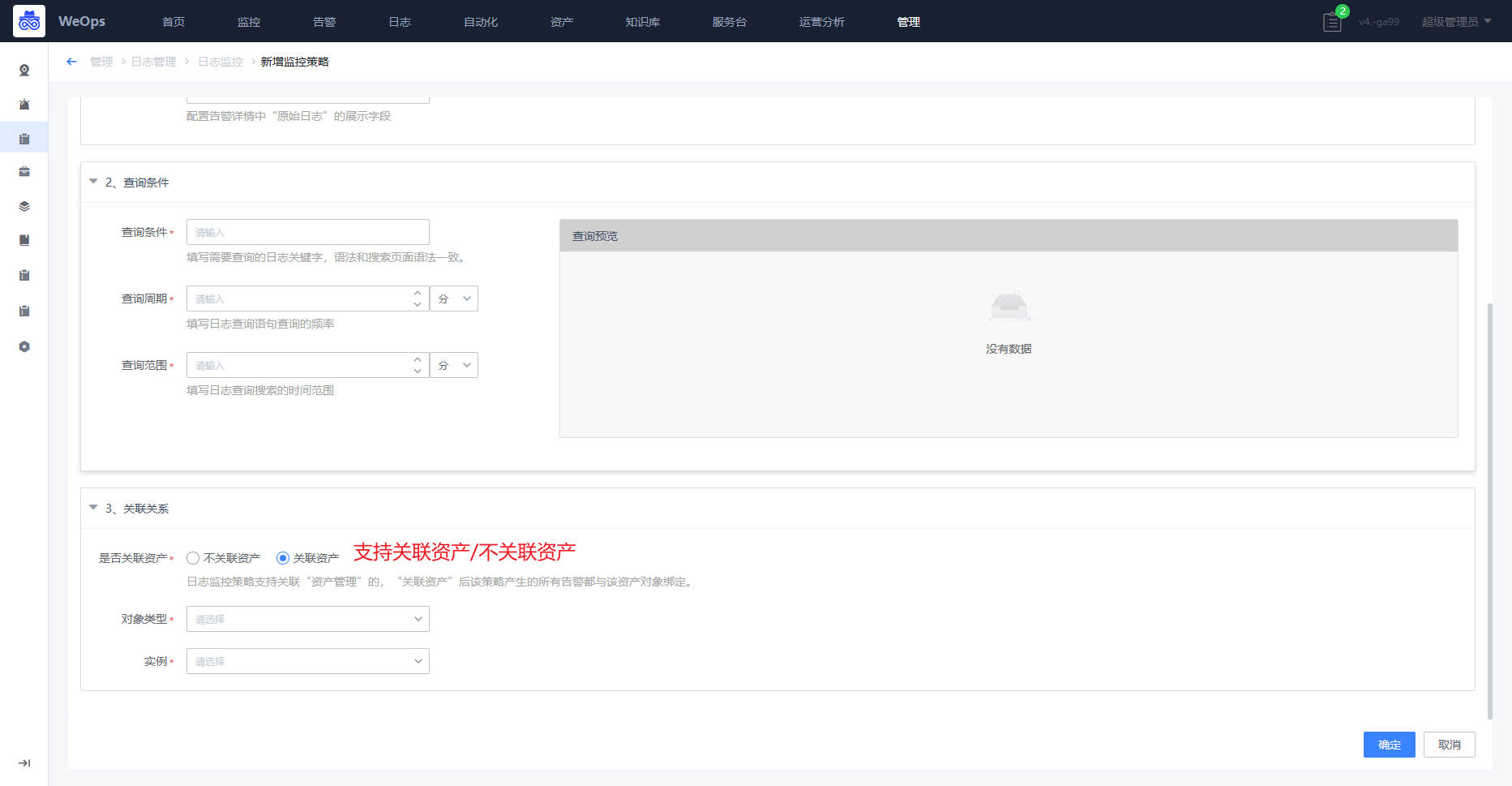
Step2:日志告警查看和处理
- 安装日志监控策略进行监控,一旦符合策略配置的条件,即可产生告警,告警内容如下图
日志关联资产
背景介绍:已经接入对应的日志数据,需要从资产的角度查询和使用对应的日志,可以将日志与资产进行匹配关联
整体步骤:创建数据关联——查看资产的日志数据
Step1:创建数据关联
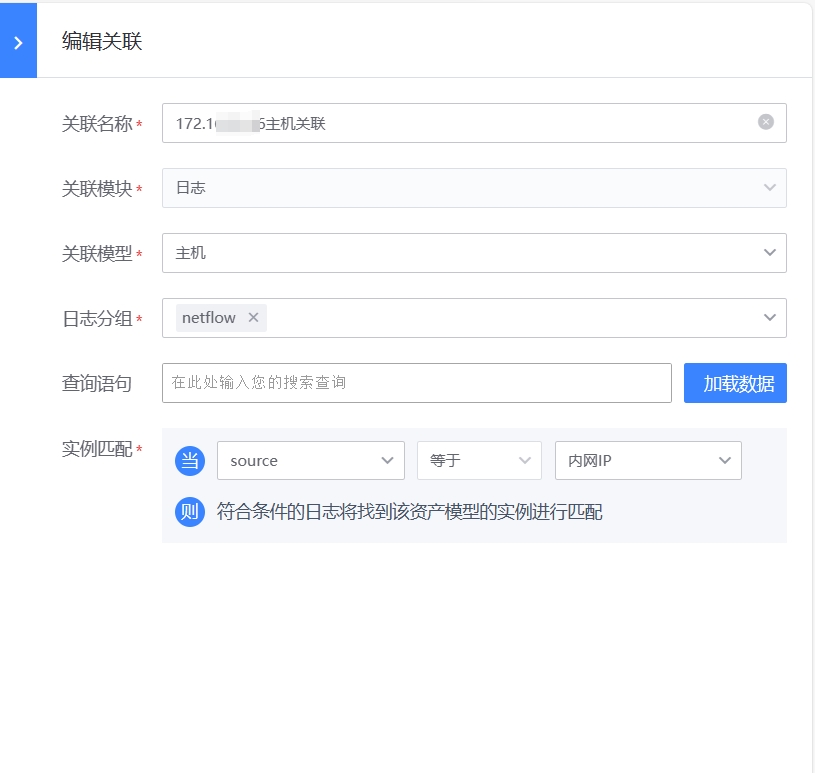
路径:管理-资产管理-数据关联
如下图,点击“新建关联”,选择对应的关联资产模型(比如主机),可以过滤需要的日志(从日志分组和查询语句两个角度进行过滤),并且通过字段的匹配,动态查找到对应的资产(比如source字段匹配主机的内网IP,当出现的日志数据中source是某个固定的IP时,就会归属到这个对应资产)
Step2:查看资产的日志数据
当匹配设置完成后,设置了匹配规则的模型下的资产,会增加“资产日志”的tab,呈现该资产的日志数据,具体有如下两个地方。
路径:资产-资产记录-对应模型/资产
- 如下图,当在“资产管理-数据关联”中配置好资产和日志的匹配关联后,可以在此处查看该资产的相关日志信息
路径:监控-告警对象/监控视图-对应资产
- 通过“资产管理-数据关联”设置资产和日志的匹配规则,将会在资产的监控信息中展示与该个资产相关联的所有的日志数据
自动化运维配置
工具管理
背景介绍:公司有经验的运维人员需要将自己沉淀的脚本转化为小工具,便于后续其他运维人员使用。
整体步骤:新建工具——工具使用
新建工具
路径:管理-管理中心-自动化运维-运维工具
WeOps-运维工具包括操作系统和网络设备两类
首先是操作系列类的工具新建:在工具管理界面,点击“新增工具”可进行工具的新增
在工具新增界面,填写工具名称,选择对应标签和操作系统,Windows支持powershell和bat两类言语,linux支持shell和python两类语言。
特殊说明:与传统脚本使用不同,为了支持脚本工具在批量执行过程无需输入“参数信息”,在运维工具自定义的时候,将执行中用到的参数作为“位置参数“提前定义,并在脚本中对应的位置进行引用。这样,在工具执行前输入脚本执行需要的参数信息,即可一键批量执行,中途无需输入。
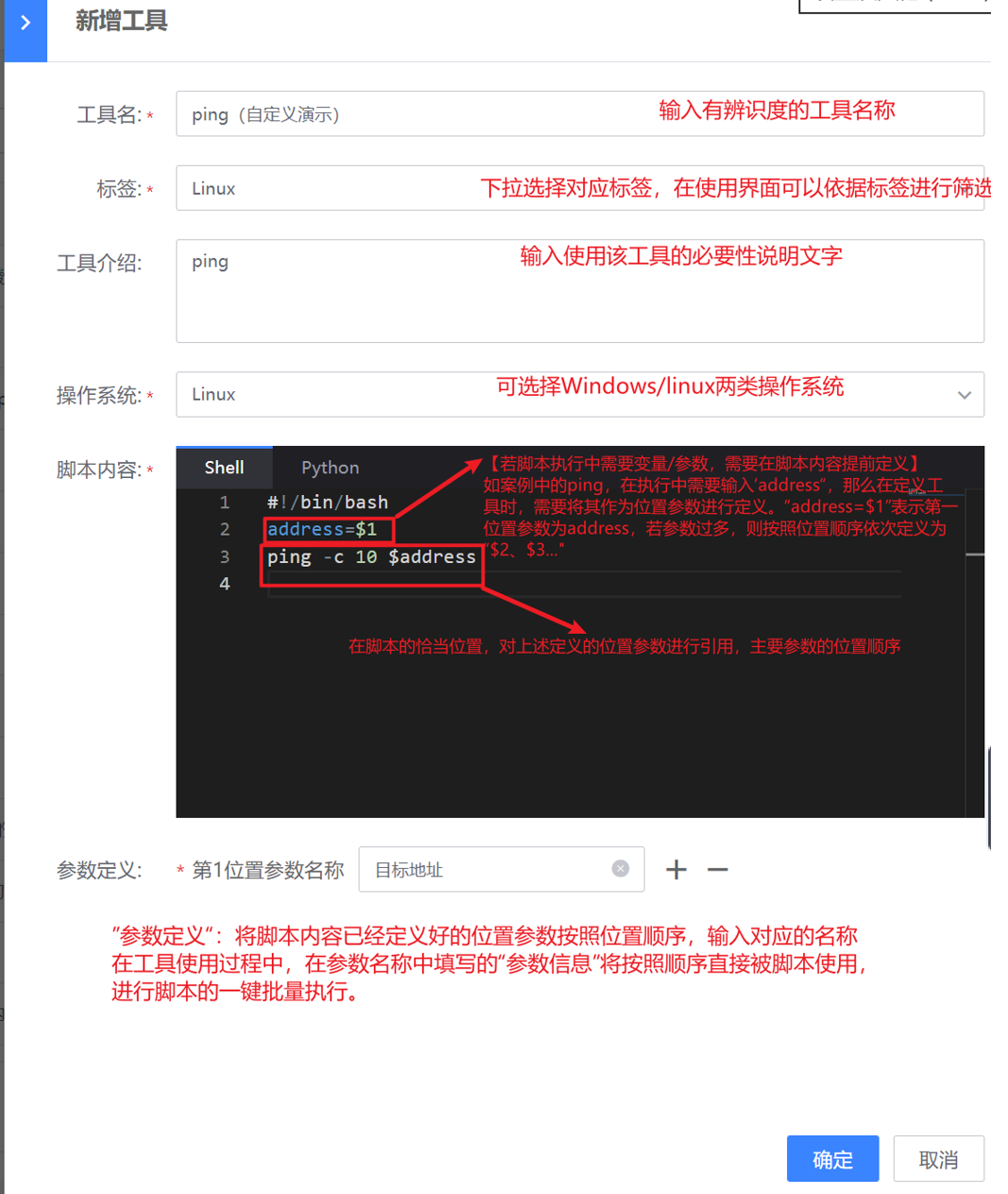
再者是网络设备类的工具新建:在自定义工具之前,需要对各类网络设备的脚本执行结束语进行设置,设置完成后方可在工具管理界面,进行工具的新建,这样工具在执行的时候就会按照设定的结束语结束脚本的执行
在“网络设备模板”中,点击“新建”按钮,创建某个品牌的某一类设备的结束语模板


点击模板的结束语,进行结束的创建
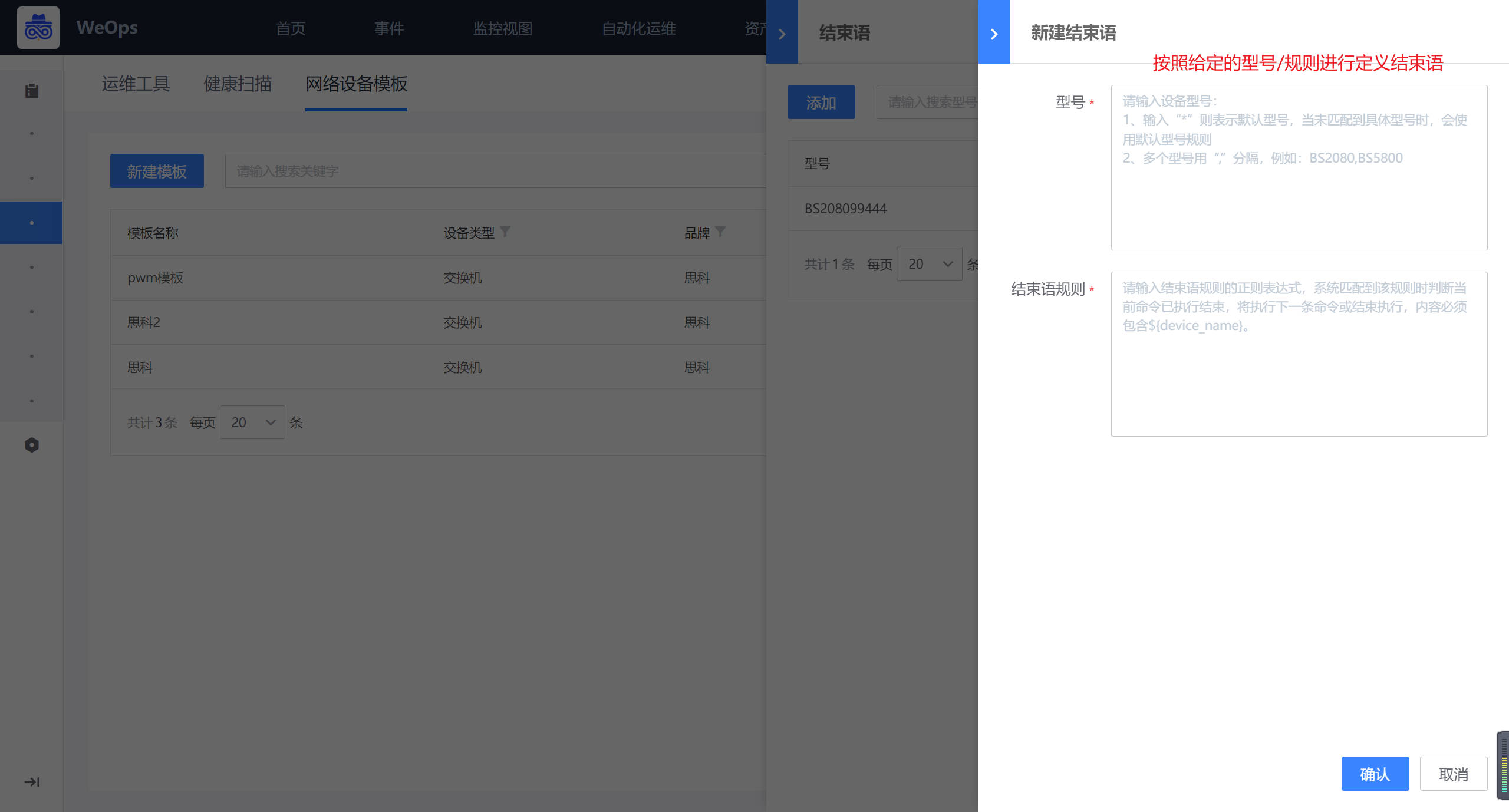
结束语定义完成以后,在选择“网络设备”,点击“新增工具”可进行工具的新增
在工具新增界面,填写工具名称,选择对应标签,支持交换机/路由器/防火墙/负载均衡,支持Telnet和SSH两类协议。
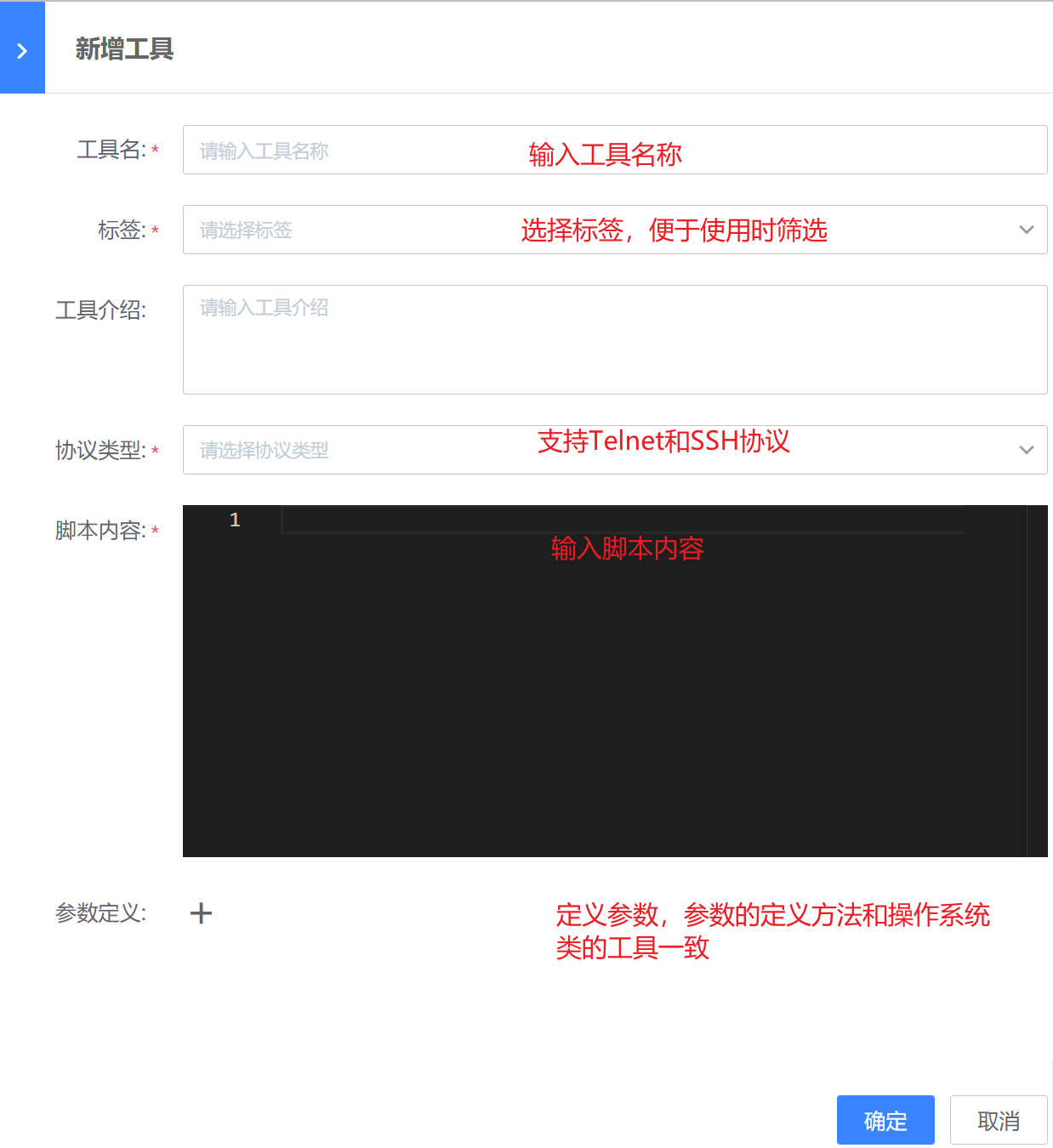
工具使用
路径:自动化运维-运维工具-脚本工具
工具新建完成后,可在“运维工具-脚本工具”中查看到新建的工具,点击工具,选择对应的资产列表,输入定义好的参数信息,点击执行,即可查看执行结果。

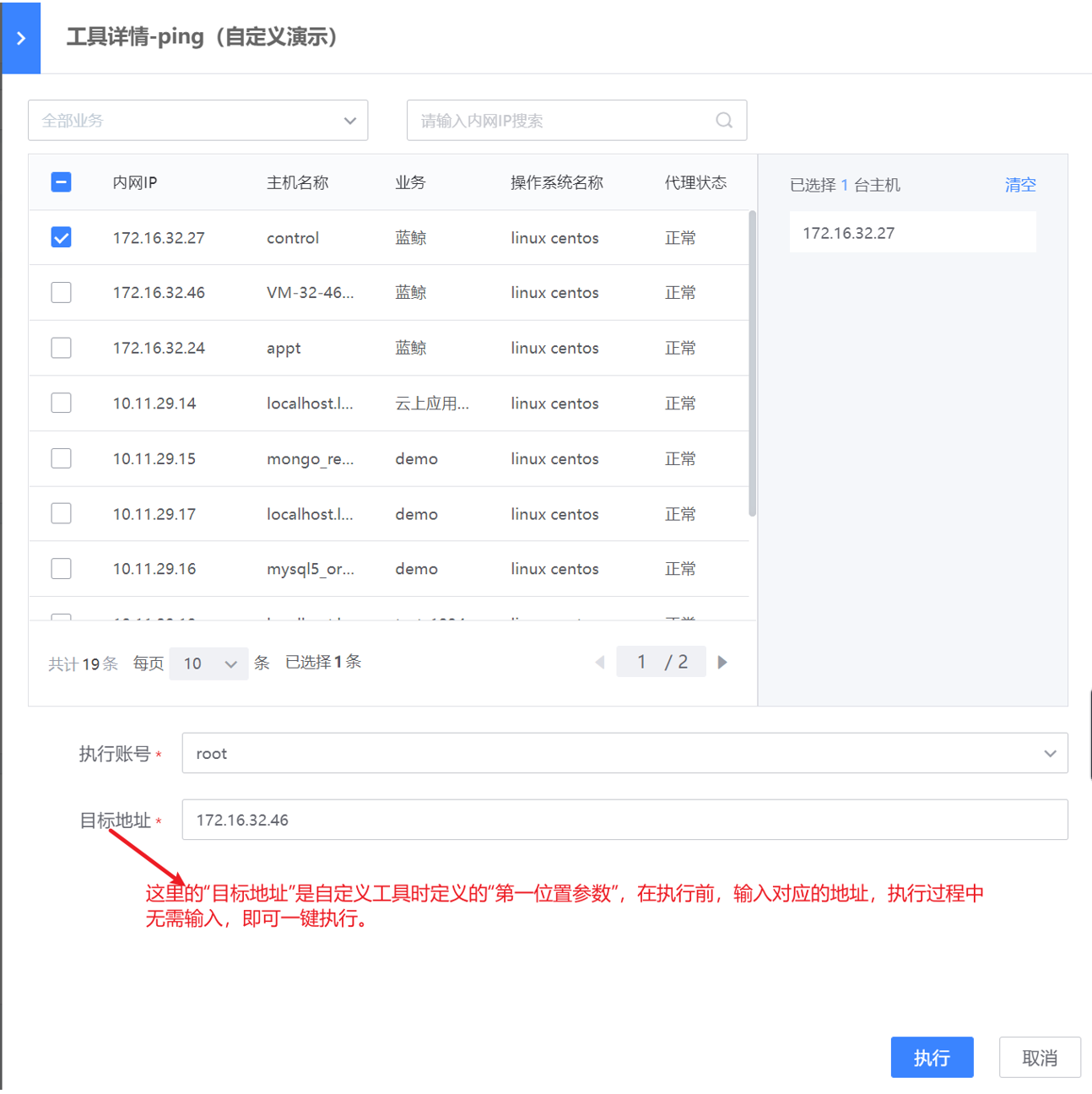
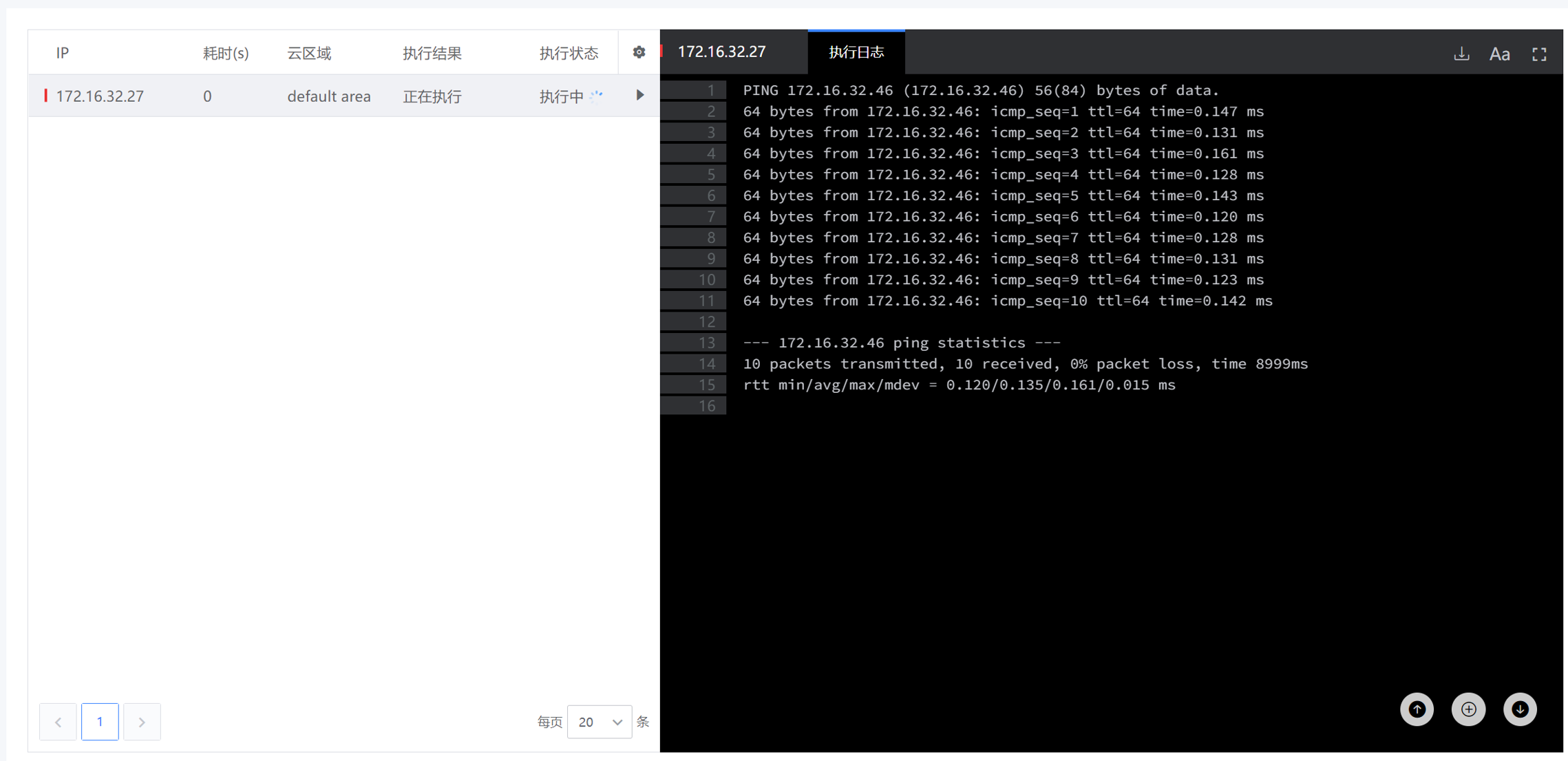
扫描包管理
背景介绍:运维人员需要新增扫描包,或者对现在内置的扫描包的检查项和参数进行设置。
整体步骤:新建扫描包——扫描包设置——扫描包使用
step1:新建扫描包
路径:管理-管理中心-自动化运维-健康扫描
- 新建扫描包的方式有两种,一种是导入json文件的方式,一种是手动创建扫描包,接下来分别介绍
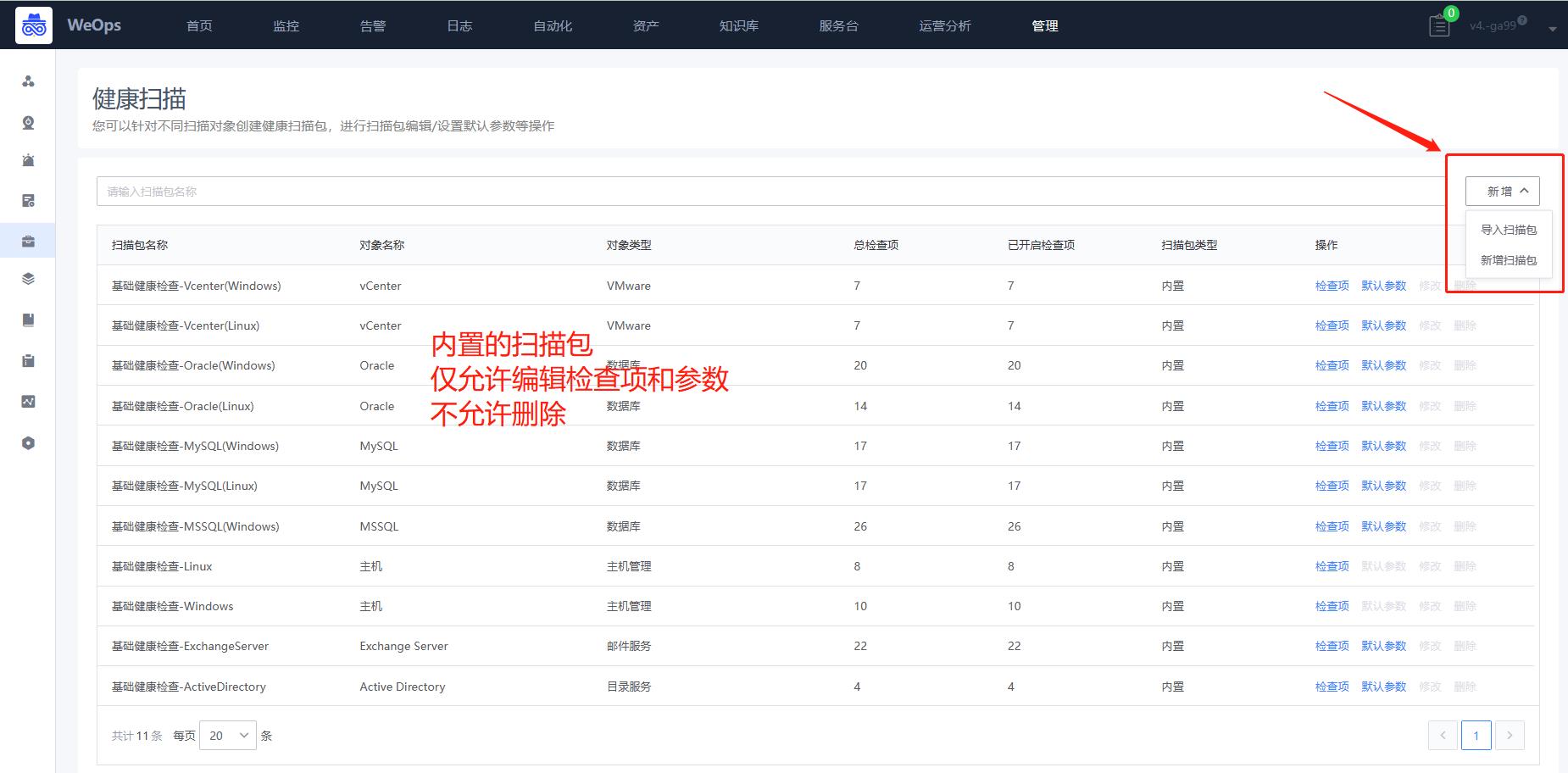
- 导入扫描包:在扫描包新建页面,需要按照模板的.json文件进行导入,模板文件包括扫描包的基本信息(名称/对象类型/对象名称)、检查项采集脚本、检查项基本信息(名称、阈值、单位、解释说明、治愈建议等)。导入完成后,可以在“健康扫描”界面使用该扫描包进行资源的健康扫描。
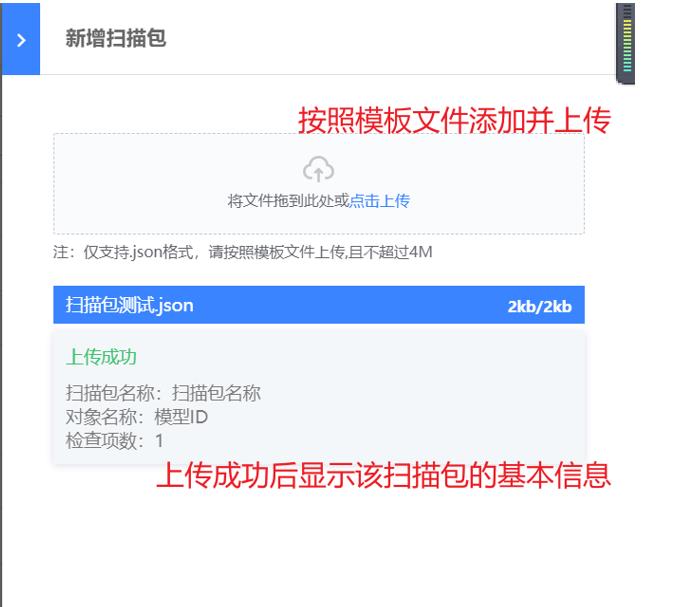
- 新建扫描包:点击“新建扫描包”,弹出抽屉,进行扫描包的创建,包括几个部分:基础信息(名称、关联的模型、展示的字段等)、脚本内容(获取检查项的脚步)、参数定义(脚本执行需要的参数,注意以$1、$2区分位置)、检查项(检查项的中英文名称,单位、健康值、维度等信息)
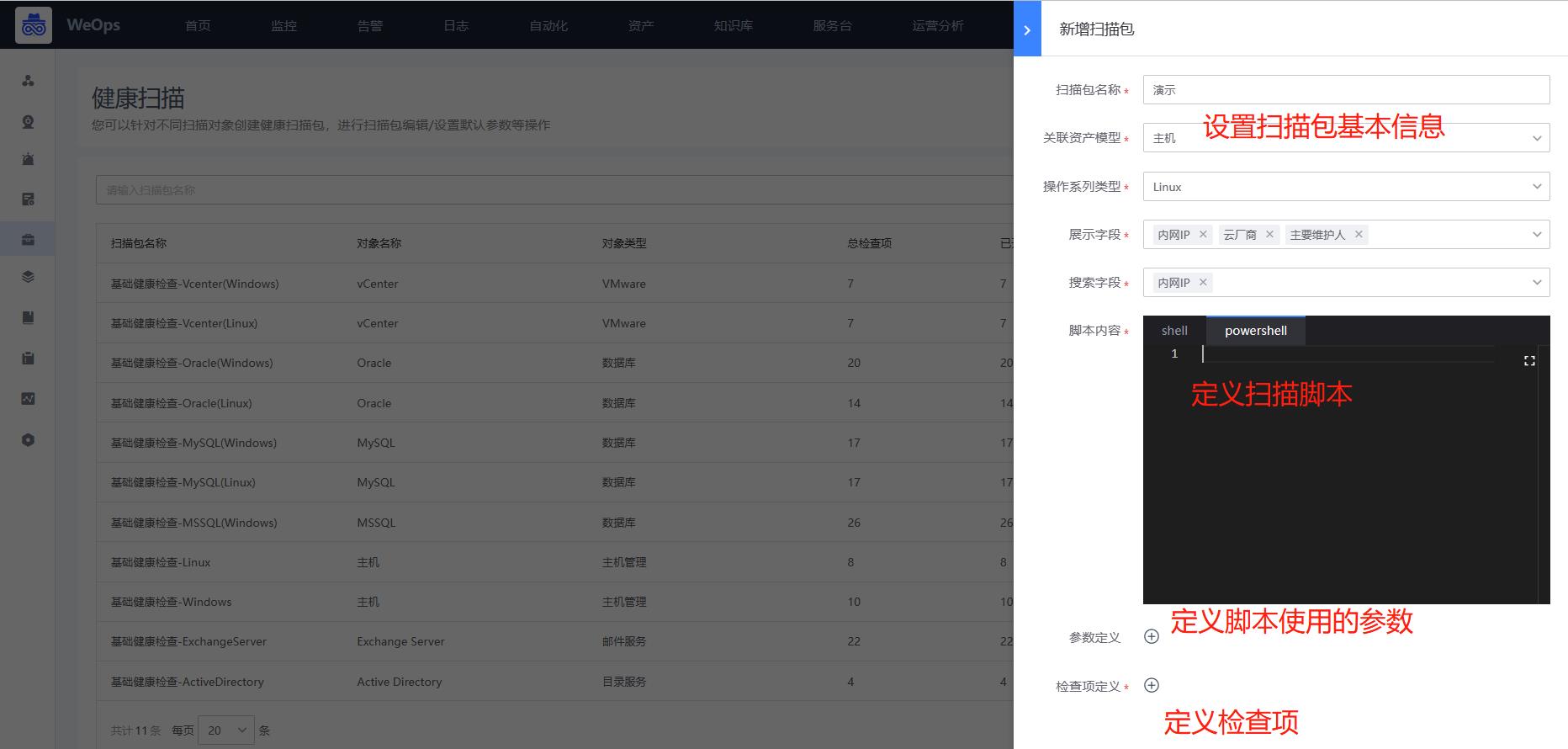
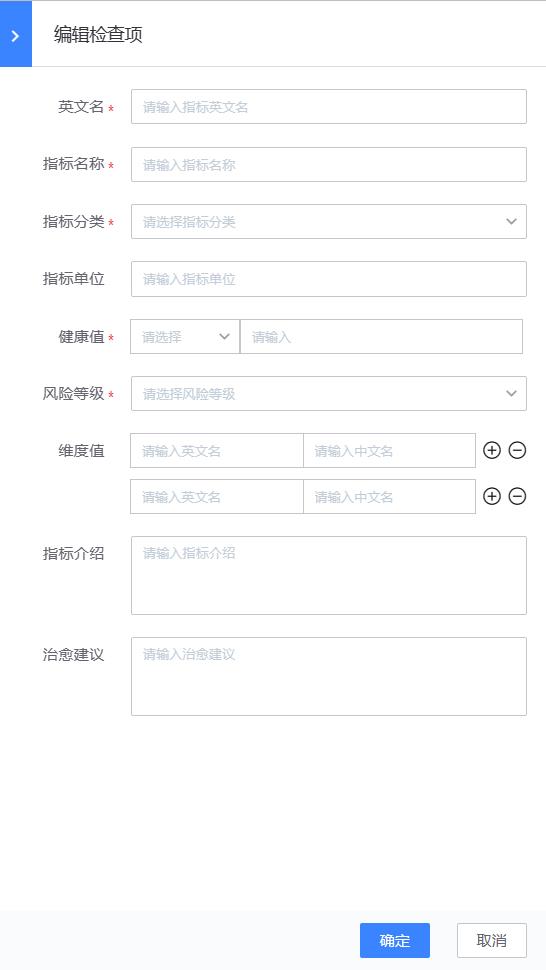
step2:进行扫描包设置
路径:管理-管理中心-扫描包管理
扫描包创建完成之后,可以在“扫描包管理”界面进行检查项的简单编辑,点击“检查项”按钮,可以进行检查项的设置
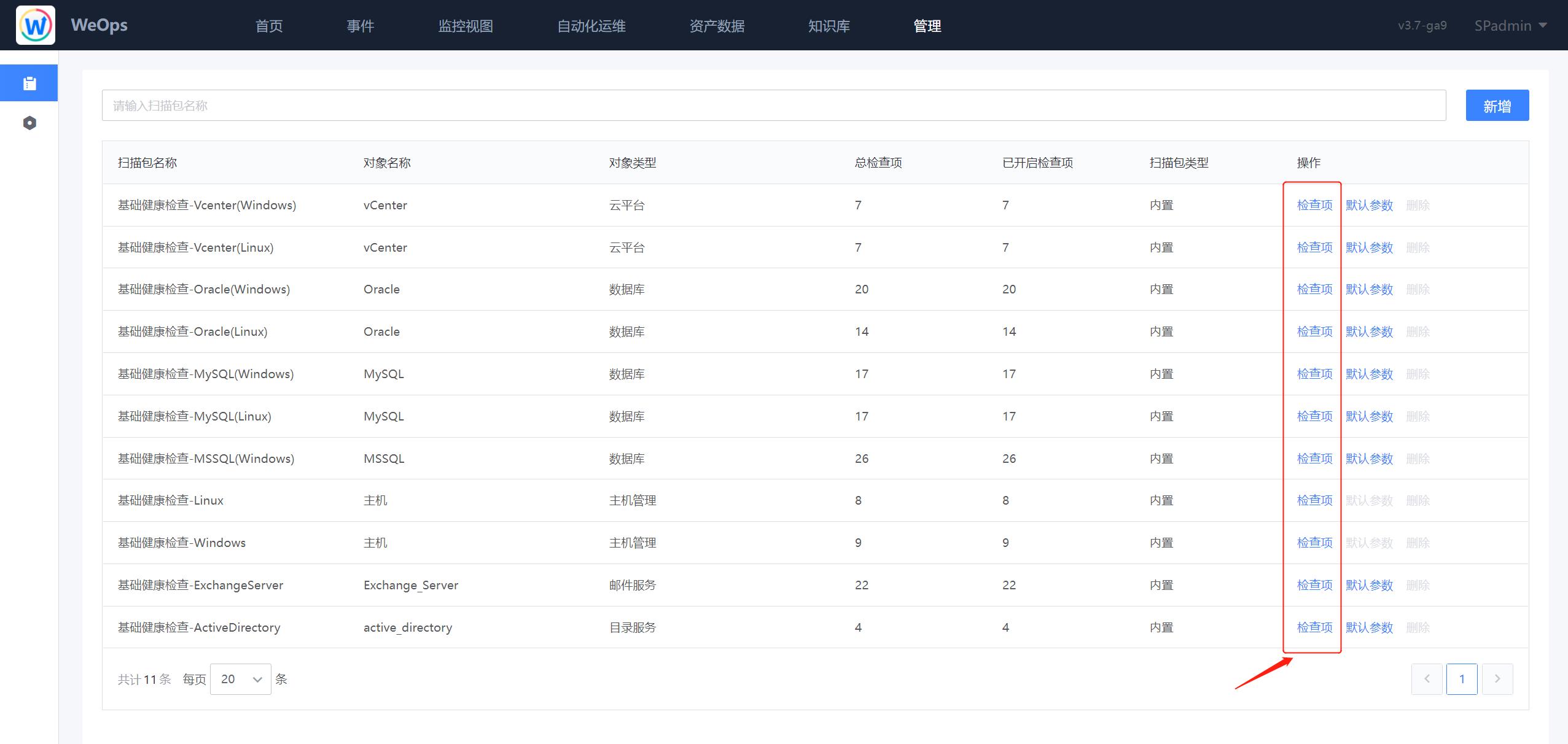
在检查项的设置界面,可以进行检查项部分信息的重新编辑,包括阈值、指标介绍、治愈建议,也可以进行检查项的启停,对于不使用的检查项可以进行关闭。

在“扫描包管理”界面,点击“默认参数”按钮,可以进行默认参数的设置,设置成功后,在使用该扫描包时,对应实例的参数凭据无需再次输入。
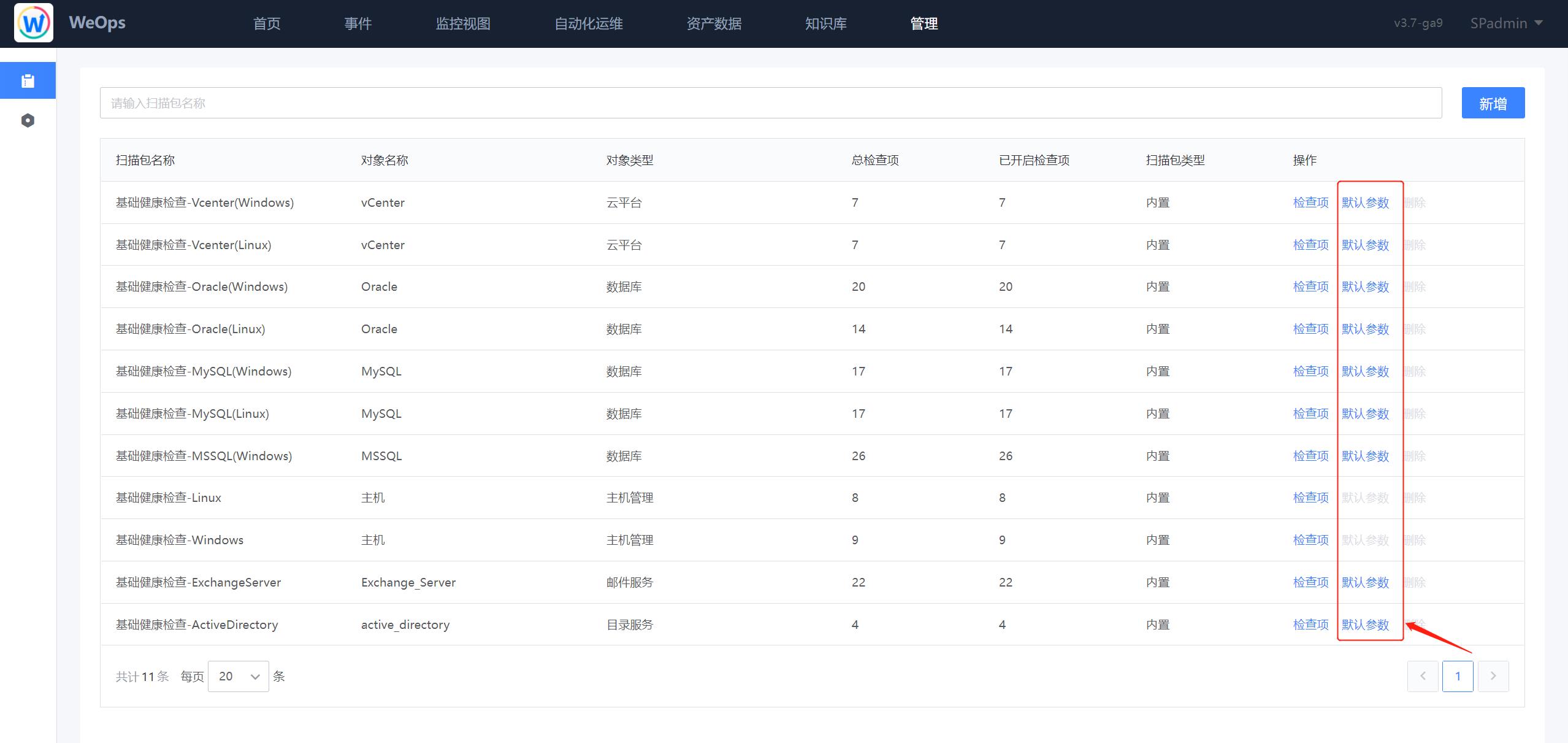
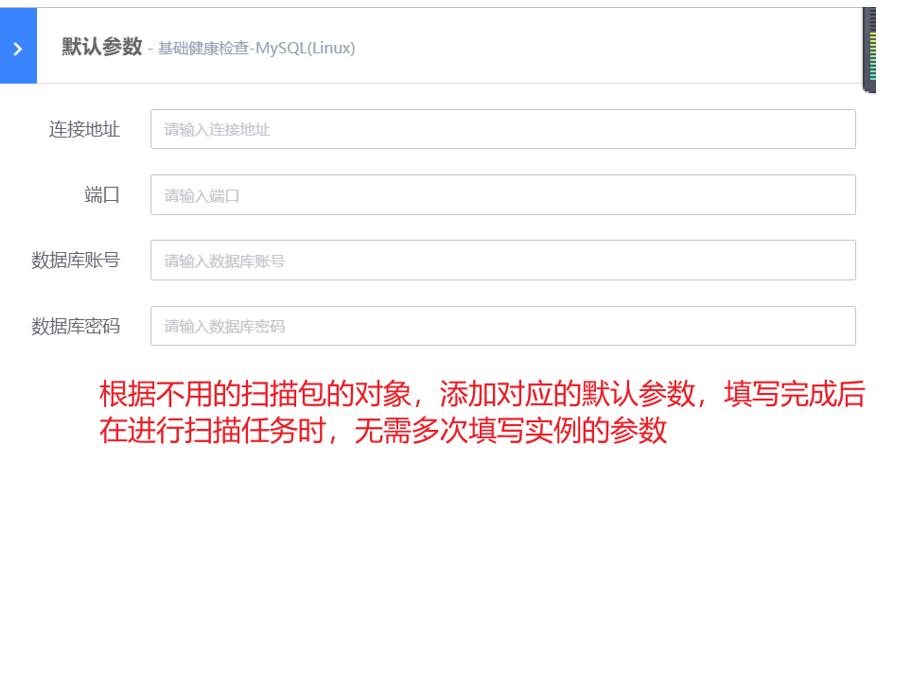
step3:进行扫描包使用
路径:自动化——健康扫描
- 扫描包设置成功后,即可在自动化运维-健康扫描中使用,创建健康扫描任务,选择对应的扫描包和对象,按照设置的周期进行扫描,并呈现扫描的结果
- 如下图为任务创建,可选择扫描包,以及对应资源,并可以选择扫描周期,也可以选择邮件通知人,选定邮件通知人后将在该任务扫描完成后接收到任务完成情况的邮件。
- 任务详情:如下图为任务详情界面,分为基本信息、任务概览、实例列表。基本信息展示该改任务的扫描时间、扫描包信息、扫描对象列表等信息;任务概览展示了该任务整体的健康状态、通过率、资源扫描情况以及警告/危险的指标情况,可以对任务概览进行PDF的导出;实例列表则将该任务下所有的扫描实例的情况进行展示。
- 实例详情:通过任务详情中的概览页/实例列表页可以查看具体实例的扫描报告,针对实例详情可以导出为PDF格式文件。
定时任务
背景介绍:IT运维部门常常有一些定时执行的任务,比如定时数据库备份等
整体步骤:新建作业(选择执行策略和工具)——按照策略执行——查看执行结果
新建作业
路径:自动化-定时作业
如下图,支持选择对应工具和资产,并且设置执行策略,其中定时作业支持无agent模式,即主机无需安装agent也可执行对应脚本,设置任务时需要填写对应凭据。
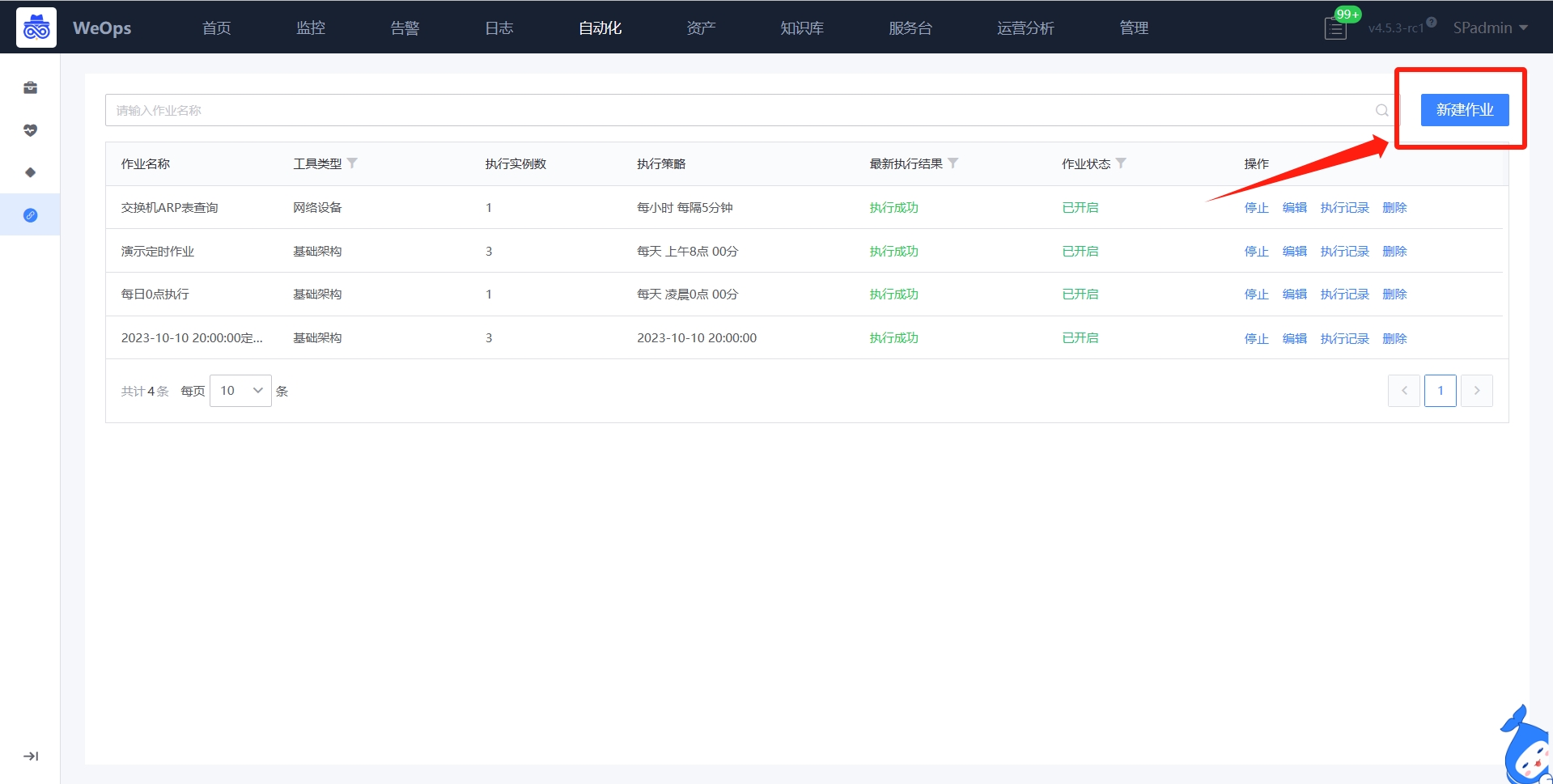
执行策略:定时执行-选择特定的时间只执行一次;周期执行-设置循环执行的周期,按照周期进行执行
工具类型:支持基础架构和网络设备两类设备的脚本执行
工具名称:与运维工具结合,可以选择现成的运维工具,进行定时作业
资源选择:支持跨业务选择多个资源,批量执行,支持无agent模式周期执行的时间语法采用crontab语法,具体说明如下
`数字`:固定的时间点,比如9点,周一
`*/数字`:"每隔",比如每隔2天,每隔15分钟
时间规范通常包含分钟、小时、天、月以及星期等信息,例如分钟可以是0-59的任意一个数字,小时可以是0-23,日可以是1-31,月(1-12),周(0-6)(星期天为0或者7)
比如:每隔2小时执行一次(0 */2 * * * ),每日凌晨1点执行一次(0 1 * * *),每周日凌晨1点执行一次(0 1 * * 0)按照策略进行执行
路径:自动化-定时作业
作业创建完成之后,可以在列表看到该作业的情况,作业默认为开启,支持手动关闭,任务开启时按照执行策略进行自动执行,并在列表中展示最近一次的执行结果。
查看执行记录
路径:自动化-定时作业
作业每次执行结束后,会记录该次的执行情况,点击执行记录,可以查看具体的执行返回情况。
文件分发
背景介绍:让需要进行一次性传输文件的运维人员,可以在这里快速的执行文件的传输,并得到结果
整体步骤:新建任务——执行任务——查看执行结果
路径:自动化-文件分发
如下图,点击“新建按钮”,进行文件分发任务的创建
填写内容如下
【基本信息】
任务名称:分发文件的任务名,方便后续在执行历史中有迹可循
超时时长:分发文件的超时设置,当文件传输时间超过时将会自动关闭,结果被视为 "执行超时"
上传 / 下载限速:由于蓝鲸管控平台 Agent 默认的配置是会根据服务器带宽和资源使用情况进行限制的,防止出现因为执行的任务导致拖垮业务的机器;所以当用户自己确认机器允许更大限度传输时,通过开启限速设置可以提高传输的速率
【源文件】
分发的源文件选择,支持选择 本地文件 或 其他服务器文件
【传输目录】
目标路径:文件分发到目标服务器的绝对路径地址
传输模式:强制模式不论目标路径是否存在,都将强制按照用户指定的目标路径进行传输(不存在会自动创建);严谨模式严谨判断目标路径是否存在,若不存在将直接终止任务
执行账号:文件分发的目标服务器相关的账号,如 Linux 系统的 root 或者 Windows 系统的 Administrator
目标服务器:从资产管理获取执行的目标服务器任务创建完后,执行点击“确定”,即可立即执行文件批量分发任务。
文件分发任务执行完成后,可以在列表中查看最新一次的执行结果,也可以在“执行历史”中查看执行的详细结果。
自动化编排
背景介绍:IT部门想在工单流程设置中引用自动化流程实现自动处理,或想在告警处理中引用自动化流程实现自愈处理。
整体步骤:新建流程(新建-配置节点-设置全局变量)——被服务台流程使用/被告警自愈使用
新建流程
路径:管理-自动化管理-自动化编排
- 用户可以通过对标准插件节点、子流程节点与网关节点的组合,变量的配置与引用,配置出一个业务自动化流程。流程的新建分为以下三步:新建流程,填写流程名称——配置流程节点——配置全局变量
- 第一步:新建流程,填写流程名称
- 如下图,点击流程中“新建”按钮,可进行流程的新建,流程名称是用户用来描述流程模板的,默认值是 “new+时间格式串”,用户可以自行修改。
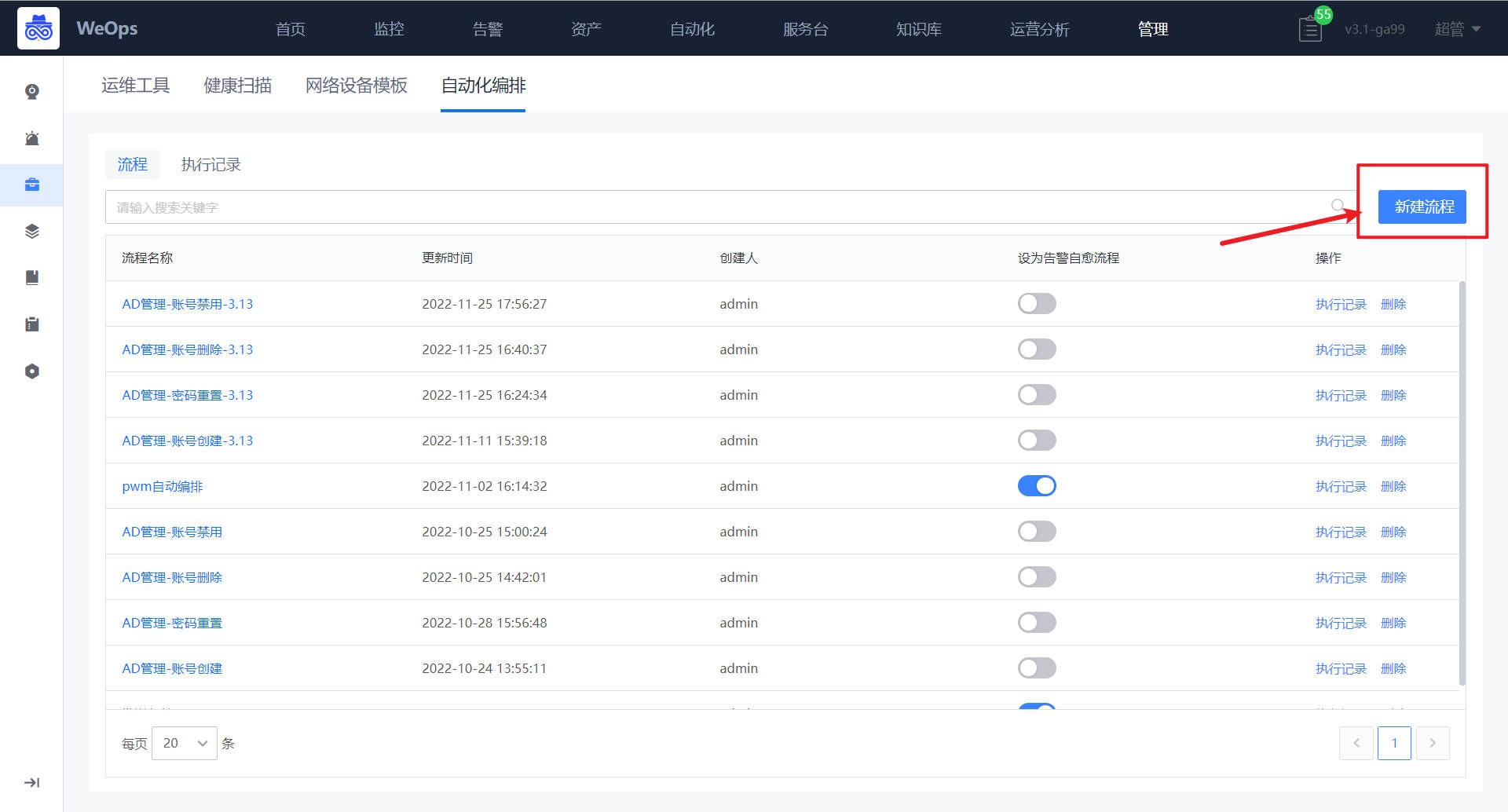
- 第二步:配置流程节点
- 根据实际需求,进行流程节点和拖拽、配置和布局等方面的设置。
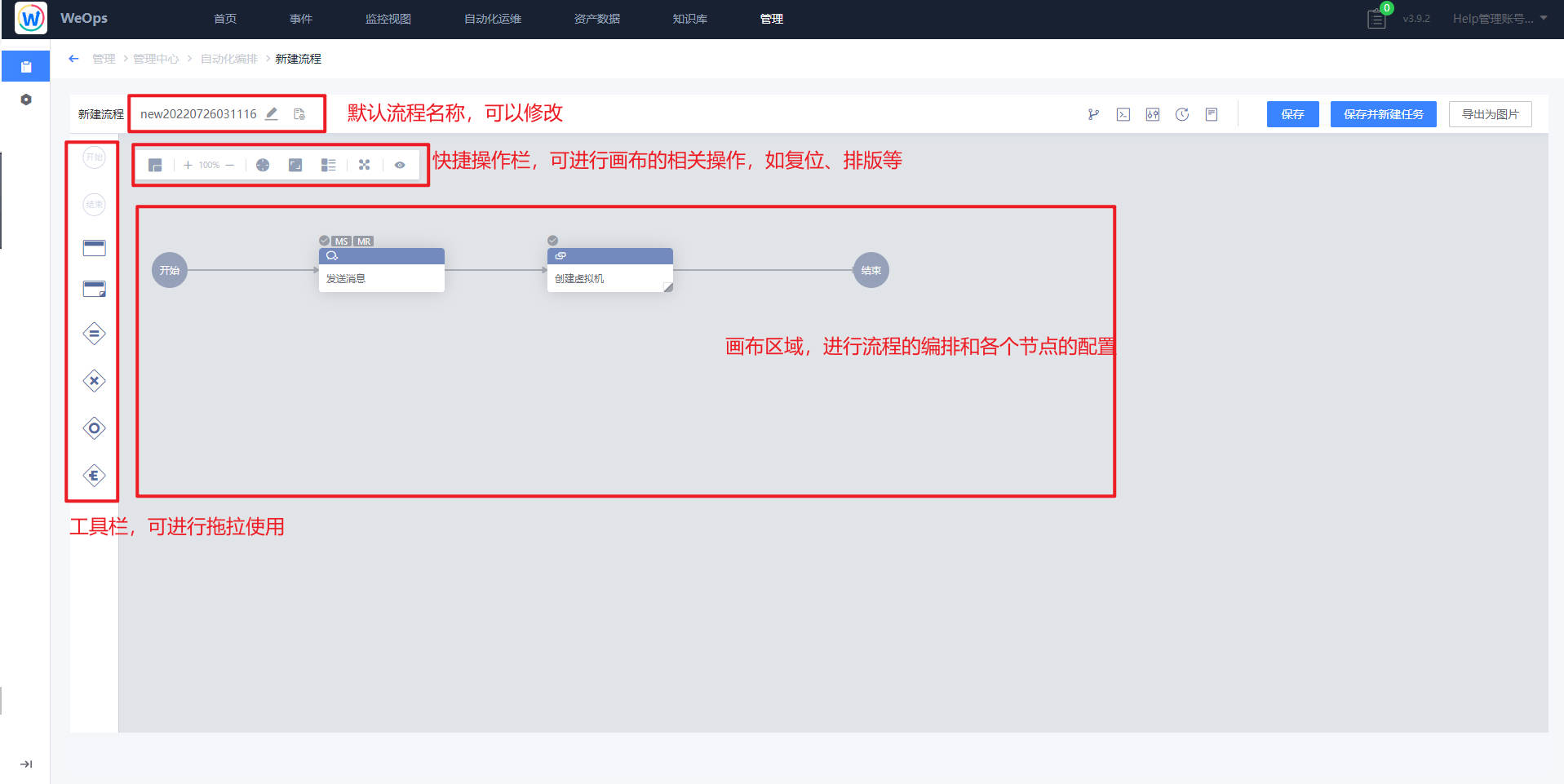
【工具栏说明】
开始节点——标识流程的开始(一般已经默认)
结束节点——标识流程的结束(一般已经默认)
并行网关——标识并行执行的开始
分支网关——标识分支执行的开始
汇聚网关——标识并行或分支的结束
标准插件节点——自动编排内置的最小执行单元,可直接使用内置的插件或使用第三方插件
子流程节点——可以选择用户已经创建的流程模板,在新的流程中引用并作为子流程执行 - 标准插件节点:双击标准插件节点可以配置标准插件节点的参数。其中标准插件类型可以选择已经接入的标准插件
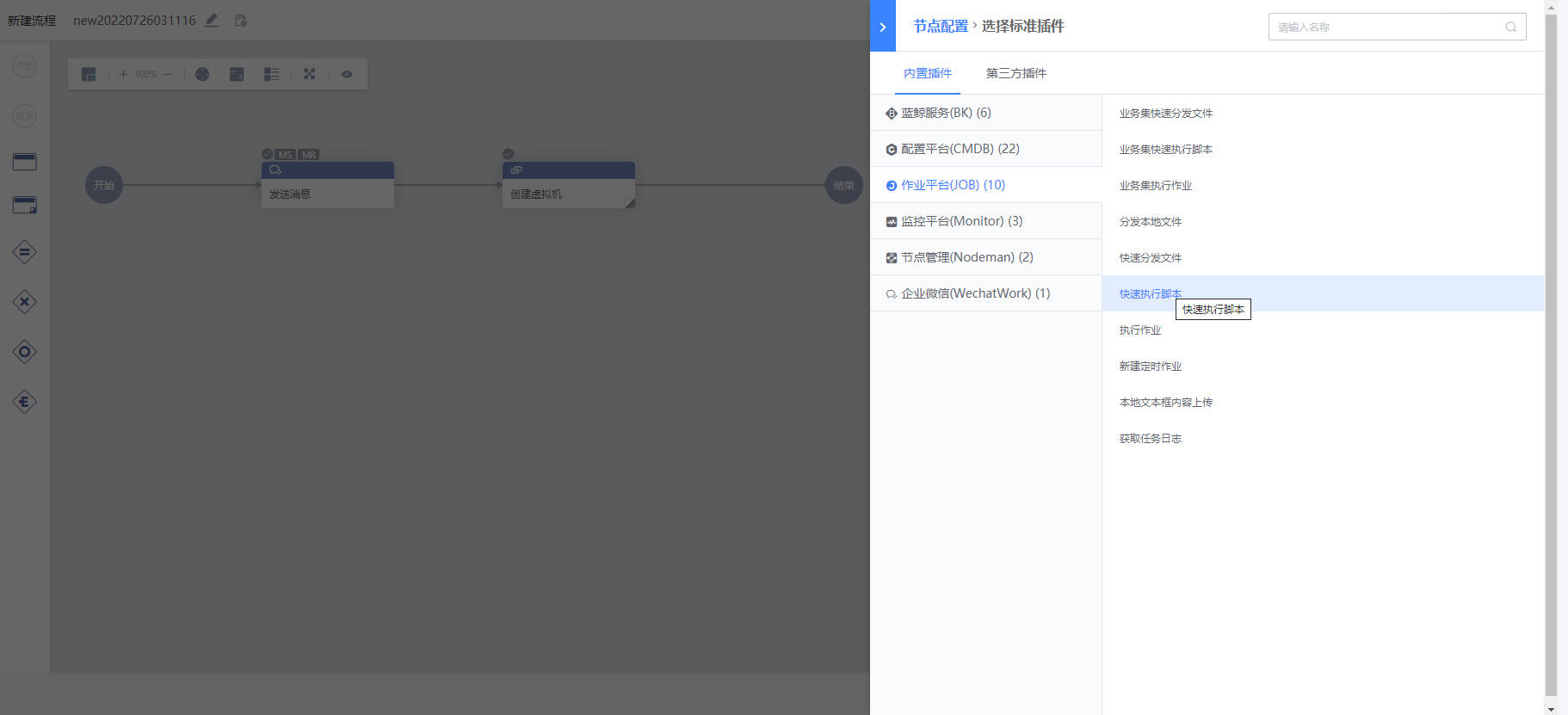
- 每个标准插件的参数一般不同,如“作业平台(JOB)-快速执行脚本”是对应作业平台的快速执行脚本 API,需要填写脚本类型、脚本内容、脚本参数等输入参数,在执行时,会利用填写参数调用 API,然后根据结果把 JOB 任务 ID、JOB 任务链接、执行结果(成功或失败)作为输出参数展示在执行详情中,后续的流程节点也可以引用前面节点的输出参数。

- 子流程节点:子流程节点可以选择用户已经创建的流程模板,在新的流程中引用并作为子流程执行。子流程节点的输入参数是子流程模板单独创建任务时需要填写的任务参数。输出变量是选择的流程模板中勾选了输出属性的全局变量。

- 第三步:配置全局变量
- 全局变量是一个流程模板的公共参数,用户可以在任务节点的输入参数和分支网关表达式中引用
- 全局变量来源有三种:通过任务节点的输入参数勾选生成、通过任务节点的输出参数勾选生成、在全局变量区点击 “新增变量” 生成


被服务台流程使用
路径:管理-管理中心-服务台管理
- 在服务流程创建的过程中,通过使用“标准运维节点”从而可以直接把已经创建好的自动化流程引用到工单流程中。
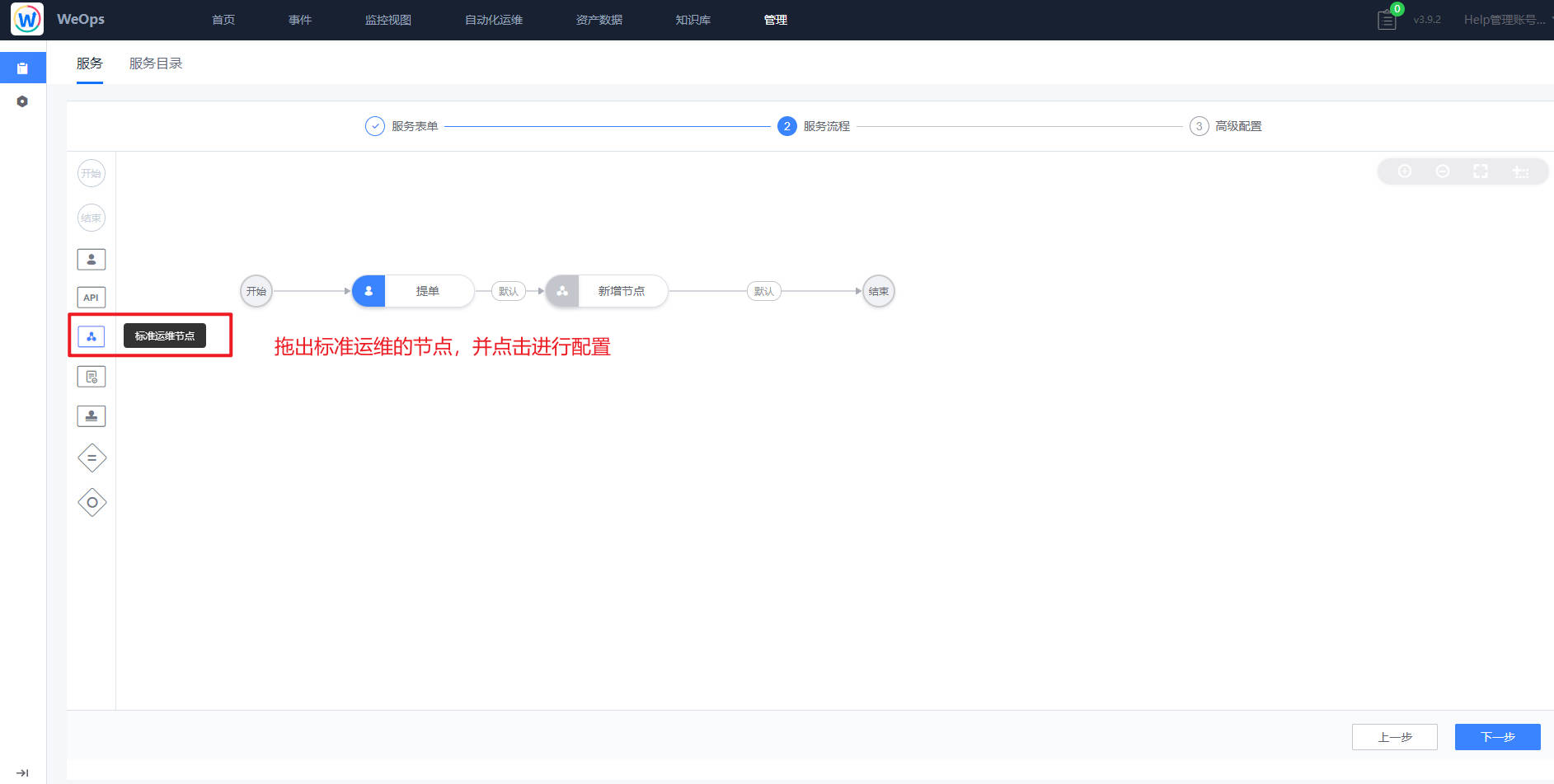
- 在“标准运维节点”的配置中,填写该节点基本信息,选择需要使用的自动流程,若该流程需要填写输入参数则需要填写。
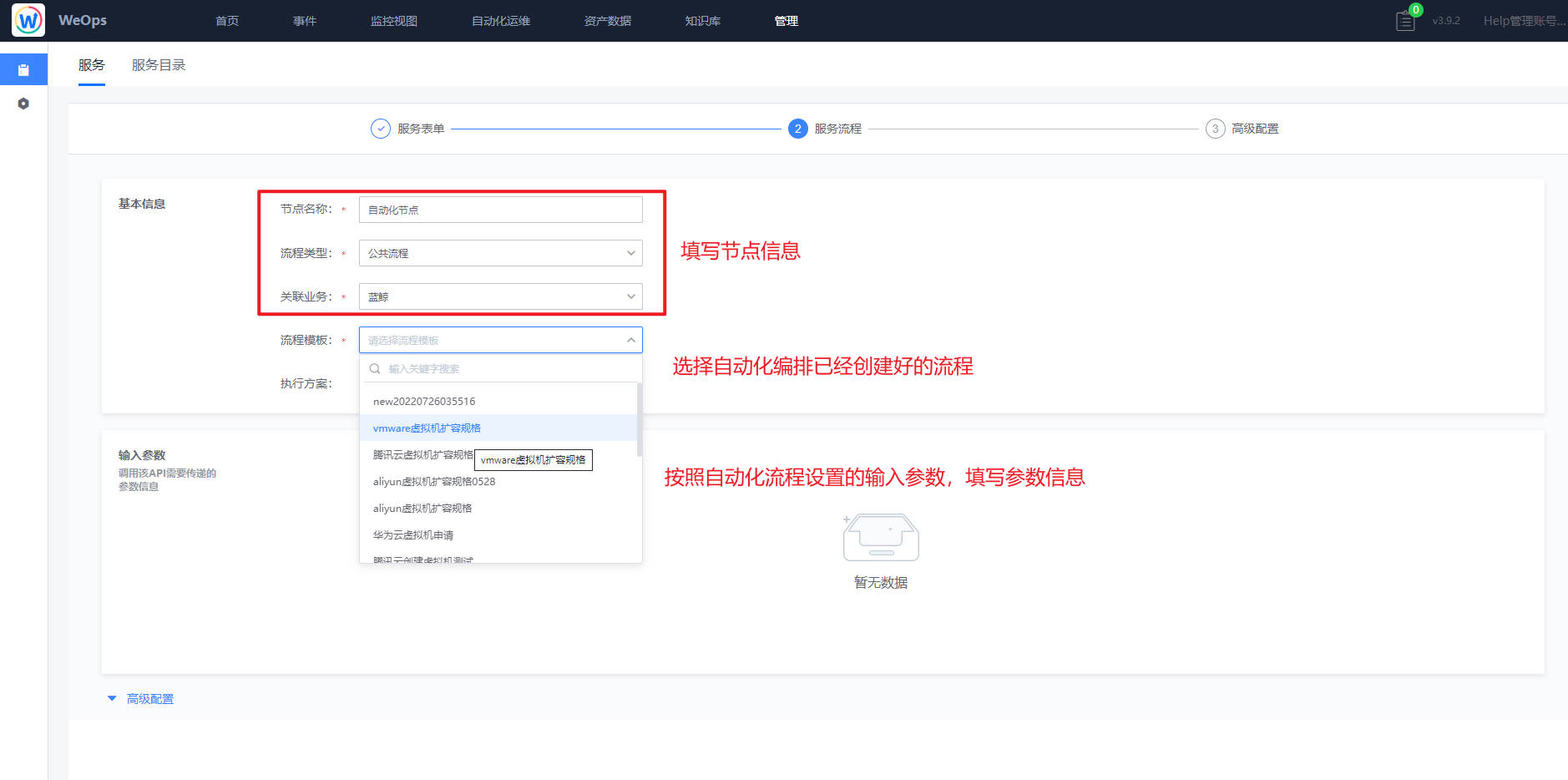
- 工单流程引用自动化流程后,当工单流转至该节点时,会自动调用自动化流程。
告警自愈使用
路径:管理-管理中心-告警管理-告警处理(自动处理)
- 在“管理中心-自动化编排”中把对应流程勾选上“设为告警自愈流程”
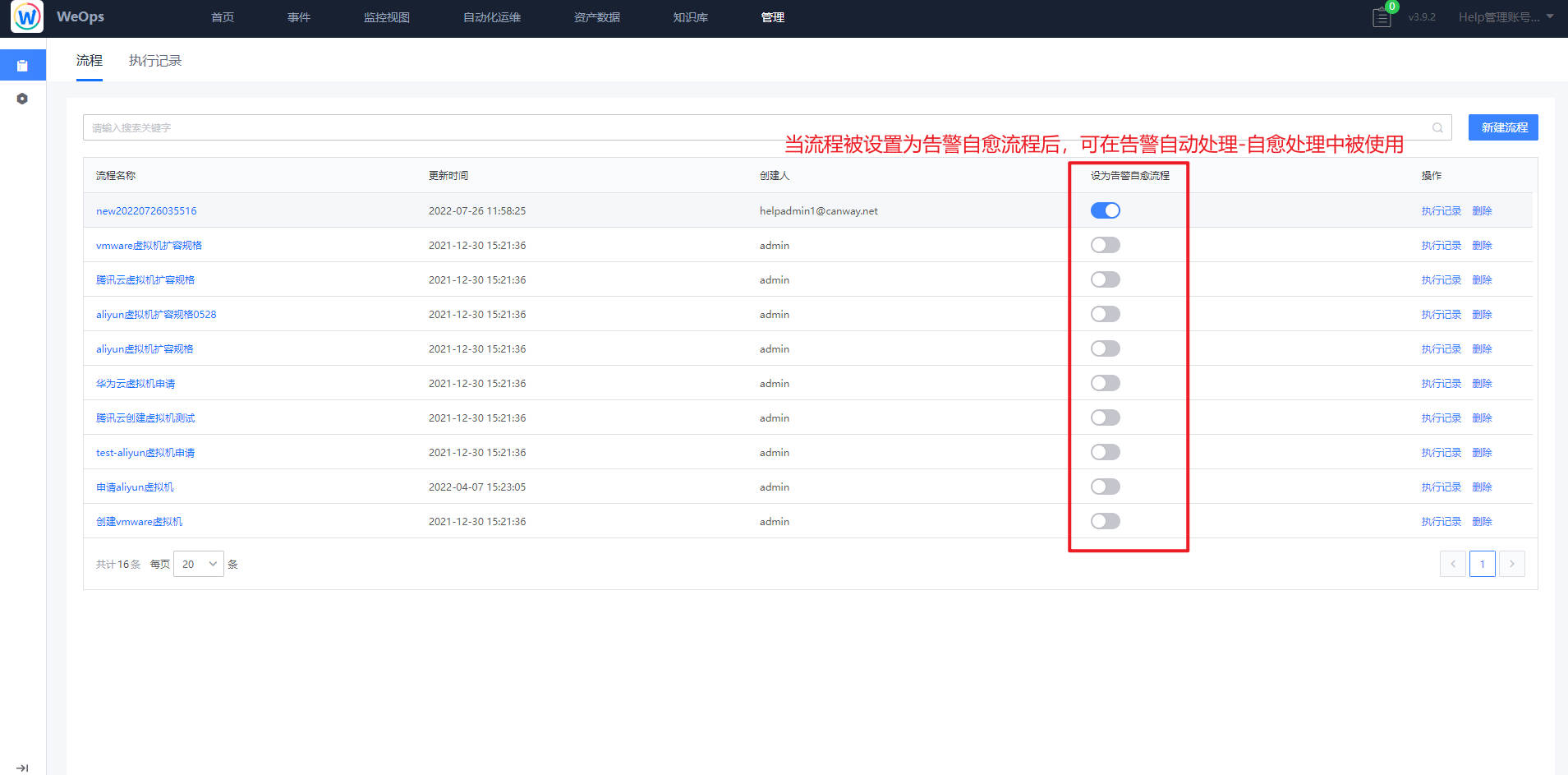
- 在“管理中心-告警管理-告警处理(自动化处理)”中,点击新建按钮,在新建的自动化处理策略中,填写基本信息、选择告警对象和规则、选择“自愈处理”并选择对应的自愈流程。
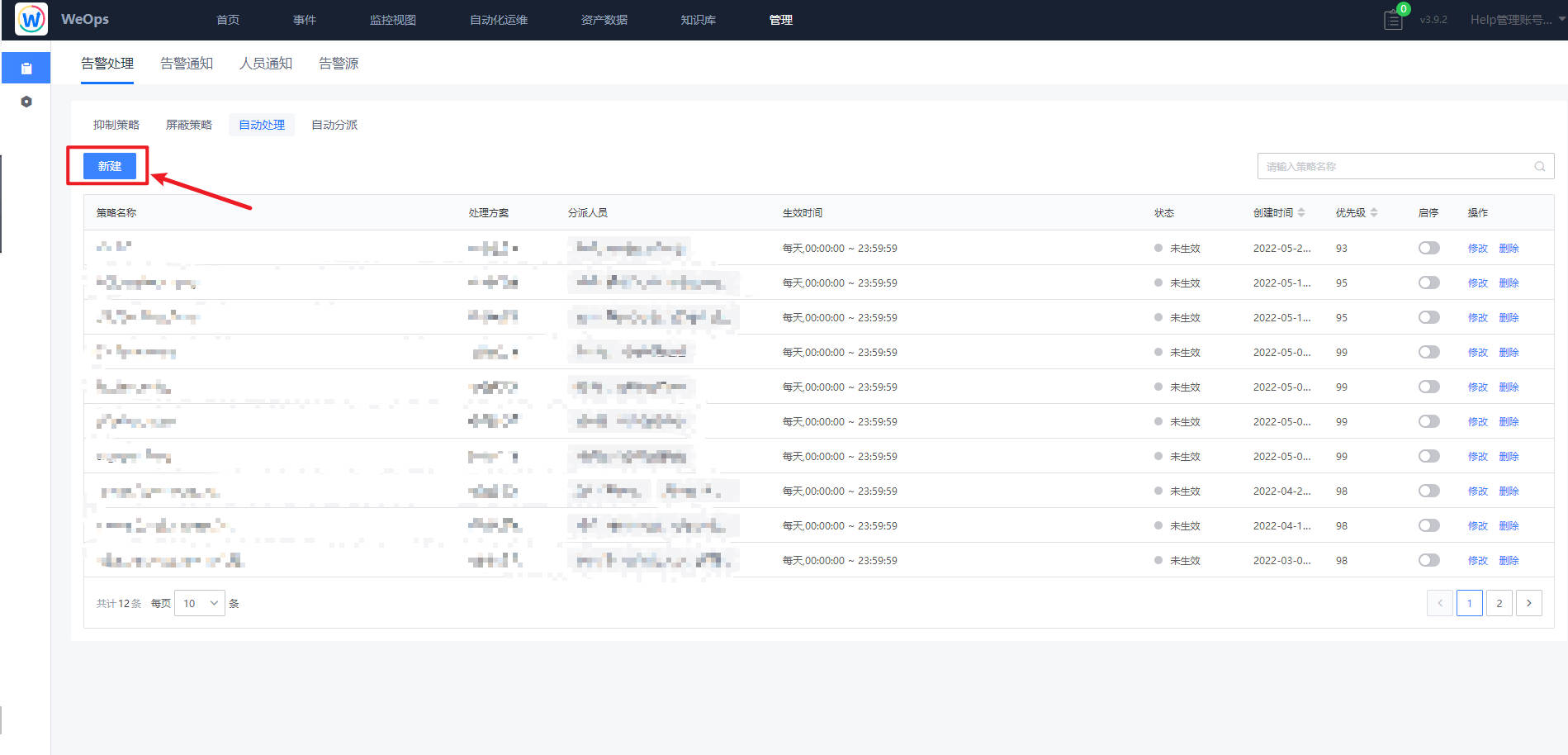

IT服务台配置
服务台-服务流程配置
背景介绍:为了贴合客户使用场景,在IT服务台中增加常用流程,需要在后台进行服务流程的表单和流程节点的配置。
整体步骤:服务目录配置——流程配置(流程信息-配置流程-启用配置)——服务配置——SLA设置(服务模式-服务协议-服务使用)——服务台提单
服务目录配置
路径:管理-管理中心-服务台管理-服务目录
- 如下图,服务目录为整体服务内容的管理视图及入口。可对服务目录进行新增,编辑,删除,排序等操作。当服务目录下有子目录时,父级目录将无法删除。将子目录删除后方可删除。
- 在“服务台管理-服务目录中”可以新建各个层级的服务目录,在各个层级中可以新增服务流程,
- 在服务目录中可将现有服务流程移除,服务的移除仅代表从该服务目录移除,并不会删除服务。从该服务目录移除后,用户在IT服务台提单时,选择原服务目录后,将看不到被移除的服务。
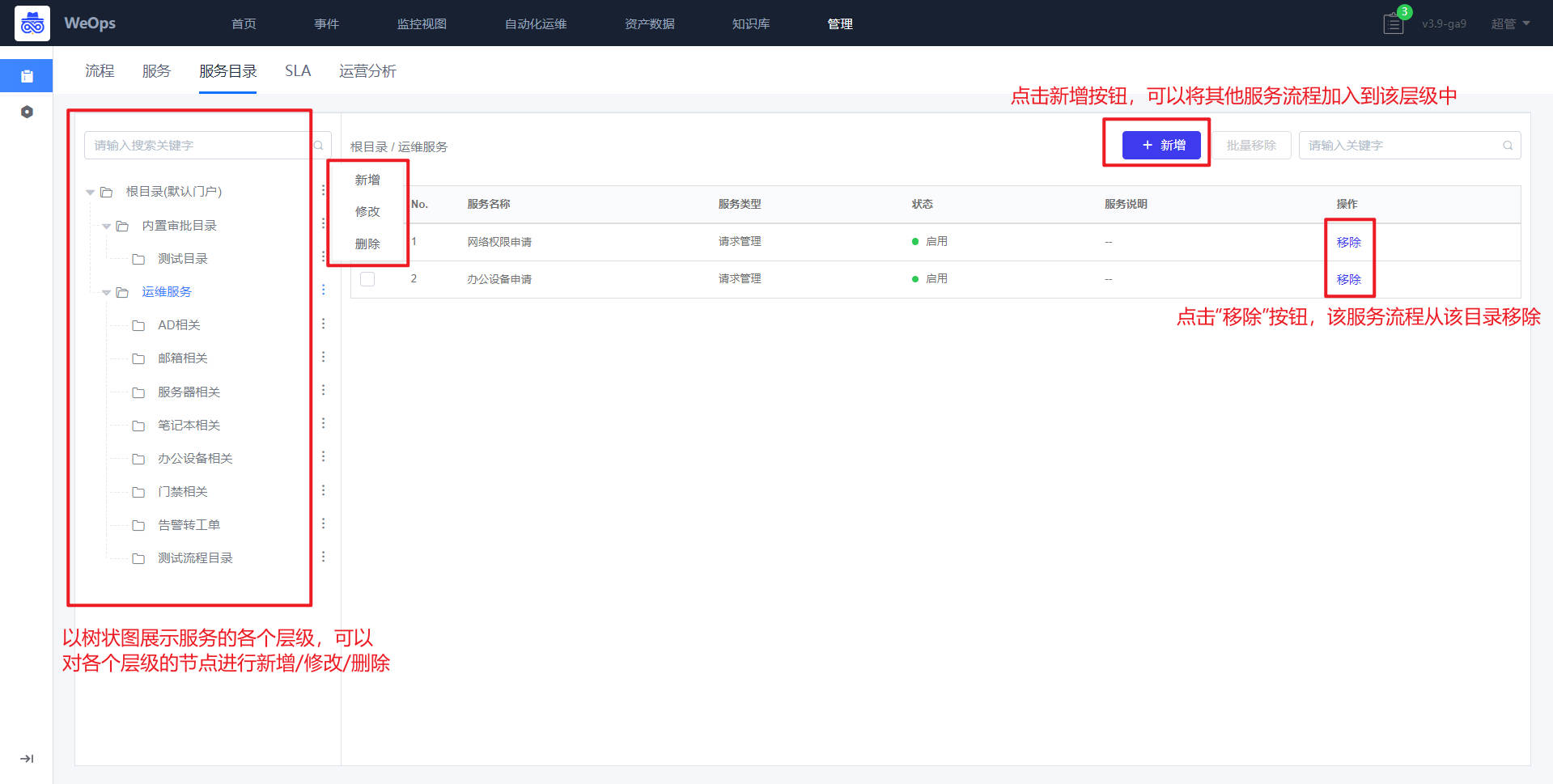
流程配置
路径:管理-管理中心-服务台管理-流程
- 流程分为流程设计和流程版本,流程新建完成部署后会形成一个流程版本,以后每修改一次流程并部署都会形成一个版本
- “流程设计”的列表页展示了所有服务流程的基本信息和状态,可进行新增和删除等操作。
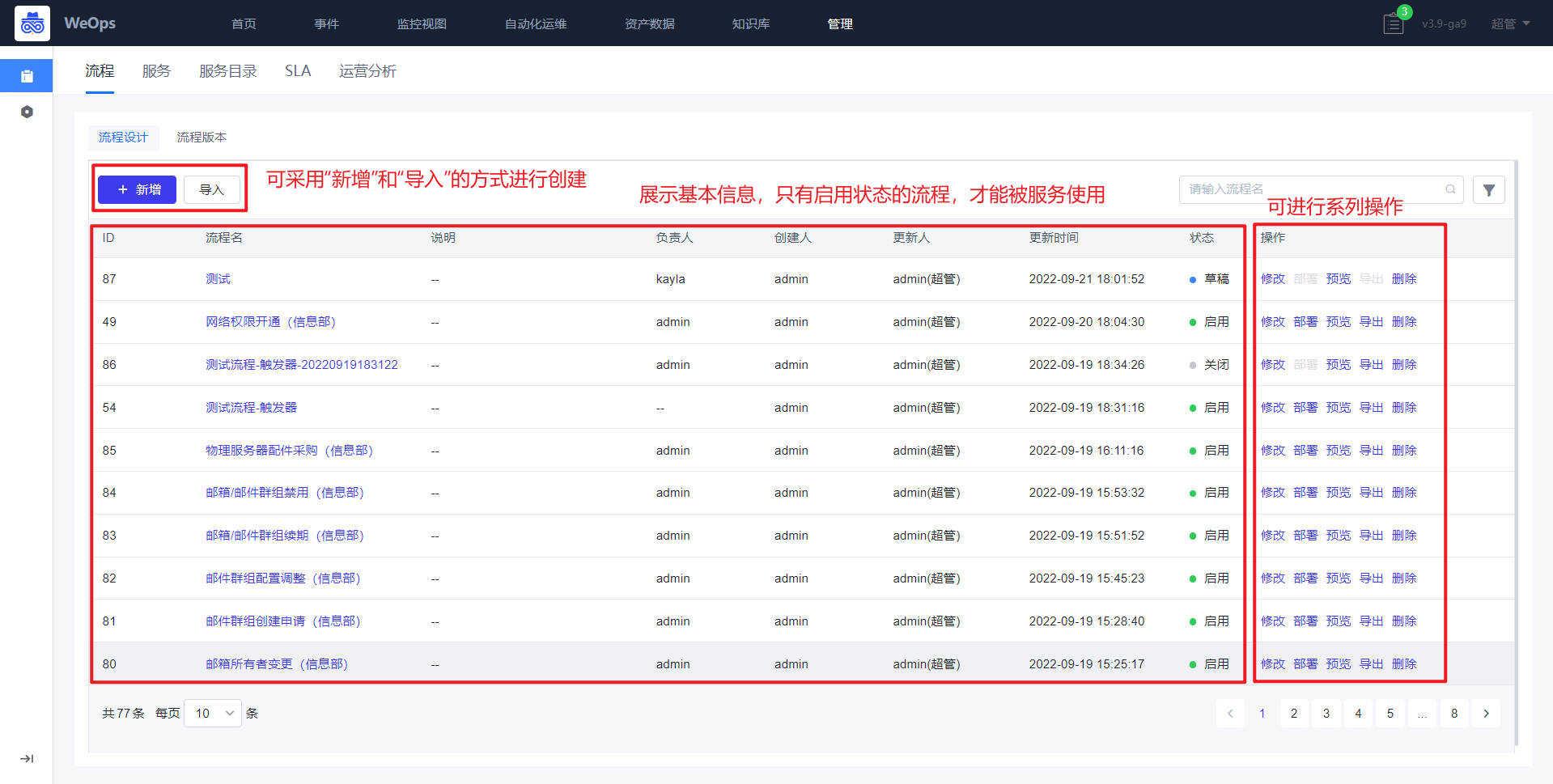
- 服务流程的配置步骤一般分为三步,分别为:填写流程信息、配置流程和启用配置。
- 步骤一:填写流程信息
填写流程的基础信息,包括:名称、基础模型(可使用内置的模型)、是否关联业务、负责人和流程说明等
- 步骤二:配置流程
当填写完成基本流程信息,会进入到流程节点的定义和配置步骤。该部分可以自行决定整体流程的长短,增删节点,节点类型,以及设置每个节点的字段信息。每个流程的默认起点环节为“提单”。
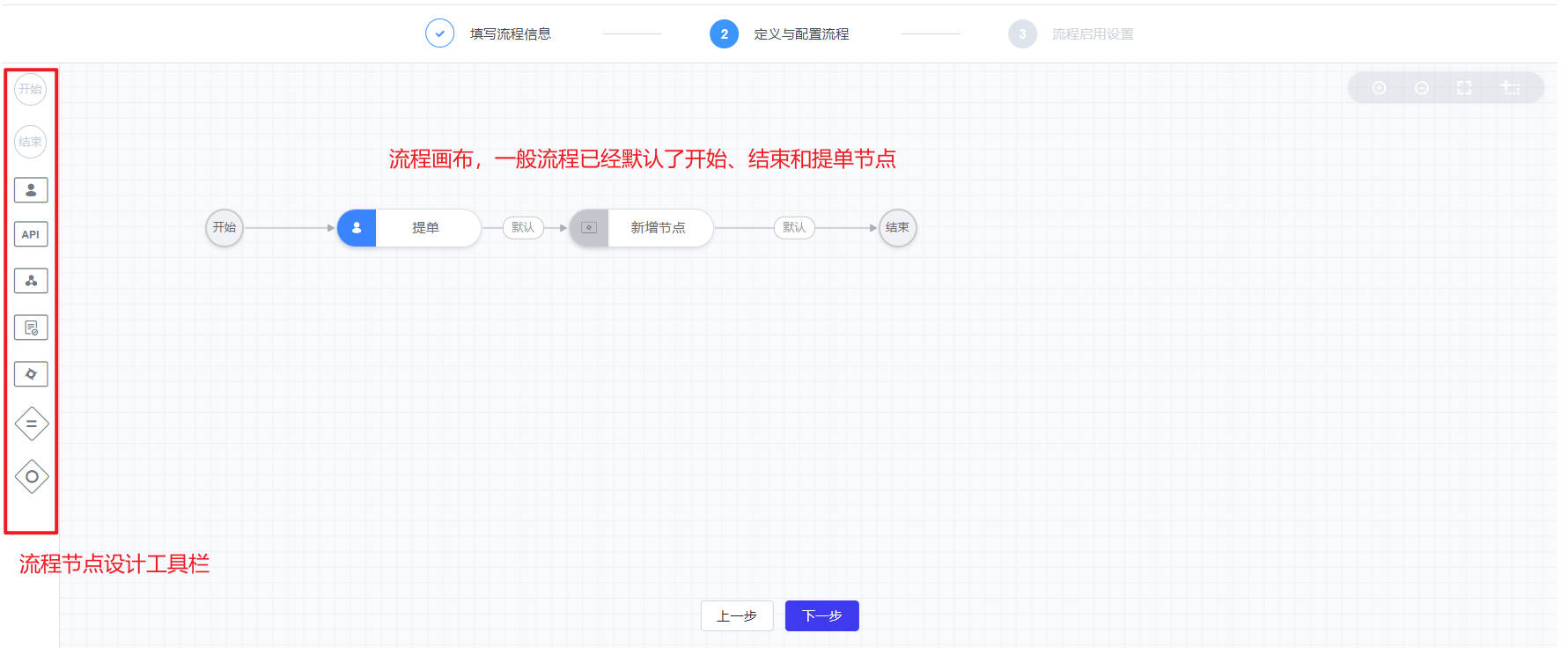
目前节点类型分为:手动节点,API 节点,会签节点,标准运维节点。
* 手动节点:该节点为人工手动进行处理反馈。
* API 节点:该节点为 API 自动处理节点。
* 会签节点:需要多人同时完成同一个处理环节。支持达到一定完成率后可以提前结束进行流转的设置。
* 审批节点:审批动作节点。内置审批内容和审批方式,可配置但无法修改。
* 标准运维节点:可调用蓝鲸平台中标准运维中的公共流程。- 这里重点讲解“提单”(手动节点)和“审批节点”两类节点
- 首先是“提单”节点,每个流程默认都以“提单节点”开始,点击提单节点,进去到该节点的配置页面,各项选择和配置详见下图。
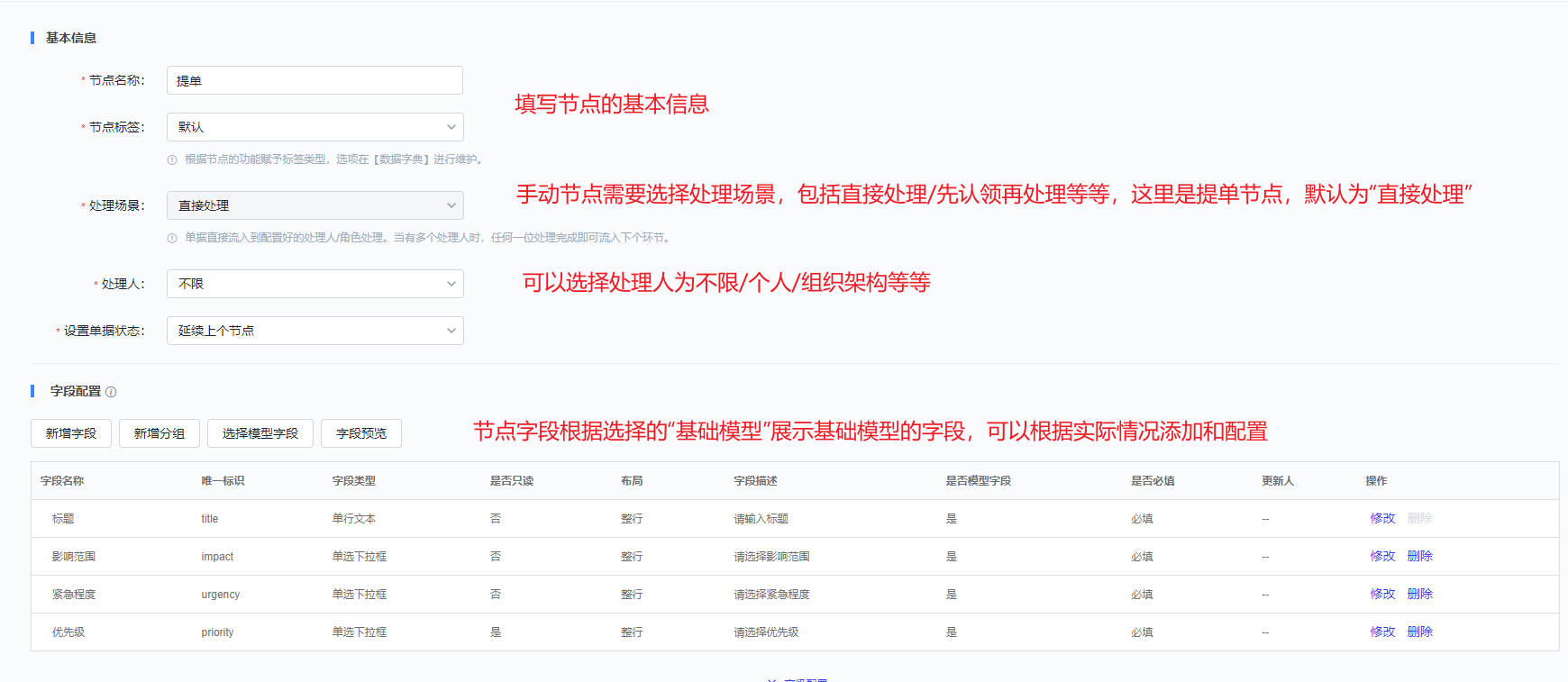
- 关于字段的配置,点击“新增字段”,填写字段名称,自动生成唯一标识,字段支持多类组件,可以通过“字段类型”切换,这里以“单行文本”为例,点击单行文本,可以对该字段进行字段名称、类型、校验、布局等方面的设置,设置成功后,增按照设置在表单的对应位置进行展示。
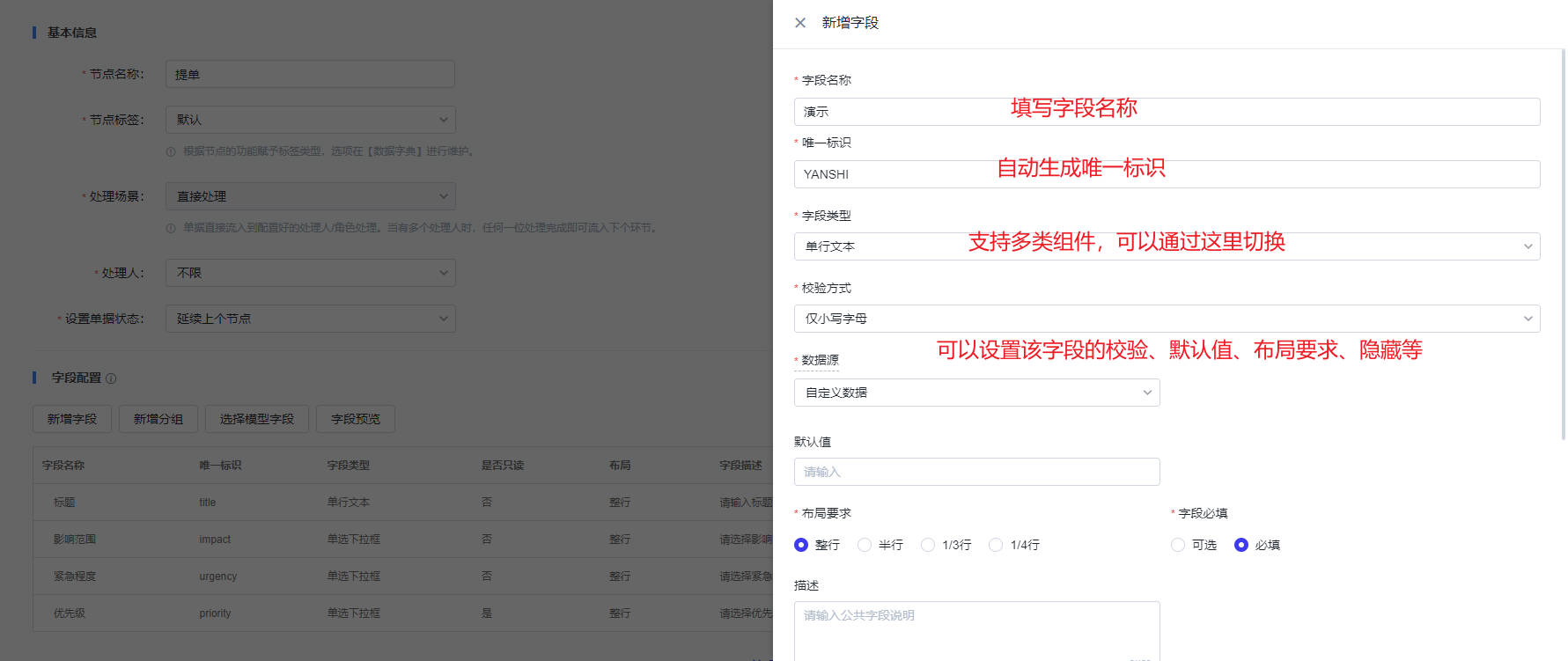
- 再者是“审批节点”,在节点工具栏中选择“审批节点”并拖至画布上,点击该节点,进行节点的配置。在“审批节点”的配置页面,可以进行该节点名称、标签、处理人、是否可以转单等方面的配置。
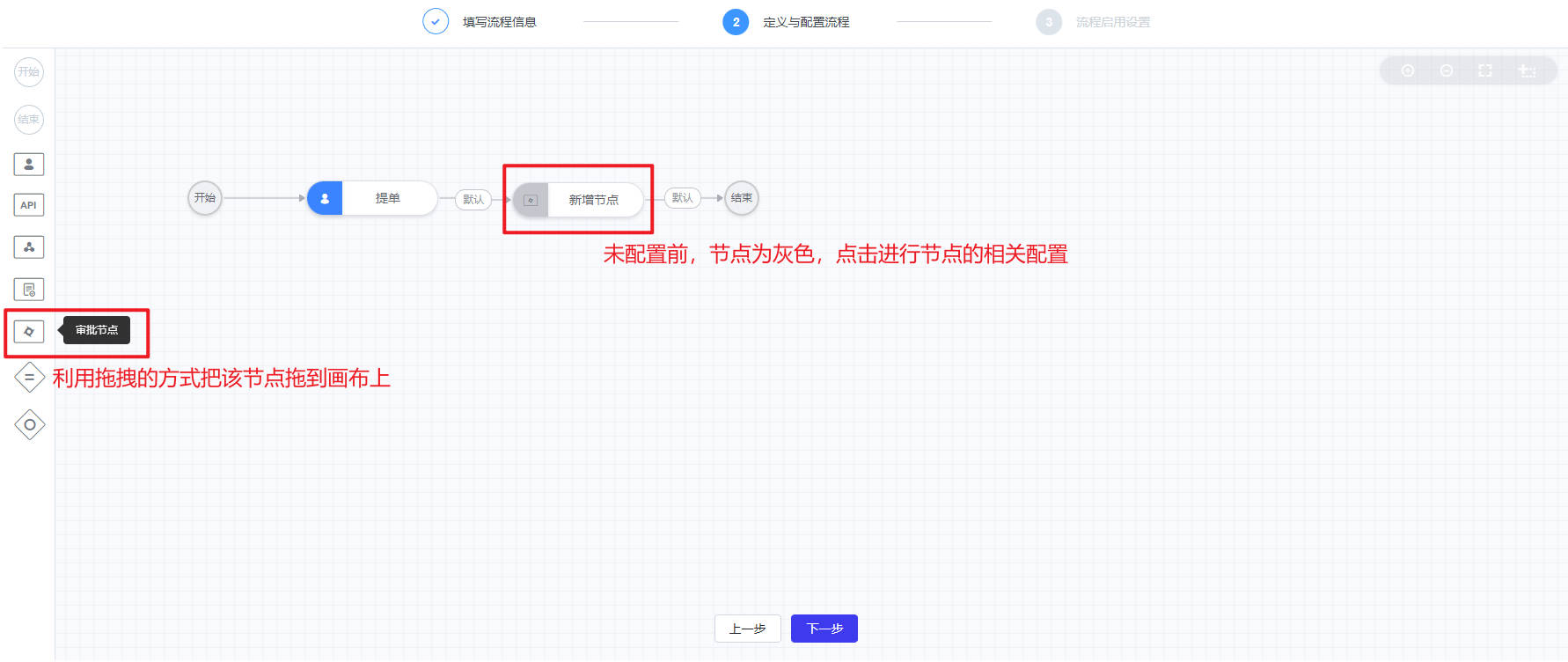
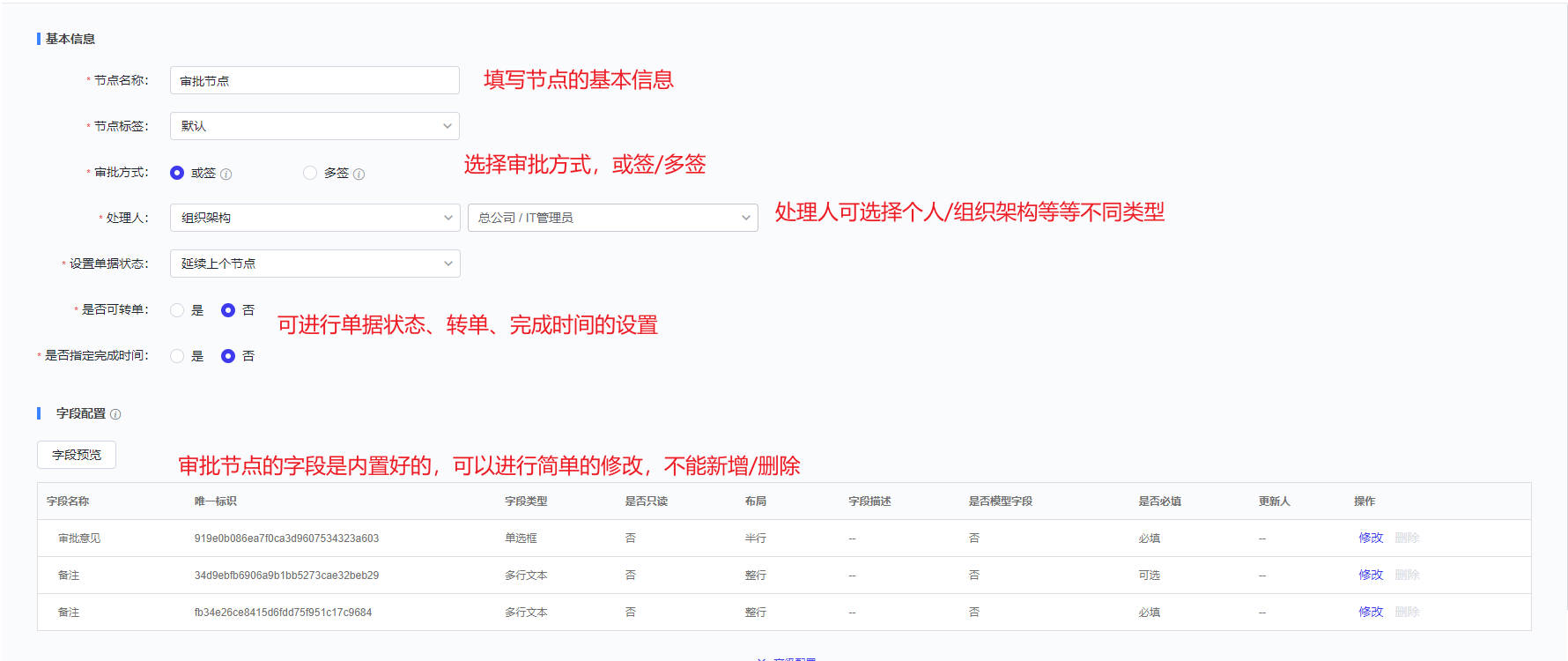
- 步骤三:高级配置
当服务表单和服务流程配置完成后,最后一步为高级高级配置,可设置基础设置、通知方式等。
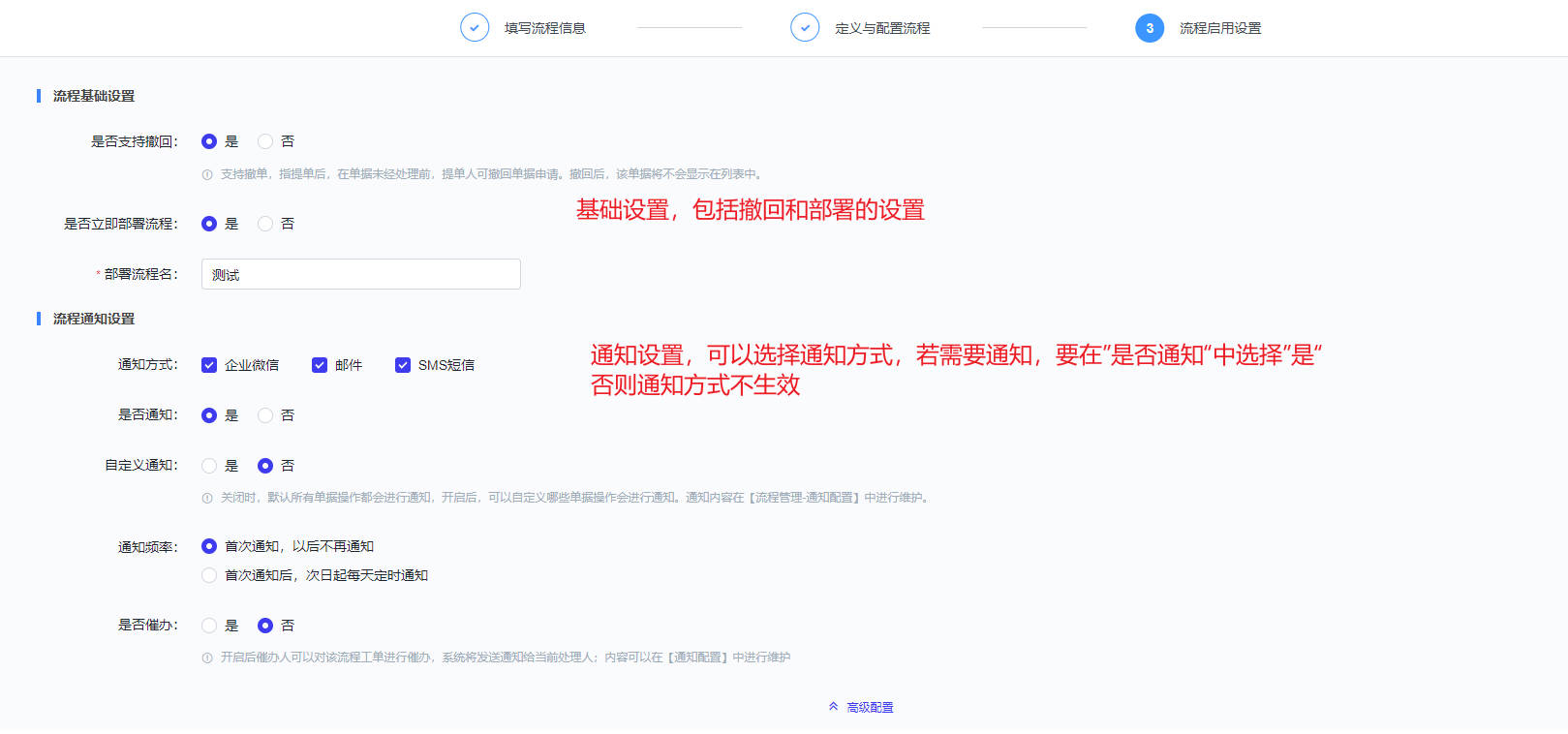
服务配置
路径:管理-管理中心-服务台管理-服务
- 流程配置部署好后,需要新建服务并与之关联,才能够提单。如下图,在服务列表页,点击“新增”按钮,进入到新增页面。
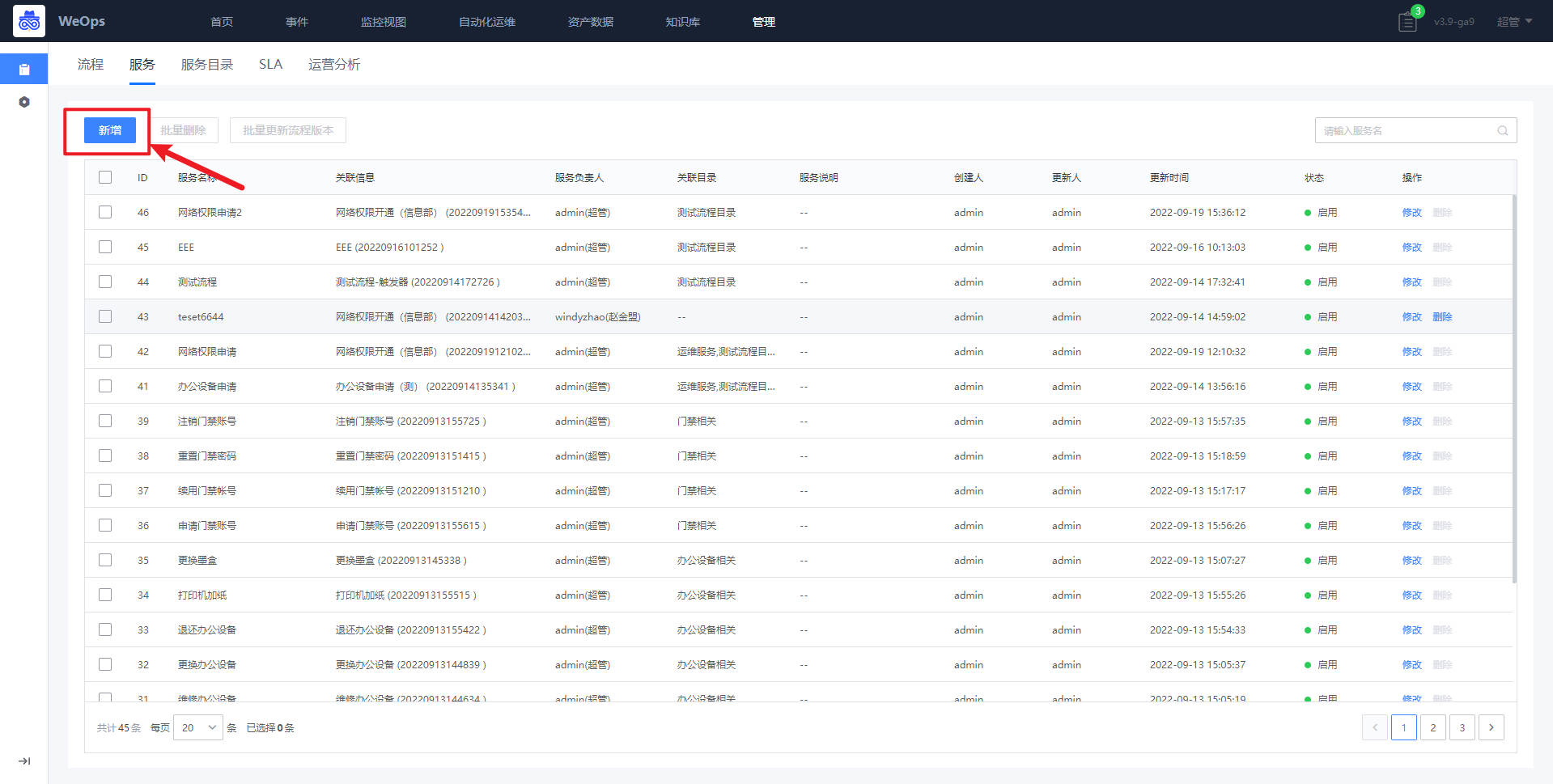
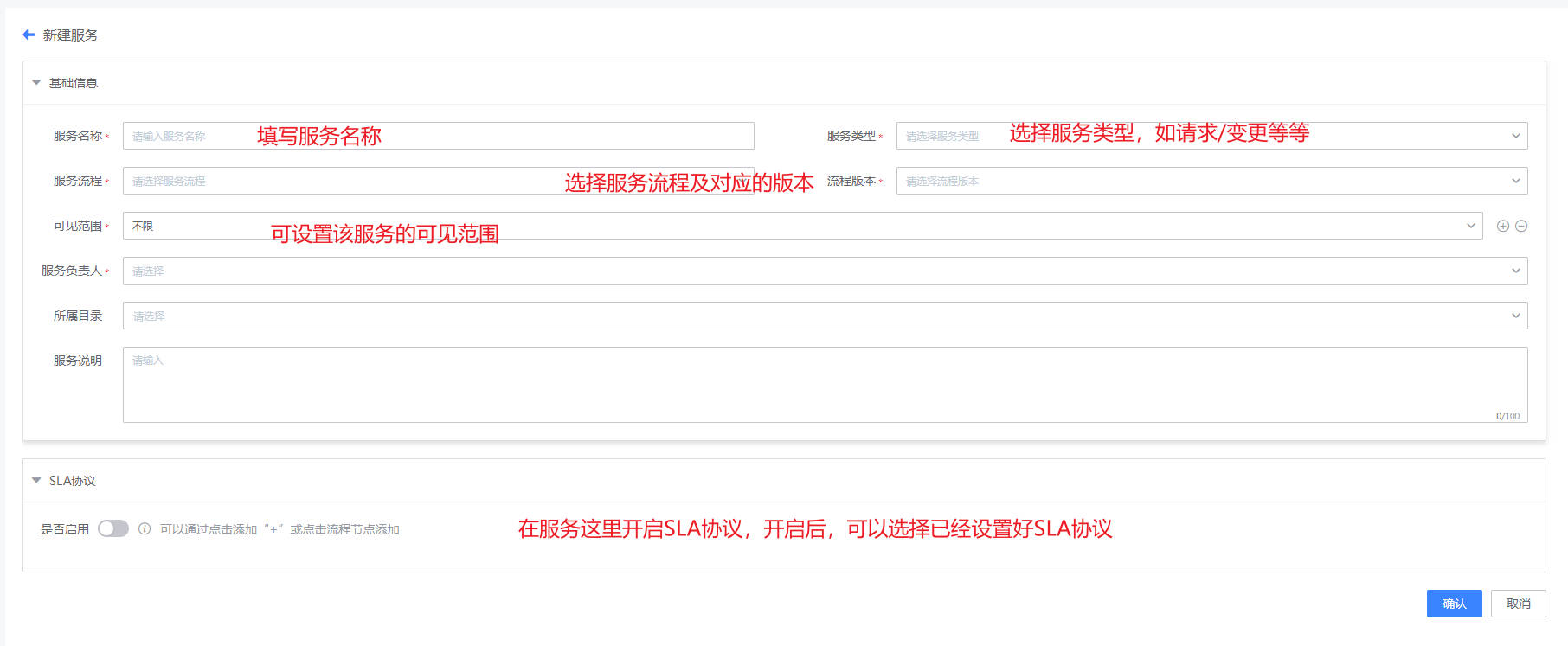
SLA设置
路径:管理-管理中心-服务台管理-SLA
关于SLA设置和使用共分为三步:设置服务模式-设置服务协议-服务流程使用SLA协议
- 步骤一:设置服务模式
通过对工作日,节假日,工作时段的设置,可配置不同的服务时间模板。服务时间将会应用到服务级别协议中,最终体现在对不同服务的受理时效要求上。
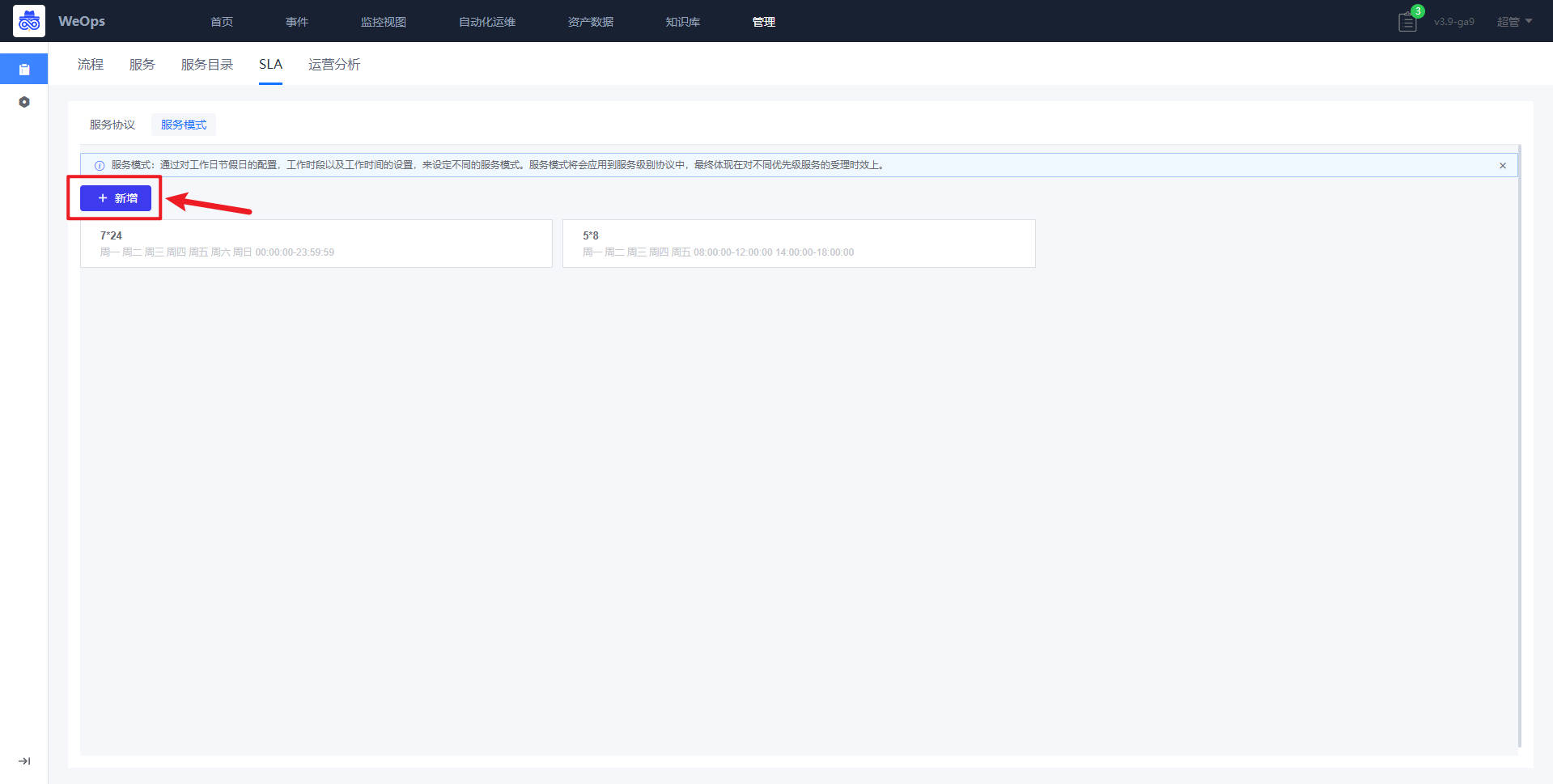
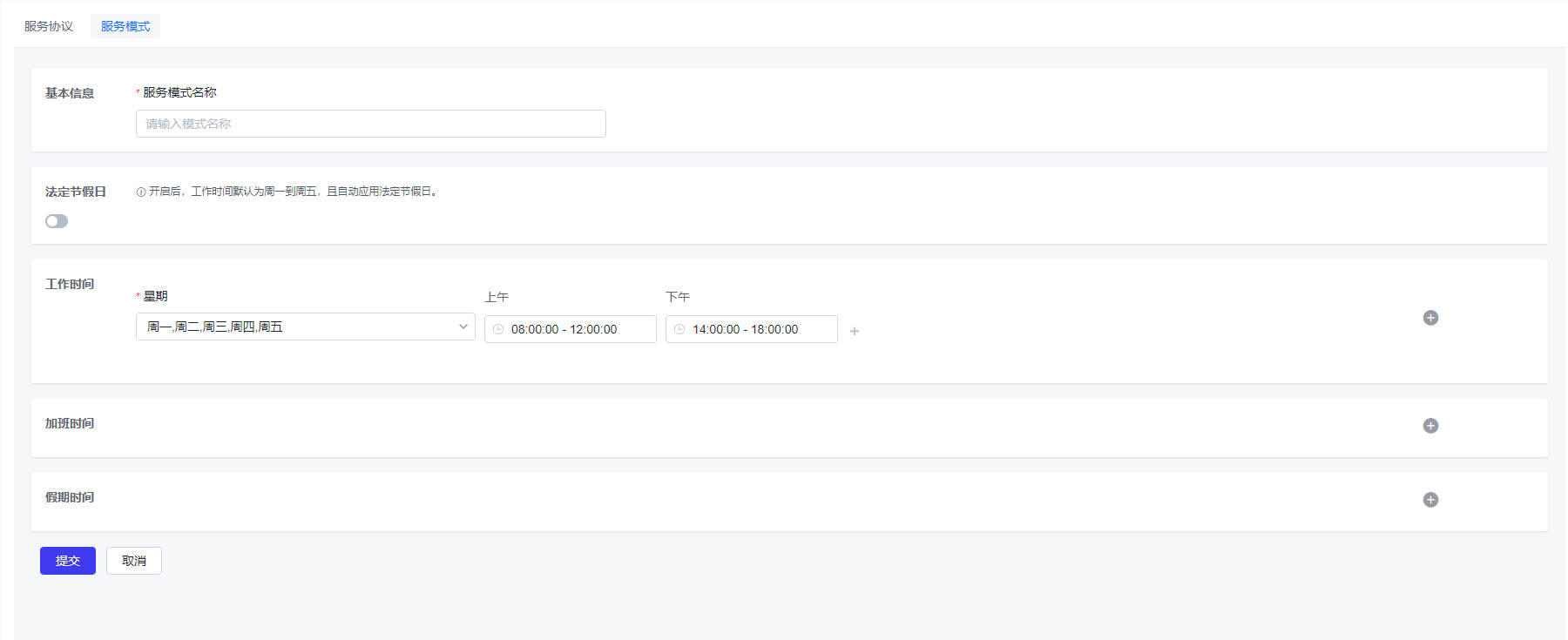
- 步骤二:设置服务协议
服务协议是由服务优先级,服务时间,服务解决时长组合配置的的一套或多套服务标准内容,协议启用后,它将可应用到具体的每个服务中。

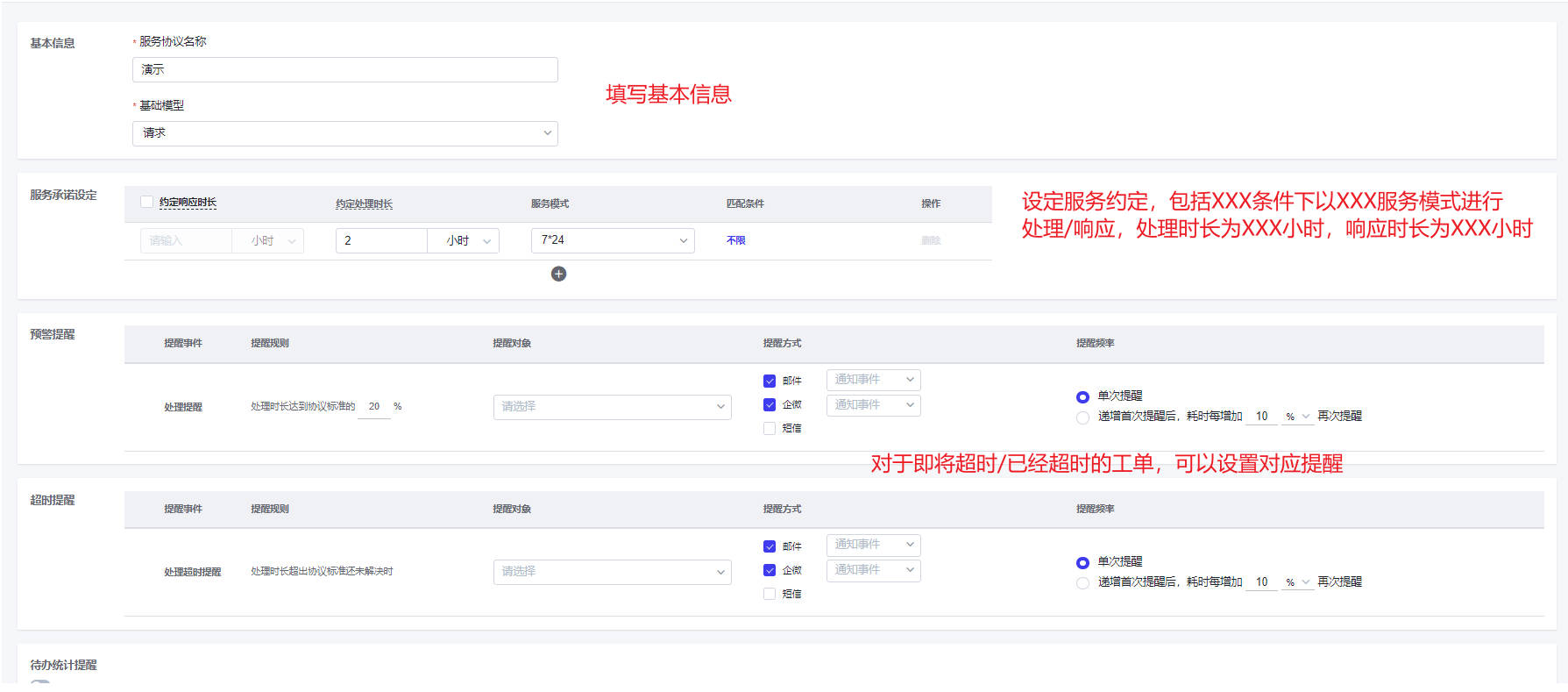
服务协议可设置如下内容:
基本信息:服务协议名称。
服务约定:管理不同优先级下的服务模式,以及解决时长。不同优先级可以设定不同的服务模式。
提醒机制设定:选择是否开启提醒机制以及对应的提醒规则。包括提醒对象,提醒方式,提醒内容(提醒内容可以自定义),提醒频率
是否启用该协议:协议启用开关。开启后,该协议会出现在服务管理中的服务协议下拉框中。
- 步骤三:服务流程使用SLA协议
当服务协议设置完成后,可以在对应服务中选择使用对应的SLA协议

提单
路径:IT服务台/WeOps-事件-工单
- 服务和服务目录创建完成后,可以在IT服务台看到对应的服务目录已经服务目录下的流程。普通用户根据自己的需求在IT服务台中选择对应服务目录下的流程进行提单。
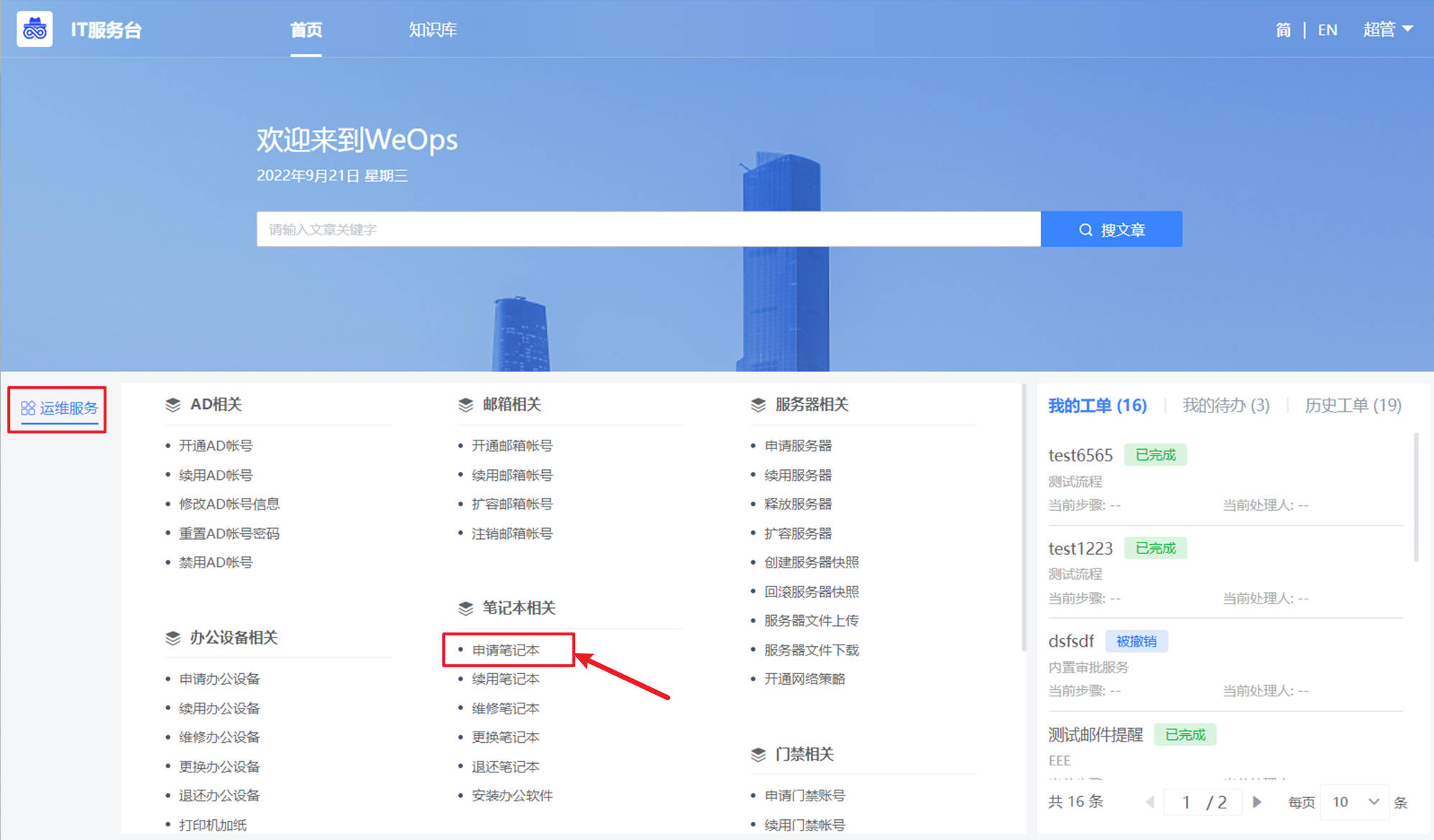
当服务应用某个服务协议之后,该服务下的所有工单将会开启相应的服务标准计时。在单据的详情中可以看到具体的服务时长信息。
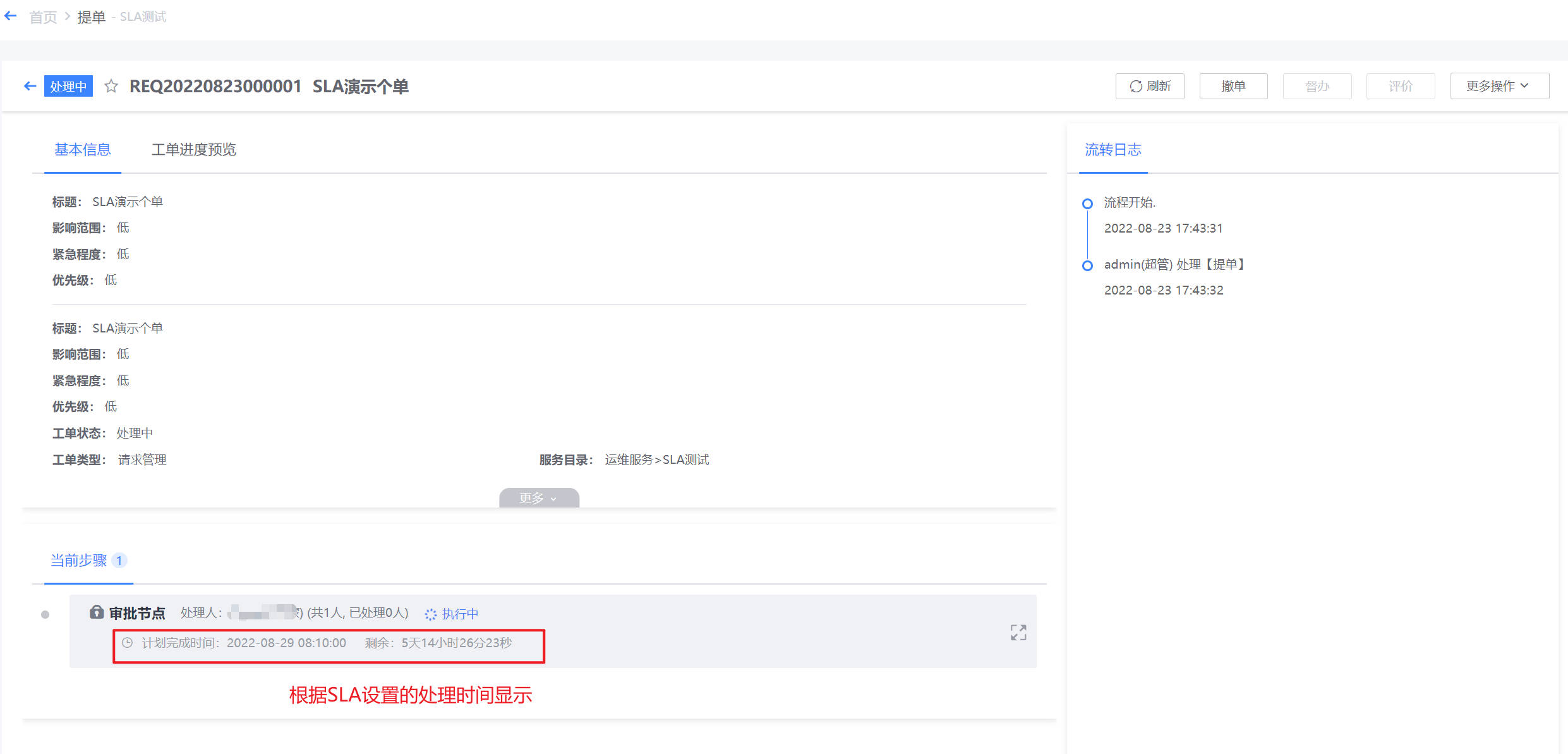
服务台-值班管理配置
背景介绍:为了贴合客户使用场景,可以采用值班的形式,设置不同的值班组对外服务。
整体步骤:供应商管理——值班模式——值班组设置——排班——值班复核,个人可以在“我的值班”查看自己排班和值班的情况,服务流程在设置节点处理人的时候可以选择“值班组成员”
供应商管理
路径:管理-服务台管理-值班管理——供应商管理
在此处管理/维护值班单位的信息和成员,若无其他供应商可以在次维护自己企业的值班成员和信息。
- 供应商管理:可以维护不同的值班单位,并设置每个值班单位下面的人员以及根据添加的值班单位字段填写每个值班单位相关的信息。
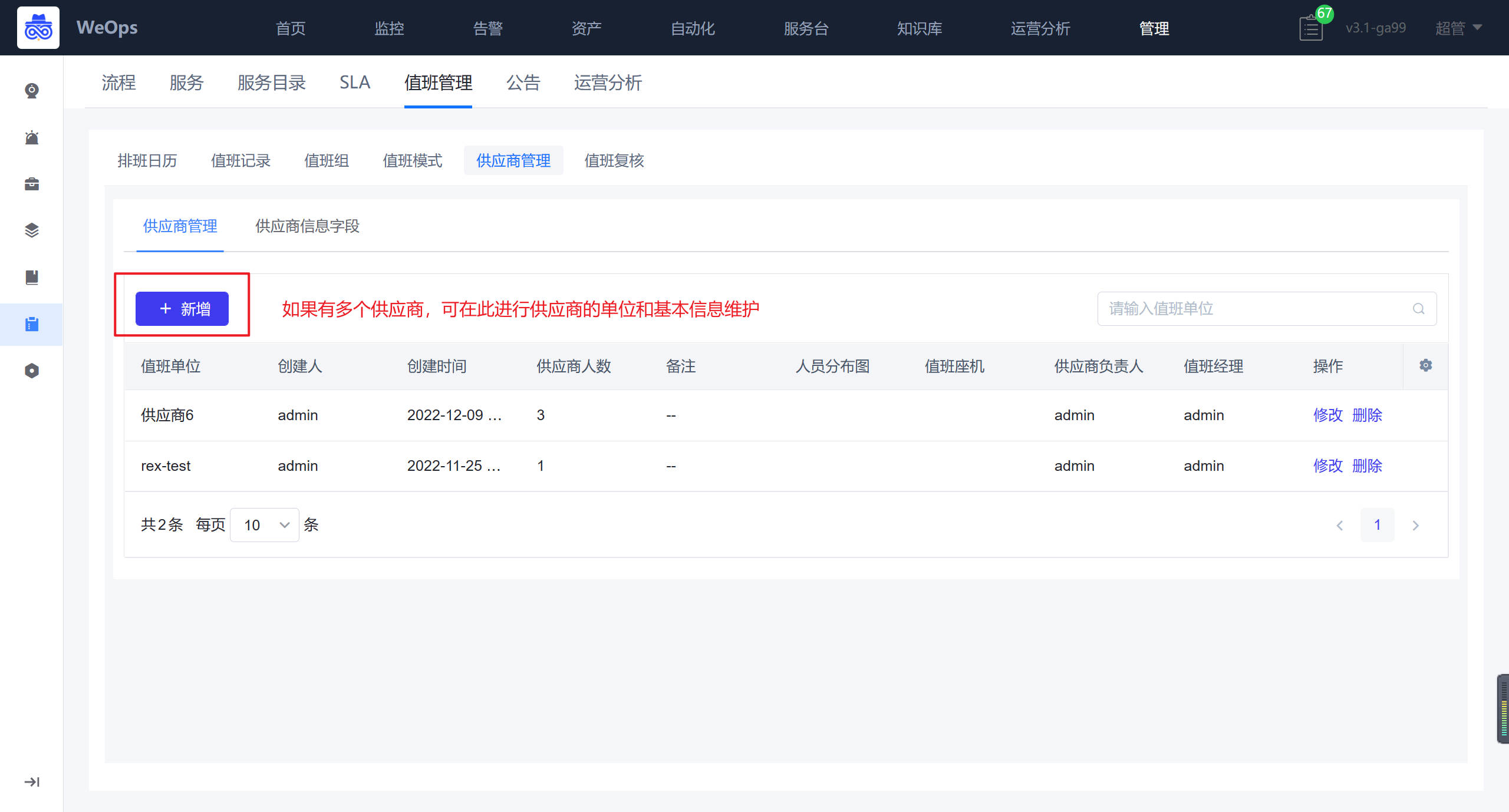
- 供应商信息字段:若系统本身的值班单位字段不满足要求,可以在此处进行扩展,如:新增人员选择字段“运维负责人”,新增后,值班单位的列表将多一列改字段,所有值班单位均需维护“运维负责人”信息。

值班模式
路径:管理-服务台管理-值班管理——值班模式
- 相当于排班规则的模板,可设定上班时间、休假时间等。设置完后可在值班组的规则中引用值班模式。当已经绑定值班组的值班模式更新后,用户需要手动在值班组管理中进行更新。

值班组设置
路径:管理-服务台管理-值班管理——值班组设置
- 点击新增可以配置值班组,值班组人员可以选择供应商中的人员。值班规则可以新增也可以引用值班模式或者新增值班模式。
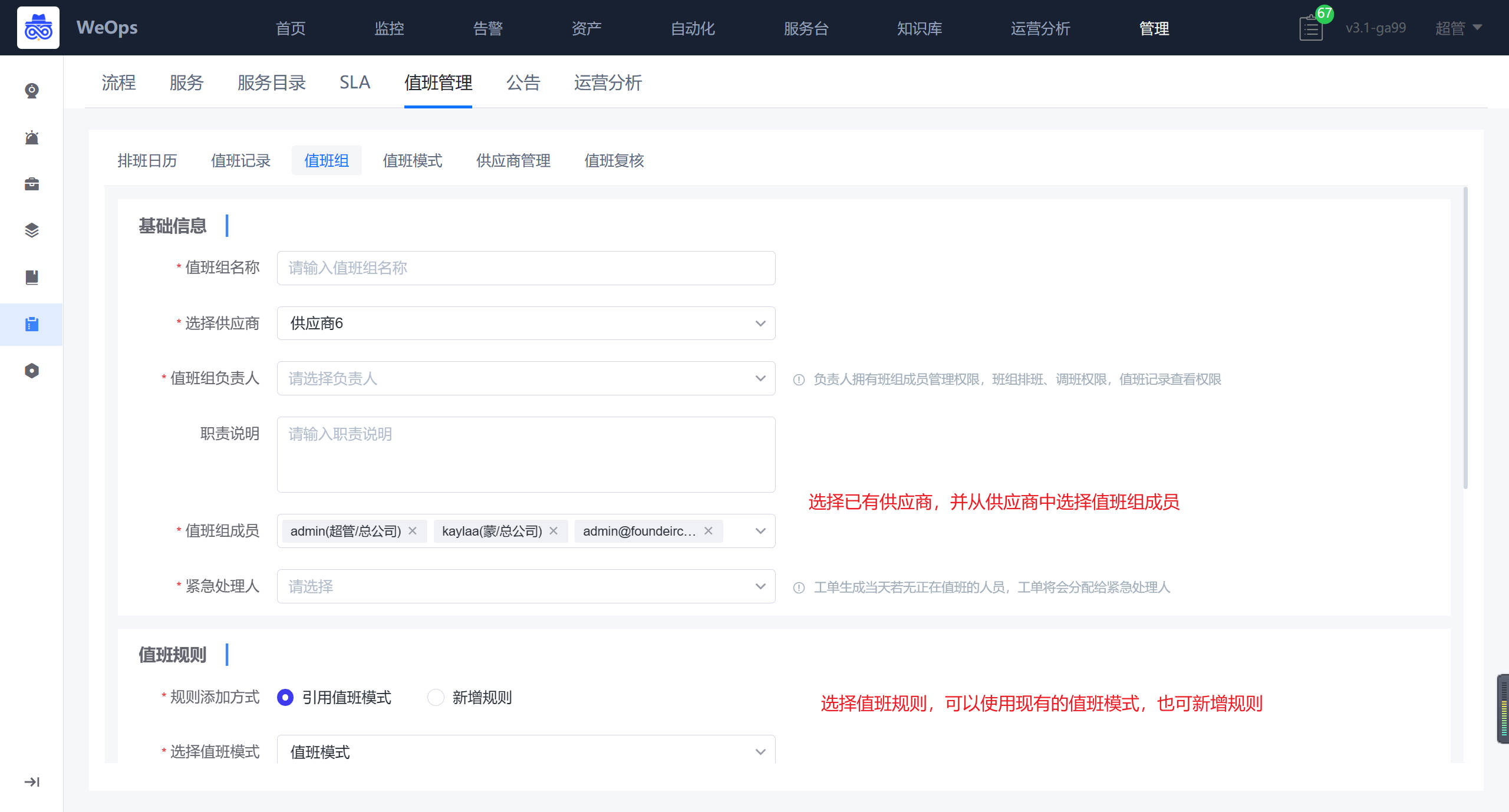
排班设置
路径:管理-服务台管理-值班管理——排班设置
- 可以手动添加新增排班,支持某一时间段自动排班/指定时间排班,并选择值班组
- 点击未值班的人员可以进行调班(跟其他人员对调)、替班(由其他未值班人员顶替)。点击未来的日期可以进行插班(新增人员在当前日期值班)。
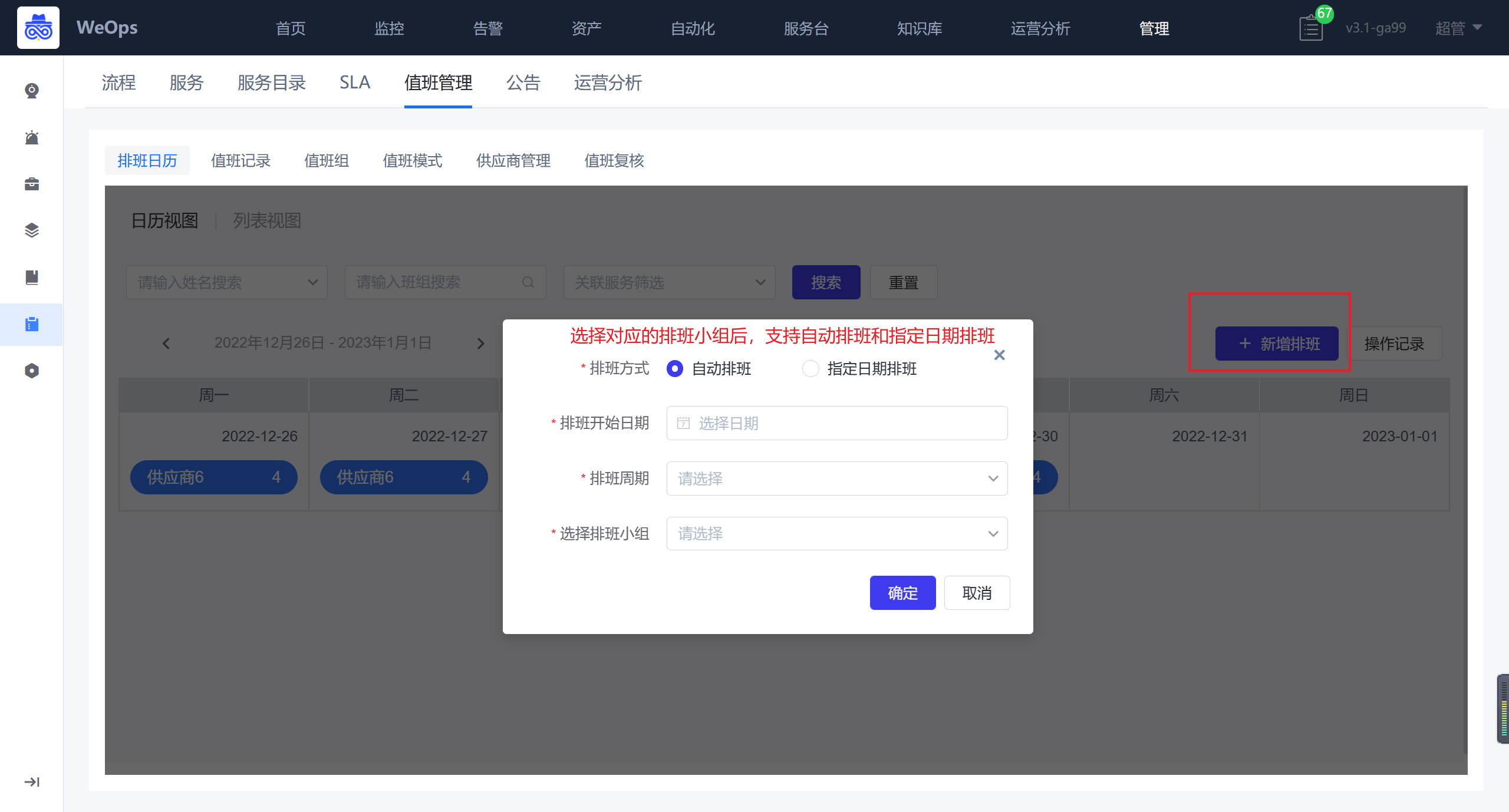

值班复核
路径:管理-服务台管理-值班管理——排班设置
- 当开启了值班复核(可在在ITSM-系统设置-基础配置中开启/关闭)后,排班的内容不会立刻生效,需经过超管及以上权限用户确认排班后,才会生效。
- 在复核时,可以调整值班成员(删除/新增);所有未经过复核的排班操作均会才此处展示;若排班已过期(到达了值班开始时间还未复核),相关内容将从此处移除。

我的值班
路径:服务台-我的值班
- 我的值班:支持切换“日历视图”和“列表视图”两种视图,根据排班情况展示我的值班情况,可进行签到、签退、工作交接。
- 值班记录:可查询以往值班记录/未来值班安排,可查看详细的值班和交接日志。
服务流程设置
路径:管理-服务台管理-流程
- 在流程配置过程中,审批节点可以选择对应值班组人员,当用户提单后,将按照值班组的值班情况分派给对应的人员来处理工单

服务台-公告配置
背景介绍:为了让用户及时获悉运维部门/其他部门对外公告,可在WeOps后台进行公告的配置,配置完成后,可根据有效期在IT服务台显示。
整体步骤:公告配置——IT服务台公告查看
公告配置 路径:管理-服务台管理-公告
- 如下图,可以根据需求设置公告内容,设置公告有效期,支持上传附件、图片、链接、表格等各种格式。
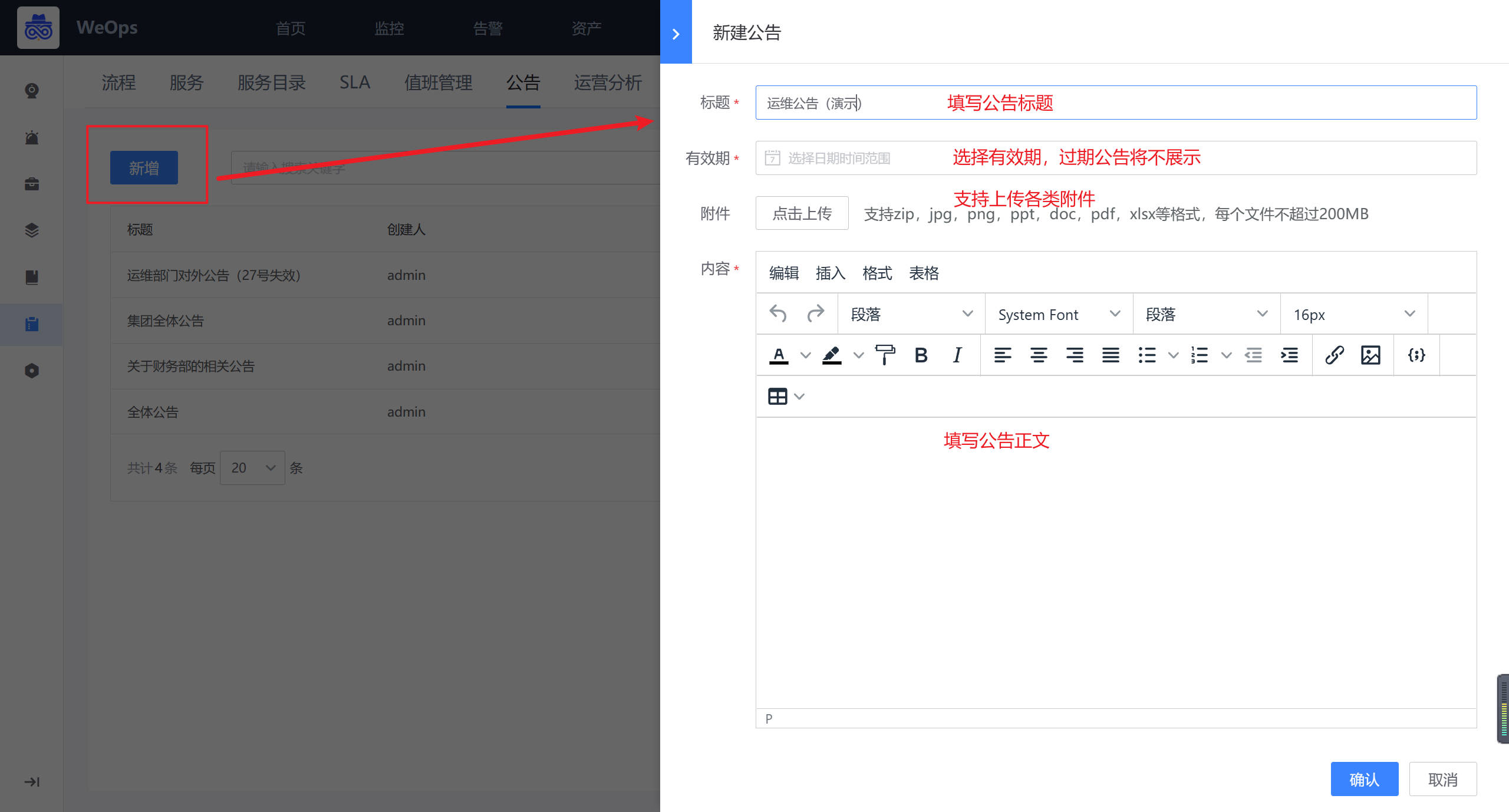
公告查看 路径:IT服务台
- 如下图,公告设置完成,可在IT服务台进行查看
APM配置
服务接入
背景介绍:用户可以方便地管理应用的接入和监控数据上报情况,并使用调用链检索功能来查看和分析trace信息,帮助定位和解决应用中的性能问题和异常情况
整体步骤:应用服务接入——调用链检索
Step1:应用服务接入
路径:管理-APM管理-应用接入
应用接入用于管理接入APM的应用,进行数据接入以及查看接入服务的数据上报情况。
- 添加应用:支持选择WeOps现有应用,加入列表后,并为该应用接入服务
- 应用加入后,点击“接入服务”根据指引进行服务的接入
- 为应用进行服务的接入,WeOps采用无代码入侵的方式进行探针的安装和采集,支持java、python等开发语言和数十种开发框架(具体开发框架详见《内容说明——4、APM内容说明》),接入成功后,可以查看各个服务的数据上报情况。
Step2:调用链检索 路径:APM-调用链检索
如下图,当应用的服务接入完成之后,可以在APM-调用链检索进行trace的搜索和查看。可分为如下四个区域,分别进行trace的条件/时间设置、trace列表查看和各个请求详情的查看。
- ①搜索条件区域:支持切换不同的应用和对应的服务,也支持通过trace ID或者链路入口接口/方法的关键词进行搜索,此外也可以设置耗时查询范围
- ②时间选择器:支持选择trace的产生时间范围,便于进一步锁定
- ③检索结果:展示符合搜索条件下所有的trace列表,可展开查看详情以及具体的请求步骤,各个请求也可点击查看详情。
- ④请求详情:展示该次请求的相关信息,具体如下:
基本信息:该请求的基本调用信息,客户端和服务端调用的耗时情况
源数据:客户端和服务端原始的数据Step3:查看应用情况
路径:APM-调用链检索
应用观测提供应用下服务运行态全景调用关系和服务、接口请求量统计情况,帮基于全景视角观测系统运行时实际流量运行状态,清晰构建系统调用依赖关系包含服务、外部服务、数据库、中间件等系统组件。
- 如下图,应用列表展示接入的所有应用,以及该应用的关键指标,点击进入该应用的详情页面。
- 应用的详情页分为三个模块:应用分析——展示整个应用的拓扑和关键指标情况,服务分析——该应用下所有服务的性能情况,接口分析——所有接口的性能情况。
- 如下图,展示整个应用的全景拓扑图和该应用的关键指标信息,具体说明如下
① 时间选择区域:支持切换时间范围,切换后下方的拓扑图和指标折线图会根据选择的时间范围更新展示。
② 应用全景拓扑图:展示该应用所有服务的调用拓扑关系,具体说明如下
节点图标大小:根据服务请求量和请求负载判断节点拓扑大小,确定当前拓扑的最大值和最小值,其余节点按比例确定节点大小
图标悬停展示:将鼠标悬停在节点可以查看该节点详情,包括负载、请求量、耗时、错误等信息
③ 应用性能关键指标:提供当前时间范围的请求数量,错误数、服务请求,响应时间的关键指标折线图
④ 错误分析:如下图,切换可以查询所有错误的情况,支持按照时间/服务/接口/方法进行筛选。点击接口名称可以调整至这个接口的分析页面;点击调用链,可以跳转到该请求的trace详情页;点击错误堆栈,可以查看堆栈的详情。
- 如下图,展示该应用下所有服务的列表,展开后可以查看服务的详情
- 如下图,展示该服务相互调用的拓扑关系、关键指标(请求、响应时间、错误率)、错误分析
- 如下图,展示该应用下所有接口的列表,展开后可以查看接口的详情
- 如下图,展示该接口关键指标(请求、响应时间、错误率)、错误分析
APM监控告警
背景介绍:公司的应用已经接入WeOps,需要对某些业务关键的APM指标进行监控,一旦发现异常情况,发出告警通知对应人员及时进行处理。
整体步骤:APM监控策略配置——APM告警查看和处理
Step1:APM监控策略配置
APM监控策略配置的入口有以下2种
- (1)监控策略:如下图,在监控管理-监控策略中也可以直接找到APM监控策略进行创建
路径:管理-监控管理-监控策略-APM策略
- (2)APM监控:如下图,在APM的管理的APM监控中,也可进行APM监控策略的创建
路径:管理-APM管理-APM监控
- 2个入口的APM监控创建策略页面一致,具体如下图
- (1)基本信息:策略名称等
- (2)监控项:支持请求数、平均响应时间、请求失败数等关键指标
- (3)监控目标:选择需要监控的业务
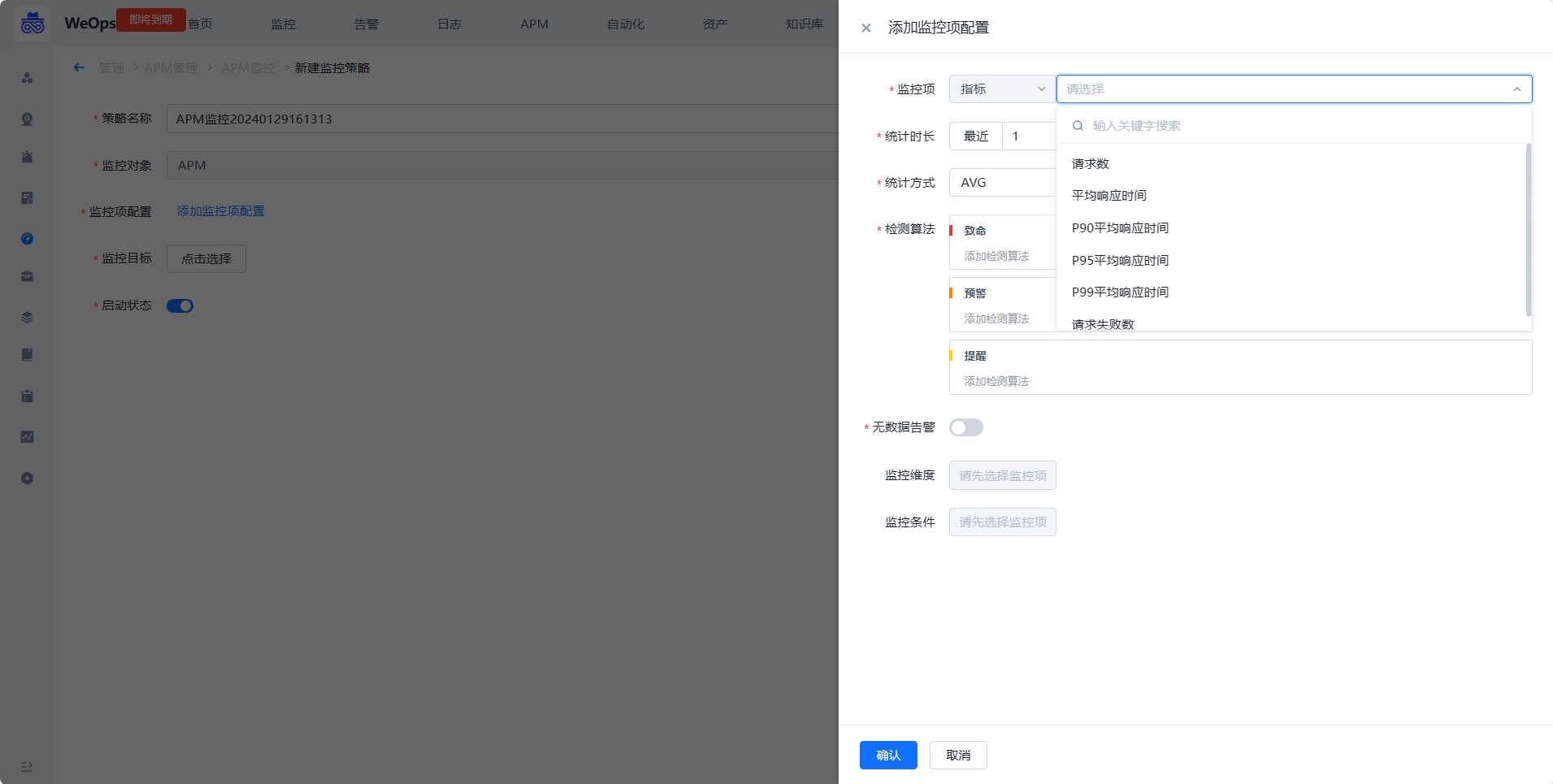
Step2:APM告警查看和处理
- 按照APM监控策略进行监控,一旦符合策略配置的条件,即可产生告警,告警内容如下图
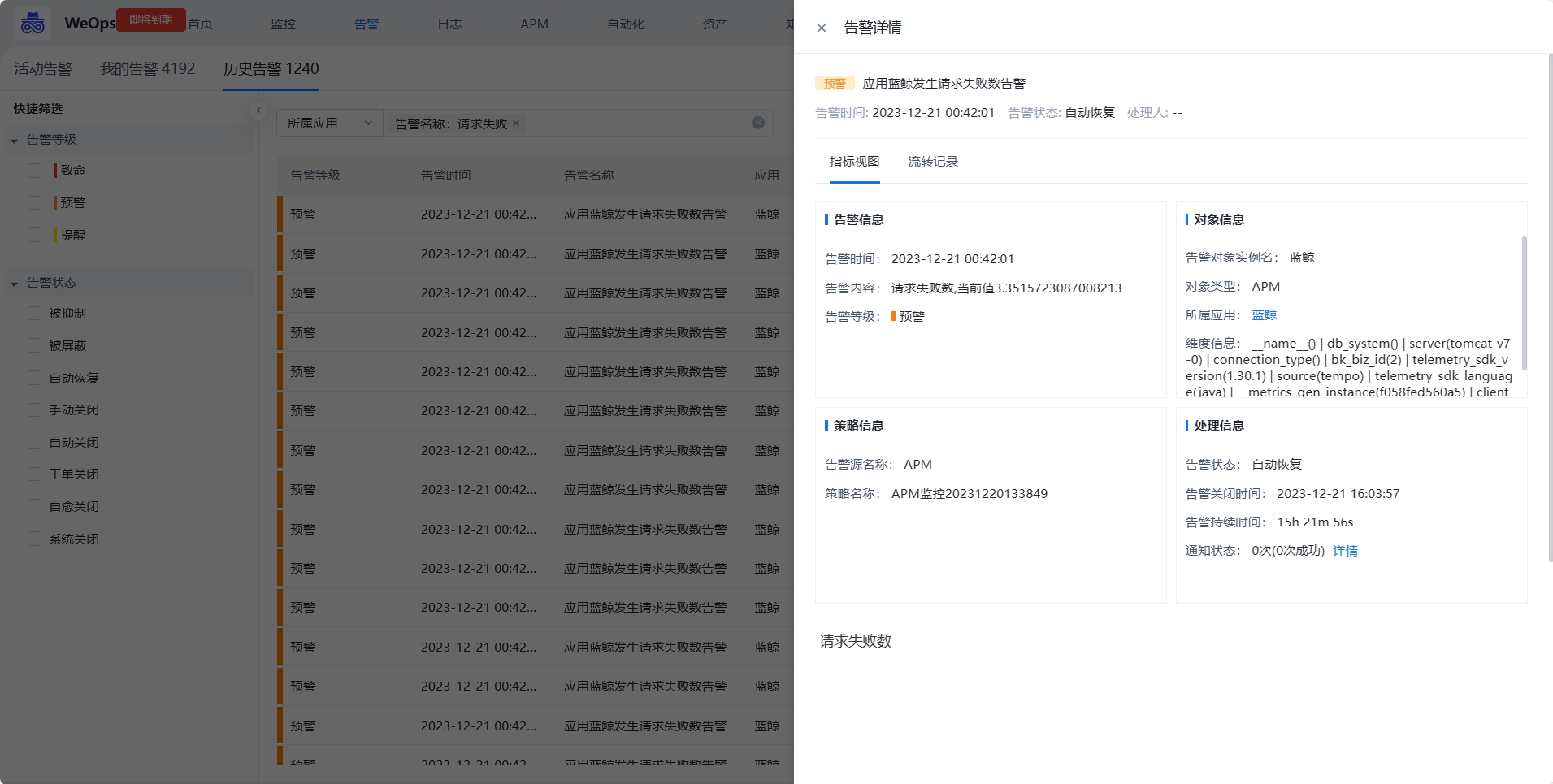
K8S集群的OT探针接入指引
前置准备
以下内容需要按照顺序进行部署
(1)部署cert manager到集群
可参考: https://cert-manager.io/docs/installation/
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.3/cert-manager.yaml等待cert-manager全部就绪才可部署opearator,例如
kubectl get pod -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-56588b57f4-6pbc2 1/1 Running 0 5d5h
cert-manager-cainjector-7bbf568f47-m2f6l 1/1 Running 0 5d5h
cert-manager-webhook-7f7c7898cc-b9x6f 1/1 Running 0 5d5h(2)部署operator
需要注意依赖的k8s版本,最下方已列出对应的版本依赖
# 版本v0.82.0
kubectl apply -f https://github.com/open-telemetry/opentelemetry-operator/releases/download/v0.82.0/opentelemetry-operator.yaml(3)部署Instrumentation
注意: 必须指定命名空间以对特定命名空间的资源进行注入,否则将不会生效。例如,如果未指定命名空间,只有默认命名空间才能接受自动注入
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: my-instrumentation
namespace: tomcat
spec:
propagators:
- tracecontext
- baggage
- b3
sampler:
type: parentbased_traceidratio
argument: "0.25"
java:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://127.0.0.1:4317
- name: OTEL_RESOURCE_ATTRIBUTES
value: bk.biz.id=2
- name: OTEL RESOURCE_ATTRIBUTES
value: 18ed4404-f20b-457d-a5e8-7fa964061823
容器安装探针
(1)提前拉取java agent镜像
docker pull ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-java:1.28.0(2)添加参数
- 注意部署文件中annotations的添加位置,在多容器情况下需要指定注入的容器名称
- 若Instrumentation修改过,则注入容器的部署部分需要重新部署,或者重新拉起新的pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-with-multiple-containers
spec:
selector:
matchLabels:
app: my-pod-with-multiple-containers
replicas: 1
template:
metadata:
labels:
app: my-pod-with-multiple-containers
annotations:
instrumentation.opentelemetry.io/inject-java: "true"
instrumentation.opentelemetry.io/container-names: "myapp"
spec:
containers:
- name: myapp
image: myImage1
- name: myapp2
image: myImage2
- name: myapp3
image: myImage3查看调用链
版本依赖
目前WeOps内置的探针版本为v0.82.0,适用的K8S版本号为:v1.19 to v1.27
| OpenTelemetry Operator | Kubernetes | Cert-Manager |
|---|---|---|
| v0.90.0 | v1.23 to v1.28 | v1 |
| v0.89.0 | v1.23 to v1.28 | v1 |
| v0.88.0 | v1.23 to v1.28 | v1 |
| v0.87.0 | v1.23 to v1.28 | v1 |
| v0.86.0 | v1.23 to v1.28 | v1 |
| v0.85.0 | v1.19 to v1.28 | v1 |
| v0.84.0 | v1.19 to v1.28 | v1 |
| v0.83.0 | v1.19 to v1.27 | v1 |
| v0.82.0 | v1.19 to v1.27 | v1 |
| v0.81.0 | v1.19 to v1.27 | v1 |
| v0.80.0 | v1.19 to v1.27 | v1 |
| v0.79.0 | v1.19 to v1.27 | v1 |
| v0.78.0 | v1.19 to v1.27 | v1 |
| v0.77.0 | v1.19 to v1.26 | v1 |
| v0.76.1 | v1.19 to v1.26 | v1 |
| v0.75.0 | v1.19 to v1.26 | v1 |
K8S集群Beyla接入指引
第一步、创建命名空间并配置权限
创建命名空间 kubectl create namespace beyla
创建ServiceAccount并绑定ClusterRole授权,授予pod和ReplicaSets的list和watch权限
apiVersion: v1
kind: ServiceAccount
metadata:
name: beyla
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: beyla
rules:
- apiGroups: ["apps"]
resources: ["replicasets"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: beyla
subjects:
- kind: ServiceAccount
name: beyla
namespace: beyla
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: beyla第二步、配置Beyla的采集规则
部署Beyla前,需通过配置采集规则,定义采集K8S集群中的哪些数据
apiVersion: v1
kind: ConfigMap
metadata:
namespace: beyla
# 如果需要接入多个的业务,需部署多套Beyla,需更改metadata.name保证不重复
name: beyla-config
data:
beyla-config.yml: |
# 开启kubernetes发现和元数据
attributes:
kubernetes:
enable: true
# 提供自动路由报告,同时最小化基数
routes:
unmatched: heuristic
# 填写需要检测的服务的deployment,比如检测docs的deployment
discovery:
services:
- k8s_deployment_name: "^docs$" # 根据实际的命名规则调整正则表达式
# 还可以支持检测多个deployment,比如解除下方注释则会同时检测docs和website的deployment
# - k8s_deployment_name: "^website$"除了使用k8s_deployment_name字段作为检测规则外,还支持以下字段(选择一类字段使用即可):
- k8s_pod_name
- k8s_namespace
- k8s_replicaset_name
- k8s_statefulset_name
- k8s_daemonset_name
- k8s_owner_name (
Deployment,ReplicaSet,DaemonSetorStatefulSet)
第三步、使用DaemonSet方式部署Beyla
具体如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: beyla
# 如果需要接入多个的业务,需部署多套Beyla,需更改metadata.name保证不重复
name: beyla
spec:
selector:
matchLabels:
instrumentation: beyla # 需与metadata.name保持一致
template:
metadata:
labels:
instrumentation: beyla # 需与metadata.name保持一致
spec:
serviceAccountName: beyla
hostPID: true # 必须为true,否则将导致Beyla服务异常
volumes:
- name: beyla-config
configMap:
name: beyla-config # 需与第二步中采集规则的metadata.name一致
containers:
- name: beyla
image: grafana/beyla:1.3.1
securityContext:
privileged: true # 必须为true,否则将导致Beyla服务异常
volumeMounts:
- mountPath: /config
name: beyla-config
env:
- name: BEYLA_CONFIG_PATH
value: /config/beyla-config.yml
- name: OTEL_EXPORTER_OTLP_ENDPOINT
valueFrom:
secretKeyRef:
name: grafana-credentials
key: otlp-endpoint
- name: OTEL_EXPORTER_OTLP_HEADERS
valueFrom:
secretKeyRef:
name: grafana-credentials
key: otlp-headers
- name: OTEL_RESOURCE_ATTRIBUTES
value: bk.biz.id=2 # WeOps中的配置应用id其他配置
资源模型配置
背景介绍:内置的资源模型不满足公司对于资源纳管的需求,需要增加新的资源模型,并配置该资源模型与其他模型之间的关联关系。
整体步骤:新建模型分组——新建模型——设置模型字段和关联关系——模型使用
step1:新建模型分组
路径:管理-管理中心-资产模型管理
- 点击在“资源模型管理”界面点击“新建分组”按钮,在新建抽屉中填写分组的中英文名称即可,内置分组不允许修改和删除,自创分组允许修改中文名称和删除


step2:新建模型
路径:管理-管理中心-资产模型管理
- 点击在“资源模型管理”界面点击“新建模型”按钮,在新建界面选择模型图标、模型分组,填写模型的标识和名称。


- 模型新建完成后,将在“WeOps-资产记录/主机/数据库/其他”中展示新建的模型tab
step3:填写模型属性字段和关联关系
路径:管理-管理中心-资产模型管理
- 模型新建完成后,点击该模型图标,可以进行“属性”和“关联”新建和管理。
- 可以进行“属性”字段的新增和编辑,在后续为该模型增加实例时,这些属性字段将作为实例信息字段填写
- 进行“模型关联”模型关联建立后,可以在新建实例后,进行实例的关联建立。

step4:模型的使用
路径:资产数据-资产记录-对应模块
- 在资产记录中,找到新建的模型tab,点击“新建”按钮,可以进行实例的新增,这里需要填写的字段信息是在“资产模型管理-属性”中建立的属性字段。
- 在实例新建完成后,点击“查看”按钮,进入到实例的详情页,在“关联管理”中可以进行该实例与其他模型实例的关联关系的新建,这里可选择实例其他模型实例的关联关系与“资产模型管理-关联”中模型之间的关联关系一致。
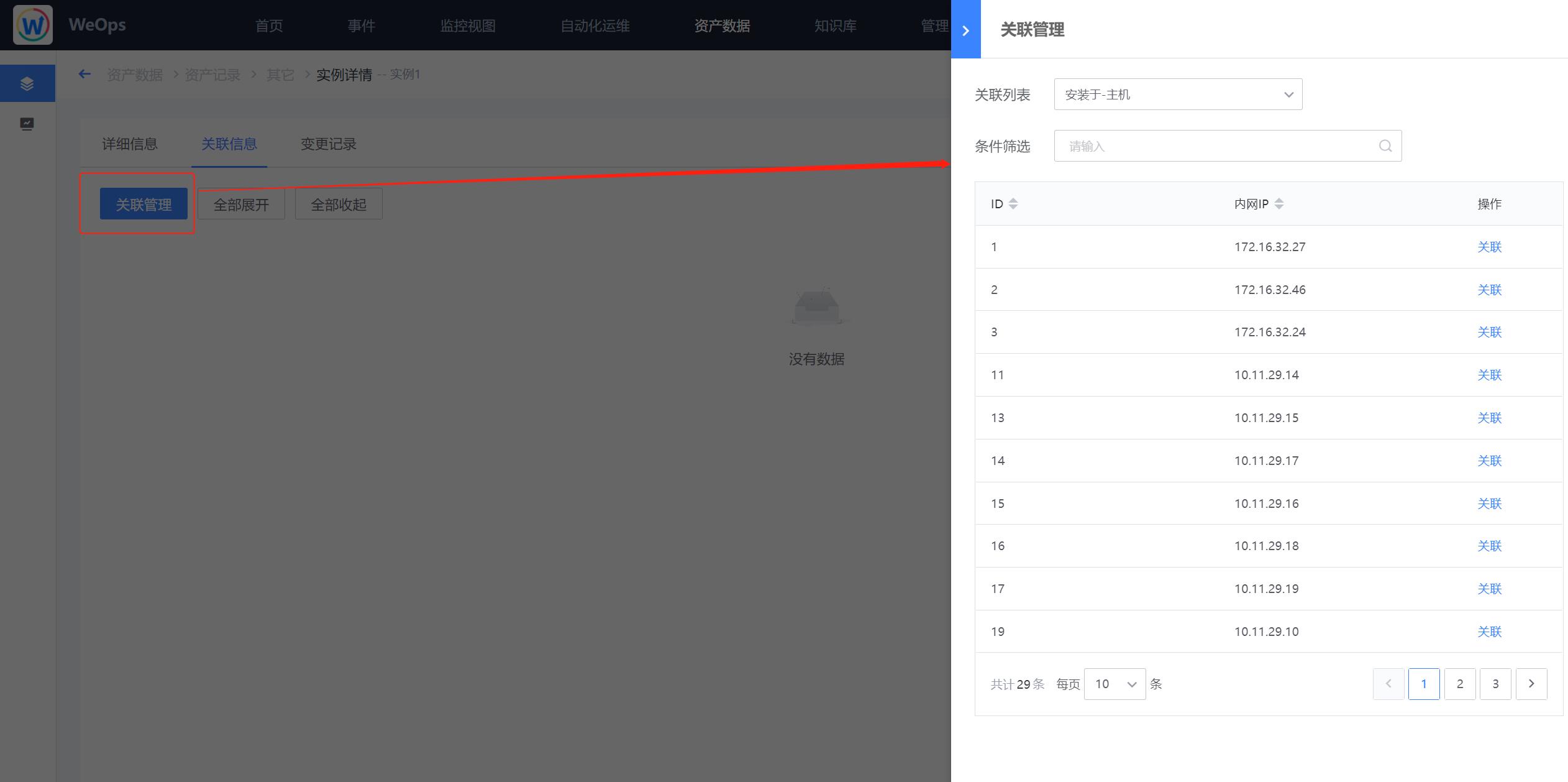
step5:模型的停用
路径:管理-管理中心-资产模型管理
- 当该模型不再使用,支持对模型进行停用,停用后,在模型管理中变暗,同时在资产记录中该模型已经相关资产也不再显示。
云区域接入点指引
先决条件
WeOps接入点包括:
- Auto-Mate边缘节点
- WeOps-Proxy边缘节点
两个服务,这两个服务都通过docker拉起。
要求接入点服务器安装了20.10.23版本以上的docker。
需要开通以下网络策略:
| 源地址 | 目标地址 | 默认端口 |
|---|---|---|
| 接入点服务器 | 蓝鲸redis | 6379 |
| 接入点服务器 | 蓝鲸nginx | 80,443 |
| 接入点服务器 | WeOps consul | 8501 |
| 接入点服务器 | WeOps Promtheus | 9093 |
| 接入点服务器 | WeOps vault | 8200 |
| 蓝鲸APPO | 接入点服务器 | 8089 |
在接入点主机上,需能正常解析到蓝鲸的paas域名或写入了正确的hosts
Step1 部署服务
启动Automate服务,具体镜像tag视关联的WeOps版本/服务器cpu架构而定
在新的接入点操作
#!/bin/bash
# 创建日志目录并授权
mkdir -p /data/bkce/logs/automate/automate && chown -R 1001:1001 /data/bkce/logs/automate
# 输入预定义的环境变量
export PROMEHTEUS_URL={{WeOps的prometheus地址,如http://10.10.10.10:9093}}
export PROMETHEUS_USER={{WeOps的prometheus用户,默认admin}}
export PROMETHEUS_PWD={{WeOps的promtheus密码,默认admin}}
export APP_PORT={{Automate的监听端口,默认为8089}}
export REDIS_IP={{蓝鲸Redis的ip}}
export REDIS_PASSWORD={{蓝鲸Redis的密码}}
export REDIS_DB={{Redis使用的DB,注意不同接入点需要使用不同的DB,默认用11和14}}
export VAULT_URL={{WeOps Vault的url,如http://10.10.10.10:8200}}
export VAULT_ROOT_TOKEN={{WeOps Vault的token}}
export ACCESS_POINT_URL={{接入点自身的服务信息,如10.10.10.10:8089}}
export BK_DOMAIN_URL={{蓝鲸域名,需要确保能正常解析,如http://paas.weops.com/o/weops_saas}}
# 启动Auto-Mate容器
docker run -d --restart=always --net=host \
-e APP_PORT=8089 \
-e CELERY_BROKER=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/11 \
-e CELERY_BACKEND=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/14 \
-e VAULT_URL=${VAULT_URL} \
-e VAULT_TOKEN=${VAULT_ROOT_TOKEN} \
-e REDIS_URL=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/14 \
-e WEOPS_PATH=${BK_DOMAIN_URL} \
-e PROMETHEUS_RW_URL=${PROMEHTEUS_URL} \
-e PROMETHEUS_USER=${PROMETHEUS_USER} \
-e PROMETHEUS_PWD=${PROMETHEUS_PWD} \
-e ACCESS_POINT_URL=${ACCESS_POINT_URL} \
-e ENABLE_OTEL=false \
-v /data/bkce/logs/automate:/app/logs \
--name=auto-mate docker-bkrepo.cwoa.net/ce1b09/weops-docker/auto-mate:v1.0.14启动WeOps Proxy服务,具体镜像tag视关联的WeOps版本/服务器cpu架构而定
在新的接入点操作
#!/bin/bash
# 创建需要的目录并授权
mkdir -p /data/weops/proxy
mkdir -p /data/bkce/logs/weopsproxy
chown -R 1001:1001 /data/bkce/logs/weopsproxy
# 输入预定义的环境变量
export PROMEHTEUS_URL={{WeOps的prometheus地址,如http://admin:admin@10.10.10.10:9093}}
export CONSUL_URL={{weops proxy的consul ip, 如http://10.10.10.10:8501}}
# 启动WeOps Proxy容器
docker run -d -e CONSUL_ADDR=${CONSUL_URL} \
-e REMOTE_URL=${PROMEHTEUS_URL} \
--net=host --restart=always --name=weops-proxy \
-v /data/bkce/logs/weopsproxy:/app/log \
docker-bkrepo.cwoa.net/ce1b09/weops-docker/weopsproxy:1.0.3Step2 注册接入点
注册新建的接入点到weops
在蓝鲸的APPT服务器操作
#!/bin/bash
# 输入预定义的环境变量
export ACCESS_POINT_URL={{接入点自身的服务信息,如10.10.10.10}}
export ACCESS_POINT_DESC={{接入点的描述,如阿里云-香港接入点}}
export CONSUL_URL={{weops proxy的consul ip, 如http://10.10.10.10:8501}}
export ZONE={{接入点所属的云区域ID,如蓝鲸的云区域默认为0}}
# 生成接入点的uuid
export UUID=$(uuid)
proxy_url="${CONSUL_ADDR}/v1/kv/weops/access_points/${UUID}"
req=$(cat << EOF
{
"ip":"${ACCESS_POINT_URL}",
"name":"${ACCESS_POINT_DESC}",
"zone":"${ZONE}",
"port": 8089
}
EOF
)
# 注册接入点到consul
curl --request PUT --data "$(jq -r <<<$req)" $proxy_url
# 检查接入点是否注册成功
curl --request GET $proxy_url | jq -r .[].Value| base64 -d凭据的配置和使用
背景介绍:运维管理员统一管理资产的凭据,并且在使用时可以快捷的选择已经保存的凭据,目前支持主机/AD两类凭据的管理和使用。
创建凭据
路径:资产数据-凭据管理-我的凭据
支持主机/AD/网络设备的凭据新建,主机支持SSH/RDP/VNC协议、AD支持LDAP/LDAPS协议,创建的凭据需要关联资产,对应的资产才可以使用这条凭据。(注:网络设备不需要关联资产)
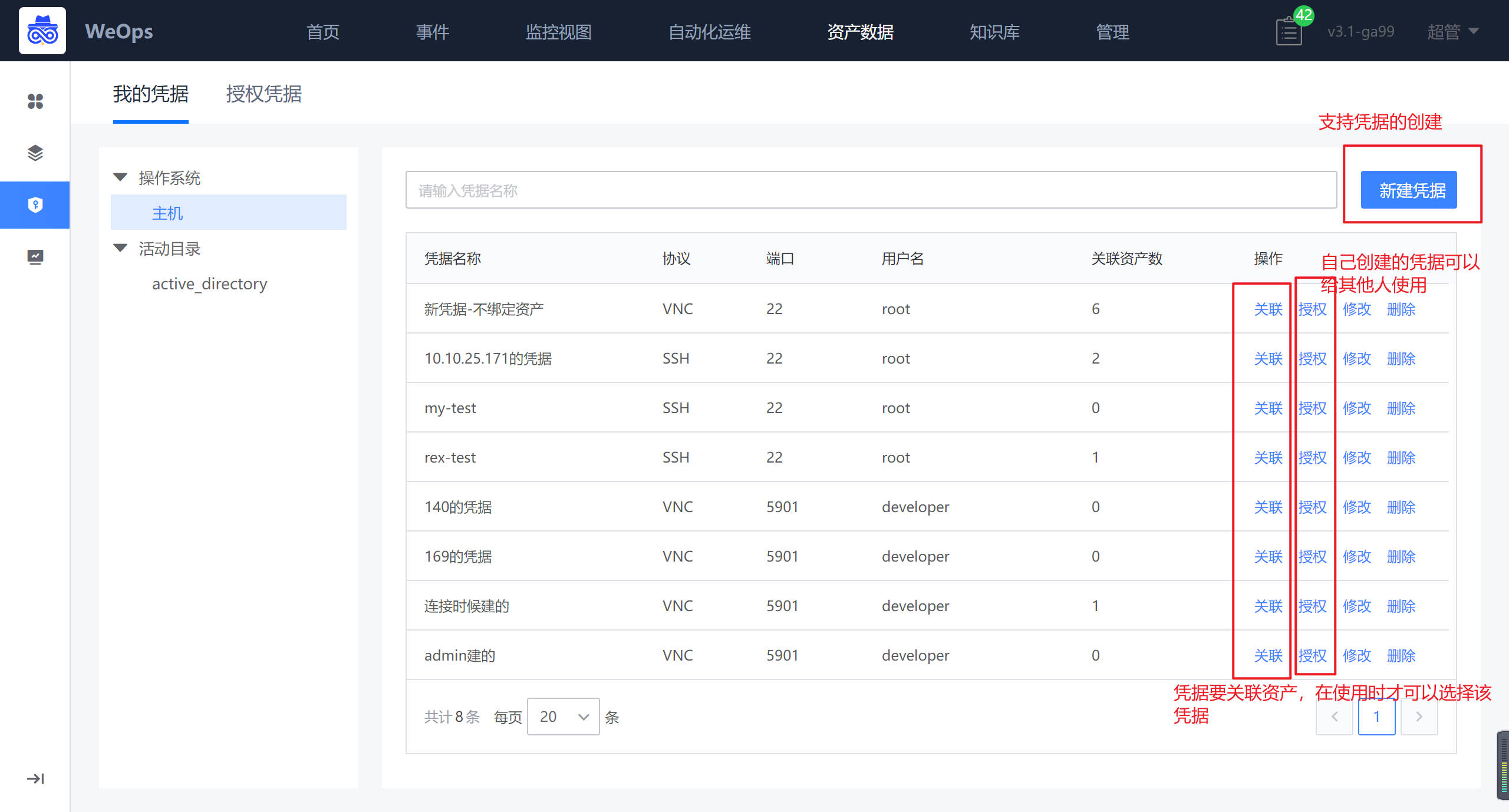

授权凭据
路径:资产数据-凭据管理-授权凭据
展示其他人授权给自己的凭据。
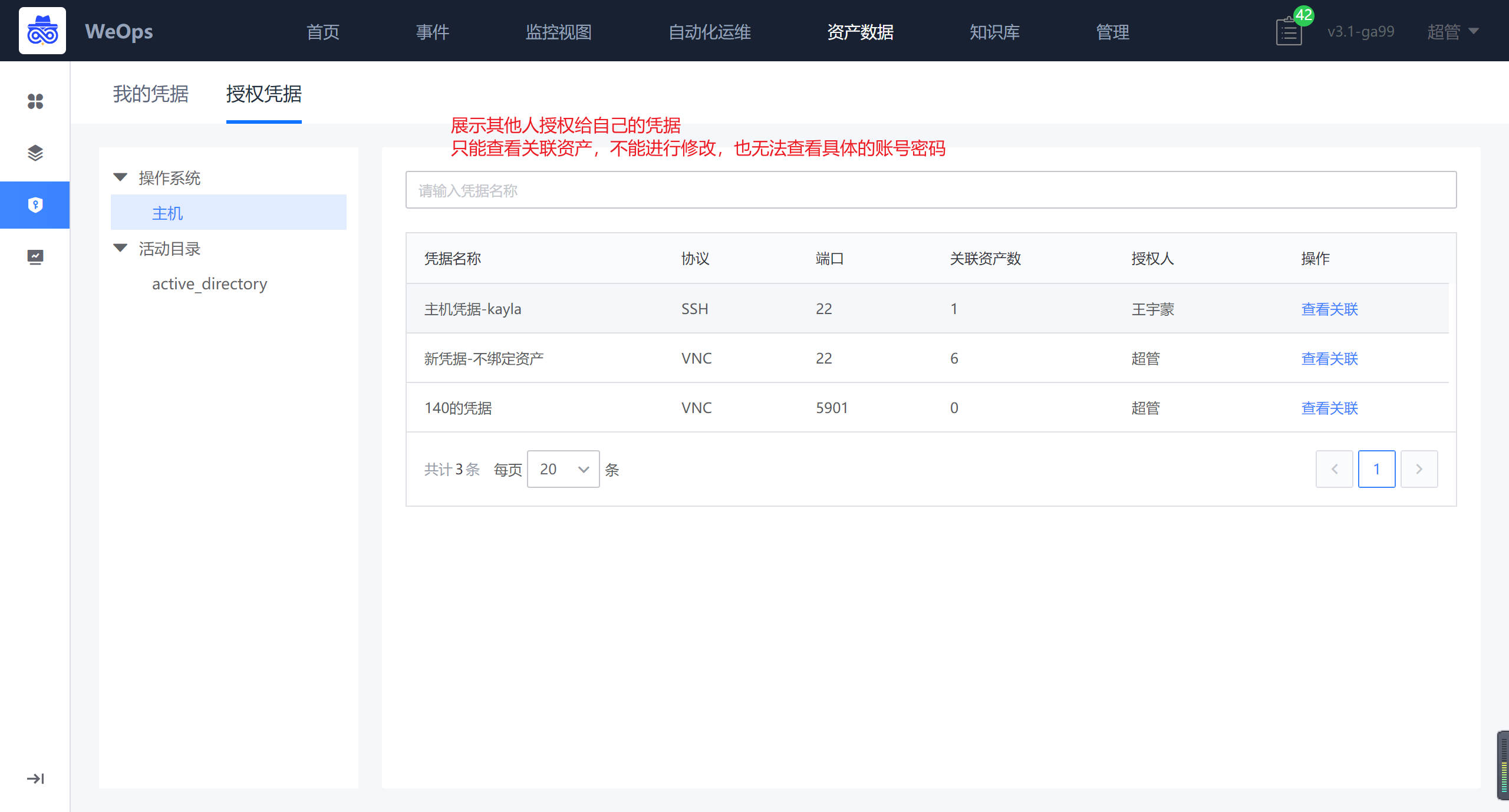
凭据使用
用户可以在某个资产使用的凭据场景包括两类:一类是自己创建的凭据,并且这个资产已经绑定凭据;另一类是别人把创建的凭据授权给自己,且这个凭据绑定了这个资产。
- 主机凭据使用有如下两个途径:在资产列表-主机中,可以点击“远程连接”快捷选择已有的凭据进行远程连接;在告警——告警详情中,若是主机产生了告警,可以快捷使用已经的凭据进行远程连接。使用ssh协议时,要求对端的ssh服务器运行使用rsa密钥,如果ssh版本高于8,需将HostKeyAlgorithms +ssh-rsa添加到/etc/ssh/sshd_config中
- AD的凭据使用:AD目前使用在weops-内置的自动化工单流程中,作为AD账号创建/修改/禁用/删除的前置条件,具体的自动化工单流程可详见“内容说明——7、内置的工单流程”
- 网络设备的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
- 云平台的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
知识库配置
背景介绍:对知识库文章的标签进行管理,若需要重复撰写同类文章通过新建文章模型的形式实现。
整体步骤:管理标签——管理模板
管理标签
路径:管理-管理中心-知识库管理-文章标签
- 在“知识库管理”中可以对标签进行新增/编辑/修改,也可以查看各类标签的引用情况。知识库所有的标签可被文章撰写/模板撰写所引用。
管理模板
路径:管理-管理中心-知识库管理-文章模板
- 在“知识库管理”中可以对模板进行新增/编辑/修改,知识库所有新建的模板可以在“写文章”时被使用。
- 点击“新建模板”可以进行模板的创建,创建模板的时候可以上传图片作为模板封面。
高级仪表盘配置
背景介绍:运维人员需要在仪表盘中配置并查看监控、告警、ITSM、日志等功能模块的数据,默认的组件和数据无法支持选择时,可以通过撰写Trino语句的方式,进行高级仪表盘的配置和使用
整体步骤:选择仪表盘组件→填写Trino语句→配置组件显示项
表格/单值
高级组件的表格和单值只需要填写Trino语句,在Trino中定义好需要获取的数据,就会以表格/单值的形式呈现
折线图/柱状图
高级组件的折线图和柱状图主要展示各个分组的变化情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,选择成为分组/X轴,度量/Y轴和维度信息,以便使用
分组/X轴:就是类别,为折线图和柱状图的X轴,呈现各个分组情况。比如告警的所属应用,每个应用就是一个分组。
度量/Y轴:就是数值,为折线图和柱状图的Y轴,展示各个分组的具体的值的情况。比如告警的处理时长,展示每个应用的告警处理时长。
维度:当分组的数值有多种情况时,需要选择展示维度,比如告警区分优先级,需要分开展示每个应用致命/预警/提醒三个等级的处理时长饼形图
高级组件的饼形图主要展示各个类别的百分比,需要填写Trino语句,点击执行从Trino语句获取返回字段,并且选择成为分组、度量值。
分组:就是类别,呈现各个分组情况,饼形图的每一块就是一个分组。比如分组是IP地址
度量值:就是数值,展示各个分组的具体的值的百分比情况,比如数值是IP地址的数量,则饼形图则表示所有IP地址数量的百分比。流量拓扑图
高级组件的流量拓扑图主要展示源和目标直接的流向关系,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及连线上的数值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
连线数值:连线上面的数值(从源到目标的数值),比如从源IP到目标IP直接响应时长的数值等桑基图
高级组件的桑基图主要展示源和目标直接的流量大小情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及度量值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
度量值:度量值决定了连线的宽窄,越宽说明流量/数值越大Trino语句的撰写示例具体如下
Trino语法官网为:https://ta.thinkingdata.cn/trino-docs/sql/select.html
(1)时间配置
在撰写Trino语句时,定义好$DATE_START$,$DATE_ END$,仪表盘的时间选择器就对该组件的时间范围生效。
select
count(*) as ticket_run
from
bk_itsm.ticket_ticket
where
current_status NOT IN ('FINISHED',REVOKED',DRAFT')
AND DATE FORMAT (create at,Y-%m-d')>=$DATE_START$
AND DATE_FORMAT (create_at,'%Y-%m-名d')<=$DATE _END$WeOps对常用的场景进行了封装,封装的汇总表如下
| 模块 | 函数名 | 数据源 | 支持参数过滤 | 返回值 | 介绍 |
|---|---|---|---|---|---|
| 资产 | 查询资产列表 | mongodb | 模型ID、所属应用、属性值 | 资产列表,包含资产的字段信息和所属应用 | 支持通过该函数快速筛选出指定模型和要求的资产列表,例如:所有蓝鲸应用下bk_os_type属性为Linux的主机 |
| 告警 | 查询告警列表 | es | 时间段、所属应用、对象类型、告警状态、告警等级 | 告警列表,包含WeOps告警详情的告警信息、对象信息、策略信息、处理信息 | 支持通过该函数快速筛选出告警列表,例如:15-17日,所有蓝鲸应用未关闭的危险告警 |
| IT服务台 | 查询工单列表 | mysql | 提单时间段、服务名称、工单状态 | 工单列表,包含工单标题、工单号、服务名称等ITSM工单列表页能看到的信息 | 支持通过该函数快速筛选出工单列表,例如:15-17日,所有笔记本申请服务的已完成工单 |
| 监控 | 查询agent信息 | mysql | agent状态、主机名、操作系统类型、biz id、云区域id | 主机配置信息,主机名称、inner_ip、业务id、云id、agent状态、操作系统类型 | 查看主机agent状态信息,筛选出不正常的agent,操作系统为LINUX的主机 |
| 监控 | 查询监控指标 | influxdb | 对象、data id、时间段 | 查看监控指标情况,支持日期时间聚合,计算最大、最小、平均值。 |
(2)CMDB资产
- 原始功能:语法复杂,不建议使用
SELECT
*
FROM
TABLE (
mongodb.system.query (
database=>'cmdb',
collection=>'cc_objectbase_0_pub_k8s_namespace',
filter=>'{ bk_inst_name: {$regex: "ch"}}'
)
);- 封装场景:可以直接使用封装后的,编写简单
封装功能说明: fields选择字段,regex填写正则匹配字段,database可不填写,默认会选择cmdb数据库。
bk_obj_id: cmdb中的对象ID fields: CMDB中资产对应字段 regex: 在选择的fields字段中进行模糊查询
例1: 查询交换机中品牌为华为的资产信息
SELECT
*
FROM
TABLE (
mongodb.system.get_inst (
database=>'cmdb',
bk_obj_id=>'bk_switch',
fields=>'brand',
regex=>'华为'
)
);例2: 查询主机中操作系统为linux的资产信息
SELECT
*
FROM
TABLE (
mongodb.system.get_inst (
bk_obj_id=>'host',
fields=>'bk_os_name',
regex=>'linux'
)
);例3: 查询业务名和id 只需要出现biz字段并且不填”空即可触发
SELECT
*
FROM
TABLE (mongodb.system.get_inst (biz=>'biz'));(3)告警列表
- 原始功能:语法复杂,不建议使用
SELECT *
FROM TABLE (
elasticsearch.system.raw_query(
schema => 'default',
index => 'cw_uac_alarm_event',
query => '{
"query": {
"bool": {
"must": [
{
"range": {
"alarm_time": {
"gte": "' || CONCAT($DATE_START$, ' 00:00:00') || '",
"lte": "' || CONCAT($DATE_END$, ' 23:59:59') || '"
}
}
}
],
"must_not": [
{
"term": {
"status": "converged"
}
}
]
}
},
"size": 0,
"track_total_hits": true
}'
)
)
)- 封装场景:可以直接使用封装后的,编写简单
查询对应时间段、所属应用、对象类型、告警状态、告警等级的告警信息。 schema: index:es告警索引 bk_obj_id: 蓝鲸对象ID size: 返回数据大小(条) bk_biz_id: 业务ID alarm_level: 告警等级, alarm_status:告警状态 start_time: 起始时间 end_time: 结束时间
SELECT
*
FROM
TABLE (
elasticsearch.system.alarm_info (
schema=>'default',
index=>'cw_uac_alarm_event',
bk_obj_id=>'host',
size=>'3',
bk_biz_id=>'2',
alarm_status=>'restored',
alarm_level=>'fatal',
start_time=>'2023-09-04 02:45:51',
end_time=>'2023-09-04 03:45:51'
)
);(4)ITSM工单
- 原始功能:语法复杂,不建议使用
已支持mysql原生sql query: mysql原生sql语句,注意不能用;结尾,mysql会自动添加该结尾符。
SELECT
*
FROM
TABLE (
mysql.system.query (
query=>'SELECT ticket.* FROM bk_itsm.ticket_ticket AS ticket JOIN bk_itsm.service_service AS service where ticket.service_id = service.id'
)
);- 封装场景:可以直接使用封装后的,编写简单
查询某时间段、服务名称、具体状态的工单。 scene: ticket_filter 工单过滤场景 service_name: 服务名称 ticket_status: 工单状态,支持多状态,以,作为分隔 start_time: 起始时间,取工单创建时间 end_time: 结束时间,取工单创建时间
SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'ticket_filter',
service_name=>'工单',
ticket_status=>'FINISHED, REVOKED',
start_time=>'2023-08-11 20:00:00',
end_time=>'2023-09-11 10:00:00'
)
);SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'ticket_filter',
service_name=>'审批',
ticket_status=>'',
start_time=>'2023-08-01',
end_time=>'2023-09-12'
)
);(5)监控
5.1 查找业务名称
填写biz字段不为空即可
SELECT
bk_biz_name
FROM
TABLE (mongodb.system.get_inst (biz=>'biz'));5.2 统计主机agent状态
scene: 固定场景,目前只支持 host_agent_info 主机agent状态 host_name: 主机名称 agent_status: agent状态 host_os_type: 操作系统类型 bk_biz_id: 业务ID cloud_id:云区域ID
SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'host_agent_info',
host_name=>'',
agent_status=>'RUNNING, NOT_INSTALLED, TERMINATED',
host_os_type=>'LINUX, WINDOWS',
bk_biz_id=>'1, 2',
cloud_id=>'0'
)
);5.3 监控指标
- 原始功能:语法复杂,不建议使用
SELECT
time,
usage,
nice
FROM
TABLE (
influxdb.system.raw_query (schema=>'system',
index=>'cpu_summary',
query=>'
SELECT
mean(usage) as usage,
max(usage) as nice
FROM
cpu_summary limit 10'
)
);以下是低负载报表中用到的场景
SELECT
usage,
nice
FROM
TABLE (
influxdb.system.raw_query (
schema=>'system',
index=>'cpu_summary',
query=>'
SELECT
mean(usage) as usage,
max(usage) as nice
FROM
cpu_summary
GROUP BY
hostname,
ip,
bk_cloud_id,
bk_biz_id
'
)
);注意group_by是额外聚合的字段,建议使用time(1h),每小时,否则数据量过多性能会较差,如果使用到time(1h)这种额外的时序聚合,需要再次对数据进行聚合过滤等操作,比如在低负载报表中是这样处理的:
WHERE
EXTRACT(
HOUR
FROM
time
) BETWEEN $TIME_START$
AND $TIME_END$注意! influxdb查询中如果在query里面更改了字段名,选择字段需要注意不能用*,必须用sql会返回的字段。 因为字段问题可能会报错Cannot invoke “java.lang.Integer.intValue()” because the return value of “java.util.Map.get(Object)” is null
一般的插件监控指标字段含有
time
bk_biz_id
bk_cloud_id
bk_collect_config_id
bk_supplier_id
bk_target_cloud_id
bk_target_ip
ip
metric_name 指标名称
metric_value 指标值指标的维度名称会作为额外字段,这类字段随指标动态变化就不写在上方,需自行识别。
- 封装场景:可以直接使用封装后的,编写简单
封装场景中select后都不能使用* scene: 场景,支持host主机性能,plugin 监控探针 schema:数据库名 index: 表名 metric:指标ID名称(英文) function: 必填否则报错,influxdb计算功能,支持min、max、mean
时间范围需满足起始时间和结束时间,否则默认使用7天内的时间范围。 start_time: 起始时间 end_time: 结束时间
① 监控插件指标
注意!schema处需要手动添加字段,比如监控exporter类的需要添加exporter_
SELECT
metric_value
FROM
TABLE (
influxdb.system.raw_query (
scene=>'plugin',
schema=>'exporter_weops_postgres_exporter',
index=>'lock',
metric=>'pg_locks_count',
function=>'mean',
start_time=>'2023-09-20T14:12:56Z',
end_time=>'2023-09-21T15:12:56Z'
)
);② 主机性能
主机性能表固定为 system
主机性能指标表名
cpu_detail
cpu_summary
disk
env
inode
io
load
mem
net
netstat
proc
proc_port
swap半封装场景
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
nice
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
schema=>'system',
index=>'cpu_summary',
metric=>'nice',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);③ cpu性能指标(已封装)
scene填入host,metric填入cpu_info则是计算cpu_usage的值 默认group_by字段为hostname, ip, bk_cloud_id, bk_biz_id
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
usage
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'cpu_info',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);SELECT
hostname,
ip,
bk_cloud_id,
bk_biz_id,
usage
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'cpu_info',
function=>'mean'
)
);④ 内存性能指标(已封装)
scene填入host,metric填入memory_info则是计算pct_used的值 默认group_by字段为hostname, ip, bk_cloud_id, bk_biz_id
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
pct_used
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'memory_info',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);SELECT
hostname,
ip,
bk_cloud_id,
bk_biz_id,
pct_used
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'memory_info',
function=>'max',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);(6)日志
支持对datainsight数据源查询,query内容支持sql模式,可参考https://opensearch.org/docs/1.1/search-plugins/sql/index/
语法为
Table(datainsight.system.query(streams=>'stream_name',type=>'sql',query='sql_str'))streams:对应datainsight的消息流,即weops的日志分组。可支持传一个或多个,
,号进行分隔,如netflow,http也可以传空
'',代表所有消息流(不建议,性能相对较差)type:目前支持sql模式(ppl模式也支持,但仅限于单消息流,不支持多个和为空)
query:
$index为固定写法,即opensearch的索引概念,如了解索引名也可以写对应索引,否则从填写的streams中获取sql模式语法为
SELECT [DISTINCT] (* | expression) [[AS] alias] [, ...]
FROM $index
[WHERE predicates]
[GROUP BY expression [, ...]
[HAVING predicates]]
[ORDER BY expression [IS [NOT] NULL] [ASC | DESC] [, ...]]
[LIMIT [offset, ] size]
流量拓扑图,桑基图
SELECT
CASE WHEN src < dst THEN src ELSE dst END AS src,
CASE WHEN src < dst THEN dst ELSE src END AS dst,
SUM(c) AS total_c
from Table(datainsight.system.query(streams=>'netflow',type=>'sql',query=>'select nf_src_address as src, nf_dst_address as dst,count(*) as c from $index where nf_src_address is not null and nf_dst_address is not null and nf_src_address!=\"0.0.0.0\" and nf_dst_address!=\"0.0.0.0\" group by nf_src_address,nf_dst_address order by count(*) desc limit 10'))
GROUP BY
CASE WHEN src < dst THEN src ELSE dst END,
CASE WHEN src < dst THEN dst ELSE src END
;自定义菜单
背景介绍:随着菜单项的增加,为了满足不同用户的需求,WeOps可支持自定义菜单,不同的客户环境可根据自己的使用习惯对菜单项进行重新排序的分层级。(目前还不支持按照某个用户/角色进行自定义菜单)
Step1:菜单的设置
路径:管理-系统管理-菜单设置
- 如下图,点击“新建菜单”按钮,可以创建一个新的菜单,并按照自己的需求进行编辑。
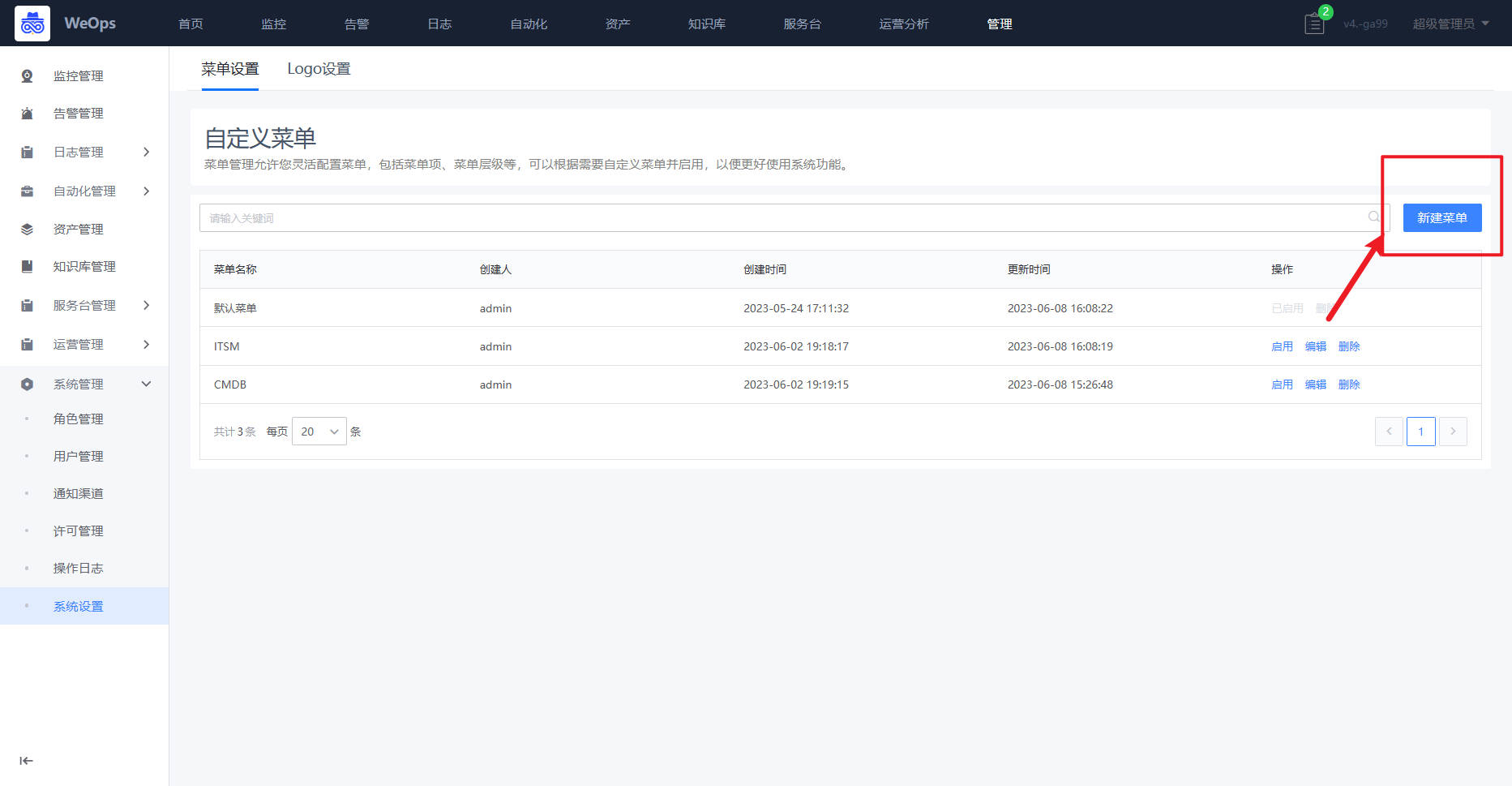
- 如下图,菜单的具体配置页面,具体说明如下
- 菜单项:展示了WeOps所有带页面的菜单项,支持勾选进入新菜单的编辑。其中“监控-基础监控”和“资产-资产记录”两个为菜单项组,下面带了动态的子页面,菜单项支持重新命名。
- 目录:支持新建目录对新菜单的菜单项进行分类展示。
- 其他说明:目前最高层级仅支持3层,目录下面必须包括菜单项,菜单项下面不可增加其他菜单项
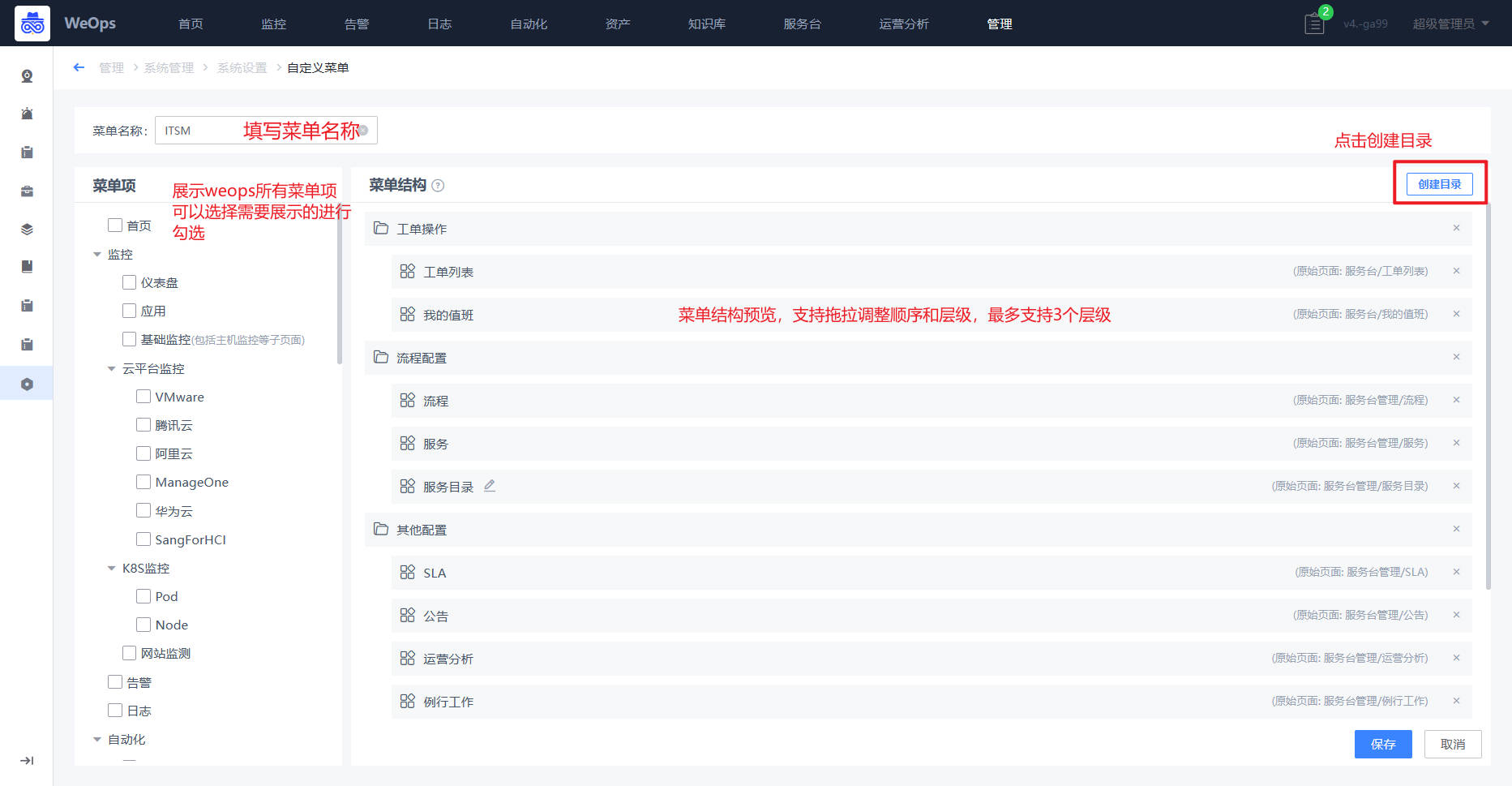
Step2:菜单的启用
- 点击“启用”按钮,就行菜单的启用,整体菜单结构立刻生效。
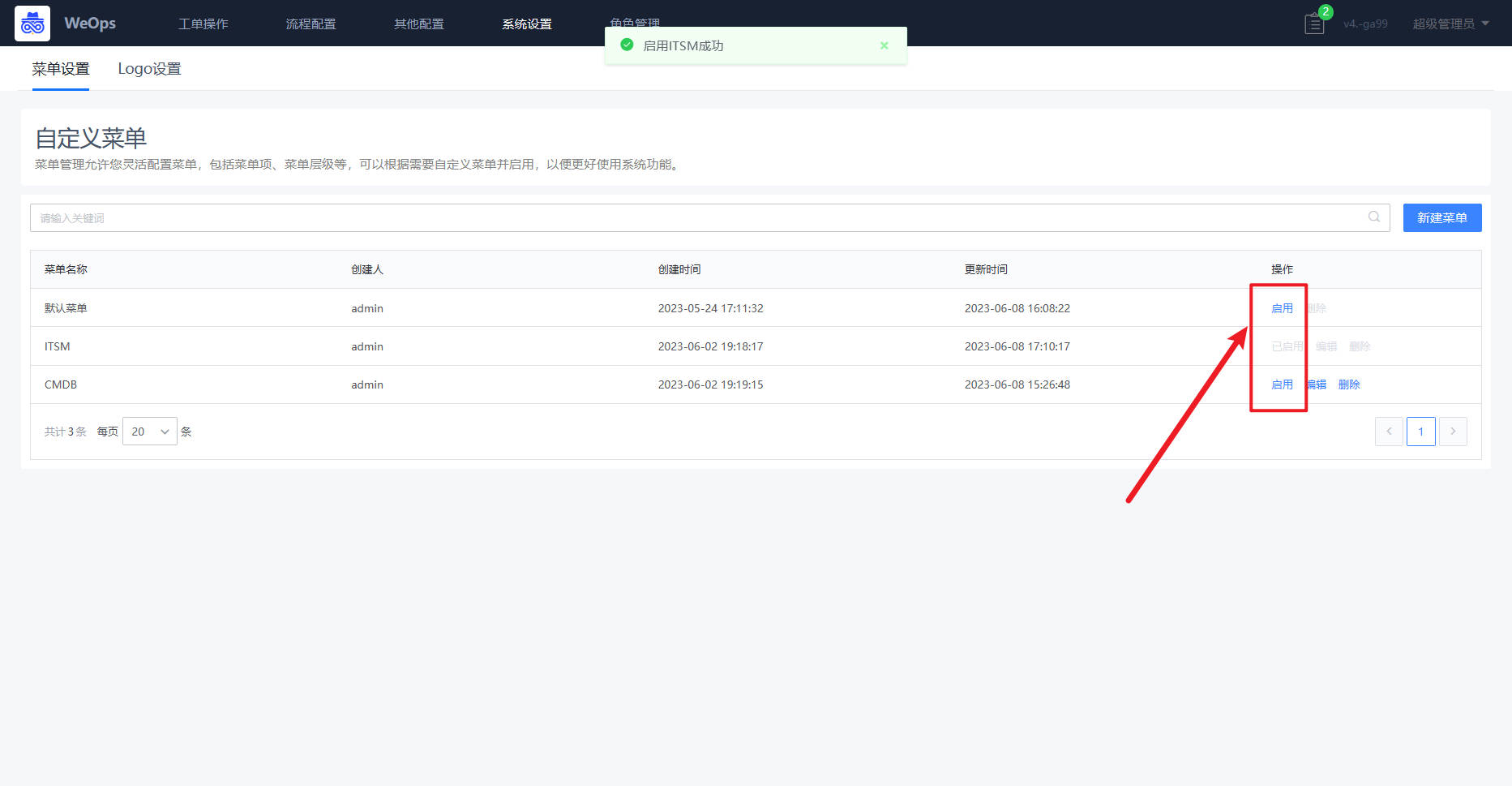
- 其他补充说明,菜单启用之后,角色的权限授权会跟随使用的菜单变动。
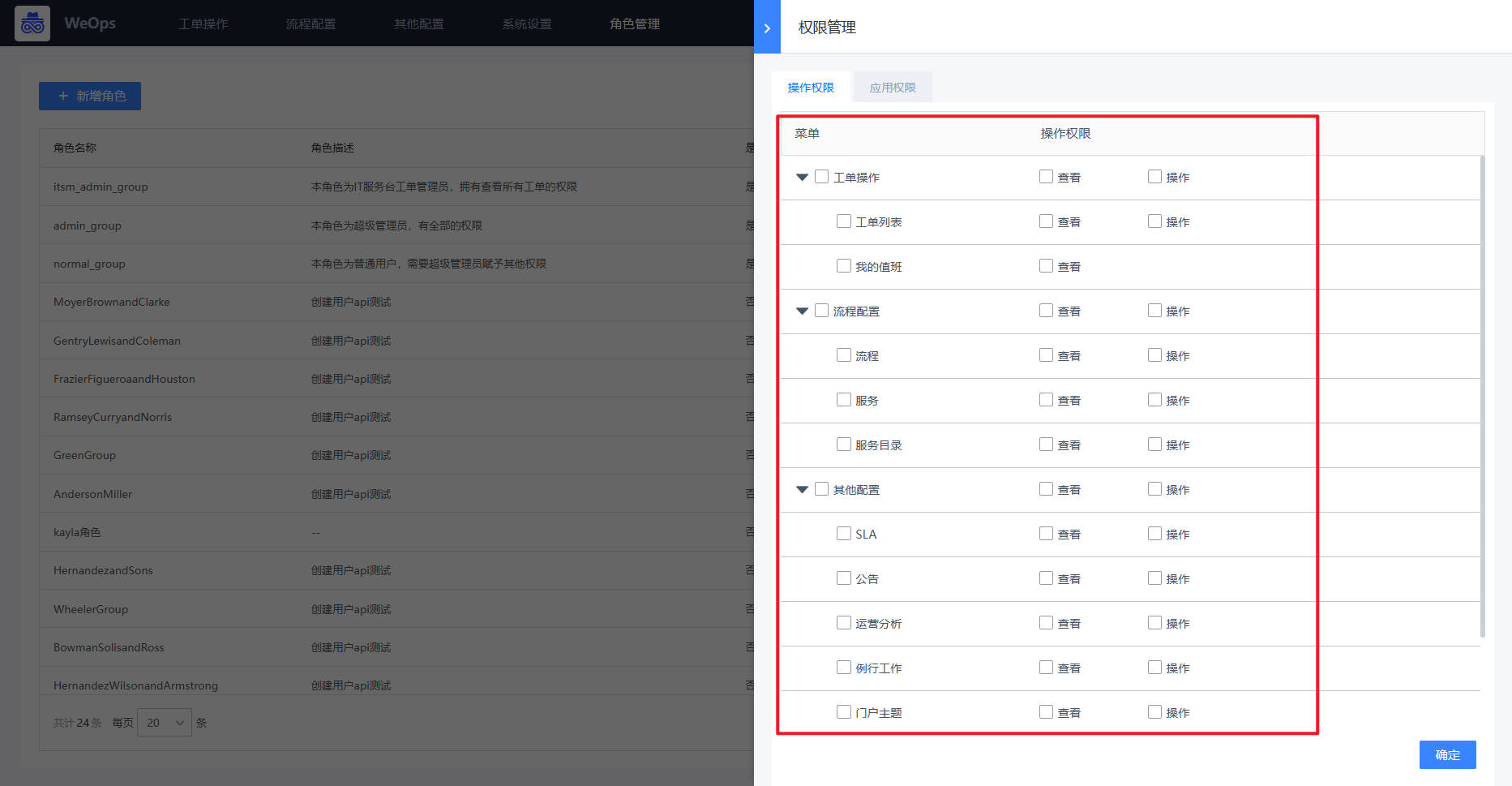
通知渠道配置
路径:管理-系统管理-通知渠道
邮件
邮件是相对较为常见的通知方式,对接配置比较简便,需提供一个发件箱,并允许蓝鲸对SMTP服务器的访问权限。参数说明如下:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到dest_url,ESB 仅作请求转发即可打通邮件配置
smtp_host: SMTP 服务器地址 (注意区分企业邮箱还是个人邮箱)
smtp_port: SMTP 服务器端口 (注意区分企业邮箱还是个人邮箱)
smtp_user: SMTP 服务器帐号
smtp_pwd: SMTP 服务器帐号密码 (一般为授权码)
smtp_usessl: 默认为 False
smtp_usetls: 默认为 False
mail_sender: 默认的邮件发送者 (smtp_user 相同)
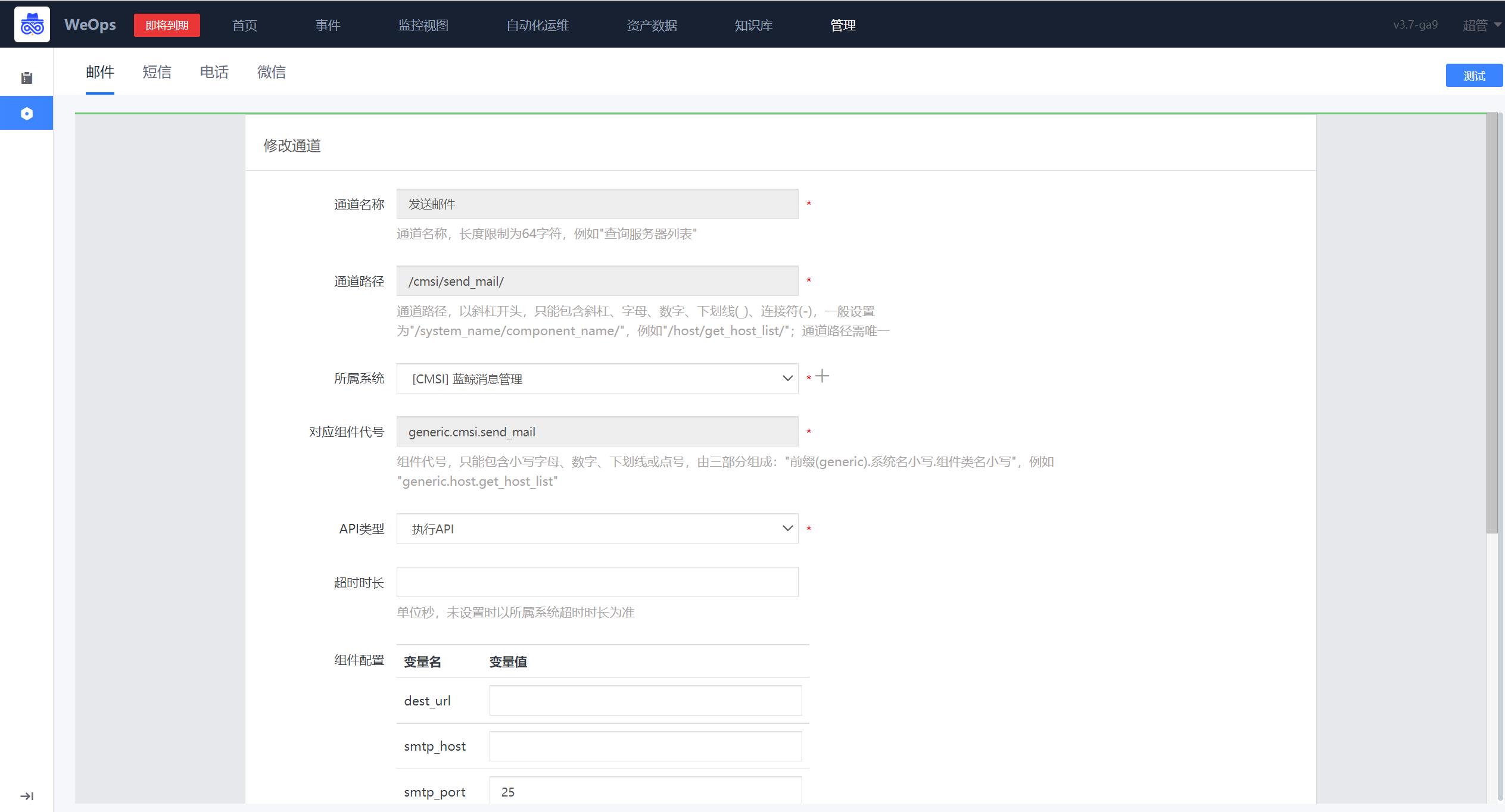
短信
企业采用的短信服务厂商不尽相同,目前蓝鲸仅支持腾讯云sms服务开箱即用,其他厂商对接需企业提供短信服务接口文档,并在蓝鲸侧做定制适配,以下以腾讯云sms为例列举参数说明:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到 dest_url,ESB 仅作请求转发即可打通短信配置
qcloud_app_id: SDK AppID
qcloud_app_key: App Key
qcloud_sms_sign: 在腾讯云 SMS 申请的签名,比如:腾讯科技
使用腾讯云发送短信,需要申请腾讯云的对应模板,以下为平台登录验证短信的模板内容:
1、两步验证的验证码模版: WeOps登录账号验证码:{},如非本人操作,请您放心忽略此短信。
2、重置密码的验证码模版: 验证码:{},如非本人操作,请您放心忽略此短信。
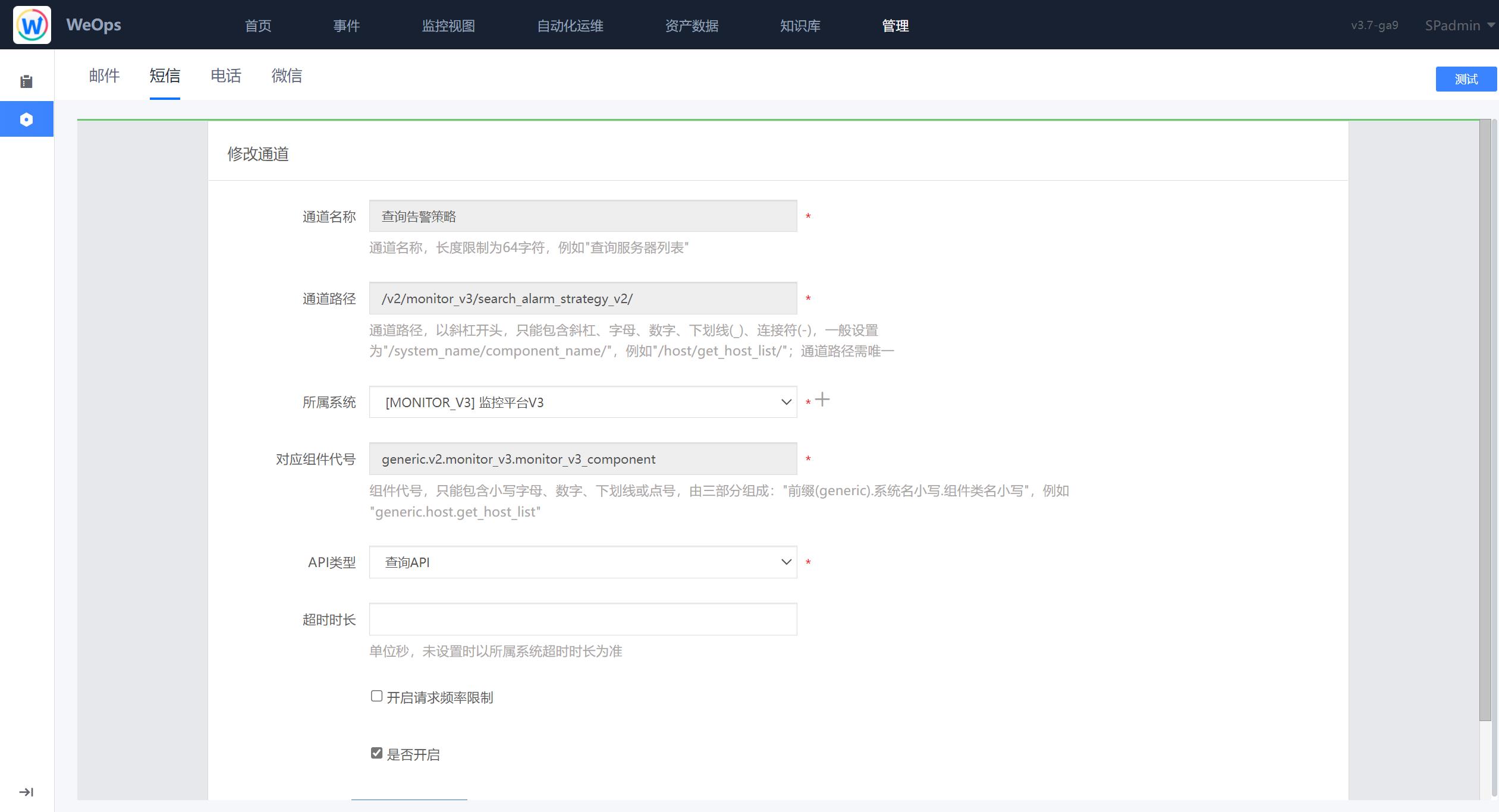
企业微信 1)企业微信对接需要满足以下先决条件:
a)统一告警中心SaaS(这里指SaaS所在蓝鲸appo服务器)能够访问外网(统一告警中心的告警会先把消息推送到企业微信服务器,然后企业微信再转发推送到客户的企业微信上,所以蓝鲸服务器需要能够访问公网);
b)蓝鲸平台的域名需要发布在公网;
c)外部访问蓝鲸公网域名+端口和在客户内网环境访问蓝鲸域名+端口需要一致,这是由告警中心这个SaaS的底层代码和企信的回调域设置决定的。事实上,告警中心移动端的配置是通过企信扫二维码实现的,这个二维码由SaaS生成,其实质是一个url,这个url只能从内网的蓝鲸服务器获取。因此,企信去访问这个url时,要先访问发布在公网的蓝鲸域名。强烈推荐蓝鲸平台采用https方式部署。
2)逻辑架构参考下图:
3)企业微信对接需在统一告警中心填写以下参数:
企业ID:在企业微信后台“我的企业”中可以获取到;
AgentID,Secret:在应用的基础信息中可以获取到

许可管理配置
背景介绍:企业客户想了解该系统的可用节点信息和许可有效期,并设置到期提醒。
路径:管理-系统管理-许可管理
可以查看激活状态,可用节点数量、有效期等信息,可设置到期提醒,设置成功后,可在菜单的左上角收到到期提醒提示。
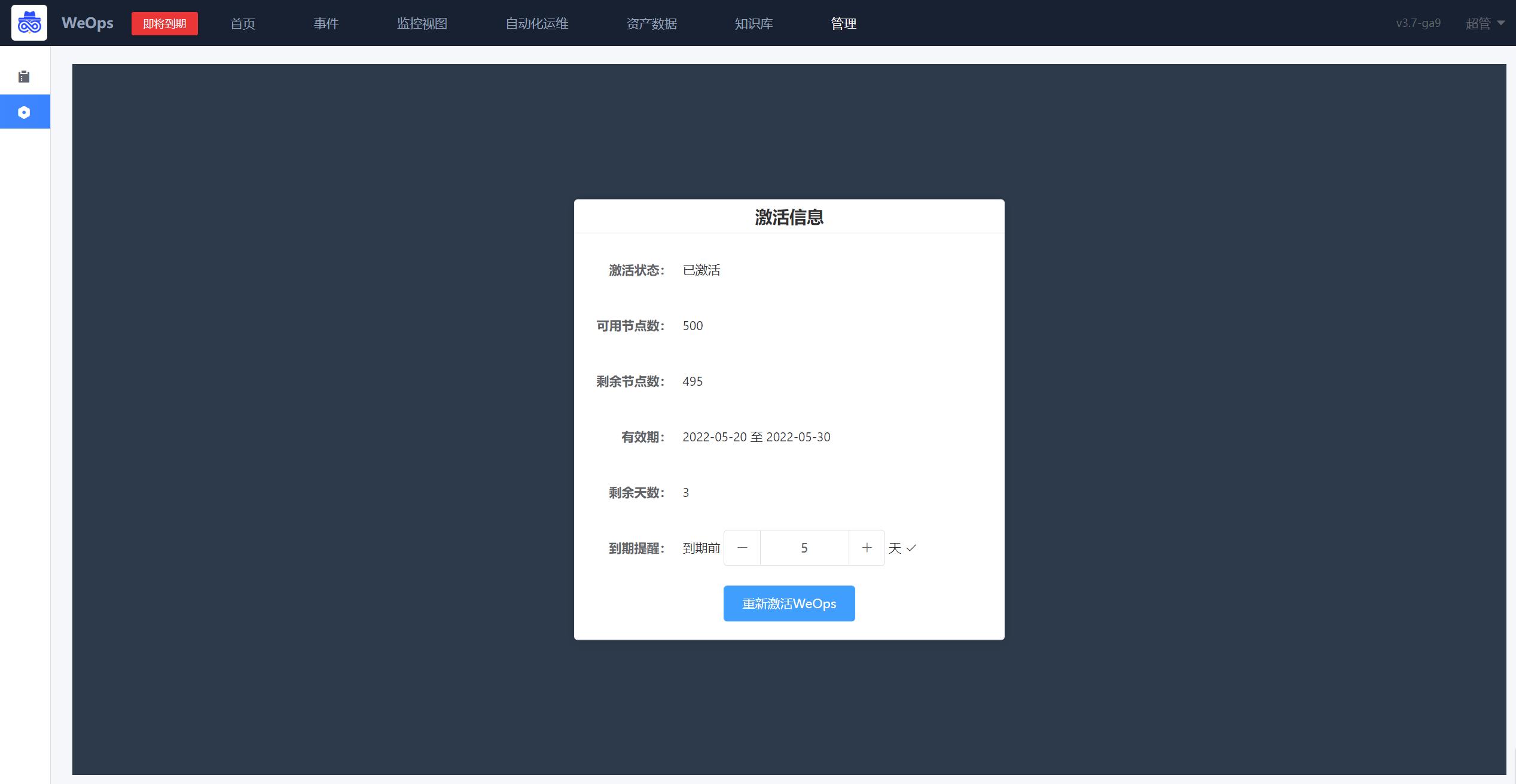
用户和角色配置
背景介绍:通过合理配置角色和权限管理,运维平台能够保护用户数据和系统安全,规范工作流程,提高工作效率,并满足合规要求。同时,角色和权限管理也能够减少人为错误和不必要的操作,增强平台的可靠性和可控性。
Step1:新建角色
路径:管理-系统管理-角色管理
如下图,点击“新建”按钮,填写相关信息,各个信息的说明如下
角色名称:用于标识角色的名称
上级角色:用于限定该角色可授权的范围,只能到上级角色的范围内进行授权
角色类型:分为“分级管理员”和“普通角色”,当用户有了分级管理员角色的时候,可以创建角色并进行授权。
角色描述:用于该角色的补充描述
Step2:角色授权
路径:管理-系统管理-角色管理
点击角色后的“设置权限”,对该角色进行授权,包括操作权限、应用权限、实例权限、日志权限。
①菜单操作权限
操作权限包括菜单权限和操作权限,用于限制该角色是否可以看到哪些菜单、以及对该菜单下的页面是否有查看/操作权限
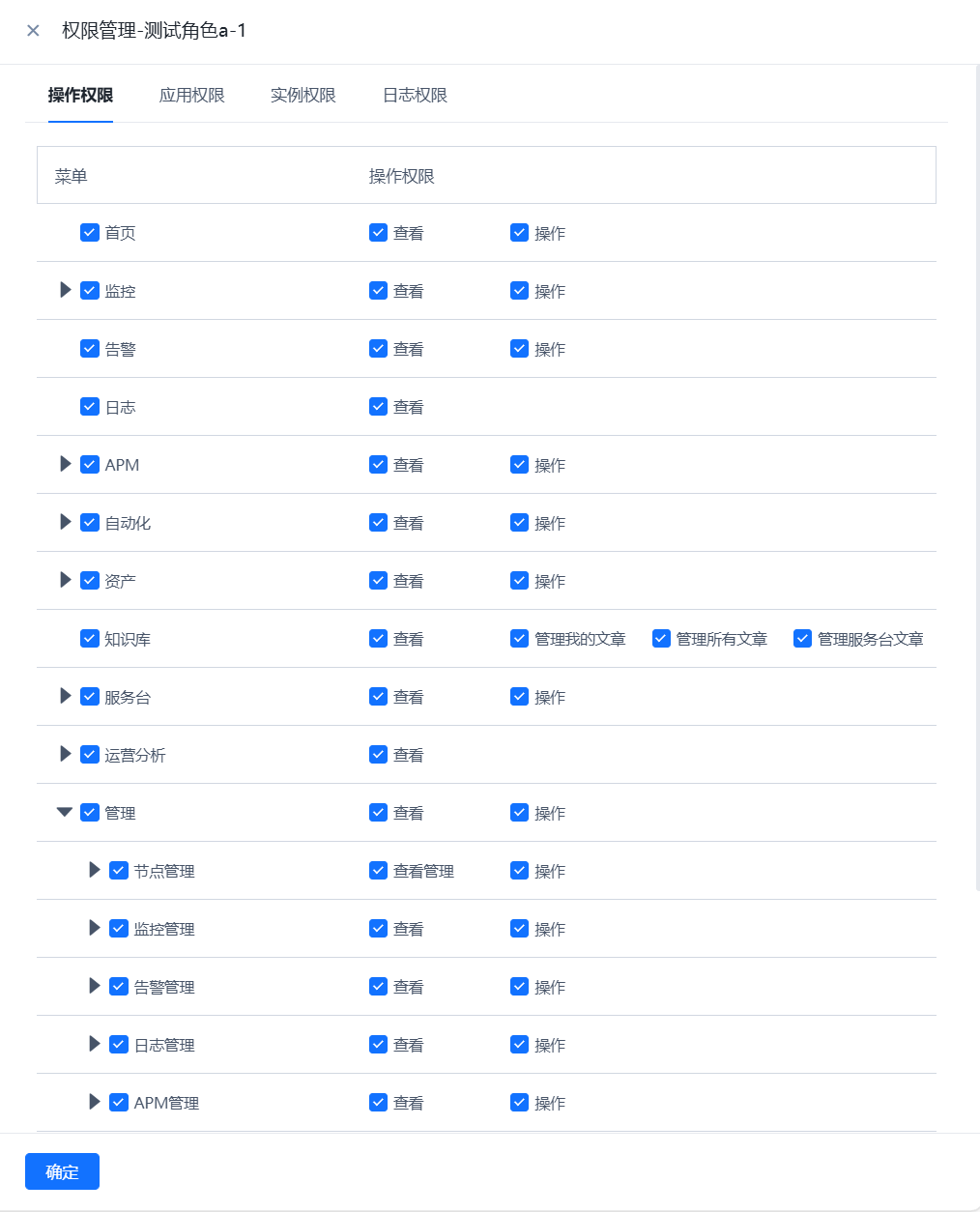
②应用权限 应用权限用于限制该角色是否可以看到该应用数据以及该应用下的资产数据,用户拥有该应用的权限,即拥有该应用下资产的查看/管理/监控/自动化操作等权限
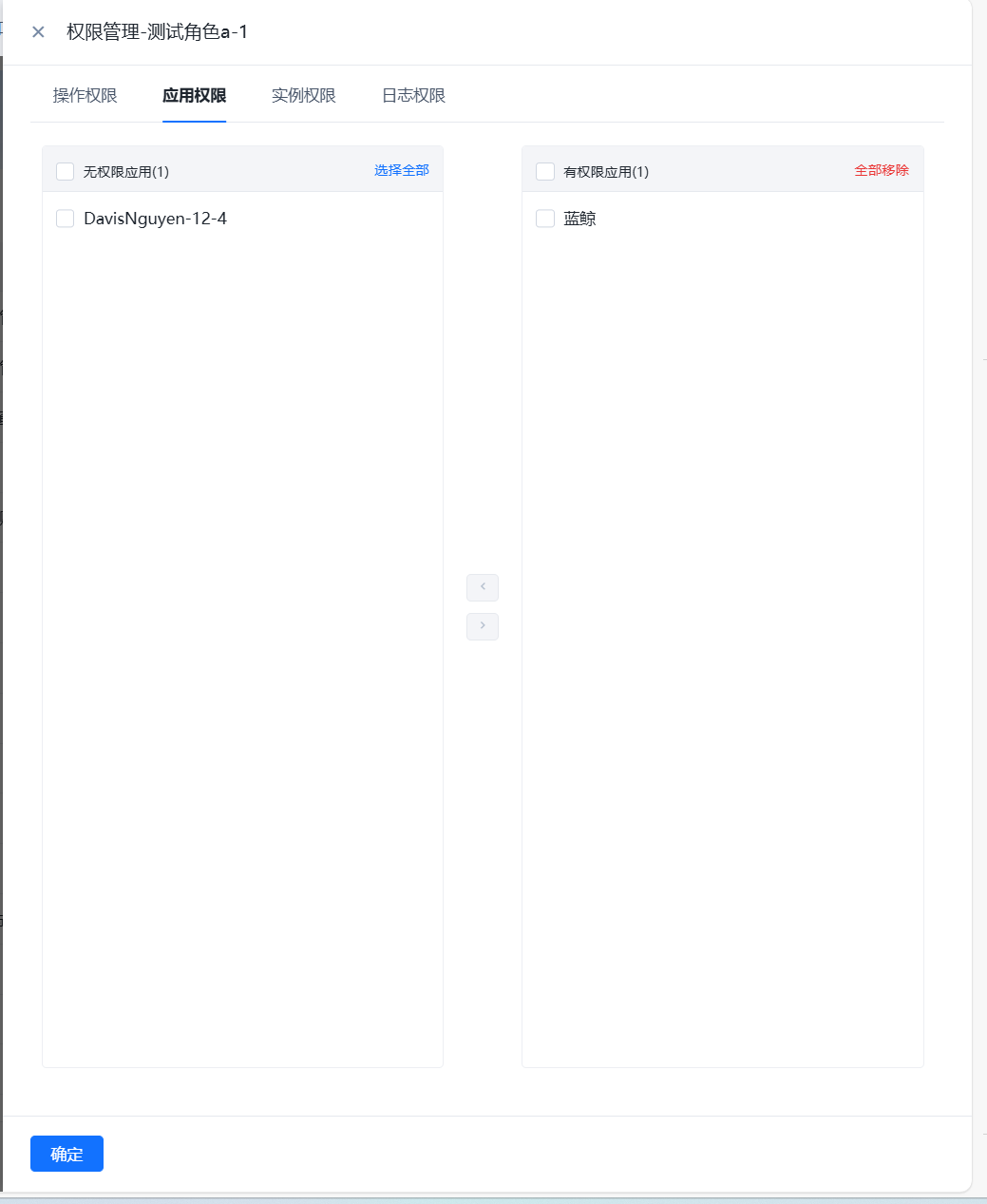
③实例权限 目前包括以下九类实例权限,拓扑图、仪表盘、文章、运维工具、监控采集任务、监控策略任务,资产权限、数据大屏、运营报表。用户拥有某些实例的权限,可以进行该实例的查看/操作。
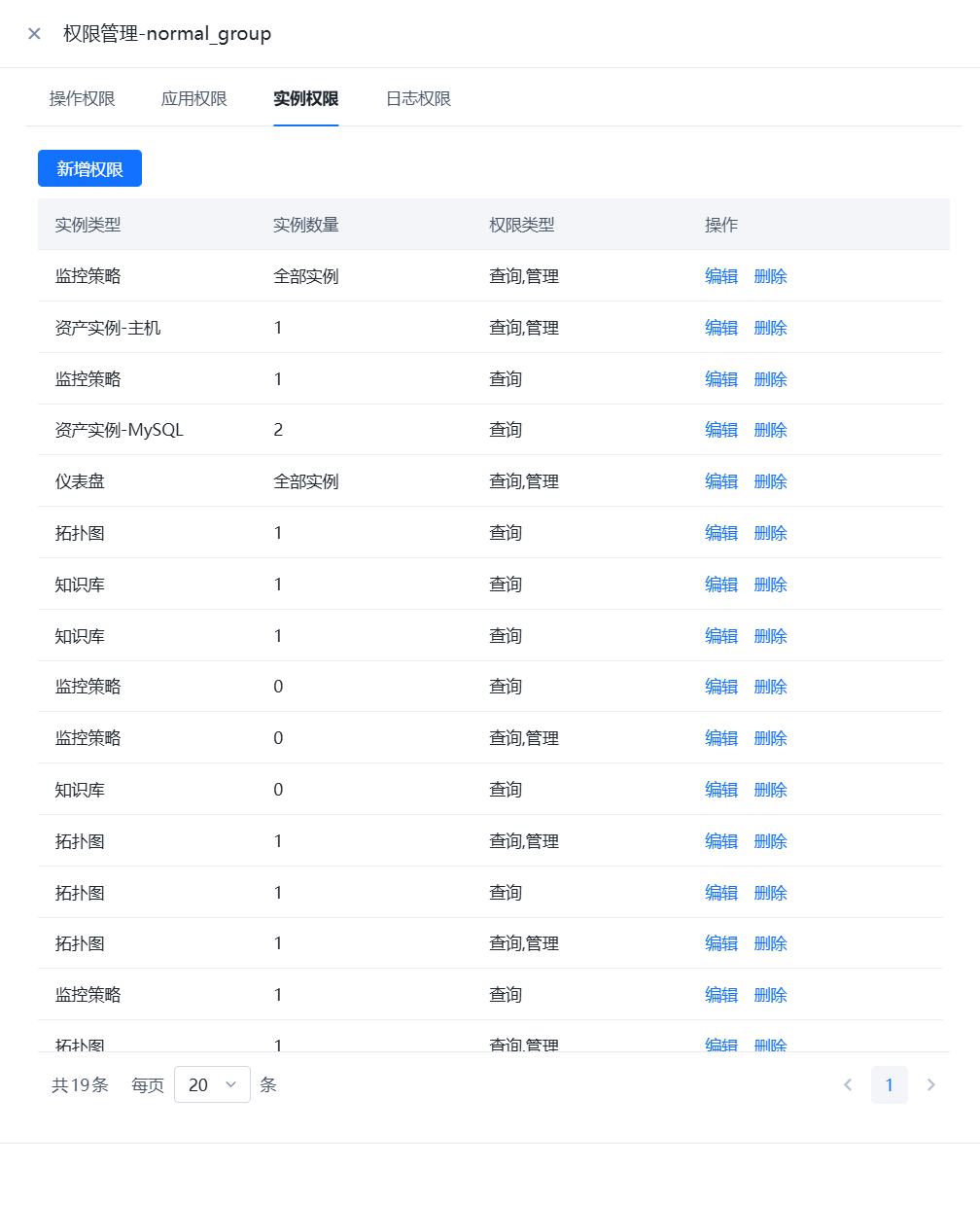
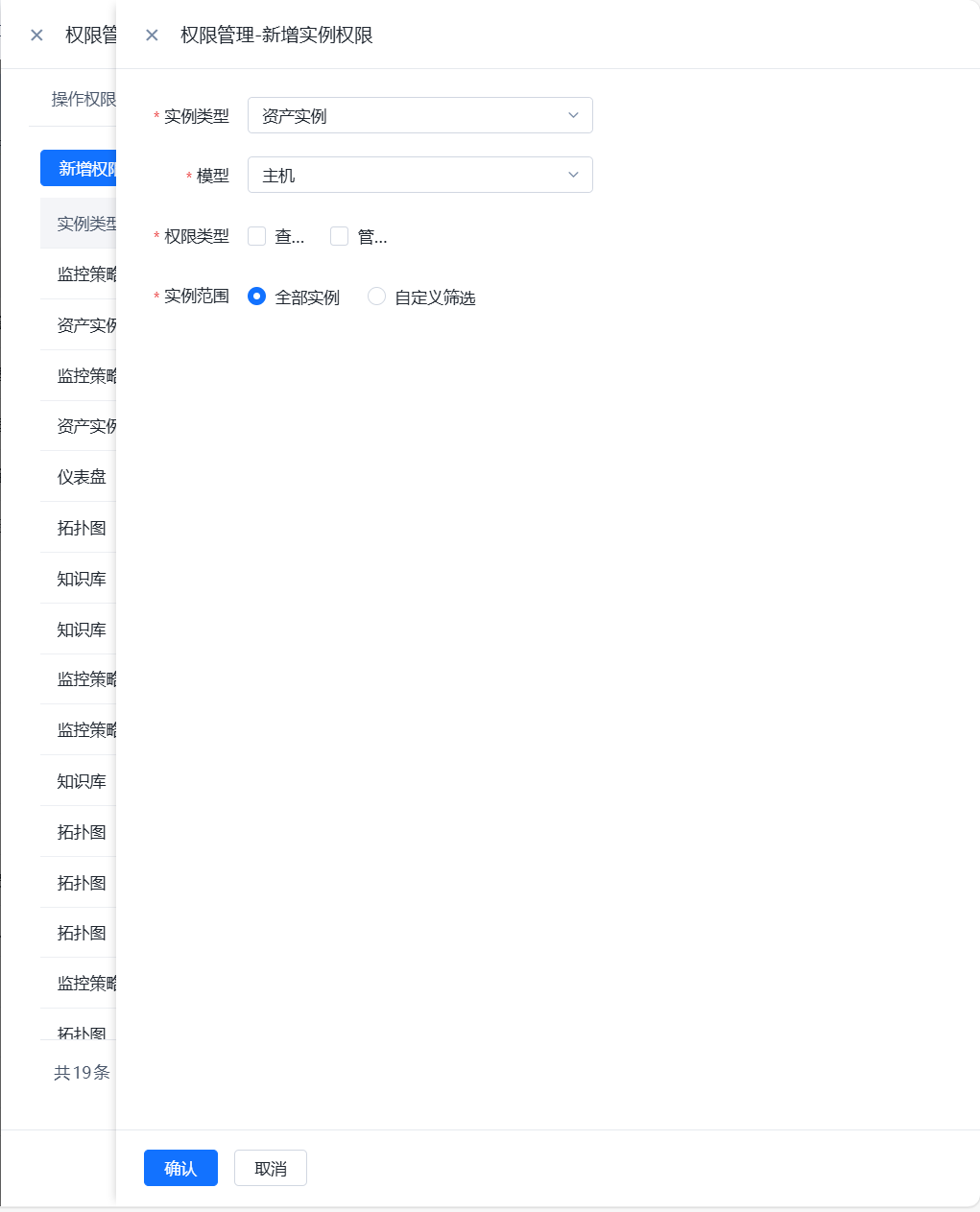
具体说明如下
拓扑图:支持对已经创建的拓扑图授权,包括查询(查看、收藏、克隆)和管理(修改和删除)
仪表盘:支持对已经创建的仪表盘授权,包括查询(查看、收藏、导出、克隆、设为首页)和管理(修改和删除)
知识库文章:支持对已经创建的知识库授权,包括查询(查看、收藏)和管理(修改、删除、设为知识库文章)
运维工具:支持对已经创建的运维授权,包括管理(编辑、删除)和使用(查看、自动化使用)
监控采集/监控策略任务:支持对已经创建的任务进行授权,包括查询(查看)和管理(修改、删除)
数字大屏/运营报表:支持对已经创建实例进行查看权限的授予
资产实例权限:支持对资产实例进行授权,角色拥有的资产实例权限为”有权限应用下的资产+专门授予的资产实例权限“另外,所有类型的资产支持两类授权方式,全部实例和自定义筛选 全部实例:只要上级角色为admin_group的角色,才可以选择全部实例,一旦角色有了全部实例的权限,后续新增加的实例也支持查看或者管理。自定义筛选:支持勾选特定的资产给这个角色
④日志权限 日志权限用于限制该角色是否可以看到该日志分组以下日志数据,用户拥有该日志分组的权限,即拥有日志搜索、分析、资产日志查看等权限。
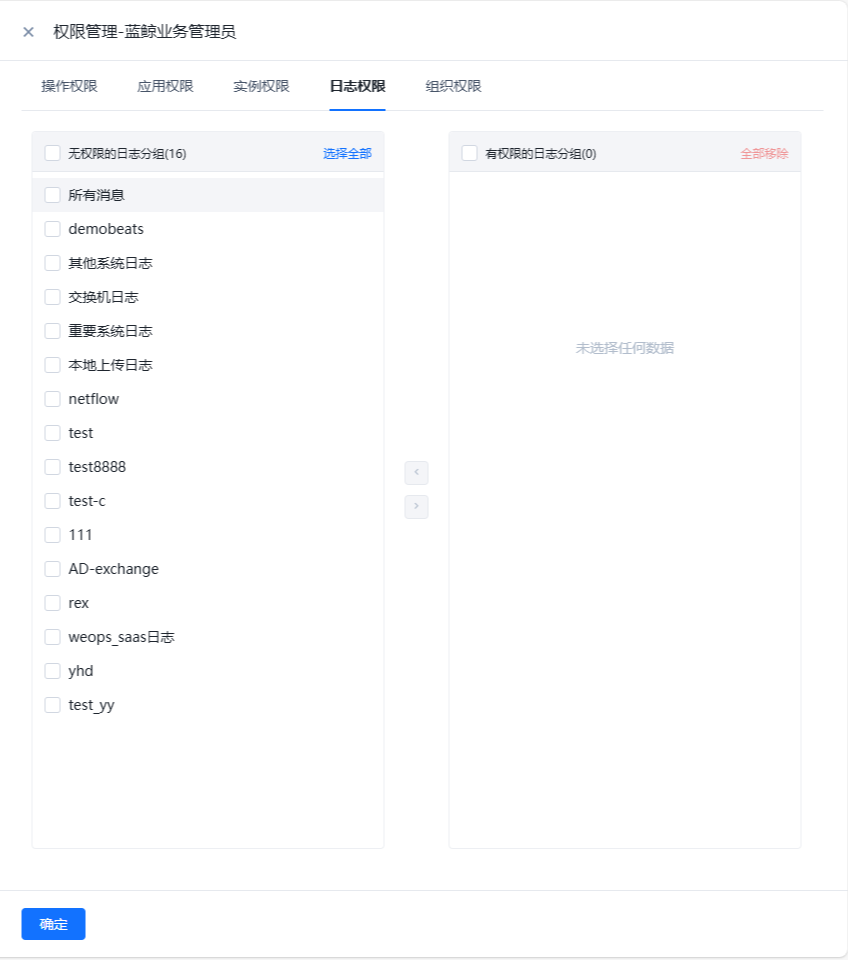
⑤组织权限 组织权限用于限制该角色是否可以看到该组织结构以及组织下的用户,当用户拥有该组织权限,可以进行组织结构的操作和组织下人员的操作。
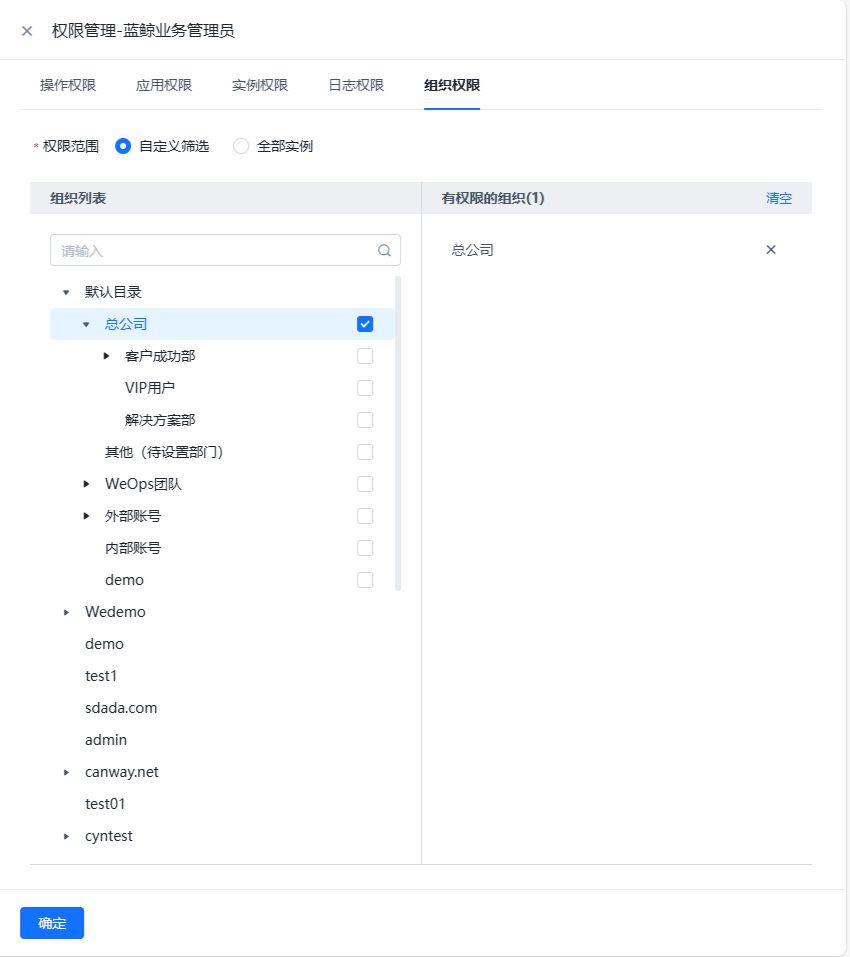
Step3:赋予人员/组织角色
路径:管理-系统管理-人员管理
①按人员授予
如下图,可以在“角色管理在中点击”人员和组织“,选择该角色适用的人员,也可以在“人员管理”中,选择需要设置的人员,在用户角色中选择对应角色,即可把该角色的权限赋予对应人员。 若某人员赋予多个角色,则他将会拥有这多个角色的所有权限。
②按组织授予
如下图,可以在“角色管理在中点击”人员和组织“,选择该角色适用的组织,也可以在“用户组织”中,选择需要设置的组织,下拉选择对应角色,即可把该角色的权限赋予对应组织。 当用户属于某个组织时,向上递归找到该组织结构下所有角色,该用户也就拥有了所有组织角色。比如:组织架构为“总公司-产品研发部-研发组”,小王属于研发组,那么小王将拥有“研发组-产品研发部-总公司”所有的组织角色。
某个用户最终的权限,等于“用户角色权限+组织角色权限”。
Step4:分级管理员
路径:管理-系统管理-角色管理
当用户拥有分级管理员角色的,支持创建角色,并给角色授权,角色的授权受该角色的上级角色的范围影响。
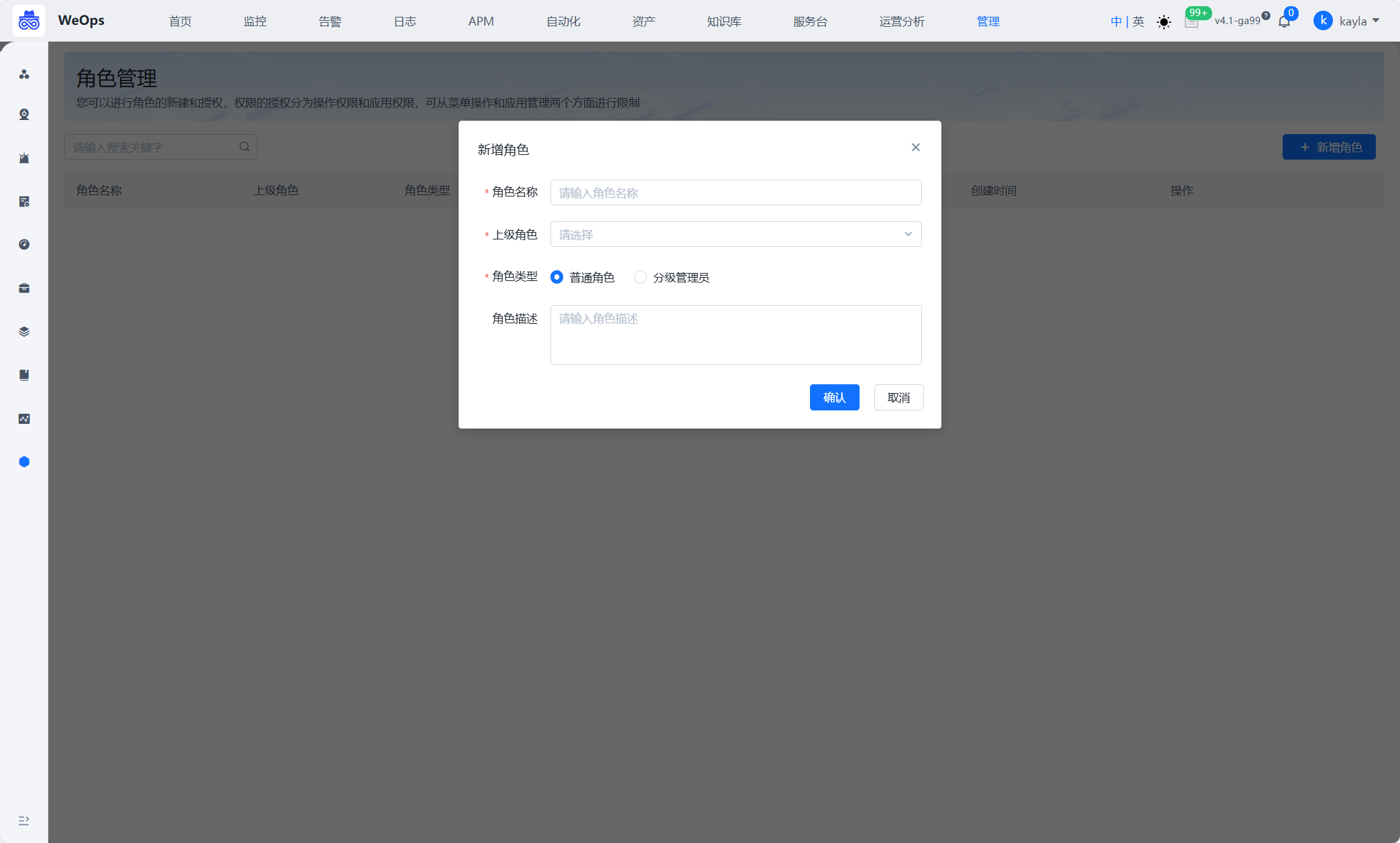
移动端配置
用户需要在企微、钉钉等IM上使用weops移动端,可以通过配置实现IM的接入,包括服务台移动端和监控告警移动端,目前内置企微、钉钉和飞书三类IM。
功能介绍
- 认证能力:支持企微,飞书,钉钉等第三方IM工具的第三方应用接入WeOps、服务台的PC端或移动端的
- 通知功能:可支持配置IM通知,消息能力下推到CMSI层,可方便其他Saas的调用,如ITSM的工单通知等
- 用户同步能力:可支持配置IM工具上的组织架构及用户同步到用户管理和WeOps,提供定时和实时同步
前提条件
- IM用户的个人信息必须与蓝鲸用户管理的个人信息某字段对应上,如通过插件用户同步时,务必实现该映射如钉钉的mobile 和蓝鲸用户的telephone匹配
环境变量
使用WeOps IM插件
- 新增环境变量 BKAPP_WEOPS_IM_AUTH 是否启用weops im认证,默认是不开启,为esm原先IM插件认证,设置1为开启
- 如开启im后,weops先配完对应IM插件,然后手动调用以下接口,给ESM引入对应IM消息能力 {itsm_uri}/helper/register_cmsi_msg/ 如http://paas.weops.com/o/bk_itsm/helper/register_cmsi_msg/
IM插件对接配置
目前WeOps已内置企微,飞书,钉钉三类IM,可以直接配置接入,以下重点介绍三类内置IM的配置过程,若使用的IM不是以下三类,需要定制化开发。
开启对应插件
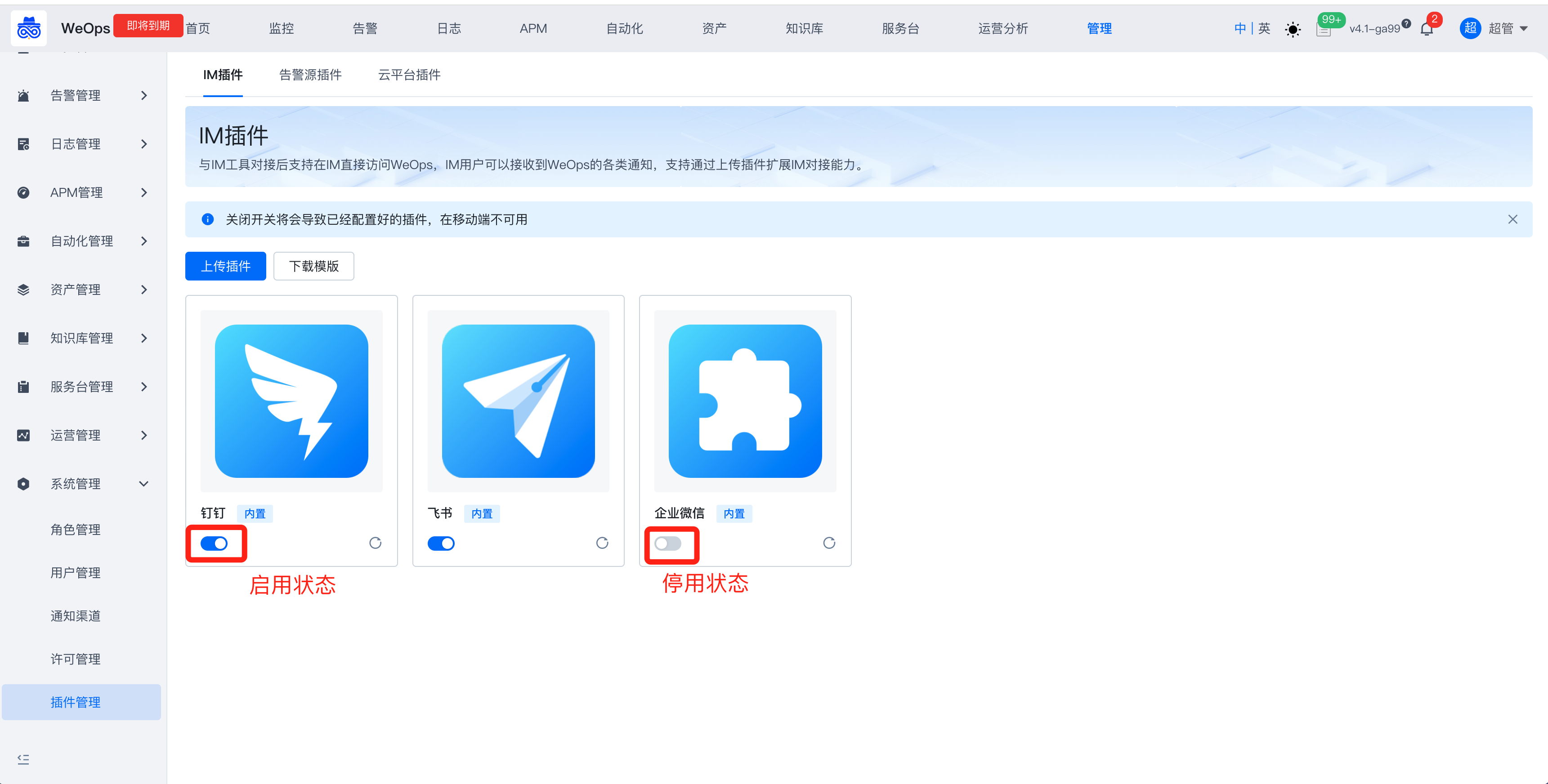
修改插件配置
企业微信
后台配置
- 进入飞书后台
公网链接: https://work.weixin.qq.com/wework_admin/frame#apps
私有化链接可咨询客户
- 创建应用
3.记录AgentId,Secret; CORP_ID 后面用于插件配置
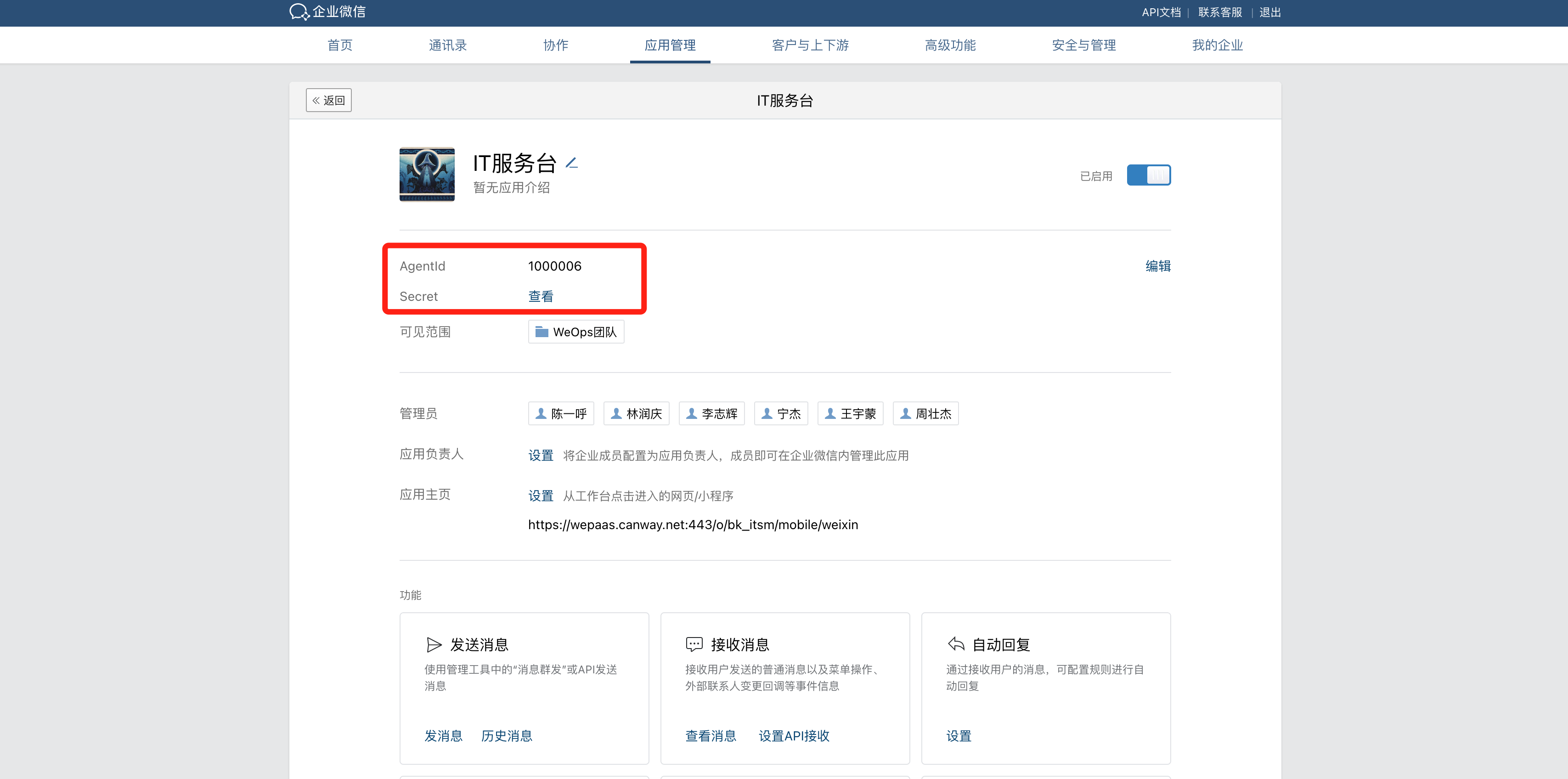
4.配置访问地址 分别对应插件配置的移动端外网地址,PC外网地址
paas.weops.com 为测试域名,公网https需加端口443。需修改为客户对应的域名,如
WeOps配置
WeOps Pc: https://paas.weops.com:443/o/weops_saas/
WeOps Mobile:https://paas.weops.com:443/o/weops_saas/mobile/
服务台配置
WeOps服务台 Pc:https://paas.weops.com:443/o/weops_saas/itsm/
WeOps服务台 Mobile:https://paas.weops.com:443/o/weops_saas/to/bk_itsm/mobile/im/
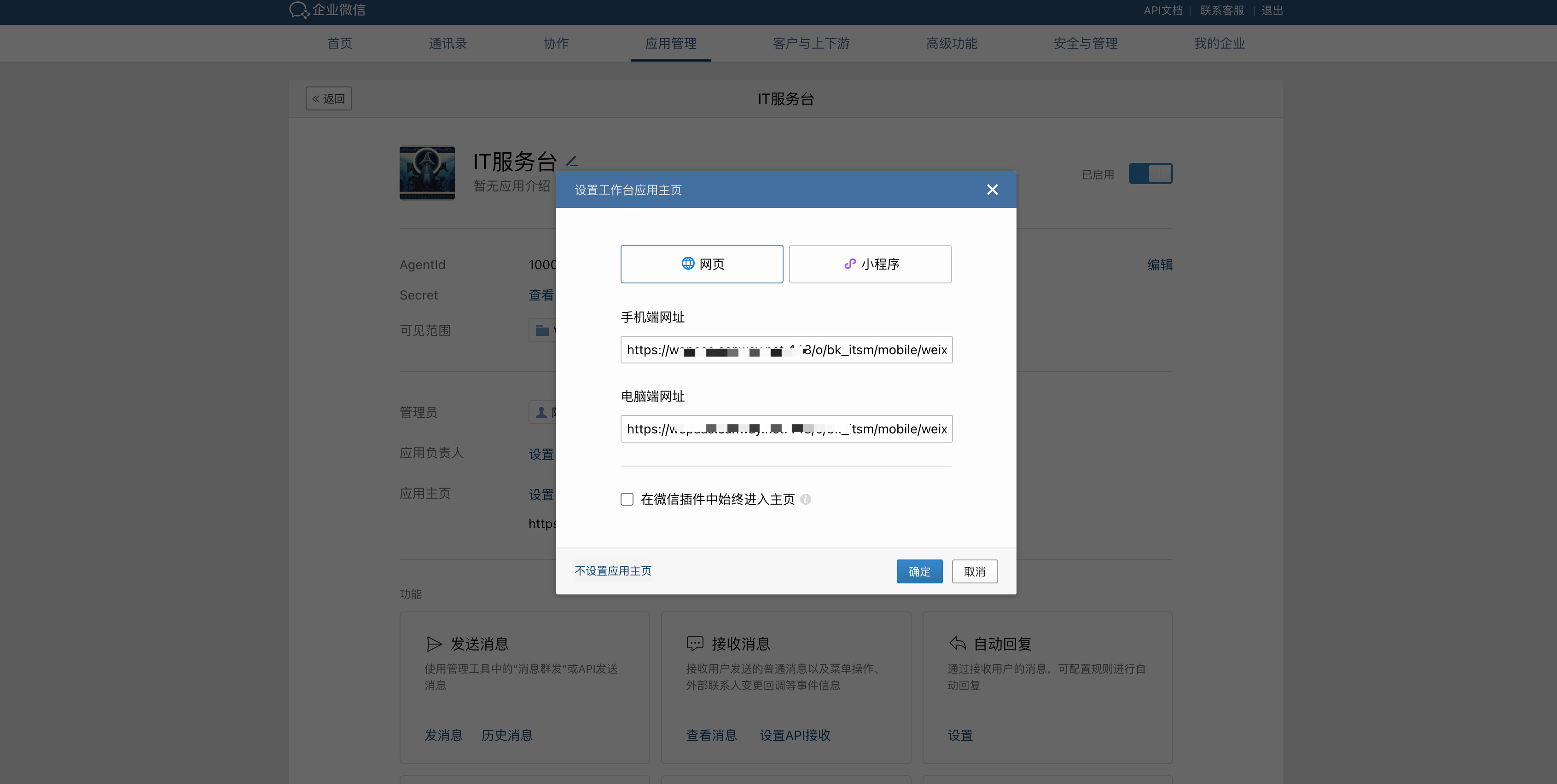
5.配置可信域名等
网页授权及JS-SDK:外网访问地址(
需写端口)网页授权回调域:内网访问地址(
需写端口)企业可信IP:nginx出站公网IP
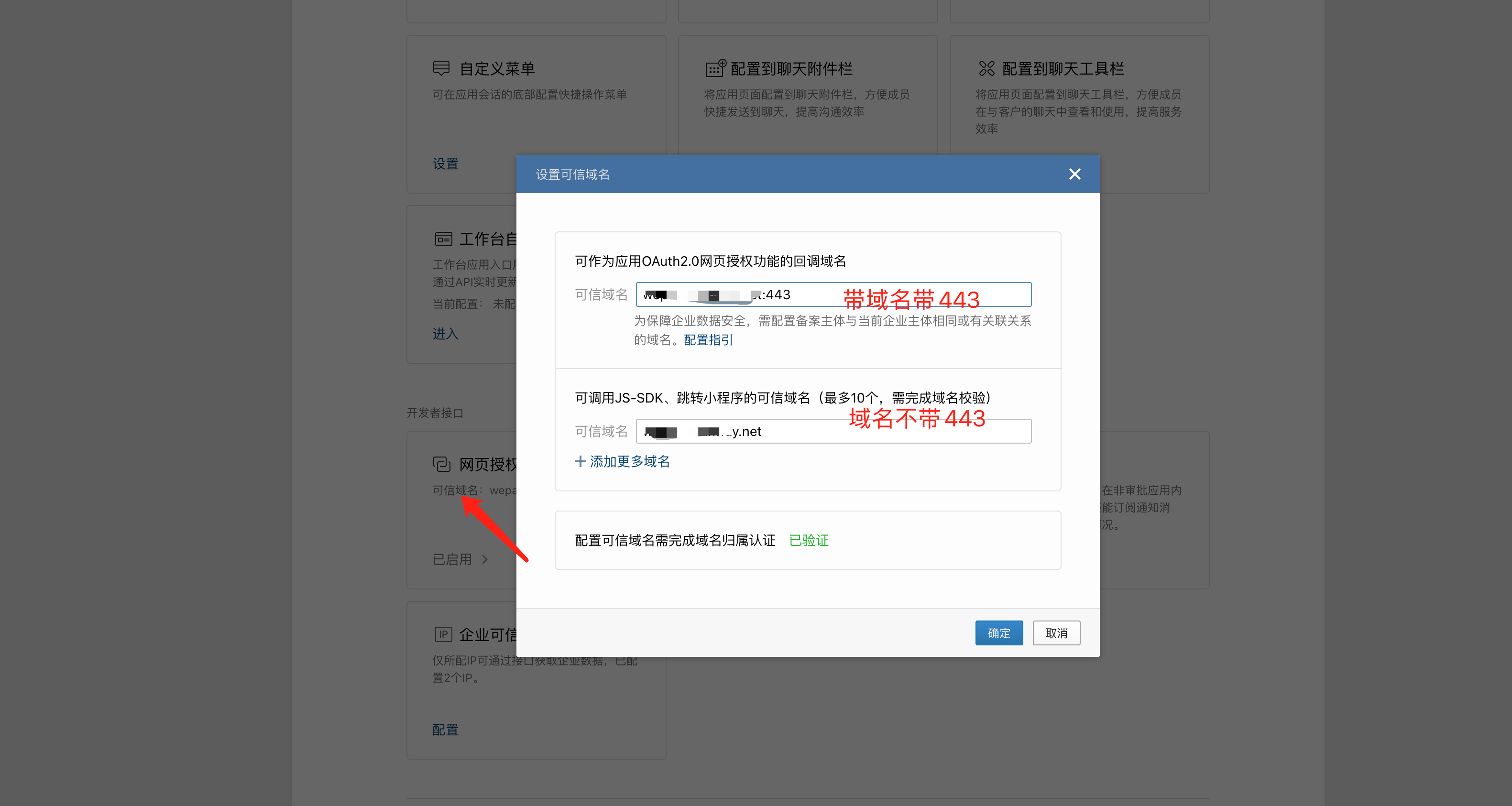
插件配置
企业微信后台配置好后,返回“WeOps-管理-系统管理-插件管理”页面,进行插件参数的配置。
必须修改的部分,已标红,修改的内容参考上面的后台配置,其他配置可按需调整
| Key | Value | Name | Type | Choices |
|---|---|---|---|---|
| CORP_ID | wx5b8412466bc7ca04 | 企业微信CORP_ID | – | – |
| AGENT_ID | 1000025 | 企业微信AgentID | – | – |
| CORP_SECRET | -g30AGu5tIk7RcrB29J6YJcIubdX8vRQEIKVl4EnbE8 | 企业微信密钥 | encrypt | – |
| SCOPE | snsapi_privateinfo | 应用授权作用域 | – | – |
| INDEX_URL | https://open.weixin.qq.com/connect/oauth2/authorize | 企业微信重定向请求地址 | – | – |
| TOKEN_URL | https://qyapi.weixin.qq.com/cgi-bin/gettoken | 获取access_token的请求地址 | – | – |
| USERINFO_URL | https://qyapi.weixin.qq.com/cgi-bin/user/getuserinfo | 获取访问用户身份 | – | – |
| USER_URL | https://qyapi.weixin.qq.com/cgi-bin/user/getuserdetail | 获取访问用户敏感信息 | – | – |
| MESSAGE_URL | https://qyapi.weixin.qq.com/cgi-bin/message/send | 发送通知接口 | – | – |
| EXTRANET_URI | https://paas.weops.com:443/o/weops_saas/mobile/ | 移动端外网地址 | – | – |
| PC_EXTRANET_URI | https://paas.weops.com:443/o/weops_saas/ | pc端外网地址 | – | – |
| USER_AGENT_FIELD | wxwork | pc端User-Agent识别标识 | – | – |
| USER_MAP_FIELD | telephone:mobile | 用户映射字段(XXX:XXX) | – | – |
| NOTIFY_MAP_FIELD | userid | 通知字段映射 | – | – |
| DIST_PC_MOBILE | 1 | 是否主动区分打开客户端 | switch | – |
| CATEGORY_DOMAIN | default.local | 用户域 | select | default.local |
| ONLY_SYNC_IM | 0 | 是否只同步IM信息(不用补部门及人员) | switch | – |
| IS_OPEN_SYNC | 0 | 自动同步用户 | switch | – |
| SYNC_PERIOD | 1 | 定时同步周期(小时) | select | 1, 3, 6, 12, 24 |
飞书
后台配置
- 进入飞书后台
公网链接: https://open.feishu.cn
私有化链接可咨询客户
- 创建应用
3.记录App Id; AppSecret 后面用于插件配置
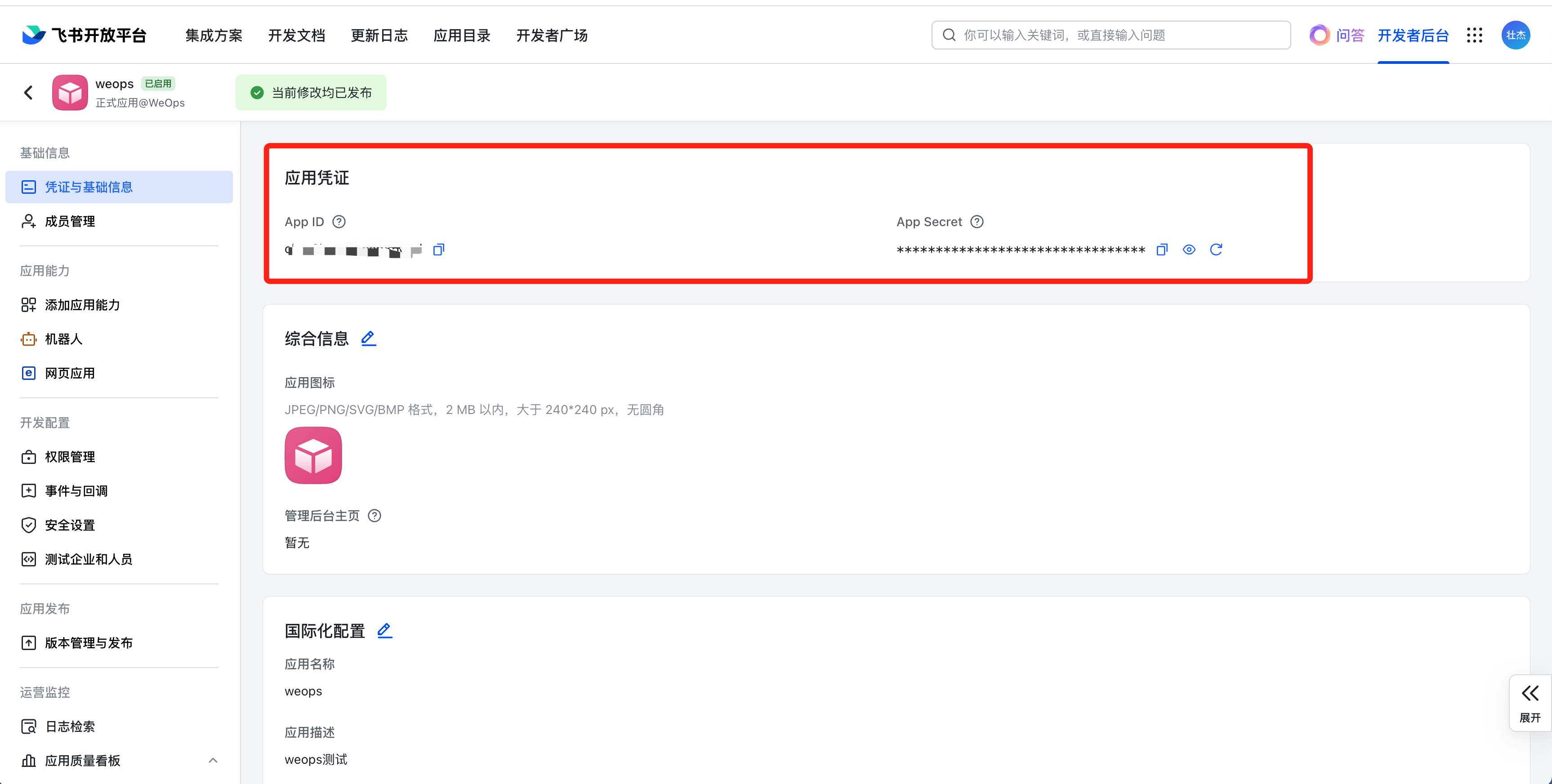
4.配置访问地址 分别对应插件配置的移动端外网地址,PC外网地址
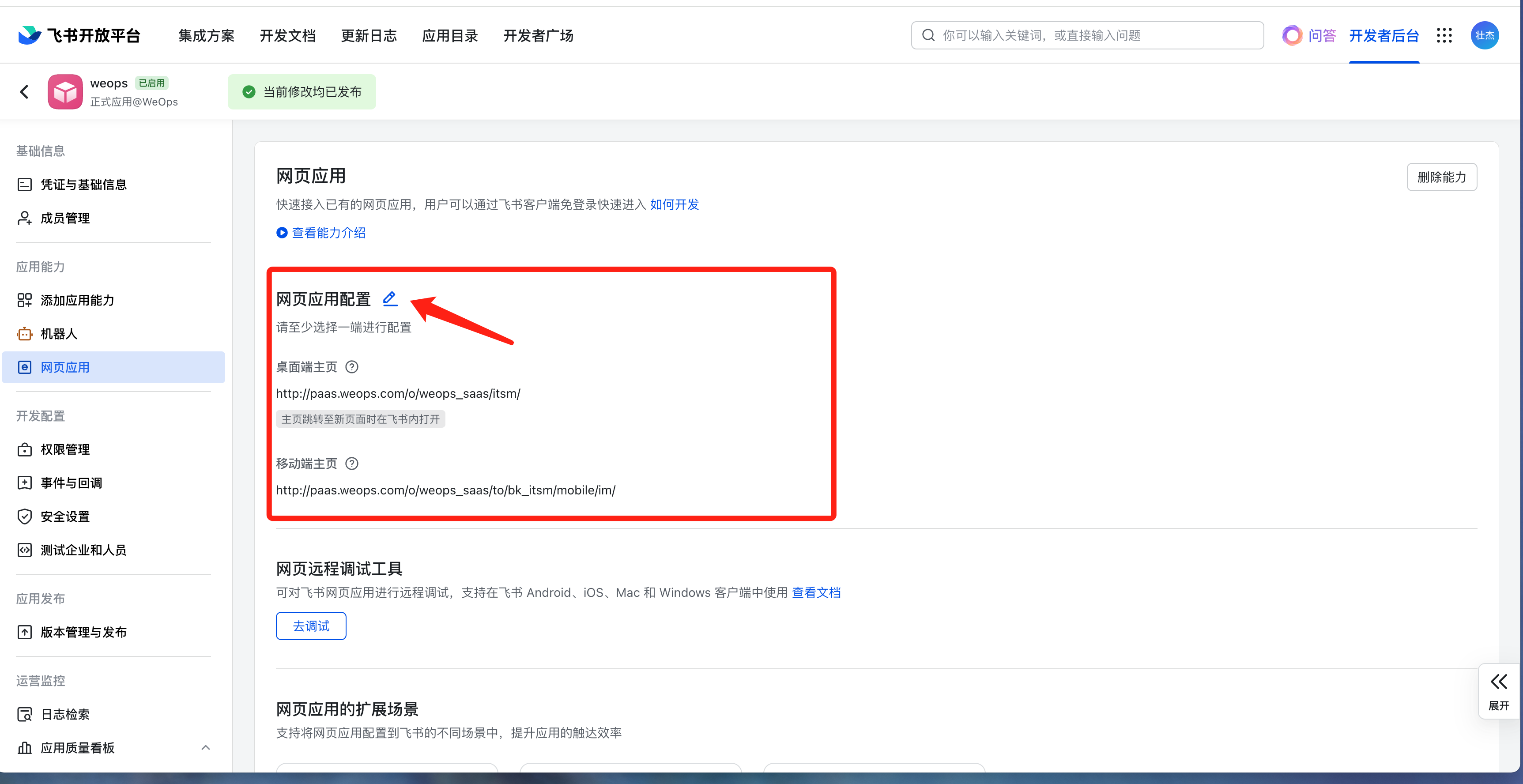
paas.weops.com 为测试域名,需修改为客户对应的域名
WeOps配置
WeOps Pc: http://paas.weops.com/o/weops_saas/
WeOps Mobile:http://paas.weops.com/o/weops_saas/mobile/
服务台配置
WeOps服务台 Pc:http://paas.weops.com/o/weops_saas/itsm/
WeOps服务台 Mobile:http://paas.weops.com/o/weops_saas/to/bk_itsm/mobile/im/
5.添加外网回调地址
与4填写的内容一致即可
- 权限开通
权限开通列表,搜索栏查询对应的Code
- 个人信息权限:contact:user.base:readonly;contact:user.department:readonly;contact:user.email:readonly;contact:user.employee_id:readonly;contact:user.id:readonly;contact:user.phone:readonly;corehr:person.email:read;corehr:person.phone:read
- 通讯录权限(用于用户同步):contact:contact.base:readonly ;contact:department.base:readonly;contact:department.organize:readonly;contact:user.department_path:readonly
- 消息权限:aily:message:write;im:message;im:message:send_as_bot
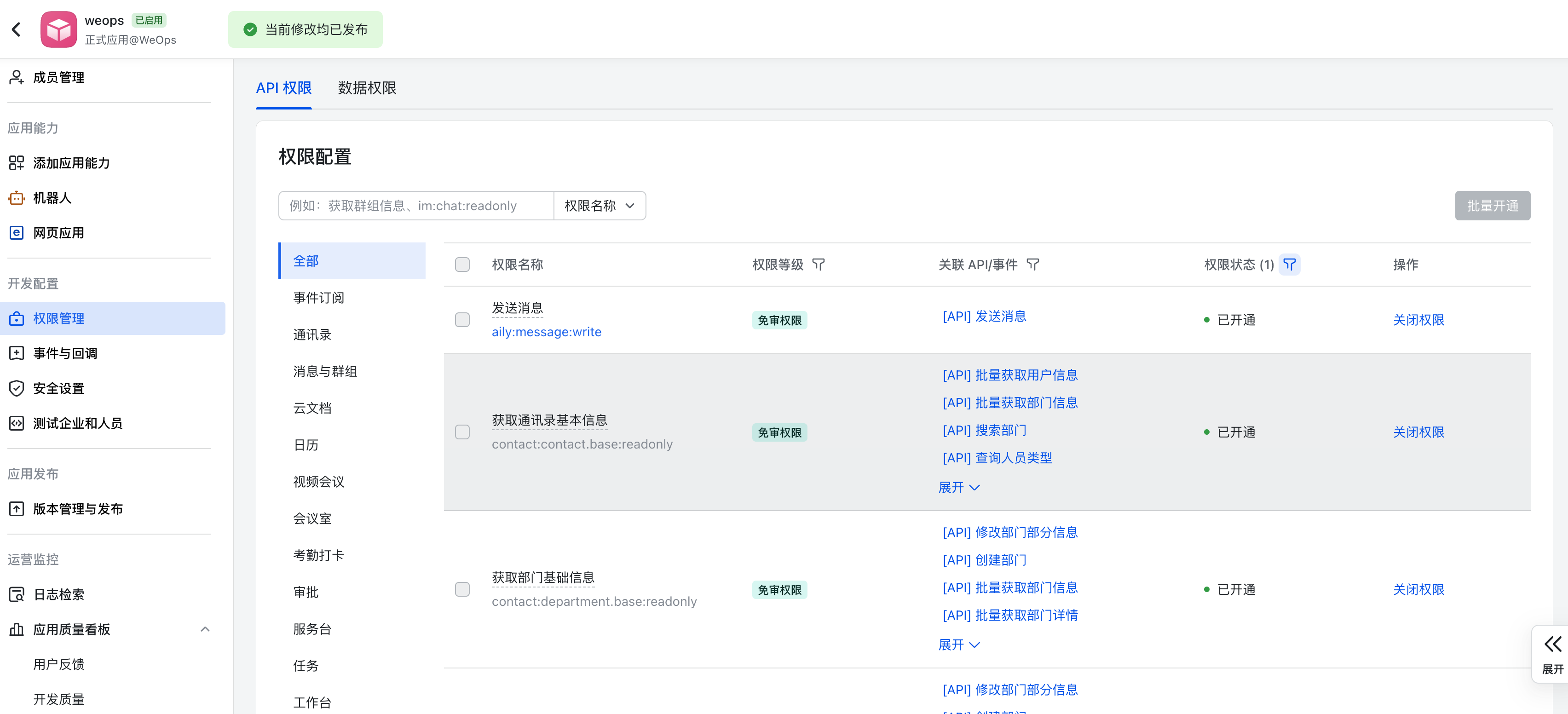
插件配置
飞书后台配置好后,返回“WeOps-管理-系统管理-插件管理”页面,进行插件参数的配置。
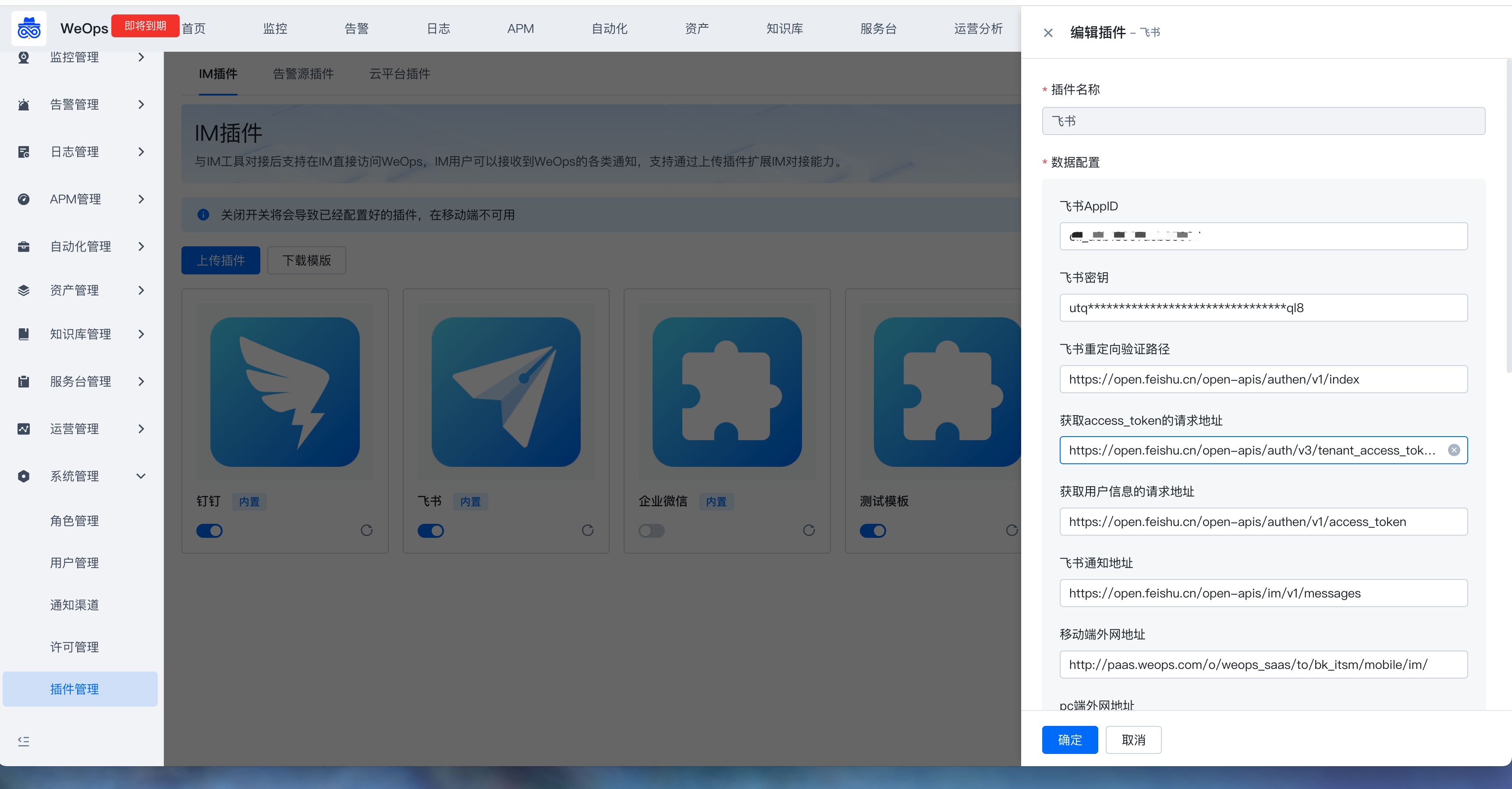
必须修改的部分,已标红,修改的内容参考上面的后台配置,其他配置可按需调整
| Key | Value | Name | Type | Choices |
|---|---|---|---|---|
| APP_ID | cli_a23b1acd22f9100b | 飞书AppID | – | – |
| APP_SECRET | d2XSJzC2g8AzqoC22xy4pGddnsYpcb5lX4 | 飞书密钥 | encrypt | – |
| INDEX_URL | https://open.feishu.cn/open-apis/authen/v1/index | 飞书重定向验证路径 | – | – |
| TOKEN_URL | https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal | 获取access_token的请求地址 | – | – |
| USERINFO_URL | https://open.feishu.cn/open-apis/authen/v1/access_token | 获取用户信息的请求地址 | – | – |
| MESSAGE_URL | https://open.feishu.cn/open-apis/im/v1/messages | 飞书通知地址 | – | – |
| EXTRANET_URI | http://paas.weops.com/o/weops_saas/mobile/ | 移动端外网地址 | – | – |
| PC_EXTRANET_URI | http://paas.weops.com/o/weops_saas/ | pc端外网地址 | – | – |
| USER_AGENT_FIELD | Lark | pc端User-Agent识别标识 | – | – |
| USER_MAP_FIELD | email:email | 用户映射字段(XXX:XXX) | – | – |
| NOTIFY_MAP_FIELD | 通知字段映射 | – | – | |
| DIST_PC_MOBILE | 1 | 是否主动区分打开客户端 | switch | – |
| CATEGORY_DOMAIN | default.local | 用户域 | select | API获取 |
| BASE_DEPT_ID | 0 | 根部门ID | – | – |
| ONLY_SYNC_IM | 0 | 是否只同步IM信息(不用补部门及人员) | switch | – |
| IS_OPEN_SYNC | 0 | 自动同步用户 | switch | – |
| SYNC_PERIOD | 1 | 定时同步周期(小时) | select | 1, 3, 6, 12, 24 |
钉钉
后台配置
- 进入钉钉后台
公网链接: https://open-dev.dingtalk.com
私有化链接可咨询客户
- 创建应用
3.记录AgentId,AppKey, AppSecret,cropId 后面用于插件配置
4.配置访问地址 分别对应插件配置的移动端外网地址,PC外网地址
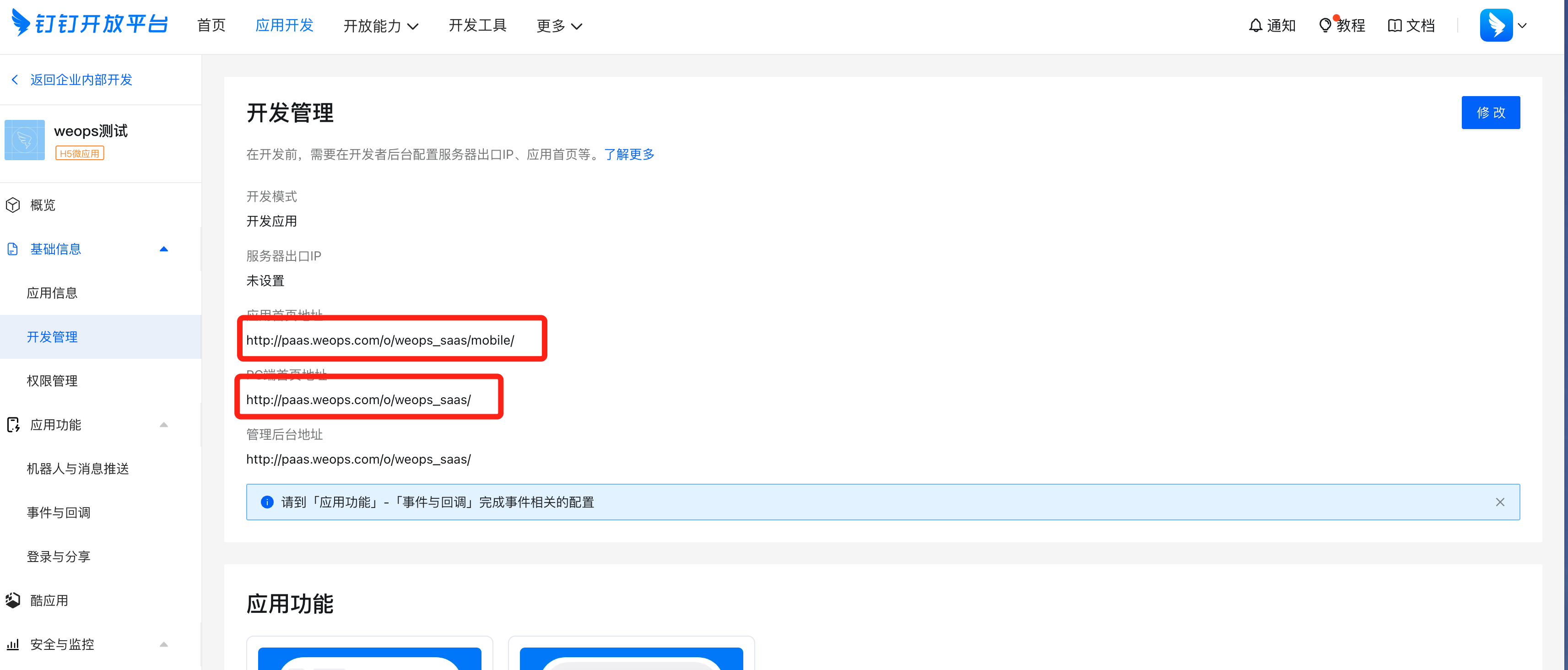
paas.weops.com 为测试域名,需修改为客户对应的域名
WeOps配置
WeOps Pc: http://paas.weops.com/o/weops_saas/
WeOps Mobile:http://paas.weops.com/o/weops_saas/mobile/
服务台配置
WeOps服务台 Pc:http://paas.weops.com/o/weops_saas/itsm/
WeOps服务台 Mobile:http://paas.weops.com/o/weops_saas/to/bk_itsm/mobile/im/
5.添加外网回调地址
与4填写的内容一致即可
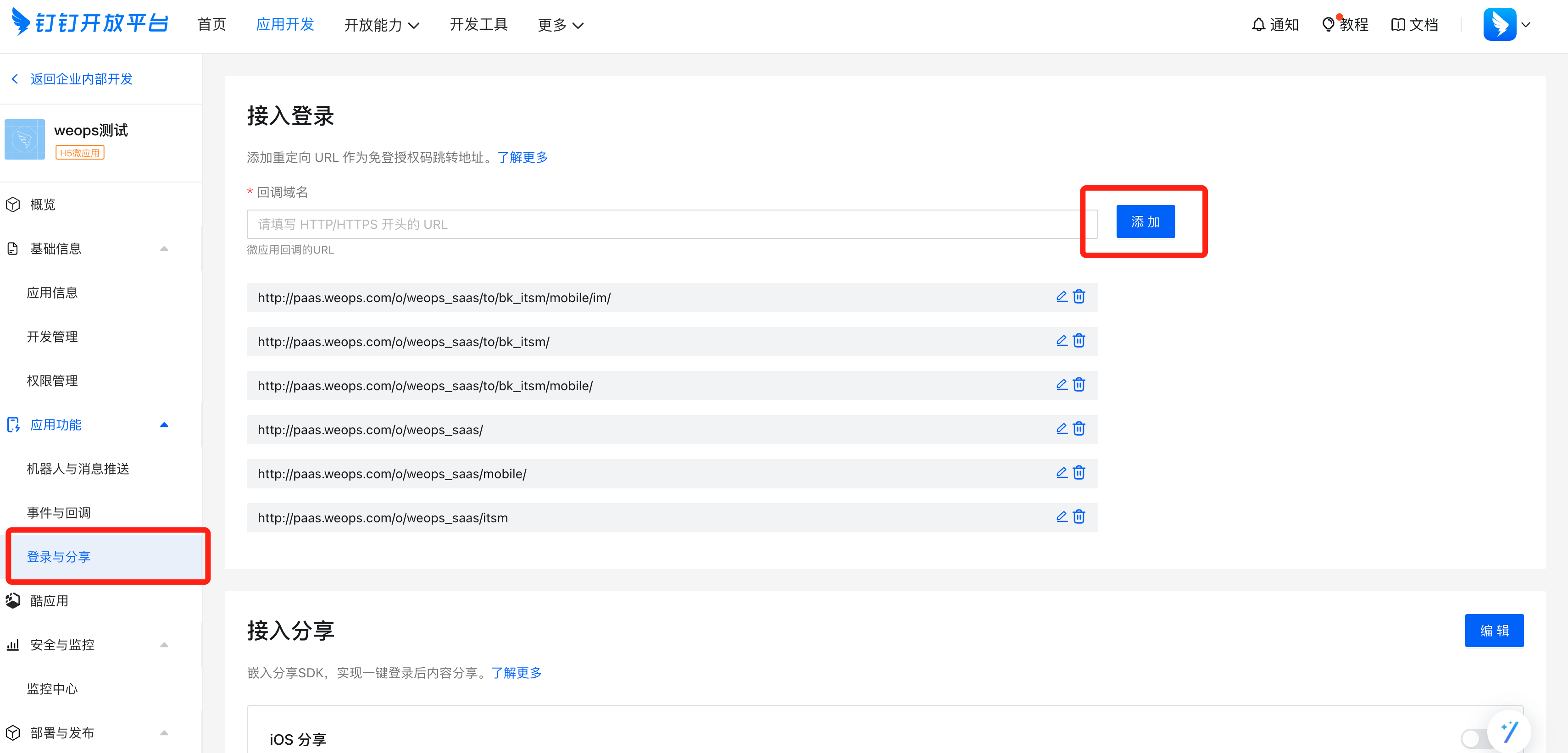
- 权限开通
权限开通列表,搜索栏查询对应的Code
- 接口API权限:snsapi_base ;qyapi_base ;qyapi_get_omp_sso_userinfo ;open_app_api_base
- 个人信息权限:Contact.User.mobile ; Contact.User.Read ; fieldMobile ; qyapi_get_member
- 通讯录权限(用于用户同步):qyapi_get_department_list ;qyapi_get_department_member
插件配置
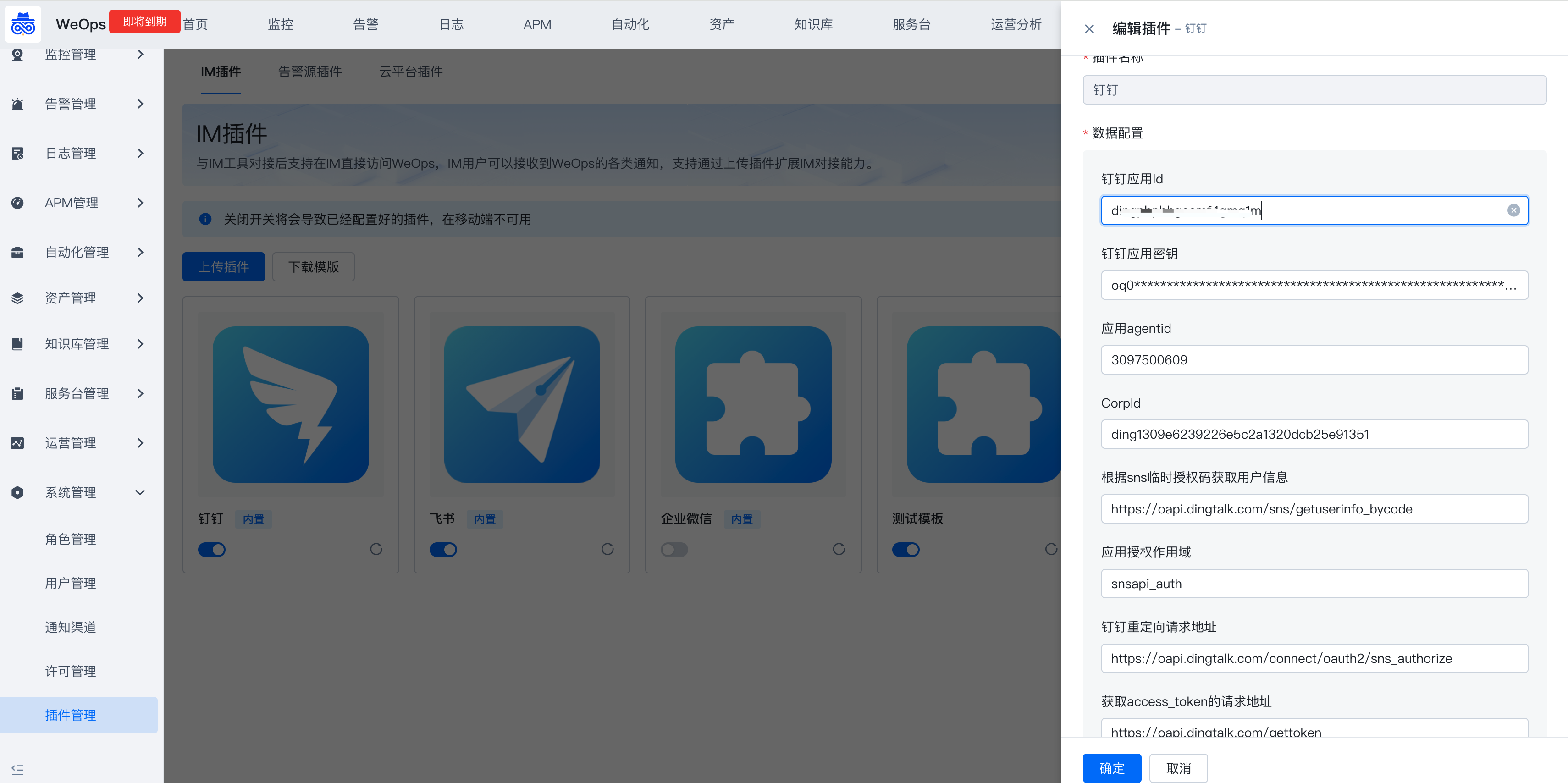
必须修改的部分,已标红,修改的内容参考上面的后台配置,其他配置可按需调整
| Key | Value | Name | Type | Choices |
|---|---|---|---|---|
| APP_KEY | dingsjik8cet6kjudvxc | 钉钉应用Id | – | – |
| APP_SECRET | CxhYsGdE1U6pICqOnl99n5_fh-IsrgdCZUinvYpMOy-LbYgrWxYBZNvON6FXzkzx | 钉钉应用密钥 | encrypt | – |
| AGENT_ID | 1836432979 | 应用agentid | – | – |
| CORP_ID | dinga6476bda235301f2d4c783f7214b6d69 | CorpId | – | – |
| GET_USER_BY_CODE_URL | https://oapi.dingtalk.com/sns/getuserinfo_bycode | 根据sns临时授权码获取用户信息 | – | – |
| SCOPE | snsapi_auth | 应用授权作用域 | – | – |
| INDEX_URL | https://oapi.dingtalk.com/connect/oauth2/sns_authorize | 钉钉重定向请求地址 | – | – |
| TOKEN_URL | https://oapi.dingtalk.com/gettoken | 获取access_token的请求地址 | – | – |
| USERINFO_URL | https://oapi.dingtalk.com/topapi/user/getbyunionid | 获取访问用户身份 | – | – |
| USER_URL | https://oapi.dingtalk.com/topapi/v2/user/get | 获取访问用户详细信息 | – | – |
| MESSAGE_URL | https://oapi.dingtalk.com/topapi/message/corpconversation/asyncsend_v2 | 通知请求接口 | – | – |
| EXTRANET_URI | http://paas.weops.com/o/weops_saas/mobile/ | 移动端外网地址 | – | – |
| PC_EXTRANET_URI | http://paas.weops.com/o/weops_saas/ | pc端外网地址 | – | – |
| USER_AGENT_FIELD | DingTalk | pc端User-Agent识别标识 | – | – |
| USER_MAP_FIELD | telephone:mobile | 用户映射字段(xxx:xxx) | – | – |
| NOTIFY_MAP_FIELD | userid | 通知字段映射 | – | – |
| DIST_PC_MOBILE | 1 | 是否主动区分打开客户端 | switch | – |
| CATEGORY_DOMAIN | default.local | 用户域 | select | API获取 |
| BASE_DEPT_ID | 1 | 根部门ID | input | – |
| ONLY_SYNC_IM | 0 | 是否只同步IM信息(不用补部门及人员) | switch | – |
| IS_OPEN_SYNC | 0 | 自动同步用户 | switch | – |
| SYNC_PERIOD | 1 | 定时同步周期(小时) | select | 1, 3, 6, 12, 24 |
整体功能调试
全部配置完成后,可以进行各个移动端使用验证,或者通知验证。
常用使用场景
场景一 如何进行主机监控告警配置和处理
场景介绍
某公司,现已存在Zabbix、动环、网络监控及阿里云监控系统,存在以下问题:告警信息查看系统过多,信息不同步,告警分析难度大,通知方式单一等问题。使用“WeOps-监控告警”可以对多类对象进行监控,提供多种方式的告警,全面展示该告警的相关信息,以便进行处理。
场景实现
Step1:监控采集-安装Agent
如下图所示,选择“操作系统-主机”,进入主机Agent安装界面,点击“安装Agent”

在安装的界面,选择该主机归属的业务、云区域以及接入点。随后在安装信息输入该纳管主机的IP地址,登录账号和密码等核心配置。输入完成之后点击[安装]按钮即可将agent部署至该主机。
Step2:监控策略配置
进入WeOps的管理中心的监控管理,找到监控策略。

- 如下图所示,进入新建监控模板配置界面
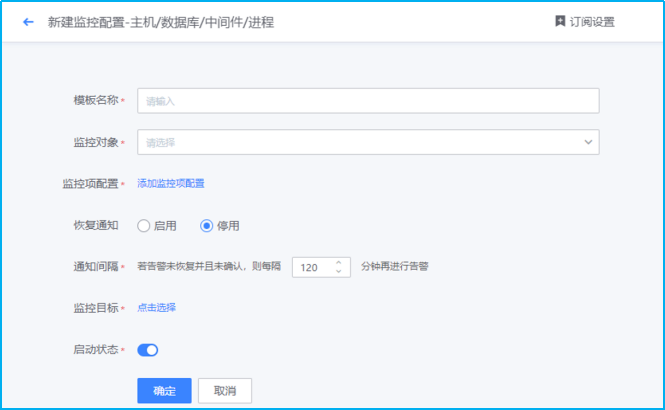
- 如下图所示,填写监控“模板名称”、“监控对象”。

- 如下图所示,点击蓝色字体【添加监控项配置】即会弹出对应界面。主机监控项分为“指标”和“事件”两类。指标主要为常见的CPU、内存、磁盘、进程等监控指标。而事件则是指Agent心跳、Ping可达、主机重启等。
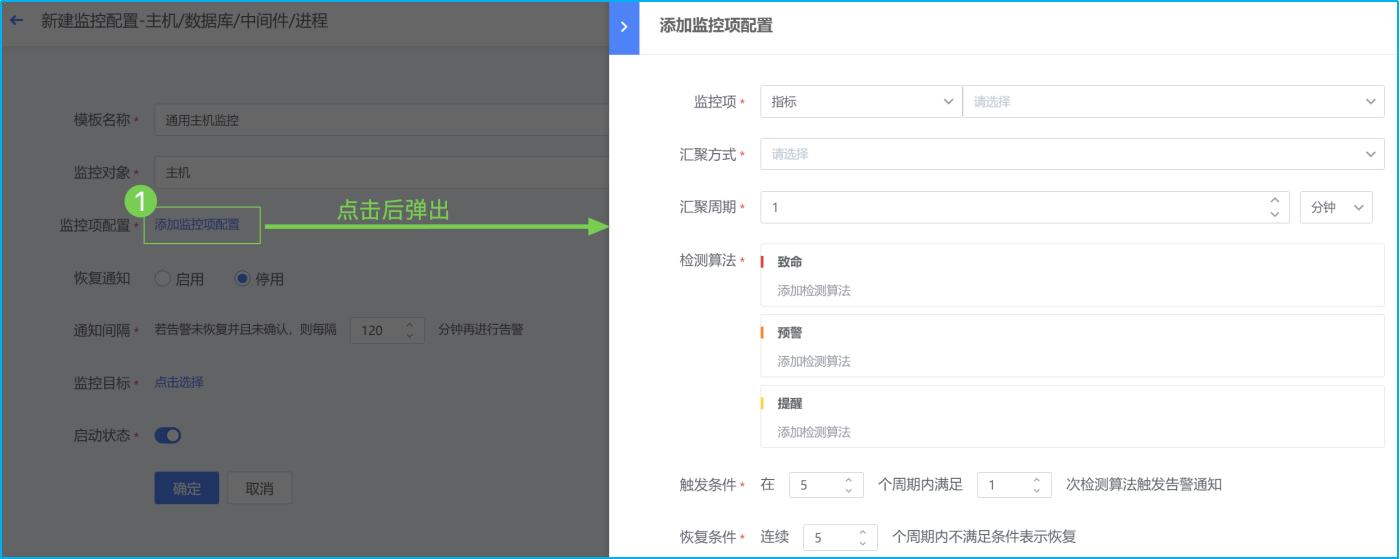
- 若下图所示,选择监控项为指标类,搜索监控项

- 选择汇聚方式为平均数,即AVG方式。SUM代表总数,AVG代表平均数,MAX代表最大值,MIN代表最小值,COUNT代表计数/总数。
- 选择汇聚周期,汇聚周期即采集数据的周期。(注:汇聚1min即是服务端每分钟向Agent采集1次数据。若是汇聚周期设置为5min则表示服务端向Agent每5分钟采集1次数据,此刻的Agent已经采集到了5次数据。之后,并根据汇聚方式将这5个数据进行计算(AVG/MAX/MIN等),计算得出的数值再于检测算法设置的阈值进行比较。)
- 如下图所示,点击蓝色字体添加检测算法,进行不同监控等级阈值的设置。以下示例采用检测静态阈值触发告警。此外还有高级的阈值检测方式可选择:各种同比/环比策略。
- 如下图所示,进行“触发条件”、“恢复条件”、“无数据告警”、“监控纬度”以及“监控条件”的设置。
- 如下图所示,对监控项进行一一添加后再进行其他配置即可完成通用监控项模板。
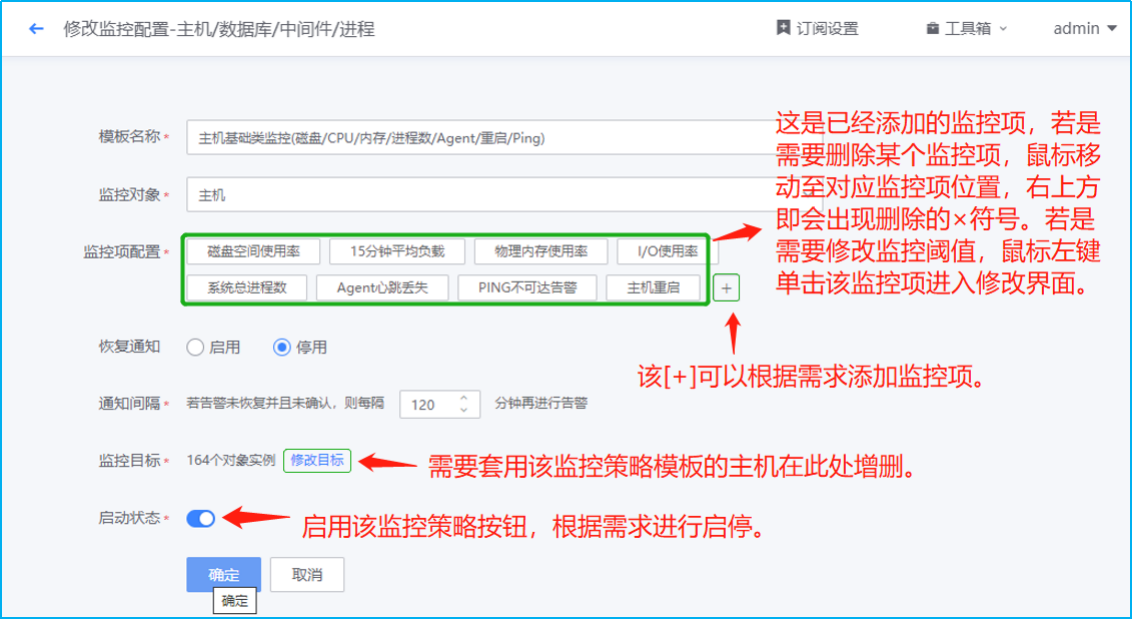
Step3:告警人员通知配置
- 如下图,进入通知配置界面,选择对应的用户,点击“配置”按钮,可以进行通知方式的配置,可选“邮件、短信、企业微信、电话”等形式
Step4:接收告警信息(以邮件为例)
路径:个人邮箱
- 发生告警时,邮箱接受到告警信息,如下图,包括告警的内容、对象、时间、业务等信息,便于快速感知告警。

Step5:告警详情查看
路径:事件-告警-活动告警
- 如下图,前往告警的活动告警中,可以找到该条关于CPU内存的告警信息。
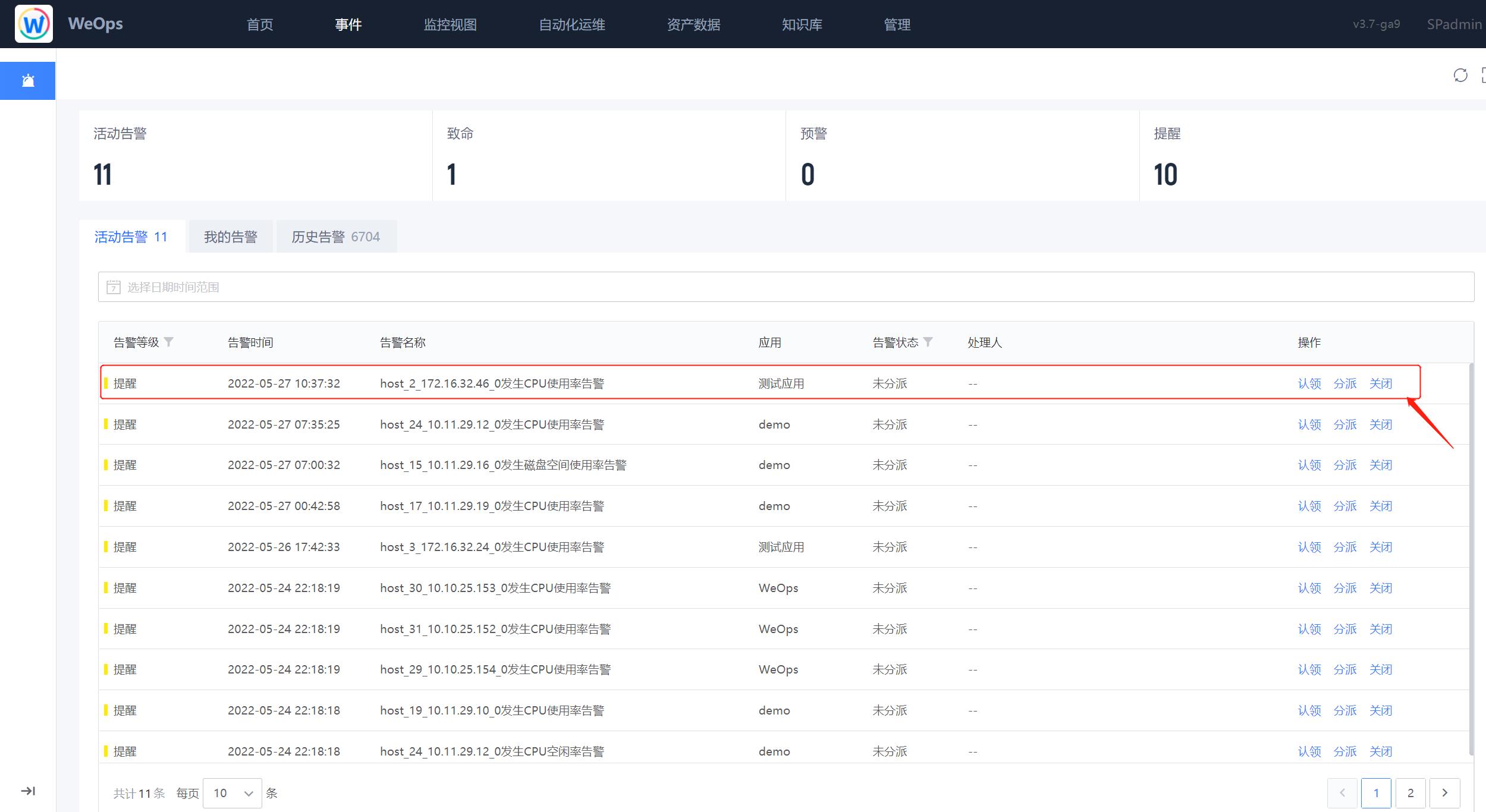
- 如下图,点击告警,可以进入告警的详情页,进行告警信息的查看,通过基础信息、指标视图等信息,可以断定告警发生的对象、时间、影响等,比如该条告警,是蓝鲸应用下一台主机的cpu单核使用率过高,设定的告警值为90%,目前该主机的CPU单核使用率已经达到了94%。
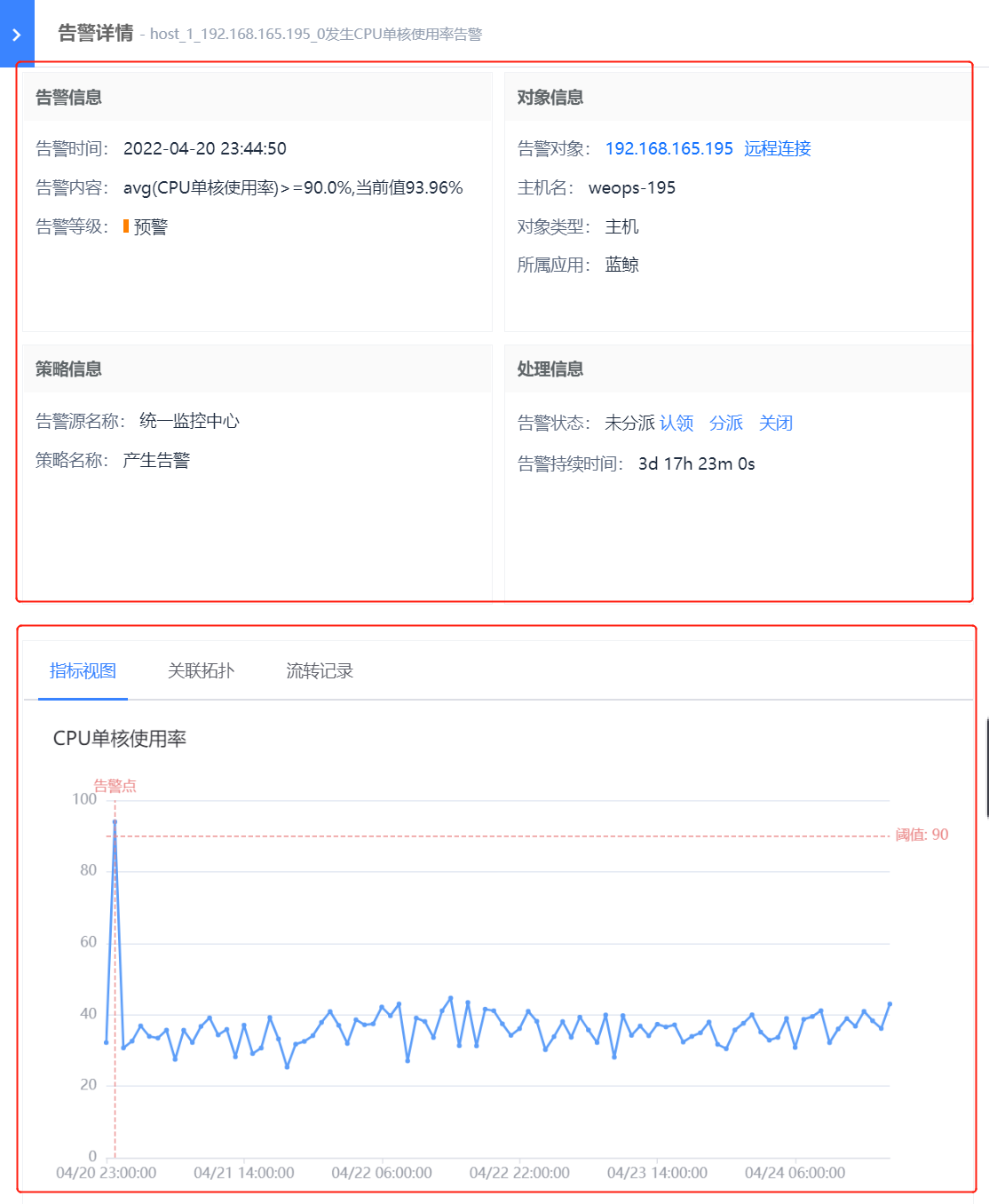
- 可以通过指标视图和关联拓扑,可以分析告警的影响范围和产生的原因。

Step6:告警分派/认领
路径:事件-告警-活动告警
- 对于告警的处理,可以进行认领和分派,点击认领按钮,可以对告警进行自行认领,认领的告警项会进入到“我的告警”,状态改变为“手动处理中”待处理完成后,可关闭告警; 点击分派按钮,可以对告警进行指定用户的分派。
- 这里我们选择自行认领该告警,告警进行手动处理阶段,在故障处理完成后可以自动/手动关闭。
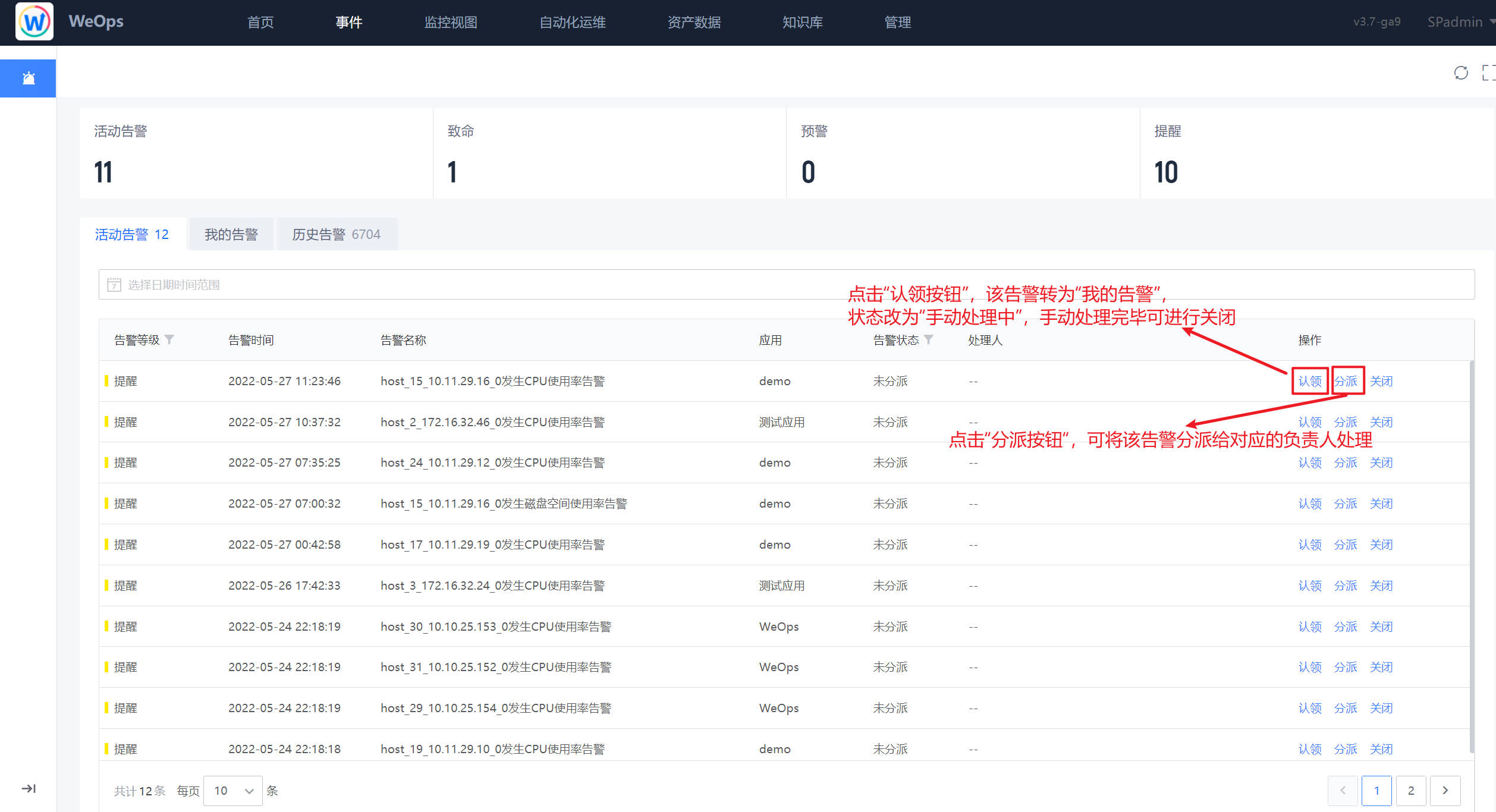
Step7:故障处理
路径:运维工具-脚本工具-查询消耗系统CPU最多的进程
- 针对上述告警关于CPU单核使用率过高的故障,需要进行故障处理,需要查看该台主机的CPU使用情况,可利用“运维工具-脚本工具-查询消耗系统CPU最多的进程”进行。
- 点击进入脚本工具的执行页面,选择有故障的主机,填写展示top20的进程
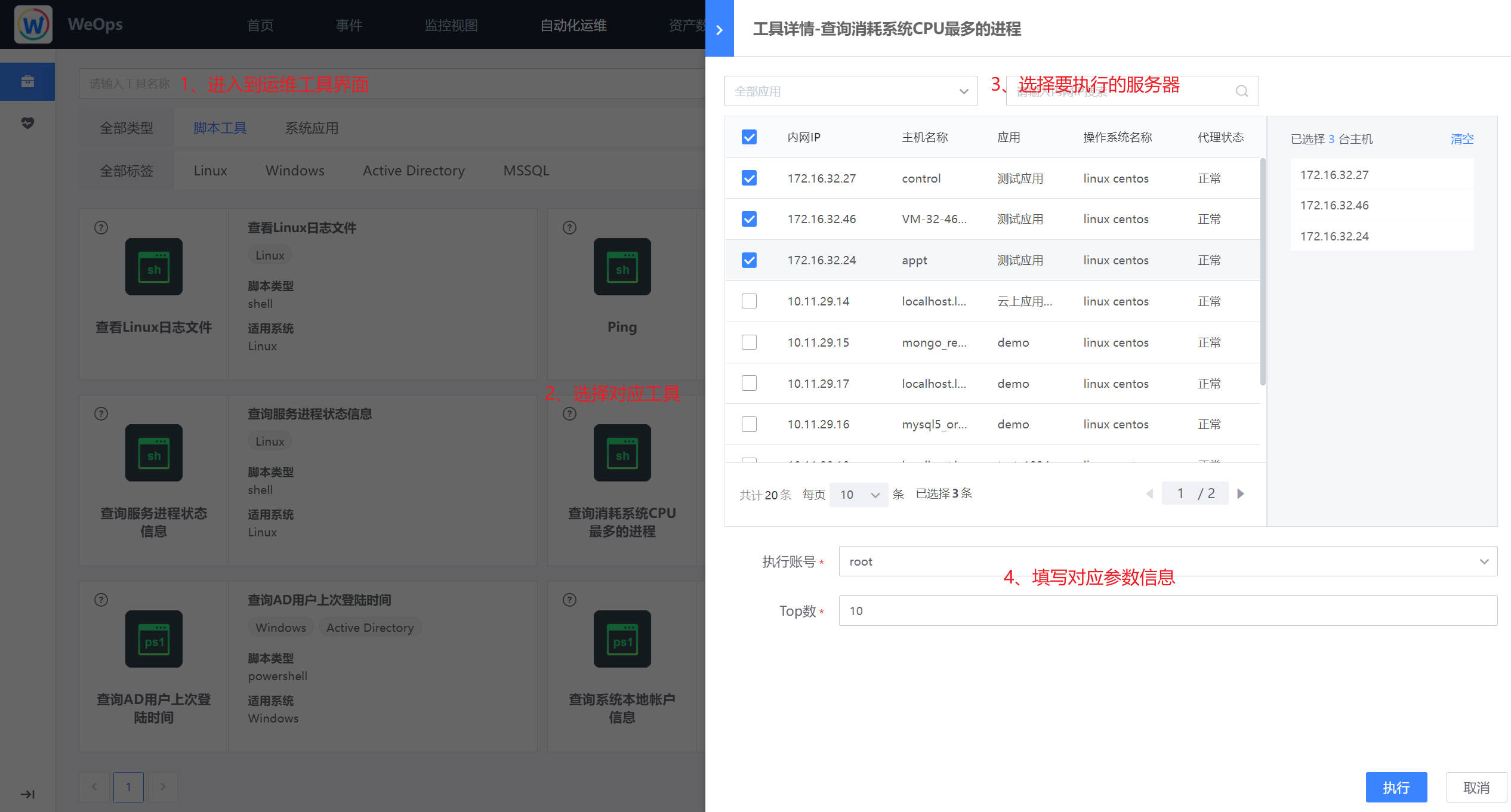
- 执行完成后,可以在结果界面,查看消耗cpu最多的top20的进行,可进行判断进行处理。
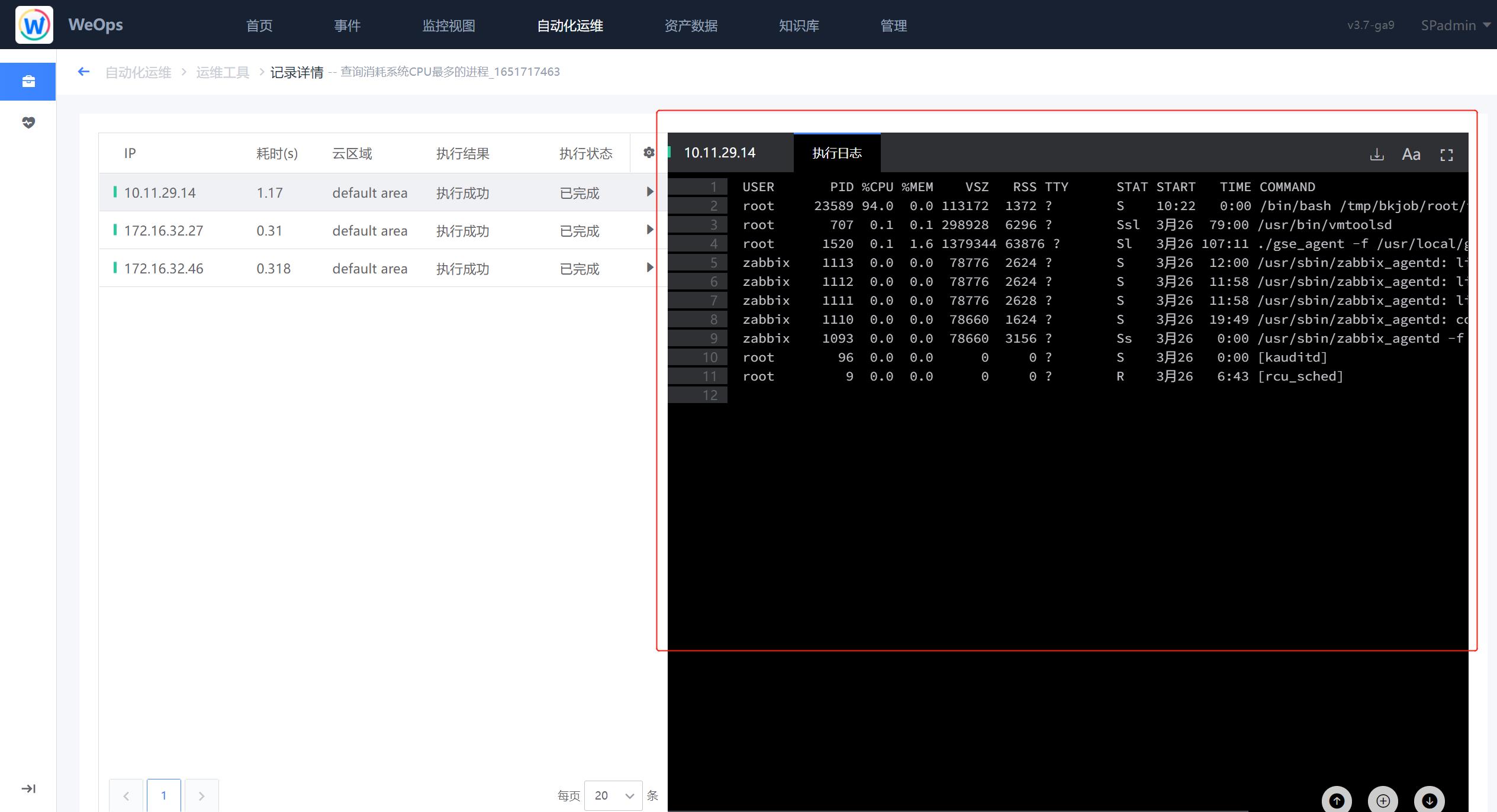
Step8:告警关闭
故障消除后,该条告警将会自动关闭,也可进行手动关闭。
场景二 如何进行应用故障的处理
场景介绍
某公司IT部门内部明文规定,作为业务管理员在收到相关业务的报障后,需要尽快进行问题的排查和处理,保证各应用的正常运行。
场景实现
路径:WeOps-应用
Step1:接收报障
- 应用管理员接收到同事的报障:今天上午9点左右,蓝鲸环境访问速度过慢,需要紧急修复。
Step2:查看网站视图
- 登录WeOps,进入应用界面,切换至“蓝鲸”应用。在页面上方的网站监测部分,可以看出在8::0-10:00直接该网站的发生了告警事件,点击可查看该段时间的网站的使用率和响应时长视图,通过视图可以看出,该时间段响应时长过长。
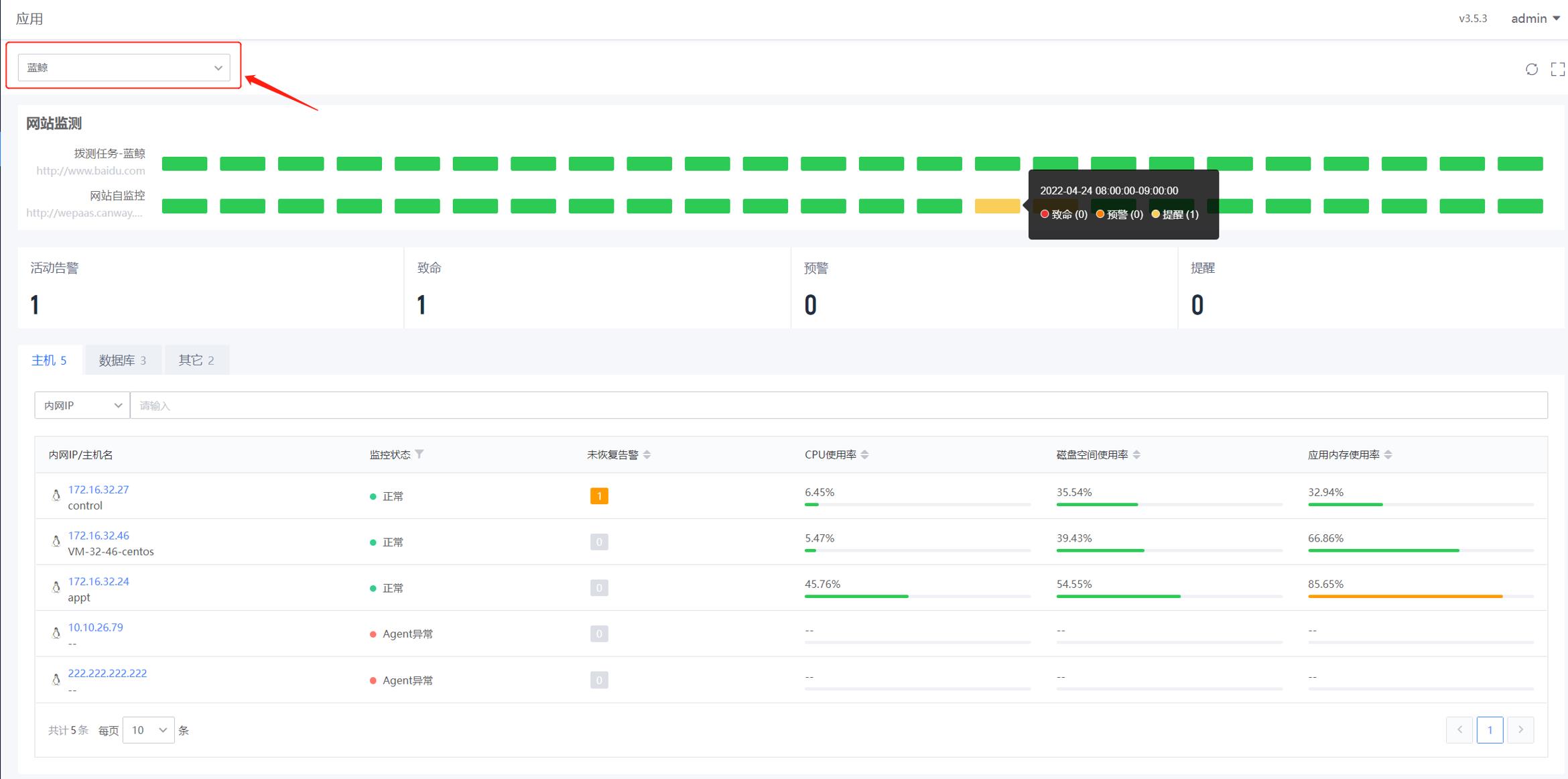

Step3:分析故障产生原因
- 协助分析1:在应用界面的中部展示与该应用所有相关的告警信息,可点击查看告警列表,查询与该故障前后发生的告警协助分析。

- 协助分析2:在应用界面的下方展示了该应用下的主机、数据库、其他资源的基本信息,CPU磁盘使用率、磁盘空间使用率、应用内存使用率等信息,可以帮助排查故障出现的原因。
Step4:进行故障处理
根据上述步骤,已经排查出故障出现的原因,同“场景一”可以使用运维工具进行故障的处理。
场景三 如何进行资源的日常检查
场景介绍
某公司IT部门内部明文规定,为了保证业务系统的正常运行,运维每天早上上班后需要对负责的IT运维对象进行整体情况的熟悉,对于出现的问题可以提前预判,避免故障发生。
场景实现
Step1:查看告警情况
路径:WeOps-首页
- 登录WeOps,进入首页,在首页中可以查看目前出现暂未处理的告警列表,也可以查看自己关注的应用的告警汇总数量,从整体上感知系统的整体状态。
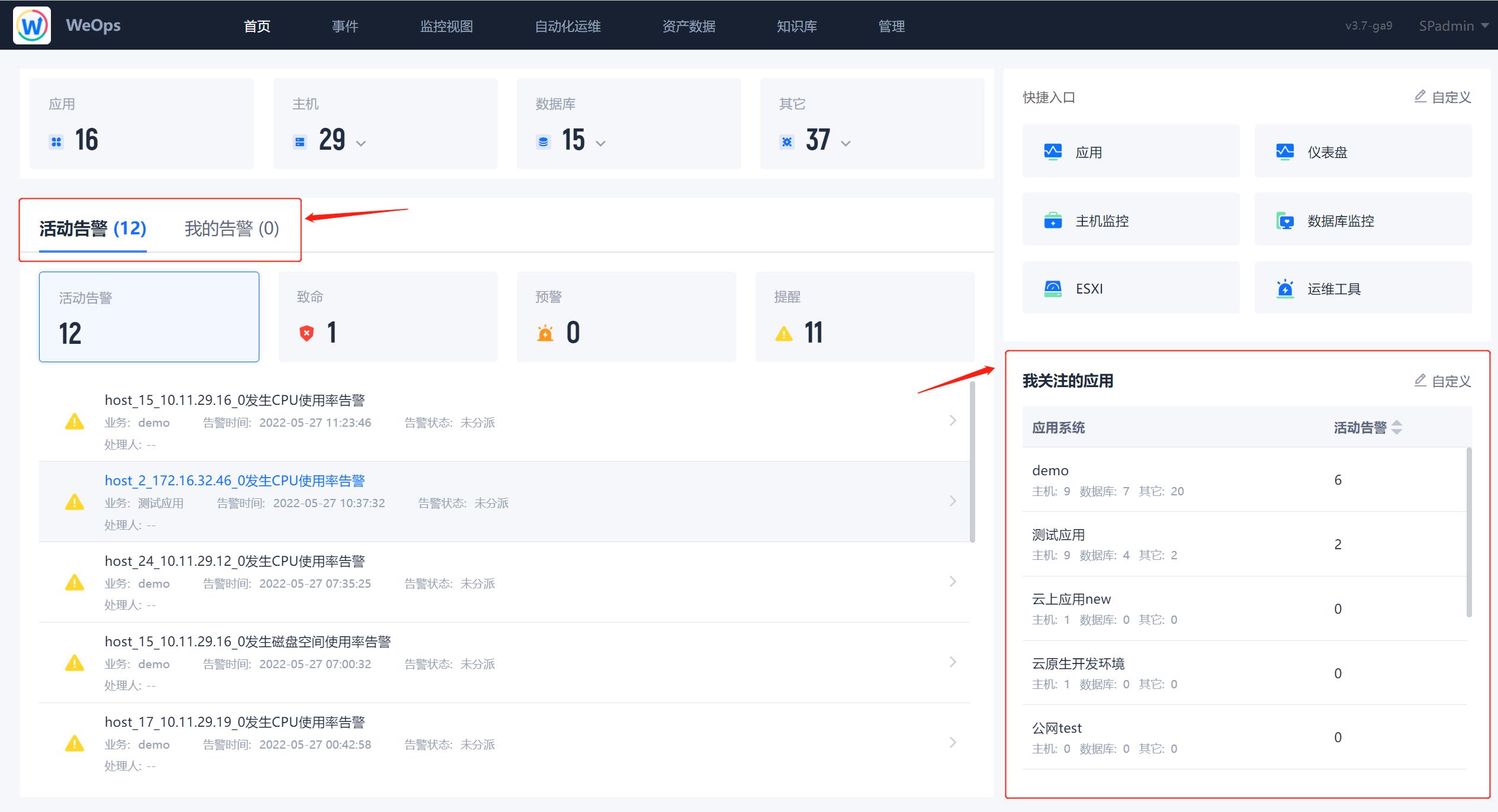
Step2:查看监控状态
路径:监控视图-应用/基础监控/网站监测
- 进入“应用”界面,从该应用的网站监测、告警情况、实例状态等方面,进行该应用的检查。

- 进入“基础监控”界面,将IT对象分为主机、数据库、中间件等分类进行不同实例的告警状态、监控状态的检查。
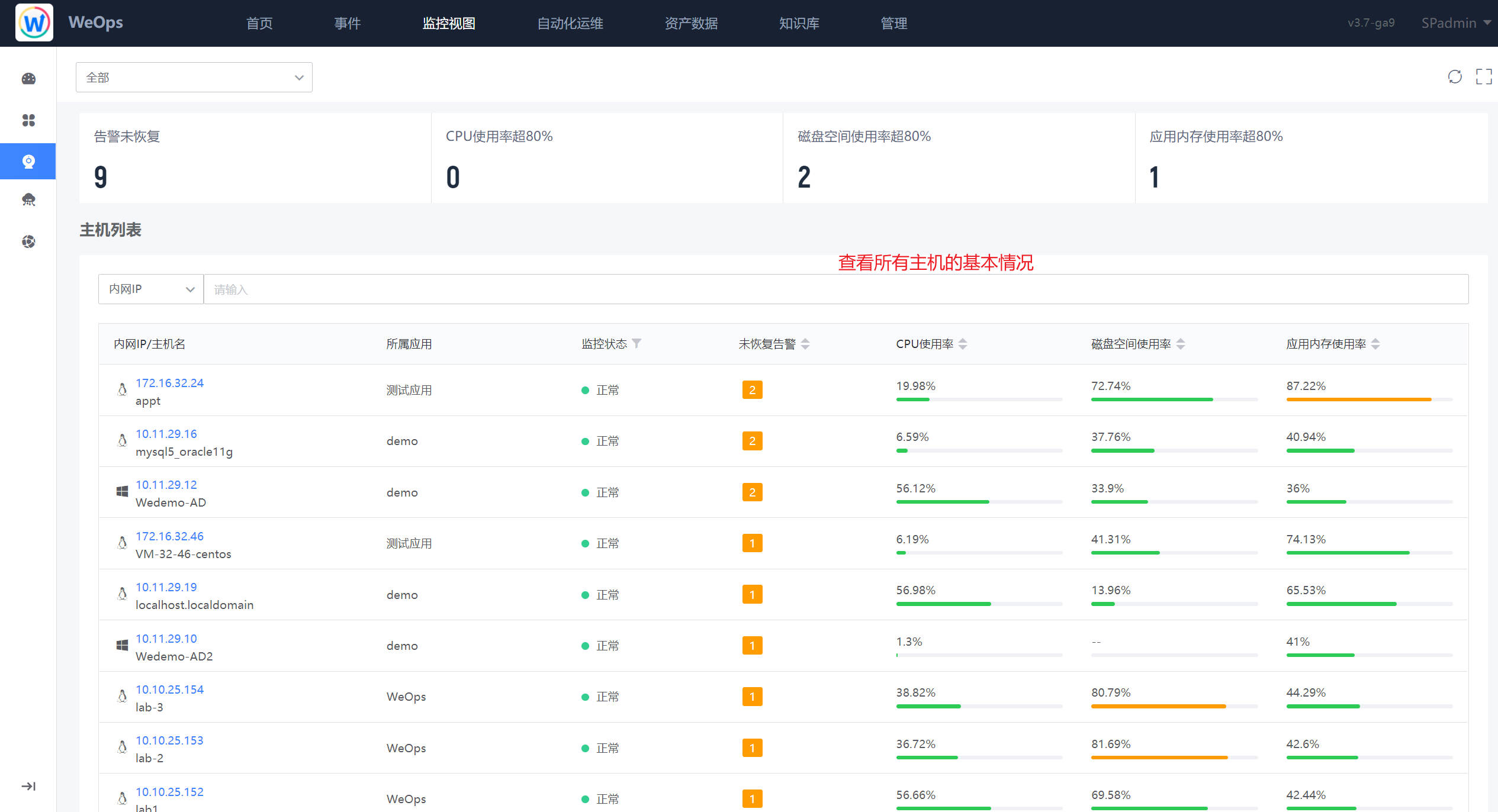
- 进入“网站监测”界面,对已经加入拨测的网站进行可用率、响应时间等方面的整体检查。

Step3:进行健康扫描
路径:健康扫描-扫描列表
- 如下图,在健康扫描中,新建扫描任务,填写基础信息、选择内置的扫描包和对应的资料。
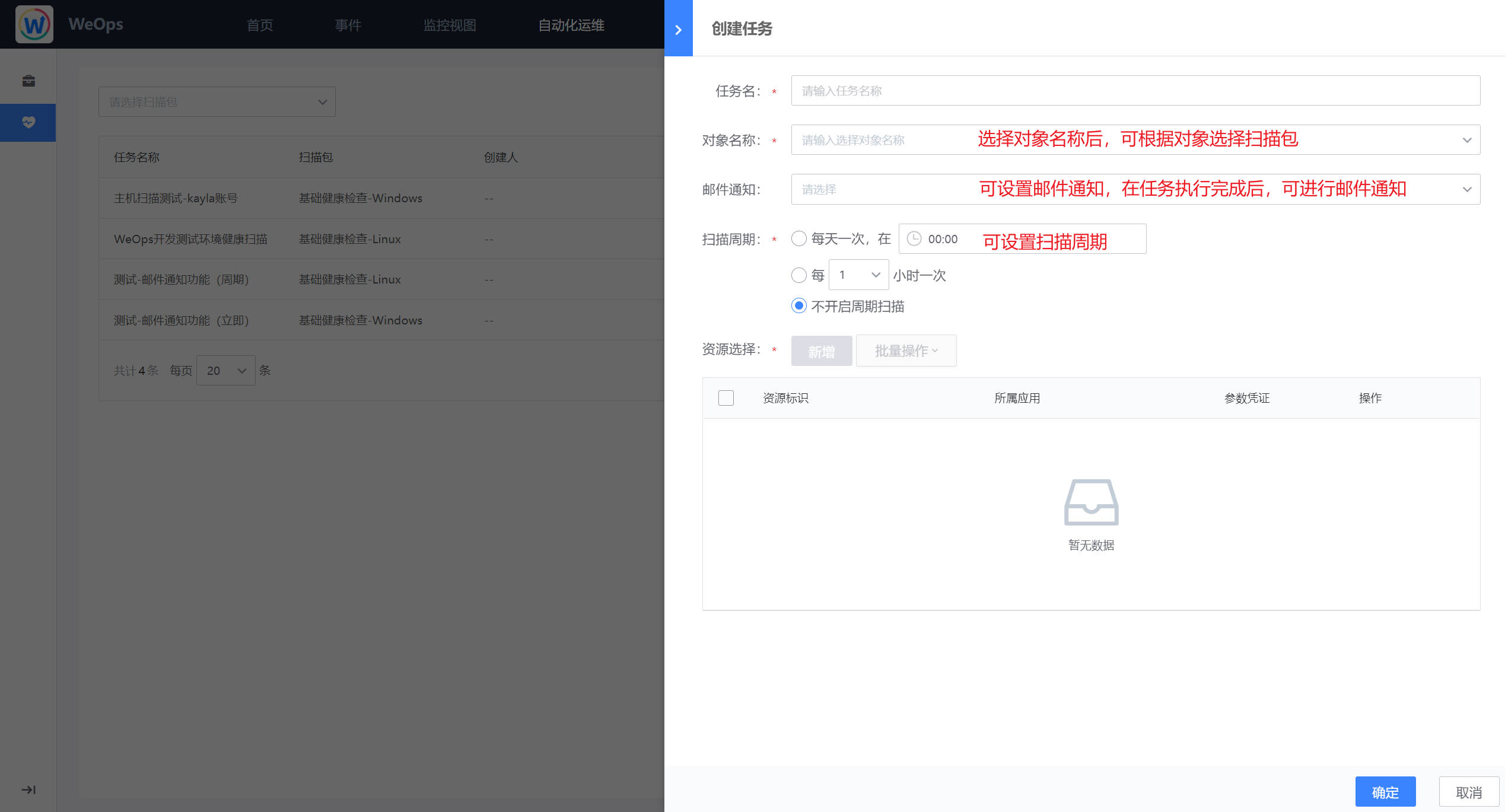
- 任务创建完成后,可执行“立即扫描”,扫描结束后如下图,在该任务下点击“详情按钮”,可以查看各个实例的扫描情况

- 点击“实例列表”后面的“详情”,可进入到该实例的详情业务,该实例的详情页面展示了实例的健康详情,具体见下图,对于警告/危险的指标予以关注,并进行处理,避免发生故障,影响系统的正常运行。
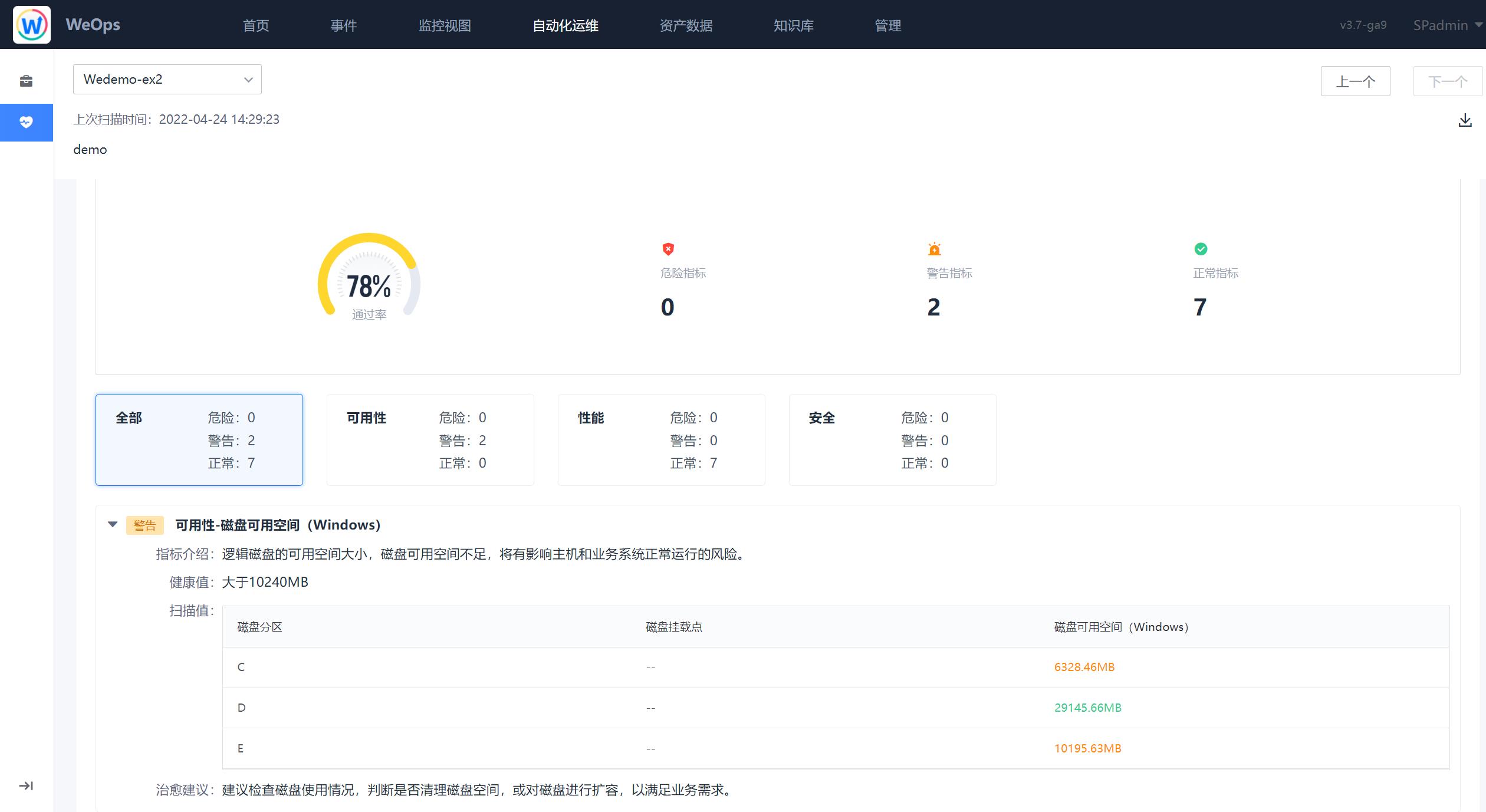
场景四 如何进行自动化运维(以Windows月度补丁安装为例)
场景介绍
某公司的安全部门要求,Windows服务器必须每个月按照要求进行对应的补丁安装,补丁来源于微软每月发布的月度补丁。
场景实现
Step1:下载/准备补丁文件
前往微软官网,下载对应月度的补丁。
Step2:创建补丁安装任务
路径:自动化运维-补丁安装
点击WeOps自动化运维中的“补丁安装”进行补丁安装操作,点击“创建任务”进行补丁任务的新建。
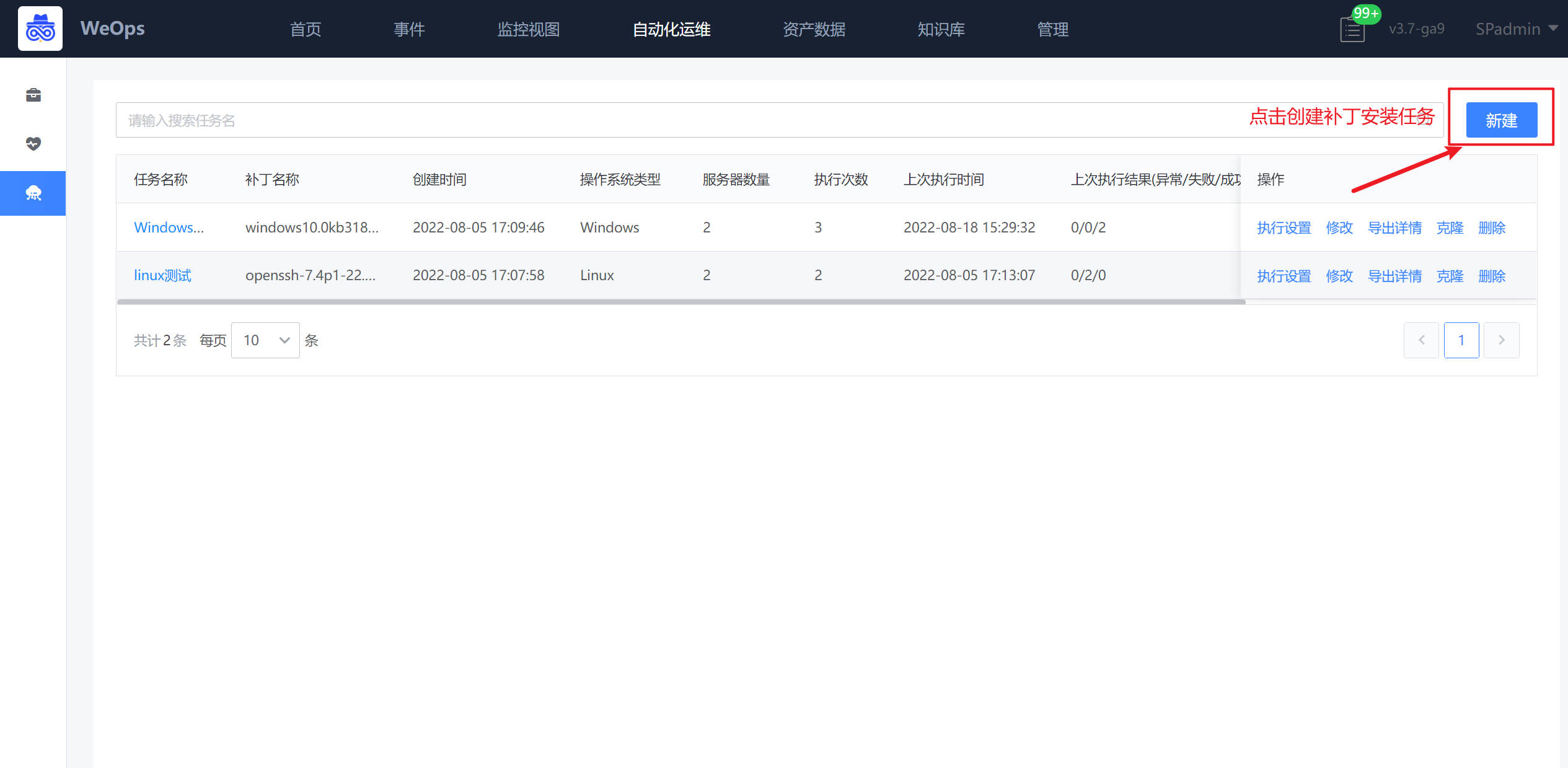
在任务新建界面,可选择Windows/linux两类操作系统,服务器支持跨业务多选,补丁文件支持本地上传/30天内上传的补丁文件复用,支持选择邮件通知人。
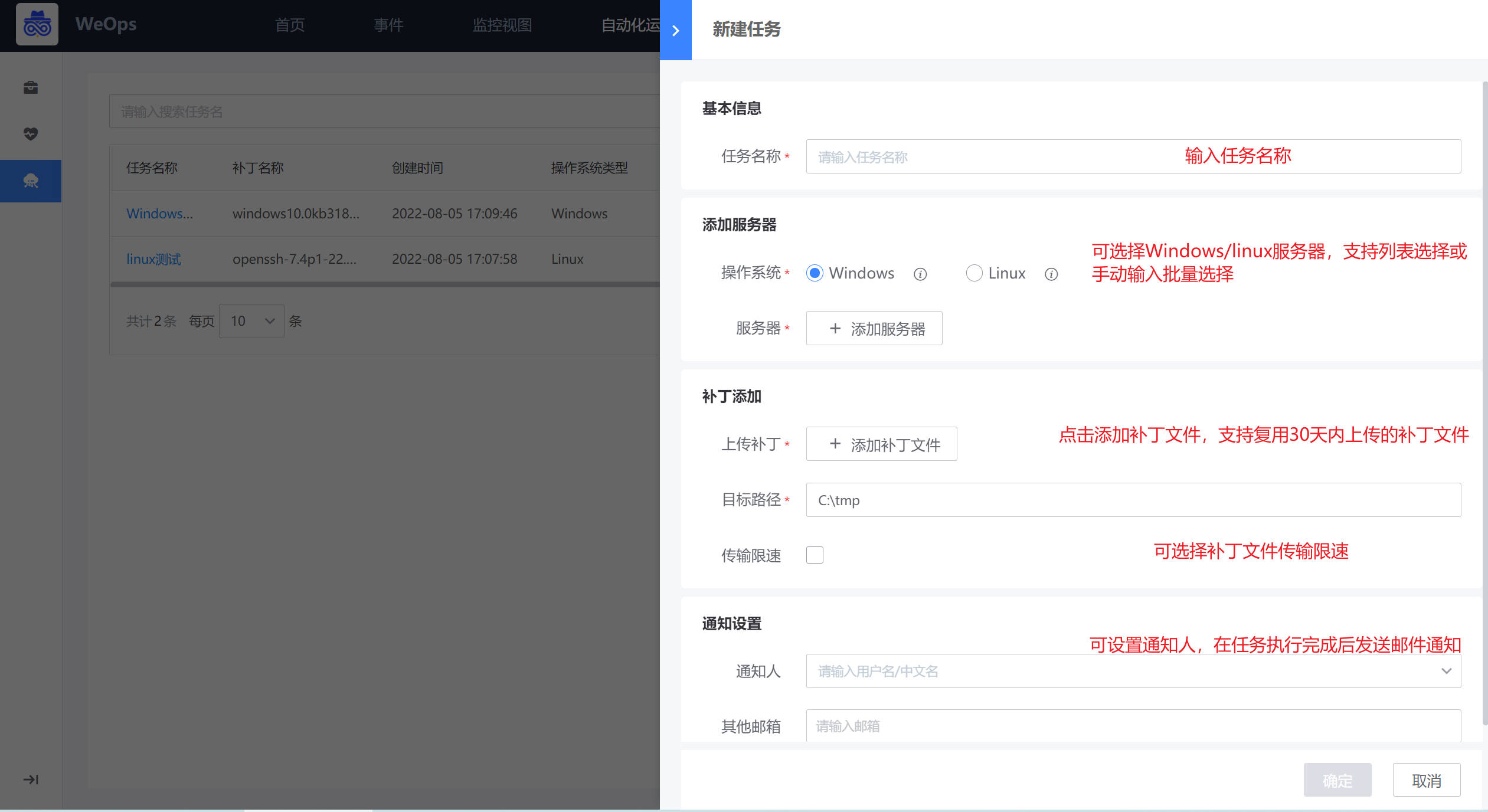
Step3:执行补丁安装
任务创建完成后,可以点击进行“立即执行”/“定时执行”
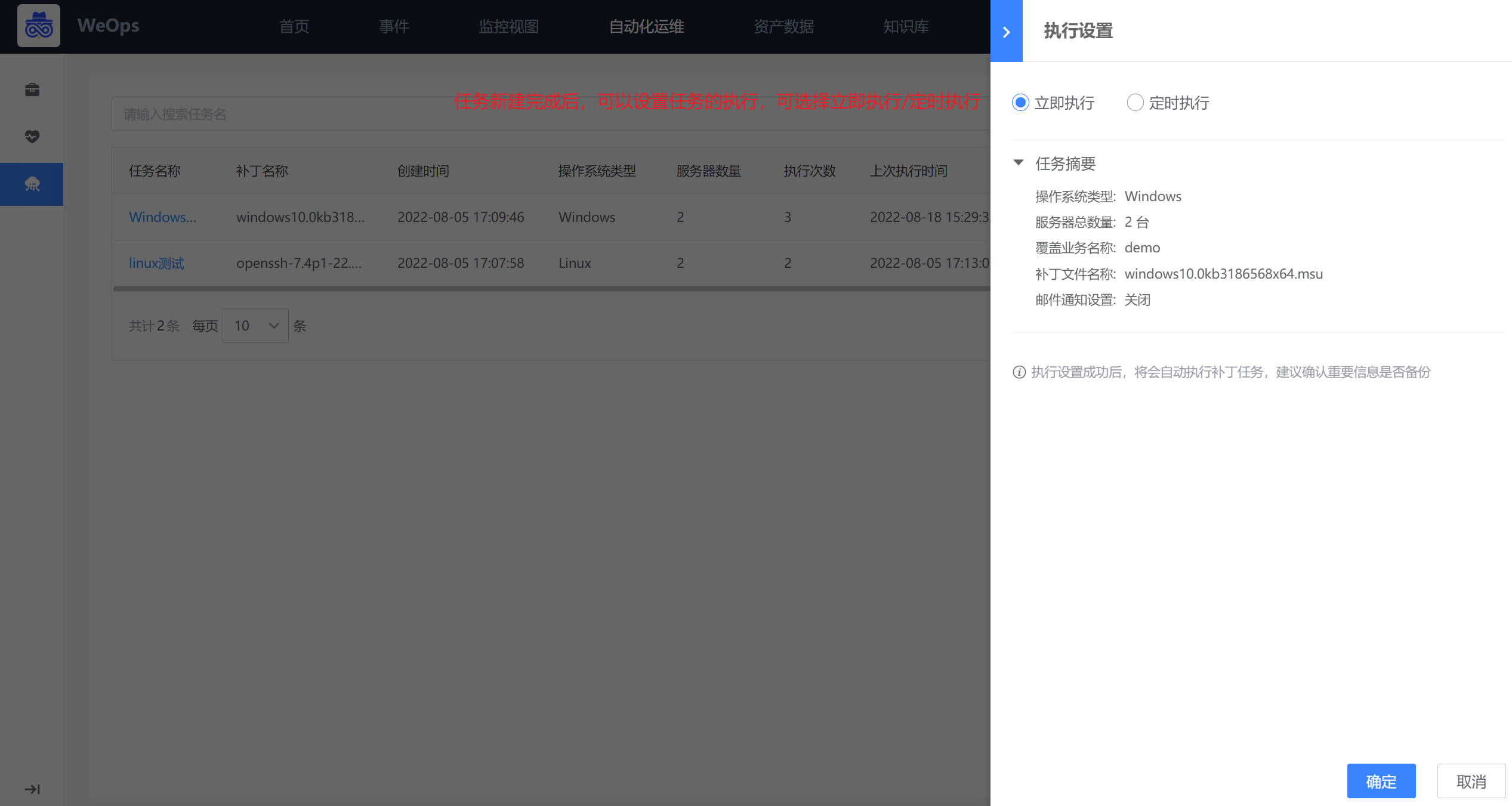
执行完成后,可以查看执行结果
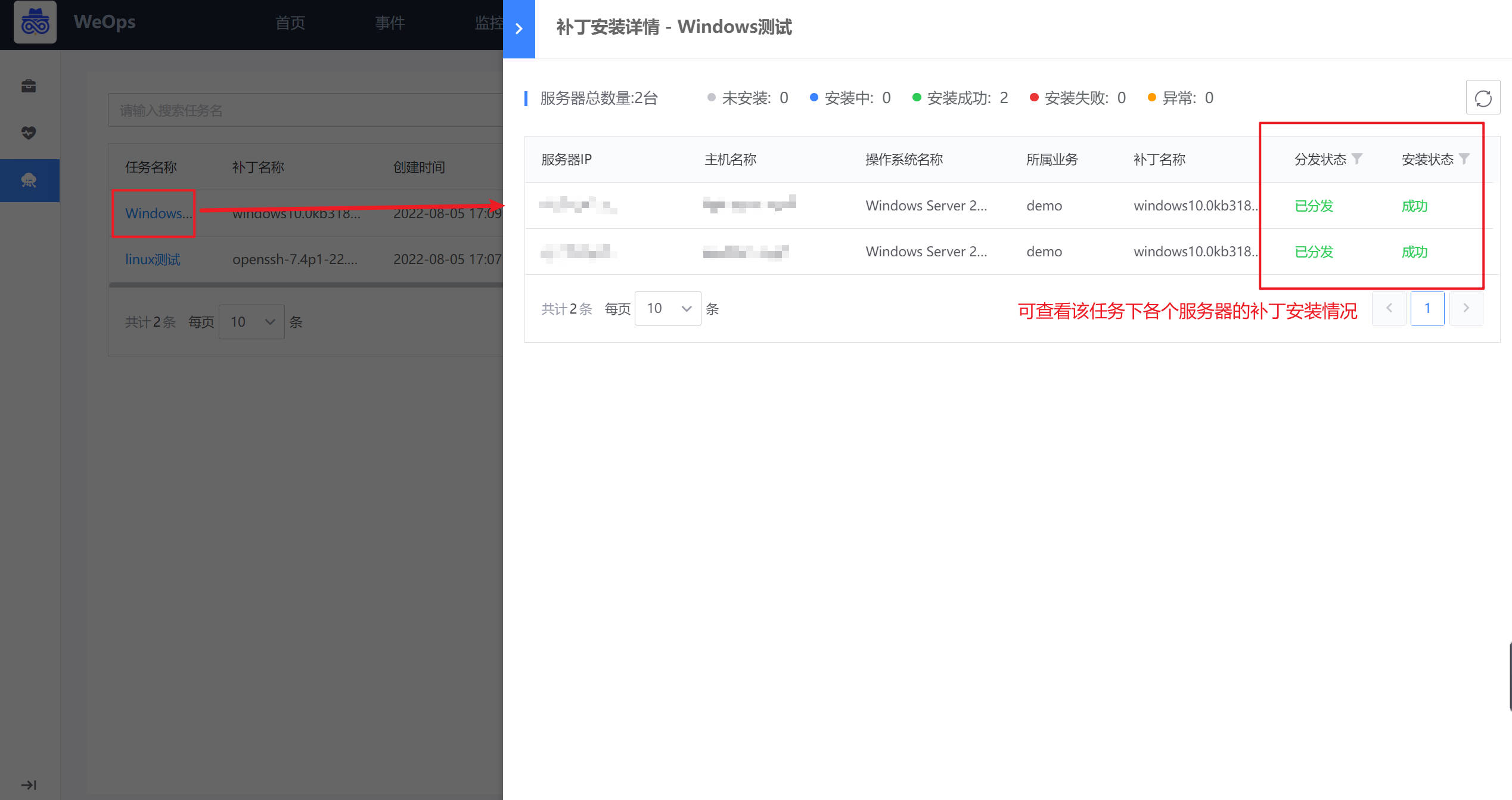
Step4:服务器重启
路径:运维工具-系统应用-作业平台
补丁安装任务执行完成后,针对需要重启的Windows服务器,可以通过作业平台进行批量服务器重启。
服务器重启完成后,补丁安装完毕。
场景五 如何进行IT资产的管理和维护
场景介绍
某公司原来对于IT资产信息的管理仍使用传统的表格进行人工手动维护,会造成资产记录完整性和及时性无法保证,资产盘点工作繁琐的问题。使用“WeOps-资源记录”模块可以实现资产信息管理自动化,拓扑展示可视化,资产盘点工作高效。
场景实现
Step1:资源纳管
对于应用、主机、数据库、中间件的纳管,可参见“1、资源纳管”的部分
Step2:应用资源信息查看
路径:管理-管理中心-应用列表
- 如下图,应用列表展示了所有的应用信息,点击“查看”按钮,可以进行该应用的详细信息查看,点击“查看拓扑”可进入到该应用的拓扑界面,进行拓扑的查看。
- 在应用列表页点击“查看”后,可进入该应用的详情页面,可以查看该应用的拓扑结构、变更记录、主机列表、节点信息。

- 在应用列表页点击“查看拓扑”后,可进入该应用的拓扑页面,可以查看该应用的拓扑图、以及拓扑图中的各个节点/实例的信息,具体详见下图

Step3:资源信息查看(以主机为例)
路径:资产数据-资源记录-主机
- 如下图,在资源列表中,可以查看所有主机的列表和信息,关联的数据库实例,可以进行主机资源的导出。
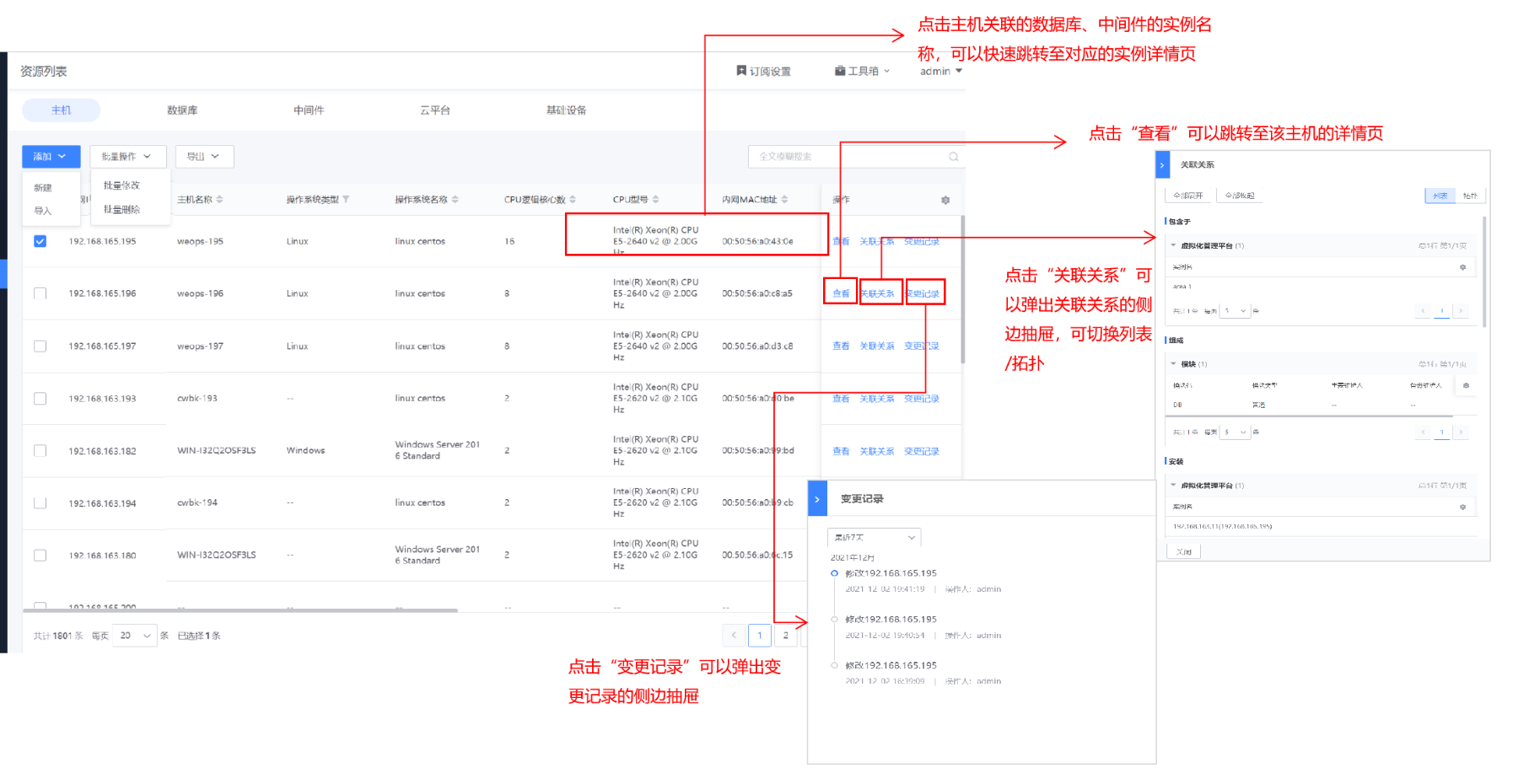
- 在资源列表中,点击“查看”按钮,跳转到该主机的详情页,详情页展示了主机的详细信息,以列表和拓扑的形式展示了主机的关联信息,以时间轴的形式展示了主机的变更记录。可以通过上述的形式获取主机的相关信息。

场景六 如何利用工单进行AD账号的自动创建
场景介绍
某公司之前AD账号创建需要运维人员接受到需求后,前往AD里面一个个手动创建账号,并把对应的账号密码信息反馈给申请人,可以使用WeOps的IT服务台进行AD账号创建的工单提交并且实行自动化创建。
场景实现
Step1:前提条件介绍
1、WeOps和AD的前期准备
- WeOps的APPT机器能通AD服务器的636端口,并且装了AD的根证书
- WeOps中已经纳管所需要的AD服务器,如下图,在WeOps-资产数据-资产记录-AD中,对所需要的AD服务器进行纳管
- AD服务器的凭据信息已经录入WeOps-凭据管理中,并且关联该AD服务器,并授权给对应需要审核的运维管理员
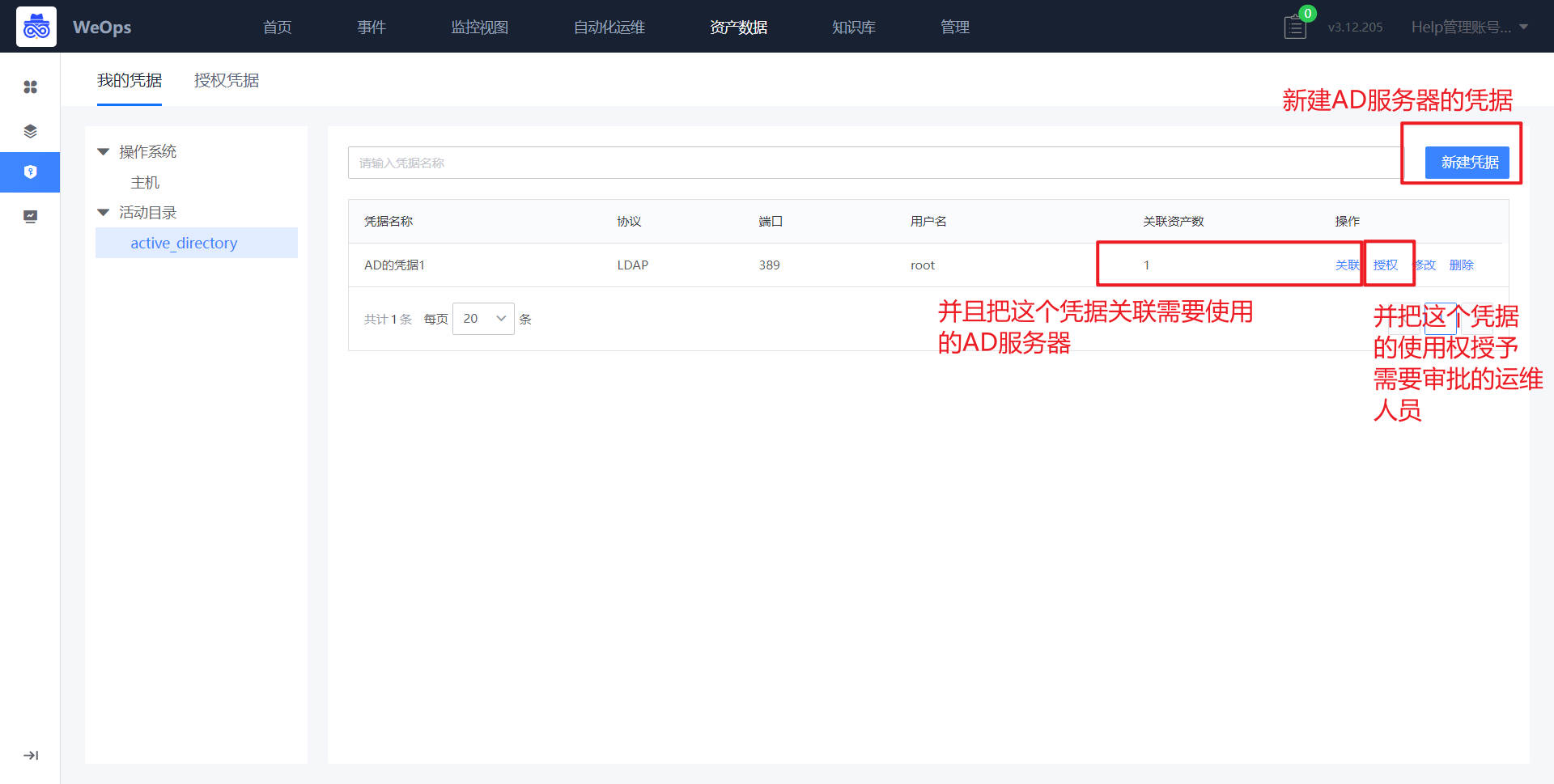
2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程
- 在WeOps后台管理-流程API配置中导入需要的API接口
- 在自动化流程中导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置,具体操作步骤可查看视频查看AD账号创建自动化流程的配置。
提单节点:用内置的不用调整
审批节点:AD服务器和AD组这两个字段需要重新选择接口
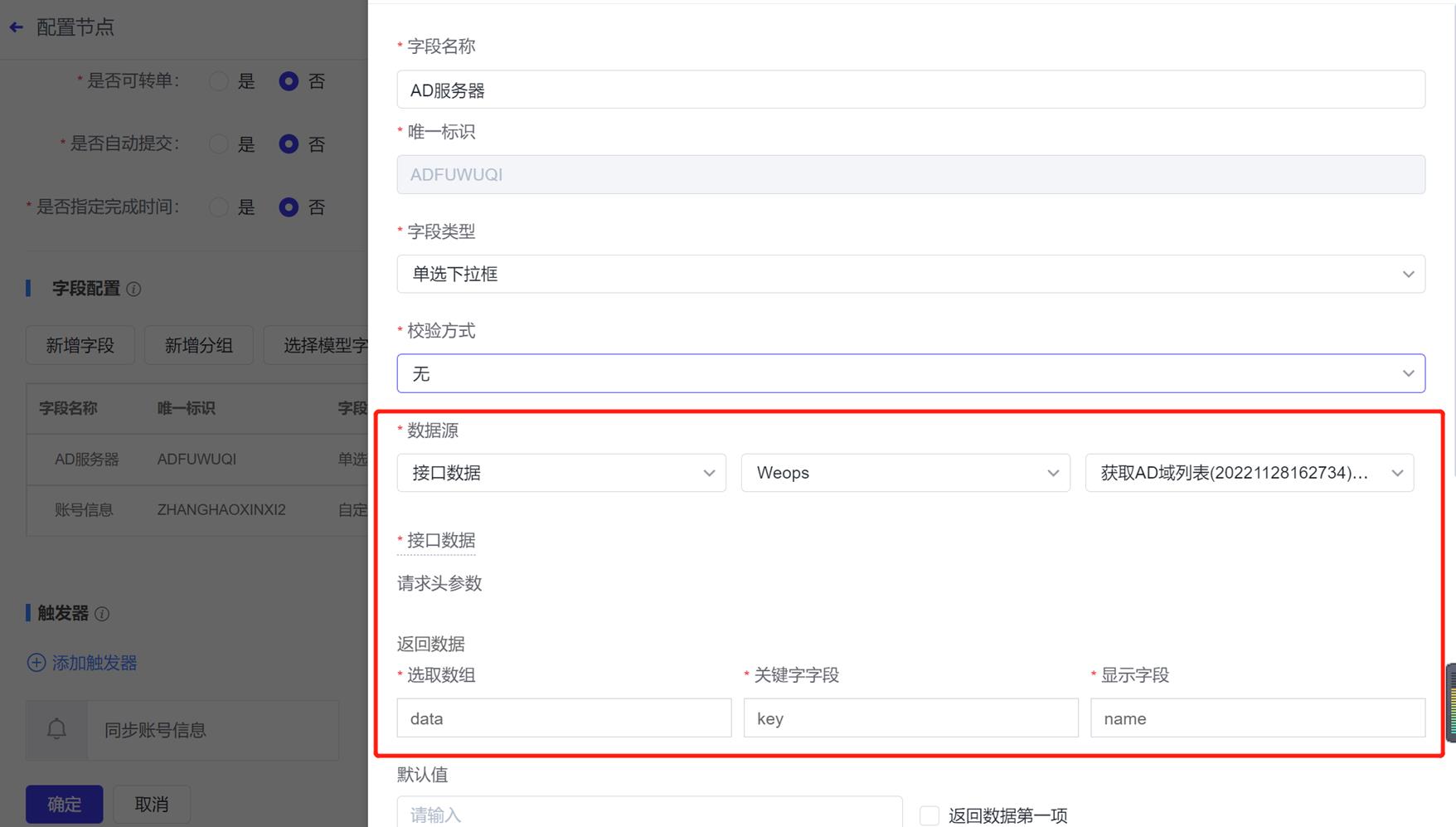
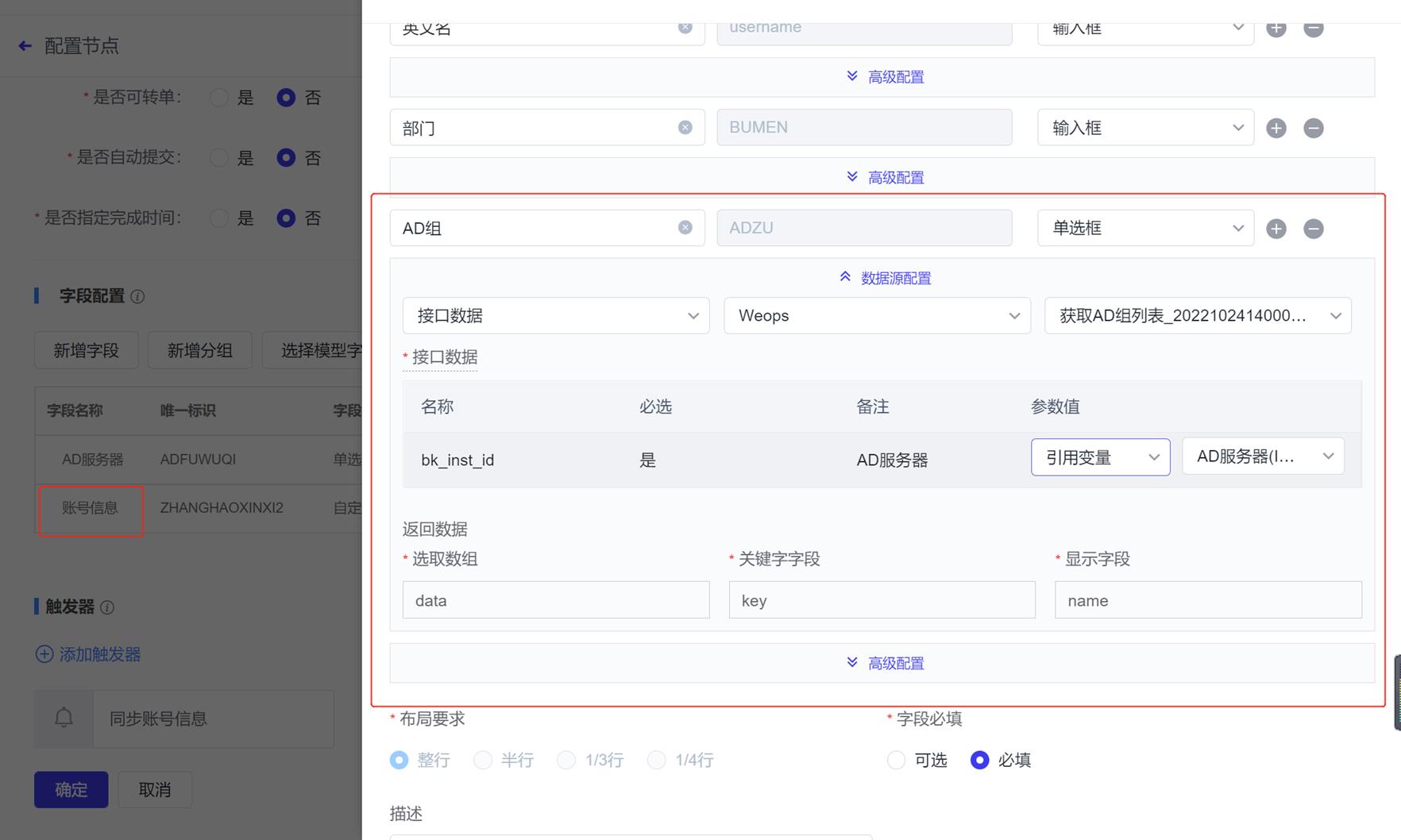
获取API详情节点:选择对应接口,下面的参数会自动勾选的
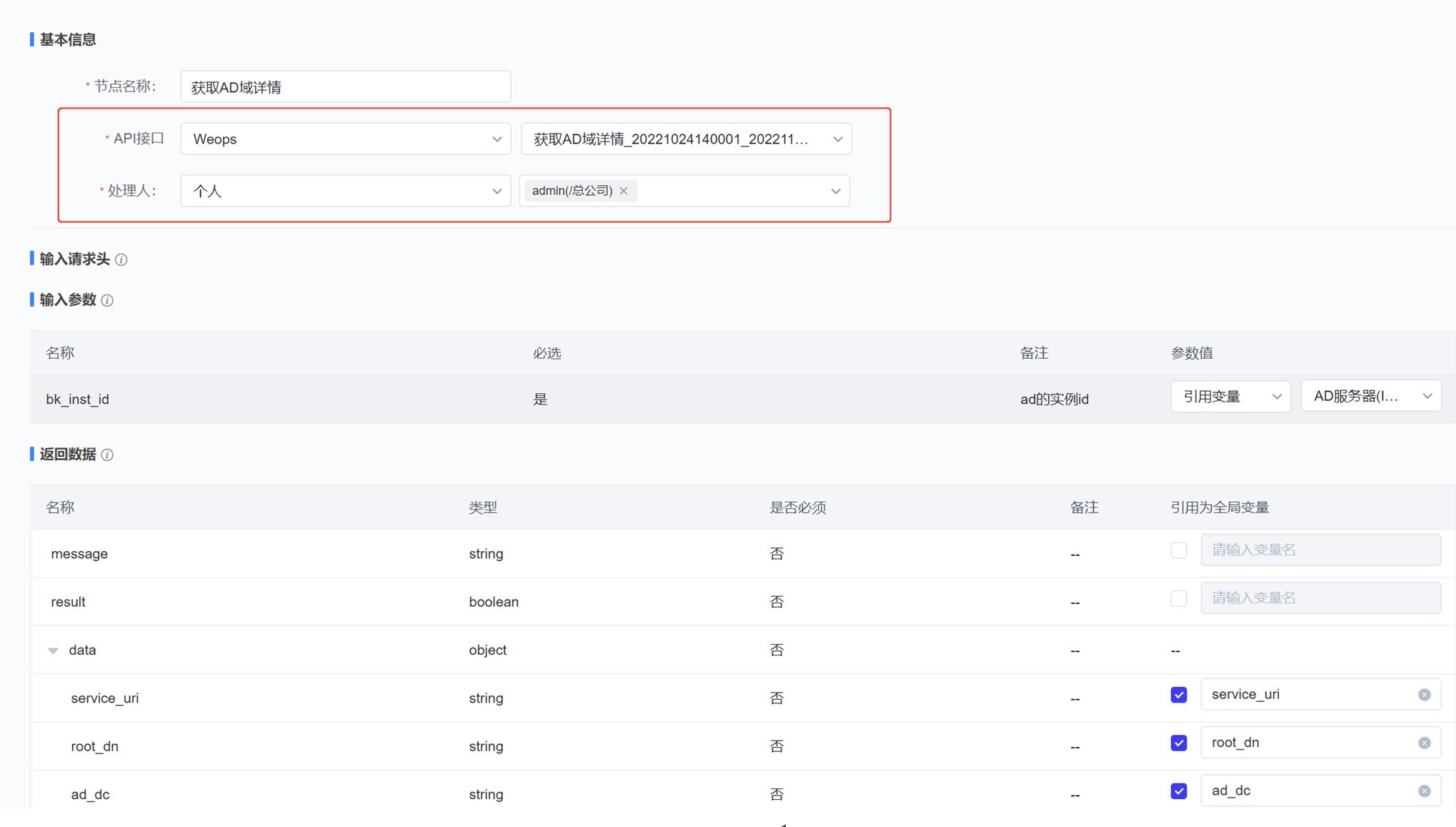
自动账号创建节点:选择需要的自动流程,填写参数
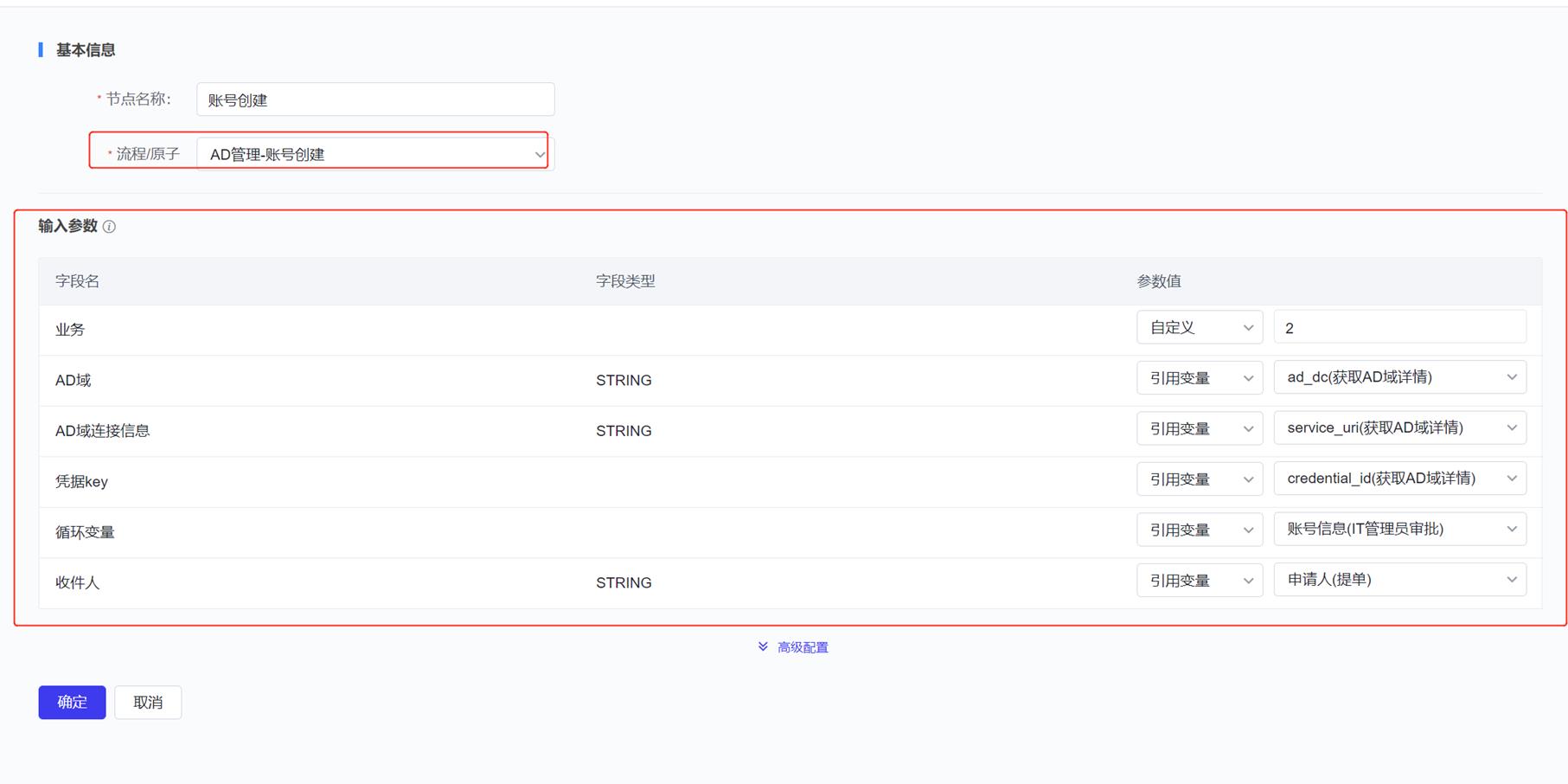
Step3:使用工单流程提单,进行自动化创建
当流程配置好以后,可以进行提单操作,具体步骤可以查看视频查看AD账号创建自动化流程的使用。
场景七 如何利用工单进行数据库SQL的自动执行
场景介绍
某公司之前的数据库SQL执行语句需要运维人员接受到需求后,手动执行前,现在可以使用WeOps的IT服务台进行自动化执行。
场景实现
Step1:前提条件介绍
1、WeOps的前期准备
- WeOps中已经纳管所需要的数据库,如下图,在WeOps-资产数据-资产记录-数据库中,对所需要的数据库进行纳管(目前可支持MySQL和Oracle的执行)
- 数据库的凭据信息已经录入WeOps-凭据管理中,并且关联该数据库,并授权给对应需要审核的运维管理员

2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程

- 在WeOps-后台管理-流程API配置中导入需要的API接口
- 需要导入的API如下:WeOps组导入获取业务某模型下的资源列表、获取实例凭据列表、获取实例详情、获取用户业务这4个API接口
- 在后台自动化流程中导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置
- 提单节点:所属应用、数据库这三个字段需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,类别展示该应用下的资产模型列表,数据库展示选择的数据库类型具体实例列表。具体选择和配置如下图所示

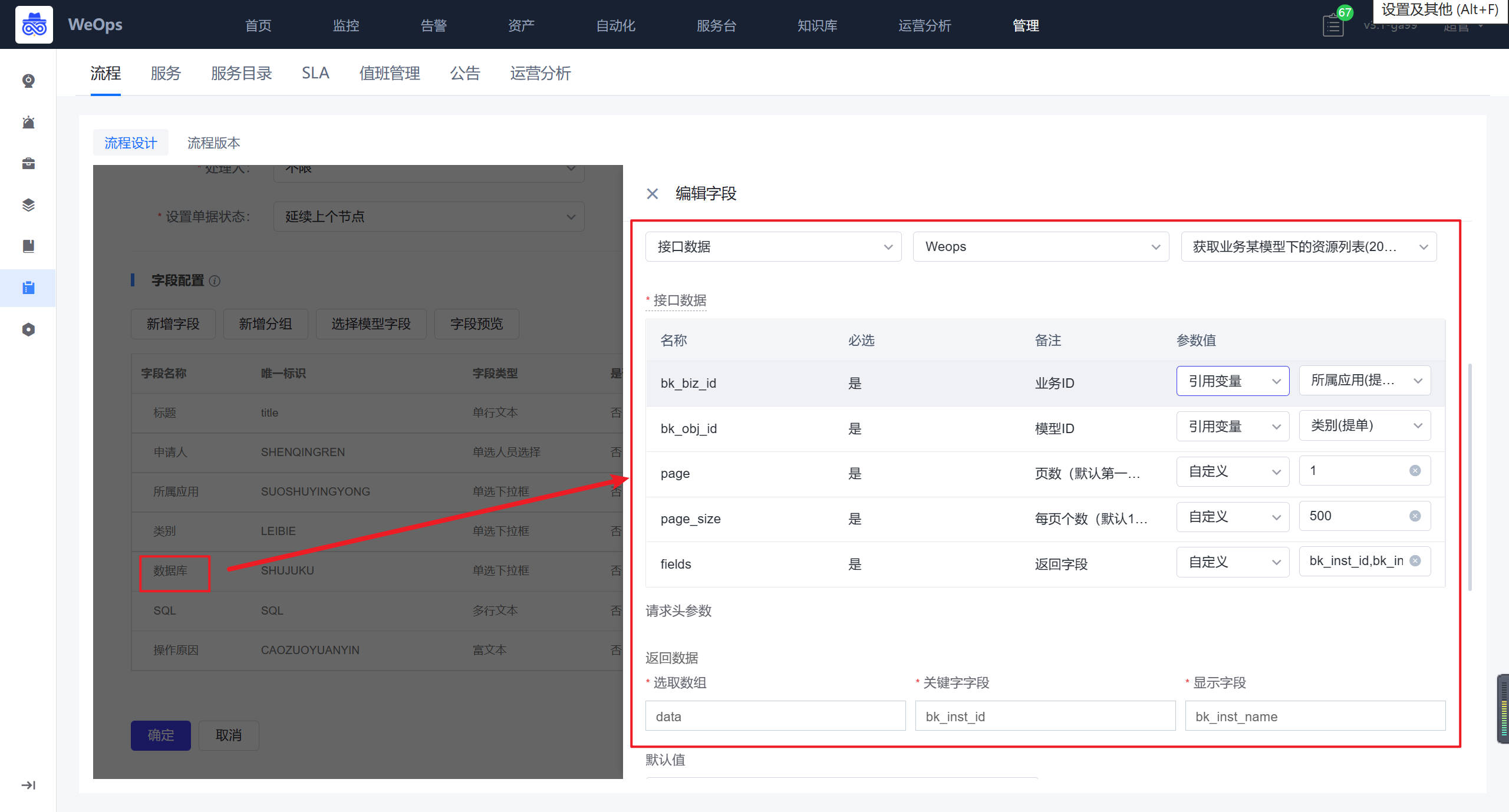
审批节点:数据库凭据需要重新选择接口,作用如下:管理员对提单人提交的SQL语句,数据库信息等进行审核,审核无误后选择该数据库的凭据,便于下一步自动执行。
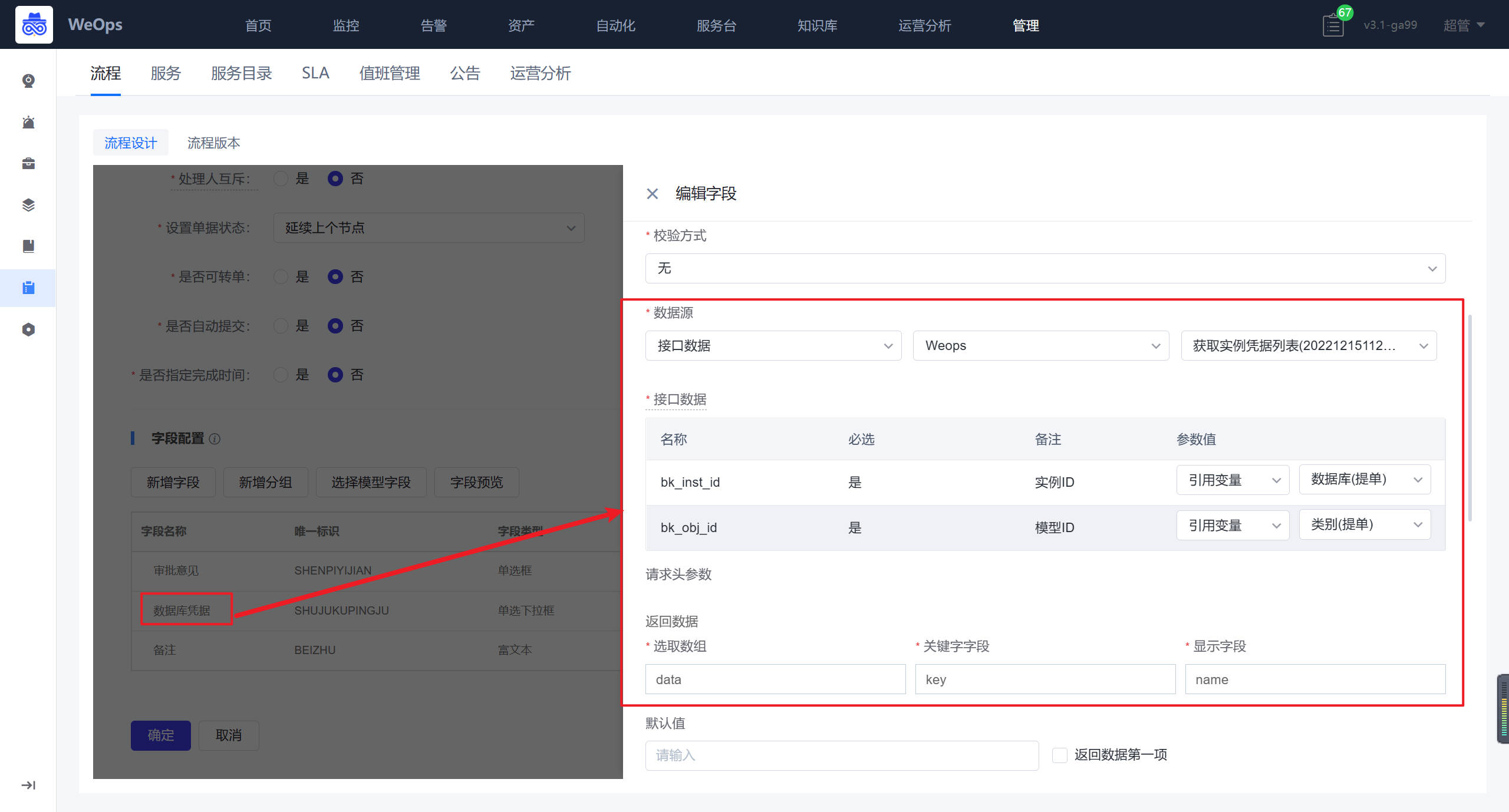
获取API详情节点:选择对应接口,下面的参数会自动勾选的
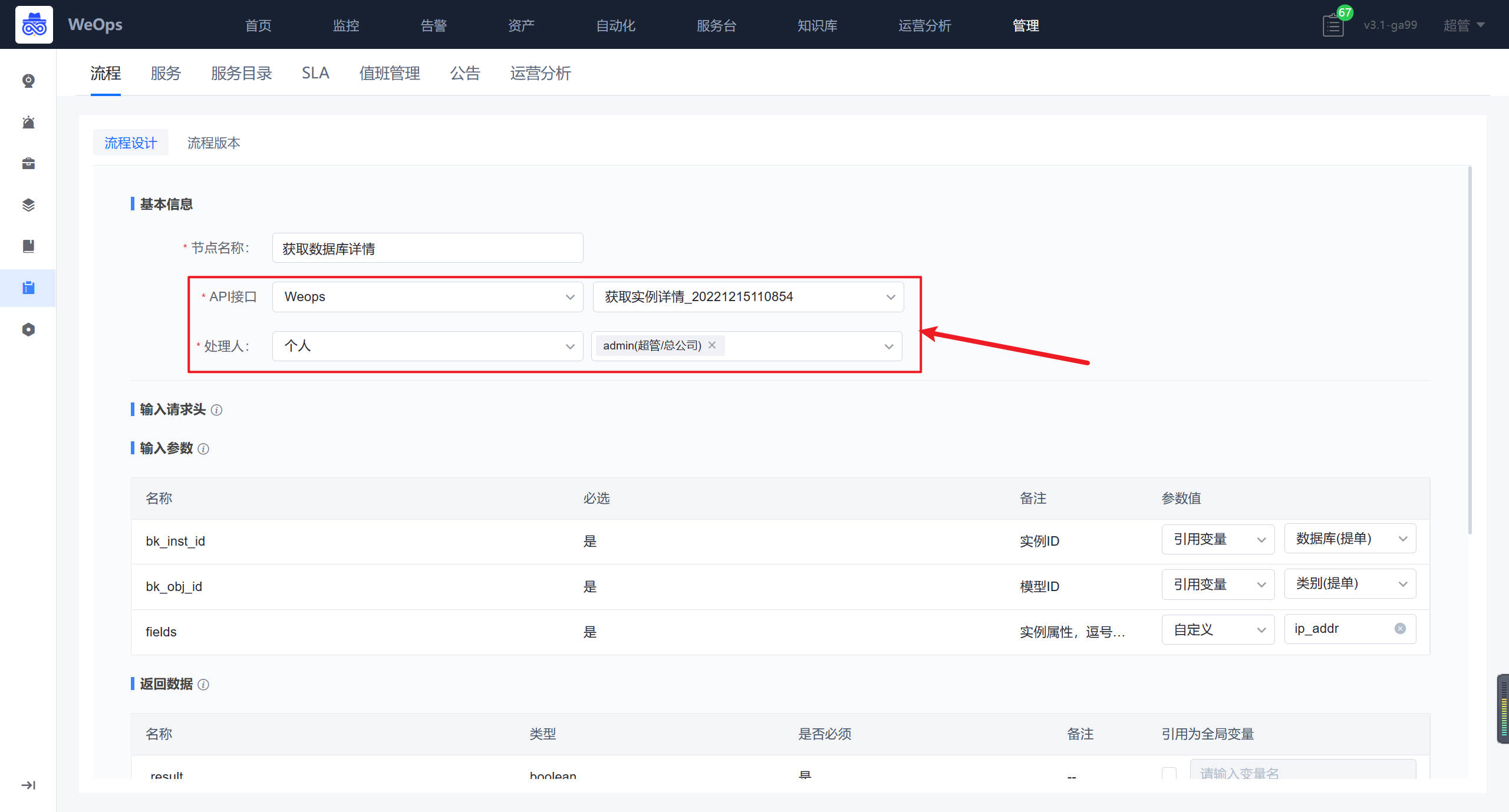
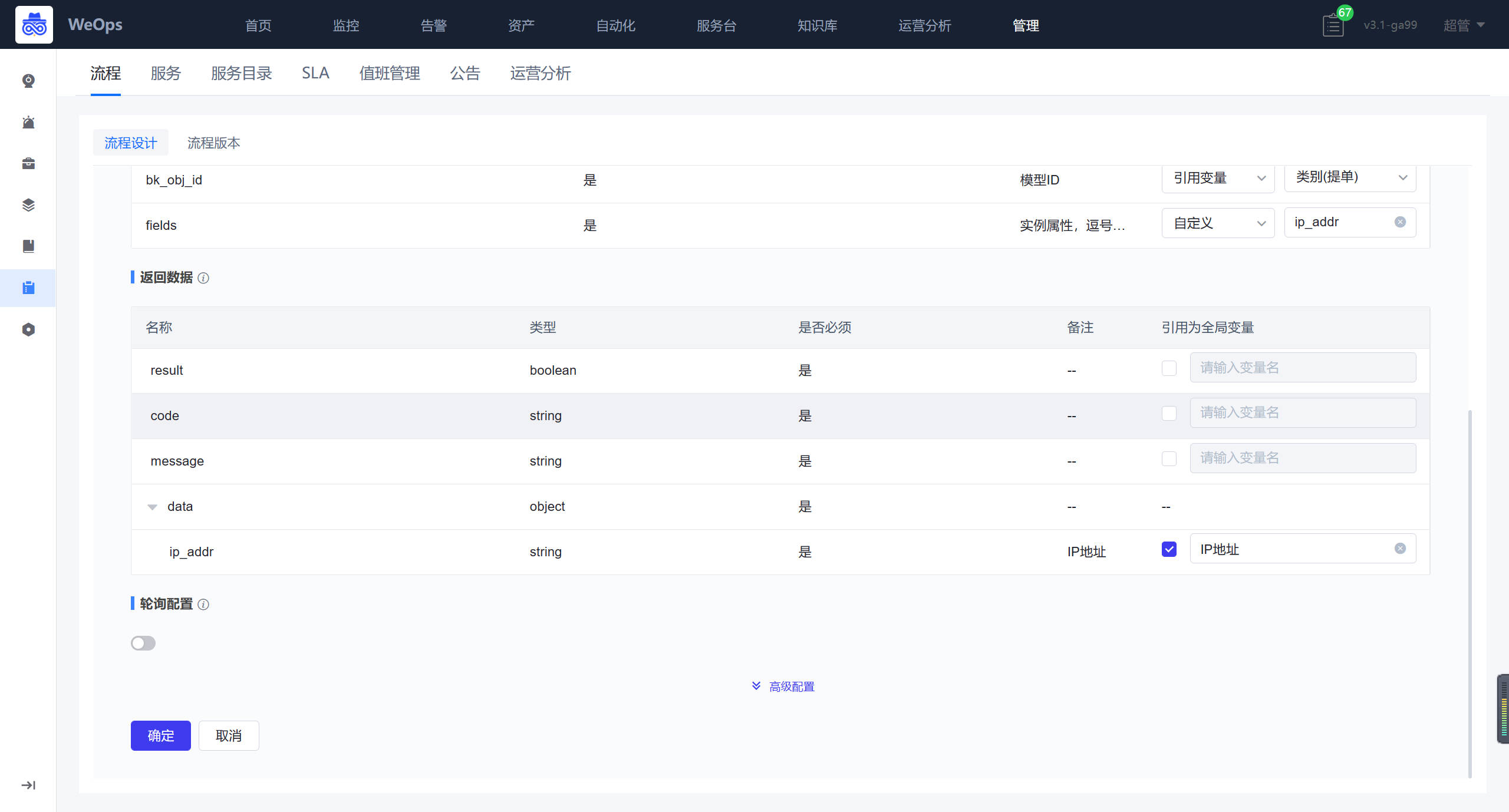
自动执行节点:选择需要的自动流程,填写参数
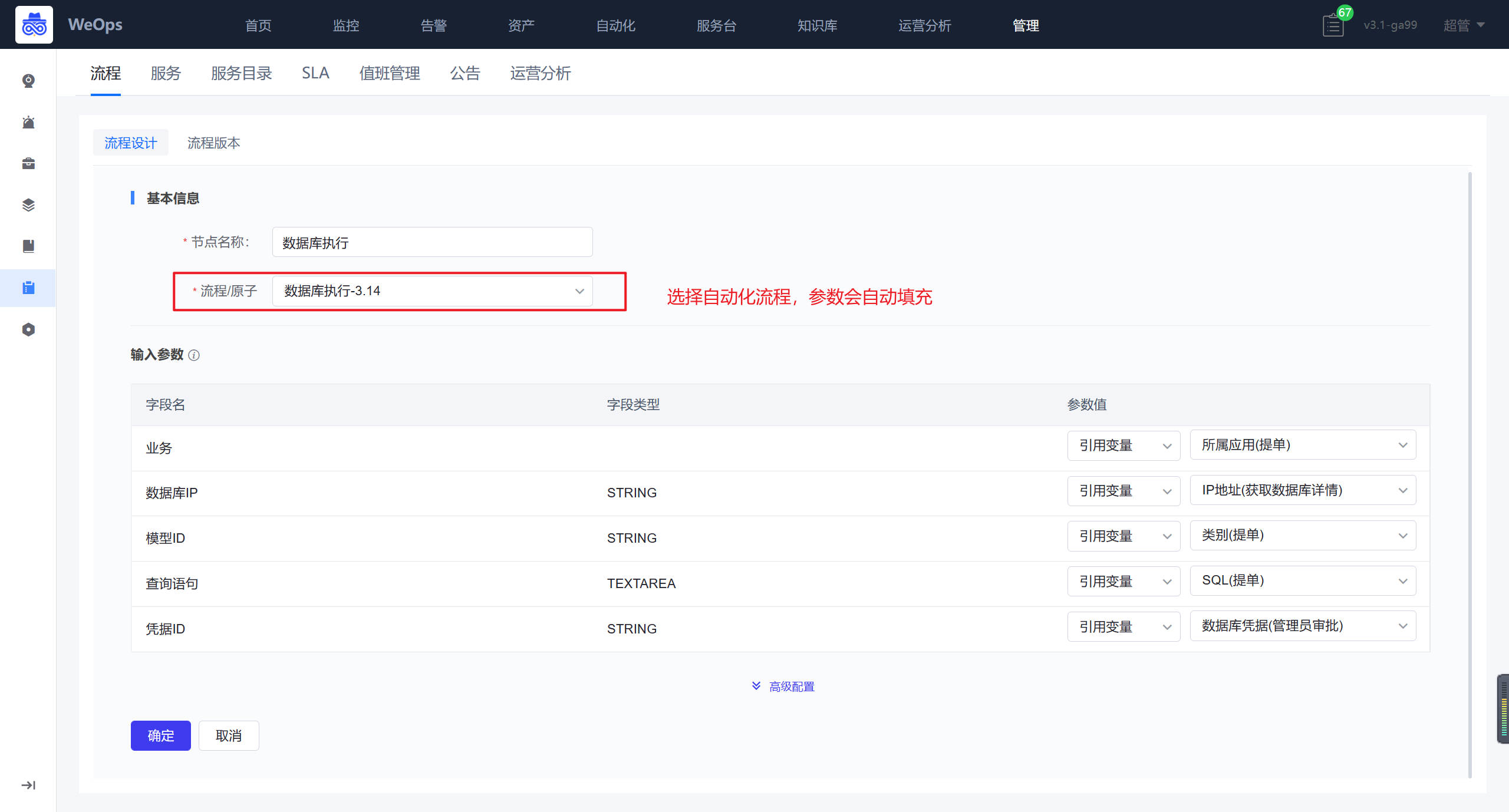
Step3:使用工单流程提单,进行自动化创建
当流程配置好以后,可以进行提单操作
- 提单:用户提单时需要选择需要执行的数据库实例,并填写SQL语句和申请原因
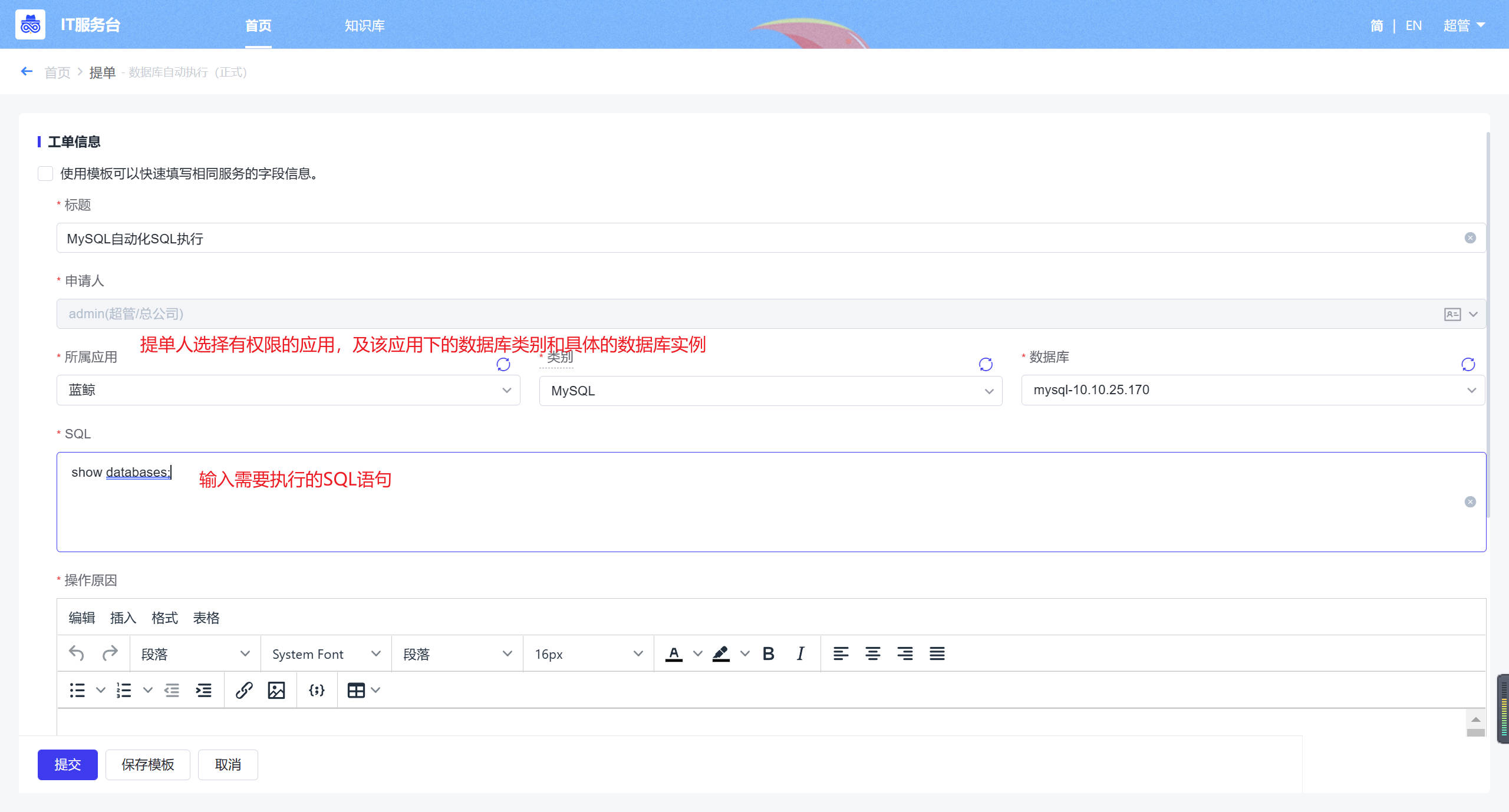
- 审批:管理员对提单人的申请信息进行审批,无误后选择执行的数据库凭据
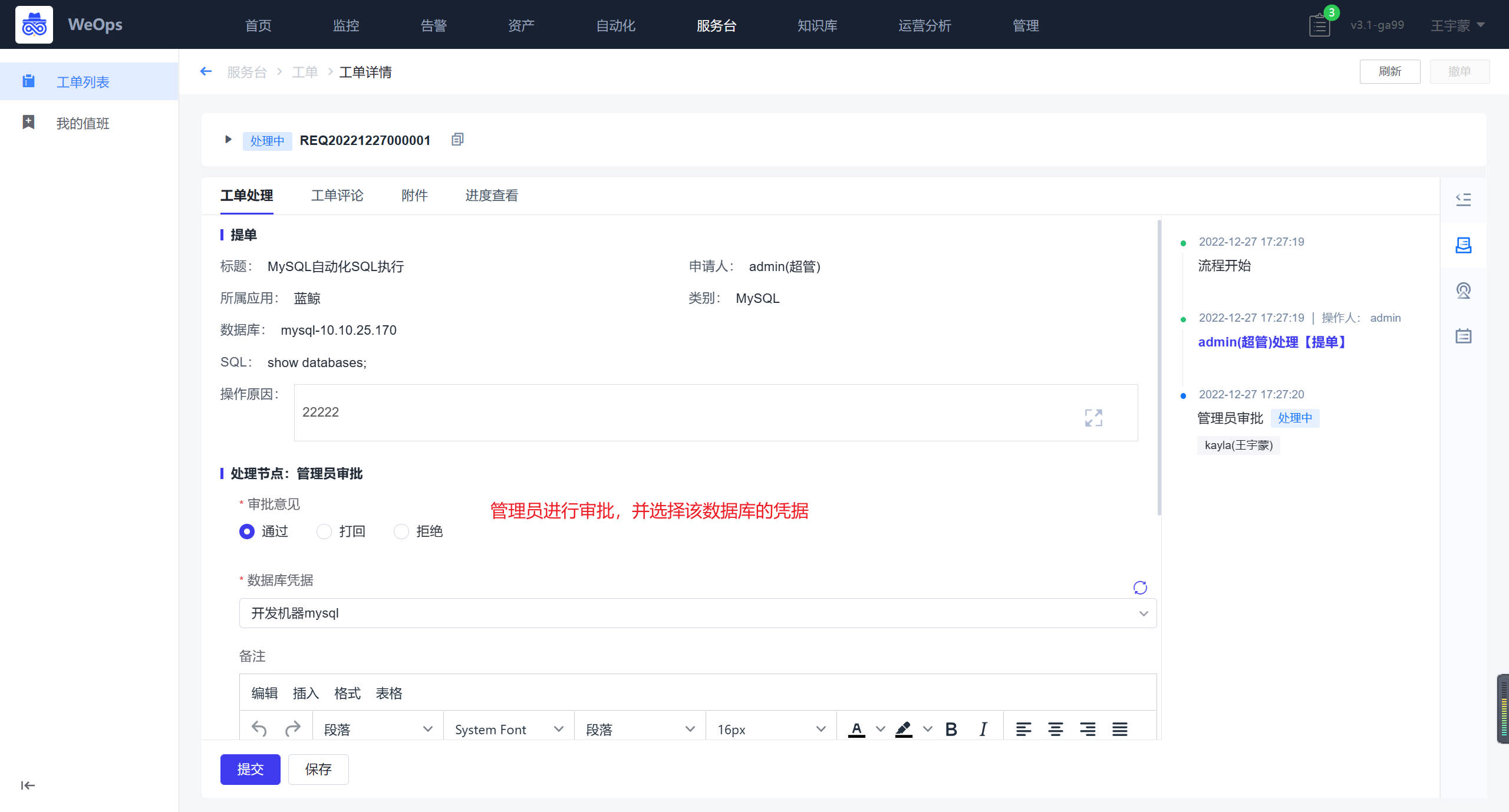
- 自动执行:提单人的SQL语句将会自动的在对应的数据中进行执行,并返回执行结果成功/失败
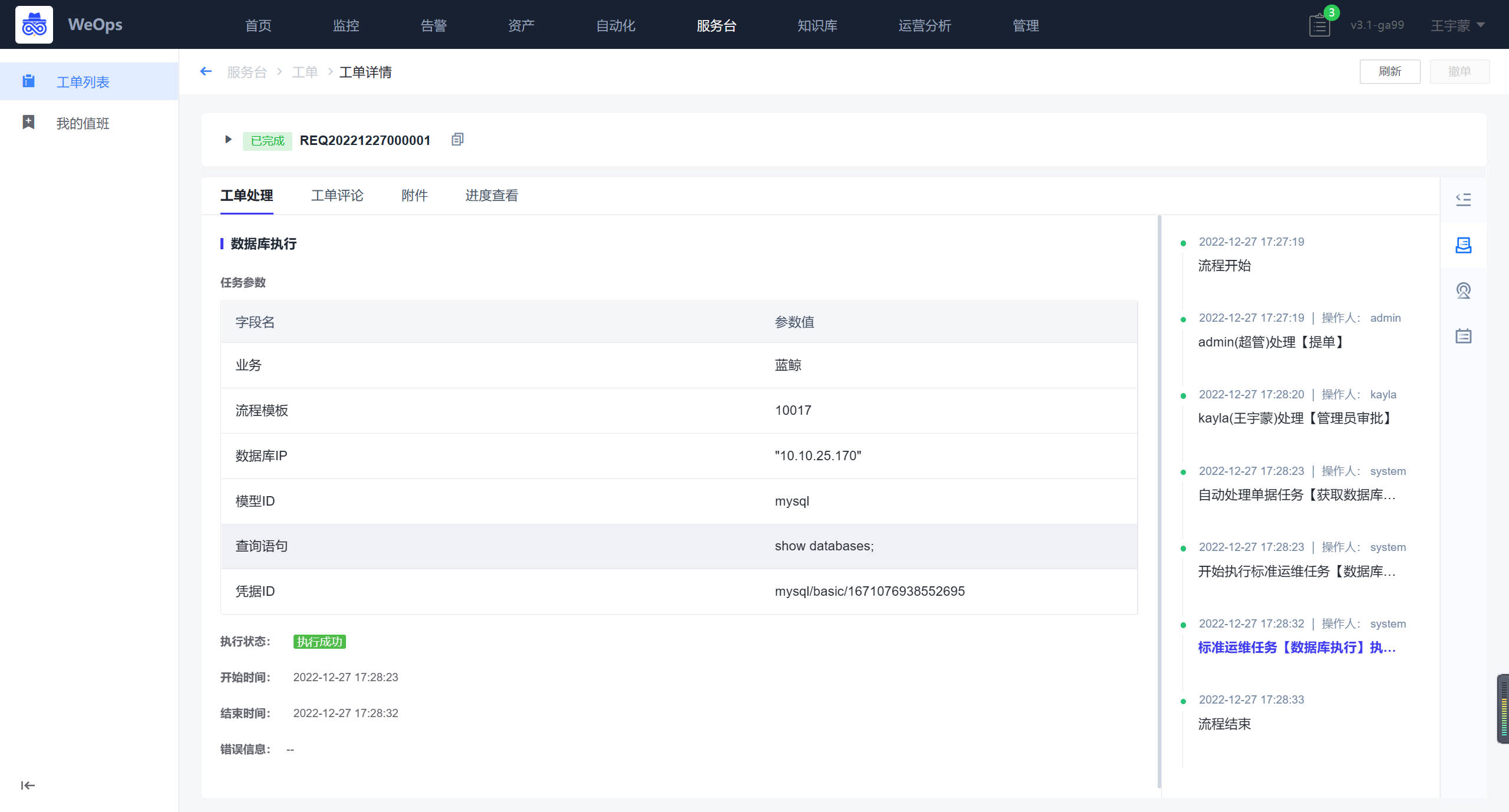
场景八 如何利用工单进行vmware虚拟机的自动创建/快照创建/快照回滚
场景介绍
某公司之前的虚拟机创建需要运维人员接受到需求后,手动进行创建,耗时耗力,准确率低,容易出错。采用工单自动化,可以实现申请人自行提单,管理员经过审批就可以创建。
场景实现
Step1:前提条件介绍
1、WeOps的前期准备
- WeOps中已经纳管所需要的Vcenter,如下图,在WeOps-资产数据-资产记录-Vcenter中,对所需要的Vcenter进行纳管
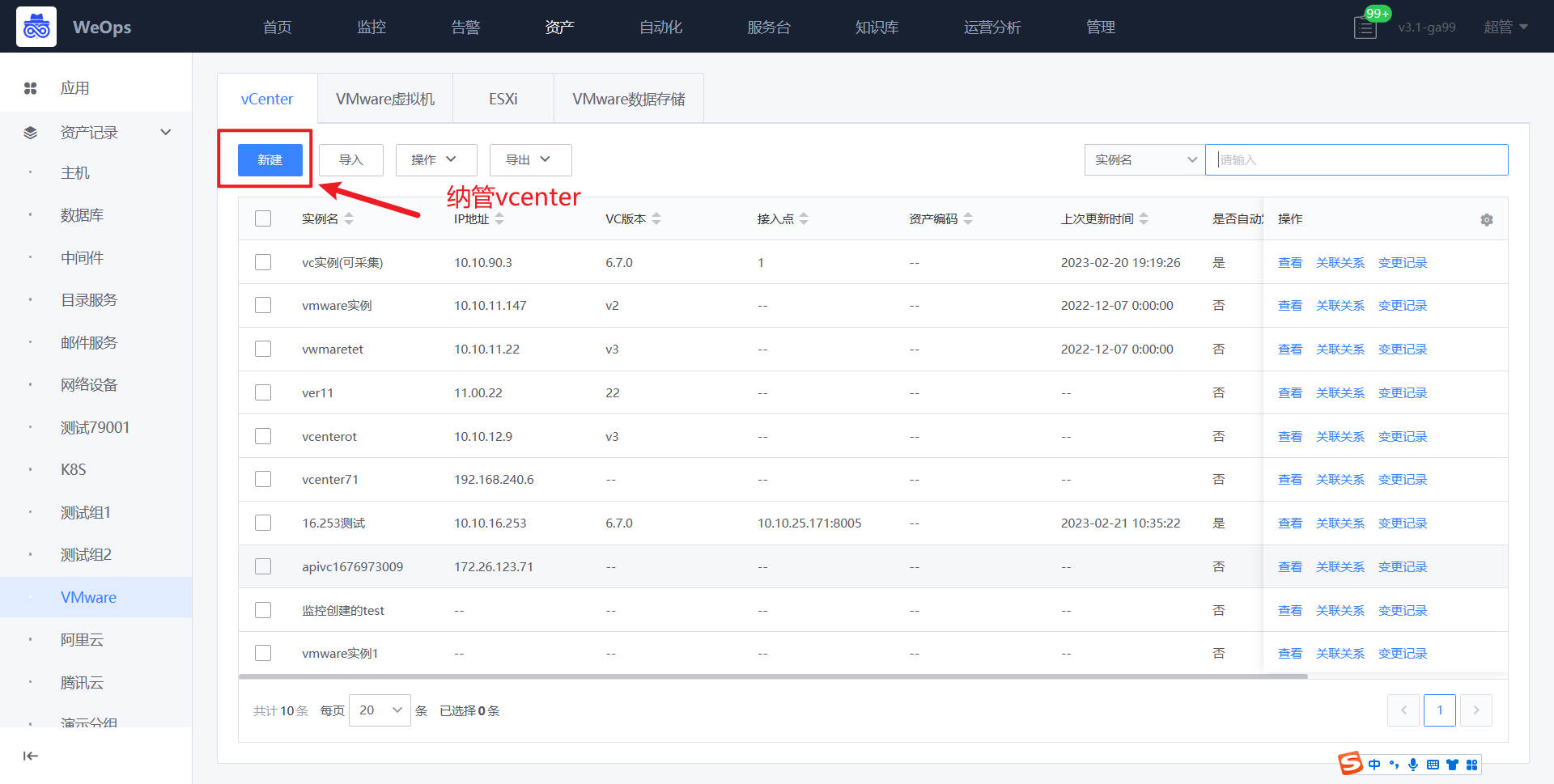
- Vcenter的凭据信息已经录入WeOps-凭据管理中,并且关联该Vcenter,并授权给对应需要审核的运维管理员,这样运维管理员在审批工单的时候,就可以选择到这个Vcenter并选择使用对应的凭据,以便后续直接进行自动化的创建。 (用户自动化流程的凭据,建议使用拥有全局权限的管理员角色)
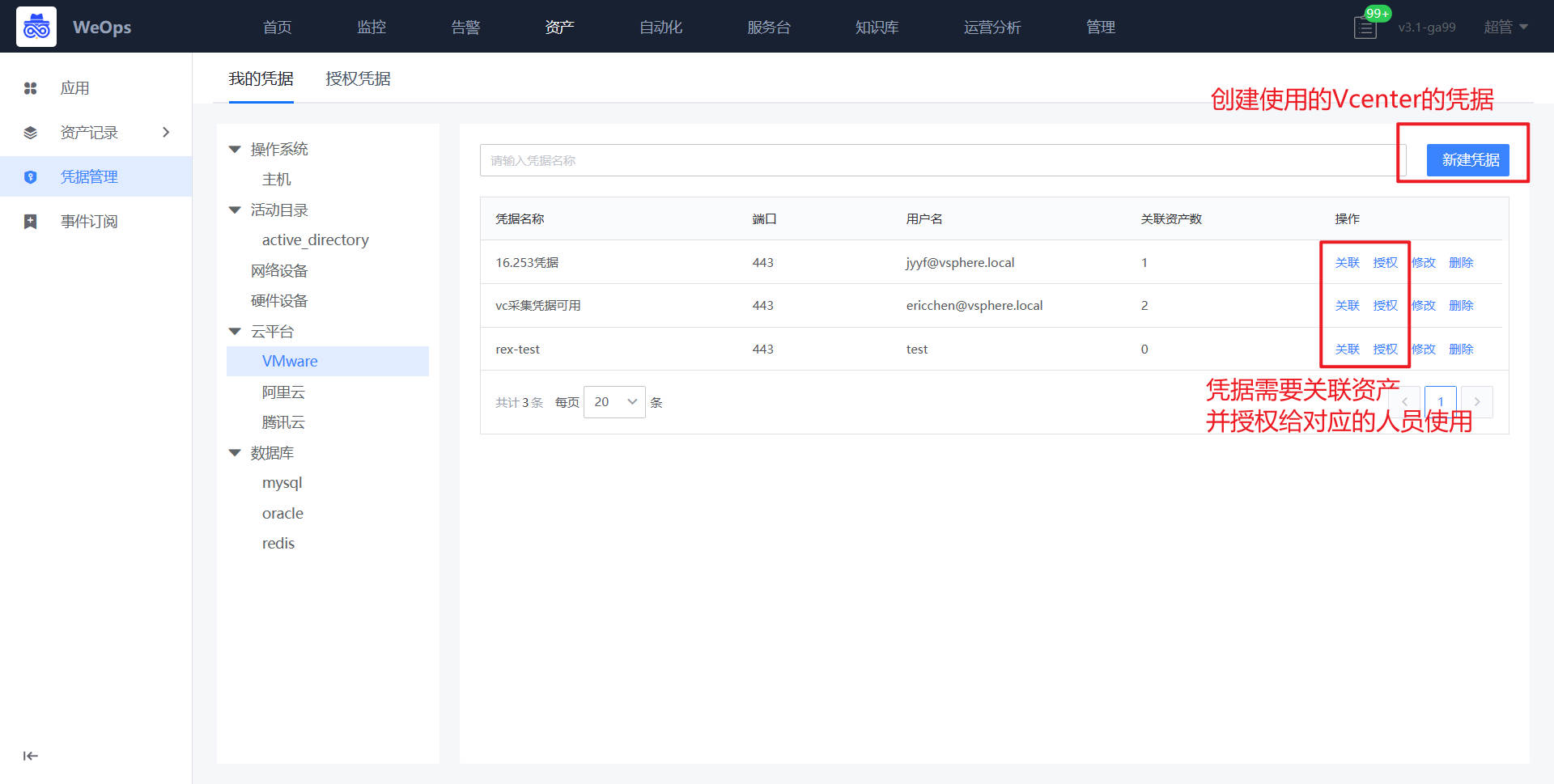
- 该Vcenter在WeOps-管理-资产管理中,已经设置了定时自动发现,可以自动发现该Vcenter下面的虚拟机、ESXI和数据存储。设置了自动发现后,自动创建的虚拟机可以定时被WeOps自动纳管,以便后续使用(比如自动创建快照,快照回滚)
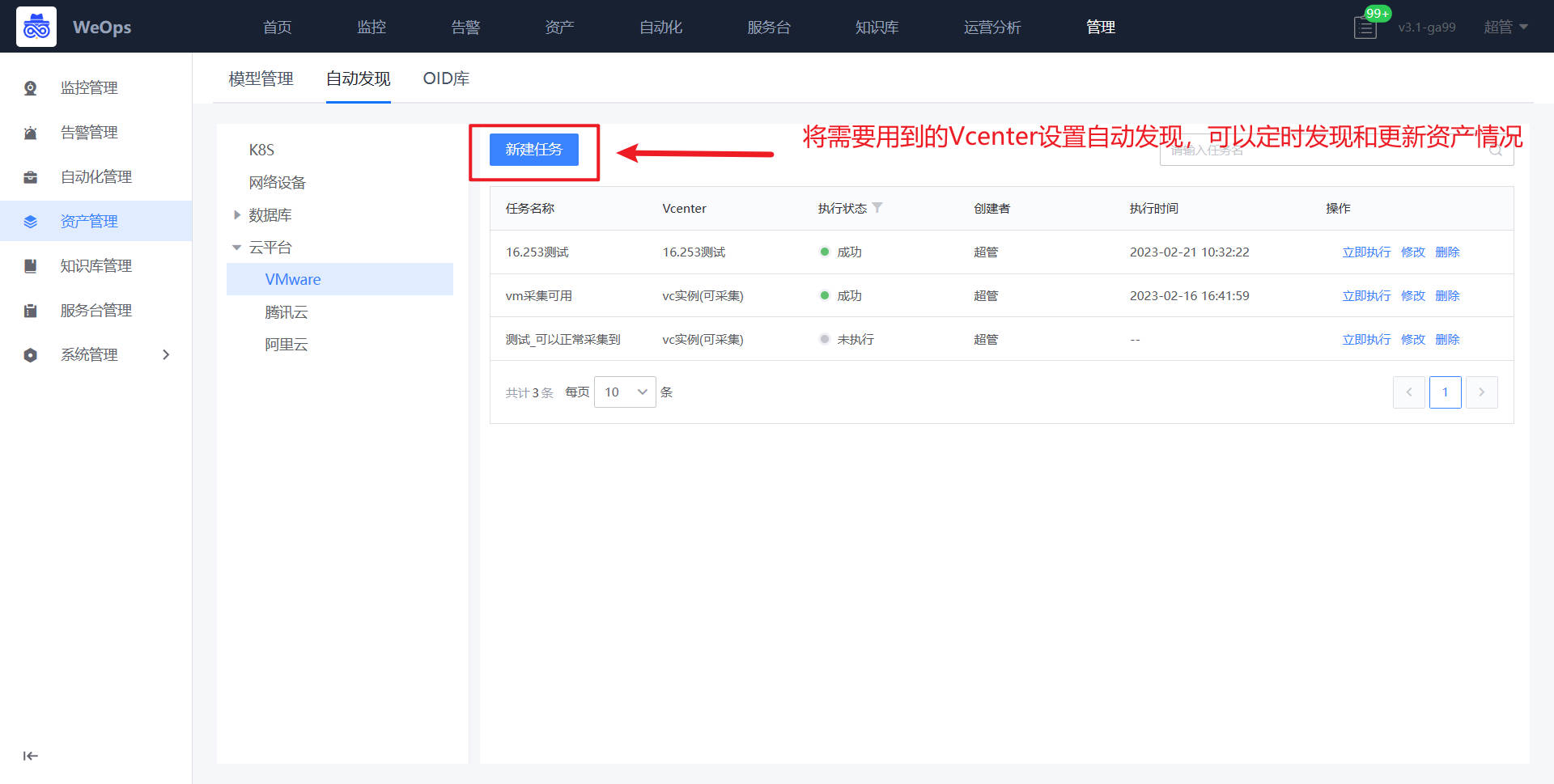
2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程
- 在WeOps-后台管理-流程API配置中导入需要的API接口
- 需要导入的API共有13个,主要用于虚拟机创建、虚拟机快照创建、虚拟机快照回滚,具体如下

- 在自动化流程导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置
虚拟机创建
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,创建的该虚拟机就归属这个应用。规格配置的字段:CPU规格、内存规格、系统容量、数据盘容量和操作系统,字段保持不变,下拉选项可以配置,以便后续把相关数据传入自动化流程。
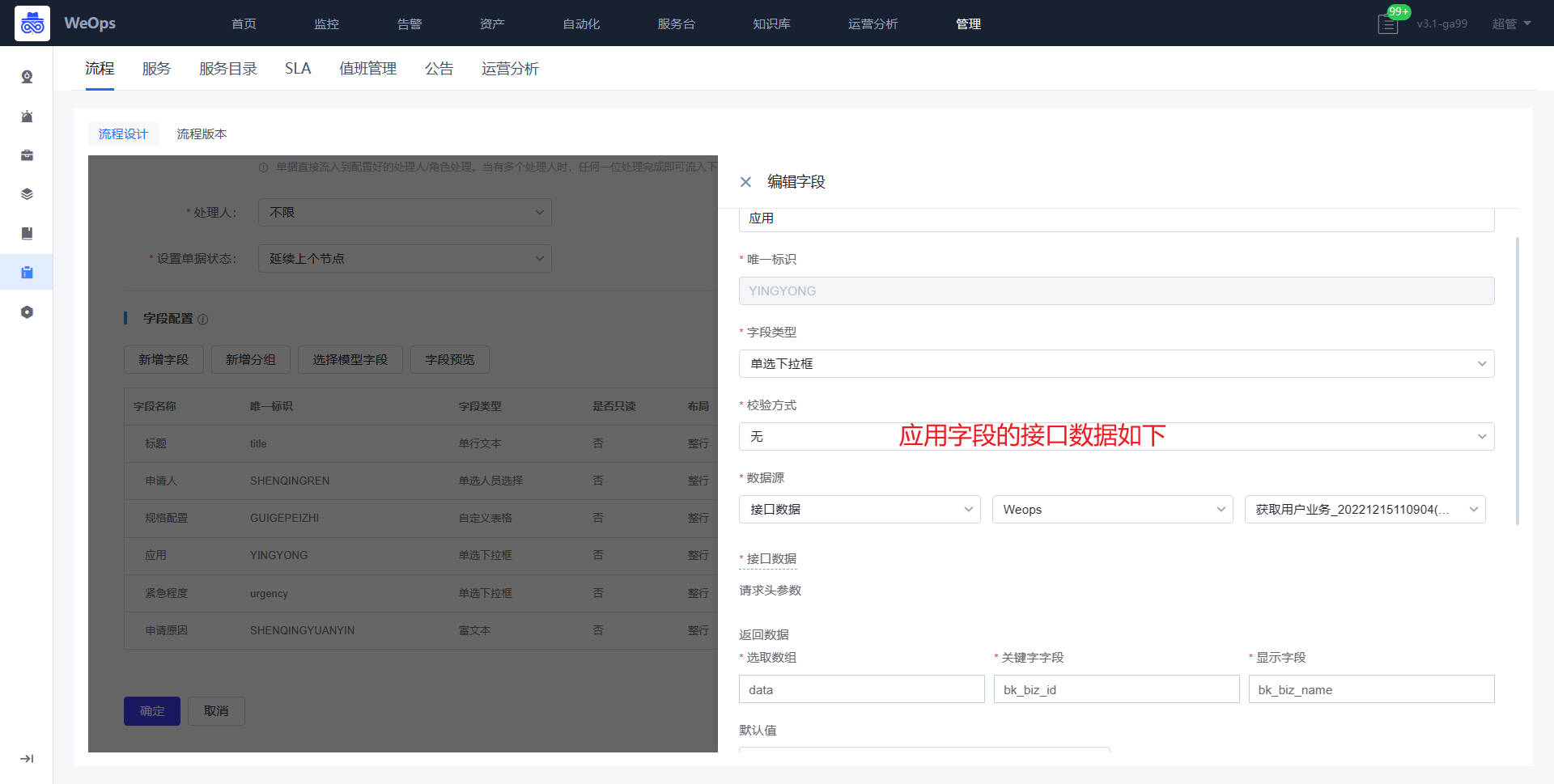
- 审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点,创建虚拟机的Vcenter以及其凭据,便于确定这个虚拟机创建的位置。
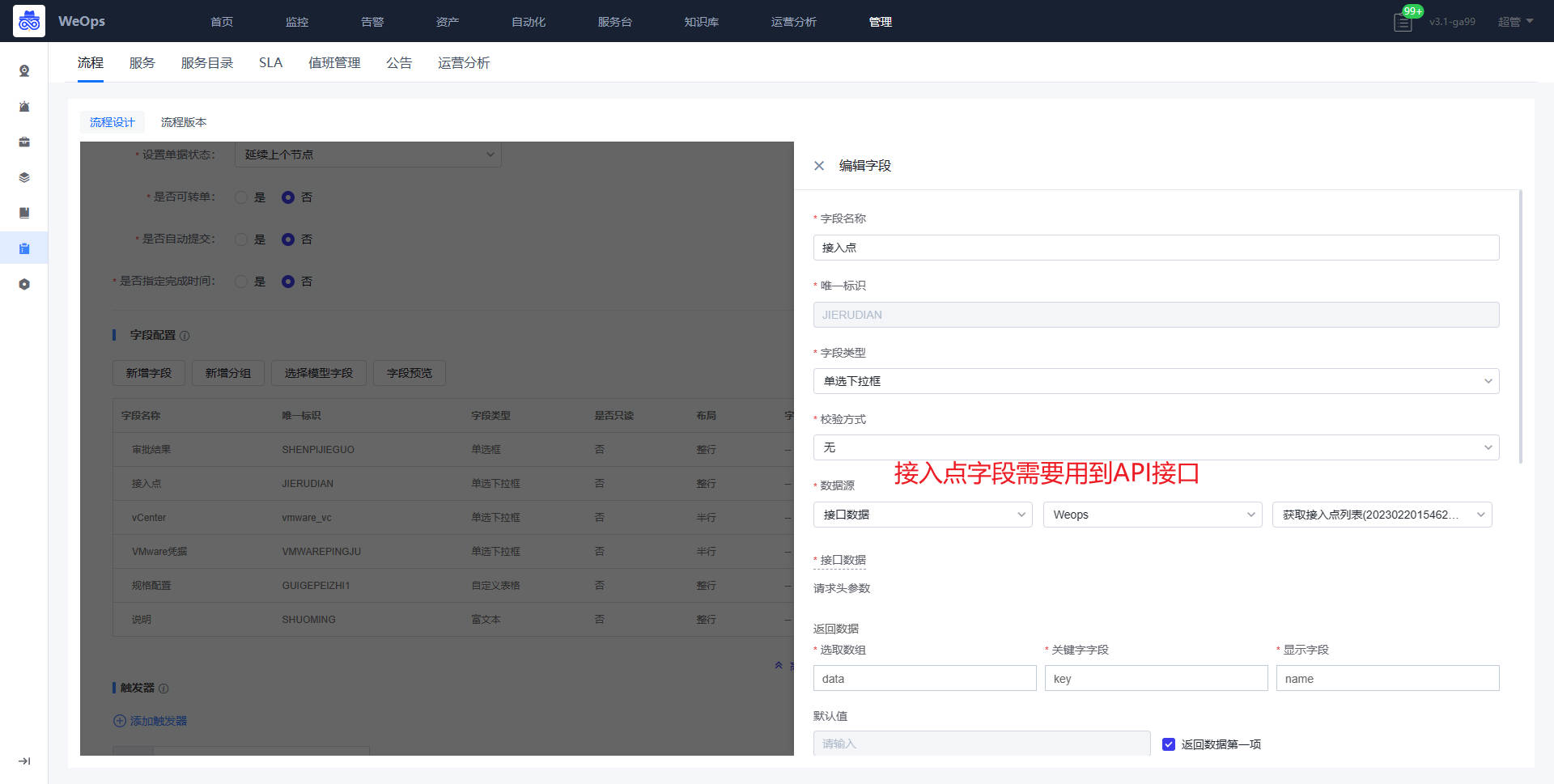

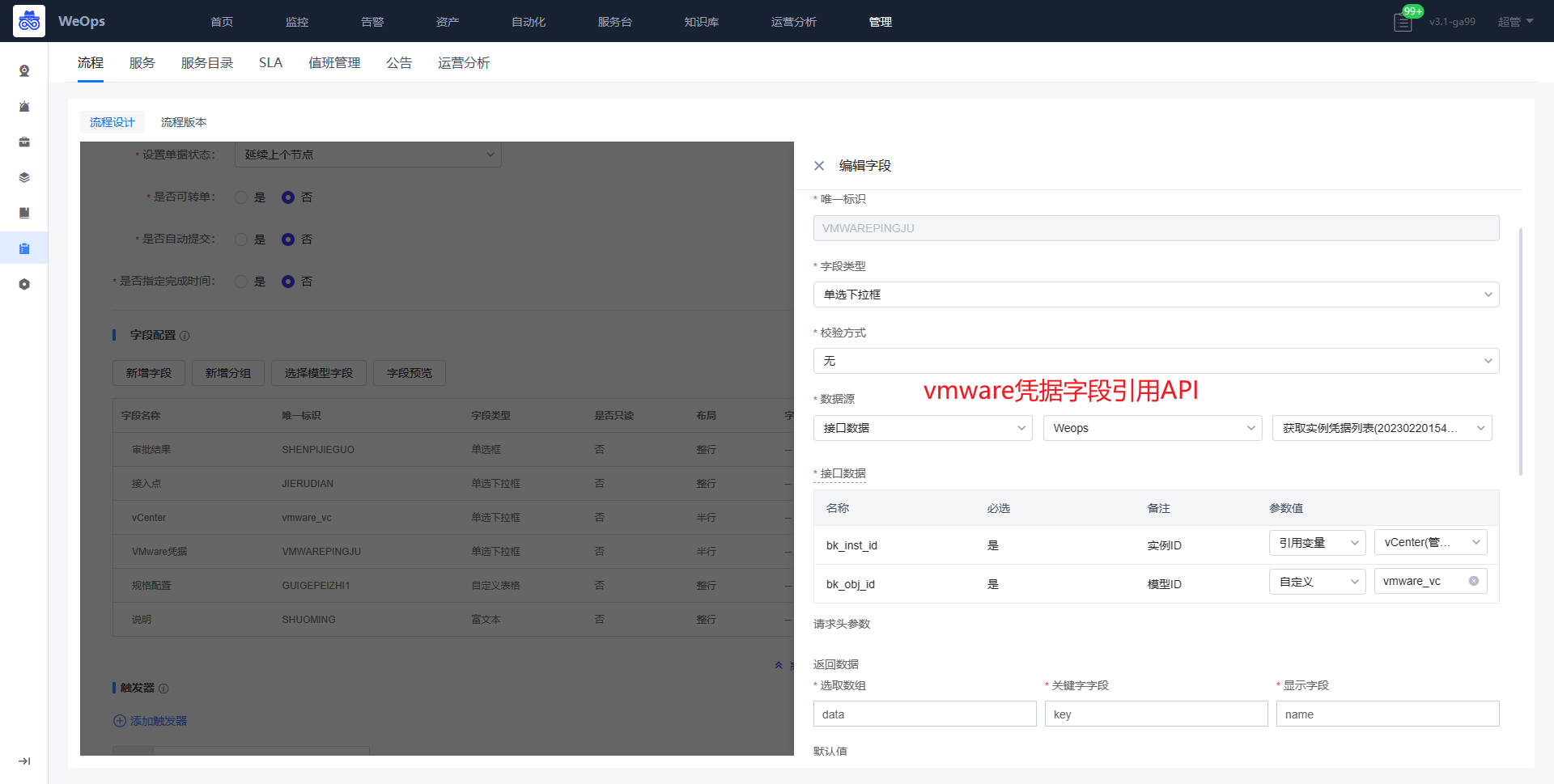
*审批节点:规格配置的字段说明如下:CPU规格、内存规格、系统容量和数据盘容量、操作系统的字段是提单节点自动获取的,无需改变;虚拟机模板、网络适配器、ESXI、文件夹的字段需要配置API获取对应信息;子网掩码、网关、DNS、虚拟机名称、IP地址的字段为手段填写;IP是否存在字段是为了验证填写的IP地址是否被使用,需要配置API信息。
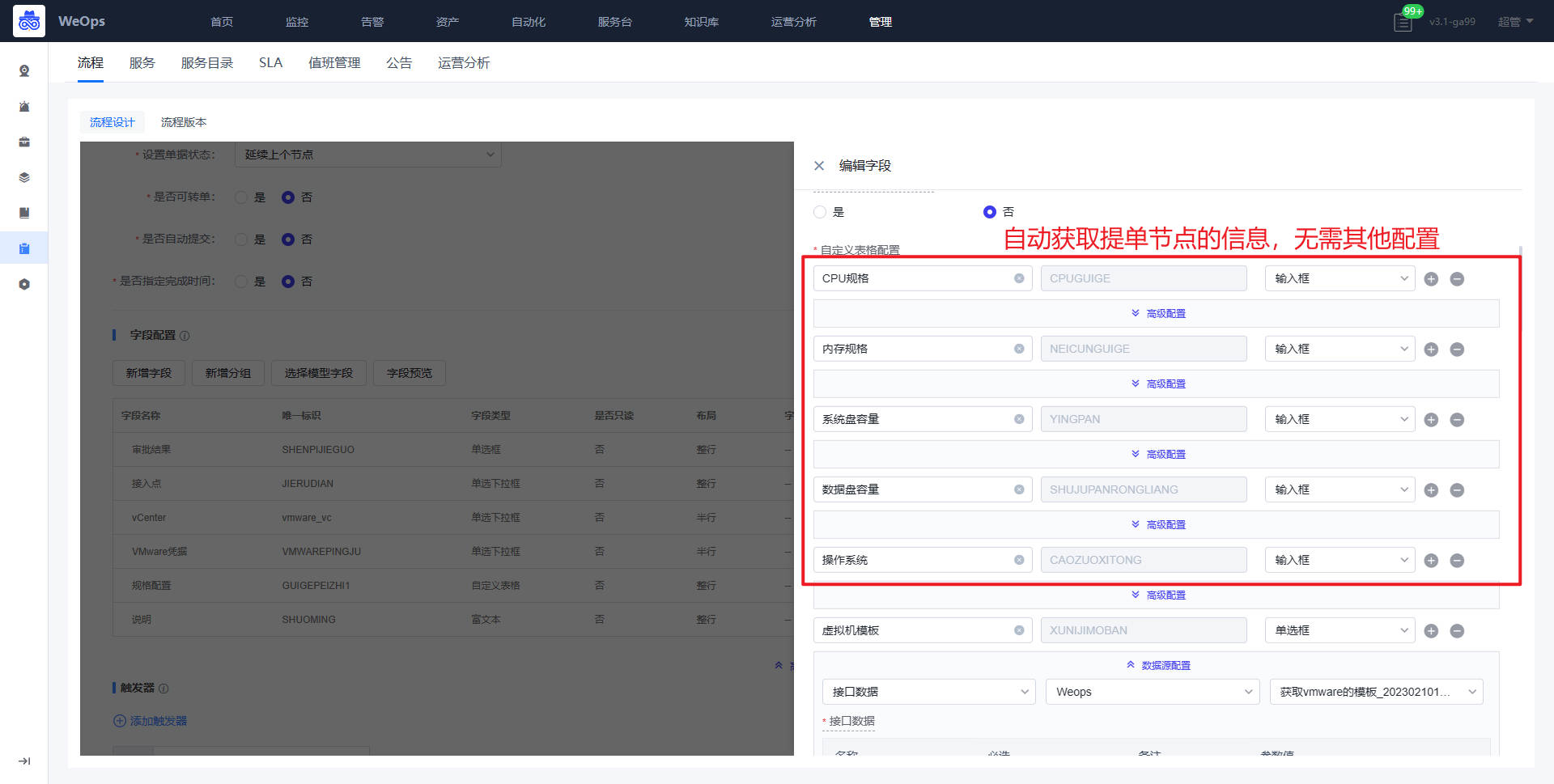

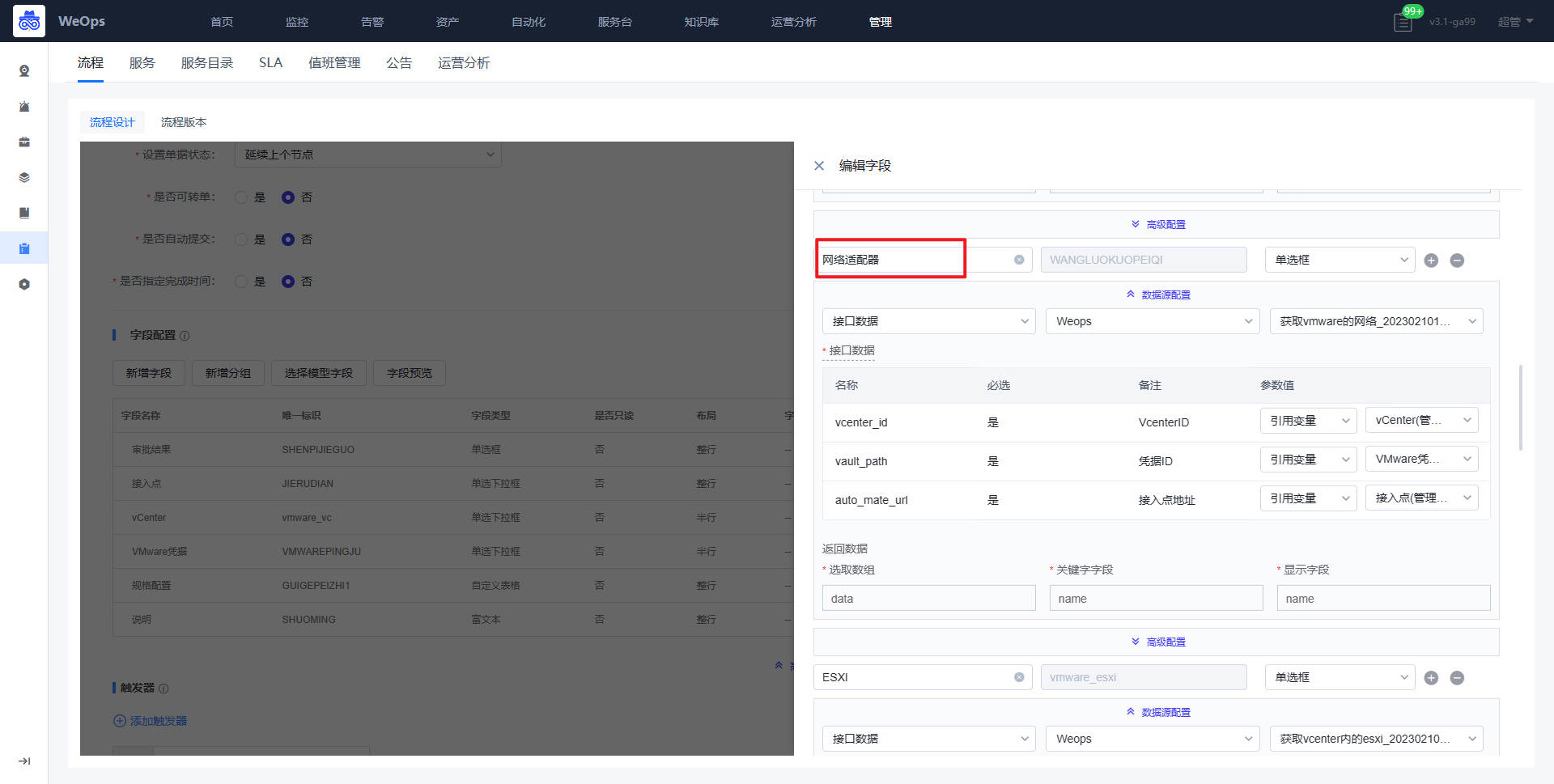


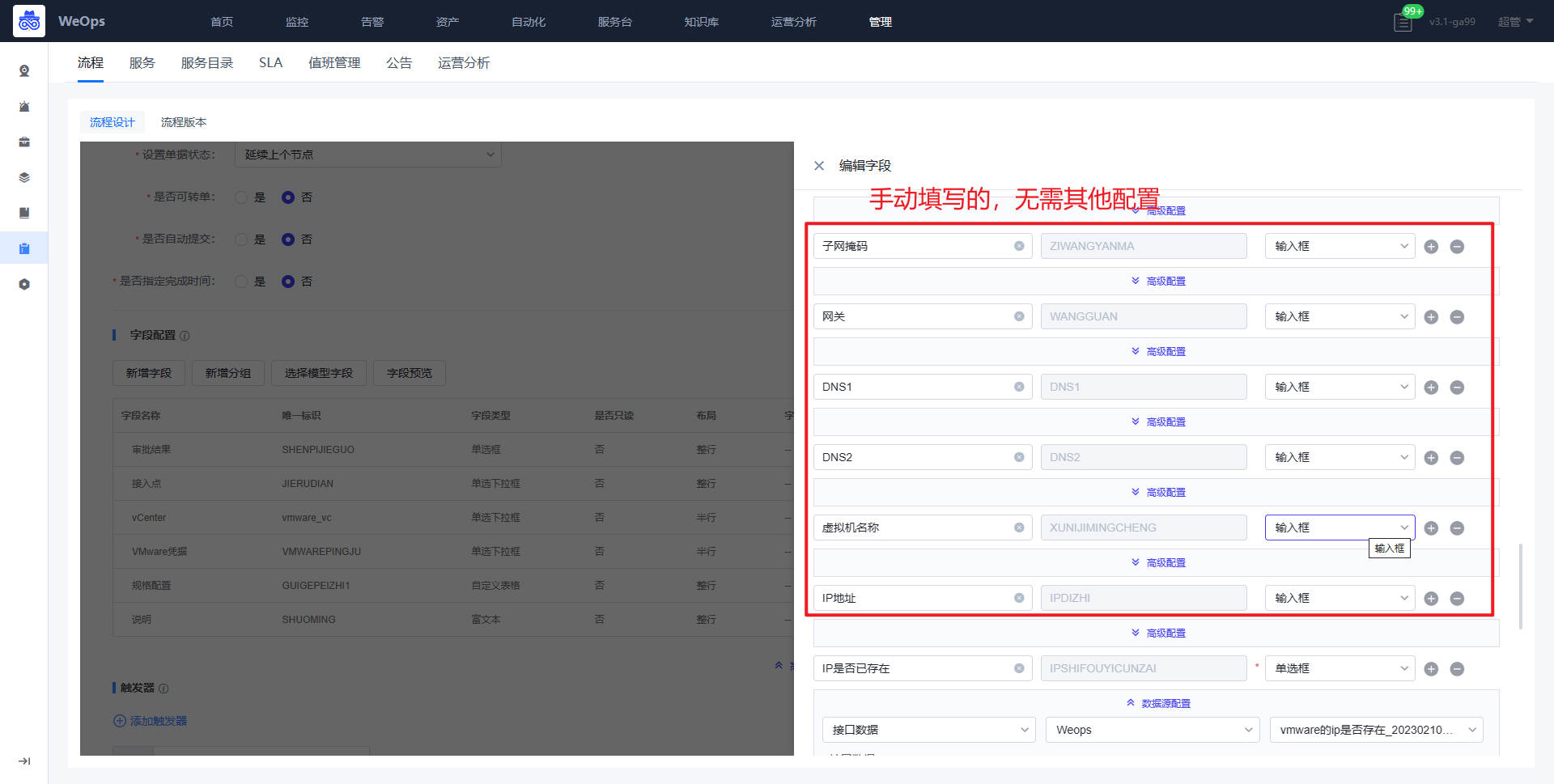

- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
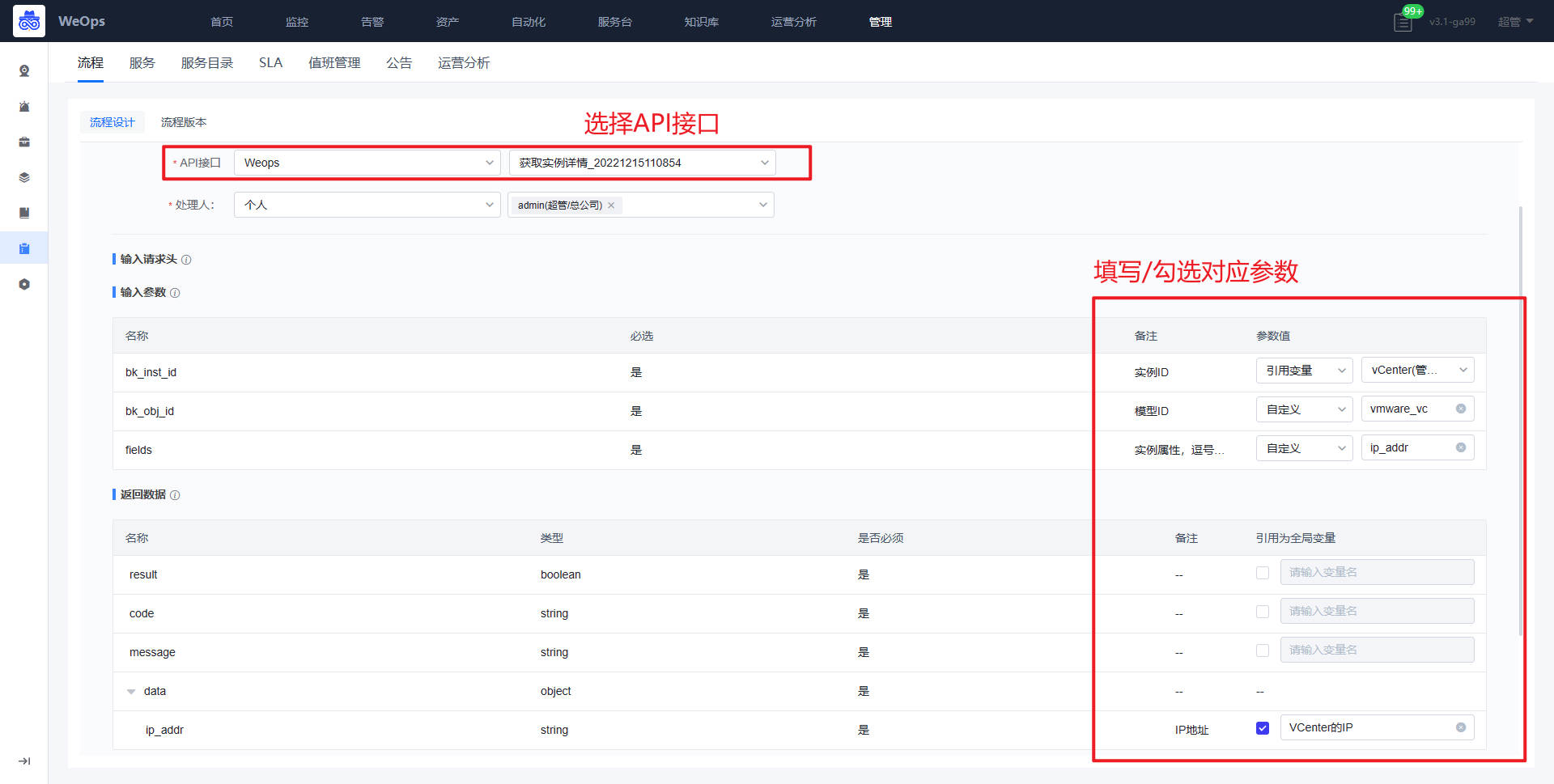
自动执行节点:选择需要的自动流程,填写参数
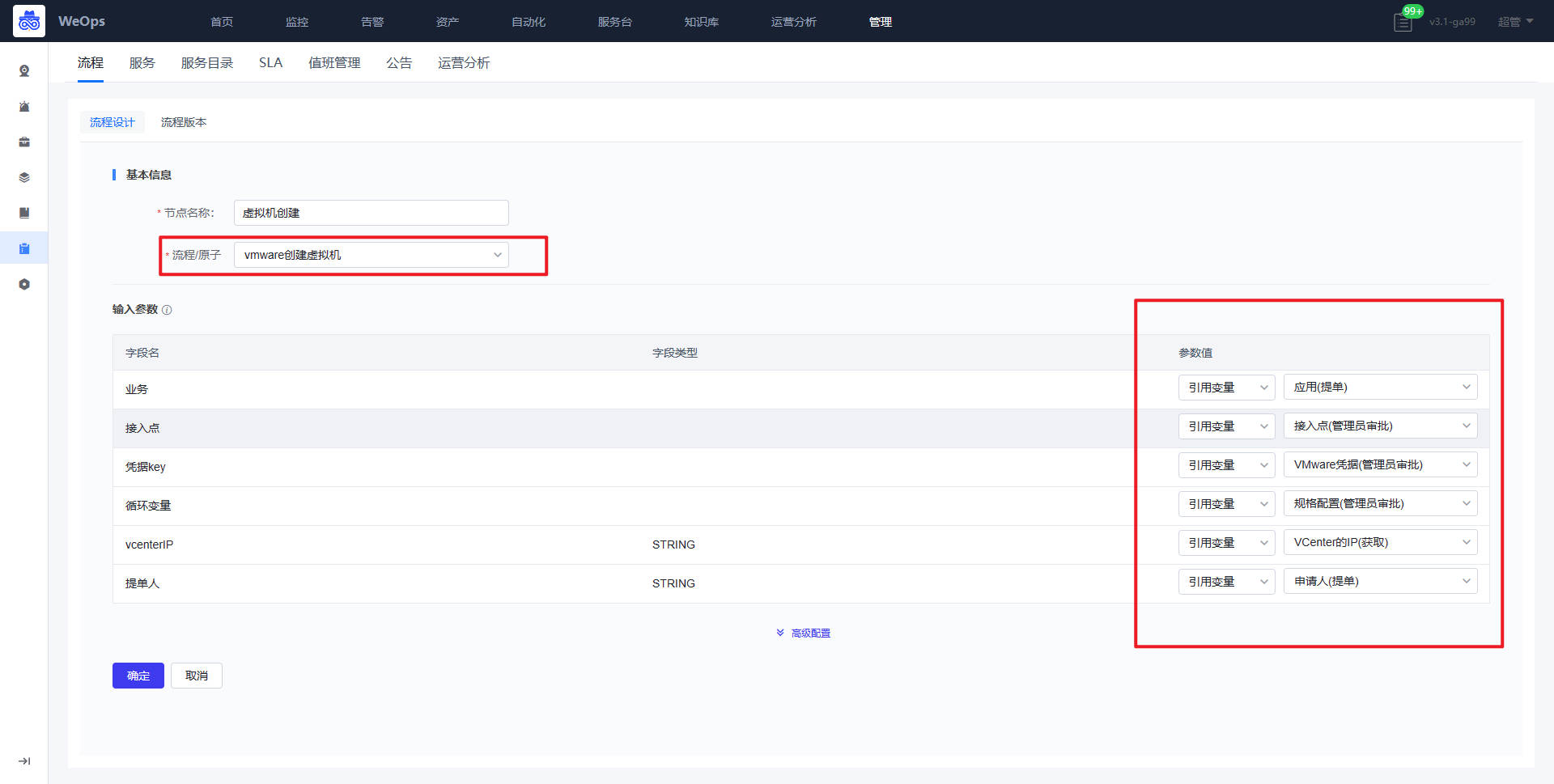
虚拟机快照创建
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用、虚拟机信息(IP地址和虚拟机名称)需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,可以展示该应用下的虚拟机IP列表和名称,便于提单人找下需要创建快照的虚拟机
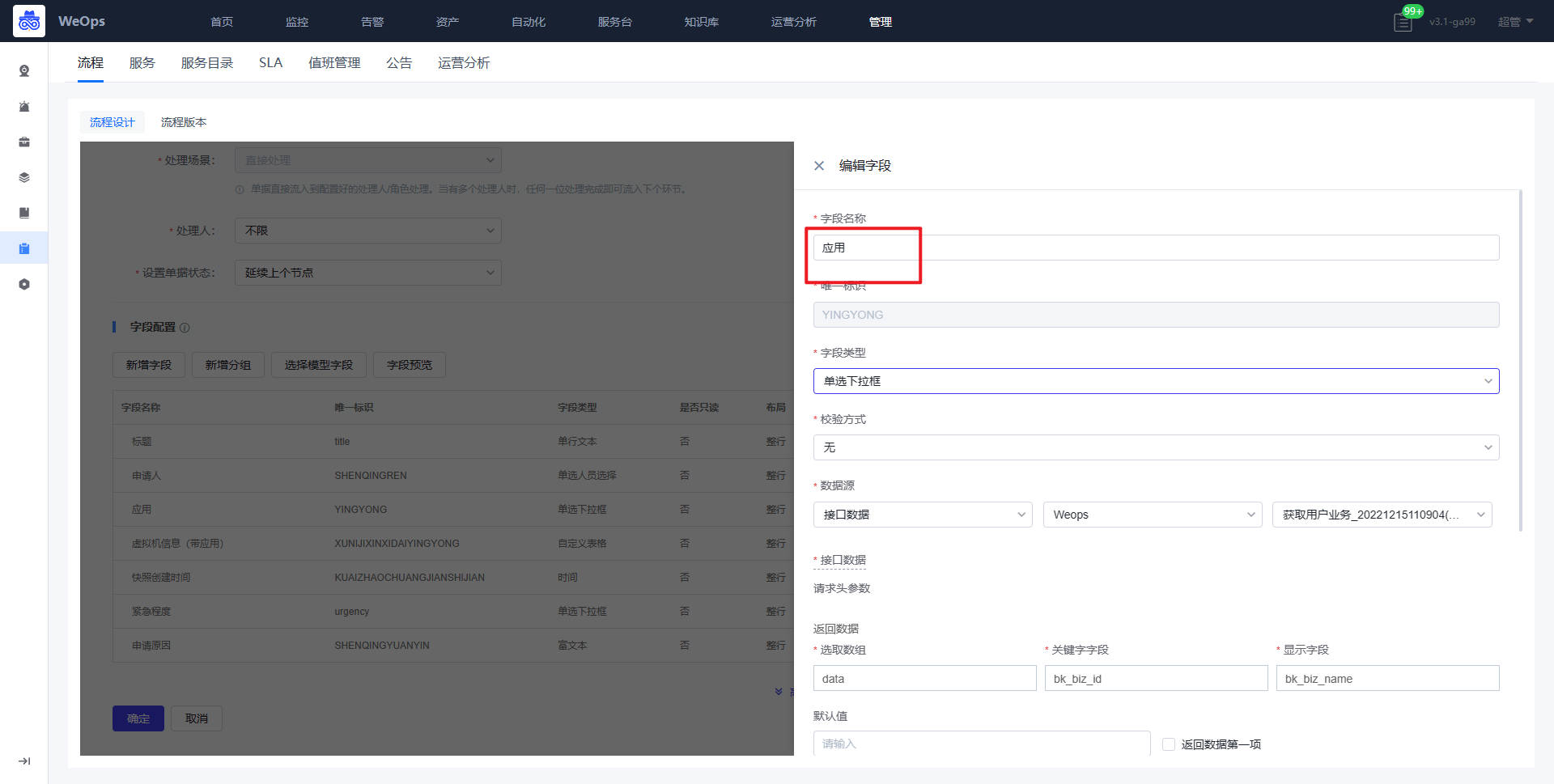
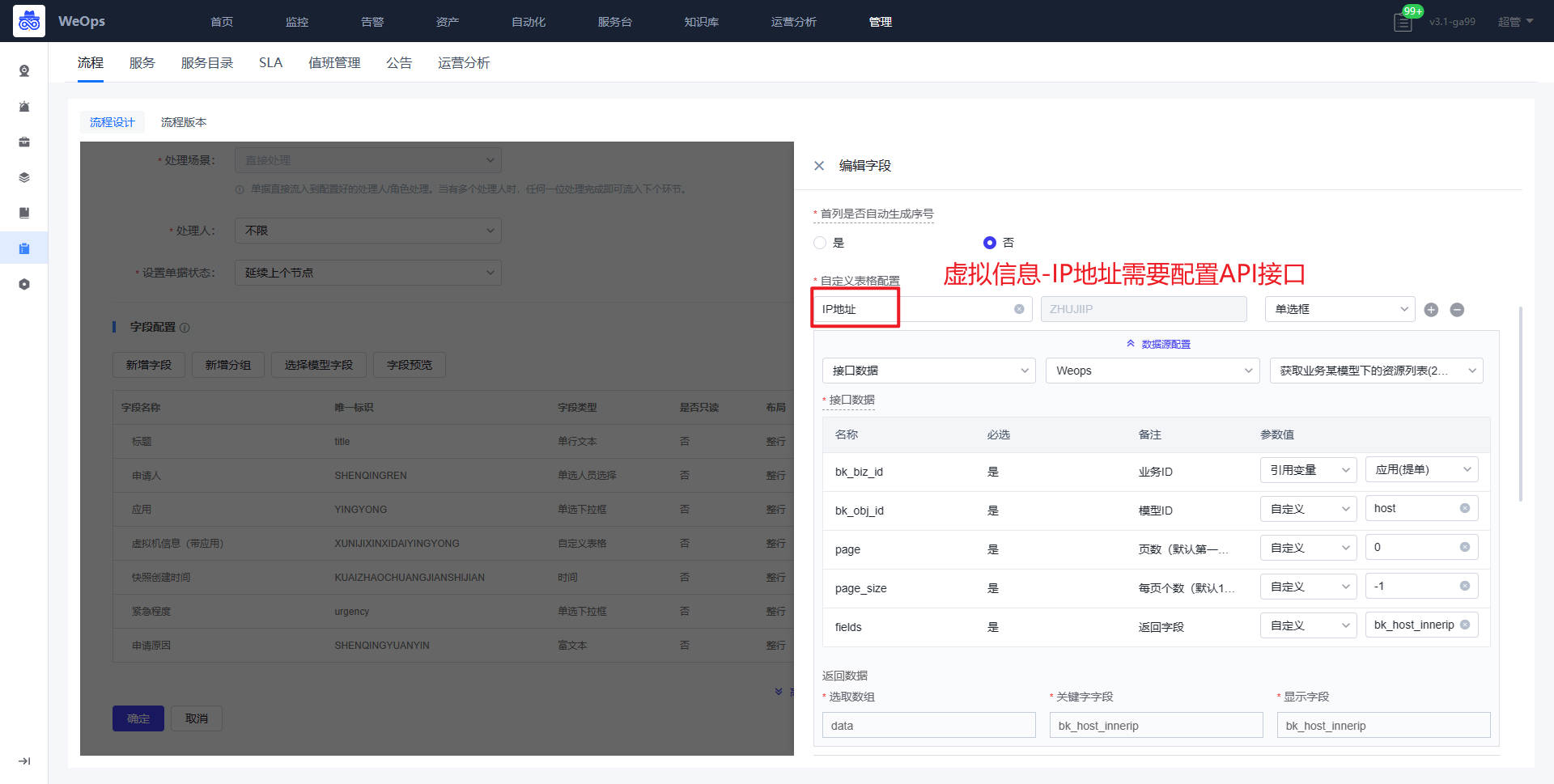
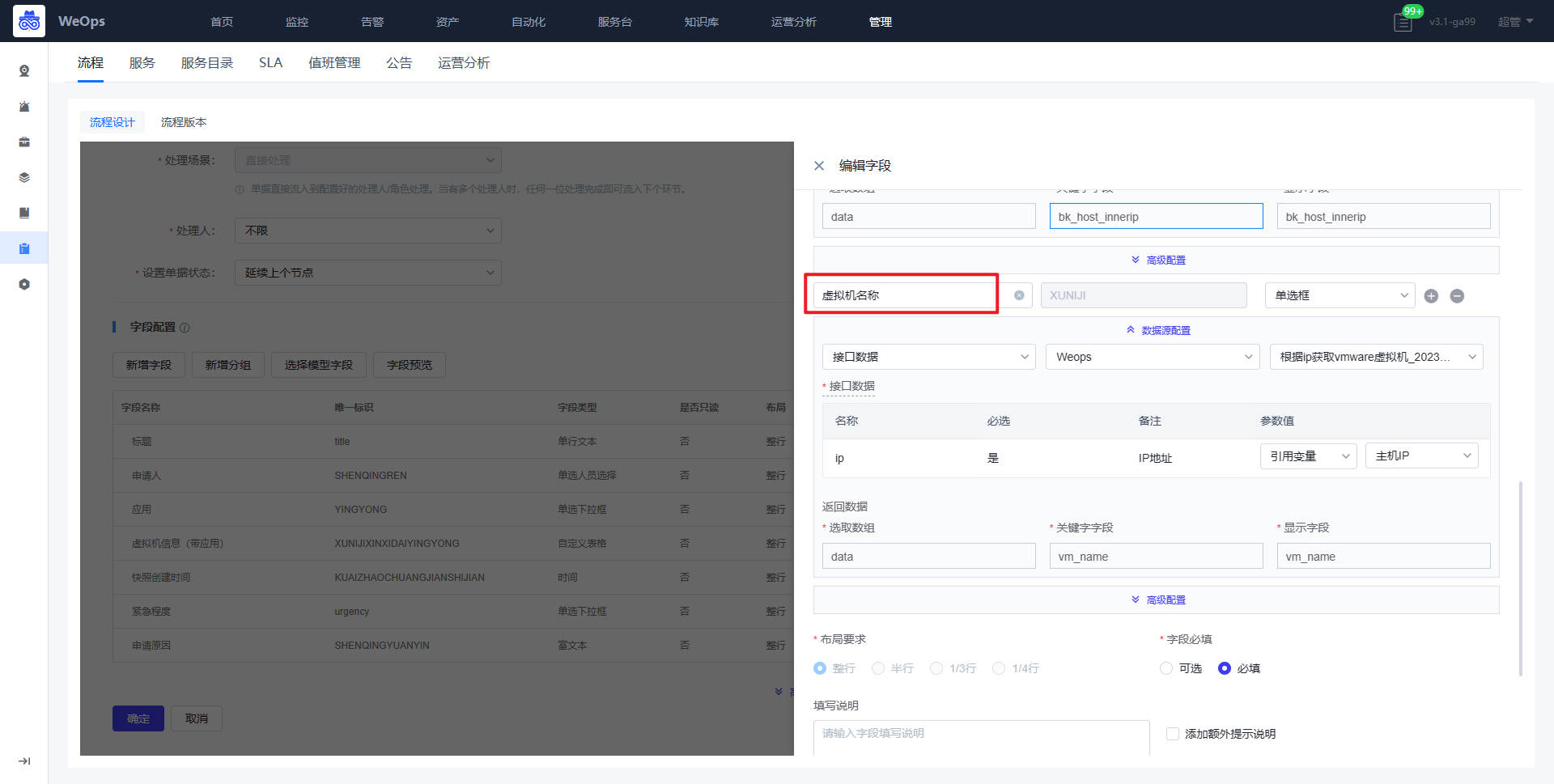
- 审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点,创建虚拟机的Vcenter以及其凭据,便于确定这个虚拟机创建的位置。(和虚拟机创建流程的配置方式一致)
- 审批节点:虚拟机信息中IP地址、虚拟机名称直接获取提单节点的信息,快照名称和描述为手填的,无需特殊配置。

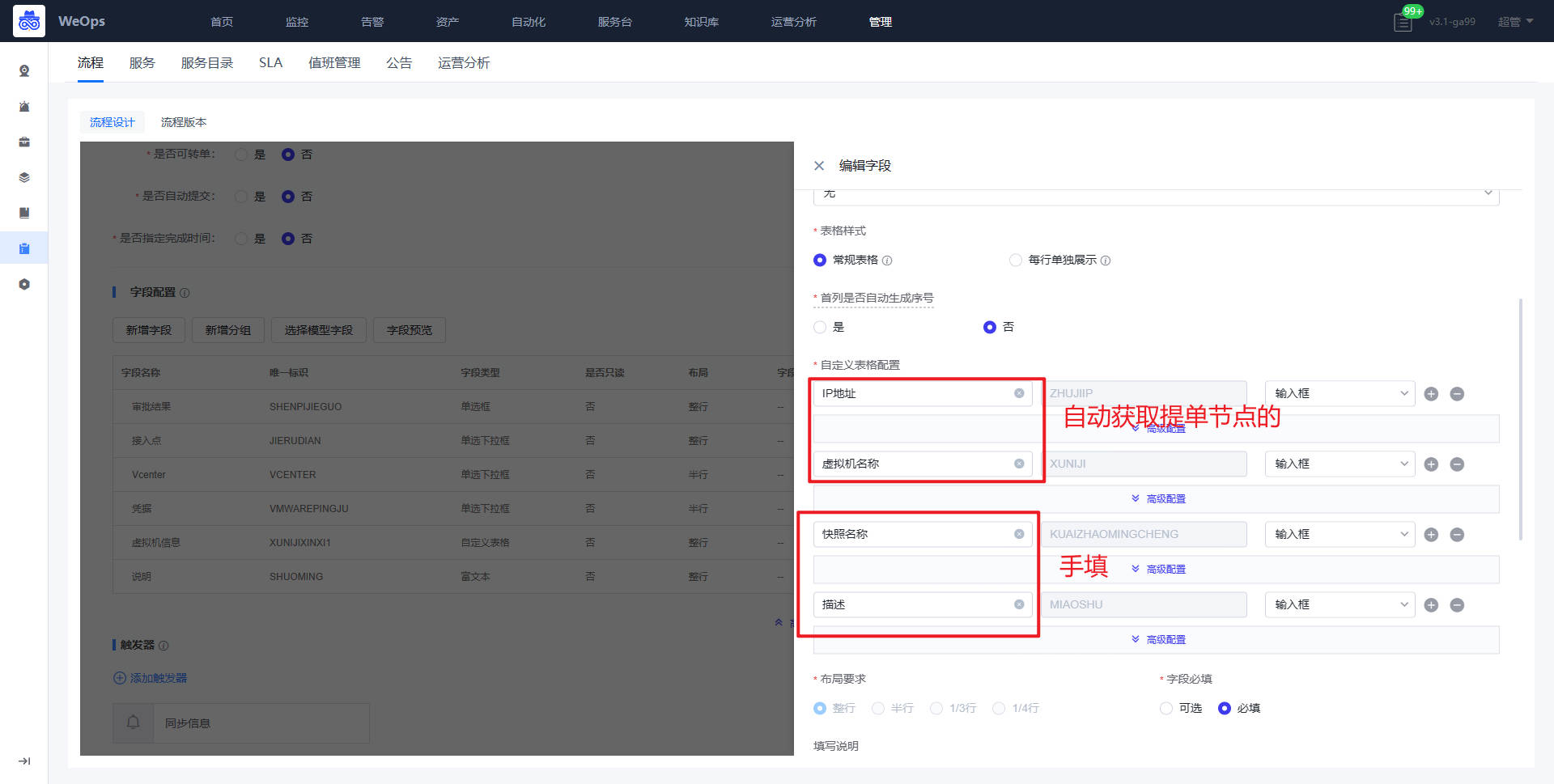
- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
- 自动执行节点:选择需要的自动流程,填写参数
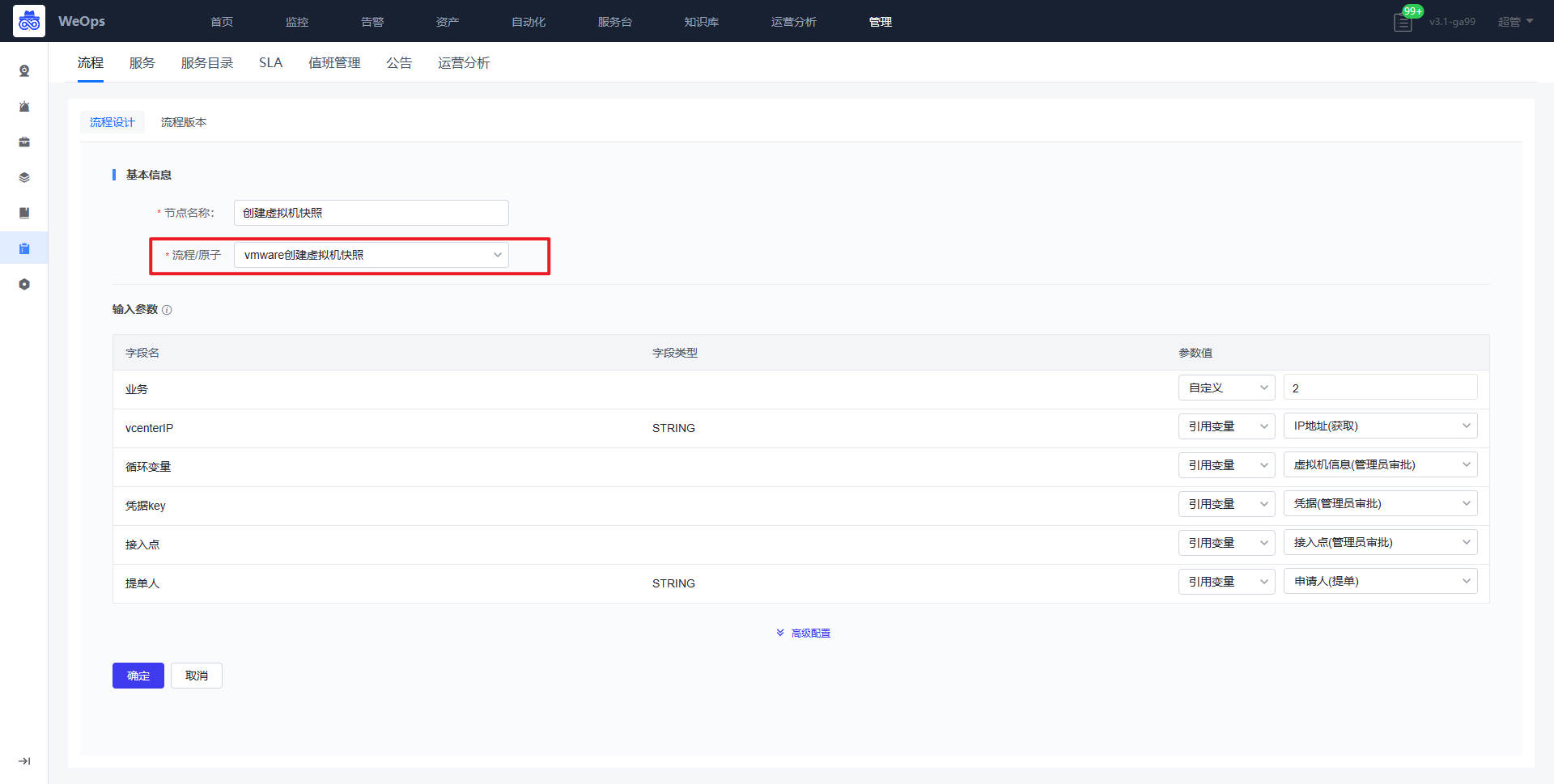
虚拟机快照回滚
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用、虚拟机信息(IP地址、虚拟机名称、快照名称)需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,可以展示该应用下的虚拟机IP列表和名称,便于提单人找下需要回滚的快照。

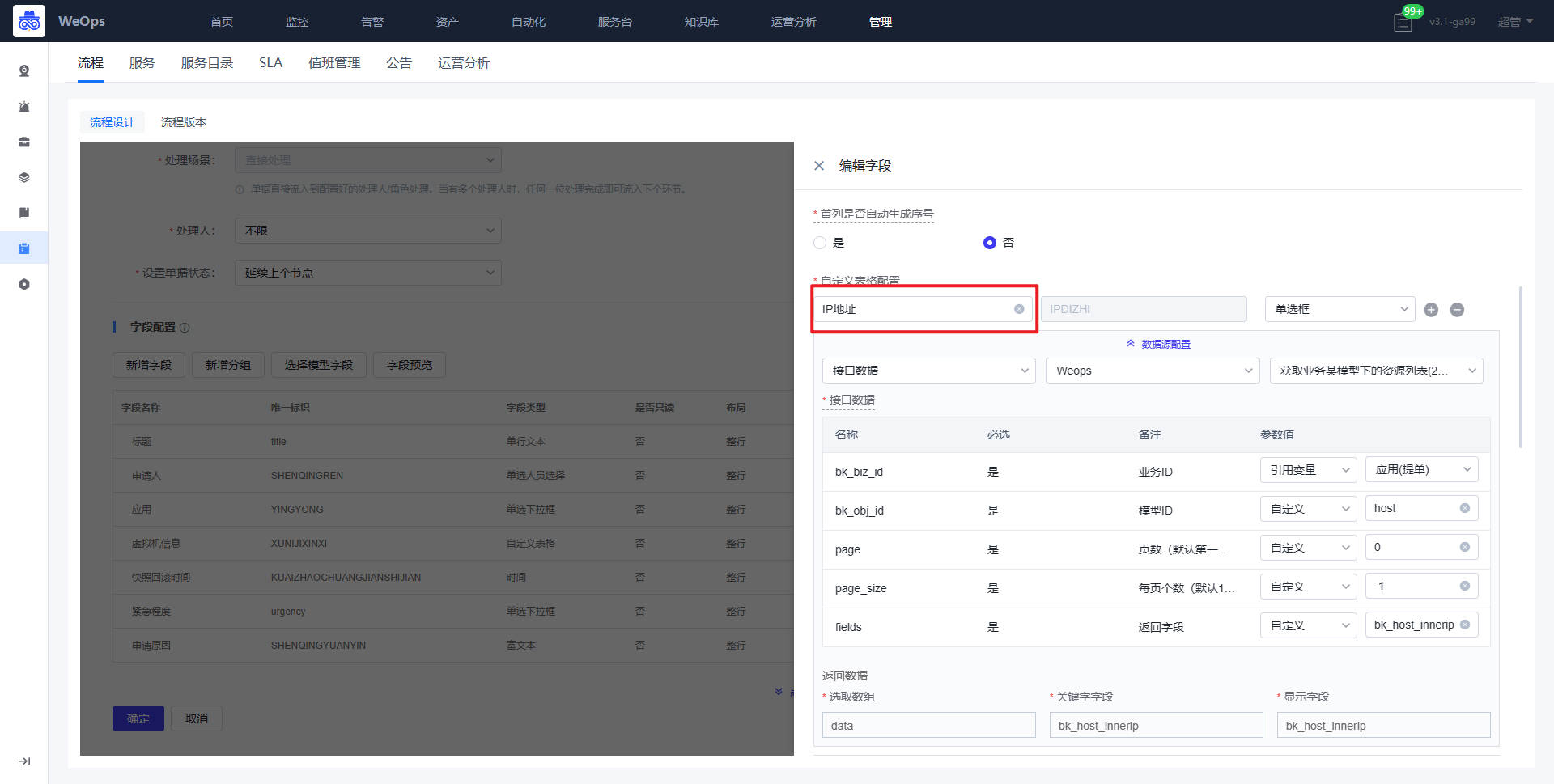
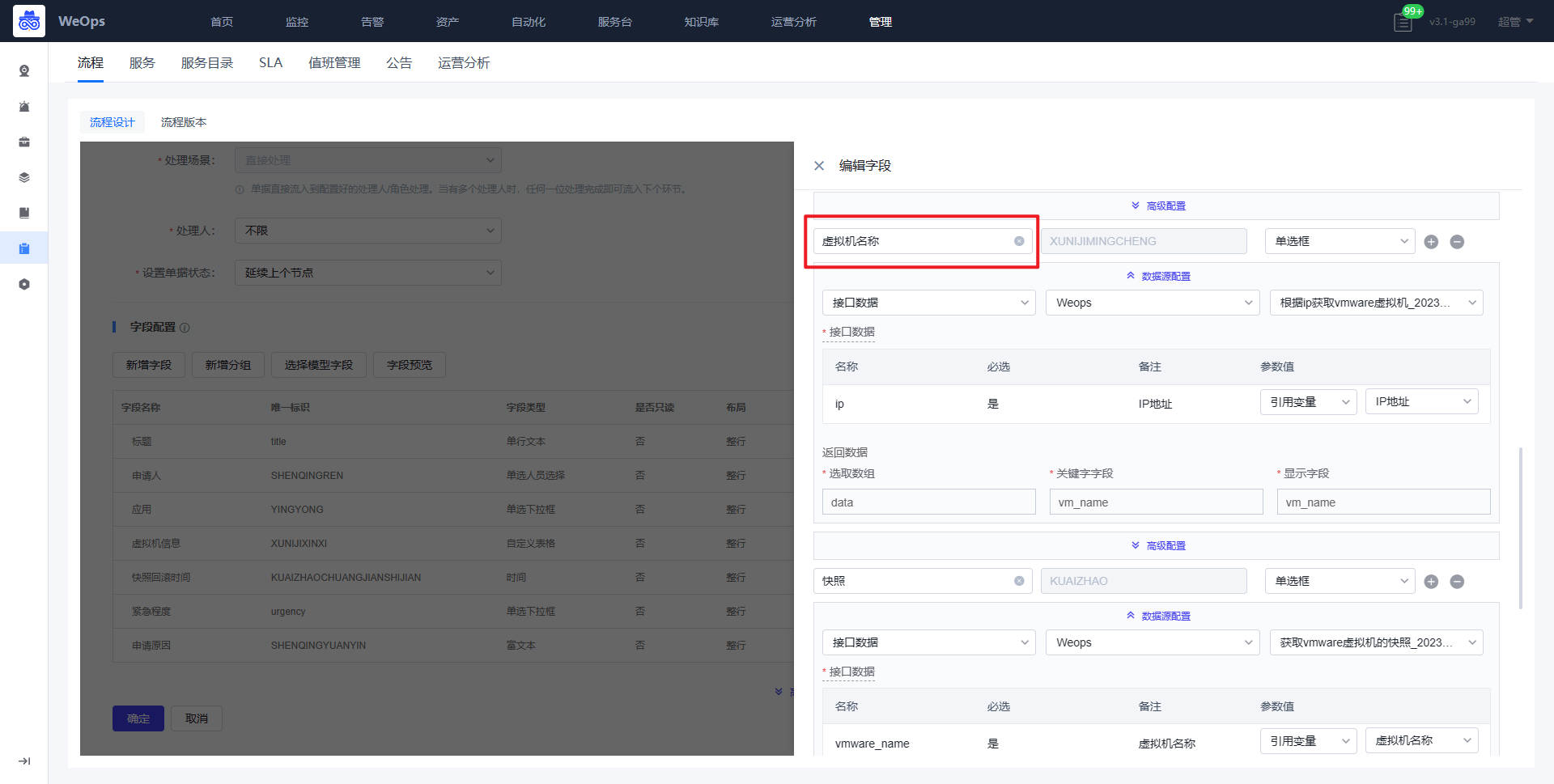

- 审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点和Vcenter以及其凭据,便于确定这个虚拟机的位置。(和虚拟机创建流程的API配置方式一致)
- 审批节点:虚拟机信息中IP地址、虚拟机名称、快照名称直接获取提单节点的信息,无需特殊配置。

- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
- 自动执行节点:选择需要的自动流程,填写参数

Step3:使用工单流程提单,进行虚拟机创建/快照创建/快照回滚
当流程配置好以后,可以进行提单操作(以虚拟机创建为例)
- 提单:用户提单时需要选择需要新建的虚拟机的配置信息,已经应用信息等,补充其他信息,进行提交。
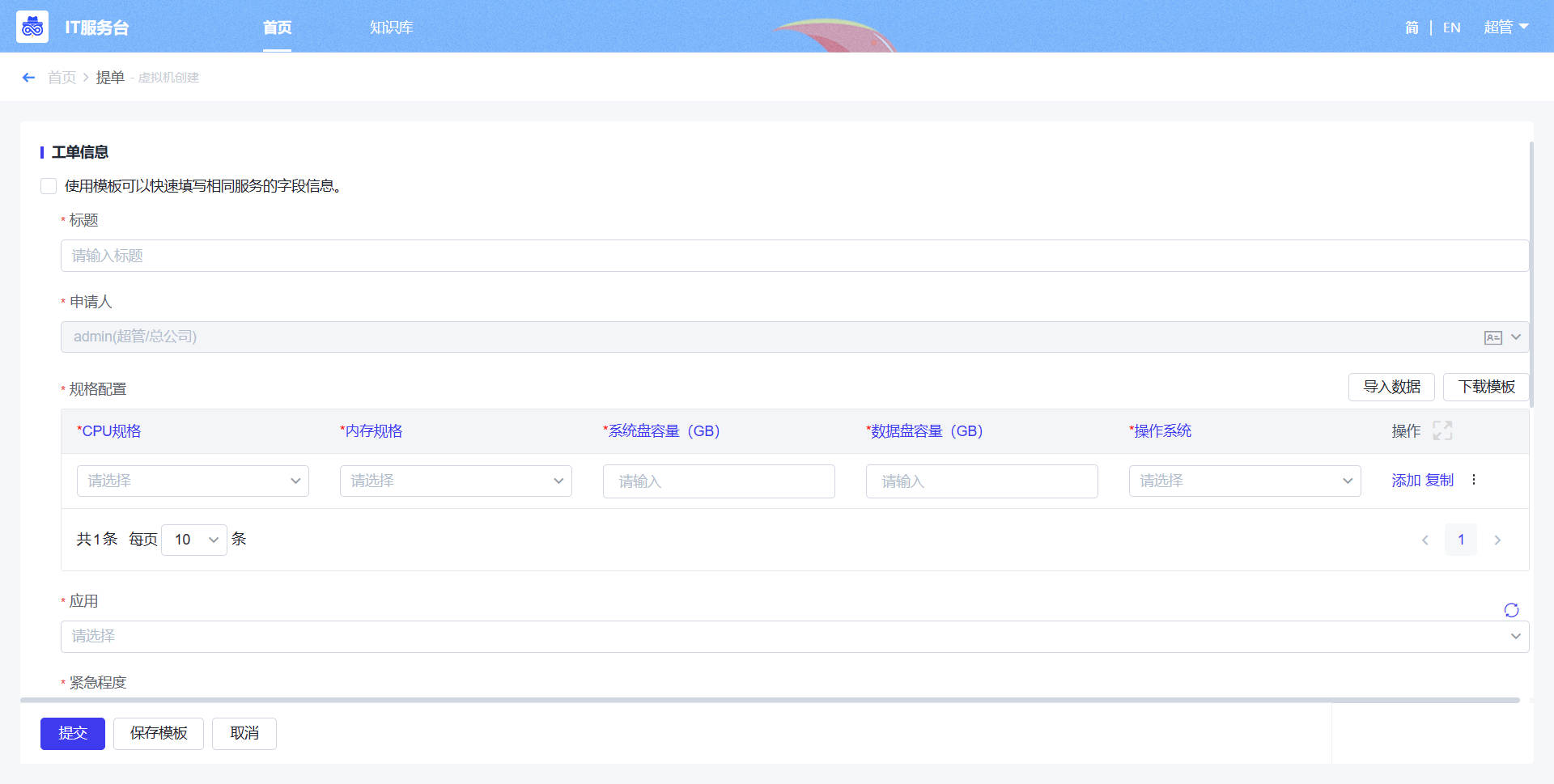
- 审批:管理员对提单人的申请信息进行审批,并选择对应的Vcenter,补齐虚拟机的相关配置信息后,提交进入到自动创建

- 自动执行:根据提单节点和审批节点填写的配置信息,进行自动的创建,创建完成之后,提单人会收到对应的通知。

场景九 如何利用工单进行资源变更,并记录在资产的“变更记录”中
场景介绍
Weops-工单支持自动化操作,包括资产自动创建/修改/删除等操作,通过工单进行的资产的变更,支持将变更情况和工单号记录在资产的“变更记录”中,支持查找和溯源。下面以“应用创建”为例进行介绍一下整个流程
场景实现
Step1:工单流程创建
- 根据实际的场景,设置好工单的提交/流转等配置,并在工单流转的过程中增加“API”节点,进行自动创建应用调用。
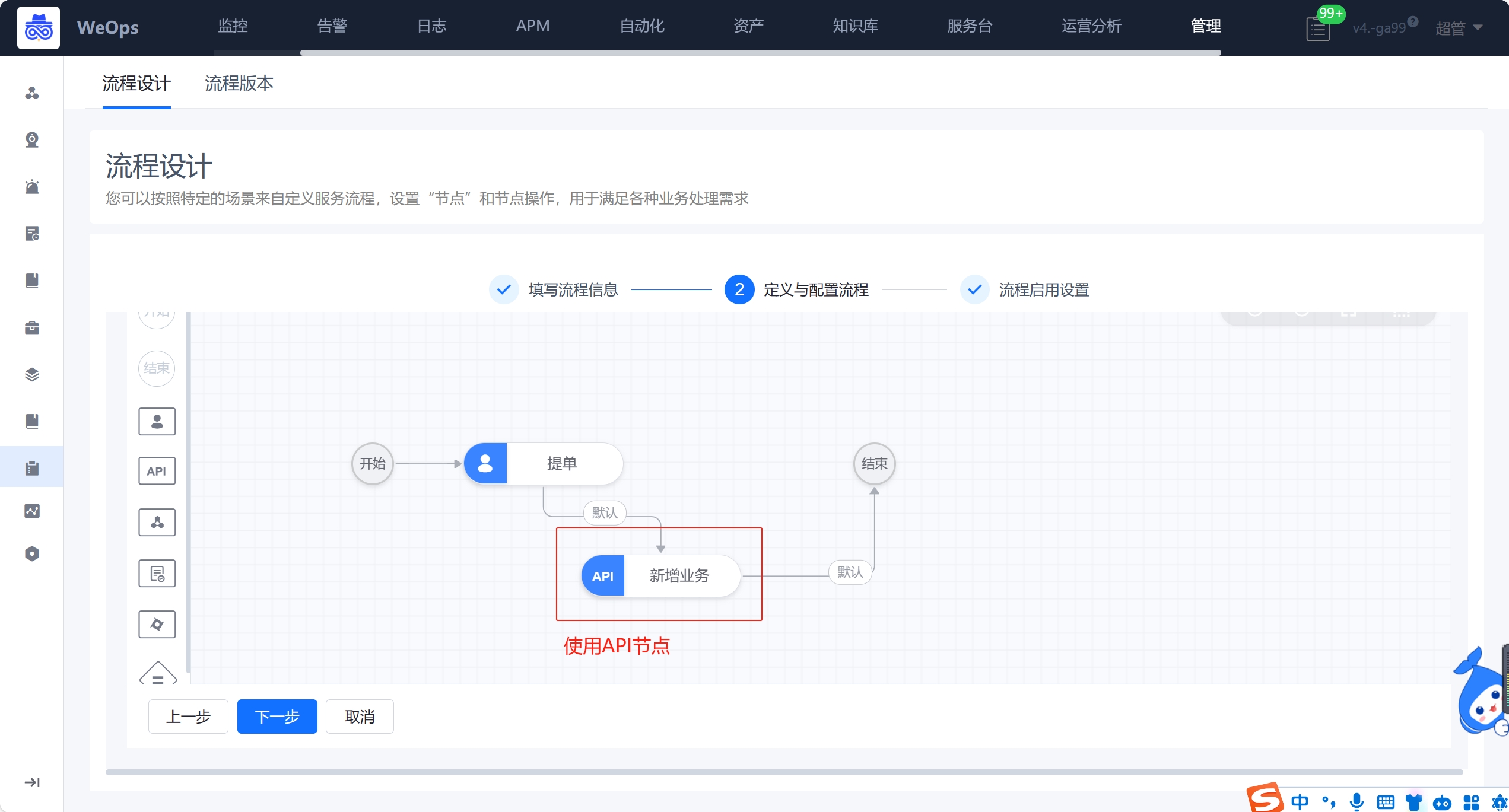
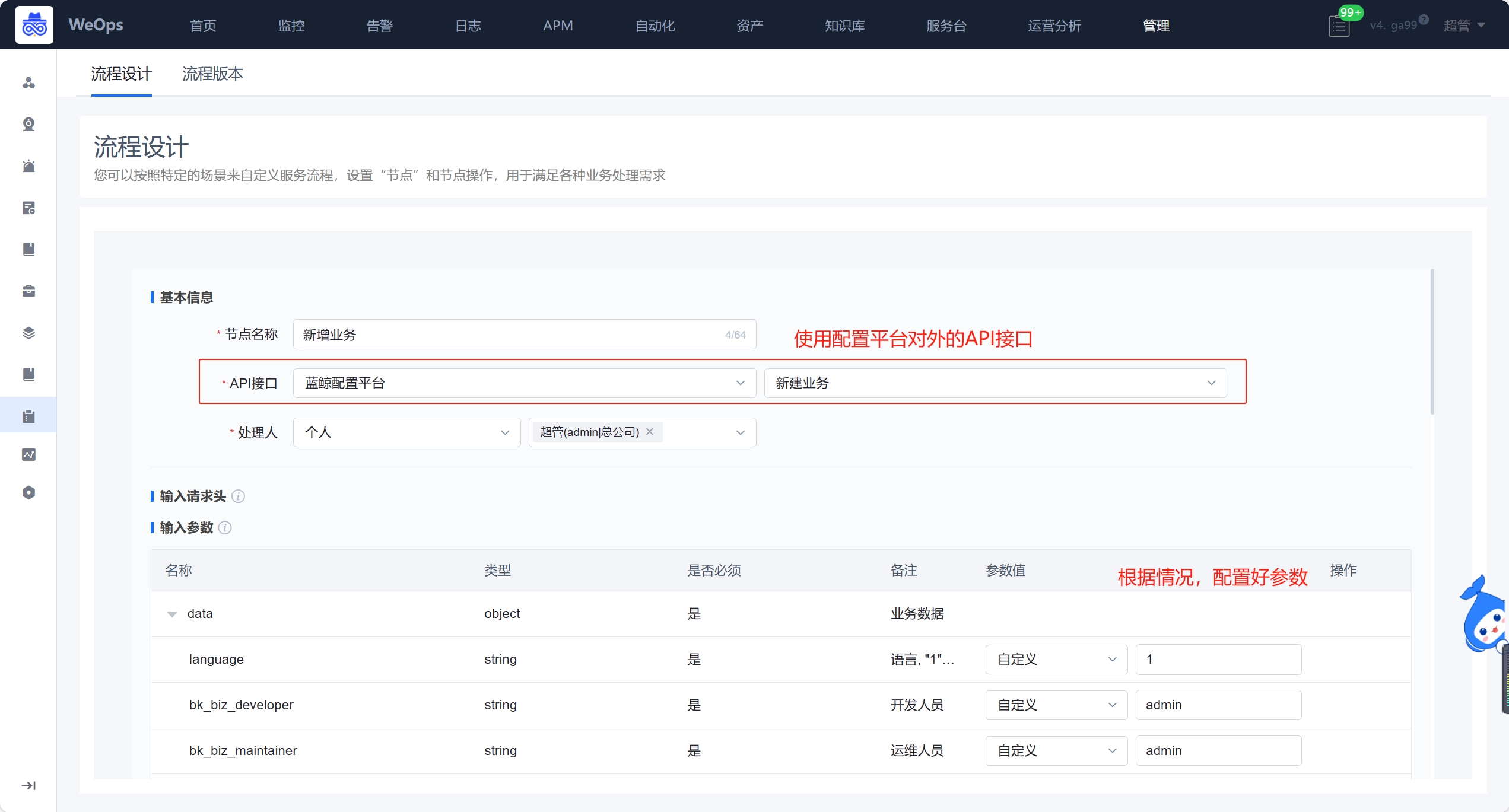
- 这里资产的相关API接口需要使用配置平台对外的接口。WeOps支持记录变更记录的接口如下图。
Step2:流程的提交和流转
流程和服务创建完成之后,按照正常的工单提交和审批流程进行流转。

Step3:自动记录在资产的变更记录
工单完成后,应用已经自动创建了,并且自动记录了变更的情况和关联的工单号
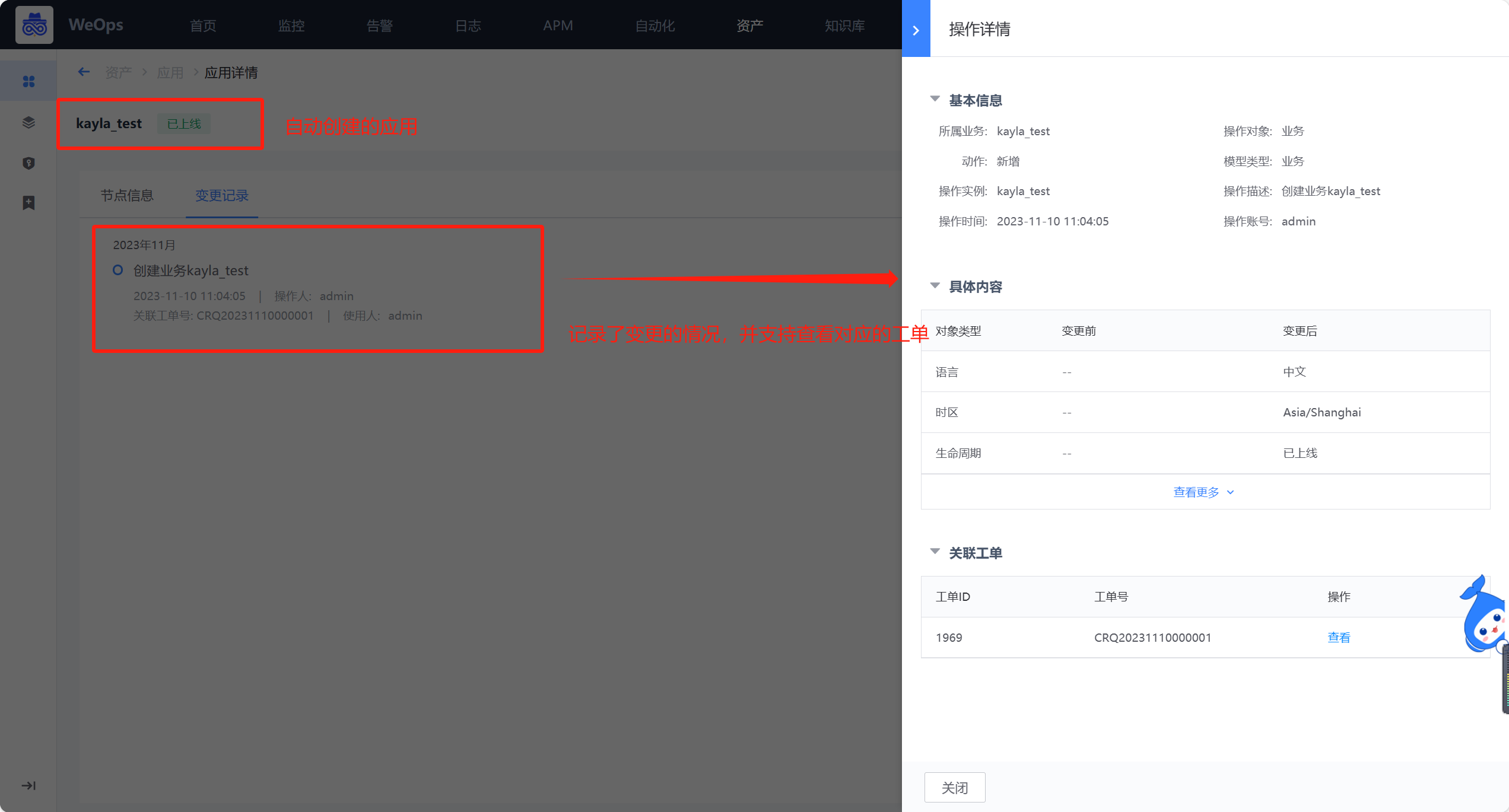
场景十 如何进行云平台监控/纳管的拓展
场景介绍
WeOps内置的云平台不满足需求,需要进行云平台的拓展,包括云平台的资产模型内置、自动发现能力、监控指标管理、监控采集能力等。
场景实现
Step1:云平台插件开发
该文档用于开发Automate的云平台插件,提供扩展云平台的能力,包含对新的云平台及云资产的采集和监控能力,同时结合weops的云平台模板对其进行采集纳管,监控,视图管理等。采用新版监控链路推送,稳定可观测。其中涉及与CMDB模型和关联关系,监控指标等关联,请详细阅读以下内容。
- 目录结构
cmp_plugins
├── README.md # 帮助文档
├── requirements.txt
└── templatecloud # 新的云平台目录
├── __init__.py
├── format # 格式转换目录
│ ├── __init__.py
│ ├── collect.py # 采集格式转换文件
│ └── credential.py # 凭据转换文件
└── resource_apis
├── __init__.py
└── cw_templatecloud.py # 核心插件文件,命名无要求如果需要新建一个云,可拷贝templatecloud目录,重命名为newcloud
Format
Collect 采集格式化
定义采集的字段,以及丰富字段能力.支持基础映射支持mako语法(更建议mako语法,功能更强大)
- 常用语法
from core.driver.cmp.collect import CMPCollectFormat
class NewCloudFormat(CMPCollectFormat):
code = "cmp_collect_newcloud" # 格式`cmp_collect_{newcloud}` 前缀必须固定,后缀使用cmdb模型分类id,否则会影响采集能力
type = "cmp_collect" # 无需修改
tag = "cmp.collect.fusion_insight" # 暂无意义,用于标记此云,可按格式`"cmp.collect.{newcloud}`
name = "XX云数据转换(cmp)" # 中文名
desc = "XX云数据转换(cmp)" # 详细描述
assoc_key = "resource_id" # 关联key,即云对象的唯一值,用于多对象构建关联使用
format_map = {}format_map支持单对象和多对象
- 单对象
format_map = {
"resource_name": "hostname",
"resource_id": "hostname",
"ip_addr": "ip",
"vcpus": "cpuCores",
"memory_mb": "totalMemory",
"storage_gb": "totalHardDiskSpace",
"status": "runningStatus",
"os_name": "osType",
"bk_inst_name": "${'%s-%s-%s'%(hostname,clusterName,account_name)}",
}tips:
- bk_inst_name必传,用来定义cmdb的唯一名,格式可使用mako语法自定义
- cmdb实例属性如设计为字符串,需使用mako手动转化,如
"${str(xx)}"否则纳管时会报类型错误 - 可以使用context传入的key,如account_name
- 多对象
assoc_key = "resource_id" # 关联key,即云对象的唯一值,用于多对象构建关联使用
format_map = {
"fusioninsight_cluster": {
"bk_inst_name": "${'%s-%s-%s'%(name,id,account_name)}",
"fusioninsight_account": "${account_name}",
"resource_name": "name",
"resource_id": "${str(id)}",
},
"fusioninsight_host": {
"resource_name": "hostname",
"resource_id": "hostname",
"ip_addr": "ip",
"vcpus": "cpuCores",
"memory_mb": "totalMemory",
"storage_gb": "totalHardDiskSpace",
"status": "runningStatus",
"os_name": "osType",
"bk_inst_name": "${'%s-%s-%s'%(hostname,clusterName,account_name)}",
"fusioninsight_cluster": "${fusioninsight_cluster_map[str(clusterId)]}"
}
}tips:
- 每个key均为cmdb模型ID,写错无法进行纳管
- assoc_key必须得有,value为其云资产的唯一值,用于寻找实例之间的关联
- 关联关系的构建需要定义对应key,否则无法对构建其关联关系,即每个对象与另一个对象只能构建一个关联,多个暂不支持如
"fusioninsight_account": "${account_name}"其值必须为关联关系对象的bk_inst_name"fusioninsight_cluster": "${fusioninsight_cluster_map[str(clusterId)]}" - 字典有顺序,即纳管CMDB资产逻辑顺序,务必从上至下进行编写
- 内置{bk_obj_id}_map,构建所有资产列表的map,便于下面的对象进行关联构建;格式为
{bk_obj_id}_map={assoc_key_value:bk_inst_name}用法可参考
> assoc_key_value即assoc_key定义的value
> bk_inst_name即关联的对象bk_obj_id的bk_inst_name"fusioninsight_cluster": "${fusioninsight_cluster_map[str(clusterId)]}" - 可以使用context传入的key,如account_name
Credential格式化
用于构建凭据到Driver层的映射,便于从vault中获取凭据后转换进入Driver层
from core.driver.cmp.credential import CMPCredentialFormat
class NewCloudFormat(CMPCredentialFormat):
code = "cmp_credential_newcloud" # 格式`cmp_credential_{newcloud}` 前缀必须固定,后缀使用cmdb模型分类,否则会影响凭据获取
type = "cmp_credential" # 无需修改
tag = "cmp.credential.newcloud" # 暂无意义,用于标记此云,可按格式`"cmp.credential.{newcloud}`
name = "XX云数据凭据转换(cmp)" # 中文名
desc = "XX云数据凭据转换(cmp)" # 详细描述
format_map = {"account": "username", "password": "password"}
tips:
- format_map的key是不能修改的,为Driver层的入参,value值分别对应vault管理中的账号和密码的key
# 账号密码型
format_map = {"account": "username", "password": "password"}
# ak/sk型
format_map = {"account": "ak", "password": "sk"}MakoFormat详细介绍
tips:
- 支持字典key映射,如
"resource_name": "resourceName" - 支持字典嵌套映射,如
"resource_name": "resourceName.xx" - 支持列表下标,如
"inner_ip": "resourceIp.0" - 支持mako语法引用变量,即
${key},如"bk_obj_id": "${vm_obj}" - 支持沙箱,可支持的语法较多
- 字符串拼接 语法:
${"prefix" + K EY}、${"prefix%s" % KEY}、${"prefix{}".format(KEY)}、${"%s%s" % (KEY1, KEY2)} - 字符串变换 语法:
${KEY.upper()}、${KEY.replace("\n", ",")}、${KEY[0:2]}、${KEY.strip()} - 数字运算 语法:
${int(KEY) + 1}、${int(KEY)/10} - 类型转换 语法:
${KEY.split("\n")}、${KEY.count()}、${list(KEY)}、${[item.strip() for item in KEY.split("\n")]} - 复杂类型取值 语法:
${KEY["a"]["b"]},${KEY[1][2]["a"]} - 支持的python内置函数
['abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip', '__import__', 'datetime', 're', 'hashlib', 'random', 'time', 'os'] - 字符串拼接 语法:
- 支持字段重写,入参item为此次迭代的字典,context为全局变量
- 单对象单key重写
get_{key} - 多对象单key重写
get_{bk_obj_id}_{key} - 统一重写
get
- 单对象单key重写
云平台API
目录:cmp_plugins/xxcloud/resource_apis/cw_xxcloud
类设计
包含2种类设计,如多个版本,可设计多个XXCloud
- CwXXCloud 》 云平台基础类,用于认证以及一些版本管理
- CwXXCloud务必添加
@register from cmp.cloud_apis.resource_client import register
@register
class CwTemplateCloud(object):
pass
- CwXXCloud务必添加
- XXCloud 》用于对接某版本各种增删改查API接口类,如查询虚机,查询所有资源,查询监控数据
list_vms虚拟机列表接口(单对象)list_hosts宿主机列表接口(单对象)- 返回格式
{
"result": true,
"data": [
{
"resource_id": "123",
"resource_name": "vm_test_1"
},
{
"resource_id": "456",
"resource_name": "vm_test_1"
}
]
}
- 返回格式
list_hosts宿主机列表接口(单对象)list_xxs其他实例列表接口(单对象)list_all_resouces获取所有资源(多对象)- 返回格式
{
"result": true,
"data": {
"template_vms": [ # template_vms为某云虚拟机的bk_obj_id
{
"resource_id": "123",
"resource_name": "vm_test_1"
},
{
"resource_id": "456",
"resource_name": "vm_test_1"
}
],
"template_ds": [ # template_ds为某云存储的bk_obj_id
{
"resource_id": "123",
"resource_name": "ds_test_1"
},
{
"resource_id": "456",
"resource_name": "ds_test_1"
}
]
}
}get_weops_monitor_data获取监控数据- 入参kwargs
- context格式
{
"resource":[
{
"bk_obj_id": "qcloud_cvm",
"bk_inst_id": 111,
"resource_id": "ins-qnopai6m",
"bk_inst_name": "深信服",
"bk_biz_id": 2
},
{
"bk_obj_id": "qcloud_cvm",
"bk_inst_id": 222,
"resource_id": "ins-0g4ehetc",
"bk_inst_name": "autopack",
"bk_biz_id": 2
}
]
}- 无维度返回格式
{'result': True, 'data':
{'MRS-MN-02':
{
'cpuUsage': [(1689585060000, 4.0)],
'memoryUsedRatio': [(1689585060000, 0.11)]
},
'MRS-MN-01':
{'cpuUsage': [(1689585060000, 2.0)],
'memoryUsedRatio': [(1689585060000, 0.04)]
}
}
}- 有维度返回格式
{'result': True, 'data':
{'MRS-MN-02':
{'freeSpace':
{
(('mountPoint', '/'),): [(1689585060000, 14.66)],
(('mountPoint', '/boot'),): [(1689585060000, 4.85)],
}
}
}
}- data数据内部介绍第一层为云实例id,如
MRS-MN-02第二层为监控指标key,如freeSpace第三层 如无维度,则value为时间戳与值的元组列表 如有维度,第三层为 key为维度key和value的嵌套元组,支持多维度,每个维度为一个元组 value为时间戳与值的元组列表 单维度(('mountPoint', '/'),): [(1689585060000, 14.66)] 多维度(('mountPoint', '/'),('xx','1')): [(1689585060000, 14.66)]
依赖
- requirements.txt填写额外依赖包,如xxsdk等
- 该版本暂不支持依赖包的直接引入,可重新生成docker镜像构建。
Step2:云平台插件开发
该文档旨在编写云平台资源,凭据,监控模板数据,用于weops平台-系统设置-插件管理-导入云平台模板文件。
- 请按顺序依次导入,资产》凭据》监控
- 导入后,请确认云平台各个菜单栏是否多出一个tab,名称为模型分类名称
- 导入资源配置后,请确认模型是否生成,模型字段是否正常
- 导入凭据配置后,请确认凭据管理处是否正常创建编辑
- 导入监控配置后,请确认监控管理的指标管理中指标是否正常
- 如上述操作出现异常请求,请排查celery.log日志确认问题根因,并检查模板文件是否编写错误。
模型配置
字段说明
| 字段 | 类型 | 描述 |
|---|---|---|
| classification | dict | 模型分类信息 |
| objects | list | 模型分类下的模型列表 |
| associations | list | 模型列表中模型之间的关联关系 |
| cannula_rules | list | 模型实例纳管规则,按照列表顺序纳管 |
- classification:
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_classification_id | str | 模型分类ID |
| bk_classification_name | str | 模型分类名称 |
- objects:
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_obj_id | str | 模型ID |
| bk_obj_name | str | 模型名称 |
| bk_obj_icon | str | 模型图标,默认icon-cc-default |
| attrs | list | 模型属性列表 |
- objects.attrs:
注意:attrs中必须有属性resource_id,对应云平台资产唯一ID。
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_property_id | str | 属性ID |
| bk_property_name | str | 属性名称 |
| bk_property_type | str | 属性类型 |
| unit | str | 属性单位 |
| placeholder | str | 占位符 |
| editable | bool | 是否可编辑 |
| isrequired | bool | 是否必填 |
| option | str | 枚举内容 |
- associations:
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_obj_id | str | 源模型ID |
| bk_asst_obj_id | str | 目标模型ID |
| bk_asst_id | str | 关联 |
| bk_obj_asst_id | str | 源模型与目标模型的关联关系ID |
| bk_obj_asst_name | str | 源模型与目标模型的关联关系名称 |
| mapping | str | 模型对应关系 |
- cannula_rules:
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_obj_id | str | 纳管模型ID |
| associations | list | 纳管模型关联列表 |
- cannula_rules.associations:
| 字段 | 类型 | 描述 |
|---|---|---|
| bk_asst_obj_id | str | 目标模型ID |
| bk_obj_asst_id | str | 源模型与目标模型的关联关系ID |
模板
{
"classification": {
"bk_classification_id": "FusionInsight",
"bk_classification_name": "FusionInsight"
},
"objects": [
{
"bk_obj_id": "fusioninsight_account",
"bk_obj_name": "FusionInsight平台",
"bk_obj_icon": "icon-cc-default",
"attrs": [
{
"bk_property_name": "资产编码",
"bk_property_id": "asset_code",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
}
]
},
{
"bk_obj_id": "fusioninsight_cluster",
"bk_obj_name": "FusionInsight集群",
"bk_obj_icon": "icon-cc-default",
"attrs": [
{
"bk_property_name": "资产编码",
"bk_property_id": "asset_code",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "资源ID",
"bk_property_id": "resource_id",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "资源名称",
"bk_property_id": "resource_name",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "是否自动发现",
"bk_property_id": "auto_collect",
"unit": "",
"placeholder": "",
"bk_property_type": "bool",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "上次更新时间",
"bk_property_id": "collect_time",
"unit": "",
"placeholder": "",
"bk_property_type": "time",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "接入点",
"bk_property_id": "access_point",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
}
]
},
{
"bk_obj_id": "fusioninsight_host",
"bk_obj_name": "FusionInsight主机",
"bk_obj_icon": "icon-cc-default",
"attrs": [
{
"bk_property_name": "资产编码",
"bk_property_id": "asset_code",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "资源ID",
"bk_property_id": "resource_id",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "资源名称",
"bk_property_id": "resource_name",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "是否自动发现",
"bk_property_id": "auto_collect",
"unit": "",
"placeholder": "",
"bk_property_type": "bool",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "上次更新时间",
"bk_property_id": "collect_time",
"unit": "",
"placeholder": "",
"bk_property_type": "time",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "接入点",
"bk_property_id": "access_point",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "内网IP",
"bk_property_id": "ip_addr",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "vCPU数",
"bk_property_id": "vcpus",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "内存容量(MB)",
"bk_property_id": "memory_mb",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "磁盘容量(GB)",
"bk_property_id": "storage_gb",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "状态",
"bk_property_id": "status",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
},
{
"bk_property_name": "操作系统名称",
"bk_property_id": "os_name",
"unit": "",
"placeholder": "",
"bk_property_type": "singlechar",
"editable": true,
"isrequired": false,
"option": ""
}
]
}
],
"associations": [
{
"bk_obj_asst_id": "fusioninsight_account_group_set",
"bk_obj_asst_name": "",
"bk_obj_id": "fusioninsight_account",
"bk_asst_obj_id": "set",
"bk_asst_id": "group",
"mapping": "n:n"
},
{
"bk_obj_asst_id": "fusioninsight_cluster_group_module",
"bk_obj_asst_name": "",
"bk_obj_id": "fusioninsight_cluster",
"bk_asst_obj_id": "module",
"bk_asst_id": "group",
"mapping": "n:n"
},
{
"bk_obj_asst_id": "fusioninsight_cluster_belong_fusioninsight_account",
"bk_obj_asst_name": "",
"bk_obj_id": "fusioninsight_cluster",
"bk_asst_obj_id": "fusioninsight_account",
"bk_asst_id": "belong",
"mapping": "n:n"
},
{
"bk_obj_asst_id": "fusioninsight_host_group_module",
"bk_obj_asst_name": "",
"bk_obj_id": "fusioninsight_host",
"bk_asst_obj_id": "module",
"bk_asst_id": "group",
"mapping": "n:n"
},
{
"bk_obj_asst_id": "fusioninsight_host_belong_fusioninsight_cluster",
"bk_obj_asst_name": "",
"bk_obj_id": "fusioninsight_host",
"bk_asst_obj_id": "fusioninsight_cluster",
"bk_asst_id": "belong",
"mapping": "n:n"
}
],
"cannula_rules": [
{
"bk_obj_id": "fusioninsight_cluster",
"associations": [
{
"bk_asst_obj_id": "fusioninsight_account",
"bk_obj_asst_id": "fusioninsight_cluster_belong_fusioninsight_account"
}
]
},
{
"bk_obj_id": "fusioninsight_host",
"associations": [
{
"bk_asst_obj_id": "fusioninsight_cluster",
"bk_obj_asst_id": "fusioninsight_host_belong_fusioninsight_cluster"
}
]
}
]
}{
"cannula_rules": [
{
"bk_obj_id": "fusioninsight_cluster",
"associations": [
{
"bk_asst_obj_id": "fusioninsight_account",
"bk_obj_asst_id": "fusioninsight_cluster_belong_fusioninsight_account"
}
]
},
{
"bk_obj_id": "fusioninsight_host",
"associations": [
{
"bk_asst_obj_id": "fusioninsight_cluster",
"bk_obj_asst_id": "fusioninsight_host_belong_fusioninsight_cluster"
}
]
}
]
}凭据
字段说明
parmas: 凭据表单字段
-key 凭据id
-name 凭据名称
-value 默认值
-type 数据类型
-per_key 父类key
-pre_value 父类的value
-display 数值是不是展示
-placeholder 提示语
bk_obj_id:唯一id,采集对象是单对象时就是采集对象的bk_obj_id,多对象时是采集对象的cmdb模型分类id
name: cmdb模型分类id
cn_name:cmdb模型分类中文名
account_obj_id: cmdb账号模型id
account_name: cmdb账号模型账号名称
regions: 是否需要选择区域
config:配置
-module 采集函数
-driver driver类型 目前有ansible和cloud
-type 采集类型 目前有ansible和cloud模版
{
"params": [{
"key": "username",
"name": "用户名",
"type": "string",
"value": "",
"display": true,
"options": [],
"pre_value": "",
"pre_select": "",
"placeholder": ""
}, {
"key": "password",
"name": "密码",
"type": "password",
"value": "",
"display": false,
"options": [],
"pre_key": "",
"pre_value": "",
"placeholder": "root"
}],
"name": "FusionInsight",
"cn_name": "FusionInsight",
"account_obj_id":"fusioninsight_account",
"account_name":"FusionInsight平台",
"bk_obj_id":"fusioninsight_host",
"regions":false,
"config": {
"module": "list_all_resources",
"driver": "cloud",
"type": "cloud"
}
}监控
字段说明
cn_name: cmdb模型分类名称
name: cmdb模型分类id
account_obj_id: cmdb账号模型id
account_name: cmdb账号模型账号名称
children: 监控指标模型数组
-bk_obj_id cmdb模型id
-bk_obj_name cmdb模型名称
-bk_classification_id cmdb模型分类id
metrics: 指标数组
-unit_id
-field_type 指标数组类型
-metric 指标英文名称
-name 指标中文名称
-unit 单位
-unit_suffix_id 单位ID
-tag 指标类型,只能是metric(指标)和dimension(维度)
-unit_suffix_list 单位列表
-id 单位id
-name 单位名称
如存在以下3个指标,CPU使用率(CpuUseRate),内存使用率(MemoryUseRate),磁盘使用率(VolumeRate),务必使用括号中的英文KEY作为metric字段,方便weops列表页面展示模板
{
"cn_name": "FusionInsight",
"name": "FusionInsight",
"account_obj_id": "fusioninsight_account",
"account_name": "FusionInsight平台",
"children": [{
"bk_obj_id": "fusioninsight_cluster",
"bk_obj_name": "FusionInsight集群",
"bk_classification_id": "FusionInsight",
"metrics": []
}, {
"bk_obj_id": "fusioninsight_host",
"bk_obj_name": "FusionInsight主机",
"bk_classification_id": "FusionInsight",
"metrics": [
{
"unit_id": "percent",
"field_type": "float",
"metric": "cpuUsage",
"name": "CPU使用率",
"unit": "percent",
"unit_suffix_id": "%",
"tag":"metric",
"unit_suffix_list": [{
"id": "%",
"name": "%"
}]
},
{
"unit_id": "M",
"field_type": "float",
"metric": "availableMemory",
"name": "空闲内存",
"unit": "M",
"tag":"metric",
"unit_suffix_id": "M",
"unit_suffix_list": [{
"id": "M",
"name": "MB"
}]
},
{
"unit_id": "percent",
"field_type": "float",
"metric": "memoryUsedRatio",
"name": "内存使用率",
"unit": "percent",
"tag":"metric",
"unit_suffix_id": "%",
"unit_suffix_list": [{
"id": "%",
"name": "%"
}]
},
{
"unit_id": "percent",
"field_type": "float",
"metric": "hardDiskSpaceUsedRatio",
"name": "磁盘空间使用率",
"unit": "percent",
"tag":"metric",
"unit_suffix_id": "%",
"unit_suffix_list": [{
"id": "%",
"name": "%"
}]
},
{
"unit_id": "G",
"field_type": "float",
"metric": "freeSpace",
"name": "磁盘分区剩余容量",
"unit": "G",
"tag":"metric",
"unit_suffix_id": "G",
"unit_suffix_list": [{
"id": "G",
"name": "GB"
}]
}
]
}]
}纳管对象
操作系统
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 操作系统 | Windows Server | 2008R2/2012/2012R2/2016/2019 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | 1、内置健康扫描包1项(基础健康检查-Windows) 2、内置运维脚本工具4项(适用于Windows系统) |
| 操作系统 | linux | RHEL 6.x/7.x/8.x | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | 1、内置健康扫描包1项(基础健康检查-Linux) 2、内置运维脚本工具7项(适用于Linux系统) |
| 操作系统 | linux | CentOS 5.x/6.x/7.x(已知不支持CentOS5的32位版本 ) | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | 1、内置健康扫描包1项(基础健康检查-Linux) 2、内置运维脚本工具7项(适用于Linux系统) |
| 操作系统 | linux | Suse 11/12(已知不支持Suse的32位版本) | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | 1、内置健康扫描包1项(基础健康检查-Linux) 2、内置运维脚本工具7项(适用于Linux系统) |
| 操作系统 | linux | Ubuntu 10.04/12.04/14.04/18.04/20.04 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | 1、内置健康扫描包1项(基础健康检查-Linux) 2、内置运维脚本工具7项(适用于Linux系统) |
| 操作系统 | linux | Fedora ≥12 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | linux | Debian ≥7.4 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | linux | OpenAnolis ≥7 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) | |
| 操作系统 | linux | openEuler ≥20.03 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | AIX | AIX 6/7系列 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | 银河麒麟 V10 | x86 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | openEuler | 20.03 LTS SP3 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s | |
| 操作系统 | 统信 UOS | >= v20 | 1、已内置资源模型 | 1、使用Agent采集监控数据,无需监控插件 2、内置关键指标10项 3、内置监控策略10项 4、内置监控仪表盘2张(单主机运行状态仪表盘、应用主机运行状态) 5、最小监控采集频率 10s |
云平台
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 云平台 | VMware | vCenter 6.5/6.7/7.0 | 1、已内置资源模型 2、支持自动发现/采集ESXI、虚拟机和数据存储 | 1、内置监控指标 2、最小监控采集频率 1min | 1、内置健康扫描包2项(基础健康检查- vCenter(Windows)、基础健康检查- vCenter(Linux)) |
| 云平台 | 腾讯云 | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | ||
| 云平台 | 阿里云 | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | ||
| 云平台 | 华为云 | ManageOne 8.2.0 | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | 华为云 | 华为公有云 | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | 深信服超融合 | 6.3.03R | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | 华为云 | 华为FusionInsight | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | NutanixHCI | NutanixHCI | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | ManageOne | ManageOne | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | |
| 云平台 | OPenStack | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | ||
| 云平台 | SmartX | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min | ||
| 云平台 | AWS | 1、已内置资源模型 2、支持自动发现/采集云服务器 | 1、内置监控指标 2、最小监控采集频率 1min |
说明:Vcenter采集“磁盘使用率“的指标需要安装vmware tools,并有如下的版本要求
| vCenter 8 | vCenter 7 | vCenter 6.7 | vCenter 6.5 | |
|---|---|---|---|---|
| Windows Server 2022 | 支持 | 支持 | 支持 | 不支持 |
| Windows Server 2019 (a) | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2016 (a) | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2012 R2 | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2012 | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2008 R2 | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2008 (o) | 支持 | 支持 | 支持 | 支持 |
| Windows Server 2003 R2 | 不支持 | 不支持 | 不支持 | 支持 |
| Windows Server 2003 (b) | 不支持 | 不支持 | 不支持 | 支持 |
| Windows 11 | 支持 | 支持 | 支持 | 不支持 |
| Windows 10 | 支持 | 支持 | 支持 | 支持 |
| Windows 8.1 | 支持 | 支持 | 支持 | 支持 |
| Windows 8 | 支持 | 支持 | 支持 | 支持 |
| Windows 7 | 支持 | 支持 | 支持 | 支持 |
| Windows Vista (o) | 支持 | 支持 | 支持 | 支持 |
| Windows XP (b) | 不支持 | 不支持 | 不支持 | 支持 |
| Red Hat Enterprise Linux 9.x (j) | 支持 | 支持 | 支持 | 不支持 |
| Red Hat Enterprise Linux 8.x | 支持 | 支持 | 支持 | 支持 |
| Red Hat Enterprise Linux 7.x | 支持 | 支持 | 支持 | 支持 |
| Red Hat Enterprise Linux 6.x | 支持 | 支持 | 支持 | 支持 |
| Red Hat Enterprise Linux 5.x | 支持 | 支持 | 支持 | 支持 |
| Red Hat Enterprise Linux 4.x | 不支持 | 不支持 | 不支持 | 支持 |
| CentOS 8.x | 支持 | 支持 | 支持 | 支持 |
| CentOS 7.x | 支持 | 支持 | 支持 | 支持 |
| CentOS 6.x | 支持 | 支持 | 支持 | 支持 |
| CentOS 5.x | 支持 | 支持 | 支持 | 支持 |
| Oracle Linux 9.x (j) | 支持 | 支持 | 不支持 | 不支持 |
| Oracle Linux 8.x | 支持 | 支持 | 支持 | 不支持 |
| Oracle Linux 7.x | 支持 | 支持 | 支持 | 支持 |
| Oracle Linux 6.x | 支持 | 支持 | 支持 | 支持 |
| Oracle Linux 5.x | 支持 | 支持 | 支持 | 支持 |
| Miracle Linux 8.x (l) | 不支持 | 支持 | 支持 | 不支持 |
| AlmaLinux OS 9.x (k) | 支持 | 支持 | 不支持 | 不支持 |
| AlmaLinux OS 8.x (g) | 支持 | 支持 | 支持 | 不支持 |
| Rocky Linux 9.x (m) | 支持 | 支持 | 不支持 | 不支持 |
| Rocky Linux 8.x (h) | 支持 | 支持 | 支持 | 不支持 |
| Debian 12.x | 支持 | 不支持 | 不支持 | 不支持 |
| Debian 11.x (i) | 支持 | 支持 | 不支持 | 不支持 |
| Debian 10.1x (i) | 支持 | 支持 | 不支持 | 不支持 |
| SLES 15 SP1-SP5 (c) | 支持 | 支持 | 支持 | 支持 |
| SLES 15 SP0 (c) | 支持 | 支持 | 支持 | 支持 |
| SLES 12 SP2-SP5 (c) | 支持 | 支持 | 支持 | 支持 |
| SLES 12 SP0-SP1 | 支持 | 支持 | 支持 | 支持 |
| SLES 11 SP3-SP4 | 支持 | 支持 | 支持 | 支持 |
| SLES 10 SP4 | 支持 | 支持 | 支持 | 支持 |
| Ubuntu 23.10 (n) | 支持 | 不支持 | 不支持 | 不支持 |
| Ubuntu 23.04 (f) | 支持 | 不支持 | 不支持 | 不支持 |
| Ubuntu 22.10 (f) | 支持 | 支持 | 不支持 | 不支持 |
| Ubuntu 22.04 LTS (f) | 支持 | 支持 | 不支持 | 不支持 |
| Ubuntu 21.10 (f) | 支持 | 支持 | 不支持 | 不支持 |
| Ubuntu 21.04 (f) | 支持 | 支持 | 不支持 | 不支持 |
| Ubuntu 20.10 (e) | 支持 | 支持 | 不支持 | 不支持 |
| Ubuntu 20.04 LTS | 支持 | 支持 | 支持 | 不支持 |
| Ubuntu 18.04 LTS (d) | 支持 | 支持 | 支持 | 支持 |
| Ubuntu 16.04 LTS | 支持 | 支持 | 支持 | 支持 |
| Ubuntu 14.04 LTS | 支持 | 支持 | 支持 | 支持 |
数据库
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 数据库 | MySQL | 5.6/5.7/8.0 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控采集插件 2、内置监控策略6项 3、内置监控仪表盘1张(MySQL监控仪表盘) 4、最小监控采集频率 10s | 1、内置健康扫描包2项(基础健康检查- MySQL(Windows)、基础健康检查- MySQL(Linux)) |
| 数据库 | SQLServer | 2014/2016/2019 | 1、已内置资源模型 | 1、已内置监控采集插件 2、内置监控策略8项 3、内置监控仪表盘1张(MSSQL监控仪表盘) 4、最小监控采集频率 10s | 1、内置健康扫描包1项( 基础健康检查- MSSQL(Windows)) 2、内置运维脚本工具1项(MSSQL全库备份) |
| 数据库 | Oracle | Oracle11g/12c/19c | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控采集插件 2、内置监控策略8项 3、内置监控仪表盘1张(Oracle监控仪表盘) 4、最小监控采集频率 10s | 1、内置健康扫描包2项( 基础健康检查- Oracle(Windows)、基础健康检查- Oracle(Linux)) |
| 数据库 | MongoDB | 3.6及以上 | 1、已内置资源模型 | 1、已内置监控采集插件 2、内置监控策略1项 3、最小监控采集频率 10s | |
| 数据库 | Redis | 2.x, 3.x, 4.x, 5.x, 6.x, 7.x | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控采集插件 2、内置关键指标3项 3、内置监控策略6项 4、内置监控仪表盘1张(redis监控仪表盘) 5、最小监控采集频率 10s | |
| 数据库 | PGSQL | 9.4 , 9.5 , 9.6 , 10 , 11 , 12 , 13 , 14 , 15 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | ElasticSearch | 5.x, 6.x, 7.x, 8.x | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | TiDB | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | ||
| 数据库 | 达梦 | >=8.1.1.126 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | openGauss | >= 2.0.1 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | Gbase8a | 11g、12c、18c、19c、21c | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | HANA | 2.X | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 数据库 | HBase | 1、已内置资源模型 | 1、已内置监控采集插件 |
中间件
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 中间件 | Apache | 2.2/2.4 | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、内置关键指标5项 3、内置监控策略2项 4、内置监控仪表盘1张(Apache监控仪表盘) 5、最小监控采集频率 10s | |
| 中间件 | Nginx | 1.12-1.20 | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、内置关键指标6项 3、内置监控策略4项 4、内置监控仪表盘1张(Nginx监控仪表盘) 5、最小监控采集频率 10s | |
| 中间件 | Tomcat | 7.0.x/8.5.x/9.0.X | 11、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、内置关键指标8项 3、内置监控仪表盘1张(Tomcat监控仪表盘) 4、最小监控采集频率 10s | |
| 中间件 | IIS | 7.0 及以上 | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | Kafka | >= 0.10.1.0 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | IBM MQ | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | ||
| 中间件 | RabbitMQ | 3.7.x, 3.8.x | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | ZooKeeper | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、最小监控采集频率 10s | ||
| 中间件 | Minio | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | ||
| 中间件 | Nacos | >= 0.8.0 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | WebLogic | 12.2.1+ | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | Websphere | 9.0.5.7+ 8.5.5.x 特殊版本8.5.5.16需要安装iFix补丁 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | ActiveMQ | Activemq 5.15.2 | 1、已内置资源模型 | ||
| 中间件 | jetty | 7.x , 8.x | 1、已内置资源模型 | ||
| 中间件 | MemCache | memcache 1.5以上 | 1、已内置资源模型 | ||
| 中间件 | TongWeb | 7.0.4.6 | 1、已内置资源模型 | ||
| 中间件 | JBoss | JBoss: 7.x JBoss EAP: 6.x | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | etcd | 3.3+ | 1、已内置资源模型 2、支持自动发现 | 1、已内置监控采集插件 2、最小监控采集频率 10s | |
| 中间件 | Consul | 1、已内置资源模型 | 1、已内置监控采集插件 | ||
| 中间件 | RocketMQ | 1、已内置资源模型 | 1、已内置监控采集插件 | ||
| 中间件 | Keepalived | 1、已内置资源模型 | 1、已内置监控采集插件 | ||
| 中间件 | Spark | 1、已内置资源模型 | 1、已内置监控采集插件 | ||
| 中间件 | HAProxy | 1、已内置资源模型 | 1、已内置监控采集插件 | ||
| 中间件 | Ceph | 1、已内置资源模型 | 1、已内置监控采集插件 |
网络设备
| 类型 | 资源模型情况 | 监控情况 | 自动化情况 | 备注 |
|---|---|---|---|---|
| 防火墙 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置常用6品牌监控指标(Cisco、H3C、华为、NETGEAR、WatchGuard、东软Neteye) 2、最小监控采集频率 1min | 1、已内置思科脚本工具16项 | 自动发现和监控采集不限品牌和型号,提供拓展的能力,自动化运维限定品牌型号,详情可查看【各版本-内容说明-运维工具说明】 |
| 路由器 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置常用3品牌监控指标(Cisco、H3C、华为) 2、最小监控采集频率 1min | 1、已内置思科脚本工具16项 | 自动发现和监控采集不限品牌和型号,提供拓展的能力,自动化运维限定品牌型号,详情可查看【各版本-内容说明-运维工具说明】 |
| 负载均衡 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置常用2品牌监控指标(Riverbed、Superiority ) 2、最小监控采集频率 1min | 1、已内置思科脚本工具16项 | 自动发现和监控采集不限品牌和型号,提供拓展的能力,自动化运维限定品牌型号,详情可查看【各版本-内容说明-运维工具说明】 |
| 交换机 | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置常用7个品牌监控指标(Cisco、H3C、华为、MOXA、NETGEAR、派凌、神州数码 2、最小监控采集频率 1min | 1、已内置思科脚本工具16项 | 自动发现和监控采集不限品牌和型号,提供拓展的能力,自动化运维限定品牌型号,详情可查看【各版本-内容说明-运维工具说明】 |
K8S
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| K8S | K8S集群 | V1.20及以上版本 | 1、已内置资源模型 | ||
| K8S | K8S命名空间 | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S工作负载 | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | Pod | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控指标 2、内置关键指标5项 3、内置监控策略4项 4、最小监控采集频率 10s | ||
| K8S | Node | 1、已内置资源模型 2、支持自动发现/采集 | 1、已内置监控指标 2、内置关键指标5项 3、内置监控策略4项 4、最小监控采集频率 10s | ||
| K8S | K8S Ingress | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S Service | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S Secret | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S Configmap | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S PV | 1、已内置资源模型 2、支持自动发现/采集 | |||
| K8S | K8S PVC | 1、已内置资源模型 2、支持自动发现/采集 |
硬件设备
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 硬件设备 | 硬件服务器 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 1min | ||
| 硬件设备 | 存储 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 1min | ||
| 硬件设备 | 安全设备 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 1min |
Docker
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| Docker | Docker | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 1min | ||
| Docker | Docker容器 | 1、已内置资源模型 | |||
| Docker | Docker镜像 | 1、已内置资源模型 | |||
| Docker | Docker网络 | 1、已内置资源模型 | |||
| Docker | Docker卷 | 1、已内置资源模型 |
文件
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 备注 |
|---|---|---|---|---|
| 文件 | 配置文件 | / | 1、已内置资源模型 | 配置文件模型可以与其他资产模型进行关联和使用,具体步骤详见“操作手册-资源纳管-配置文件” |
其他
| 类型 | 纳管对象 | 支持版本 | 资源模型情况 | 监控情况 | 自动化情况 |
|---|---|---|---|---|---|
| 其他 | 进程 | 无版本要求 | |||
| 其他 | 拨测 | 无版本要求 | |||
| 其他 | AD | 2008 R2以上版本 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s | 1、内置运维脚本工具1项(查询AD用户上次登陆时间) |
| 其他 | exchange | Exchenge 2013及以上版本 | 1、已内置资源模型 | 1、已内置监控采集插件 2、最小监控采集频率 10s |
内容说明
资源模型内置说明
操作系统、数据库、中间件、容器等对象进行资源模型内置,具体模型、字段、自动发现和采集能力详见列表
查看资产和模型字段的具体信息,点击可下载WeOps内置的模型说明表格,包括WeOps初始化内置的资产模型和字段,以及自动发现和采集能力。
1.1 操作系统模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| 操作系统 | Windows Server | 详见表格【WeOps内置的模型说明表格】 | 使用Agent采集配置数据 |
| 操作系统 | linux | 详见表格【WeOps内置的模型说明表格】 | 使用Agent采集配置数据 |
1.2 数据库模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| 数据库 | Oracle | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 数据库 | MySQL | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 数据库 | MSSQL | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | REDIS | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 数据库 | MongoDB | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | ElasticSearch | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | PostgreSQL | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 数据库 | DB2 | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | TiDB | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | 达梦 | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | openGauss | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | Gbase8a | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | HANA | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | HBase | 详见表格【WeOps内置的模型说明表格】 | |
| 数据库 | 数据库集群 | 详见表格【WeOps内置的模型说明表格】 |
1.3 中间件模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| 中间件 | Apache | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Tomcat | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Nginx | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | IIS | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | RabbitMQ | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | WebLogic | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Kafka | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | IBM MQ | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | ZooKeeper | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Minio | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | Nacos | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | WebLogic | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Websphere | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | ActiveMQ | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | jetty | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | MemCache | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | JBoss | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | etcd | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现 |
| 中间件 | Consul | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | RocketMQ | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | Keepalived | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | Spark | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | HAProxy | 详见表格【WeOps内置的模型说明表格】 | |
| 中间件 | Ceph | 详见表格【WeOps内置的模型说明表格】 |
1.4 K8S模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| K8S | K8S集群 | 详见表格【WeOps内置的模型说明表格】 | |
| K8S | K8S命名空间 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S工作负载 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | Pod | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | Node | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S Ingress | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S Service | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S Secret | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S Configmap | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S PV | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| K8S | K8S PVC | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
1.5 云平台模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| VMware | Vcenter | 详见表格【WeOps内置的模型说明表格】 | |
| VMware | VMware虚拟机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| VMware | ESXI | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| VMware | 数据存储 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云账号 | 详见表格【WeOps内置的模型说明表格】 | |
| 阿里云 | ECS | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云域名 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云解析记录 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云CDN | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云Web应用防火墙 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云SSL证书 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云对象存储Bucket | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云MySQL | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云Redis | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云MongoDB | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云Kafka实例 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云Kafka消费组 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云Kafka主题 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云CLB | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云K8S集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云EIP | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云MSE集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云MSE服务 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 阿里云 | 阿里云MSE实例 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 腾讯云 | 腾讯云账号 | 详见表格【WeOps内置的模型说明表格】 | |
| 腾讯云 | CVM | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 华为云 | ManageOne平台 | 详见表格【WeOps内置的模型说明表格】 | |
| 华为云 | ManageOne云服务器 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现采集 |
| 华为云 | ManageOne宿主机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 华为云 | ManageOne数据存储 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 华为云 | ManageOne云平台 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 华为云 | 华为云账号 | 详见表格【WeOps内置的模型说明表格】 | |
| 华为云 | 华为云ECS | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 深信服超融合(SangforHCI) | SangforHCI平台 | 详见表格【WeOps内置的模型说明表格】 | |
| 深信服超融合(SangforHCI) | SangforHCI虚拟机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 华为大数据平台 | FusionInsight平台 | 详见表格【WeOps内置的模型说明表格】 | |
| 华为大数据平台 | FusionInsight集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 华为大数据平台 | FusionInsight主机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI物理机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI虚拟机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI存储池 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI存储容器 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI卷组 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI虚拟磁盘 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| 路坦力超融合(NutanixHCI) | NutanixHCI磁盘 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| OpenStack | OpenStack平台 | 见表格【WeOps内置的模型说明表格】 | |
| OpenStack | OpenStack节点 | 见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| OpenStack | OpenStack虚拟机 | 见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| OpenStack | OpenStack卷组 | 见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| OpenStack | OpenStack存储池 | 见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| SmartX | SmartX平台 | 详见表格【WeOps内置的模型说明表格】 | |
| SmartX | SmartX集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| SmartX | SmartX物理机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| SmartX | SmartX虚拟机 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| SmartX | SmartX虚拟卷 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS账号 | 详见表格【WeOps内置的模型说明表格】 | |
| AWS | AWS EC2 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS RDS | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS MSK集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS ElastiCache | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS EKS集群 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS CloudFront分配 | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS ELB | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
| AWS | AWS S3 Bucket | 详见表格【WeOps内置的模型说明表格】 | 支持自动发现和采集 |
1.6 基础设备模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| 基础设备 | 交换机 | 实例名、管理IP、管理端口、型号、SNMP版本、品牌 | 支持自动发现采集,自动发现采集字段如下: 实例名、管理IP、管理端口、型号、SNMP版本、品牌 |
| 基础设备 | 路由器 | 实例名、管理IP、管理端口、SNMP版本、型号、品牌 | 支持自动发现采集,自动发现采集字段如下: 实例名、管理IP、管理端口、SNMP版本、型号、品牌 |
| 基础设备 | 防火墙设备 | 实例名、管理IP、管理端口、型号、SNMP版本、品牌 | 支持自动发现采集,自动发现采集字段如下: 实例名、管理IP、管理端口、型号、SNMP版本、品牌 |
| 基础设备 | 负载均衡设备 | 实例名、管理IP、管理端口、SNMP版本、型号、品牌 | 支持自动发现采集,自动发现采集字段如下: 实例名、管理IP、管理端口、型号、SNMP版本、品牌 |
| 基础设备 | 物理机 | 实例名、IP地址、型号、类型、硬盘大小、CPU型号、型号、品牌、sn设备序列号、网卡数量、内存大小、MAC地址、维护人、过保日期、存放地点、资产编号 | |
| 基础设备 | 网络设备端口 | 实例名、品牌 |
1.7 硬件设备模型内置情况
| 类型 | 纳管对象 | 内置模型字段 |
|---|---|---|
| 硬件设备 | 硬件服务器 | 详见表格【WeOps内置的模型说明表格】 |
| 硬件设备 | 存储 | 详见表格【WeOps内置的模型说明表格】 |
| 硬件设备 | 安全设备 | 详见表格【WeOps内置的模型说明表格】 |
1.8 Docker
| 类型 | 纳管对象 | 内置模型字段 |
|---|---|---|
| Docker | Docker | 详见表格【WeOps内置的模型说明表格】 |
| Docker | Docker容器 | 详见表格【WeOps内置的模型说明表格】 |
| Docker | Docker镜像 | 详见表格【WeOps内置的模型说明表格】 |
| Docker | Docker网络 | 详见表格【WeOps内置的模型说明表格】 |
| Docker | Docker卷 | 详见表格【WeOps内置的模型说明表格】 |
1.9 其他模型内置情况
| 类型 | 纳管对象 | 内置模型字段 | 自动发现采集情况 |
|---|---|---|---|
| 目录服务 | AD | 详见表格【WeOps内置的模型说明表格】 | |
| 邮件服务 | Exchange Server | 详见表格【WeOps内置的模型说明表格】 | |
| 证书 | SSL证书 | 详见表格【WeOps内置的模型说明表格】 |
监控指标说明
各对象支持监控方式汇总
| 对象类型 | 对象名称 | 支持的监控方式 |
|---|---|---|
| 操作系统 | linux、Windows等 | 1、Agent采集 2、自定义脚本监控插件(shell、powershell) |
| 数据库 | Oracle、MySQL、MSSQL | 1、内置监控插件 2、自定义脚本监控插件(shell、powershell) 3、SQL监控插件 |
| MongoDB、Redis、PGSQL、其他扩展数据库 | 1、内置监控插件 2、自定义脚本监控插件(shell、powershell) | |
| 中间件 | Apache、Nginx、Tomcat… | 1、内置监控插件 2、自定义脚本监控插件(shell、powershell、BK-pull) |
| 云平台 | 阿里云、腾讯云、华为公有云…… | 1、内置监控插件 |
| K8S | node、pod | 1、内置监控插件 |
| 网络设备snmp | 交换机、路由器、防火墙、负载均衡 | 1、内置监控插件 2、自定义SNMP监控模板 |
| 硬件设备IPMI | 硬件服务器….. | 1、内置IPMI监控插件 2、自定义SNMP监控模板 |
操作系统、数据库、中间件等对象内置监控插件的监控指标,具体如下表。(部分对象已经内置监控插件、内置关键指标、内置监控策略详见列表)
点击可下载WeOps内置的监控指标说明表格,包括WeOps初始化内置的资产指标、指标说明和推荐阈值等信息
各对象监控说明
1 操作系统监控指标
| 序号 | 对象类型 | 指标数量 | 指标/事件 | 内置监控插件 | 内置监控策略 |
|---|---|---|---|---|---|
| 1 | 操作系统-Windows | 97 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 2 | 操作系统-Linux | 97 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
2 数据库监控指标
| 序号 | 对象类型 | 指标数量 | 指标/事件 | 内置监控插件 | 内置监控策略 |
|---|---|---|---|---|---|
| 1 | 数据库-MySQL | 21 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 2 | 数据库-MSSQL | 20 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 3 | 数据库-Oracle | 25 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 4 | 数据库-MongoDB | 27 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 5 | 数据库-Redis | 30 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 6 | 数据库-PGSQL | 74 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 7 | 数据库-MongoDB | 74 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 8 | 数据库-ElasticSearch | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 9 | 数据库-TiDB | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 10 | 数据库-达梦数据库 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 11 | 数据库-openGauss | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 12 | 数据库-Gbase8a | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 13 | 数据库-HANA | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
3 中间件监控指标
| 序号 | 对象类型 | 指标数量 | 指标/事件 | 内置关键指标 | 内置监控插件 | 内置监控策略 |
|---|---|---|---|---|---|---|
| 1 | 中间件-Tomcat | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 2 | 中间件-Nginx | 8 | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
| 3 | 中间件-Apache | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 4 | 中间件-IIS | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 5 | 中间件-Kafka | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 6 | 中间件-RabbitMQ | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 7 | 中间件-IBM MQ | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 8 | 中间件-ZooKeeper | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 9 | 中间件-WebLogic | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 10 | 中间件-Websphere | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 11 | 中间件-Nacos | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 12 | 中间件-Minio | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 13 | 中间件-JBoss | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 | |
| 14 | 中间件-etcd | 详见【WeOps内置的监控指标说明表格】 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 | 详见【WeOps内置的监控指标说明表格】 |
4 K8S监控指标
| 序号 | 对象类型 | 指标数量 | 指标 | 内置关键指标 | 内置监控插件 | 内置监控策略 |
|---|---|---|---|---|---|---|
| 1 | K8S-Pod | 17 | 详见【WeOps内置的监控指标说明表格】 | |||
| 2 | K8S-Node | 14 | 详见【WeOps内置的监控指标说明表格】 | |||
| 3 | K8S-K8S集群 | / | 详见【WeOps内置的监控指标说明表格】 |
5 云平台监控指标
| 序号 | 云平台 | 类型 | 指指标 |
|---|---|---|---|
| 1 | VMware | 数据存储、ESXI、虚拟机 | 详见【WeOps内置的监控指标说明表格】 |
| 2 | 阿里云 | ECS、CDN、Web应用防火墙、对象存储Bucket、MySQL、Redis、MongoDB、Kafka、EIP | 详见【WeOps内置的监控指标说明表格】 |
| 3 | 腾讯云 | CVM、MySQL、RocketMQ、TKEServerless | 详见【WeOps内置的监控指标说明表格】 |
| 4 | 华为云-manageone | 云服务器、云平台、宿主机、存储、弹性IP、负载均衡 | 详见【WeOps内置的监控指标说明表格】 |
| 5 | 华为公有云 | 华为云ECS | 详见【WeOps内置的监控指标说明表格】 |
| 6 | 深信服超融合 | SangforHCI虚拟机 | 详见【WeOps内置的监控指标说明表格】 |
| 7 | NutanixHCI(路坦力) | 虚拟机、物理机、磁盘、虚拟磁盘、存储容器、存储池、卷组 | 详见【WeOps内置的监控指标说明表格】 |
| 8 | 华为FusionInsight | 集群、云服务器 | 详见【WeOps内置的监控指标说明表格】 |
| 9 | OPenStack | 节点、虚拟机、存储池 | 详见【WeOps内置的监控指标说明表格】 |
| 10 | SmartX | 物理机、虚拟机、虚拟卷 | 详见【WeOps内置的监控指标说明表格】 |
| 11 | AWS | EC2、RDS、Elasticache | 详见【WeOps内置的监控指标说明表格】 |
6 网络设备监控指标
以下展示的是内置的网络设备指标模板,WeOps提供拓展能力,可支持不同品牌和型号的设备(通过自定义监控模板的方式进行能力拓展)。
| 序号 | 对象类型 | 模板数量 | 指标 |
|---|---|---|---|
| 1 | 防火墙 | 12 | 详见【WeOps内置的监控指标说明表格】 |
| 2 | 交换机 | 58 | 详见【WeOps内置的监控指标说明表格】 |
| 3 | 路由器 | 10 | 详见【WeOps内置的监控指标说明表格】 |
| 4 | 负载均衡 | 5 | 详见【WeOps内置的监控指标说明表格】 |
7 硬件设备监控指标
| 序号 | 对象类型 | 模板数量 | 指标 |
|---|---|---|---|
| 1 | 硬件服务器 | 10 | 详见【WeOps内置的监控指标说明表格】 |
| 2 | 存储 | 14 | 详见【WeOps内置的监控指标说明表格】 |
| 3 | 安全设备 | 4 | 详见【WeOps内置的监控指标说明表格】 |
8 Docker监控指标
| 序号 | 对象类型 | 指标数量 | 指标 |
|---|---|---|---|
| 1 | Docker | / | 详见【WeOps内置的监控指标说明表格】 |
9 其他监控指标
| 序号 | 对象类型 | 指标数量 | 指标/事件 | 内置监控插件 |
|---|---|---|---|---|
| 1 | 进程 | 15 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控指标 |
| 2 | 拨测 | 12 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控指标 |
| 3 | Active Directory活动目录 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控指标 | |
| 4 | Exchange邮件系统 | 详见【WeOps内置的监控指标说明表格】 | 已内置监控插件 |
监控插件参数和权限说明
WeOps监控插件使用的参数和授予权限说明如下
MSSQL
使用说明
插件功能
基于配置连接数据库并从中收集指标,其收集的指标及其采集、生成方式均由配置文件定义。
插件版本
适用于插件版本V3.1.2,其他版本插件说明详见: sql-exporter
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
| 主版本号 | 次版本号 | 指标支持 |
|---|---|---|
| 2008 | 10.x | – |
| 2008 R2 | 10.5 | – |
| 2012 | 11.x | – |
| 2014 | 12.x | – |
| 2016 | 13.x | ✔ |
| 2017 | 14.x | ✔ |
| 2019 | 15.x | ✔ |
| 2022 | 16.x | ✔ |
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| -host | 数据库主机IP | 是 | 127.0.0.1 |
| -port | 数据库服务端口 | 是 | 1433 |
| SQLSERVERUSER | 数据库用户名(环境变量) | 是 | SA |
| SQLSERVERPASSWORD | 数据库密码(环境变量) | 是 | |
| -config.file | sql_exporter.yml 采集器全局配置文件, 包含超时设置、最大连接数、目标配置、采集指标配置文件名等 | 是 | 默认已有采集器全局配置文件 |
| -log.level | 日志级别 | 否 | info |
| -web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| collector.file.content | mssql_standard.collector.yml 采集指标配置文件, 包含指标名、维度、sql等内容。注意!该参数为文件参数,非探针执行文件参数! | 是 | 默认已有标准采集指标配置文件 |
采集器全局配置文件说明(sql_exporter.yml)
# 全局配置
global:
# sql语句的超时时间,这个值需要比prometheus的 `scrape_timeout` 值要小。如果配置了下方的 scrape_timeout_offset 值,那么最终的超时时间为, min(scrape_timeout, X-Prometheus-Scrape-Timeout-Seconds - scrape_timeout_offset)
# X-Prometheus-Scrape-Timeout-Seconds 为 prometheus 的超时时间
scrape_timeout: 10s
# 从 prometheus 的超时时间中减去一个偏移量,防止 prometheus 先超时。
scrape_timeout_offset: 500ms
# 各个sql收集器之间运行间隔的秒数
min_interval: 0s
# 允许获取到的数据库最大的连接数, <=0 表示不限制。
max_connections: 3
# 允许空闲连接数的个数,<=0 不做限制
max_idle_connections: 3
# 配置监控的数据库和抓取信息
target:
# 配置数据库链接信息
# sqlserver://user(用户名):password(密码)@127.0.0.1(数据库服务域名或者IP):1433(数据库服务端口号)
data_source_name: "sqlserver://user:password@127.0.0.1:1433"
# 收集器的名字, 对应下方 collector_files 中文件的 collector_name 的值
collectors: [mssql_*]
collector_files:
- "*.collector.yml"采集指标配置文件(mssql_standard.collector.yml)
# 收集器的名字
collector_name: mssql_standard
metrics:
- metric_name: mssql_version # 指标ID
type: counter # 类型
help: 'Fetched version of instance.' # 描述
key_labels: # 维度值
- ProductVersion
values: [value] # 值
query: | # sql语句
SELECT CONVERT(VARCHAR(128), SERVERPROPERTY ('productversion')) AS ProductVersion, 1 AS value使用指引
以下是在SQL Server中使用命令行创建监控用户的教程:
方式一:
- 连接到 MSSQL 数据库服务器,并使用具有足够权限的管理员用户帐户登录。
- 在 SQL Server Management Studio 中,右键单击 Security,然后选择 “New Login”。
- 在 “Login – New” 对话框中,输入监控用户的用户名,选择 “SQL Server authentication” 作为登录类型,并设置一个强密码。
- 在 “Default database” 下拉菜单中,选择用户需要访问的数据库,一般默认master即可。
- 在 “Server Roles” 选项卡中,选择 “public” 角色。
- 在 “User Mapping” 选项卡中,将需要访问的数据库分配给该用户。
- 单击 “OK” 按钮以创建该用户。
在 MSSQL exporter 的配置文件中,使用此监控用户的凭据访问数据库。
方式二: 通过终端与数据库交互
- 打开命令提示符或PowerShell,使用sqlcmd命令连接到SQL Server,如下所示:
sqlcmd -S server_address -U sa -P your_password其中,server_address是SQL Server的访问地址,sa是具有足够权限的SQL Server管理员的登录名,your_password是对应的密码。 - 使用以下命令创建监控用户,该用户只具有读取权限,允许用户查看所有对象的定义:
CREATE LOGIN monitoring_user WITH PASSWORD = 'your_password';其中,monitoring_user是监控用户的名称,your_password是对应的密码。
GRANT VIEW SERVER STATE TO monitoring_user;
GRANT VIEW ANY DEFINITION TO monitoring_user;
GO - 如果需要在特定的数据库中监控,请使用以下命令授予监控用户对该数据库的访问权限:
USE database_name;其中,database_name是要监控的数据库的名称,一般默认使用master。
CREATE USER monitoring_user FOR LOGIN monitoring_user;
ALTER ROLE db_datareader ADD MEMBER monitoring_user;
GO
MySQL
使用说明
插件功能
采集器会定期执行SQL查询语句,例如 show global status 和 show slave status 等,获取相应的指标数据。
插件版本
适用于插件版本V4.2.4,其他版本插件说明详见: mysql-exporter
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本
MySQL >= 5.6
MariaDB >= 10.3
是否支持远程采集
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| MYSQL_USER | mysql登录账户名(环境变量) | 是 | monitor |
| MYSQL_PASSWORD | mysql登录账户名的密码(环境变量) | 是 | Monitor123! |
| –mysqld.host | mysql服务地址 | 是 | 127.0.0.1 |
| –mysqld.port | mysql服务端口号 | 是 | 3306 |
| –log.level | 日志级别 | 否 | info |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
- 连接MySQL
mysql -u[username] -p[password] -h[host] -P[port]
- 创建账户及授权
CREATE USER '[username]'@'%' IDENTIFIED BY '[password]'; GRANT PROCESS, SELECT, REPLICATION CLIENT ON *.* TO '[username]'@'%';
在 MariaDB 10.5+ 版本中,为了支持增量备份,引入了一种新的权限 REPLICA MONITOR。该权限允许用户监视复制进程,并查询与备份有关的信 息。
当 mysql exporter 用于监控 MariaDB 10.5+ 版本的数据库时,它需要使用 REPLICA MONITOR 权限来获取与备份有关的信息。如果没有授予监控用户 REPLICA MONITOR 权限,则无法获取这些信息,导致监控数据不完整或无法正常工作。 因此,在 MariaDB 10.5+ 版本中,需要使用 GRANT 命令为监控用户授予 REPLICA MONITOR 权限。
GRANT REPLICA MONITOR ON *.* TO '[username]'@'%';
Oracle
使用说明
插件功能
采集器连接oracle数据库,执行SQL查询语句,将结果解析到prometheus数据格式的监控指标。 实际收集的指标取决于数据库的配置和版本。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
Oracle Database: 11g, 12c, 18c, 19c, 21c
部署模式支持: standalone(单点), RAC(集群), dataGuard(DG)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| –host | 数据库主机IP | 是 | 127.0.0.1 |
| –port | 数据库服务端口 | 是 | 1521 |
| USER | 数据库用户名(环境变量) | 是 | |
| PASSWORD | 数据库密码(环境变量) | 是 | |
| SERVICE_NAME | 数据库服务名(环境变量) | 是 | ORCLCDB |
| –isRAC | 是否为rac集群架构(开关参数), 默认不开启 | 否 | |
| –isASM | 是否有ASM磁盘组(开关参数), 默认不开启 | 否 | |
| –isDataGuard | 是否为DataGuard(开关参数), 默认不开启 | 否 | |
| –isArchiveLog | 是否采集归档日志指标, 默认不开启 | 否 | |
| –query.timeout | 查询超时秒数,默认使用5s | 否 | 5 |
| –log.level | 日志级别 | 否 | info |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
- 查看Oracle数据库服务名和域名注意!对于oracle数据库12版本,DSN中数据库名后必须加入域名,其他版本一般不需要ORCLCDB是Oracle数据库的一个服务名称(Service Name),它用于唯一标识数据库实例中的一个服务。例: “oracle://system:Weops123!@db12c-oracle-db.oracle:1521/ORCLCDB.localdomain”
- 查看当前数据库实例的
SERVICE_NAME参数的值。SELECT value FROM v$parameter WHERE name = 'service_names'; - 查看当前数据库实例的
DB_DOMAIN参数的值。如果返回结果为空,表示未设置特定的域名。SELECT value FROM v$parameter WHERE name = 'db_domain';
- 查看当前数据库实例的
- 若出现unknown service error
- 需检查监听器的当前状态,确保监听器正在运行并监听正确的端口,运行命令
lsnrctl status。 - 确认监听器配置文件(
lsnrctl status会输出监听器配置状态等信息,寻找配置文件,通常是 listener.ora)中是否正确定义了服务名称,并与您尝试连接的服务名称匹配。 lsnrctl在oracle数据库12版本中,此命令一般存放于/u01/app/oracle/product/12.2.0/dbhome_1/; 在oracle数据库19版本中,一般存放于/opt/oracle/product/19c/dbhome_1/bin
- 需检查监听器的当前状态,确保监听器正在运行并监听正确的端口,运行命令
- 连接Oracle数据库 使用操作系统的身份认证(通常是超级用户或管理员),直接以 sysdba 角色登录到数据库
sqlplus / as sysdba使用指定账户登录sqlplus username/password@host:port/service_name - 创建账户及授权
注意!创建账户时必须使用管理员账户创建账户类型有区别:
a) 在Oracle数据库中,使用C##前缀是为了创建一个包含大写字母和特殊字符的用户名,这样可以确保在创建和使用这些用户时不会发生命名冲突。C##前缀表示”Container Database”,用于标识这个用户是一个全局共享的用户,而不是只属于某个具体的Pluggable Database (PDB)。
b) 要决定是否在用户名前使用C##,主要取决于数据库的架构。在Oracle 12c及更高版本中,数据库被分为一个容器数据库(CDB)和一个或多个可插拔数据库(PDB)。如果你在CDB层面创建用户,可以选择使用C##前缀,表示这个用户是一个全局共享的用户。如果在PDB层面创建用户,通常不需要使用C##前缀,因为PDB内的用户空间是相互隔离的。
c) 在创建用户时是否使用C##前缀取决于你的特定需求和数据库架构。如果你的用户需要在不同的PDB之间共享,并且你希望避免命名冲突,那么可以考虑使用C##前缀。如果用户只在特定的PDB中使用,可能不需要这个前缀。
d) 使用 C## 前缀的情况:CREATE USER C##GlobalUser IDENTIFIED BY password CONTAINER = ALL;
e) 不使用 C## 前缀的情况:CREATE USER LocalUser IDENTIFIED BY password;
# 新建用户
CREATE USER [user] IDENTIFIED BY [password];
# 修改用户的密码,密码若含特殊字符需使用双引号将密码括起来
ALTER USER [user] IDENTIFIED BY [password];
# 允许用户建立数据库会话
GRANT CREATE SESSION TO [user];
# uptime指标授权
GRANT SELECT ON V_$instance to [user];
# rac指标授权
GRANT SELECT ON GV_$instance to [user];
# sessions类指标授权
GRANT SELECT ON V_$session to [user];
# resource类指标授权
GRANT SELECT ON V_$resource_limit to [user];
# asm_diskgroup类指标授权
GRANT SELECT ON V_$datafile to [user];
GRANT SELECT ON V_$asm_diskgroup_stat to [user];
# activity类指标授权
GRANT SELECT ON V_$sysstat to [user];
# process类指标授权
GRANT SELECT ON V_$process to [user];
# wait_time类指标授权
GRANT SELECT ON V_$waitclassmetric to [user];
GRANT SELECT ON V_$system_wait_class to [user];
# tablespace类指标授权
GRANT SELECT ON dba_tablespace_usage_metrics to [user];
GRANT SELECT ON dba_tablespaces to [user];
# asm_disk_stat类指标授权
GRANT SELECT ON V_$asm_disk_stat to [user];
GRANT SELECT ON V_$asm_diskgroup_stat to [user];
GRANT SELECT ON V_$instance to [user];
# asm_space_consumers类指标授权
GRANT SELECT ON V_$asm_alias to [user];
GRANT SELECT ON V_$asm_diskgroup to [user];
GRANT SELECT ON V_$asm_file to [user];
# sga类指标授权
GRANT SELECT ON V_$sga TO [user];
GRANT SELECT ON V_$sgastat TO [user];
# pga类指标授权
GRANT SELECT ON V_$pgastat TO [user];
# dataguard类指标授权
GRANT SELECT ON V_$dataguard_stats TO [user];
# archived_log类指标授权
GRANT SELECT ON V_$database to [user];
GRANT SELECT ON V_$archive_dest to [user];
GRANT SELECT ON V_$parameter to [user];
GRANT SELECT ON V_$asm_diskgroup to [user];PostgreSQL
使用说明
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
PostgreSQL: 9.4, 9.5, 9.6, 10, 11, 12, 13, 14, 15
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| DATA_SOURCE_HOST | 数据库主机IP(环境变量) | 是 | 127.0.0.1 |
| DATA_SOURCE_PORT | 数据库服务端口(环境变量) | 是 | 5432 |
| DATA_SOURCE_USER | 数据库用户名(环境变量) | 是 | postgres |
| DATA_SOURCE_PASS | 数据库密码(环境变量) | 是 | |
| DATA_SOURCE_DB | 数据库库名(环境变量) | 是 | postgres |
| –collector.postmaster | postmaster采集器开关(开关参数),默认关闭 | 否 | |
| –collector.stat_statements | stat_statements采集器开关(开关参数),默认关闭 | 否 | |
| –collector.stat_statements | stat_statements采集器开关(开关参数),默认关闭 | 否 | |
| –collector.xlog_location | xlog_location采集器开关(开关参数),默认关闭 | 否 | |
| –log.level | 日志级别 | 否 | info |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| additional | 额外参数,可留空内容 | 否 | –disable-default-metrics |
注意 一般连接的数据库名都需要填写为 postgres
额外参数说明
额外参数(additional)不需要赋值,只需要填写对应内容,作为采集器的功能或者采集指标的开关,postgreSQL插件支持的额外参数如下:
- 不采集默认指标,只保留自定义指标采集文件中的指标 –disable-default-metrics
- 不采集配置(Setting)类,pg_settings前缀开头的指标 –disable-settings-metrics
- 不采集后台写入器(Bgwriter)类,pg_stat_bgwriter前缀开头的指标 –no-collector.bgwriter
- 不采集复制槽信息,replication_slot前缀开头的指标 –no-collector.replication_slot
使用指引
- 连接Postgres数据库 输入连接指令后输入对应的密码即可进入数据库。
psql -U [user] -h [host] -p [port] -d [database] - 创建账户及授权 执行下方sql可以创建具有监控权限的账户,用户名
weops,密码Weops123!。 注意! 数据库版本 >= 10才需要执行GRANT pg_monitor TO weops;,9.x版本无法执行该授权。CREATE OR REPLACE FUNCTION __tmp_create_user() returns void as $$
BEGIN
IF NOT EXISTS (
SELECT -- SELECT list can stay empty for this
FROM pg_catalog.pg_user
WHERE usename = 'weops') THEN
CREATE USER weops;
END IF;
END;
$$ language plpgsql;
SELECT __tmp_create_user();
DROP FUNCTION __tmp_create_user();
ALTER USER weops WITH PASSWORD 'Weops123!';
ALTER USER weops SET SEARCH_PATH TO weops,pg_catalog;
GRANT CONNECT ON DATABASE postgres TO weops;
GRANT pg_monitor TO weops; -- 数据库版本 >= 10 才需要执行这条sql
CREATE SCHEMA IF NOT EXISTS weops;
GRANT USAGE ON SCHEMA weops TO weops;
CREATE OR REPLACE FUNCTION get_pg_stat_activity() RETURNS SETOF pg_stat_activity AS
$$ SELECT * FROM pg_catalog.pg_stat_activity; $$
LANGUAGE sql
VOLATILE
SECURITY DEFINER;
CREATE OR REPLACE VIEW weops.pg_stat_activity
AS
SELECT * from get_pg_stat_activity();
GRANT SELECT ON weops.pg_stat_activity TO weops;
CREATE OR REPLACE FUNCTION get_pg_stat_replication() RETURNS SETOF pg_stat_replication AS
$$ SELECT * FROM pg_catalog.pg_stat_replication; $$
LANGUAGE sql
VOLATILE
SECURITY DEFINER;
CREATE OR REPLACE VIEW weops.pg_stat_replication
AS
SELECT * FROM get_pg_stat_replication();
GRANT SELECT ON weops.pg_stat_replication TO weops;
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
CREATE OR REPLACE FUNCTION get_pg_stat_statements() RETURNS SETOF pg_stat_statements AS
$$ SELECT * FROM public.pg_stat_statements; $$
LANGUAGE sql
VOLATILE
SECURITY DEFINER;
CREATE OR REPLACE VIEW weops.pg_stat_statements
AS
SELECT * FROM get_pg_stat_statements();
GRANT SELECT ON weops.pg_stat_statements TO weops;
Redis
使用说明
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
Redis版本支持: 2.x, 3.x, 4.x, 5.x, 6.x, 7.x
部署模式支持: 单机模式(Standalone), 主从复制模式(Master-Slave Replication), 集群(Cluster), 哨兵模式(Sentinel)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| REDIS_USER | 用于身份验证的用户名(环境变量),Redis ACL for Redis 6.0+, 默认为空 | 否 | admin |
| REDIS_PASSWORD | redis密码(环境变量),若为空则不填,默认为空 | 否 | 123456 |
| -redis.addr | redis 实例地址 | 是 | redis://localhost:6379 |
| -include-system-metrics | 是否包含系统指标,比如total_system_memory_bytes, 默认为false | 否 | true |
| -is-cluster | 是否集群模式, 默认为false | 是 | false |
| -ping-on-connect | 连接后是否ping redis 实例并将持续时间记录为指标,默认为false | 否 | true |
| -connection-timeout | 连接到redis的超时时间, 默认为15s | 否 | 15s |
| -web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
- 验证redis密码
./redis-cli -h redis地址 -p 端口号
./redis-cli -h 127.0.0.1 -p 6379
# 进入后会出现 127.0.0.1:6379>
# 在右侧输入AUTH 密码, 如果正确会返回OK, 下面是一些示例
root@5a3f395bab17:/usr/local/bin# ./redis-cli -h 127.0.0.1 -p 6379 -a wsbs201712
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379>
127.0.0.1:6379> AUTH 1234567
(error) ERR invalid password
127.0.0.1:6379> AUTH 123456
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"- 查看redis密码 方法1: 通过redis-cli进入redis后执行config get requirepass命令
# 返回示例,密码为空方法2: 寻找Redis的配置文件, 默认在/etc/redis.conf,找到字样”requirepass” requirepass redis密码
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
# 返回示例,密码不为空
127.0.0.1:6379> config get requirepass
(error) NOAUTH Authentication required.
- 查看redis密码 方法1: 通过redis-cli进入redis后执行config get requirepass命令
- redis账户 如果用到redis账户需要确保授权,注意redis版本不同可能授权不同 例: redis v7授权
127.0.0.1:6379> ACL SETUSER weops on >123456 +client +ping +info +config|get +cluster|info +slowlog +latency +memory +select +get +scan +xinfo +type +pfcount +strlen +llen +scard +zcard +hlen +xlen +eval allkeys
OK
MongoDB
使用说明
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
mongoDB版本: >= 3.6
注意 mongodb低于3.6版本(例如3.4)可能会缺少部分监控指标,还可能出现连接不兼容等问题。
部署模式支持: 单机(Standalone), 集群(Replicaset), 分片(Sharded)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| –mongodb.host | 数据库主机IP | 是 | 127.0.0.1 |
| –mongodb.port | 数据库服务端口 | 是 | 27017 |
| –mongodb.db | 数据库库名 | 是 | admin |
| MONGODB_USER | 数据库用户名(环境变量) | 是 | admin |
| MONGODB_PASSWORD | 数据库密码(环境变量) | 是 | |
| –collect-all | 是否采集所有collectors的指标,默认采集所有 | 是 | true |
| –timeout | 连接mongodb超时时间(seconds), 默认为10s | 否 | 5 |
| –log.level | 日志级别 | 否 | info |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
额外参数说明
,mongoDB插件支持的额外参数如下:
- collect-all默认使用采集以下所有collector指标,如果不需要采集所有,可选择赋值–collect-all=false并单独启用以下的collector, 若启用则赋值true –collector.diagnosticdata: getDiagnosticData类指标 –collector.replicasetstatus: replSetGetStatus类指标 –collector.dbstats: dbStats类指标 –collector.topmetrics: top admin command类指标 –collector.indexstats: $indexStats类指标 –collector.collstats: $collStats类指标
使用指引
- 连接mongoDB
- 输入连接指令后输入对应的账户配置即可进入。有多种方式进入MongoDB,下面列出常用的使用方式
# 常用
mongo -u [username] -p [password] --host [host] --port [port]
# 连接MongoDB并指定端口
mongo 127.0.0.1:27017
# 使用用户名和密码连接到指定的MongoDB数据库
mongo 127.0.0.1:27017/test -u [username] -p [password] - 如果没有mongo命令,可尝试使用mongosh命令,具体使用方式与上面mongo连接命令方式一致,MongoDB Shell下载地址: https://www.mongodb.com/try/download/shell
- 输入连接指令后输入对应的账户配置即可进入。有多种方式进入MongoDB,下面列出常用的使用方式
- 创建账户及授权
- 需要注意auth授权的账户密码是管理员, 创建的用户是新的账户密码
- 管理员授权命令若失败,可尝试直接创建账户,一般管理员为admin
- 创建账户 创建在admin下的账户
use admin;创建在其他数据库下的账号
db.auth('admin', '管理员密码');
db.createUser({
user: 'weops',
pwd: 'Weops123',
roles: [{ role: 'read', db: 'admin' }, 'clusterMonitor'],
mechanisms: ['SCRAM-SHA-256']
});use admin;需要注意mongodb的版本,
db.auth('admin', '管理员密码');
use weops;
db.createUser({
user: 'weops',
pwd: 'Weops123',
roles: [{ role: 'read', db: 'weops' }],
mechanisms: ['SCRAM-SHA-256']
});
db.grantRolesToUser('weops', [{ role: 'clusterMonitor', db: 'admin' }]);mechanisms: ['SCRAM-SHA-256']身份认证一般用于 >= 4.0, 若mongodb < 4.0 (比如3.6), 那么可以去掉mechanisms: ['SCRAM-SHA-256'], 或者使用mechanisms: ['SCRAM-SHA-1']
- mongo相关命令指引
- 查询特定数据库下的用户属性
use weops;
db.getUser('weops');
# 执行命令返回的用户信息
{
"_id" : "weops.weops",
"userId" : UUID("2a14dcf6-fd72-4247-9a45-092ea128c775"),
"user" : "weops",
"db" : "weops",
"roles" : [
{
"role" : "read",
"db" : "weops"
},
{
"role" : "clusterMonitor",
"db" : "admin"
}
],
"mechanisms" : [
"SCRAM-SHA-256"
]
}
- 查询特定数据库下的用户属性
- 查看全局所有用户
db.system.users.find().pretty(); - 查看所有数据库
show dbs;
IIS
使用说明
IIS Exporter用于采集Internet Information Services(IIS)服务器的性能指标。它通过从Perflib(Performance Library)获取监控数据来实现监控功能。
版本支持
操作系统支持: windows
是否支持arm: 否
组件支持版本:
IIS Exporter 支持的 IIS 版本为 7.0 及以上。
注意 部分指标需要 IIS 8 及以上版本才能够正确采集。 例如: windows_iis_worker_request_errors_total、windows_iis_worker_current_websocket_requests
建议使用 IIS 10.0 或更高版本作为采集对象,以确保能够获得更完整的性能指标数据。
是否支持远程采集:
否
参数说明
IIS exporter采集目前只可以设置日志级别参数,直接下发到windows服务器即可。
使用指引
- 检查 IIS 服务是否已启动:
- 打开 IIS 管理器:
- 直接进入 IIS 管理器: 在计算机中搜索并运行 “IIS 管理器”。选择你的服务器,然后在左侧面板中展开 “服务器名”,选择 “应用程序池”,在右侧窗口中查看应用程序池的状态。
- 使用服务器管理器进入 IIS 管理器:
使用开始菜单或搜索栏找到 “服务器管理器” 并打开。打开 “服务器管理器”,在左侧面板中选择 “IIS”。右键点击你的服务器,选择 “Internet Information Services (IIS) 管理器”。
- 检查应用程序池和网站状态:
在 IIS 管理器中,展开 “服务器名”,然后选择 “应用程序池”。在应用程序池窗口内查看应用程序池的状态。同时,选择 “网站”,然后右键点击网站,在管理网站选项中查看是否已启动。 - 验证 IIS 服务是否启动: 在浏览器中输入默认的 IIS 服务地址:http://127.0.0.1。如果 IIS 服务已启动并运行,你应该会看到 “Internet Information Services” 或类似的内容页面。否则,可能会显示连接错误或无法访问页面。
- 检查性能计数器
Get-Counter '\Web Service(_total)\*'此命令将返回有关IIS Web服务的总体性能计数器信息。
AD
使用说明
AD Exporter用于采集Windows Active Directory域控制器的指标,通过 Windows Management Instrumentation (WMI) 提供的接口来采集数据。
版本支持
操作系统支持: windows
是否支持arm: 否
组件支持版本:
可以在支持 WMI 的 Windows 操作系统上采集数据。
是否支持远程采集:
否
参数说明
AD exporter采集目前只可以设置日志级别参数,直接下发到windows服务器即可。
Exchange
使用说明
Windows Exchange Exporter用于采集Windows Exchange的指标,通过 Windows Management Instrumentation (WMI) 提供的接口来采集数据。
版本支持
操作系统支持: windows
是否支持arm: 否
组件支持版本:
可以在支持 WMI 的 Windows 操作系统上采集数据。
是否支持远程采集:
否
参数说明
Exchange exporter采集目前只可以设置日志级别参数,直接下发到windows服务器即可。
ElasticSearch
使用说明
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
elasticsearch版本: 5.x, 6.x, 7.x, 8.x 部署模式支持: 单机(Standalone), 集群(Cluster)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| ES_USERNAME | elasticsearch账户名, 填入则会覆盖uri中的账户, 特殊字符不需要转义 | 否 | weops |
| ES_PASSWORD | elasticsearch密码, 填入则会覆盖uri中的密码, 特殊字符不需要转义 | 否 | Weops@123 |
| –es.uri | elasticsearch访问地址, 注意区分http和https, uri中的账户密码特殊字符需要转义 | 是 | http://127.0.0.1:9200 |
| –es.all | 全节点采集开关(开关参数), 如果打开则采集集群中所有节点, 否则只采集填写的连接地址的节点数据, 默认关闭 | 是 | |
| –es.ssl-skip-verify | 跳过SSL认证开关(开关参数), 如果打开则跳过SSL认证, 默认关闭 | 是 | |
| –es.indices | 索引采集开关(开关参数), 如果打开则采集所有在集群中的索引, 默认关闭 | 否 | |
| –es.indices_settings | 索引配置采集开关(开关参数), 如果打开则采集所有在集群中的索引配置信息, 默认关闭 | 否 | |
| –es.indices_mappings | 索引映射采集开关(开关参数), 如果打开则采集所有在集群中的索引映射信息, 默认关闭 | 否 | |
| –es.shards | 分片采集开关(开关参数), 如果打开则采集所有在集群中的分片信息, 默认关闭 | 否 | |
| –es.slm | 快照管理采集开关(开关参数), 如果打开则采集快照管理信息, 默认关闭 | 否 | |
| –collector.clustersettings | 集群配置采集开关(开关参数), 如果打开则采集集群配置信息, 默认关闭 | 否 | |
| –collector.snapshots | 快照采集开关(开关参数), 如果打开则采集快照信息, 默认关闭 | 否 | |
| –es.clusterinfo.interval | 集群配置信息更新时间间隔,默认5m | 否 | 5m |
| –es.timeout | 连接elasticsearch超时时间, 默认5s | 否 | 5s |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| –log.level | 日志级别 | 否 | info |
使用指引
- 配置监控账户 示例:
| 设置 | 所需权限 | 描述 |
|---|---|---|
| exporter defaults | cluster monitor | 所有集群的只读操作,如集群健康和状态、热线程、节点信息、节点和集群统计以及待处理的集群任务。 |
| cluster_settings | cluster monitor | |
| indices | indices monitor | 所有监控所需的操作(恢复、段信息、索引统计和状态)。 可对每个索引或 *(通配符)应用此权限。 |
| indices_settings | indices monitor | 可对每个索引或 *(通配符)应用此权限。 |
| indices_mappings | indices view_index_metadata | 可对每个索引或 *(通配符)应用此权限。 |
| shards | 不确定是indices、cluster monitor还是两者都是 | |
| snapshots | cluster:admin/snapshot/status 和 cluster:admin/repository/get | ES Forum Post |
| slm | read_slm | |
| data_stream | monitor 或 manage | 可对每个数据流或 *(通配符)应用此权限。 |
不同版本的elasticsearch配置监控账户的方式和可配置权限不同,具体可参考官方文档
- 采集参数 探针每次从 Elasticsearch 服务抓取监控指标时都会获取新的信息。 因此,需要注意频繁的采集频率可能会对 Elasticsearch 服务造成过大的压力, 特别是当打开了
--es.all和--es.indices的采集开关。 建议首先测量从/_nodes/stats和/_all/_stats获取数据所需的时间,然后根据实际情况来调整采集频率。
Kafka
使用说明
插件功能 连接到Kafka,获取与主题、消费者组以及其他相关数据。帮助用户监控Kafka健康状态、性能指标以及消费者行为。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
kafka版本: >= 0.10.1.0 部署模式支持: 单机(Standalone), 集群(Cluster)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| –kafka.server | kafka服务主机ip:服务端口,若为集群,也请填写单个ip和服务端口 | 是 | 127.0.0.1:9092 |
| –kafka.version | kafka服务版本 | 是 | 0.10.1.0 |
| –sasl.enabled | SASL认证开关(开关参数) | 是 | |
| SASL_USERNAME | kafka SASL用户名(环境变量) | 是 | weops |
| SASL_PASSWORD | kafka SASL用户的密码(环境变量) | 是 | weops123 |
| SASL_MECHANISM | kafka SASL机制(环境变量),若不开启SASL则填空,否则可填plain、scram-sha512、scram-sha256 | 否 | plain |
| TOPIC_FILTER | 筛选并留下含有正则关键字的主题(环境变量),默认不过滤 | 是 | .* |
| TOPIC_EXCLUDE | 筛选并排除含有正则关键字的主题(环境变量),默认不过滤 | 是 | ^$ |
| GROUP_FILTER | 筛选并留下含有正则关键字的消费者组(环境变量),默认不过滤 | 是 | .* |
| GROUP_EXCLUDE | 筛选并排除含有正则关键字的消费者组(环境变量),默认不过滤 | 是 | ^$ |
| –verbosity | 日志级别,默认为0,0(ERROR级别),1(INFO级别),(DEBUG级别) | 否 | 0 |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
- 查看kafka版本 有以下几种方式:
- 进入kafka安装目录,比如
/opt/kafka_2.11-0.11.0.3/bin,那么该kafka版本为0.11.0.3 - 进入kafka目录,比如
/opt/kafka/libs,该路径底下的包会含有版本信息,比如kafka_2.12-0.10.2.0.jar,那么该kafka版本为0.10.2.0
- 进入kafka安装目录,比如
- 主题和消费者组过滤选项 支持主题和消费者组的过滤,需要注意如果主题过多或者在集群的模式下,可能监控获取到的数据量会较大,指标抓取时长会增加并且会占用较多的cpu资源, 一般建议缩小监控的主题和消费者组范围,减少指标抓取时长和资源占用。若需要全部数据,注意要增加抓取时长等待时间(采集任务采集周期)。
Tomcat
使用说明
通过抓取和公开JMX目标的mBeans来收集有关应用程序的度量数据,并将这些度量数据转换为Prometheus监控指标格式。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
tomcat版本: 6.x, 7.x, 8.x, 9.x, 10.x
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| host | 监听IP(采集器IP),建议使用默认的127.0.0.1 | 是 | 127.0.0.1 |
| port | 监听端口(采集器监听端口),一般为9601,注意不要与已使用端口冲突 | 是 | 9601 |
| username | jmx认证用户名,若未配置则留空 | 否 | |
| password | jmx认证密码,若未配置则留空 | 否 | |
| jmx_url | jmx 连接字符串,格式为service:jmx:rmi:///jndi/rmi://${target_host}:${target_port}/jmxrmi | 是 | service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi |
使用指引
- 配置tomcat jmx参数
- 打开tomcat的bin目录下的catalina.sh文件
- 在文件中找到CATALINA_OPTS变量,添加如下参数
-Dcom.sun.management.jmxremote例如:
-Dcom.sun.management.jmxremote.port=1234
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=falseCATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=192.168.1.1 -Dcom.sun.management.jmxremote.port=1234 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"配置JMX的账号密码验证(选择性):CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=192.168.1.1 -Dcom.sun.management.jmxremote.port=1234 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.access.file=./jmx.access -Dcom.sun.management.jmxremote.password.file=./jmx.password"jmx.access文件内容参考:#用户名 权限jmx.password参考内容:
monitor readonly注意:若无法启动tomcat则建议修改jmx.password文件的权限,权限设置为400或600
#用户名 密码
monitor monitor - 重启tomcat
- 验证jmx端口是否生效:
netstat -antlp |grep 1234
Apache
使用说明
向Apache服务器的server-status模块页面发送请求,获取服务器的运行状态信息。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
Apache版本: 2.2, 2.4
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| SCRAPE_URI | apache server-status模块访问地址(环境变量),如果有http auth则使用http://user:password@localhost/server-status?auto | 是 | http://localhost/server-status/?auto |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| –log.level | 日志级别 | 否 | info |
使用指引
- 配置server-status 默认配置文件存放于
/etc/httpd/conf/httpd.conf需要先检查是否开启mod_status模块,检查文件内容是否含有LoadModule status_module modules/mod_status.so,若没有则需要手动添加 开启模块后,在文件末尾添加以下内容,若已存在则修改对应配置ExtendedStatus On # 开启ExtendedStatus修改后使用
<Location /server-status> # server-status服务地址,按需配置
SetHandler server-status # 开启server-status服务
Deny from all # 禁止任何来源访问,按需配置
Allow from 127.0.0.1 # 允许指定IP访问
</Location>apachectl -t检查配置文件内容是否正确,如果正确会返回Syntax OK,否则会返回错误信息注意: 配置更改后需要重启服务,使用apachectl graceful重启apache服务不会中断原有连接 - 验证server-status 配置完成后,使用
curl http://localhost/server-status?auto验证server-status是否正常工作,如果正常会返回以下内容Total Accesses: 1如果返回
Total kBytes: 0
CPULoad: .000797
Uptime: 884
ReqPerSec: .00113208
BytesPerSec: .000797
BytesPerReq: 702.5
BusyWorkers: 1
IdleWorkers: 7
Scoreboard: _W_______Forbidden,则需要检查配置文件中的Allow from是否正确配置,如果返回Not Found,则需要检查配置文件中的Location是否正确配置
Nginx
使用说明
插件功能
Nginx Exporter通过解析 Nginx 的状态页面和其他可访问的信息源, 从中提取出有价值的监控数据。 该工具能够将从 Nginx 收集到的数据转换为易于理解和分析的监控指标,使用户能够更轻松地监视和评估 Nginx 实例的性能。收集多种关键的 Nginx 指标,从而实现性能优化和故障排查。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| -nginx.common | nginx stub采集开关(开关参数), 默认打开 | 是 | |
| NGINX_SCRAPE_URI | nginx stub访问地址(环境变量) | 否 | http://127.0.0.1:8080/stub_status |
| -nginx.vts | nginx vts采集开关(开关参数), 默认关闭 | 是 | |
| NGINX_VTS_SCRAPE_URI | nginx vts访问地址(环境变量) | 否 | http://127.0.0.1:8080/vts_status |
| -nginx.rtmp | nginx rtmp采集开关(开关参数), 默认关闭 | 是 | |
| NGINX_RTMP_SCRAPE_URI | nginx rtmp访问地址(环境变量) | 否 | http://127.0.0.1:8080/rtmp_status |
| NGINX_RTMP_REGEX_STREAM | nginx rtmp音视频流正则过滤(环境变量), 默认采集所有 | 否 | .* |
| -nginx.timeout | nginx采集超时时间, 默认为5s | 是 | 5s |
| -log.level | 日志级别 | 否 | info |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
注意:采集器所在的服务器需要能够正常访问对应模块功能的地址。
- nginx配置 采集nginx基础指标需要开启stub_status模块。 采集vts类指标需要开启vts模块, 提供对 nginx 虚拟机主机状态数据的访问,可将数据输出格式为json、html、jsonp、prometheus。 采集rtmp类指标需要开启rtmp模块。
- 检查模块配置
通过nginx -V查看模块是否添加成功, 可看到示例中已安装stub_status和vts模块nginx -V
# 返回结果示例
nginx version: nginx/1.25.1
built with OpenSSL 1.1.1n 15 Mar 2022
TLS SNI support enabled
configure arguments: --prefix=/opt/bitnami/nginx --with-http_stub_status_module --with-stream --with-http_gzip_static_module --with-mail --with-http_realip_module --with-http_stub_status_module --with-http_v2_module --with-http_ssl_module --with-mail_ssl_module --with-http_gunzip_module --with-threads --with-http_auth_request_module --with-http_sub_module --with-http_geoip_module --with-compat --with-stream_realip_module --with-stream_ssl_module --with-cc-opt=-Wno-stringop-overread --add-module=/bitnami/blacksmith-sandox/nginx-module-vts-0.2.2 --add-dynamic-module=/bitnami/blacksmith-sandox/nginx-module-geoip2-3.4.0 --add-module=/bitnami/blacksmith-sandox/nginx-module-substitutions-filter-0.20220124.0 --add-dynamic-module=/bitnami/blacksmith-sandox/nginx-module-brotli-0.20220429.0 - nginx配置文件 文件内容示例(一般为nginx.conf)
# 开启 upstram zonesnginx访问控制需要自行配置,
upstream backend{
server 127.0.0.1:80;
}
vhost_traffic_status_zone; # 开启vts统计模块
vhost_traffic_status_filter_by_host on; # 打开vts vhost过滤
vhost_traffic_status_filter_by_set_key $status $server_name; # 开启vts详细状态码统计
server {
server_name *.example.org;
listen 8080;
# vts访问路径
location /vts_status {
vhost_traffic_status_display; # 开启vts展示
vhost_traffic_status_display_format html;
}
# stub_status访问路径
location /stub_status {
stub_status on; # 开启stub_status模块
access_log off;
allow 127.0.0.1; # 只允许本地IP访问
deny all; # 禁止任何IP访问
}
}allow和deny后内容按照实际情况填写。vts除了状态码统计, 还有基于地理信息的统计,根据访问量或访问流量对nginx做访问限制,详细使用见文档: https://github.com/vozlt/nginx-module-vts#installation - 重新加载配置
sudo nginx -t && sudo nginx -s reload - 检查配置
` nginx -t返回结果示例nginx: the configuration file /opt/bitnami/nginx/conf/nginx.conf syntax is ok nginx: configuration file /opt/bitnami/nginx/conf/nginx.conf test is successful ` - 重启服务 如果是改变
Nginx的编译参数、添加新的模块, 通常需要重新编译和安装, 然后重启服务。
Zookeeper
使用说明
插件连接Zookeeper并执行命令:mntr 和 ruok。通过执行这些命令,插件会收集相关输出结果,并将其转化为监控指标以供分析。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
部署模式支持: 单机(Standalone), 集群(Cluster)
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| –zk-hosts | Zookeeper服务的地址,可使用逗号分隔多个服务地址。例如 10.0.0.1:2181,10.0.0.2:2181,10.0.0.3:2181 | 是 | 127.0.0.1:2181 |
| –timeout | 连接超时时间(s) | 否 | 30 |
使用指引
需要确保zookeeper能够响应监控探针输入的命令。 注意从版本v3.4.10开始可能需要 mntr 命令白名单,详情参考: 4lw.commands.whitelist
测试mntr结果
echo mntr | nc 127.0.0.1 2181
zk_version 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 1
zk_packets_sent 0
zk_num_alive_connections 1
zk_outstanding_requests 0
zk_server_state standalone
zk_znode_count 51
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 621501
zk_open_file_descriptor_count 38
zk_max_file_descriptor_count 1048576
zk_fsync_threshold_exceed_count 0测试ruok结果
echo ruok | nc 127.0.0.1 2181
imok% 注意
能采集到的监控指标与zookeeper版本有关,如果发现监控指标有缺失,请检查mntr和ruok是否能显示对应的字段,否则监控探针无法转换为对应的指标。
RabbitMQ
使用说明
插件功能
从rabbitmq服务的管理插件模块页获取服务的运行状态信息。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
rabbitmq版本: 3.7.x, 3.8.x
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| RABBIT_URL | RabbitMQ管理插件的URL | 是 | http://127.0.0.1:15672 |
| RABBIT_USER | RabbitMQ管理插件的用户名,该用户需要具备监控标签 | 是 | guest |
| RABBIT_PASSWORD | RabbitMQ管理插件的密码 | 是 | guest |
| RABBIT_CONNECTION | 连接类型,”direct”或”loadbalancer”. 使用”loadbalancer”时会删除自身标签 | 是 | direct |
| RABBIT_EXPORTERS | 激活的模块列表。可能的模块包括: connections,shovel,federation,exchange,node,queue,memory | 是 | connections,exchange,node,queue,memory |
| RABBIT_TIMEOUT | 从管理插件检索数据的超时时间,以秒为单位 | 是 | 30 |
| LOG_LEVEL | 日志级别,可能的值包括:”debug”, “info”, “warning”, “error”, “fatal”或”panic” | 是 | info |
| SKIP_VHOST | 正则表达式,与之匹配的vhost名字不会被导出。该操作在INCLUDE_VHOST之后进行,适用于队列和交换机 | 是 | ^$ |
| INCLUDE_VHOST | 正则表达式用于过滤vhost. 只有匹配的vhosts会被导出。适用于队列和交换机 | 是 | .* |
| INCLUDE_QUEUES | 正则表达式用于过滤队列. 只有匹配的名字会被导出 | 是 | |
| SKIP_QUEUES | 正则表达式,与之匹配的队列名不会被导出(适用于处理短暂的rpc队列) | 是 | |
| INCLUDE_EXCHANGES | 正则表达式用于过滤交换机. (只有在匹配的vhosts中的交换机会被导出) | 是 | |
| SKIP_EXCHANGES | 正则表达式,与之匹配的交换机名不会被导出 | 是 | |
| MAX_QUEUES | 删除度量之前,队列的最大数量(如果将其设置为0,则禁用) | 是 | 0 |
使用指引
- 需要获取rabbitmq管理插件页面的账户和密码才可使用。
- rabbitmq_up指标与常见的up指标不同,若其他模块的rabbitmq_module_up指标采集异常也会导致rabbitmq_up指标为0,只有全部采集模块正常时rabbitmq_up才会为1,若不清楚哪些模块有问题,可以编辑RABBIT_EXPORTERS参数,减少采集的模块。
TiDB
使用说明
插件功能
从TiDB Server的监控指标接口拉取指标数据
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | http://127.0.0.1:10080/metrics |
使用指引
检查TiDB服务是否正常
TiDB Server
TiDB API 地址:http://${host}:${port}
默认端口:10080
- 获取当前 TiDB Server 的状态
判断该 TiDB Server 是否存活。结果以 JSON 格式返回
curl http://127.0.0.1:10080/status
{
connections: 0, # 当前 TiDB Server 上的客户端连接数
version: "8.0.11-TiDB-v8.1.0", # TiDB 版本号
git_hash: "7267747ae0ec624dffc3fdedb00f1ed36e10284b" # TiDB 当前代码的 Git Hash
}- 使用 metrics 接口
Metrics 接口用于监控整个集群的状态和性能。
curl http://127.0.0.1:10080/metrics
IBM MQ
使用说明
版本支持
操作系统支持: linux
是否支持arm: 不支持
是否支持远程采集:
是
备注: 可在linux远程采集在windows上运行的IBMMQ服务
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| –ibmmq.httpListenHost | 插件监听地址(下发请保持默认) | 是 | 127.0.0.1 |
| –ibmmq.httpListenPort | 插件监听端口(下发请保持默认) | 是 | 9601 |
| –ibmmq.client | 以客户端形式连接(开关参数), 默认关闭 | 否 | |
| –ibmmq.usePublications | 资源发布控制开关, 默认使用true | 否 | |
| –ibmmq.useStatus | 获取所有STATUS开关, 默认使用false | 否 | |
| IBMMQ_CONNECTION_CONNNAME | ibmmq服务连接地址(环境变量), 注意填写形式 ip(port) | 是 | 127.0.0.1(1414) |
| IBMMQ_CONNECTION_QUEUEMANAGER | ibmmq队列管理器名称(环境变量) | 是 | QM1 |
| IBMMQ_CONNECTION_CHANNEL | ibmmq连接通道名称(环境变量) | 是 | SERVER |
| IBMMQ_CONNECTION_USER | ibmmq连接账户名称(环境变量) | 否 | admin |
| IBMMQ_CONNECTION_PASSWORD | ibmmq连接密码(环境变量) | 否 | |
| IBMMQ_OBJECTS_QUEUES | 过滤监控队列正则表达式, 默认使用 * 获取所有队列 | 是 | * |
| –log.level | 日志级别 | 否 | info |
使用指引
- 配置IBM MQ redistributable client 使用该探针的前提条件必须在下发探针的机器配置IBM MQ redistributable client。如果没有配置客户端, 可以下载安装包。
根据需要的版本下载x.x.x.x-IBM-MQC-Redist-LinuxX64.tar.gz
下载地址: IBM MQ redistributable client
指定版本下载地址: 9.3.4.1-IBM-MQC-Redist-LinuxX64.tar.gz
下载后解压到对应目录
linux在目录/opt/mqm下解压, 如果没有该目录请新建一个即可
- 配置账户授权
该配置授权命令windows和linux都可使用
# 进入名称为QM1的队列管理器管理界面
runmqsc QM1
# 查看ccsid
display qmgr ccsid
# 修改队列管理器的ccsid, 建议修改为819
alter qmgr ccsid(819)
# 定义类型为SVRCONN名称为SERVER的远程连接通道,同时授权mqm账号进行远程连接
def chl(SERVER) chltype(SVRCONN) trptype(tcp) mcauser('mqm') replace
# 定义名称为TCP端口为1414的tcp监听端口
def listener(TCP) trptype(tcp) port(1414)
# 启动监听端口
start listener(TCP)定义通道时 SERVER 是填入探针参数 IBMMQ_CONNECTION_CHANNEL的通道名称, mqm 是填入探针参数 IBMMQ_CONNECTION_USER 已存在的账号名称
可以选择验证方式, 一般不建议取消验证
- 正常验证
# 关闭对mqm的禁用
SET CHLAUTH(*) TYPE(BLOCKUSER) USERLIST(*MQADMIN) ACTION(REMOVE) - 取消验证
# 禁用通道校验
ALTER QMGR CHLAUTH(DISABLED)
# 禁用连接权限认证
ALTER QMGR CONNAUTH('')
# 刷新安全策略:
REFRESH SECURITY TYPE(CONNAUTH)
3.19 minio
使用说明
插件功能 从minio的cluster监控指标接口拉取指标数据
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | http://127.0.0.1:9000/minio/v2/metrics/cluster |
使用指引
需要minio提供cluster监控指标接口, 启动minio时加入环境变量 MINIO_PROMETHEUS_AUTH_TYPE=public
nacos
使用说明
插件功能 从nacos提供的监控指标地址拉取监控数据
版本支持
组件支持版本:
nacos版本: >= 0.8.0
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | http://127.0.0.1:8848/nacos/actuator/prometheus |
使用指引
- 提供监控数据接口
配置application.properties文件,暴露metrics数据例如k8s部署的nacos,该配置文件存放于/home/nacos/conf目录,找到application.properties修改或增加配置management.endpoints.web.exposure.include=*修改完成后需要重启nacos服务,然后访问{nacos_ip}:8848/nacos/actuator/prometheus,看是否能访问到metrics数据
WebLogic
使用说明
插件功能 WebLogic监控探针通过使用WebLogic Server的RESTful API ( /management/weblogic/latest/serverRuntime/search ) 导出监控指标数据。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
Weblogic Server: 12.2.1+
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| USERNAME | weblogic登录用户名(环境变量) | 是 | weblogic |
| PASSWORD | weblogic登录密码(环境变量) | 是 | welcome |
| –host | weblogic服务实例IP地址 | 是 | 127.0.0.1 |
| –port | weblogic服务实例端口 | 是 | 7001 |
| –config-file | 采集配置文件(文件参数), 默认内容已填写, 不需要修改 | 是 | config.yaml |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
使用指引
- 验证登录信息 访问Weblogic Servers实例, 登录
host:port/console。默认管理服务器端口一般是7001
输入账户和密码, 验证是否账户是否正确。 - 如果需要采集数据源监控指标
配置数据源指引
如果没有配置数据源, 那么将采集不到wls_datasource_类指标。
Websphere
使用说明
插件功能
从web application server的监控指标接口拉取指标数据
是否支持远程采集:
是
支持版本:
- 9.0.5.7+
- 8.5.5.x
- 特殊版本8.5.5.16需要安装iFix补丁
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | http://127.0.0.1:9080/metrics |
使用指引
websphere application server监控需要完成以下操作
获取metrics.ear文件
metrics.ear 文件存放于 <WAS_HOME>/installableApps 目录下。如果没有可以直接拿包上传安装。
登录websphere
安装metrics服务
- 在工作台最左侧,选择Applications -> Application Type
- 选择右方视图中的 New Enterprise Application
- 选择上传文件 metrics.ear,点击 Next
- 选择Fast Path,点击 Next
- 进入 Select installation options,保持默认选择,点击 Next
- 进入 Map modules to servers,点击 Module 名称为 metrics的一栏中的Select,Select 下方出现 √ 选择才是正确的,点击 Next
- 进入 Summary,点击 Finish 完成配置
- 开始自动开始,等出现 Save 选择即可点击
- 安装完成后返回 Applications -> Enterprise Applications
- 查看右方视图,MetricsApp 一栏的 Application Status 是否正常,绿色箭头代表 Started,红色 × 代表Failed,出现绿色箭头才是正常部署状态
- 如果是异常状态,可以尝试选择 MetricsApp 后再点击 Start 启动
- 配置监控指标
- 进入 Monitoring and Tunning – > Performance Monitoring Infrastructure (PMI) ,选择Name下发的server1
- 选择 Runtime -> Currently monitored statistic set -> All ,点击OK,打开所有监控指标
查看HTTP端口
- 导航到服务器设置: 在管理控制台的左侧导航栏中,展开 Servers > Server Types > WebSphere application servers。点击你想要配置的服务器(例如,server1)。
- 进入通信设置:
在服务器详细信息页面,展开Communications,再点击Ports。 - 查看服务端口信息 找到WC_defaulthost 或类似的 HTTP 端口配置。默认情况下,这个端口可能被禁用或设置为一个你不期望的端口号。 确认或修改WC_defaulthost 端口号。例如,将它设置为 9080(或你希望的端口号)。
获取metrics 获取metrics不需要账户和密码
http://127.0.0.1:9080/metrics
HANA
使用说明
从系统表/视图中收集所有 HANA 信息,SYS 模式下所有以 M 为前缀的表/视图都是监控表/视图,只从 SYS.M* 表/视图中获取数据。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
HanaData数据库版本: 2.x
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| HOST | 数据库服务IP(环境变量) | 是 | |
| PORT | 数据库服务端口(环境变量) | 是 | |
| USER | 数据库账户名(环境变量) | 是 | |
| PASS | 数据库密码(环境变量) | 是 | |
| TIMEOUT | 连接超时时间(s), 默认5s(环境变量) | 否 | 5 |
| –web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| –log.level | 日志级别 | 否 | info |
使用指引
- 配置监控账户 用户需要拥有 SAP_INTERNAL_HANA_SUPPORT 角色才能访问 SYS 模式。如果没有 SAP_INTERNAL_HANA_SUPPORT 角色,这些信息只能由 SYSTEM 用户选择。
注意:配置的用户至少需要对 SYS 模式具有 SELECT 权限,所有收集器将从该模式下的表/视图中收集信息。
授予用户 SAP_INTERNAL_HANA_SUPPORT 角色:GRANT SAP_INTERNAL_HANA_SUPPORT TO user;
达梦
使用说明
采集器连接数据库后执行sql,转换为监控指标。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
达梦数据库: >=8.1.1.126
使用指引
登录数据库并执行命令创建蓝鲸监控账号和授权:
# 创建用户: weops 密码: Weops123!
CREATE USER weops IDENTIFIED BY "Weops123!";
# 要获取DB\table级别的监控信息必须拥有对应数据库的select权限
GRANT SELECT ON v$sessions TO weops;
GRANT SELECT ON V$SYSTEMINFO TO weops;
GRANT SELECT ON V$DM_INI TO weops;
GRANT SELECT ON V$SYSSTAT TO weops;
GRANT SELECT ON V$LOCK TO weops;
GRANT SELECT ON V$PARAMETER TO weops;
GRANT SELECT ON DBA_TABLES TO weops;
GRANT SELECT ON DBA_INDEXES TO weops;
GRANT SELECT ON V$OPEN_STMT TO weops;
GRANT SELECT ON V$RLOGFILE TO weops;
GRANT SELECT ON V$TRX TO weops;
GRANT SELECT ON V$ASMGROUP TO weops;
GRANT SELECT ON V$RLOG TO weops;
GRANT SELECT ON DBA_FREE_SPACE TO weops;
GRANT SELECT ON DBA_DATA_FILES TO weops;
GRANT SELECT ON DBA_OBJECTS TO weops;
GRANT SELECT ON V$BUFFERPOOL TO weops;
GRANT SELECT ON v$rapply_stat TO weops;
GRANT SELECT ON V$ARCH_STATUS TO weops;
GRANT SELECT ON V$UTSK_SYS2 TO weops;
GRANT SELECT ON v$instance TO weops;
GRANT SELECT ON v$dmwatcher TO weops;
GRANT SELECT ON V$DM_MAL_INI TO weops;
GRANT SELECT ON SYS.V$DM_MAL_INI TO weops;
GRANT SOI TO weops;参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| SQL_EXPORTER_USER | 数据库用户名(环境变量),特殊字符不需要编码转义 | 是 | SYSDBA |
| SQL_EXPORTER_PASS | 数据库密码(环境变量),特殊字符不需要编码转义 | 是 | SYSDBA001 |
| SQL_EXPORTER_DB_TYPE | 数据库类型(环境变量) | 是 | dm |
| SQL_EXPORTER_HOST | 数据库服务IP(环境变量) | 是 | 127.0.0.1 |
| SQL_EXPORTER_PORT | 数据库服务端口(环境变量) | 是 | 5236 |
| -config.file | sql_exporter.yml 采集器全局配置文件, 包含超时设置、最大连接数、目标配置、采集指标配置文件名等 | 是 | 默认已有采集器全局配置文件 |
| -log.level | 日志级别 | 否 | info |
| -web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| collector.file.content | *.collector.yml 采集指标配置文件, 包含指标名、维度、sql等内容。注意!该参数为文件参数,非探针执行文件参数! | 是 | 默认已有标准采集指标配置文件 |
GBase8a
使用说明
采集器连接数据库后执行sql,转换为监控指标。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
GBase8a数据库
使用指引
登录数据库并执行命令创建蓝鲸监控账号和授权:
# 创建用户: weops 密码: Weops123!
CREATE USER 'weops' IDENTIFIED BY 'Weops123!';
# 要获取DB\table级别的监控信息必须拥有对应数据库的select权限
GRANT SELECT ON *.* TO 'weops';参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| SQL_EXPORTER_USER | 数据库用户名(环境变量),特殊字符不需要编码转义 | 是 | weops |
| SQL_EXPORTER_PASS | 数据库密码(环境变量),特殊字符不需要编码转义 | 是 | Weops123! |
| SQL_EXPORTER_DB_TYPE | 数据库类型(环境变量) | 是 | gbase8a |
| SQL_EXPORTER_HOST | 数据库服务IP(环境变量) | 是 | 127.0.0.1 |
| SQL_EXPORTER_PORT | 数据库服务端口(环境变量) | 是 | 5258 |
| SQL_EXPORTER_DB_NAME | 数据库名(环境变量) | 是 | gbase |
| -config.file | sql_exporter.yml 采集器全局配置文件, 包含超时设置、最大连接数、目标配置、采集指标配置文件名等 | 是 | 默认已有采集器全局配置文件 |
| -log.level | 日志级别 | 否 | info |
| -web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| collector.file.content | *.collector.yml 采集指标配置文件, 包含指标名、维度、sql等内容。注意!该参数为文件参数,非探针执行文件参数! | 是 | 默认已有标准采集指标配置文件 |
OpenGauss
使用说明
采集器连接数据库后执行sql,转换为监控指标。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
OpenGauss: >= 2.0.1
使用指引
登录数据库并执行命令创建蓝鲸监控账号和授权:
创建账户名 weops, 密码 Weops123!
CREATE USER weops PASSWORD 'Weops123!';参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| SQL_EXPORTER_USER | 数据库用户名(环境变量),特殊字符不需要编码转义 | 是 | SYSDBA |
| SQL_EXPORTER_PASS | 数据库密码(环境变量),特殊字符不需要编码转义 | 是 | SYSDBA001 |
| SQL_EXPORTER_DB_TYPE | 数据库类型(环境变量) | 是 | dm |
| SQL_EXPORTER_HOST | 数据库服务IP(环境变量) | 是 | 127.0.0.1 |
| SQL_EXPORTER_PORT | 数据库服务端口(环境变量) | 是 | 5236 |
| SQL_EXPORTER_DB_NAME | 数据库名(环境变量) | 是 | postgres |
| -config.file | sql_exporter.yml 采集器全局配置文件, 包含超时设置、最大连接数、目标配置、采集指标配置文件名等 | 是 | 默认已有采集器全局配置文件 |
| -log.level | 日志级别 | 否 | info |
| -web.listen-address | exporter监听id及端口地址 | 否 | 127.0.0.1:9601 |
| collector.file.content | *.collector.yml 采集指标配置文件, 包含指标名、维度、sql等内容。注意!该参数为文件参数,非探针执行文件参数! | 是 | 默认已有标准采集指标配置文件 |
ETCD
使用说明
从etcd提供的监控指标接口获取prometheus指标
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
etcd版本: 3.3+
是否支持远程采集:
是
注意 蓝鲸 bk-pull 不支持证书配置,而 etcd 提供的监控指标接口通常需要证书才能访问。
- 本地采集 如果选择在本地采集 etcd 的监控指标,需要在采集机器上安装 agent,该 agent 对本机 IP 进行数据采集。这种方法不需要额外的证书配置,因为采集是在本地进行的。
- 远程采集 对于远程采集,可以使用 NGINX 进行转发。通过配置 NGINX,将 etcd 的 metrics 接口转发到本地端口,并确保 NGINX 的证书配置正确。这样,蓝鲸 bk-pull 可以通过 NGINX 代理访问 etcd 的监控指标。
远程采集时nginx配置示例: 编辑 Nginx 配置文件(通常位于 /etc/nginx/nginx.conf 或 /etc/nginx/conf.d/default.conf),添加一个新的 server 块,用于转发 etcd 的 /metrics 接口。
以下是一个示例配置:
server {
listen 8080; # 本地端口
server_name your_domain_or_ip;
location /metrics {
proxy_pass https://<etcd_node_ip>:2379/metrics; # 填入etcd节点ip
proxy_ssl_certificate /etc/kubernetes/ssl/etcd.pem; # etcd 证书路径
proxy_ssl_certificate_key /etc/kubernetes/ssl/etcd-key.pem; # etcd 证书密钥路径
proxy_ssl_trusted_certificate /etc/kubernetes/ssl/ca.pem; # etcd CA 证书路径
proxy_ssl_verify off; # 禁用主机名验证
proxy_ssl_server_name on;
proxy_ssl_name etcd; # 使用证书中的主机名
proxy_ssl_session_reuse on;
proxy_ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
proxy_ssl_ciphers HIGH:!aNULL:!MD5;
}
}保存配置文件后,重启 Nginx 使配置生效
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | http://127.0.0.1:2379/metrics |
使用指引
etcd内置 /metrics 接口,默认的 2379 端口的访问一般是需要证书
JBoss
注意jboss版本,某些旧版本使用的是jmxrmi,新版本使用的是remote+http ,请选用适用的插件,两类插件的操作指引如下:
插件使用说明
通过抓取和公开JMX目标的mBeans来收集有关应用程序的度量数据,并将这些度量数据转换为Prometheus监控指标格式。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
JBoss: 7.x JBoss EAP: 6.x
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| host | 监听IP(采集器IP),建议使用默认的127.0.0.1 | 是 | 127.0.0.1 |
| port | 监听端口(采集器监听端口),一般为9601,注意不要与已使用端口冲突 | 是 | 9601 |
| username | jmx认证用户名,若未配置则留空 | 否 | |
| password | jmx认证密码,若未配置则留空 | 否 | |
| jmx_url | jmx 连接字符串,格式为service:jmx:remote+http://{服务IP}:{管理端口} | 是 | service:jmx:remote+http://127.0.0.1:9990 |
注意jboss版本,某些旧版本使用的是jmxrmi,新版本使用的是remote+http
如果是旧版本,那么请填写 service:jmx:rmi:///jndi/rmi://{服务IP}:{管理端口}/jmxrmi
使用指引
配置JBoss
需要确保JBoss打开了管理端口,新版本的JBoss默认管理端口为9990,一般都默认打开,否则无法登录。此处新版本指JBoss 7.x 和 JBoss EAP 6.x。
Linux环境
需要配合jboss-cli-client.jar和jmx_exporter.jar使用,具体步骤如下: 如果要运行探针,请执行命令 java -cp jmx_exporter.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer 127.0.0.1:9601 etc/config.yaml
蓝鲸下发的采集任务缺少部分参数,可以更改start.sh内容后再次启动采集任务
客户端包一般存放于<WILDFLY_HOME>/bin/client/jboss-cli-client.jar
config.yaml内容
---
jmxUrl: service:jmx:remote+http://127.0.0.1:9990
ssl: false
username: {JBoss管理员账户}
password: {JBoss管理员密码}
lowercaseOutputName: true
lowercaseOutputLabelNames: true
whitelistObjectNames:
- "jboss.as:subsystem=messaging-activemq,server=*,jms-queue=*"
- "jboss.as:subsystem=messaging-activemq,server=*,jms-topic=*"
- "jboss.as:subsystem=datasources,data-source=*,statistics=*"
- "jboss.as:subsystem=datasources,xa-data-source=*,statistics=*"
- "jboss.as:subsystem=transactions*"
- "jboss.as:subsystem=undertow,server=*,http-listener=*"
- "jboss.as:subsystem=undertow,server=*,https-listener=*"
# - "java.lang:*"
rules:
- pattern: "^jboss.as<subsystem=messaging-activemq, server=.+, jms-(queue|topic)=(.+)><>(.+):"
attrNameSnakeCase: true
name: wildfly_messaging_$3
labels:
$1: $2
- pattern: "^jboss.as<subsystem=datasources, (?:xa-)*data-source=(.+), statistics=(.+)><>(.+):"
attrNameSnakeCase: true
name: wildfly_datasource_$2_$3
labels:
source_name: $1
- pattern: "^jboss.as<subsystem=transactions><>number_of_(.+):"
attrNameSnakeCase: true
name: wildfly_transaction_$1
- pattern: "^jboss.as<subsystem=undertow, server=(.+), (http[s]?-listener)=(.+)><>(bytes_.+|error_count|processing_time|request_count):"
attrNameSnakeCase: true
name: wildfly_undertow_$4
labels:
server_name: $1
listener: $3
Windows环境
windows环境配置原理与linux基本一致,都是通过管理端口连接。
采集方案
方案1 使用蓝鲸JMX采集任务
如果想使用监控平台JMX采集,请确保下发采集机器的java,默认1.8是不支持使用jboss-cli-client.jar的,需要自行安装java。另外蓝鲸自带的jmx_exporter.jar版本过低,需要替换为高级版本。
因蓝鲸JMX采集任务写死java运行命令,下发后,需要找到对应的采集任务目录,添加jmx_prometheus_httpserver-0.20.0.jar和jboss-cli-client.jar路径,并修改start.sh 原始内容java -jar jmx_exporter.jar ${BK_LISTEN_HOST}:${BK_LISTEN_PORT} ${BK_CONFIG_PATH} > ${log_filepath} 2>&1 &
修改为java -cp jmx_prometheus_httpserver-0.20.0.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer ${BK_LISTEN_HOST}:${BK_LISTEN_PORT} ${BK_CONFIG_PATH} > ${log_filepath} 2>&1 &
修改后,重启采集任务即可。
方案2 使用bkpull
在服务器上手动启动监控探针java -cp jmx_prometheus_httpserver-0.20.0.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer 127.0.0.1:9601 config.yaml
启动后,使用bkpull拉取该探针提供的监控指标
bkpull使用说明
从JBoss jmx exporter提供的指标接口采集监控数据。
版本支持
操作系统支持: linux, windows
是否支持arm: 支持
组件支持版本:
JBoss: 7.x JBoss EAP: 6.x
是否支持远程采集:
是
参数说明
| 参数名 | 含义 | 是否必填 | 使用举例 |
|---|---|---|---|
| metrics_url | 采集URL | 是 | 127.0.0.1:9601/metrics |
注意jboss版本,某些旧版本使用的是jmxrmi,新版本使用的是remote+http
如果是旧版本,那么请填写 service:jmx:rmi:///jndi/rmi://{服务IP}:{管理端口}/jmxrmi
使用指引
配置JBoss
需要确保JBoss打开了管理端口,新版本的JBoss默认管理端口为9990,一般都默认打开,否则无法登录。此处新版本指JBoss 7.x 和 JBoss EAP 6.x。
Linux环境
需要配合jboss-cli-client.jar和jmx_exporter.jar使用,具体步骤如下: 如果要运行探针,请执行命令 java -cp jmx_exporter.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer 127.0.0.1:9601 etc/config.yaml
蓝鲸下发的采集任务缺少部分参数,可以更改start.sh内容后再次启动采集任务
客户端包一般存放于<WILDFLY_HOME>/bin/client/jboss-cli-client.jar
config.yaml内容
---
jmxUrl: service:jmx:remote+http://127.0.0.1:9990
ssl: false
username: {JBoss管理员账户}
password: {JBoss管理员密码}
lowercaseOutputName: true
lowercaseOutputLabelNames: true
whitelistObjectNames:
- "jboss.as:subsystem=messaging-activemq,server=*,jms-queue=*"
- "jboss.as:subsystem=messaging-activemq,server=*,jms-topic=*"
- "jboss.as:subsystem=datasources,data-source=*,statistics=*"
- "jboss.as:subsystem=datasources,xa-data-source=*,statistics=*"
- "jboss.as:subsystem=transactions*"
- "jboss.as:subsystem=undertow,server=*,http-listener=*"
- "jboss.as:subsystem=undertow,server=*,https-listener=*"
# - "java.lang:*"
rules:
- pattern: "^jboss.as<subsystem=messaging-activemq, server=.+, jms-(queue|topic)=(.+)><>(.+):"
attrNameSnakeCase: true
name: wildfly_messaging_$3
labels:
$1: $2
- pattern: "^jboss.as<subsystem=datasources, (?:xa-)*data-source=(.+), statistics=(.+)><>(.+):"
attrNameSnakeCase: true
name: wildfly_datasource_$2_$3
labels:
source_name: $1
- pattern: "^jboss.as<subsystem=transactions><>number_of_(.+):"
attrNameSnakeCase: true
name: wildfly_transaction_$1
- pattern: "^jboss.as<subsystem=undertow, server=(.+), (http[s]?-listener)=(.+)><>(bytes_.+|error_count|processing_time|request_count):"
attrNameSnakeCase: true
name: wildfly_undertow_$4
labels:
server_name: $1
listener: $3
Windows环境 windows环境配置原理与linux基本一致,都是通过管理端口连接。
采集方案
方案1 使用蓝鲸JMX采集任务
如果想使用监控平台JMX采集,请确保下发采集机器的java,默认1.8是不支持使用jboss-cli-client.jar的,需要自行安装java。
因蓝鲸JMX采集任务写死java运行命令,下发后,需要找到对应的采集任务目录,修改start.sh
原始内容java -jar jmx_exporter.jar ${BK_LISTEN_HOST}:${BK_LISTEN_PORT} ${BK_CONFIG_PATH} > ${log_filepath} 2>&1 &
修改为java -cp jmx_exporter.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer ${BK_LISTEN_HOST}:${BK_LISTEN_PORT} ${BK_CONFIG_PATH} > ${log_filepath} 2>&1 &
修改后,重启采集任务即可。
方案2 使用bkpull
在服务器上手动启动监控探针java -cp jmx_exporter.jar:jboss-cli-client.jar io.prometheus.jmx.WebServer 127.0.0.1:9601 config.yaml
启动后,使用bkpull拉取该探针提供的监控指标
告警源插件说明
| 序号 | 告警源插件 | 版本 |
|---|---|---|
| 1 | REST API | 无需版本适配 |
| 2 | VCenter | 5.5及以上 |
| 3 | 华为云 | |
| 4 | 阿里云 | |
| 5 | 腾讯云 | |
| 6 | 听云 | |
| 6 | Zabbix | 3.X、4.X、5.X |
| 7 | Prometheus | 2.15 |
| 8 | 日志易 | 3.6 |
| 9 | H3C-IMC | |
| 10 | 华为esight系统 | |
| 11 | 绿盟日志审计系统 | V2.0 |
日志内容说明
日志探针说明
Weops支持日志探针管理和安装,并内置探针对应的配置文件模板详情如下,若查看更加详细内容可下载表格WeOps内置日志探针说明
| 序号 | 探针名称 | 探针说明 | 内置模板 |
|---|---|---|---|
| 1 | Filebeat | 能够采集操作系统中的任意日志文件。 | 1、自定义模板 2、内置模板:ActiveMQ 、Coredns 、Elasticsearch、IIS、Kafka、mongodb、mssql、MySQL、Nginx、Oracle、PostgreSQL、RabbitMQ、Redis、Apache Tomcat |
| 2 | Packetbeat | 能够采集操作系统中的流量数据 | 1、自定义模板 2、内置模板:AMQP、Cassandra、DHCPv4、DNS、HTTP、ICMP、Memcache、MongoDb、MySQL、NFS、PostgreSQL(pgSQL)、Redis、SIP、Thrift-RPC、Detailed TLS |
| 3 | Auditbeat | 能够监听文件或操作系统的变更动态,例如文件发生了修改、用户登录了操作系统等。 | 1、自定义模板 2、内置模板:文件变化日志、系统变更日志 |
| 4 | Metricbeat | 轻量级的指标收集器,用于监控和收集系统和应用程序的指标数据 | 1、自定义模板 2、内置模板:system指标日志、Window指标日志、linux指标日志、docker指标日志 |
| 5 | Winlogbeat | 能够采集Windows事件 | 1、自定义模板 2、内置模板:应用程序日志、安全事件日志、系统事件日志 |
| 6 | Uniprobe | 与packetbeat功能类似,额外具备http请求的响应延迟、操作系统的网络环境质量等数据 | 1、自定义模板 |
日志提取器说明
WeOps支持的提取器如下表
| 提取器名称 | 适用 | 说明 |
|---|---|---|
| 复制输入 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 将原始消息中的一部分数据复制到提取器的规则中,并将其存储在结构化的数据字段中 |
| Grok模式 | 适用于需要从非结构化的日志数据中提取特定字段或值的场景。 | 用于从非结构化的日志数据中提取结构化数据。它使用预定义的Grok模式或自定义Grok模式来匹配和提取数据,包括一些特殊的模式,用于匹配常见的数据格式,如IP地址、日期、时间戳等。(WeOps内置常用的Grok表达式)(Grok表达式是一种用于解析非结构化或半结构化数据的模式匹配工具。它是由Elasticsearch社区开发的一种基于正则表达式的模式匹配语言) |
| JSON | 适用于处理JSON格式的日志数据的场景。 | 可以从JSON格式的数据中提取特定的字段,并将它们存储在结构化的数据字段中。 |
| 正则表达式 | 适用于需要从未结构化的日志数据中提取特定字段或值的场景。 | 使用正则表达式从数据中提取特定的字段,并将它们存储在结构化的数据字段中 |
| 正则表达式替换 | 适用于需要替换日志数据中特定字符串的场景。 | 正则表达式替换器可以使用正则表达式从数据中匹配特定的模式,并将其替换为指定的字符串 |
| 分隔 | 适用于需要从日志数据中提取特定字段或值的场景。 | 使用指定的分隔符将数据分割成多个部分,并将它们存储在结构化的数据字段中 |
| 子窜捕获 | 适用于需要从日志数据中提取特定子字符串的场景。 | 使用指定的开始和结束字符串或位置来捕获数据中的子串,并将它们存储在结构化的数据字段中 |
日志NIDS网络入侵识别能力
WeOps支持接入NIDS网络入侵识别识别日志,支持的识别规则类别如下,点击可下载WeOps-NIDS网络入侵识别能力清单,
| 规则类型 | 说明 |
|---|---|
| CVE | 识别利用CVE通用漏洞进行的网络攻击 |
| Malicious_behavior | 识别常见的可疑行为,例如利用http请求执行netstat命令 |
| Crypto_miner_pool | 识别与常见公共矿池地址进行的网络传输 |
| MySQL | 识别特定的 MySQL 数据库恶意活动 |
| DNS_tunnel | 识别可疑的DNS隧道请求 |
| ICMP_tunnel | 识别可疑的ICMP隧道请求 |
| Behinder | 识别冰蝎渗透 |
| Metasploit | 识别Metasploit渗透 |
| PHP_Weevely_Webshell | 识别Weevely渗透 |
| PowerShell_Empire | 识别PowerShell Empire渗透 |
| webshell_caidao | 识别菜刀渗透 |
| CobaltStrike | 识别CobaltStrike渗透 |
APM内容说明
服务器-应用探针接入
支持语言框架说明
WeOps目前封装支持两类开发语言,java和python,具体的框架如下
(1)Java
| 库/框架 | 支持版本 |
|---|---|
| Akka Actors | 2.5+ |
| Akka HTTP | 10.0+ |
| Apache Axis2 | 1.6+ |
| Apache Camel | 2.20+ (不包括3.x) |
| Apache DBCP | 2.0+ |
| Apache CXF JAX-RS | 3.2+ |
| Apache CXF JAX-WS | 3.0+ |
| Apache Dubbo | 2.7+ |
| Apache HttpAsyncClient | 4.1+ |
| Apache HttpClient | 2.0+ |
| Apache Kafka Producer/Consumer API | 0.11+ |
| Apache Kafka Streams API | 0.11+ |
| Apache MyFaces | 1.2+ (不包括3.x) |
| Apache Pulsar | 2.8+ |
| Apache RocketMQ gRPC/Protobuf-based Client | 5.0.0+ |
| Apache RocketMQ Remoting-based Client | 4.8+ |
| Apache Struts 2 | 2.3+ |
| Apache Tapestry | 5.4+ |
| Apache Wicket | 8.0+ |
| Armeria | 1.3+ |
| AsyncHttpClient | 1.9+ |
| AWS Lambda | 1.0+ |
| AWS SDK | 1.11.x和2.2.0+ |
| Azure Core | 1.14+ |
| Cassandra Driver | 3.0+ |
| Couchbase Client | 2.0+和3.1+ |
| c3p0 | 0.9.2+ |
| Dropwizard Metrics | 4.0+ (默认禁用) |
| Dropwizard Views | 0.7+ |
| Eclipse Grizzly | 2.3+ |
| Eclipse Jersey | 2.0+ (不包括3.x) |
| Eclipse Jetty HTTP Client | 9.2+ (不包括10+) |
| Eclipse Metro | 2.2+ (不包括3.x) |
| Eclipse Mojarra | 1.2+ (不包括3.x) |
| Elasticsearch API Client | 7.16+和8.0+ |
| Elasticsearch REST Client | 5.0+ |
| Elasticsearch Transport Client | 5.0+ |
| Finatra | 2.9+ |
| Geode Client | 1.4+ |
| Google HTTP Client | 1.19+ |
| Grails | 3.0+ |
| GraphQL Java | 12.0+ |
| gRPC | 1.6+ |
| Guava ListenableFuture | 10.0+ |
| GWT | 2.0+ |
| Hibernate | 3.3+ (not including 6.x yet) |
| HikariCP | 3.0+ |
| HttpURLConnection Java | 8+ |
| Hystrix | 1.4+ |
| Java Executors | Java 8+ |
| Java Http Client | Java 11+ |
| java.util.logging | Java 8+ |
| Java Platform | Java 8+ |
| JAX-RS | 0.5+ |
| JAX-RS Client | 1.1+ |
| JAX-WS | 2.0+ (not including 3.x yet) |
| JBoss Log Manager | 1.1+ |
| JDBC | Java 8+ |
| Jedis | 1.4+ |
| JMS | 1.1+ |
| Jodd Http | 4.2+ |
| JSP | 2.3+ |
| Kotlin Coroutines | 1.0+ |
| Ktor | 1.0+ |
| Kubernetes Client | 7.0+ |
| Lettuce | 4.0+ |
| Log4j 1 | 1.2+ |
| Log4j 2 | 2.11+ |
| Logback | 1.0+ |
| Micrometer | 1.5+ |
| MongoDB Driver | 3.1+ |
| Netty | 3.8+ |
| OkHttp | 2.2+ |
| Oracle UCP | 11.2+ |
| OSHI | 5.3.1+ |
| Play | 2.4+ |
| Play WS | 1.0+ |
| Quartz | 2.0+ |
| R2DBC | 1.0+ |
| RabbitMQ Client | 2.7+ |
| Ratpack | 1.4+ |
| Reactor | 3.1+ |
| Reactor Netty | 0.9+ |
| Rediscala | 1.8+ |
| Redisson | 3.0+ |
| RESTEasy | 3.0+ |
| Restlet | 1.0+ |
| RMI Java | 8+ |
| RxJava | 1.0+ |
| Scala ForkJoinPool | 2.8+ |
| Servlet | 2.2+ |
| Spark Web Framework | 2.3+ |
| Spring Boot | |
| Spring Batch | 3.0+ (not including 5.0+ yet) |
| Spring Data | 1.8+ |
| Spring Integration | 4.1+ (not including 6.0+ yet) |
| Spring JMS | 2.0+ |
| Spring Kafka | 2.7+ |
| Spring RabbitMQ | 1.0+ |
| Spring Scheduling | 3.1+ |
| Spring RestTemplate | 3.1+ |
| Spring Web MVC | 3.1+ |
| Spring Web Services | 2.0+ |
| Spring WebFlux | 5.3+ |
| Spymemcached | 2.12+ |
| Tomcat JDBC Pool | 8.5.0+ |
| Twilio | 6.6+ (not including 8.x yet) |
| Undertow | 1.4+ |
| Vaadin | 14.2+ |
| Vert.x Web | 3.0+ |
| Vert.x HttpClient | 3.0+ |
| Vert.x Kafka Client | 3.6+ |
| Vert.x RxJava2 | 3.5+ |
| Vert.x SQL Client | 4.0+ |
| Vibur DBCP | 11.0+ |
| ZIO | 2.0.0+ |
(2)python
| 库/框架 |
|---|
| aio_pika |
| aiohttp_client |
| aiopg |
| asgi |
| asyncpg |
| aws_lambda |
| base |
| boto |
| boto3sqs |
| botocore |
| celery |
| confluent_kafka |
| dbapi |
| django |
| elasticsearch |
| falcon |
| fastapi |
| flask |
| grpc |
| httpx |
| jinja2 |
| kafka_python |
| logging |
| mysql |
| mysqlclient |
| pika |
| psycopg2 |
| pymemcache |
| pymongo |
| pymysql |
| pyramid |
| redis |
| remoulade |
| requests |
| sqlalchemy |
| sqlite3 |
| starlette |
| system_metrics |
| tornado |
| tortoiseorm |
| urllib |
| urllib3 |
| wsgi |
(3)其他
| 库/框架 |
|---|
| Node.js |
| TypeScript |
接入步骤说明
(1)Java
WeOps采用OpenTelemetry探针无代码侵入的接入方式, 支持上百种Java框架自动上传Trace数据, 详细的Java框架列表请参见支持清单,若您的Java框架不在支持清单,请参考接入文档进行手动接入。
前置检查
开始探针安装前,请检查主机环境,确保满足以下条件:
1、 WeOps数据接收端所在系统和探针所在系统的时钟同步
2、 WeOps数据接收端所在系统和探针所在系统、后端服务之间网络环境正常可以相互通信
3、 探针所在系统Java运行环境已安装
4、 服务启动所使用的操作系统用户具备探针安装目录的读、写、运行权限安装流程
1、下载Agent,通过“WeOps-管理-APM关联-应用接入”页面下载
2、修改启动参数
java -javaagent:<opentelemetry-javaagent.jar文件路径> -Dotel.resource.attributes=service.name=<服务英文名>,bk.biz.id=41,probe.name=3781099f-a6c8-48d6-aedf-7fdff1ff1eca -Dotel.exporter.otlp.endpoint=10.10.26.235:4317 -Dotel.metrics.exporter=none -jar <myapp.jar>3、前往“WeOps-APM-调用链”查看调用链情况
(2)Python
WeOps采用OpenTelemetry探针无代码侵入的接入方式, 支持数十种Python框架自动上传Trace数据, 详细的Python框架列表请参见支持清单,若您的Python框架不在支持清单,请参考接入文档进行手动接入。
前置检查
开始探针安装前,请检查主机环境,确保满足以下条件:
1、 WeOps数据接收端所在系统和探针所在系统的时钟同步
2、 WeOps数据接收端所在系统和探针所在系统、后端服务之间网络环境正常可以相互通信
3、 探针所在系统Python运行环境已安装
4、 服务启动所使用的操作系统用户具备探针安装目录的读、写、运行权限安装流程
1、在项目中安装OpenTemetry组件
pip install opentelemetry-distro opentelemetry-exporter-otlp
opentelemetry-bootstrap -a install2、项目运行时修改OpenTemetry配置并运行
opentelemetry-instrument --traces_exporter otlp --resource_attributes "bk.biz.id=32" --resource_attributes "probe.name=4dff9337-5e2a-4de9-a372-2edcae98d89c" --exporter_otlp_endpoint 10.10.26.235:4317 --service_name <服务英文名> python <myapp.py>3、前往“WeOps-APM-调用链”查看调用链情况
K8S集群-应用探针接入
K8S集群的OT探针接入指引
前置准备
以下内容需要按照顺序进行部署
(1)部署cert manager到集群
可参考: https://cert-manager.io/docs/installation/
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.3/cert-manager.yaml等待cert-manager全部就绪才可部署opearator,例如
kubectl get pod -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-56588b57f4-6pbc2 1/1 Running 0 5d5h
cert-manager-cainjector-7bbf568f47-m2f6l 1/1 Running 0 5d5h
cert-manager-webhook-7f7c7898cc-b9x6f 1/1 Running 0 5d5h(2)部署operator
需要注意依赖的k8s版本,最下方已列出对应的版本依赖
# 版本v0.82.0
kubectl apply -f https://github.com/open-telemetry/opentelemetry-operator/releases/download/v0.82.0/opentelemetry-operator.yaml(3)部署Instrumentation
注意: 必须指定命名空间以对特定命名空间的资源进行注入,否则将不会生效。例如,如果未指定命名空间,只有默认命名空间才能接受自动注入
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: my-instrumentation
namespace: tomcat
spec:
propagators:
- tracecontext
- baggage
- b3
sampler:
type: parentbased_traceidratio
argument: "0.25"
java:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://127.0.0.1:4317
- name: OTEL_RESOURCE_ATTRIBUTES
value: bk.biz.id=2
- name: OTEL RESOURCE_ATTRIBUTES
value: 18ed4404-f20b-457d-a5e8-7fa964061823
容器安装探针
(1)提前拉取java agent镜像
docker pull ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-java:1.28.0(2)添加参数
- 注意部署文件中annotations的添加位置,在多容器情况下需要指定注入的容器名称
- 若Instrumentation修改过,则注入容器的部署部分需要重新部署,或者重新拉起新的pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-with-multiple-containers
spec:
selector:
matchLabels:
app: my-pod-with-multiple-containers
replicas: 1
template:
metadata:
labels:
app: my-pod-with-multiple-containers
annotations:
instrumentation.opentelemetry.io/inject-java: "true"
instrumentation.opentelemetry.io/container-names: "myapp"
spec:
containers:
- name: myapp
image: myImage1
- name: myapp2
image: myImage2
- name: myapp3
image: myImage3查看调用链
版本依赖
目前WeOps内置的探针版本为v0.82.0,适用的K8S版本号为:v1.19 to v1.27
| OpenTelemetry Operator | Kubernetes | Cert-Manager |
|---|---|---|
| v0.90.0 | v1.23 to v1.28 | v1 |
| v0.89.0 | v1.23 to v1.28 | v1 |
| v0.88.0 | v1.23 to v1.28 | v1 |
| v0.87.0 | v1.23 to v1.28 | v1 |
| v0.86.0 | v1.23 to v1.28 | v1 |
| v0.85.0 | v1.19 to v1.28 | v1 |
| v0.84.0 | v1.19 to v1.28 | v1 |
| v0.83.0 | v1.19 to v1.27 | v1 |
| v0.82.0 | v1.19 to v1.27 | v1 |
| v0.81.0 | v1.19 to v1.27 | v1 |
| v0.80.0 | v1.19 to v1.27 | v1 |
| v0.79.0 | v1.19 to v1.27 | v1 |
| v0.78.0 | v1.19 to v1.27 | v1 |
| v0.77.0 | v1.19 to v1.26 | v1 |
| v0.76.1 | v1.19 to v1.26 | v1 |
| v0.75.0 | v1.19 to v1.26 | v1 |
K8S集群Beyla接入指引
第一步、创建命名空间并配置权限
创建命名空间 kubectl create namespace beyla
创建ServiceAccount并绑定ClusterRole授权,授予pod和ReplicaSets的list和watch权限
apiVersion: v1
kind: ServiceAccount
metadata:
name: beyla
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: beyla
rules:
- apiGroups: ["apps"]
resources: ["replicasets"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: beyla
subjects:
- kind: ServiceAccount
name: beyla
namespace: beyla
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: beyla第二步、配置Beyla的采集规则
部署Beyla前,需通过配置采集规则,定义采集K8S集群中的哪些数据
apiVersion: v1
kind: ConfigMap
metadata:
namespace: beyla
# 如果需要接入多个的业务,需部署多套Beyla,需更改metadata.name保证不重复
name: beyla-config
data:
beyla-config.yml: |
# 开启kubernetes发现和元数据
attributes:
kubernetes:
enable: true
# 提供自动路由报告,同时最小化基数
routes:
unmatched: heuristic
# 填写需要检测的服务的deployment,比如检测docs的deployment
discovery:
services:
- k8s_deployment_name: "^docs$" # 根据实际的命名规则调整正则表达式
# 还可以支持检测多个deployment,比如解除下方注释则会同时检测docs和website的deployment
# - k8s_deployment_name: "^website$"除了使用k8s_deployment_name字段作为检测规则外,还支持以下字段(选择一类字段使用即可):
- k8s_pod_name
- k8s_namespace
- k8s_replicaset_name
- k8s_statefulset_name
- k8s_daemonset_name
- k8s_owner_name (
Deployment,ReplicaSet,DaemonSetorStatefulSet)
第三步、使用DaemonSet方式部署Beyla
具体如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: beyla
# 如果需要接入多个的业务,需部署多套Beyla,需更改metadata.name保证不重复
name: beyla
spec:
selector:
matchLabels:
instrumentation: beyla # 需与metadata.name保持一致
template:
metadata:
labels:
instrumentation: beyla # 需与metadata.name保持一致
spec:
serviceAccountName: beyla
hostPID: true # 必须为true,否则将导致Beyla服务异常
volumes:
- name: beyla-config
configMap:
name: beyla-config # 需与第二步中采集规则的metadata.name一致
containers:
- name: beyla
image: grafana/beyla:1.3.1
securityContext:
privileged: true # 必须为true,否则将导致Beyla服务异常
volumeMounts:
- mountPath: /config
name: beyla-config
env:
- name: BEYLA_CONFIG_PATH
value: /config/beyla-config.yml
- name: OTEL_EXPORTER_OTLP_ENDPOINT
valueFrom:
secretKeyRef:
name: grafana-credentials
key: otlp-endpoint
- name: OTEL_EXPORTER_OTLP_HEADERS
valueFrom:
secretKeyRef:
name: grafana-credentials
key: otlp-headers
- name: OTEL_RESOURCE_ATTRIBUTES
value: bk.biz.id=2 # WeOps中的配置应用id仪表盘说明
仪表盘说明
| 序号 | 仪表盘名称 | 关键指标 |
|---|---|---|
| 1 | 单主机运行状态 | CPU使用率、应用内存可用率、磁盘空间使用率、1分钟系统负载、系统进程数、磁盘IO使用率、当前连接数、网卡出流量、网卡入流量、可用inode数量 |
| 2 | 应用主机运行状态 | CPU使用率、内存剩余空间、磁盘空间使用率、5分钟系统负载、磁盘IO使用率、当前连接数、网卡出流量、网卡入流量 |
| 3 | Oracle监控 | 数据库状态、服务器CPU使用率、服务器内存使用率、数据库会话数、进程数、解析次数、执行次数、PGA使用率、表空间使用率、SGA使用率、当前资源使用量、用户提交次数、ASM磁盘使用率、系统I/O等待时间、用户I/O等待时间、归档日志空间使用率 |
| 4 | MySQL监控 | 服务器CPU使用率、服务器内存使用率、执行命令总数、当前已连接的线程数、查询缓存命中数、慢查询的次数、最大连接数、IO线程运行状态、InnoDB日志文件大小、主从延迟时间、SQL线程运行状态、InnoDB缓冲池大小、打开文件数、查询总次数 |
| 5 | MSSQL监控 | 数据库状态、数据库连接数、用户错误数、服务器CPU使用率、服务器内存使用率、缓冲区命中率、阻塞进程数、数据库文件使用率、页面错误次数、I/O暂停时间、数据库日志文件使用率、页面读取数、死锁数、批量请求、页面写入数 |
| 6 | Redis监控仪表盘 | Redis可用性、内存碎片率、客户端连接数、拒绝的连接数、服务器CPU使用率、服务器内存使用率、处理命令数、网络接送流量、Key数量、过期的key数量、已删除key数量、命令执行数量、命令执行时间 |
| 7 | Apache监控仪表盘 | Apache状态、运行时间、服务进程状态、重启配置次数、服务器CPU使用率、服务器内存使用率、总访问次数、发送总量、进程CPU秒数总计、进程最大文件描述符数、进程打开文件描述符数、服务平均负载、CPU使用负载 |
| 8 | Tomcat监控仪盘 | 服务器CPU使用率、服务器内存使用率、会话数、请求数、过期会话数、全局处理总时长、发送的流量、接收的流量、线程连接数、当前线程数、繁忙线程数 |
| 9 | Nginx监控仪盘 | Nginx监控状态、活动连接数、已接受连接数、已处理连接数、服务器CPU使用率、服务器内存使用率、读取连接数、写入连接数、空闲连接数、请求总数 |
仪表盘各个组件说明
| 所属模块 | 组件名称 | 作用 | 支持的配置 |
|---|---|---|---|
| 监控 | 仪表盘 | 展示指定时间范围内,该监控指标的最近数值 | 1、配置需要展示的监控指标 2、可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量” 3、支持配置仪表盘展示的最大值/最小值,支持选择各个阈值的配色 |
| 监控 | 单值 | 展示指定时间范围内,该监控指标的最近数值 | 1、配置需要展示的监控指标 2、可以根据选择的维度汇聚方式展示“最大值”“最小值”“平均值”“累加值”“维度数量” |
| 监控 | 饼形图 | 指定时间范围内,该监控指标的最近数值,每个饼状图代表一项资产,若有多维度则展示百分比 | 1、配置需要展示的监控指标 |
| 监控 | 柱状图 | 展示指定时间范围内,该监控指标的最近数值;柱状图的每一簇代表一项资产,若资产有多维度,则展示多条 | 1、配置需要展示的监控指标 |
| 监控 | 折线图 | 以时间为横坐标展示指定时间内该监控指标的数值变化,多资产和多维度都在用一个折线图中展示 | 1、配置需要展示的监控指标 2、支持配置阈值线 3、支持配置是否面积填充 |
| 资产 | 资产表格 | 展示选中的资产基本配置信息 | 1、支持配置所有资产管理的资产 2、支持选择展示的字段 3、对于枚举型字段等特殊字段,支持筛选/排序等操作 |
| 自动化 | 运维工具 | 展示/执行各个运维工具 | 1、配置展示不同的运维工具 2、在仪表盘直接使用该工具对选中的资产进行操作,并展示执行结果 |
| 日志 | 日志消息 | 展示日志的原始消息 | 1、配置搜索条件 2、配置展示字段 3、支持配置某个字段的升序/降序 |
| 日志 | 单值 | 展示单个数值或统计结果,最近数据的第一个值 | 1、配置分组和度量,确定统计的角度和值 2、设置趋势:越大越好、越小越好,普通 |
| 日志 | 表格 | 以表格的形式展示各个分组的度量统计数值 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 饼形图 | 按照特定度量字段,统计各个分组该度量值所占的百分比 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 折线图 | 用于展示统计数据的变化趋势,比如随时间的变化趋势 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 |
| 日志 | 柱状图 | 以柱形图展示日志数据,展示各个分组的度量值 | 1、配置搜索语句 2、配置分组和度量,确定统计的角度和值 3、配置排序,分组和度量的字段可以设置排序 4、支持设置堆叠/分组模式 |
| 日志 | 地图 | 以地图的形式展示IP地址的地域分布情况 | 1、配置搜索语句 2、选择中国地图/世界地图 3、配置地域字段 4、支持阈值配色 |
| 高级 | 单值 | 填写Trino语句,获取对应数据后,以单值形式呈现 | 1、填写Trino语句 |
| 高级 | 折线图 | 填写Trino语句,获取对应数据后,以折线图形式呈现 | 1、填写Trino语句 2、配置X轴、Y轴展示的数值和维度数值 |
| 高级 | 饼形图 | 填写Trino语句,获取对应数据后,以饼形图形式呈现 | 1、填写Trino语句 2、配置分组(组别)和度量值 |
| 高级 | 柱状图 | 填写Trino语句,获取对应数据后,以柱状图形式呈现 | 1、填写Trino语句 2、配置X轴、Y轴展示的数值和维度数值 |
| 高级 | 表格 | 填写Trino语句,获取对应数据后,以表格形式呈现 | 1、填写Trino语句 |
| 高级 | 流量拓扑 | 填写Trino语句,获取对应数据后,以流量拓扑形式呈现 | 1、填写Trino语句 2、配置源对象和目标对象 3、配置连线数值和阈值配色 |
| 高级 | 桑基图 | 填写Trino语句,获取对应数据后,以桑基图形式呈现 | 1、填写Trino语句 2、配置源对象、目标对象和度量值 |
健康扫描包说明
共内置11个扫描包,各个扫描包的介绍和相关指标见下表
| 序号 | 扫描包名称 | 对象 | 操作系统 | 检查项数量 | 检查项 |
|---|---|---|---|---|---|
| 1 | 基础健康检查-Windows | 主机 | Windows | 10 | Windows是否激活、内存可用大小、磁盘空间使用率(Windows)、磁盘可用空间(Windows)、磁盘IO读速率、磁盘IO写速率、DCP时间百分比、处理器队列长度、逻辑磁盘队列长度、每秒页面错误数 |
| 2 | 基础健康检查-Linux | 主机 | Linux | 8 | 磁盘空间使用率(Linux)、磁盘可用空间(Linux)、交换空间使用率、iNode可用大小、iNode使用率、僵尸进程数、TIME_WAIT状态的连接数、passwd文件权限 |
| 3 | 基础健康检查-ActiveDirectory | ActiveDirectory | 4 | AD数据库文件盘可用空间、AD数据库日志文件盘可用空间、AD健康性检查、时间偏差检查 | |
| 4 | 基础健康检查-ExchangeServer | ExchangeServer(支持系统为Exchange Server 2016/2019的邮箱角色) | 22 | 关键服务测试、活动目录连接测试、ActiveSync连接测试、Ecp连接测试、Imap连接测试、Owa连接测试、Pop连接测试、Outlook连接测试、Smtp连接测试、复制健康性测试、数据包出站错误、数据库平均读延迟、数据库平均写延迟、数据库日志平均读延迟、数据库日志平均写延迟、应用重启次数、工作进程重启次数、应用队列中的请求数、RPC请求数(信息存储进程)、RPC平均延迟(客户端协议)、RPC平均延迟(数据库)、证书过期时间 | |
| 5 | 基础健康检查- MSSQL(Windows) | MSSQL | Windows | 26 | 缓冲区命中率、磁盘空间使用率、可用连接数、MSSQL内存可用大小、阻塞源会话(近一个小时)、死锁情况(近一个小时)、长事务(TOP5)、页生存周期、实例内存使用情况、数据库使用内存、可用线程数、资源等待Top5、磁盘队列数、群集资源状态、群集网络状态、群集仲裁状态、AlwaysOn同步健康状态、AlwaysOn发送队列大小、AlwaysOn重做队列大小、AlwaysOn重做延迟时长、文件组可用大小、错误日志磁盘可用大小、作业执行失败Top20、最近备份时间、SQL代理服务启动方式、最近完整备份时间 |
| 6 | 基础健康检查- MySQL(Windows) | MySQL | Windows | 17 | InnoDB缓冲区命中率、每秒查询数、每秒事务数、每秒全表扫描数量、慢查询数量、数据空间使用率、Binlog日志空间使用率、不能立即获得表锁次数、InnoDB行锁次数、可用连接数、数据文件总大小、InnoDB缓存池可用大小、锁等待数量、操作系统CPU使用率、操作系统内存使用率、操作系统内存可用大小、操作系统交换空间使用率 |
| 7 | 基础健康检查- MySQL(Linux) | MySQL | Linux | 17 | InnoDB缓冲区命中率、每秒查询数、每秒事务数、每秒全表扫描数量、慢查询数量、数据空间使用率、Binlog日志空间使用率、不能立即获得表锁次数、InnoDB行锁次数、可用连接数、数据文件总大小、InnoDB缓存池可用大小、锁等待数量、操作系统CPU使用率、操作系统内存使用率、操作系统内存可用大小、操作系统交换空间使用率 |
| 8 | 基础健康检查- Oracle(Windows) | Oracle | Windows | 20 | 缓冲区命中率、共享池命中率、表空间空间使用率、归档空间使用率、数据空间使用率、ASM磁盘组空间使用率、可用会话数、可用进程数、SQL硬解析百分比、内存排序百分比、无效索引个数、行锁等待大于1分钟数量、联机日志每小时切换次数、DG状态、最近备份成功状态、实例状态、监听状态、Oracle目录使用率、操作系统内存使用率、操作系统内存可用大小 |
| 9 | 基础健康检查- Oracle(Linux) | Oracle | Linux | 14 | 缓冲区命中率、共享池命中率、表空间空间使用率、可用会话数、可用进程数、SQL硬解析百分比、内存排序百分比、无效索引个数、行锁等待大于1分钟数量、联机日志每小时切换次数、最近备份成功状态、实例状态、监听状态、Oracle目录使用率 |
| 10 | 基础健康检查- vCenter(Windows) | vCenter | Windows | 7 | 物理机最新启动时间、物理机cpu使用率、物理机内存使用率、物理机上虚拟机数量、存储空间使用率、物理机NTP服务器、物理机NTP服务状态 |
| 11 | 基础健康检查- vCenter(Linux) | vCenter | Linux | 7 | 物理机最新启动时间、物理机cpu使用率、物理机内存使用率、物理机上虚拟机数量、存储空间使用率、物理机NTP服务器、物理机NTP服务状态 |
运维工具说明
内置的脚本工具的介绍见下表
| 序号 | 工具类型 | 工具名 | 脚本类型 | 工具介绍 |
|---|---|---|---|---|
| 1 | 操作系统类 | 查询消耗系统内存最多的进程 | shell(Linux) | 查找出Linux系统当前占用内存资源最多的TopN进程 |
| 2 | 操作系统类 | 查询消耗系统CPU最多的进程 | shell(Linux) | 查找出Linux系统当前占用CPU资源最多的TopN进程 |
| 3 | 操作系统类 | MSSQL全库备份 | powershell(Windows) | 将MSSQL全库备份到所选服务器的指定目录,支持SQL Server 2008 R2及以上版本 |
| 4 | 操作系统类 | 修改Windows本地账号密码 | powershell(Windows) | 修改Windows本地账号密码,支持Powershell 5.2及以上版本 |
| 5 | 操作系统类 | 修改Linux账号密码 | shell(Linux) | 修改Linux账号密码 |
| 6 | 操作系统类 | 查询系统本地帐户信息 | powershell(Windows) | 查找出Windows系统所有本地帐户的信息 |
| 7 | 操作系统类 | 查询AD用户上次登陆时间 | powershell(Windows) | 查找出指定的AD用户上次登陆时间,需在域服务器执行该脚本 |
| 8 | 操作系统类 | 查询服务进程状态信息 | shell(Linux) | 查找出Linux系统指定进程的状态信息 |
| 9 | 操作系统类 | 查询占用空间最大的目录和文件 | shell(Linux) | 查找出Linux系统指定目录下占用空间最大的top N目录和文件 |
| 10 | 操作系统类 | Ping | shell(Linux) | 测试所选主机与目标主机的数据连通性是否正常 |
| 11 | 操作系统类 | 查看Linux日志文件 | shell(Linux) | 查看Linux日志文件,协助问题排查 |
| 12 | 操作系统类 | AD密码质量审计 | powershell(Windows) | 执行AD审计,检查AD账号使用弱密码、重复密码、默认密码和空密码等情况 |
| 13 | 操作系统类 | 查找容量最大的文件 | shell(Linux) | 查找容量最大的文件 |
| 14 | 操作系统类 | 统计目录的文件数量 | shell(Linux) | 统计目录的文件数量 |
| 15 | 操作系统类 | 查询僵尸进程数 | shell(Linux) | 查询僵尸进程数 |
| 16 | 操作系统类 | 查询文件打开数最多的进程 | shell(Linux) | 查询文件打开数最多的进程 |
| 17 | 操作系统类 | MySQL显示错误日志内容 | shell(Linux) | MySQL显示错误日志内容 |
| 18 | 操作系统类 | Oracle显示错误日志内容 | shell(Linux) | Oracle显示错误日志内容 |
| 19 | 操作系统类 | MySQL显示参数值 | shell(Linux) | MySQL显示参数值 |
| 20 | 操作系统类 | 查询网络连接数最多的服务 | python(Linux) | 查询网络连接数最多的服务 |
| 21 | 操作系统类 | 查找UID或GID为0的系统用户 | shell(Linux) | 查找UID或GID为0的系统用户 |
| 22 | 操作系统类 | 查询已删除用户的进程 | shell(Linux) | 查询已删除用户的进程 |
| 23 | 操作系统类 | Oracle显示参数值 | shell(Linux) | Oracle显示参数值 |
| 24 | 操作系统类 | 查询权限为777的文件 | shell(Linux) | 查询权限为777的文件 |
| 25 | 操作系统类 | 统计TIME_WAIT连接数量 | python(Linux) | 统计TIME_WAIT连接数量 |
| 26 | 操作系统类 | 查询无属主或无属组的文件 | shell(Linux) | 查询无属主或无属组的文件 |
| 27 | 操作系统类 | 查询进程的文件打开数 | shell(Linux) | 查询进程的文件打开数 |
| 28 | 操作系统类 | 收集sosreport | shell(Linux) | 收集sosreport或 supportconfig |
| 29 | 操作系统类 | 检查拥有sudo权限账号或组 | shell(Linux) | 检查拥有sudo权限账号或组 |
| 30 | 操作系统类 | MySQL查询实例连接数和活动连接数 | shell(Linux) | MySQL查询实例连接数和活动连接数 |
| 31 | 操作系统类 | Oracle查询实例连接数和活动连接数 | shell(Linux) | Oracle查询实例连接数和活动连接数 |
| 32 | 操作系统类 | Oracle查看正在运行的SQL语句 | shell(Linux) | Oracle查看正在运行的SQL语句 |
| 33 | 操作系统类 | Oracle查看最近15分钟的等待事件 | shell(Linux) | Oracle查看最近15分钟的等待事件 |
| 34 | 操作系统类 | Oracle查询会话增长趋势 | shell(Linux) | Oracle查询会话增长趋势 |
| 35 | 操作系统类 | Oracle查看当前的等待事件 | shell(Linux) | Oracle查看当前的等待事件 |
| 36 | 操作系统类 | Oracle查看表空间的大小和可用空间 | shell(Linux) | Oracle查看表空间的大小和可用空间 |
| 37 | 操作系统类 | Oracle查看数据库锁信息 | shell(Linux) | Oracle查看数据库锁信息 |
| 38 | 操作系统类 | 查看系统防火墙启用情况 | powershell(Windows) | 查看系统防火墙启用情况 |
| 39 | 操作系统类 | 查看占用内存 Top10进程信息 | powershell(Windows) | 查看占用内存 Top10进程信息 |
| 40 | 操作系统类 | Oracle查看ASM磁盘组大小和可用空间 | shell(Linux) | Oracle查看ASM磁盘组大小和可用空间 |
| 41 | 操作系统类 | Oracle查询数据库中具有DBA权限的用户 | shell(Linux) | Oracle查询数据库中具有DBA权限的用户 |
| 42 | 操作系统类 | MySQL查看表空间的大小和可用空间 | shell(Linux) | MySQL查看表空间的大小和可用空间 |
| 42 | 操作系统类 | MySQL查询当前运行的SQL语句 | shell(Linux) | MySQL查询当前运行的SQL语句 |
| 43 | 操作系统类 | 查看所有物理网卡的网线连接状态 | shell(Linux) | 查看所有物理网卡的网线连接状态 |
| 44 | 操作系统类 | Linux补丁升级 | shell(Linux) | 适用于已部署Yum源的Linux服务器 |
| 序号 | 工具类型 | 工具名 | 脚本类型 | 工具介绍 |
|---|---|---|---|---|
| 1 | 网络设备类 | 显示CDP查找进程的结果(思科) | telnet | 可以看见本地接口ID,与此接口直连的设备ID,设备类型,若对端接口是路由接口,可以看见对端接口ID |
| 2 | 网络设备类 | 显示打开的CDP接口信息(思科) | telnet | 可以看见接口状态,连接状态,封装类型,发送cdp报文周期 |
| 3 | 网络设备类 | 显示CDP表中所列相邻设备的信息(思科) | telnet | 展示运行cdp协议的邻居设备的详细信息:设备ID,厂家,设备能力,ip地址,IOS类型和版本,设备功能 |
| 4 | 网络设备类 | 展示总包吞吐量(思科) | telnet | |
| 5 | 网络设备类 | 展示接口统计信息(思科) | telnet | 显示设置在路由器和访问服务器上所有接口的统计信息 |
| 6 | 网络设备类 | 显示连接所有用户(思科) | telnet | |
| 7 | 网络设备类 | 显示产品库存清单(思科) | telnet | 显示安装的所有思科产品的产品库存清单和UDI |
| 8 | 网络设备类 | 显示接口的状态和全局参数(思科) | telnet | |
| 9 | 网络设备类 | 显示路由选择表的当前状态(思科) | telnet | |
| 10 | 网络设备类 | 显示IP路由表信息(思科) | telnet | |
| 11 | 网络设备类 | 显示路由器的进程(思科) | telnet | |
| 12 | 网络设备类 | 显示设置的协议(思科) | telnet | 显示全局和接口的第三层协议的特定状态。 |
| 13 | 网络设备类 | 显示内存大小(思科) | telnet | |
| 14 | 网络设备类 | 展示进程内存使用量(思科) | telnet | 显示每个系统进程或指定进程使用的内存量 |
| 15 | 网络设备类 | 展示进程CPU使用率(思科) | telnet | 显示所有进程及其CPU利用率 |
| 16 | 网络设备类 | 显示系统版本信息(思科) | telnet |
【备注】网络设备自动化运维支持的范围如下 | 类别|型号| | —–| —-| | 网络设备自动化支持的型号|A10, Accedian, AdtranOS,AlcatelAos,NokiaSros, ApresiaAeos, Arista, Aruba, HPProcurve, HPProcurve, ExtremeErs, ExtremeVsp, BroadcomIcos, RuckusFastiron, ExtremeNetiron, ExtremeNos,ExtremeNos, VyOS, CheckPointGaia, CalixB6,CentecOS,CienaSaos,CiscoAsa,CiscoFtd,CiscoIos,CiscoNxos,CiscoS300,CiscoTpTcCe,CiscoWlc,CiscoIos,CiscoXr,CloudGenixIon,Coriant,DellForce10,DellForce10,DellDNOS6,DellForce10,DellOS10,DellPowerConnect,DellIsilon,DlinkDS,Endace,Eltex,EltexEsr,Enterasys,ExtremeExos,ExtremeErs,ExtremeExos, ExtremeNetiron,ExtremeNos,ExtremeSlx,ExtremeNos,ExtremeVsp,ExtremeWing,F5Tmsh,F5Tmsh,F5Linux,Flexvnf,Fortinet,Generic,TerminalServer,HPComware,HPProcurve,Huawei,HuaweiSmartAX,HuaweiSmartAX,HuaweiVrpv8,IpInfusionOcNOS,Juniper,Juniper,JuniperScreenOs,Keymile,KeymileNOS,Linux, MikrotikRouterOs,MikrotikSwitchOs,MellanoxMlnxos, MellanoxMlnxos,MrvLx, MrvOptiswitch,NetAppcDot,NetgearProSafe,Netscaler, NokiaSros, OneaccessOneOS,OvsLinux, PaloAltoPanos,Pluribus,QuantaMesh,RaisecomRoap,RuckusFastiron,RuijieOS,SixwindOS,SophosSfos,TPLinkJetStream,UbiquitiEdge, UbiquitiEdgeRouter, UbiquitiEdge, UbiquitiUnifiSwitch,VyOS, WatchguardFireware, ZteZxros, Yamaha,|
内置工单流程
共内置5个自动化工单流程,具体介绍见下表
| 序号 | 服务名称 | 服务流程 |
|---|---|---|
| 1 | AD账号创建 | 【前置条件】AD已经纳管/AD凭据已经录入→【提单】填写新建的信息→【管理员审批】选择域和组→【自动执行】引用自动化流程自动批量创建→【发送邮件】申请人接收通知邮件 |
| 2 | AD账号密码重置 | 【前置条件】AD已经纳管/AD凭据已经录入→【提单】填写重置信息→【管理员审批】选择域和组→【自动执行】引用自动化流程自动批量重置→【发送邮件】申请人接收通知邮件 |
| 3 | AD账号禁用 | 【前置条件】AD已经纳管/AD凭据已经录入→【提单】填写禁用的信息→【管理员审批】选择域和组→【自动执行】引用自动化流程自动批量禁用→【发送邮件】申请人接收通知邮件 |
| 4 | AD账号删除 | 【前置条件】AD已经纳管/AD凭据已经录入→【提单】填写删除的信息→【管理员审批】选择域和组→【自动执行】引用自动化流程自动批量删除→【发送邮件】申请人接收通知邮件 |
| 5 | 数据库SQL语句执行 | 【前置条件】数据库已经纳管/数据库凭据已经录入→【提单】填写执行对象和SQL语句→【管理员审批】审批并选择凭据→【自动执行】引用自动化流程自动执行 |
| 6 | VMware虚拟机创建 | 【前置条件】vcenter已经纳管并设置自动发现/凭据已经录入→【提单】填写申请的虚拟机配置→【管理员审批】审批并选择凭据→【自动执行】引用自动化流程自动执行 |
| 7 | VMware虚拟机快照创建 | 【前置条件】vcenter已经纳管并设置自动发现/凭据已经录入→【提单】填写申请的信息→【管理员审批】审批并选择凭据→【自动执行】引用自动化流程自动执行 |
| 8 | VMware虚拟机快照回滚 | 【前置条件】vcenter已经纳管并设置自动发现/凭据已经录入→【提单】填写申请的信息→【管理员审批】审批并选择凭据→【自动执行】引用自动化流程自动执行 |
共内置36个工单流程,具体介绍见下表
| 序号 | 服务类型 | 服务流程 | 流程字段 |
|---|---|---|---|
| 1 | 【AD相关】 | 开通AD帐号 | 使用人、账号名、显示名、手机号、邮箱、部门、使用时间、禁用时间、用途、紧急程度 |
| 2 | 【AD相关】 | 续用AD帐号 | 使用人、账号名、手机号、邮箱、部门、禁用时间、原因、紧急程度 |
| 3 | 【AD相关】 | 修改AD帐号信息 | 使用人、账号名、部门、修改内容、原因、紧急程度 |
| 4 | 【AD相关】 | 重置AD帐号密码 | 使用人、账号名、部门、原因、紧急程度 |
| 5 | 【AD相关】 | 禁用AD帐号 | 使用人、账号名、部门、原因、紧急程度 |
| 6 | 【邮箱相关】 | 开通邮箱帐号 | 使用人、账号名、手机号、部门、使用时间、释放时间、邮箱容量、原因、紧急程度 |
| 7 | 【邮箱相关】 | 续用邮箱帐号 | 使用人、邮箱、部门、释放时间、补充说明、紧急程度 |
| 8 | 【邮箱相关】 | 扩容邮箱帐号 | 使用人、邮箱、部门、原因、扩容量、紧急程度 |
| 9 | 【邮箱相关】 | 注销邮箱帐号 | 使用人、邮箱、部门、原因、紧急程度 |
| 10 | 【服务器相关】 | 申请服务器 | 使用人、部门、使用时间、释放时间、规格、操作系统、指定IP、用途、补充说明、紧急程度 |
| 11 | 【服务器相关】 | 续用服务器 | 使用人、部门、服务器IP、释放时间、用途、紧急程度 |
| 12 | 【服务器相关】 | 释放服务器 | 使用人、部门、服务器IP、原因、紧急程度 |
| 13 | 【服务器相关】 | 扩容服务器 | 使用人、部门、服务器IP、现规格、扩充至、紧急程度 |
| 14 | 【服务器相关】 | 创建服务器快照 | 使用人、部门、服务器IP、原因、紧急程度 |
| 15 | 【服务器相关】 | 回滚服务器快照 | 使用人、部门、服务器IP、原因、快照时间、紧急程度 |
| 16 | 【服务器相关】 | 服务器文件上传 | 使用人、部门、服务器IP、操作系统、原因、紧急程度、附件 |
| 17 | 【服务器相关】 | 服务器文件下载 | 使用人、部门、服务器IP、操作系统、文件路径、原因、紧急程度 |
| 18 | 【服务器相关】 | 开通网络策略 | 使用人、部门、服务器IP、开通端口、用途、紧急程度 |
| 19 | 【笔记本相关】 | 申请笔记本 | 使用人、部门、操作系统、型号、规格、预装软件、使用时间、退还时间、用途、紧急程度 |
| 20 | 【笔记本相关】 | 续用笔记本 | 使用人、部门、资产编码、型号、退还时间、原因、紧急程度 |
| 21 | 【笔记本相关】 | 维修笔记本 | 使用人、部门、资产编码、型号、是否为公司电脑、维修方式、故障现象、故障原因、紧急程度 |
| 22 | 【笔记本相关】 | 更换笔记本 | 使用人、部门、资产编码、型号、现规格型号、期望规格型号、原因、紧急程度 |
| 23 | 【笔记本相关】 | 退还笔记本 | 使用人、部门、资产编码、型号、原因 |
| 24 | 【笔记本相关】 | 安装办公软件 | 使用人、部门、资产编码、型号、操作系统、软件名称、软件版本、用途、紧急程度 |
| 25 | 【办公设备相关】 | 申请办公设备 | 使用人、部门、设备类型、使用时间、退还时间、用途、其他要求、紧急程度 |
| 26 | 【办公设备相关】 | 续用办公设备 | 使用人、部门、资产编码、设备类型、型号、退还时间、原因、紧急程度 |
| 27 | 【办公设备相关】 | 维修办公设备 | 使用人、部门、资产编码、设备类型、型号、故障现象、故障原因 |
| 28 | 【办公设备相关】 | 更换办公设备 | 使用人、部门、资产编码、设备类型、现规格型号、期望规格型号、原因、紧急程度 |
| 29 | 【办公设备相关】 | 退还办公设备 | 使用人、部门、资产编码、型号、原因 |
| 30 | 【办公设备相关】 | 打印机加纸 | 设备位置、紧急程度 |
| 31 | 【办公设备相关】 | 更换墨盒 | 设备位置、紧急程度 |
| 32 | 【门禁相关】 | 申请门禁账号 | 使用人、工号、部门、使用时间、注销时间、原因、紧急程度 |
| 33 | 【门禁相关】 | 续用门禁帐号 | 使用人、工号、部门、注销时间、原因、紧急程度 |
| 34 | 【门禁相关】 | 重置门禁密码 | 使用人、工号、部门、原因、紧急程度 |
| 35 | 【门禁相关】 | 注销门禁账号 | 使用人、工号、部门、原因、紧急程度 |
| 36 | 【告警转工单】 | 告警转工单 | 标题、关联业务、影响范围、紧急程度、优先级、描述 |
技术说明
资源需求说明
服务器资源需求
标准架构说明
WeOps采用蓝鲸PaaS+SaaS的基础架构,通过PaaS的管控平台能力和在客户端安装Agent实现纳管,并为企业的IT运维部门提供覆盖资源管理、监控告警、健康扫描、运维工具等多项功能为一体的运维工具,以故障定位和全生命周期管理为核心,持续保障业务连续性。
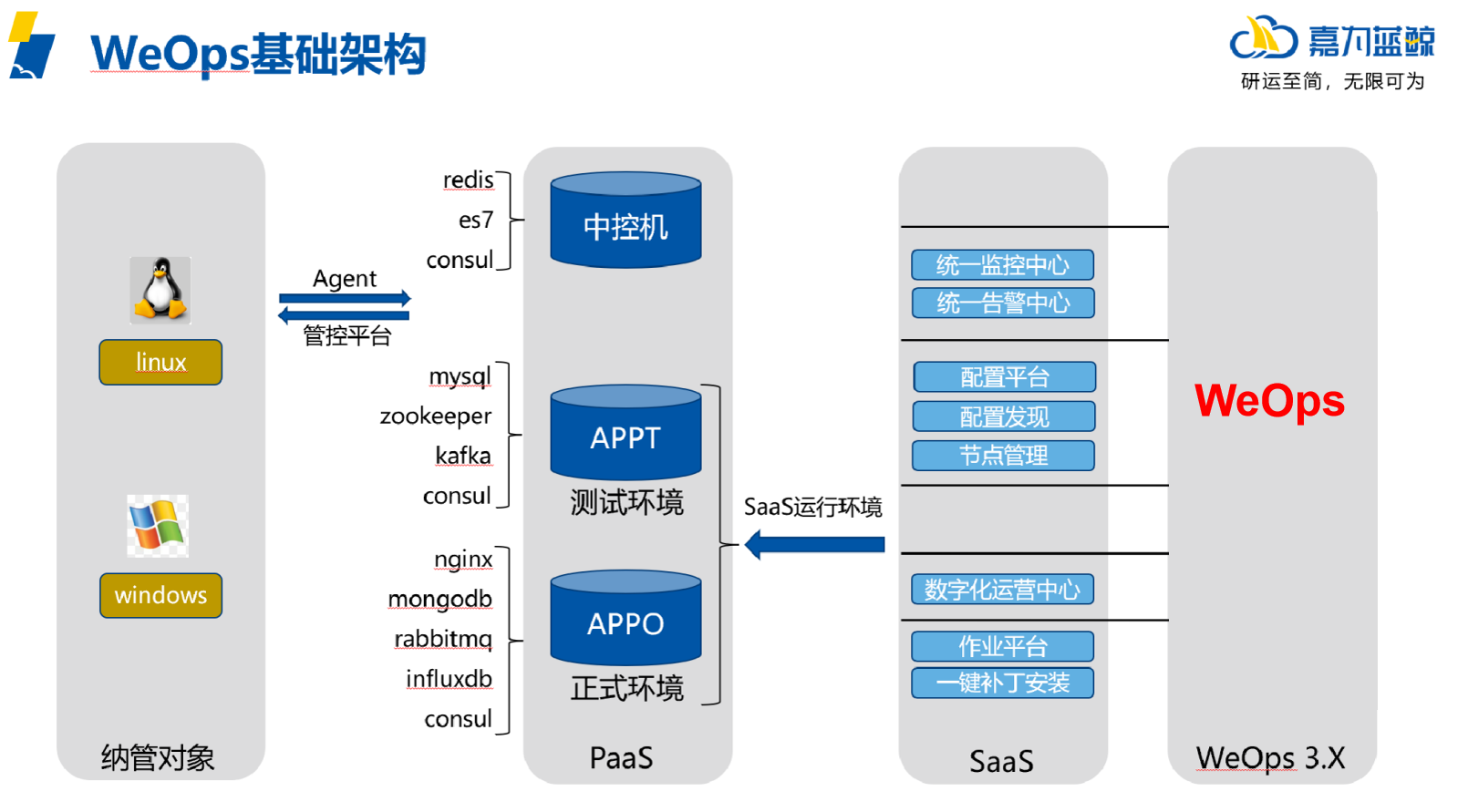
标准资源需求
服务器资源需求为标准3台架构,推荐配置如下:
| 序号 | 节点角色 | 推荐操作系统 | CPU最低配置 | 内存推荐配置 | 数据盘空间(务必划分至/data,建议支持在线扩容) | 组件清单 |
|---|---|---|---|---|---|---|
| 1 | 中控机 | RedHat/CentOS7.9 64位 | 8核 | 32GB | 200GB | iam,ssm,usermgr,gse,license,redis,consul,es7,monitorv3(influxdb-proxy),monitorv3(monitor),monitorv3(grafana) |
| 2 | APPO | RedHat/CentOS7.9 64位 | 8核 | 32GB | 200GB | nginx,consul,mongodb,rabbitmq,appo,influxdb(bkmonitorv3),monitorv3(transfer),fta,beanstalk |
| 3 | APPT | RedHat/CentOS7.9 64位 | 8核 | 32GB | 200GB | paas,cmdb,job,mysql,zk(config),kafka(config),appt,consul,log(api),nodeman(nodeman) |
支持部署的操作系统
| CPU架构 | 操作系统 |
|---|---|
| x86 | Open Euler 20.03 |
| x86 | 银河麒麟v10sp3 |
| x86 | Rocky Linux8 |
| x86 | RedHat 8 |
| arm64 | 银河麒麟v10 sp3 |
网络权限需求
| 纳管对象 | 源地址 | 方向 | 目标地址 | 协议 | 端口 | 用途 |
|---|---|---|---|---|---|---|
| 直连主机 | linux | nodeman –> agent | TCP | 22 | SSH协议,节点管理推送Linux-Agent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | |
| windows | nodeman –> agent | TCP | 135,137,139 | RPC协议,节点管理推送Windows-Agent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||
| TCP | 445 | SMB协议,节点管理推送Windows-Agent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| TCP | 1025-5000 | RPC动态端口(WinSvr08或以前),节点管理推送Windows-Agent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| TCP | 49152-65535 | RPC动态端口(WinSvr08R2之后),节点管理推送Windows-Agent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| linux/windows | gse_btsvr –> agent | TCP | 60020-60030 | BT传输 | ||
| agent –> nodeman | TCP | 80,443 | 节点管理后台Nginx端口,用于介质下载、上报日志、获取配置 | |||
| TCP | 10300 | 节点管理后台CallBack端口,用于回调获取配置 | ||||
| agent –> zk | TCP | 2181 | agent从zk获取GSE配置 | |||
| agent –> gse_task | TCP | 48533 | GSE任务服务端口 | |||
| agent –> gse_data | TCP | 58625 | GSE数据上报端口 | |||
| agent –> gse_btsvr | TCP | 59173 | BT传输 | |||
| agent –> gse_btsvr | TCP,UDP | 10020 | BT传输 | |||
| agent –> gse_btsvr | UDP | 10030 | BT传输 | |||
| 非直连主机 | linux | Proxy –> Pagent | TCP | 22 | SSH协议,节点管理推送Linux-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | |
| windows | Proxy –> Pagent | TCP | 135,137,139 | RPC协议,节点管理推送Windows-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||
| TCP | 445 | SMB协议,节点管理推送Windows-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| TCP | 1025-5000 | RPC动态端口(WinSvr08或以前),节点管理推送Windows-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| TCP | 49152-65535 | RPC动态端口(WinSvr08R2之后),节点管理推送Windows-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||||
| linux/windows | nodeman –> Proxy | TCP | 22 | SSH协议,节点管理推送Linux-Pagent(仅用于一次性远程安装,可临时开通,手动安装可不开通) | ||
| gse_btsvr –> Proxy | TCP | 60020-60030 | BT传输 | |||
| Proxy –> Pagent | ||||||
| Pagent –> Proxy | TCP | 17980,17981 | Proxy CallBack 端口,用于转发Pagent的回调 | |||
| Proxy –> nodeman | TCP | 80,443 | 节点管理后台Nginx端口,用于介质下载、上报日志、获取配置 | |||
| TCP | 10300 | 节点管理后台CallBack端口,用于回调获取配置 | ||||
| Proxy –> zk | TCP | 2181 | Proxy从zk获取GSE配置 | |||
| Pagent –> Proxy | TCP | 48533 | GSE任务服务端口 | |||
| Proxy –> gse_task | ||||||
| Pagent –> Proxy | TCP | 58625 | GSE数据上报端口 | |||
| Proxy –> gse_data | ||||||
| Pagent –> Proxy | TCP | 58725 | Ping告警数据上报端口 | |||
| Pagent –> Proxy | TCP | 59173 | BT传输 | |||
| Proxy –> gse_btsvr | ||||||
| Pagent –> Proxy | TCP,UDP | 10020 | BT传输 | |||
| Proxy –> gse_btsvr | ||||||
| Pagent –> Proxy | TCP | 10030 | BT传输 | |||
| Proxy –> gse_btsvr | ||||||
| 云平台 | Vmware | “automate接入点 (如默认区域采集节点)” –> vSphere API | TCP | 443 | 使用HTTPS协议连接vSphere API进行自动发现及监控采集 | |
| 腾讯云 | –> CVM API | 使用HTTPS协议连接CVM API进行自动发现及监控采集,采集腾讯云需要访问 *.tencentcloudapi.com的域名 | ||||
| 阿里云 | –> ECS API | 使用HTTPS协议连接ECS API进行自动发现及监控采集,采集阿里云需要访问 *.aliyuncs.com的域名 | ||||
| 华为云ManageOne | –> RESTful API | 使用HTTPS协议连接RESTful API进行自动发现及监控采集 | ||||
| 华为公有云 | –> OpenStack API | 使用HTTPS协议连接OpenStack API进行自动发现及监控采集,采集华为云需要访问 *.myhuaweicloud.com的域名 | ||||
| 深信服超融合 | –> RESTful API | 使用HTTPS协议连接RESTful API进行自动发现及监控采集 | ||||
| 网络设备 | 防火墙/路由器/负载均衡/交换机 “weops-proxy接入点 (如默认区域采集节点)” –> 防火墙/路由器/负载均衡/交换机 | UDP | 161 | 使用SNMP协议连接目标网络设备进行自动发现及监控采集 | ||
| 防火墙/路由器/负载均衡/交换机 –> SNMP Trap服务端 | UDP | 162 | 网络设备通过SNMP Trap向服务端发送告警信息 | |||
| 硬件设备 | 硬件服务器 “weops-proxy接入点 (如默认区域采集节点)” –> 硬件服务器 | UDP | 161 | 使用SNMP协议连接目标硬件服务器进行监控采集 | ||
| UDP | 623 | 使用IPMI协议连接目标硬件服务器进行监控采集 | ||||
| K8S | / | K8S集群 –> weops-chart接入点 | TCP | 9093 | 数据回写到WeOps的Prometheus | |
| 自定义上报 | / | 自定义上报源 –> weops指定自定义上报服务器 | TCP | 10205 | 自定义上报默认端口 |
告警源接入API
1、调用方式
POST
2、调用格式
{
“ip”: ‘10.0.0.1’, // 告警对象
“source_time”: ” 2022-04-13 17:00:53 “, // 告警发生的时间,格式:YYYY-MM-DD HH:mm:ss,必须
“alarm_type”: “api_default”, // 告警指标,必须
“level”: “remain”, // 告警级别,必须,枚举:remain/warning/fatal(提醒/警告/致命)
“alarm_name”: “FAILURE for production/HTTP”, // 告警名称,可选
“alarm_content”: “FAILURE for production/HTTP on machine 10.0.0.1”, // 告警详情,可选
“meta_info”: “结算中心”, // 告警其余信息,可选
“action”: “firing”, // 告警事件动作,可选,不传默认是firing, 枚举:firing/resolved(产生告警/消除告警)
“bk_obj_id”: “host”, // CMDB模型ID,可选,
“bk_inst_id”: 2, // CMDB模型实例ID,可选
}
3、参数列表
| 参数 | 必须 | 备注 |
|---|---|---|
| ip | Y | 告警对象 |
| source_time | Y | 告警发生的时间,格式:YYYY-MM-DD HH:mm:ss |
| alarm_type | Y | 告警指标 |
| level | Y | 告警级别 |
| alarm_name | N | 告警名称 |
| alarm_content | N | 告警详情 |
| meta_info | N | 告警其余信息 |
| action | N | 告警事件动作 |
| bk_obj_id | N | CMDB模型ID |
| bk_inst_id | N | CMDB模型实例ID |
备注信息:告警源为REST API的告警,会根据告警源ID+告警对象+告警指标+告警级别,自动生成唯一的告警事件I
4、标准返回字段说明
| 名称 | 类型 | 说明 |
|---|---|---|
| result | bool | 请求成功与否,true:请求成功,false:请求失败 |
| code | string | 返回状态码:1200为成功,其余为失败 |
| data | object | 请求成功返回的数据 |
| message | string | 请求失败返回的错误消息 |
5、调用示例

通知支持方式说明
邮件
邮件是相对较为常见的通知方式,对接配置比较简便,需提供一个发件箱,并允许蓝鲸对SMTP服务器的访问权限。参数说明如下:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到dest_url,ESB 仅作请求转发即可打通邮件配置
smtp_host: SMTP 服务器地址 (注意区分企业邮箱还是个人邮箱)
smtp_port: SMTP 服务器端口 (注意区分企业邮箱还是个人邮箱)
smtp_user: SMTP 服务器帐号
smtp_pwd: SMTP 服务器帐号密码 (一般为授权码)
smtp_usessl: 默认为 False
smtp_usetls: 默认为 False
mail_sender: 默认的邮件发送者 (smtp_user 相同)
短信
企业采用的短信服务厂商不尽相同,目前蓝鲸仅支持腾讯云sms服务开箱即用,其他厂商对接需企业提供短信服务接口文档,并在蓝鲸侧做定制适配,以下以腾讯云sms为例列举参数说明:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到 dest_url,ESB 仅作请求转发即可打通短信配置
qcloud_app_id: SDK AppID
qcloud_app_key: App Key
qcloud_sms_sign: 在腾讯云 SMS 申请的签名,比如:腾讯科技
企业微信
1)企业微信对接需要满足以下先决条件:
a)统一告警中心SaaS(这里指SaaS所在蓝鲸appo服务器)能够访问外网(统一告警中心的告警会先把消息推送到企业微信服务器,然后企业微信再转发推送到客户的企业微信上,所以蓝鲸服务器需要能够访问公网);
b)蓝鲸平台的域名需要发布在公网;
c)外部访问蓝鲸公网域名+端口和在客户内网环境访问蓝鲸域名+端口需要一致,这是由告警中心这个SaaS的底层代码和企信的回调域设置决定的。事实上,告警中心移动端的配置是通过企信扫二维码实现的,这个二维码由SaaS生成,其实质是一个url,这个url只能从内网的蓝鲸服务器获取。因此,企信去访问这个url时,要先访问发布在公网的蓝鲸域名。强烈推荐蓝鲸平台采用https方式部署。
2)逻辑架构参考下图:
3)企业微信对接需在统一告警中心填写以下参数:
企业ID:在企业微信后台“我的企业”中可以获取到;
AgentID,Secret:在应用的基础信息中可以获取到